Fonctionnalités et terminologie dans Azure Event Hubs
Azure Event Hubs est un service évolutif de traitement d’événements qui ingère et traite de gros volumes de données et d’événements avec une faible latence et une haute fiabilité. Pour obtenir une présentation générale du service, consultez Qu’est-ce qu’Event Hubs ?.
Cet article s’appuie sur les informations de l’article de présentation et fournit des détails techniques et de mise en œuvre sur les fonctionnalités et composants d’Event Hubs.
Espace de noms
Un espace de noms Event Hubs est un conteneur de gestion pour les Event Hubs (ou rubriques, en jargon Kafka). Il fournit des points de terminaison de réseau intégrés au DNS et une gamme de fonctionnalités de contrôle d’accès et de gestion de l’intégration réseau, telles que le filtrage IP, les points de terminaison de service de réseau virtuel et la liaison privée.

Partitions
Event Hubs organise les séquences d’événements envoyés à un hub d’événements dans une ou plusieurs partitions. Les événements les plus récents sont ajoutés à la fin de cette séquence.

Une partition peut être considérée comme un « journal de validation ». Les partitions contiennent des données d’événement qui comprennent les informations suivantes :
- Corps de l’événement
- Jeu de propriétés défini par l’utilisateur décrivant l’événement
- Métadonnées telles que son décalage dans la partition, son numéro dans la séquence de flux
- Horodatage côté service indiquant quand il a été accepté

Avantages de l’utilisation des partitions
Event Hubs est conçu pour faciliter le traitement de gros volumes d’événements, et le partitionnement aide à cela de deux manières :
- Bien qu’Event Hubs soit un service PaaS, il y a une réalité physique sous-jacente. La gestion d’un journal qui conserve l’ordre des événements exige que ces événements soient conservés ensemble dans le stockage sous-jacent et ses réplicas, ce qui entraîne un plafond de débit pour ce type de journal. Le partitionnement permet d’utiliser plusieurs journaux parallèles pour le même hub d’événements et donc de multiplier la capacité de débit d’entrée/sortie (E/S) brute disponible.
- Vos propres applications doivent être en mesure de traiter le volume d’événements envoyé dans un hub d’événements. Cela peut être complexe et nécessiter une capacité de traitement parallèle importante ayant fait l’objet d’un scale-out. La capacité d’un processus unique à gérer des événements étant limitée, vous avez besoin de plusieurs processus. C’est grâce aux partitions que votre solution alimente ces processus tout en garantissant que chaque événement a un propriétaire de traitement clair.
Nombre de partitions
Le nombre de partitions est spécifié au moment de la création d’un hub d’événements. Il doit être compris entre un et le nombre maximal de partitions autorisé pour chaque niveau tarifaire. Pour connaître la limite du nombre de partitions de chaque niveau, consultez cet article.
Nous vous recommandons de choisir au moins autant de partitions que nécessaire pendant le pic de charge de votre application pour ce hub d’événements particulier. Pour les niveaux autres que les niveaux premium et dédié, vous ne pouvez pas modifier le nombre de partitions d’un event hub après sa création. Pour un hub d’événements dans un niveau premium ou dédié, vous pouvez augmenter le nombre de partitions après sa création, mais vous ne pouvez pas le réduire. La distribution des flux entre les partitions changera à mesure que le mappage des clés de partition aux partitions changera. Vous devez donc tenter d’éviter de telles modifications si l’ordre relatif des événements est important dans votre application.
Il est tentant de définir le nombre de partitions sur la valeur maximale autorisée, mais gardez toujours à l’esprit que vos flux d’événements doivent être structurés de sorte que vous puissiez tirer parti de plusieurs partitions. Si vous avez impérativement besoin de préserver l’ordre parmi tous les événements ou seulement quelques sous-flux, vous ne pourrez peut-être pas tirer parti de nombreuses partitions. En outre, de nombreuses partitions rendent le côté traitement plus complexe.
Les tarifs ne tiennent pas compte du nombre de partitions présentes dans un hub d’événements. Cela dépend du nombre d’unités tarifaires (unités de débit pour le niveau Standard, unités de traitement pour le niveau Premium et unités de capacité pour le niveau dédié) de l’espace de noms ou du cluster dédié. Par exemple, un hub d’événements de niveau standard avec 32 partitions ou une seule occasionne exactement le même coût quand l’espace de noms a une capacité d’une unité de débit. De plus, vous pouvez mettre à l’échelle les unités de débit ou les unités de traitement de votre espace de noms, ou les unités de capacité de votre cluster dédié, indépendamment du nombre de partitions.
Une partition est un mécanisme d’organisation des données qui vous permet de publier et de consommer des données en parallèle. Nous vous recommandons d’équilibrer les unités de mise à l’échelle (unités de débit pour le niveau standard, unités de traitement pour le niveau premium ou unités de capacité pour le niveau dédié) et les partitions afin d’obtenir une mise à l’échelle optimale. En général, nous recommandons un débit maximal de 1 Mo/s par partition. Par conséquent, pour calculer le nombre de partitions, il est conseillé de diviser le débit maximal attendu par 1 Mo/s. Par exemple, si votre cas d’usage nécessite 20 Mo/s, nous vous recommandons de choisir au moins 20 partitions pour obtenir le débit optimal.
Toutefois, si vous disposez d’un modèle dans lequel votre application a une affinité avec une partition particulière, l’augmentation du nombre de partitions n’offre aucun avantage. Pour plus d’informations, consultez Disponibilité et cohérence.
Mappage d’événements à des partitions
Vous pouvez utiliser une clé de partition pour mapper des données d’événement entrant dans des partitions spécifiques dans le cadre de l’organisation des données. La clé de partition est une valeur fournie par l’expéditeur transmise dans un concentrateur d’événements. Elle est traitée par le biais d’une fonction de hachage statique qui crée l’affectation de la partition. Si vous ne spécifiez aucune clé de partition lors de la publication d’un événement, une affectation de type tourniquet (round robin) est utilisée.
L’éditeur d’événements est uniquement informé de sa clé de partition, et non de la partition sur laquelle les événements sont publiés. Grâce à cette dissociation de la clé et de la partition, l’expéditeur n’a pas besoin de connaître trop d’informations sur le traitement en aval. Une identité par appareil ou unique à l'utilisateur constitue une bonne clé de partition, mais d'autres attributs tels que la géographie, peuvent également être utilisés pour regrouper des événements liés dans une seule partition.
Le fait de spécifier une clé de partition permet de conserver les événements associés dans la même partition et dans l’ordre exact de leur arrivée. La clé de partition est une chaîne qui est dérivée de votre contexte d’application et qui identifie les relations entre les événements. Une séquence d’événements identifiée par une clé de partition est un flux. Une partition est un magasin de journaux multiplexé pour de nombreux flux de ce type.
Notes
Bien que vous puissiez envoyer des événements directement à des partitions, ceci n’est pas recommandé, surtout si vous accordez de l’importance à la haute disponibilité. Cela rétrograde la disponibilité d’un hub d’événements au niveau de la partition. Pour plus d’informations, consultez Disponibilité et cohérence.
Éditeurs d'événements
Toute entité qui envoie des données à un Event Hub est un éditeur d’événements (synonyme de producteur d’événements). Les éditeurs d’événements peuvent publier des événements à l’aide du protocole HTTPS, AMQP 1.0 ou Kafka. Les éditeurs d’événements utilisent l’autorisation Microsoft Entra ID avec des jetons JWT émis par OAuth2 ou un jeton de signature d’accès partagé (SAP) spécifique à Event Hub pour obtenir un accès à la publication.
Vous pouvez publier un événement via le protocole AMQP 1.0, Kafka ou HTTPS. Le service Event Hubs fournit l'API REST ainsi que les bibliothèques de clients .NET, Java, Python, JavaScript et Go pour la publication d'événements dans un Event Hub. Pour les autres runtimes et plateformes, vous pouvez utiliser n'importe quel client AMQP 1.0, comme Apache Qpid.
Le choix d'utiliser AMQP ou HTTPS est spécifique au scénario d'utilisation. AMQP requiert l'établissement d'un socket bidirectionnel persistant en plus de la sécurité au niveau du transport (TLS) ou SSL/TLS. Le protocole AMQP présente des coûts de gestion réseau plus élevés lors de l’initialisation de la session, mais le protocole HTTPS nécessite un temps de traitement TLS en plus pour chaque requête. AMQP offre des performances supérieures pour les éditeurs fréquents et peut atteindre des latences beaucoup plus faibles lorsqu’il est utilisé avec du code de publication asynchrone.
Vous pouvez publier les événements individuellement ou par lots. Une publication unique est limitée à 1 Mo, qu’il s’agisse d’un événement unique ou d’un lot. La publication d’événements plus volumineux que ce seuil sera rejetée.
Le débit Event Hubs est mis à l’échelle à l’aide de partitions et d’allocations d’unités de débit. Il est recommandé aux éditeurs de ne pas connaître le modèle de partitionnement spécifique choisi pour un Event Hub et de spécifier uniquement une clé de partition qui est utilisée pour attribuer systématiquement des événements connexes à la même partition.

Azure Event Hubs garantit que tous les événements qui partagent une clé de partition sont stockés ensemble et livrés dans l’ordre d’arrivée. Si des clés de partition sont utilisées avec des stratégies d’éditeur, l’identité de l’éditeur et la valeur de la clé de partition doivent correspondre. Sinon, une erreur se produit.
Rétention des événements
Les événements publiés sont supprimés d’un Event Hub selon une stratégie de rétention configurable basée sur un délai. Voici quelques points importants :
- La valeur par défaut et la période de rétention la plus courte possible est de 1 heure.
- Pour Event Hubs Standard, la période de rétention maximale est de 7 jours.
- Pour Event Hubs Premium et Dedicated, la période de rétention maximale s’élève à 90 jours.
- Si vous modifiez la période de rétention, celle-ci s’applique à tous les événements, dont ceux figurant déjà dans Event Hub.
Event Hubs conserve les événements pendant une durée de conservation configurée qui s’applique à toutes les partitions. Les événements sont automatiquement supprimés lorsque la période de conservation est atteinte. Si vous spécifiez une période de rétention d’une journée (24 heures), l’événement devient indisponible exactement 24 heures après son acceptation. Vous ne pouvez pas supprimer des événements explicitement.
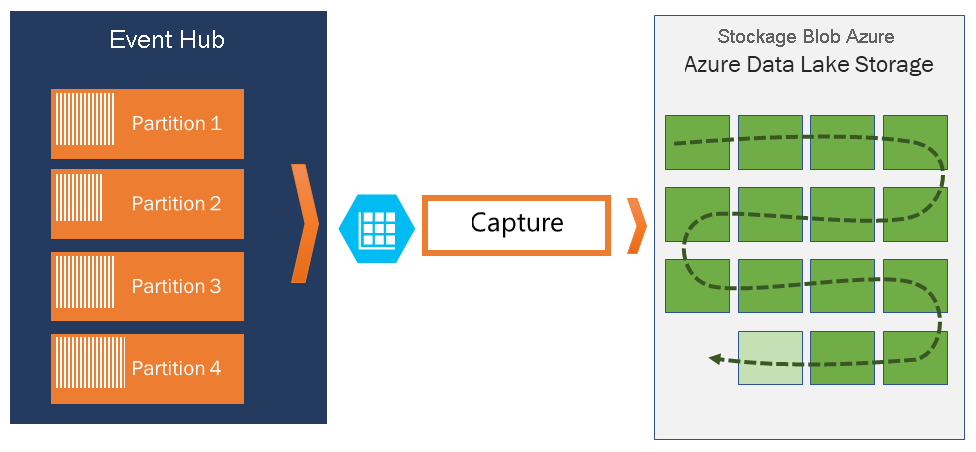
Si vous devez archiver des événements au-delà de la période de conservation autorisée, vous pouvez les stocker automatiquement dans le Stockage Azure ou Azure Data Lake en activant la fonctionnalité de capture d’Event Hubs. Si vous avez besoin de rechercher ou d’analyser de telles archives profondes, vous pouvez facilement les importer dans Azure Synapse ou d’autres magasins et plateformes d’analyse similaires.
La limite de conservation des données en fonction du temps appliquée par Event Hubs a pour but d’éviter que des volumes importants de données historiques client soient interceptés dans un magasin profond qui n’est indexé que par un horodatage et qui n’autorise que l’accès séquentiel. La philosophie architecturale est que les données historiques nécessitent une indexation plus riche et un accès plus direct que l’interface d’événements en temps réel fournie par Event Hubs ou Kafka. Les moteurs de streaming d’événements ne sont pas adaptés pour jouer le rôle de lacs de données ou d’archives à long terme pour l’approvisionnement en événements.
Remarque
Event Hubs est un moteur de flux d’événements en temps réel et n’est pas conçu pour être utilisé à la place d’une base de données et/ou d’un magasin permanent pour les flux d’événements se déroulant de manière illimitée.
Plus l’historique d’un flux d’événements est approfondie, plus vous aurez besoin d’index auxiliaires pour rechercher une tranche d’historique particulière d’un flux donné. L’inspection des charges utiles d’événements et l’indexation ne font pas partie des fonctionnalités d’Event Hubs (ni d’Apache Kafka). Les bases de données et les magasins et moteurs d’analytiques spécialisés tels qu’Azure Data Lake Storage, Azure Data Lake Analytics et Azure Synapse sont donc bien mieux adaptés au stockage d’événements historiques.
Event Hubs Capture s’intègre directement à Stockage Blob Azure et Azure Data Lake Storage et, grâce à cette intégration, permet également le flux des événements directement dans Azure Synapse.
Stratégie de l'éditeur
Event Hubs permet un contrôle granulaire sur les éditeurs d'événements par le biais des stratégies d'éditeur. Les stratégies d’éditeur regroupent des fonctionnalités runtime conçues pour fournir un grand nombre d’éditeurs d’événements indépendants. Avec les stratégies d’éditeur, chaque éditeur utilise son propre identificateur unique lors de la publication d’événements sur un concentrateur d’événements, à l’aide du mécanisme suivant :
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Vous n'êtes pas obligé de créer des noms d'éditeurs à l'avance, mais ils doivent correspondre au jeton SAS utilisé lors de la publication d'un événement, afin de garantir les identités de l'éditeur indépendant. Lorsque vous utilisez des stratégies d’éditeur, la valeur PartitionKey doit être définie sur le nom de l’éditeur. Pour fonctionner correctement, ces valeurs doivent correspondre.
Capture
Event Hubs Capture vous permet de capturer automatiquement les données de streaming dans Event Hubs et de les enregistrer dans le compte Stockage Blob ou le compte Azure Data Lake Storage de votre choix. Vous pouvez activer la fonctionnalité Capture à partir du portail Azure et spécifier une taille minimale, ainsi que la période pour l’exécution de la capture. Avec Event Hubs Capture, vous pouvez spécifier vos propres compte Stockage Blob Azure et conteneur, ou votre propre compte Azure Data Lake Storage, celui qui est utilisé pour stocker les données capturées. Les données capturées sont écrites dans le format Apache Avro.
Les fichiers générés par Event Hubs Capture présentent le schéma Avro suivant :

Remarque
Lorsque vous n’utilisez aucun éditeur de code dans le Portail Azure, vous pouvez capturer des données de streaming dans Event Hubs dans un compte Azure Data Lake Storage Gen2 au format Parquet. Pour plus d’informations, consultez le Guide pratique : Capturer des données à partir d’Event Hubs au format Parquet et le Tutoriel : Capturer des données Event Hubs au format Parquet et les analyser avec Azure Synapse Analytics.
Jetons SAS
Azure Event Hubs utilise des signatures d’accès partagé disponibles au niveau du concentrateur d’événements et de l’espace de noms. Un jeton SAS est généré à partir d'une clé SAS. C'est un hachage SHA d'une URL, codé dans un format spécifique. Event Hubs peut regénérer le hachage en utilisant le nom de la clé (stratégie) et le jeton, et ainsi, authentifier l’expéditeur. Normalement, les jetons SAS pour les éditeurs d’événements sont créés uniquement avec des privilèges d’envoi sur un concentrateur d’événements spécifique. Le mécanisme URL de ce jeton SAS constitue la base de l'identification de l'éditeur introduite dans la stratégie de l'éditeur. Pour plus d’informations sur l’utilisation de SAS, consultez Authentification par signature d’accès partagé avec Service Bus.
Consommateurs d'événements
Toute entité qui lit des données d’événement à partir d’un concentrateur d’événements est un consommateur d’événements. Les consommateurs ou les récepteurs utilisent AMQP ou Apache Kafka pour recevoir des événements depuis un hub d’événements. Event Hubs prend en charge seulement le modèle d’extraction pour que les consommateurs reçoivent des événements de celui-ci. Même quand vous utilisez des gestionnaires d’événements pour gérer les événements provenant d’un hub d’événements, le processeur d’événements utilise en interne le modèle d’extraction pour recevoir des événements du hub d’événements.
Groupes de consommateurs
Le mécanisme de publication/d’abonnement des concentrateurs d’événements est activé à l’aide de groupes de consommateurs. Un groupe de consommateurs est un regroupement logique de consommateurs qui lisent des données à partir d’un hub d’événements ou d’une rubrique Kafka. Il permet à plusieurs applications consommatrices de lire les mêmes données de diffusion en continu dans un hub d’événements indépendamment à leur propre rythme avec leurs décalages. Il vous permet de paralléliser la consommation des messages et de répartir la charge de travail entre plusieurs consommateurs tout en conservant l’ordre des messages au sein de chaque partition.
Nous vous recommandons de n’avoir qu’un seul récepteur actif sur une partition au sein d’un groupe de consommateurs. Toutefois, dans certains scénarios, vous pouvez utiliser jusqu’à cinq consommateurs ou récepteurs par partition où tous les récepteurs obtiennent tous les événements de la partition. Si vous avez plusieurs lecteurs sur la même partition, vous traitez des événements en double. Vous devez gérer cela dans votre code, ce qui n’est pas anodin. Toutefois, il s’agit une approche valide dans certains scénarios.
Dans une architecture de traitement de flux, chaque application en aval équivaut à un groupe de consommateurs. Si vous souhaitez écrire des données d'événement dans le stockage à long terme, alors cette application d'enregistreur de stockage est un groupe de consommateurs. Le traitement des événements complexes est ensuite effectué par un autre groupe de consommateurs distinct. Vous ne pouvez accéder aux partitions que par le biais d'un groupe de consommateurs. Il existe toujours un groupe de consommateurs par défaut dans un hub d’événements. Vous pouvez par ailleurs créer autant de groupes de consommateurs que le permet le niveau tarifaire correspondant.
Certains clients proposés par les kits de développement logiciel (SDK) Azure sont des agents de consommateurs intelligents qui gèrent automatiquement les détails pour garantir que chaque partition possède un lecteur unique à partir duquel toutes les partitions d’un Event Hub sont lues. Cela permet à votre code de se concentrer sur le traitement des événements lus à partir du hub d’événements afin qu’il puisse ignorer la plupart des détails des partitions. Pour plus d’informations, consultez Connexion à une partition.
Les exemples suivants montrent la convention URI de groupe consommateurs :
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
La figure suivante montre l’architecture de traitement de flux Event Hubs :

Décalages du flux
Un décalage correspond à la position d’un événement dans une partition. Vous pouvez considérer un décalage comme un curseur côté client. Le décalage est une numérotation en octets de l'événement. Ce décalage permet à un consommateur d’événements (lecteur) de spécifier un point dans le flux d’événements à partir duquel il veut commencer la lecture des événements. Vous pouvez spécifier le décalage comme un horodatage ou une valeur de décalage. Les consommateurs ont la responsabilité de stocker leurs propres valeurs de décalage en dehors du service des hubs d'événements. Dans une partition, chaque événement inclut un décalage.

Points de contrôle
Les points de contrôle constituent un processus par lequel les lecteurs marquent ou valident leur position dans une séquence d’événements de partition. La réalisation des points de contrôle est la responsabilité du consommateur et se produit sur une base par partition dans un groupe de consommateurs. Cette responsabilité signifie que pour chaque groupe de consommateurs, chaque lecteur de partition doit conserver une trace de sa position actuelle dans le flux d’événements. Il peut informer le service lorsqu’il considère que le flux de données est complet.
Si un lecteur se déconnecte d'une partition, lorsqu'il se reconnecte il commence la lecture au point de contrôle qui a été précédemment soumis par le dernier lecteur de cette partition dans ce groupe de consommateurs. Lorsque le lecteur se connecte, il transmet le décalage à l’Event Hub pour spécifier l’emplacement où commencer la lecture. De cette façon, vous pouvez utiliser les points de contrôle pour marquer les événements comme « terminés » par les applications en aval et pour assurer la résilience si un basculement se produit entre des lecteurs en cours d’exécution sur des ordinateurs différents. Il est possible de revenir à des données plus anciennes en spécifiant un décalage inférieur à partir de ce processus de vérification. Grâce à ce mécanisme, les points de contrôle permettent une résilience au basculement renforcée, mais également la relecture du flux d’événements.
Important
Les décalages sont fournis par le service Event Hubs. Il incombe au consommateur de créer des points de contrôle à mesure que les événements sont traités.
Suivez les recommandations ci-dessous quand vous utilisez Stockage Blob Azure comme magasin de points de contrôle :
- Utilisez un conteneur distinct pour chaque groupe de consommateurs. Vous pouvez utiliser le même compte de stockage, mais utiliser un conteneur par groupe.
- N’utilisez pas le conteneur et le compte de stockage pour quoi que ce soit d’autre.
- Le compte de stockage doit se trouver dans la même région que l’application déployée. Si l’application est locale, essayez de choisir la région la plus proche possible.
Sur la page Compte de stockage du Portail Azure, dans la section Service BLOB, vérifiez que les paramètres suivants sont désactivés.
- Espace de noms hiérarchique
- Suppression réversible de blob
- Contrôle de version
Compactage de journal
Azure Event Hubs prend en charge le compactage du journal des événements pour conserver les derniers événements d’une clé d’événement donnée. Avec des hubs d’événements/une rubrique Kafka compactés, vous pouvez utiliser la conservation basée sur les clés plutôt que la conservation basée sur le temps plus grossière.
Pour plus d’informations sur le compactage des journaux, consultez Compactage des journaux.
Tâches courantes du consommateur
Tous les consommateurs Azure Event Hubs se connectent via une session AMQP 1.0, un canal de communication bidirectionnelle prenant en charge l’état. Chaque partition inclut une session AMQP 1.0, qui facilite le transport des événements séparés par partition.
Se connecter à une partition
Lors de la connexion aux partitions, il est courant d’utiliser un mécanisme de bail pour coordonner les connexions du lecteur à des partitions spécifiques. De cette façon, chaque partition dans un groupe de consommateurs peut n'avoir qu'un seul lecteur actif. Les points de contrôle, la location et la gestion des lecteurs sont simplifiés à l’aide des clients dans les kits de développement logiciel (SDK) Event Hubs, qui jouent le rôle d’agents de consommateurs intelligents. Il s’agit de :
- EventProcessorClient for .NET
- EventProcessorClient for Java
- EventHubConsumerClient for Python
- EventHubConsumerClient for JavaScript/TypeScript
Lire les événements
Après l'ouverture d'une session AMQP 1.0 et d'une liaison pour une partition spécifique, les événements sont livrés par le service de hubs d'événements au client AMQP 1.0. Ce mécanisme de livraison permet un débit plus élevé et une latence plus faible par rapport aux mécanismes basés sur l'extraction, tels que HTTP GET. Alors que les événements sont envoyés au client, chaque instance de données d'événement contient des métadonnées importantes, comme le décalage et le numéro de séquence, qui sont utilisées pour faciliter les points de contrôle sur la séquence d'événements.
Données d’événement :
- Offset
- Numéro de séquence
- body
- Propriétés de l’utilisateur
- Propriétés système
Il vous incombe de gérer le décalage.
Groupes d’applications
Un groupe d’applications est une collection d’applications clientes qui se connectent à un espace de noms Event Hubs partageant une condition d’identification unique telle que le contexte de sécurité : stratégie d’accès partagé ou ID d’application Microsoft Entra.
Azure Event Hubs vous permet de définir des stratégies d’accès aux ressources telles que des stratégies de limitation pour un groupe d’applications donné et contrôle le streaming d’événements (publication ou consommation) entre les applications clientes et Event Hubs.
Pour plus d’informations, consultez Gouvernance des ressources pour les applications clientes avec des groupes d’applications.
Prise en charge d’Apache Kafka
La prise en charge du protocole pour les clients Apache Kafka (versions >=1.0) fournit des points de terminaison qui permettent aux applications Kafka existantes d’utiliser Event Hubs. La plupart des applications Kafka existantes peuvent être reconfigurées pour pointer vers un espace de noms au lieu d’un serveur de démarrage de cluster Kafka.
Du point de vue du coût, de l’effort opérationnel et de la fiabilité, Azure Event Hubs constitue une excellente alternative au déploiement et à l’exploitation de vos propres clusters Kafka et Zookeeper, ainsi qu’aux offres de Kafka en tant que service non natives d’Azure.
En plus d’obtenir les mêmes fonctionnalités de base que celles du répartiteur Apache Kafka, vous pouvez également accéder aux fonctionnalités d’Azure Event Hubs, telles que le traitement par lots et l’archivage automatiques via Event Hubs Capture, la mise à l’échelle et l’équilibrage automatiques, la récupération d’urgence, la prise en charge des zones de disponibilité à coût neutre, l’intégration réseau flexible et sécurisée ainsi que la prise en charge multiprotocole, notamment le protocole AMQP sur WebSockets compatible avec les pare-feu.
Protocoles
Les producteurs ou les expéditeurs peuvent utiliser les protocoles AMQP (Advanced Messaging Queuing Protocol), Kafka ou HTTPS pour envoyer des événements à un hub d’événements.
Les consommateurs ou les récepteurs utilisent AMQP ou Kafka pour recevoir des événements depuis un hub d’événements. Event Hubs prend en charge seulement le modèle d’extraction pour que les consommateurs reçoivent des événements de celui-ci. Même quand vous utilisez des gestionnaires d’événements pour gérer les événements provenant d’un hub d’événements, le processeur d’événements utilise en interne le modèle d’extraction pour recevoir des événements du hub d’événements.
AMQP
Vous pouvez utiliser le protocole AMQP 1.0 pour envoyer des événements à Azure Event Hubs et en recevoir. AMQP fournit une communication fiable, performante et sécurisée pour l’envoi et la réception d’événements. Vous pouvez l’utiliser pour le streaming à hautes performances et en temps réel, et il est pris en charge par la plupart des Kits de développement logiciel (SDK) Azure Event Hubs.
API REST/HTTPS
Vous pouvez envoyer des événements à Event Hubs seulement en utilisant des requêtes HTTP POST. Event Hubs ne prend pas en charge la réception d’événements via HTTPS. Il convient aux clients légers pour lesquels une connexion TCP directe n’est pas réalisable.
Apache Kafka
Azure Event Hubs a un point de terminaison Kafka intégré qui prend en charge les producteurs et les consommateurs Kafka. Les applications créées en utilisant Kafka peuvent utiliser le protocole Kafka (version 1.0 ou ultérieure) pour envoyer et recevoir des événements depuis Event Hubs sans aucune modification du code.
Les Kits de développement logiciel (SDK) Azure rendent abstraits les protocoles de communication sous-jacents, et fournissent un moyen simplifié d’envoyer des événements à Event Hubs et d’en recevoir en utilisant des langages comme C#, Java, Python, JavaScript, etc.
Étapes suivantes
Pour plus d’informations sur les concentrateurs d’événements, accédez aux liens suivants :
- Prise en main des hubs d’événements