Stratégies de partitionnement des données (Création d’applications cloud Real-World avec Azure)
par Rick Anderson, Tom Dykstra
Télécharger corriger le projet ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps with Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer des applications web pour le cloud. Pour plus d’informations sur la série, consultez le premier chapitre.
Plus tôt, nous avons vu à quel point il est facile de mettre à l’échelle la couche web d’une application cloud, en ajoutant et en supprimant des serveurs web. Mais s’ils atteignent tous le même magasin de données, le goulot d’étranglement de votre application passe du front-end au back-end, et la couche données est la plus difficile à mettre à l’échelle. Dans ce chapitre, nous examinons comment rendre votre niveau de données évolutif en partitionnant les données en plusieurs bases de données relationnelles ou en combinant le stockage de base de données relationnelle avec d’autres options de stockage de données.
Il est préférable de configurer un schéma de partitionnement à l’avance pour la même raison que celle mentionnée précédemment : il est très difficile de modifier votre stratégie de stockage de données une fois qu’une application est en production. Si vous réfléchissez bien à différentes approches, vous pouvez éviter d’avoir un « moment Twitter » lorsque votre application se bloque ou tombe en panne pendant une longue période pendant que vous réorganisez les données et le code d’accès aux données de votre application.
Les trois Vs du stockage de données
Pour déterminer si vous avez besoin d’une stratégie de partitionnement et de ce qu’elle doit être, réfléchissez à trois questions sur vos données :
- Volume : quelle quantité de données allez-vous finalement stocker ? Quelques gigaoctets ? Quelques centaines de gigaoctets ? Téraoctets? Pétaoctets?
- Vélocité : à quelle vitesse vos données augmenteront-elles ? S’agit-il d’une application interne qui ne génère pas beaucoup de données ? Une application externe dans laquelle les clients chargeront des images et des vidéos ?
- Variété : quel type de données allez-vous stocker ? Relationnel, images, paires clé-valeur, graphiques sociaux ?
Si vous pensez avoir beaucoup de volume, de vélocité ou de variété, vous devez examiner attentivement le type de schéma de partitionnement qui permettra le mieux à votre application d’être mise à l’échelle efficacement et efficacement à mesure qu’elle grandit, et de vous assurer de ne pas rencontrer de goulots d’étranglement.
Il existe essentiellement trois approches pour le partitionnement :
- Partitionnement vertical
- Partitionnement horizontal
- Partitionnement hybride
Partitionnement vertical
Le fractionnement vertical revient à fractionner une table par colonnes : un ensemble de colonnes passe dans un magasin de données et un autre ensemble de colonnes dans un autre magasin de données.
Par exemple, supposons que mon application stocke des données sur des personnes, y compris des images :
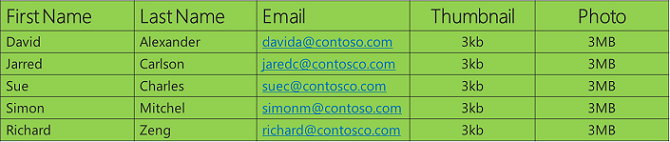
Lorsque vous représentez ces données sous la forme d’une table et examinez les différentes variétés de données, vous pouvez voir que les trois colonnes à gauche ont des données de chaîne qui peuvent être stockées efficacement par une base de données relationnelle, tandis que les deux colonnes situées à droite sont essentiellement des tableaux d’octets provenant de fichiers image. Il est possible de stocker des données de fichier image dans une base de données relationnelle, et de nombreuses personnes le font parce qu’elles ne veulent pas enregistrer les données dans le système de fichiers. Il se peut qu’ils ne disposent pas d’un système de fichiers capable de stocker les volumes de données requis ou qu’ils ne souhaitent pas gérer un système de sauvegarde et de restauration distinct. Cette approche fonctionne bien pour les bases de données locales et pour de petites quantités de données dans les bases de données cloud. Dans l’environnement local, il peut être plus facile de laisser le DBA s’occuper de tout.
Toutefois, dans une base de données cloud, le stockage est relativement coûteux et un volume élevé d’images peut faire en sorte que la taille de la base de données augmente au-delà des limites auxquelles elle peut fonctionner efficacement. Vous pouvez résoudre ces problèmes en partitionnant les données verticalement, ce qui signifie que vous choisissez le magasin de données le plus approprié pour chaque colonne de votre table de données. Ce qui peut fonctionner le mieux pour cet exemple est de placer les données de chaîne dans une base de données relationnelle et les images dans le stockage Blob.
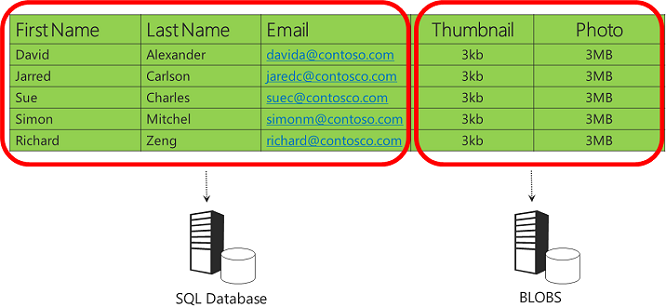
Le stockage d’images dans le stockage Blob au lieu d’une base de données est plus pratique dans le cloud que dans un environnement local, car vous n’avez pas à vous soucier de la configuration des serveurs de fichiers ou de la gestion de la sauvegarde et de la restauration des données stockées en dehors de la base de données relationnelle : tout ce qui est géré automatiquement par le service de stockage Blob.
Il s’agit de l’approche de partitionnement que nous avons implémentée dans l’application Corriger le problème, et nous allons examiner le code pour cela dans le chapitre Stockage Blob. Sans ce schéma de partitionnement, et en supposant une taille d’image moyenne de 3 mégaoctets, l’application Corriger ne serait en mesure de stocker qu’environ 40 000 tâches avant d’atteindre la taille maximale de base de données de 150 gigaoctets. Après avoir supprimé les images, la base de données peut stocker 10 fois plus de tâches ; vous pouvez aller beaucoup plus longtemps avant d’avoir à réfléchir à l’implémentation d’un schéma de partitionnement horizontal. Et à mesure que l’application évolue, vos dépenses augmentent plus lentement, car l’essentiel de vos besoins de stockage passe dans le stockage Blob très bon marché.
Partitionnement horizontal (sharding)
Le fractionnement horizontal revient à fractionner une table par lignes : un ensemble de lignes est placé dans un magasin de données et un autre ensemble de lignes dans un autre magasin de données.
Avec le même jeu de données, une autre option consiste à stocker différentes plages de noms de clients dans différentes bases de données.
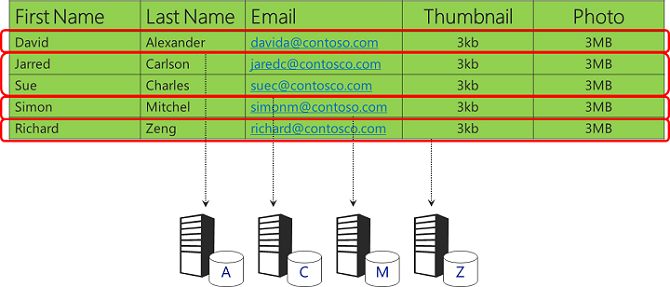
Vous souhaitez faire très attention à votre schéma de partitionnement pour vous assurer que les données sont distribuées uniformément afin d’éviter les points chauds. Cet exemple simple utilisant la première lettre du nom de famille ne répond pas à cette exigence, car de nombreuses personnes ont des noms de famille qui commencent par certaines lettres courantes. Vous avez atteint des limitations de taille de table plus tôt que prévu, car certaines bases de données deviendrait très volumineuses alors que la plupart resteraient petites.
Un côté inférieur du partitionnement horizontal est qu’il peut être difficile d’effectuer des requêtes sur toutes les données. Dans cet exemple, une requête doit extraire jusqu’à 26 bases de données différentes pour obtenir toutes les données stockées par l’application.
Partitionnement hybride
Vous pouvez combiner le partitionnement vertical et horizontal. Par exemple, dans l’exemple de données, vous pouvez stocker les images dans stockage Blob et partitionner horizontalement les données de chaîne.
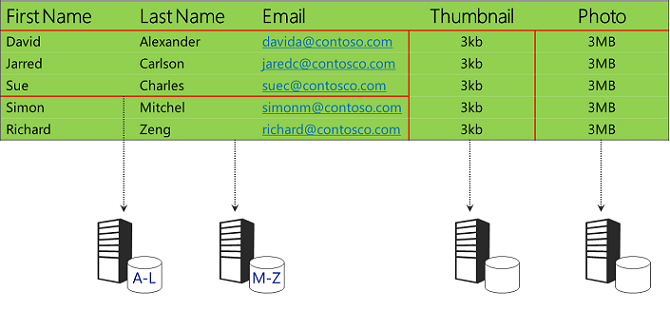
Partitionnement d’une application de production
Conceptuellement, il est facile de voir comment un schéma de partitionnement fonctionnerait, mais n’importe quel schéma de partitionnement augmente la complexité du code et introduit de nombreuses nouvelles complications que vous devez gérer. Si vous déplacez des images vers le stockage d’objets blob, que faites-vous lorsque le service de stockage est en panne ? Comment gérez-vous la sécurité des objets blob ? Que se passe-t-il si la base de données et le stockage d’objets blob sont désynchronisées ? Si vous effectuez un partitionnement, comment gérerez-vous les requêtes sur toutes les bases de données ?
Les complications sont gérables tant que vous les planifiez avant de passer en production. Beaucoup de gens qui n’ont pas fait ce souhait qu’ils avaient plus tard. En moyenne, notre équipe de conseil à la clientèle (CAT) reçoit des appels téléphoniques paniqués environ une fois par mois de clients dont les applications décollent d’une très grande manière, et ils n’ont pas fait cette planification. Et ils disent quelque chose comme: « Aide! Je mets tout dans un magasin de données unique, et dans 45 jours, je vais manquer d’espace dessus! Et si vous avez une grande logique métier intégrée à la façon dont vous accédez à votre magasin de données et que vous avez des clients qui utilisent votre application, il n’y a pas de bon moment pour descendre pendant une journée pendant que vous migrez. Nous finissent par passer par des efforts herculéennes pour aider le client à partitionner ses données à la volée sans temps d’arrêt. C’est très excitant et très effrayant, et pas quelque chose dans lequel vous voulez être impliqué si vous pouvez l’éviter! En réfléchissant à cela à l’avance et en l’intégrant à votre application, vous serez beaucoup plus facile si l’application grandit plus tard.
Résumé
Un schéma de partitionnement efficace peut permettre à votre application cloud de s’adapter à des pétaoctets de données dans le cloud sans goulots d’étranglement. Et vous n’avez pas besoin de payer à l’avance pour des machines massives ou une infrastructure étendue, comme vous le pourriez si vous exécutiez l’application dans un centre de données local. Dans le cloud, vous pouvez ajouter de manière incrémentielle de la capacité selon vos besoins, et vous ne payez que pour autant que vous l’utilisez.
Dans le chapitre suivant , nous allons voir comment l’application Corriger implémente le partitionnement vertical en stockant des images dans le stockage Blob.
Ressources
Pour plus d’informations sur les stratégies de partitionnement, consultez les ressources suivantes.
Documentation :
- Meilleures pratiques pour la conception de Large-Scale Services sur Windows Azure Services cloud. Livre blanc de Mark Simms et Michael Thomassy.
- Modèles et pratiques Microsoft - Modèles de conception cloud. Consultez Instructions sur le partitionnement des données, Modèle de partitionnement.
Vidéos :
- FailSafe : création de Services cloud évolutifs et résilients. Série en neuf parties par Ulrich Homann, Marc Mercuri et Mark Simms. Présente des concepts de haut niveau et des principes architecturaux d’une manière très accessible et intéressante, avec des histoires tirées de l’expérience de l’équipe de conseil à la clientèle Microsoft (CAT) avec des clients réels. Consultez la discussion sur le partitionnement dans l’épisode 7.
- Création d’une grande taille : leçons apprises des clients Windows Azure - Première partie. Mark Simms décrit les schémas de partitionnement, les stratégies de partitionnement, la façon d’implémenter le partitionnement et les fédérations SQL Database, à partir de 19:49. Similaire à la série Failsafe, mais va dans plus de détails.
Exemple de code :
- Principes de base du service cloud dans Windows Azure. Exemple d’application qui inclut une base de données partitionnée. Pour obtenir une description du schéma de partitionnement implémenté, consultez DAL – Partitionnement du SGBDR sur le blog Windows Azure.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour