Groupes de disponibilité distribués
S'applique à : ![]() SQL Server
SQL Server
Un groupe de disponibilité distribué est un type spécial de groupe de disponibilité qui s’étend sur deux groupes de disponibilité distincts. Les groupes de disponibilité distribués sont disponibles à partir de SQL Server 2016.
Cet article décrit la fonctionnalité de groupe de disponibilité distribué. Pour configurer un groupe de disponibilité distribué, consultez Configurer des groupes de disponibilité distribués.
Vue d’ensemble
Un groupe de disponibilité distribué est un type spécial de groupe de disponibilité qui englobe deux groupes de disponibilité distincts. Les groupes de disponibilité qui participent à un groupe de disponibilité distribué n’ont pas besoin de se trouver au même emplacement. Ils peuvent être physiques, virtuels, locaux, ou se trouver dans le cloud public ou en tout lieu prenant en charge le déploiement d’un groupe de disponibilité. Ils peuvent notamment être sur plusieurs domaines et même sur plusieurs plateformes, comme entre un groupe de disponibilité hébergé sur Linux et un hébergé sur Windows. Tant que les deux groupes de disponibilité peuvent communiquer, vous pouvez configurer un groupe de disponibilité distribué avec eux.
Un groupe de disponibilité traditionnel a des ressources configurées dans un cluster de basculement Windows Server (WSFC) ou, pour Linux, dans Pacemaker. Un groupe de disponibilité distribué ne configure rien dans le cluster sous-jacent (WSFC ou Pacemaker). Tout élément le concernant est géré dans SQL Server. Pour savoir comment afficher les informations relatives à un groupe de disponibilité distribué, consultez Affichage des informations relatives aux groupes de disponibilité distribués.
Un groupe de disponibilité distribué requiert que les groupes de disponibilité sous-jacents aient un écouteur. Au lieu de fournir le nom du serveur sous-jacent pour une instance autonome (ou, dans le cas d’une instance de cluster de basculement SQL Server, la valeur associée à la ressource de nom réseau) comme vous le feriez avec un groupe de disponibilité traditionnel, vous spécifiez l’écouteur configuré pour le groupe de disponibilité distribué avec le paramètre ENDPOINT_URL quand vous le créez. Bien que chaque groupe de disponibilité sous-jacent du groupe de disponibilité distribué ait un écouteur, un groupe de disponibilité distribué n’en a pas.
La figure suivante montre une vue générale d’un groupe de disponibilité distribué qui comprend deux groupes de disponibilité (AG 1 et AG 2), chacun configuré sur son propre cluster WSFC. Le groupe de disponibilité distribué a un total de quatre réplicas, à raison de deux par groupe de disponibilité. Chaque groupe de disponibilité pouvant prendre en charge le nombre maximal de réplicas, un groupe de disponibilité distribué peut avoir jusqu’à 18 réplicas au total.
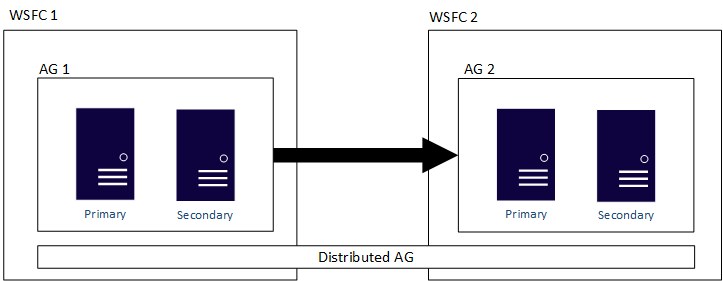
Vous pouvez configurer le déplacement des données dans des groupes de disponibilité distribués sous forme synchrone ou asynchrone. Toutefois, le déplacement des données est légèrement différent au sein des groupes de disponibilité distribués par rapport à un groupe de disponibilité traditionnel. Bien que chaque groupe de disponibilité ait un réplica principal, une seule copie des bases de données participant à un groupe de disponibilité distribué accepte les insertions, les mises à jour et les suppressions. Comme indiqué dans la figure suivante, AG 1 est le groupe de disponibilité principal. Son réplica principal envoie les transactions aux réplicas secondaires d’AG 1 et au réplica principal d’AG2. Le réplica principal d’AG 2 est également appelé un redirecteur. Un redirecteur est un réplica principal dans un groupe de disponibilité secondaire au sein d’un groupe de disponibilité distribué. Le redirecteur reçoit des transactions du réplica principal dans le groupe de disponibilité principal et les transfère aux réplicas secondaires dans son propre groupe de disponibilité. Le redirecteur maintient ensuite à jour les réplicas secondaires d’AG 2.
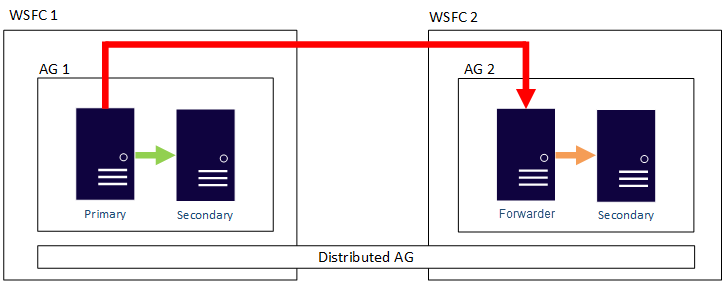
Pour que le réplica principal d’AG 2 accepte les insertions, les mises à jour et les suppressions, vous n’avez d’autre choix que de basculer manuellement le groupe de disponibilité distribué à partir d’AG 1. Dans la figure précédente, étant donné qu’AG 1 contient la copie accessible en écriture de la base de données, émettre un basculement fait d’AG 2 le groupe de disponibilité qui peut gérer les insertions, les mises à jour et les suppressions. Pour plus d’informations sur la façon de basculer un groupe de disponibilité distribué vers un autre, consultez Basculer vers un groupe de disponibilité secondaire.
Notes
Les groupes de disponibilité distribués dans SQL Server 2016 prennent en charge le basculement uniquement depuis un groupe de disponibilité vers un autre à l’aide de l’option FORCE_FAILOVER_ALLOW_DATA_LOSS.
Notes
Quand la réplication transactionnelle est utilisée avec les groupes de disponibilité distribués, le réplica redirecteur ne peut pas être configuré comme serveur de publication.
Version et édition requises
Les groupes de disponibilité distribués dans SQL Server 2017 ou ultérieur peuvent combiner des versions principales de SQL Server dans le même groupe de disponibilité distribué. Le groupe de disponibilité contenant le réplica principal en lecture/écriture peut être d’une version identique ou antérieure aux autres groupes de disponibilité membres du groupe de disponibilité distribué. Les autres groupes de disponibilité peuvent être de la même version ou d’une version ultérieure. Ce scénario s’applique aux opérations de mise à niveau et de migration. Par exemple, si le groupe de disponibilité qui contient le réplica principal en lecture/écriture est SQL Server 2016, mais que vous souhaitez effectuer une mise à niveau ou une migration vers SQL Server 2017 ou une version ultérieure, l’autre groupe de disponibilité membre du groupe de disponibilité distribué peut être configuré avec SQL Server 2017.
Étant donné que la fonctionnalité de groupes de disponibilité distribués n’existe pas dans SQL Server 2012 ou 2014, les groupes de disponibilité qui ont été créés dans ces versions ne peuvent pas participer à des groupes de disponibilité distribués.
Remarque
Selon la version de SQL Server, vous pouvez, lors de la connexion aux services Azure (par exemple, la liaison Managed Instance), configurer un groupe de disponibilité distribué avec l'édition Standard ou une combinaison d'éditions Standard et Enterprise. Pour en savoir plus, référez-vous à KB5016729
Étant donné qu’il existe deux groupes de disponibilité distincts, le processus d’installation d’un Service Pack ou d’une mise à jour cumulative sur un réplica qui fait partie d’un groupe de disponibilité distribué est légèrement différent de celui d’un groupe de disponibilité traditionnel :
Commencez par mettre à jour les réplicas du deuxième groupe de disponibilité dans le groupe de disponibilité distribué.
Appliquez le correctif aux réplicas du groupe de disponibilité principal dans le groupe de disponibilité distribué.
Comme dans le cas d’un groupe de disponibilité standard, basculez le groupe de disponibilité principal vers un de ses propres réplicas (pas vers le réplica principal du deuxième groupe de disponibilité) et appliquez-lui le correctif. Si le seul réplica existant est le réplica principal, un basculement manuel vers le deuxième groupe de disponibilité est nécessaire.
Versions de Windows Server et groupes de disponibilité distribués
Un groupe de disponibilité distribué comprend plusieurs groupes de disponibilité, chacun sur son propre cluster WSFC sous-jacent, et est une construction SQL Server uniquement. Cela signifie que les clusters WSFC qui hébergent les différents groupes de disponibilité peuvent avoir différentes versions majeures de Windows Server. Les versions principales de SQL Server doivent être les mêmes, comme indiqué dans la section précédente. Tout comme l’illustration initiale, la figure suivante montre AG 1 et AG 2 participant à un groupe de disponibilité distribué, mais chacun des clusters WSFC a une version différente de Windows Server.
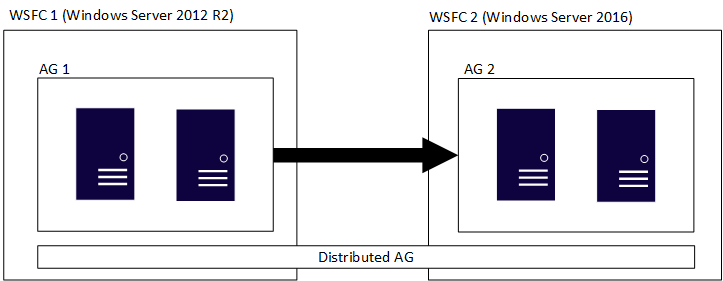
Les clusters WSFC individuels et leurs groupes de disponibilité correspondants suivent les règles habituelles. En d’autres termes, ils peuvent être joints ou non à un domaine (Windows Server 2016 ou version ultérieure). Quand deux groupes de disponibilité différents sont combinés dans un groupe de disponibilité distribué unique, quatre scénarios sont possibles :
- Les deux clusters WSFC sont joints au même domaine.
- Chaque cluster WSFC est joint à un domaine différent.
- Un des clusters WSFC est joint à un domaine et l’autre n’est pas joint à un domaine.
- Aucun des clusters WSFC n’est joint à un domaine.
Quand les deux clusters WSFC sont joints au même domaine (des domaines non approuvés), vous ne devez rien faire de spécial quand vous créez le groupe de disponibilité distribué. Pour les groupes de disponibilité et les clusters WSFC qui ne sont pas joints au même domaine, utilisez des certificats pour que le groupe de disponibilité distribué fonctionne, à l’image de la création d’un groupe de disponibilité pour un groupe de disponibilité indépendant du domaine. Pour savoir comment configurer des certificats pour un groupe de disponibilité distribué, suivez les étapes 3 à 13 de la section Créer un groupe de disponibilité indépendant du domaine.
Dans le cas d’un groupe de disponibilité distribué, le réplica principal de chaque groupe de disponibilité sous-jacent doit disposer des certificats des autres réplicas principaux. Si vous avez déjà des points de terminaison qui n’utilisent pas de certificats, reconfigurez ces points de terminaison à l’aide de l’instruction ALTER ENDPOINT afin de refléter l’utilisation de certificats.
Scénarios d’usage
Voici les trois principaux scénarios d’utilisation d’un groupe de disponibilité distribué :
- Récupération d’urgence et configurations multisites plus faciles
- Migration vers du nouveau matériel ou de nouvelles configurations, ce qui peut impliquer d’utiliser du nouveau matériel ou de changer de systèmes d’exploitation sous-jacents
- Augmentation au-delà de huit du nombre de réplicas lisibles dans un même groupe de disponibilité en englobant plusieurs groupes de disponibilité
Scénarios de récupération d’urgence et de configuration multisite
Un groupe de disponibilité traditionnel nécessite que tous les serveurs fassent partie du même cluster WSFC, ce qui peut compliquer la couverture de plusieurs centres de données. La figure suivante présente l’architecture d’un groupe de disponibilité traditionnel multisite, flux de données compris. Il existe un réplica principal qui envoie les transactions à tous les réplicas secondaires. Cette configuration est moins souple à certains égards qu’un groupe de disponibilité distribué. Par exemple, vous devez implémenter des choses comme Active Directory (si c’est applicable) et le témoin pour un quorum dans le cluster WSFC. Il peut aussi être nécessaire de prendre en compte d’autres aspects d’un cluster WSFC, comme la modification des votes des nœuds.

Les groupes de disponibilité distribués offrent un scénario de déploiement plus flexible pour les groupes de disponibilité qui couvrent plusieurs centres de données. Vous pouvez même vous servir de groupes de disponibilité distribués là où des fonctionnalités telles que la copie des journaux de transaction étaient utilisées par le passé dans des situations de type récupération d'urgence. Toutefois, contrairement à la copie des journaux de transaction, les groupes de disponibilité distribués ne sont pas compatibles avec l’application différée des transactions. Cela signifie que les groupes de disponibilité ou les groupes de disponibilité distribués ne peuvent être d’aucun secours si une erreur humaine entraîne une mise à jour ou une suppression de données incorrecte.
Les groupes de disponibilité distribués sont faiblement couplés, ce qui signifie dans ce cas qu’ils ne nécessitent pas de cluster WSFC et qu’ils sont gérés par SQL Server. Comme les clusters WSFC sont gérés de façon individuelle et que la synchronisation est principalement asynchrone entre les deux groupes de disponibilité, il est plus facile de configurer la reprise d’activité sur un autre site. Les réplicas principaux dans chaque groupe de disponibilité synchronisent leurs propres réplicas secondaires.
- Seul le basculement manuel est pris en charge pour un groupe de disponibilité distribué. Dans une situation de récupération d’urgence où vous permutez les centres de données, vous ne devez pas configurer le basculement automatique (à de rares exceptions près).
- Dans la majorité des cas, vous n’avez pas besoin de définir certains des éléments ou paramètres traditionnels pour les clusters WSFC multisites ou de sous-réseau, comme CrossSubnetThreshold, mais vous devez néanmoins toujours vous préoccuper de la latence réseau à une couche différente pour le transport des données. La différence est que chaque cluster WSFC gère sa propre disponibilité : le cluster n’est pas une grosse entité de quatre nœuds. Vous avez deux clusters WSFC distincts à deux nœuds, comme indiqué dans la figure précédente.
- Nous recommandons le déplacement de données asynchrone, qui convient pour la récupération d’urgence.
- Si vous configurez le déplacement de données synchrone entre le réplica principal et au moins un réplica secondaire du deuxième groupe de disponibilité, et que vous configurez le déplacement synchrone sur le groupe de disponibilité distribué, un groupe de disponibilité distribué attend que toutes les copies synchrones reconnaissent qu’elles disposent des données. Si plusieurs groupes de disponibilité distribués sont connectés en série (AG1 -> AG2 -> AG3) et définis sur Synchrone, un groupe de disponibilité distribué attend que le dernier réplica du dernier groupe de disponibilité soit mis à jour.
Migrate
Étant donné que les groupes de disponibilité distribués prennent en charge deux configurations de groupe de disponibilité complètement différentes, ils facilitent non seulement les scénarios multisites et de récupération d’urgence, mais également les scénarios de migration. Que vous effectuiez une migration vers un nouveau matériel ou des machines virtuelles (localement ou de type IaaS dans le cloud public), configurer un groupe de disponibilité distribué permet d’effectuer une migration là où, dans le passé, vous auriez utilisé une sauvegarde, une copie, une restauration ou une copie des journaux de transaction.
La possibilité de migrer est particulièrement utile dans les scénarios où vous changez ou mettez à niveau le système d’exploitation sous-jacent tout en conservant la même version de SQL Server. Bien que Windows Server 2016 permette une mise à niveau propagée à partir de Windows Server 2012 R2 sur le même matériel, la plupart des utilisateurs choisissent de déployer un nouveau matériel ou des machines virtuelles.
Pour effectuer la migration vers la nouvelle configuration, à la fin du processus, arrêtez tout le trafic de données vers le groupe de disponibilité d’origine et paramétrez le groupe de disponibilité distribué afin qu’il utilise le déplacement de données synchrone. Cette action garantit que le réplica principal du deuxième groupe de disponibilité est entièrement synchronisé, empêchant toute perte de données. Après avoir vérifié la synchronisation, basculez le groupe de disponibilité distribué vers le deuxième groupe de disponibilité. Pour plus d’informations, consultez Basculer vers un groupe de disponibilité secondaire.
Après la migration, une fois que le deuxième groupe de disponibilité fait office de nouveau groupe de disponibilité principal, vous pouvez être amené à effectuer l’une des étapes suivantes :
- Renommez l’écouteur sur le groupe de disponibilité secondaire (et éventuellement supprimez ou renommez l’ancien sur le groupe de disponibilité principal d’origine), ou recréez-le avec l’écouteur du groupe de disponibilité principal d’origine, afin que les applications et les utilisateurs puissent accéder à la nouvelle configuration.
- Si un renommage ou une recréation est impossible, faites pointer les applications et les utilisateurs vers l’écouteur sur le deuxième groupe de disponibilité.
Migrer vers des versions de SQL Server supérieures
Au cours d’un scénario de migration, bien qu’il soit possible de configurer un groupe de disponibilité distribué pour migrer vos bases de données vers un serveur SQL Server cible qui présente une version plus récente que la source, il existe quelques limitations.
Quand vous configurez le groupe de disponibilité distribué avec une cible de migration SQL Server dont la version est supérieure à la source, l’amorçage n’est pas pris en charge, de sorte que le mode d’amorçage doit être défini sur MANUAL. Si vous ne désactivez pas AUTO-SEEDING, votre migration échouera et vous verrez l’erreur 946 « Impossible d’ouvrir la base de données 'DistributionAG' version xxx. Mettez à niveau la base de données vers la dernière version » dans le journal des erreurs. Vous devez définir le mode d’amorçage sur MANUAL et effectuer manuellement une sauvegarde complète et du journal des transactions de la base de données source à partir du groupe de disponibilité principal. Ensuite, restaurez la base de données manuellement, avec le journal des transactions, sur le groupe de disponibilité secondaire. Pour plus d’informations, consultez les étapes sur l’amorçage manuel pour configurer votre groupe de disponibilité distribué, ainsi que les scripts pour sauvegarder et restaurer votre base de données du groupe de disponibilité principal vers le groupe de disponibilité secondaire.
En supposant que le groupe de disponibilité secondaire (AG2) est la cible de migration et qu’il s’agit d’une version supérieure à la version du groupe de disponibilité principale (AG1), tenez compte des limitations suivantes :
- Vous n’aurez pas accès en lecture aux bases de données de réplica sur le groupe de disponibilité secondaire tant que le groupe de disponibilité principal se trouve dans une version antérieure.
- Pendant ce temps, les mises à jour continuent de circuler du groupe de disponibilité principal (AG1) vers le groupe de disponibilité secondaire (AG2), mais l’état du groupe de disponibilité secondaire s’affiche comme Partiellement sain, et les bases de données sur les réplicas secondaires du groupe de disponibilité secondaire (AG2) affichent l’état En synchronisation/En récupération (même si le groupe de disponibilité est dans une validation de synchronisation).
- Une fois le groupe de disponibilité distribué basculé vers la version supérieure (AG2), AG2 doit devenir sain.
- Pendant ce temps, la restauration automatique vers AG1 n’est pas possible, car il s’agit d’une version antérieure.
- Étant donné que le groupe de disponibilité AG1 correspond à une version antérieure, les mises à jour à partir du groupe de disponibilité AG2 après le basculement vers AG2 ne sont pas répliquées sur le groupe de disponibilité AG1.
- À partir de là, choisissez si vous souhaitez désactiver le groupe de disponibilité d’origine (principal), ou si vous souhaitez mettre à niveau le groupe de disponibilité AG1 et conserver le groupe de disponibilité distribué.
- Si vous choisissez de désactiver le groupe de disponibilité AG1, supprimez le groupe de disponibilité principal d’origine du groupe de disponibilité distribué. Le processus est alors terminé.
- Si vous choisissez de conserver le groupe de disponibilité distribué, mettez à niveau la version de SQL Server pour AG1 pour qu’elle corresponde à AG2. Une fois le groupe de disponibilité AG1 mis à niveau, le groupe AG1 et le groupe de disponibilité distribué deviennent sains. Les réplicas reprennent la synchronisation et la restauration automatique devient possible.
Effectuer un scale-out des réplicas lisibles
Un même groupe de disponibilité distribué peut avoir jusqu’à 16 réplicas secondaires, en fonction des besoins. Ainsi, il peut avoir 18 copies à des fins de lecture, y compris les deux réplicas principaux des différents groupes de disponibilité. Cette approche signifie que plusieurs sites peuvent avoir accès pratiquement en temps réel à différentes applications pour des opérations de rapport.
Les groupes de disponibilité distribués peuvent vous aider à augmenter la taille des instances d’une batterie de serveurs en lecture seule, plus qu’avec simplement un seul groupe de disponibilité. Un groupe de disponibilité distribué peut augmenter la taille des instances des réplicas lisibles de deux manières :
- Vous pouvez utiliser le réplica principal du deuxième groupe de disponibilité dans un groupe de disponibilité distribué pour créer un autre groupe de disponibilité distribué, même si la base de données n’est pas dans RECOVERY.
- Vous pouvez également utiliser le réplica principal du premier groupe de disponibilité pour créer un autre groupe de disponibilité distribué.
En d’autres termes, un réplica principal peut participer à des groupes de disponibilité distribués différents. Dans la figure suivante, AG 1 et AG 2 participent au groupe de disponibilité distribué AG 1, tandis qu’AG 2 et AG 3 participent au groupe de disponibilité distribué AG 2. Le réplica principal (ou redirecteur) d’AG 2 est à la fois un réplica secondaire pour le groupe de disponibilité distribué AG 1 et un réplica principal du groupe de disponibilité distribué AG 2.
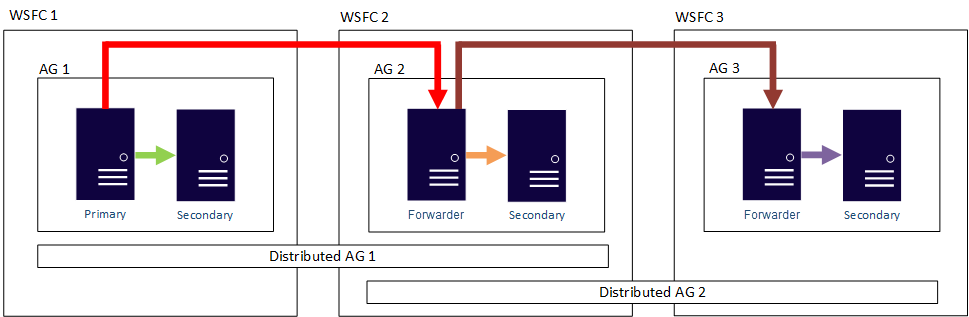
Dans la figure suivante, AG 1 fait office de réplica principal pour deux groupes de disponibilité distribués : le groupe de disponibilité distribué AG 1 (composé d’AG 1 et AG 2) et le groupe de disponibilité distribué AG 2 (composé d’AG 1 et AG 3).
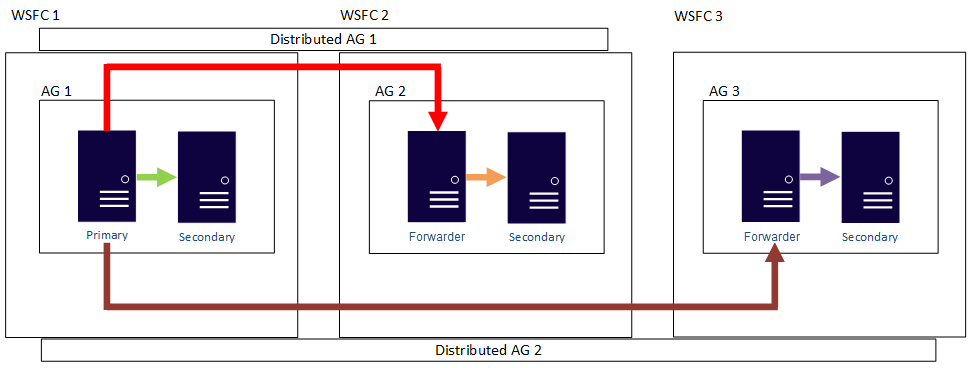
Dans les deux exemples précédents, les trois groupes de disponibilité peuvent comprendre jusqu’à 27 réplicas en tout, qui peuvent tous être utilisés pour des requêtes en lecture seule.
Le routage en lecture seule ne fonctionne pas complètement avec les groupes de disponibilité distribués. Plus précisément :
- Le routage en lecture seule peut être configuré et fonctionne pour le groupe de disponibilité principal du groupe de disponibilité distribué.
- Le routage en lecture seule peut être configuré, mais ne fonctionne pas pour le groupe de disponibilité secondaire du groupe de disponibilité distribué. Toutes les requêtes, si elles utilisent l’écouteur pour se connecter au groupe de disponibilité secondaire, accèdent au réplica principal du groupe de disponibilité secondaire. Sinon, vous devez configurer chaque réplica pour autoriser toutes les connexions en tant que réplica secondaire et y accéder directement. Toutefois, le routage en lecture seule fonctionne si le groupe de disponibilité secondaire devient principal après un basculement. Ce comportement pourrait être modifié dans une mise à jour vers SQL Server 2016 ou dans une future version de SQL Server.
Initialiser des groupes de disponibilité secondaires
Bénéficiant de l’amorçage automatique, les groupes de disponibilité distribués constituent la méthode principale pour initialiser le réplica principal sur le deuxième groupe de disponibilité. Une restauration complète de la base de données sur le réplica principal du deuxième groupe de disponibilité est possible si vous effectuez les opérations suivantes :
- Restaurez la sauvegarde de base de données à l’aide de WITH NORECOVERY.
- Si nécessaire, restaurez les sauvegardes de fichier journal appropriées à l’aide de WITH NORECOVERY.
- Créez le deuxième groupe de disponibilité sans spécifier de nom de base de données et en définissant SEEDING_MODE sur AUTOMATIC.
- Créez le groupe de disponibilité distribué à l’aide de l’amorçage automatique.
Quand vous ajoutez le réplica principal du deuxième groupe de disponibilité au groupe de disponibilité distribué, le réplica est vérifié par rapport aux bases de données primaires du premier groupe de disponibilité, et l’amorçage automatique prend la base de données jusqu’à la source. Il existe quelques inconvénients :
La sortie dans
sys.dm_hadr_automatic_seedingsur le réplica principal du deuxième groupe de disponibilité affiche uncurrent_statede valeur FAILED avec le motif « Seeding Check Message Timeout » (Expiration du message de vérification de l’amorçage).Le journal des erreurs SQL Server actuel sur le réplica principal du deuxième groupe de disponibilité indique que l’amorçage automatique a fonctionné et que les LSN ont été synchronisés.
La sortie dans
sys.dm_hadr_automatic_seedingsur le réplica principal du premier groupe de disponibilité indique que current_state a pour valeur COMPLETED.L’amorçage automatique a également un comportement différent avec des groupes de disponibilité distribués. Pour que l’amorçage automatique commence sur le deuxième réplica, vous devez y émettre la commande
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASE. Bien que cette condition s’applique systématiquement à tout réplica secondaire participant au groupe de disponibilité sous-jacent, le réplica principal du deuxième groupe de disponibilité a déjà les autorisations appropriées pour permettre à l’amorçage automatique de commencer une fois qu’il est ajouté au groupe de disponibilité distribué.
Surveiller l’intégrité
Un groupe de disponibilité distribué est une construction SQL Server uniquement, et il n’est pas visible dans le WSFC sous-jacent. L’exemple de code suivant illustre deux WSFC différents (CLUSTER_A et CLUSTER_B), chacun ayant ses propres groupes de disponibilité. Seuls AG1 dans CLUSTER_A et AG2 dans CLUSTER_B sont présentés ici.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
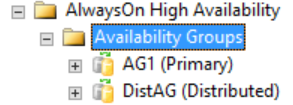
Toutes les informations détaillées sur un groupe de disponibilité distribué sont dans SQL Server, plus spécifiquement dans les vues de gestion dynamique du groupe de disponibilité. Actuellement, la seule information indiquée dans SQL Server Management Studio pour un groupe de disponibilité distribué est sur le réplica principal pour les groupes de disponibilité. Comme l’illustre la figure suivante, sous le dossier Groupes de disponibilité, SQL Server Management Studio indique qu’il existe un groupe de disponibilité distribué. La figure montre AG1 comme réplica principal pour un groupe de disponibilité qui est local à cette instance, et non pour un groupe de disponibilité distribué.
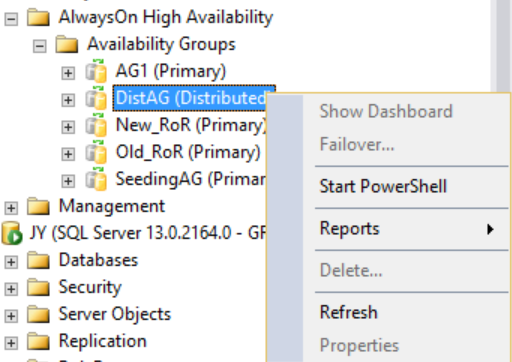
Toutefois, si vous cliquez sur le groupe de disponibilité distribué, aucune option n’est disponible (voir la figure suivante) et les dossiers Bases de données de disponibilité, Écouteurs de groupe de disponibilité et Réplicas de disponibilité développés sont tous vides. SQL Server Management Studio 16 affiche ce résultat, mais cela peut changer dans une version ultérieure de SQL Server Management Studio.
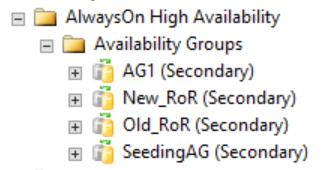
Comme le montre la figure ci-dessous, les réplicas secondaires n’affichent rien dans SQL Server Management Studio concernant le groupe de disponibilité distribué. Les noms de ces groupes de disponibilité correspondent aux rôles montrés dans l’image précédente du cluster WSFC CLUSTER_A.
Vue de gestion dynamique pour répertorier tous les noms de réplica de disponibilité
Les mêmes concepts sont valables quand vous utilisez les vues de gestion dynamique. En exécutant la requête suivante, vous pouvez voir tous les groupes de disponibilité (réguliers et distribués) et les nœuds qui y participent. Ce résultat s’affiche seulement si vous interrogez le réplica principal dans un des clusters WSFC qui participent au groupe de disponibilité distribué. Il existe une nouvelle colonne dans la vue de gestion dynamique sys.availability_groups nommée is_distributed, qui a la valeur 1 quand le groupe de disponibilité est un groupe de disponibilité distribué. Pour afficher cette colonne
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
La figure suivante montre un exemple de sortie du deuxième cluster WSFC qui participe à un groupe de disponibilité distribué. SPAG1 est composé de deux réplicas : DENNIS et JY. Toutefois, le groupe de disponibilité distribué nommé SPDistAG a les noms des deux groupes de disponibilité participants (SPAG1 et SPAG2) plutôt que les noms des instances, comme avec un groupe de disponibilité traditionnel.
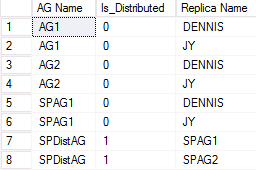
Vue de gestion dynamique pour afficher l’intégrité du groupe de disponibilité distribué
Dans SQL Server Management Studio, tout état indiqué dans le Tableau de bord et d’autres zones concerne uniquement la synchronisation locale dans ce groupe de disponibilité. Pour afficher l’intégrité d’un groupe de disponibilité distribué, interrogez les vues de gestion dynamique. L’exemple de requête suivante étend et affine la requête précédente :
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

Vue de gestion dynamique pour afficher les performances sous-jacentes
Pour étendre la requête précédente, vous pouvez également afficher les performances sous-jacentes par le biais des vues de gestion dynamique en ajoutant sys.dm_hadr_database_replicas_states. Actuellement, la vue de gestion dynamique stocke des informations concernant uniquement le deuxième groupe de disponibilité. L’exemple de requête suivant, exécuté sur le groupe de disponibilité principal, génère l’exemple de sortie ci-dessous :
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

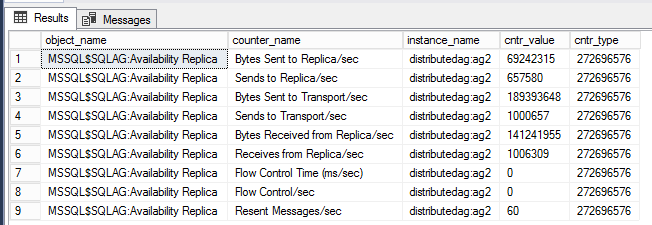
Vue de gestion dynamique pour afficher les compteurs de performances pour le groupe de disponibilité distribué
La requête ci-dessous affiche les compteurs de performances associés au groupe de disponibilité distribué spécifique.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
Notes
Le filtre LIKE doit porter le nom du groupe de disponibilité distribué. Dans cet exemple, le nom du groupe de disponibilité distribué est « distributedag ». Changez le modificateur LIKE afin de refléter le nom de votre groupe de disponibilité distribué.
Vue de gestion dynamique pour afficher l’intégrité du groupe de disponibilité et du groupe de disponibilité distribué
La requête ci-dessous affiche une mine d’informations sur l’intégrité du groupe de disponibilité et du groupe de disponibilité distribué. (Reproduit avec l’autorisation de Tracy Bolinano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

Vues de gestion dynamique pour afficher les métadonnées du groupe de disponibilité distribué
Les requêtes ci-dessous affichent des informations sur les URL de point de terminaison utilisées par les groupes de disponibilité, dont le groupe de disponibilité distribué. (Reproduit avec l’autorisation de David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

Vue de gestion dynamique pour afficher l’état actuel de l’amorçage
La requête ci-dessous affiche des informations sur l’état actuel de l’amorçage. Cela est utile pour le dépannage des erreurs de synchronisation entre les réplicas. (Reproduit avec l’autorisation de David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO

Contenu connexe
Commentaires
Prochainement : Tout au long de l'année 2024, nous supprimerons progressivement les GitHub Issues en tant que mécanisme de retour d'information pour le contenu et nous les remplacerons par un nouveau système de retour d'information. Pour plus d’informations, voir: https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour