Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Une transformation de la source configure votre source de données pour le flux de données. Lorsque vous concevez des flux de données, la première étape consiste toujours à configurer une transformation de source. Pour ajouter une source, sélectionnez Ajouter une source dans le canevas de flux de données.
Chaque flux de données nécessite au moins une transformation de source. Vous pouvez cependant ajouter autant de sources que nécessaire pour effectuer vos transformations de données. Vous pouvez joindre ces sources à l’aide d’une transformation de jointure, de recherche ou d’union.
Chaque transformation de source est associée à un jeu de données ou à un service lié unique. Le jeu de données définit la forme et l’emplacement des données que vous voulez lire ou écrire. Si vous utilisez un jeu de données basé sur des fichiers, vous pouvez utiliser des caractères génériques et des listes de fichiers dans votre source pour utiliser plusieurs fichiers à la fois.
Jeux de données inline
Lorsque vous créez une transformation de source, vous devez d’abord décider si les informations de votre source doivent être définies dans un objet de jeu de données ou dans la transformation de source. La plupart des formats sont uniquement disponibles dans l’un ou l’autre. Pour savoir comment utiliser un connecteur en particulier, référez-vous à la documentation le concernant.
Si un format est pris en charge à la fois inlined et dans les objets de jeu de données, notez que ces deux options présentent des avantages. Les objets de jeu de données sont des entités réutilisables qui peuvent être utilisées dans d’autres flux de données et activités telles que la copie. Ces entités réutilisables sont particulièrement utiles lorsque vous utilisez un schéma renforcé. Les jeux de données ne sont pas basés sur Spark. Il peut arriver que vous deviez remplacer certains paramètres ou la projection de schéma dans la transformation de source.
Les jeux de données inlined sont recommandés lors de l’utilisation de schémas flexibles, d’instances sources uniques ou de sources paramétrables. Si votre source est fortement paramétrée, les jeux de données inlined vous permettront de ne pas créer d’objet « factice ». Les jeux de données inlined sont basés sur Spark et leurs propriétés sont natives au flux de données.
Pour utiliser un jeu de données inlined, sélectionnez le format de votre choix à l’aide du sélecteur Type de source. Au lieu de sélectionner un jeu de données source, sélectionnez le service lié auquel vous souhaitez vous connecter.
Options de schéma
Étant donné qu'un jeu de données en ligne est défini dans le flux de données, il n'y a pas de schéma défini associé au jeu de données en ligne. Sous l’onglet Projection, vous pouvez importer le schéma de données source et le stocker en tant que projection source. Sous cet onglet, vous trouverez un bouton « Options de schéma » qui vous permet de définir le comportement du service de découverte de schéma ADF.
- Utiliser le schéma projeté : cette option est utile lorsque vous avez un grand nombre de fichiers sources qu'ADF analyse comme source. Le comportement par défaut d’ADF consiste à découvrir le schéma de chaque fichier source. Toutefois, si vous avez une projection prédéfinie déjà stockée dans votre transformation source, vous pouvez définir cette option sur « true ». Par conséquent, ADF ignore l'auto-découverte de chaque schéma. Avec cette option activée, la transformation source peut lire tous les fichiers de manière beaucoup plus rapide, en appliquant le schéma prédéfini à chaque fichier.
- Autoriser la dérive des schémas : activez la dérive des schémas pour que votre flux de données autorise les nouvelles colonnes qui ne sont pas déjà définies dans le schéma source.
- Valider le schéma : le paramétrage de cette option entraîne l'échec du flux de données si une colonne ou un type défini dans la projection ne correspond pas au schéma découvert des données sources.
- Inférence des types de colonnes dérivée : lorsque de nouvelles colonnes dérivées sont identifiées par ADF, elles sont converties dans le type de données approprié à l'aide de l'inférence de type automatique ADF.
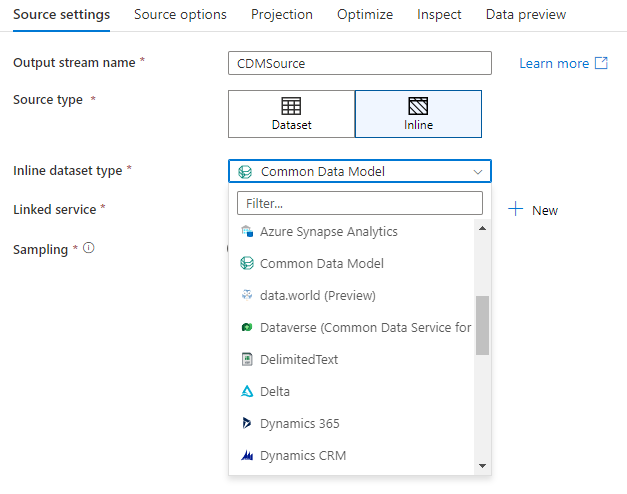
Workspace DB (espaces de travail Synapse uniquement)
Dans les espaces de travail Azure Synapse, une option supplémentaire, Workspace DB, est disponible pour les transformations des sources de flux de données. Cette fonction vous permet de sélectionner directement une base de données de l'espace de travail de tout type disponible en tant que source de données. De plus, vous n'avez pas besoin de services ou de jeu de données liés supplémentaires. Les bases de données créées via les modèles de base de données Azure Synapse sont également accessibles lorsque vous sélectionnez Base de données de l’espace de travail.
Types de sources pris en charge
Le flux de données de mappage suit une approche basée sur l’extraction, le chargement et la transformation (ELT, extract, load, transform) et fonctionne avec des jeux de données intermédiaires qui se trouvent tous dans Azure. Actuellement, les jeux de données suivants peuvent être utilisés dans une transformation de source.
Les paramètres propres à ces connecteurs se trouvent sous l’onglet Options de la source. Vous trouverez des informations et des exemples de scripts de flux de données concernant ces paramètres dans la documentation relative aux connecteurs.
Les pipelines Azure Data Factory et Synapse ont accès à plus de 90 connecteurs natifs. Pour inclure dans votre flux de données des données provenant de ces autres sources, utilisez l’outil Copier l’activité pour charger ces données dans l’une des zones de transit prises en charge.
Paramètres de la source
Une fois que vous avez ajouté une source, configurez-la dans l’onglet Paramètres de la source. Sous cet onglet, vous pouvez sélectionner ou créer le jeu de données vers lequel pointe la source. Vous pouvez également sélectionner des options de schéma et d’échantillonnage pour vos données.
Les valeurs de développement des paramètres de jeux de données peuvent être configurées dans les paramètres de débogage. (Le mode débogage doit être activé.)
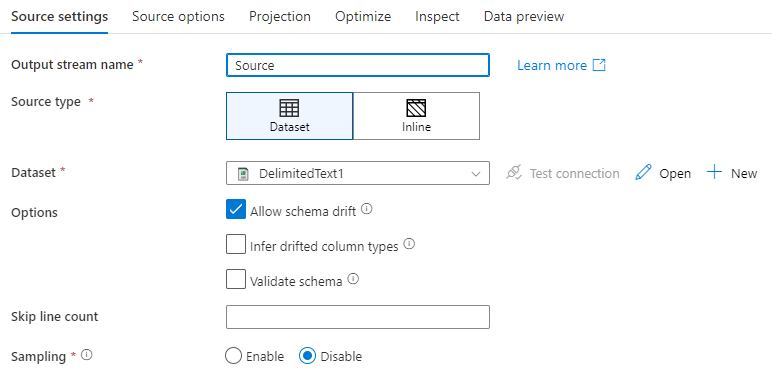
Nom du flux de sortie : nom de la transformation de source.
Type de source : permet de choisir entre un jeu de données inline et un objet DataSet existant.
Tester la connexion : Faites un test pour déterminer si le service Spark du flux de données peut se connecter au service lié utilisé dans votre jeu de données source. Le mode de débogage doit être activé pour que cette fonctionnalité soit activée.
Dérive de schéma : La dérive de schéma est la capacité du service à gérer nativement des schémas flexibles dans vos flux de données sans avoir besoin de définir explicitement des changements de colonnes.
Cochez la case Autoriser la dérive de schéma si les colonnes sources changent souvent. Ce paramètre autorise tous les champs sources entrants à circuler jusqu’au récepteur, par le biais des transformations.
La sélection de l’option Déduire les types de colonnes dérivés ordonne au service de détecter et de définir les types de données pour chaque nouvelle colonne découverte. Si cette fonctionnalité est désactivée, toutes les colonnes dérivées sont de type chaîne de caractères.
Valider le schéma : si l'option Valider le schéma est sélectionnée, le flux de données ne s'exécute pas lorsque les données source entrantes ne correspondent pas au schéma défini du jeu de données.
Nombre de lignes à ignorer : Ce champ spécifie le nombre de lignes à ignorer au début du jeu de données.
Échantillonnage : Activez Échantillonnage pour limiter le nombre de lignes provenant de la source. Utilisez ce paramètre quand vous testez ou échantillonnez des données à partir de votre source à des fins de débogage. Cela est très utile lors de l’exécution de flux de données en mode débogage à partir d’un pipeline.
Pour vérifier que votre source est correctement configurée, activez le mode débogage et récupérez un aperçu des données. Pour en savoir plus, consultez Mode débogage.
Remarque
Lorsque le mode débogage est activé, la configuration de la limite de lignes dans les paramètres de débogage remplace le paramètre d'échantillonnage dans la source lors de la préversion des données.
Options de la source
L’onglet Options de la source contient des paramètres propres au connecteur et au format choisis. Pour plus d’informations et d’exemples, consultez la documentation du connecteur en question. Ce remplacement inclut des détails comme le niveau d'isolation pour les sources de données qui le prennent en charge (comme les serveurs SQL sur site, Azure SQL Database et les instances Azure SQL Managed), ainsi que d'autres paramètres spécifiques à la source de données.
Projection
Comme les schémas des jeux de données, la projection d’une source définit les colonnes, les types et les formats des données sources. Pour la plupart des types de jeu de données, tels que SQL et Parquet, la projection dans une source est corrigée pour refléter le schéma défini dans un jeu de données, qui variera en fonction de la source. Quand vos fichiers sources ne sont pas fortement typés (par exemple, des fichiers .csv plats et non des fichiers Parquet), vous pouvez définir les types de données pour chaque champ de la transformation de source. L’illustration suivante montre un exemple de projection :
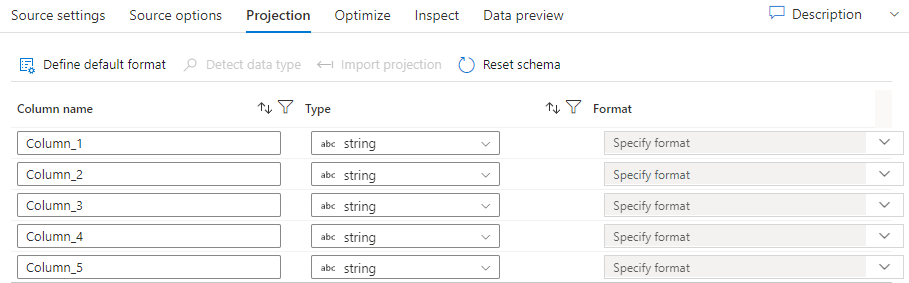
Si votre fichier texte ne comporte aucun schéma défini, sélectionnez Détecter le type de données afin que le service échantillonne et déduise les types de données. Sélectionnez Définir le format par défaut pour détecter automatiquement les formats de données par défaut.
Réinitialiser le schéma réinitialise la projection en fonction de ce qui est défini dans le jeu de données référencé.
Remplacer le schéma vous permet de modifier les types de données projetés, ici la source, en remplaçant les types de données définis par le schéma. Vous pouvez également modifier les types de données des colonnes lors d’une transformation de colonne dérivée en aval. Utilisez une transformation de sélection pour modifier les noms de colonnes.
Importer un schéma
Sélectionnez le bouton Importer un schéma sous l’onglet Projection pour utiliser un cluster de débogage actif dans le but de créer une projection de schéma. Il est disponible dans chaque type de source. L'importation du schéma ici remplace la projection définie dans le jeu de données. L’objet de jeu de données ne sera pas changé.
L’importation de schéma est utile dans les jeux de données tels qu’Avro et Azure Cosmos DB qui prennent en charge des structures de données complexes et qui ne nécessitent pas l’existence de définitions de schéma dans le jeu de données. Pour les jeux de données inlined, l’importation de schéma est la seule façon de référencer des métadonnées de colonne sans dérive de schéma.
Optimiser la transformation de la source
L’onglet Optimiser permet de modifier les informations de partition à chaque étape de transformation. Dans la plupart des cas, l'option Utiliser le partitionnement actuel sera optimisée afin d'obtenir la structure de partitionnement idéale d'une source.
Si vous lisez des données à partir d'une source Azure SQL Database, la partition source personnalisée est probablement celle qui lit les données le plus rapidement. Le service lit les requêtes volumineuses en établissant des connexions avec votre base de données en parallèle. Ce partitionnement source peut être effectué sur une colonne ou à l’aide d’une requête.
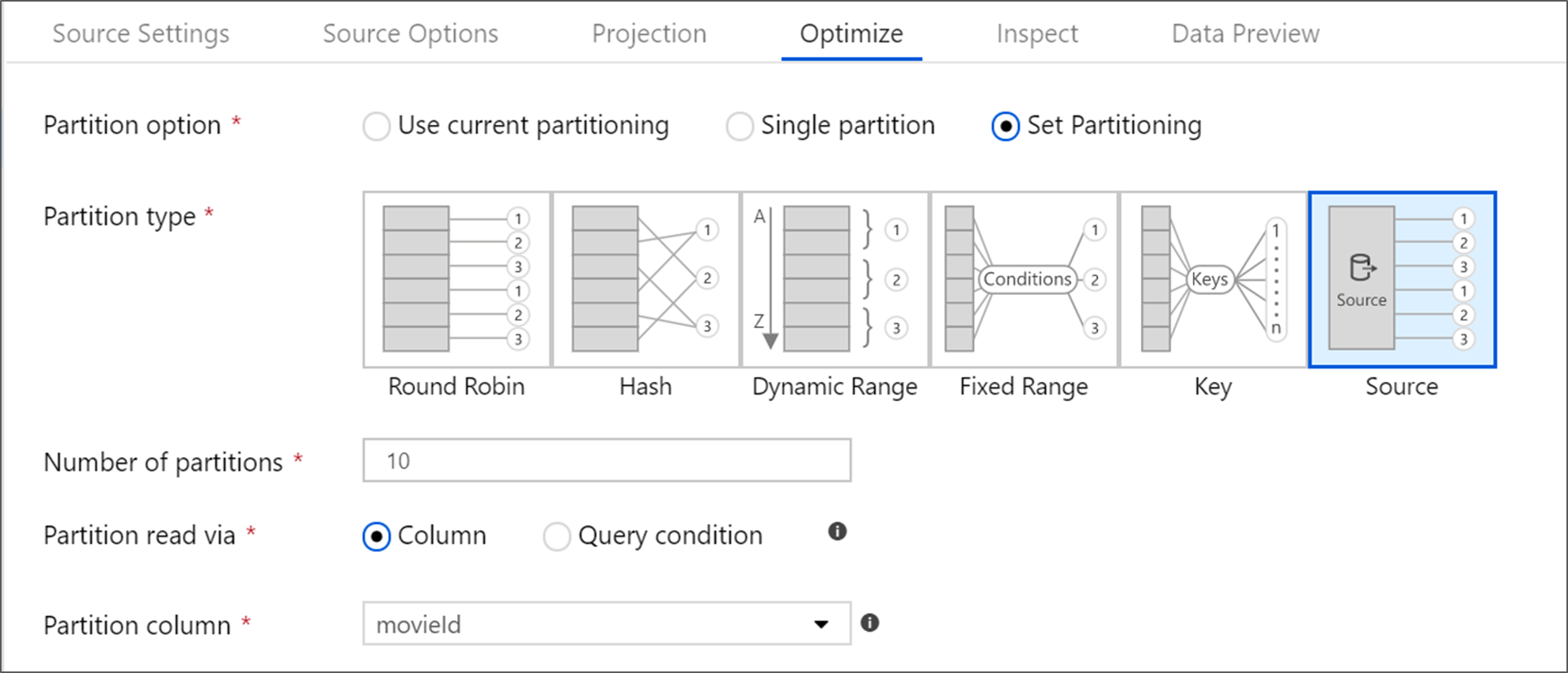
Pour plus d’informations sur l’optimisation dans le mappage de flux de données, consultez la section Onglet Optimiser.
Contenu connexe
Commencez à créer votre flux de données avec une transformation de colonne dérivée, puis une transformation de sélection.