Événements
31 mars, 23 h - 2 avr., 23 h
L’événement de la communauté Microsoft Fabric, Power BI, SQL et AI ultime. 31 mars au 2 avril 2025.
Inscrivez-vous aujourd’huiCe navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
par Rick Anderson, Tom Dykstra
Télécharger le projet de correction ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps avec Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer avec succès des applications web pour le cloud. Pour plus d’informations sur le livre électronique, consultez le premier chapitre.
La plupart des gens sont habitués aux bases de données relationnelles, et ils ont tendance à négliger d’autres options de stockage de données lorsqu’ils conçoivent une application cloud. Le résultat peut être des performances non optimales, des dépenses élevées ou pire, car les bases de données NoSQL (non relationnelles) peuvent gérer certaines tâches plus efficacement que les bases de données relationnelles. Lorsque les clients nous demandent de l’aide pour résoudre un problème critique de stockage de données, c’est souvent parce qu’ils disposent d’une base de données relationnelle où l’une des options NoSQL aurait mieux fonctionné. Dans ces situations, le client aurait été mieux s’il avait implémenté la solution NoSQL avant de déployer l’application en production.
D’un autre côté, il serait également erroné de supposer qu’une base de données NoSQL peut tout faire bien ou assez bien. Il n’existe pas de meilleur choix de gestion des données pour toutes les tâches de stockage de données ; différentes solutions de gestion des données sont optimisées pour différentes tâches. La plupart des applications cloud du monde réel ont une variété d’exigences de stockage de données et sont souvent mieux servies par une combinaison de plusieurs solutions de stockage de données.
L’objectif de ce chapitre est de vous donner une idée plus large des options de stockage de données disponibles pour une application cloud, ainsi que des conseils de base sur la façon de choisir celles qui correspondent à votre scénario. Il est préférable de connaître les options qui s’offrent à vous et de réfléchir à leurs forces et faiblesses avant de développer une application. Changer les options de stockage de données dans une application de production peut être extrêmement difficile, comme avoir à changer un moteur à réaction pendant que l’avion est en vol.
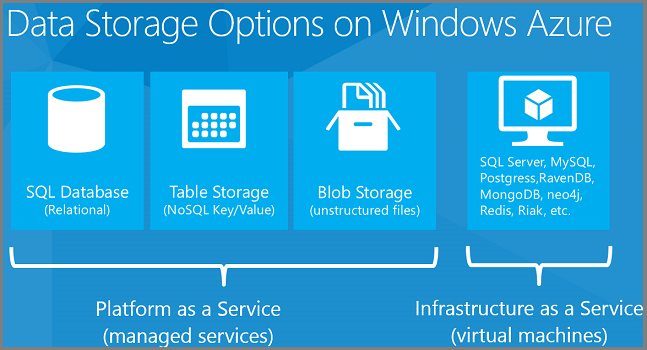
Le cloud facilite relativement l’utilisation d’une variété de magasins de données Relationnelles et NoSQL. Voici quelques-unes des plateformes de stockage de données que vous pouvez utiliser dans Azure.
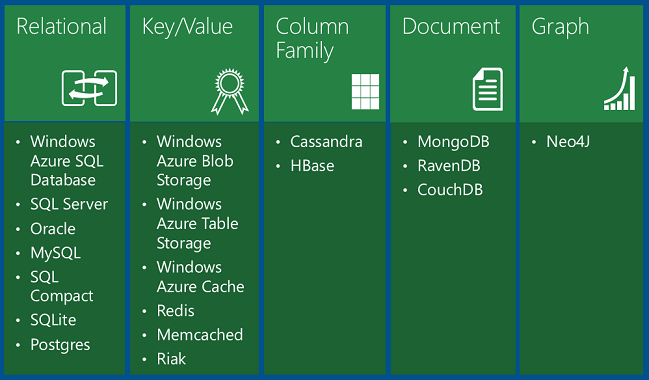
Le tableau présente quatre types de bases de données NoSQL :
Les bases de données de clé/valeur stockent un seul objet sérialisé pour chaque valeur de clé. Elles sont parfaites pour le stockage de grands volumes de données lorsque vous souhaitez obtenir un élément pour une valeur de clé donnée et que vous n’avez pas besoin d’interroger les données en fonction d’autres propriétés de l’élément.
Le Stockage Blob Azure est une base de données clé/valeur qui fonctionne comme le stockage de fichiers dans le cloud, avec des valeurs de clé qui correspondent aux noms de dossiers et de fichiers. Vous récupérez un fichier en fonction de son dossier et de son nom de fichier, et non en recherchant des valeurs dans le contenu du fichier.
Le stockage Table Azure est également une base de données clé/valeur. Chaque valeur est appelée entité (similaire à une ligne, identifiée par une clé de partition et une clé de ligne) et contient plusieurs propriétés (similaires aux colonnes, mais pas toutes les entités d’une table doivent partager les mêmes colonnes). L’interrogation sur des colonnes autres que la clé est extrêmement inefficace et doit être évitée. Par exemple, vous pouvez stocker des données de profil utilisateur, avec une partition stockant des informations sur un seul utilisateur. Vous pouvez stocker des données telles que le nom d’utilisateur, le hachage du mot de passe, la date de naissance, etc., dans des propriétés distinctes d’une entité ou dans des entités distinctes dans la même partition. Toutefois, vous ne souhaitez pas interroger tous les utilisateurs avec une plage donnée de dates de naissance, et vous ne pouvez pas exécuter une requête de jointure entre votre table de profil et une autre table. Le stockage table est plus évolutif et moins coûteux qu’une base de données relationnelle, mais il n’active pas de requêtes ou de jointures complexes.
Les bases de données de document sont des bases de données clé/valeur dans lesquelles les valeurs sont des documents. « Document » ici n’est pas utilisé dans le sens d’un document Word ou Excel, mais signifie une collection de champs et de valeurs nommés, dont l’un peut être un document enfant. Par exemple, dans une table d’historique des commandes, un document de commande peut avoir un numéro de commande, une date de commande et des champs client ; et le champ client peut avoir des champs nom et adresse. La base de données encode les données de champ dans un format tel que XML, YAML, JSON ou BSON ; ou il peut utiliser du texte brut. Une fonctionnalité qui distingue les bases de données de documents des bases de données clé/valeur est la possibilité d’interroger sur des champs non clés et de définir des index secondaires pour rendre l’interrogation plus efficace. Cette fonctionnalité rend une base de données de documents plus adaptée aux applications qui doivent récupérer des données en fonction de critères plus complexes que la valeur de la clé de document. Par exemple, dans une base de données de documents d’historique des commandes client, vous pouvez interroger différents champs tels que l’ID de produit, l’ID client, le nom du client, etc. MongoDB est une base de données de documents populaire.
Les bases de données de famille de colonnes sont des magasins de données clé/valeur qui vous permettent de structurer le stockage de données en collections de colonnes associées appelées familles de colonnes. Par exemple, une base de données de recensement peut avoir un groupe de colonnes pour le nom d’une personne (prénom, milieu, dernier), un groupe pour l’adresse de la personne et un groupe pour les informations de profil de la personne (DOB, sexe, etc.). La base de données peut ensuite stocker chaque famille de colonnes dans une partition distincte tout en conservant toutes les données d’une personne liée à la même clé. Vous pouvez ensuite lire toutes les informations de profil sans avoir à lire toutes les informations de nom et d’adresse. Cassandra est une base de données de famille de colonnes populaire.
Les bases de données de graphe stockent des informations sous la forme d’une collection d’objets et de relations. L’objectif d’une base de données de graphe est de permettre à une application d’effectuer efficacement des requêtes qui parcourent le réseau d’objets et les relations entre eux. Par exemple, les objets peuvent être des employés dans une base de données de ressources humaines, et vous pouvez faciliter les requêtes telles que « Rechercher tous les employés qui travaillent directement ou indirectement pour Scott ». Neo4j est une base de données de graphe populaire.
Par rapport aux bases de données relationnelles, les options NoSQL offrent une scalabilité et une rentabilité bien supérieures pour le stockage et l’analyse des données non structurées. L’inconvénient est qu’ils ne fournissent pas la possibilité de requête riche et les fonctionnalités d’intégrité des données robustes des bases de données relationnelles. NoSQL fonctionne bien pour les données de journal IIS, ce qui implique un volume élevé sans besoin de requêtes de jointure. NoSQL ne fonctionnerait pas si bien pour les transactions bancaires, ce qui nécessite une intégrité absolue des données et implique de nombreuses relations avec d’autres données liées aux comptes.
Il existe également une nouvelle catégorie de plateforme de base de données appelée NewSQL qui combine la scalabilité d’une base de données NoSQL avec la possibilité de requête et l’intégrité transactionnelle d’une base de données relationnelle. Les bases de données NewSQL sont conçues pour le stockage distribué et le traitement des requêtes, ce qui est souvent difficile à implémenter dans les bases de données « OldSQL ». NuoDB est un exemple de base de données NewSQL qui peut être utilisée sur Azure.
Les volumes élevés de données que vous pouvez stocker dans les bases de données NoSQL peuvent être difficiles à analyser efficacement en temps opportun. Pour ce faire, vous pouvez utiliser une infrastructure comme Hadoop qui implémente la fonctionnalité MapReduce . Essentiellement, ce qu’un processus MapReduce fait est le suivant :
Sur Azure, HDInsight vous permet de traiter, d’analyser et d’obtenir de nouvelles informations à partir du Big Data à l’aide de la puissance de Hadoop. Par exemple, vous pouvez l’utiliser pour analyser les journaux du serveur web :
Activez la journalisation du serveur web dans votre compte de stockage. Cela configure Azure pour écrire des journaux dans le service Blob pour chaque requête HTTP adressée à votre application. Le service Blob est essentiellement un stockage de fichiers cloud et s’intègre parfaitement à HDInsight.
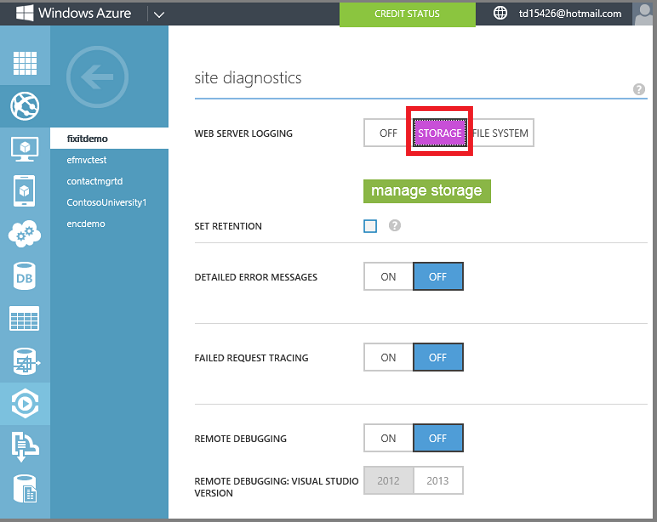
Lorsque l’application obtient du trafic, les journaux IIS du serveur web sont écrits dans le stockage Blob.
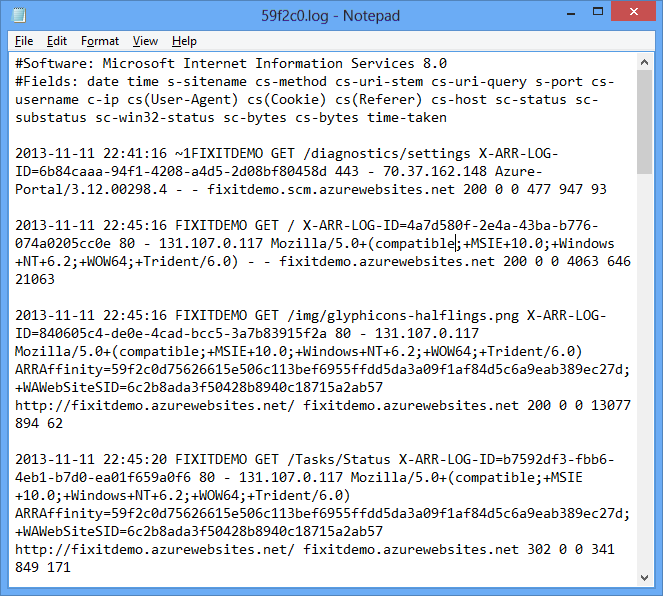
Dans le portail, cliquez surCréation rapidenew - Data Services - HDInsight - et spécifiez un nom de cluster HDInsight, une taille de cluster (nombre de nœuds de données de cluster HDInsight), ainsi qu’un nom d’utilisateur et un mot de passe pour le cluster HDInsight.
Vous pouvez maintenant configurer des travaux MapReduce pour analyser vos journaux et obtenir des réponses à des questions telles que :
Vous pouvez ensuite utiliser les réponses à des questions comme celles-ci pour cibler les publicités en fonction de la probabilité qu’un client soit intéressé ou susceptible d’acheter un produit particulier.
Comme expliqué dans le chapitre Tout automatiser, la plupart des fonctions que vous pouvez effectuer dans le portail peuvent être automatisées, notamment la configuration et l’exécution des travaux d’analyse HDInsight. Un script HDInsight classique peut contenir les étapes suivantes :
En exécutant un script qui effectue tout cela, vous réduisez la durée de provisionnement du cluster HDInsight, ce qui réduit vos coûts.
Les options de stockage de données répertoriées précédemment incluent les solutions PaaS (Platform-as-a-Service) et IaaS (Infrastructure as a Service). PaaS signifie que nous gérons l’infrastructure matérielle et logicielle et que vous utilisez simplement le service. SQL Database est une fonctionnalité PaaS d’Azure. Vous demandez des bases de données et, en arrière-plan, Azure configure et configure les machines virtuelles et configure les bases de données sur celles-ci. Vous n’avez pas d’accès direct aux machines virtuelles et n’avez pas à les gérer. IaaS signifie que vous configurez, configurez et gérez les machines virtuelles qui s’exécutent dans notre infrastructure de centre de données, et que vous y placez ce que vous voulez. Nous fournissons une galerie d’images de machine virtuelle préconfigurées pour les configurations de machine virtuelle courantes. Par exemple, vous pouvez installer des images de machine virtuelle préconfigurées pour Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle Database, etc.
Les solutions de données PaaS proposées par Azure incluent :
Pour IaaS, vous pouvez exécuter tout ce que vous pouvez charger sur une machine virtuelle, par exemple :
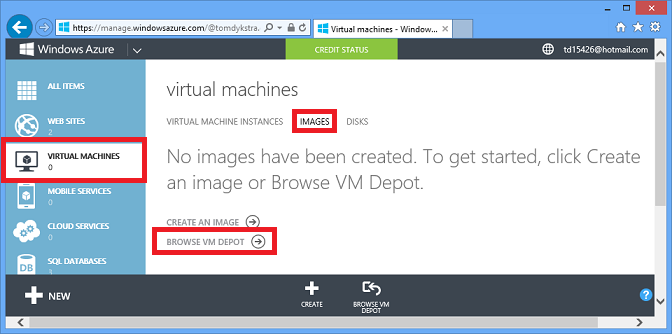
L’option IaaS vous offre des options de stockage de données presque illimitées, et la plupart d’entre elles sont particulièrement faciles à utiliser, car vous pouvez créer des machines virtuelles à l’aide d’images préconfigurées. Par exemple, dans le portail de gestion, accédez à Machines Virtuelles, cliquez sur l’onglet Images, puis sur Parcourir le dépôt de machines virtuelles.
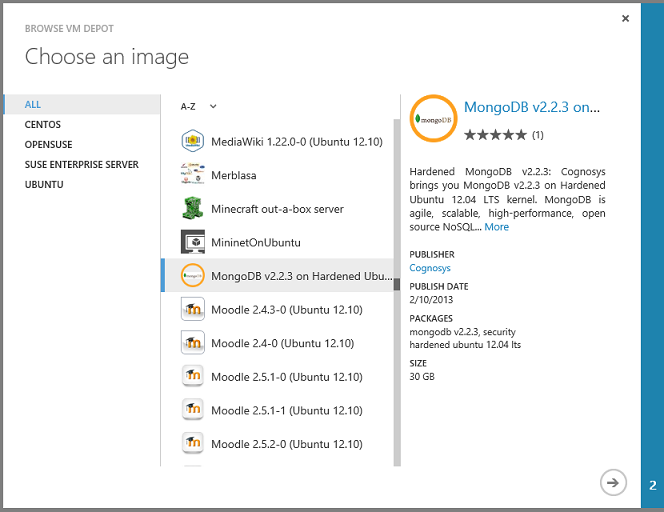
Vous voyez ensuite une liste de centaines d’images de machine virtuelle préconfigurées, et vous pouvez créer une machine virtuelle à partir d’une image avec un système de gestion de base de données préinstallé, comme MongoDB, Neo4J, Redis, Cassandra ou CouchDB :
Azure rend les options de stockage de données IaaS aussi faciles à utiliser que possible, mais les offres PaaS présentent de nombreux avantages qui les rendent plus rentables et pratiques dans de nombreux scénarios :
Les options de stockage de données PaaS dans Azure incluent les offres de fournisseurs tiers.
Aucune approche n’est appropriée pour tous les scénarios. Si quelqu’un dit que cette technologie est la réponse, la première chose à poser est « Quelle est la question ? », car différentes solutions sont optimisées pour différentes choses. Le modèle relationnel présente des avantages indéniables; c’est pour ça que ça existe depuis si longtemps. Mais il existe également des côtés inférieurs à SQL qui peuvent être traités avec une solution NoSQL.
Souvent, ce que nous voyons le mieux est une approche de composition, où vous utilisez SQL et NoSQL dans une solution unique. Même quand les gens disent qu’ils adoptent NoSQL, si vous explorez ce qu’ils font, vous constatez souvent qu’ils utilisent plusieurs frameworks NoSQL différents : ils utilisent CouchDB, redis et Riak pour différentes choses. Même Facebook, qui utilise Largement NoSQL, utilise différentes infrastructures NoSQL pour différentes parties du service. La flexibilité de combiner et de faire correspondre des approches de stockage de données est l’une des choses intéressantes dans le cloud, car il est facile d’utiliser plusieurs solutions de données et de les intégrer dans une seule application.
Voici quelques questions à prendre en compte lorsque vous choisissez une approche :
| Sémantique des données | - Qu’est-ce que la sémantique principale du stockage des données et de l’accès aux données (stockez-vous des données relationnelles ou non structurées) ? Les données non structurées, telles que les fichiers multimédias, s’intègrent mieux dans le stockage d’objets blob ; une collection de données connexes telles que les produits, les inventaires, les fournisseurs, les commandes client, etc., s’intègre le mieux dans une base de données relationnelle. |
|---|---|
| Prise en charge des requêtes | - Est-il facile d’interroger les données ? - Quels types de questions peuvent être posées efficacement ? Les magasins de données clé/valeur sont très bons pour obtenir une seule ligne en fonction d’une valeur de clé, mais pas si bons pour les requêtes complexes. Pour un magasin de données de profil utilisateur où vous obtenez toujours les données d’un utilisateur particulier, un magasin de données clé/valeur peut fonctionner correctement ; pour un catalogue de produits dans lequel vous souhaitez obtenir différents regroupements basés sur différents attributs de produit, une base de données relationnelle peut fonctionner mieux. Les bases de données NoSQL peuvent stocker efficacement de grands volumes de données, mais vous devez structurer la base de données en fonction de la façon dont l’application interroge les données, ce qui rend les requêtes ad hoc plus difficiles à exécuter. Avec une base de données relationnelle, vous pouvez générer presque n’importe quel type de requête. |
| Projection fonctionnelle | - Les questions, les agrégations, etc., peuvent-elles être exécutées côté serveur ? Si j’exécute SELECT COUNT(*) à partir d’une table dans SQL, il effectue très efficacement tout le travail sur le serveur et retourne le nombre que je recherche. Si je veux le même calcul à partir d’un magasin de données NoSQL qui ne prend pas en charge l’agrégation, il s’agit d’une « requête non limitée » inefficace qui expirera probablement. Même si la requête réussit, je dois récupérer toutes les données du serveur vers le client et compter les lignes sur le client. - Quels langages ou types d’expressions peuvent être utilisés ? Avec une base de données relationnelle, je peux utiliser SQL. Avec certaines bases de données NoSQL telles que le stockage Table Azure, j’utiliserai OData, et tout ce que je peux faire est de filtrer sur la clé primaire et d’obtenir des projections (sélectionnez un sous-ensemble des champs disponibles). |
| Facilité de scalabilité | - À quelle fréquence et à quelle quantité les données devront-elles être mises à l’échelle ? - La plateforme implémente-t-elle le scale-out en mode natif ? - Est-il facile d’ajouter/supprimer de la capacité (taille et débit) ? Les bases de données relationnelles et les tables ne sont pas automatiquement partitionnées pour les rendre évolutives, de sorte qu’elles sont difficiles à mettre à l’échelle au-delà de certaines limitations. Les magasins de données NoSQL comme le stockage Table Azure partitionnent tout, et il n’y a presque aucune limite à l’ajout de partitions. Vous pouvez facilement mettre à l’échelle le stockage table jusqu’à 200 téraoctets, mais la taille maximale de la base de données pour Azure SQL base de données est de 500 gigaoctets. Vous pouvez mettre à l’échelle des données relationnelles en les partitionnant dans plusieurs bases de données, mais la configuration d’une application pour prendre en charge ce modèle implique beaucoup de travail de programmation. |
| Instrumentation et facilité de gestion | - Dans quelle mesure la plateforme est-elle facile à instrumenter, surveiller et gérer ? Vous devez rester informé de l’intégrité et des performances de votre magasin de données. Vous devez donc savoir à l’avance quelles métriques une plateforme vous fournit gratuitement et ce que vous devez développer vous-même. |
| Operations | - La plateforme est-elle facile à déployer et à exécuter sur Azure ? Paas? Iaas? Linux? Le stockage table et les SQL Database sont faciles à configurer sur Azure. Les plateformes qui ne sont pas des solutions PaaS Azure intégrées nécessitent plus d’efforts. |
| Prise en charge des API | - Une API est-elle disponible pour faciliter l’utilisation de la plateforme ? Pour le service Table Azure, il existe un KIT de développement logiciel (SDK) avec une API .NET qui prend en charge le modèle de programmation asynchrone .NET 4.5. Si vous écrivez une application .NET, il sera beaucoup plus facile d’écrire et de tester du code pour azure Table Service par rapport à une autre plateforme de magasin de données de colonne clé/valeur qui n’a pas d’API ou une plateforme moins complète. |
| Intégrité transactionnelle et cohérence des données | - Est-il essentiel que la plateforme prend en charge les transactions afin de garantir la cohérence des données ? Pour assurer le suivi des e-mails en bloc envoyés, les performances et le faible coût de stockage des données peuvent être plus importants que la prise en charge automatique des transactions ou l’intégrité référentielle dans la plateforme de données, ce qui fait d’Azure Table Service un bon choix. Pour le suivi des soldes des comptes bancaires ou des bons de commande, une plateforme de base de données relationnelle qui fournit des garanties transactionnelles fortes serait un meilleur choix. |
| Continuité de l’activité | - La sauvegarde, la restauration et la récupération d’urgence sont-elles faciles ? Tôt ou tard, les données de production seront endommagées et vous aurez besoin d’une fonction d’annulation. Les bases de données relationnelles ont souvent des fonctionnalités de restauration plus précises, telles que la possibilité de restaurer à un point dans le temps. Comprendre les fonctionnalités de restauration disponibles dans chaque plateforme que vous envisagez est un facteur important à prendre en compte. |
| Coût | - Si plusieurs plateformes peuvent prendre en charge votre charge de travail de données, comment se comparent-elles en coût ? Par exemple, si vous utilisez ASP.NET Identity, vous pouvez stocker des données de profil utilisateur dans Azure Table Service ou Azure SQL Database. Si vous n’avez pas besoin des fonctionnalités d’interrogation complètes de SQL Database, vous pouvez choisir des tables Azure en partie, car cela coûte beaucoup moins cher pour une quantité donnée de stockage. |
En règle générale, nous vous recommandons de connaître la réponse aux questions de chacune de ces catégories avant de choisir vos solutions de stockage de données.
En outre, votre charge de travail peut avoir des exigences spécifiques que certaines plateformes peuvent mieux prendre en charge que d’autres. Par exemple :
L’application Corriger utilise une base de données relationnelle pour stocker les tâches. La création d’environnement Windows PowerShell script indiqué dans le chapitre Automatiser tout crée deux instances SQL Database. Vous pouvez les voir dans le portail en cliquant sur l’onglet Bases de données SQL .
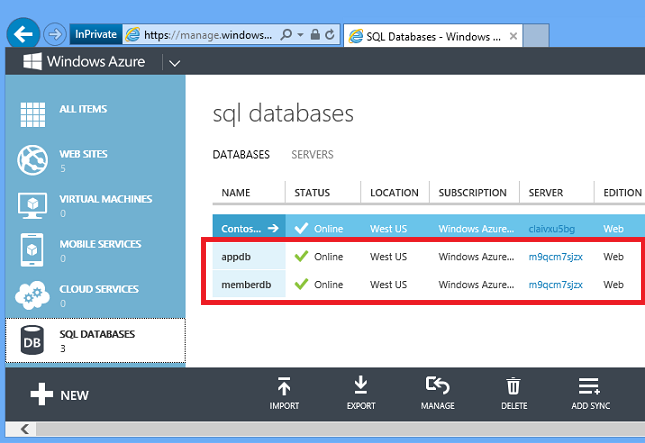
Il est également facile de créer des bases de données à l’aide du portail.
Cliquez sur Nouveau -- Services de données -- SQL Database -- Créer, entrez un nom de base de données, choisissez un serveur que vous avez déjà dans votre compte ou créez-en un, puis cliquez sur Créer SQL Database.
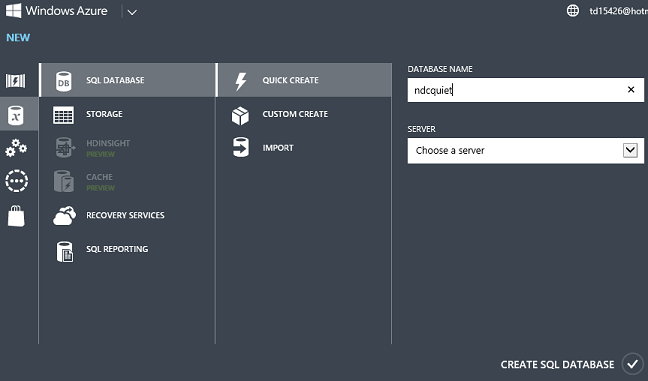
Attendez plusieurs secondes et vous disposez d’une base de données dans Azure prête à être utilisée.
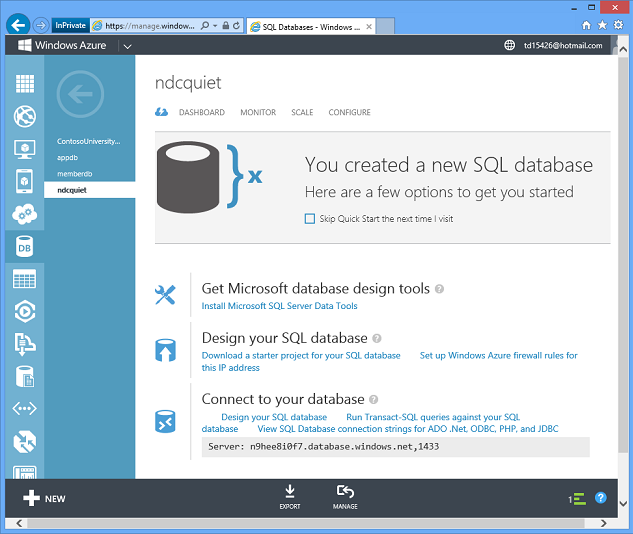
Azure fait donc en quelques secondes ce qu’il peut vous prendre un jour, une semaine ou plus pour accomplir dans l’environnement local. Et comme vous pouvez créer des bases de données automatiquement automatiquement dans un script ou à l’aide d’une API de gestion, vous pouvez effectuer un scale-out dynamiquement en répartissant vos données entre plusieurs bases de données, tant que votre application a été programmée pour cela.
Il s’agit d’un exemple de notre modèle Platform-as-a-Service. Vous n’avez pas besoin de gérer les serveurs, nous le faisons. Vous n’avez pas à vous soucier des sauvegardes, nous le faisons. Il s’exécute en haute disponibilité : les données de la base de données sont répliquées automatiquement sur trois serveurs. Si une machine meurt, nous basculons automatiquement et vous ne perdez aucune donnée. Le serveur est régulièrement corrigé. Vous n’avez pas besoin de vous en soucier.
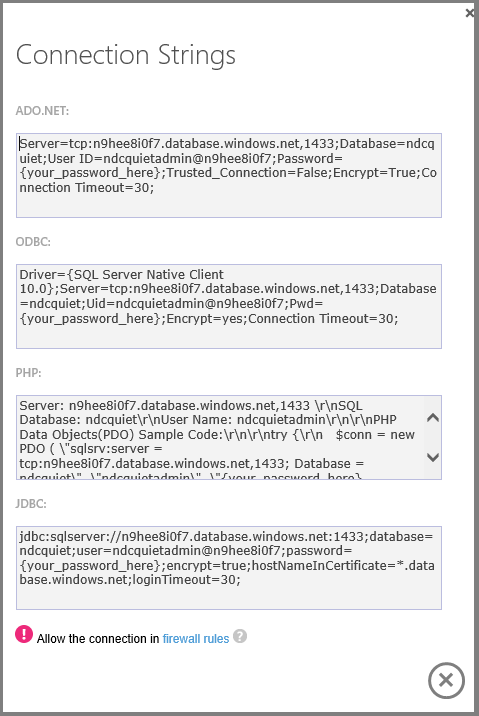
Cliquez sur un bouton pour obtenir la chaîne de connexion exacte dont vous avez besoin et pouvez immédiatement commencer à utiliser la nouvelle base de données.
Le tableau de bord affiche l’historique des connexions et la quantité de stockage utilisé.
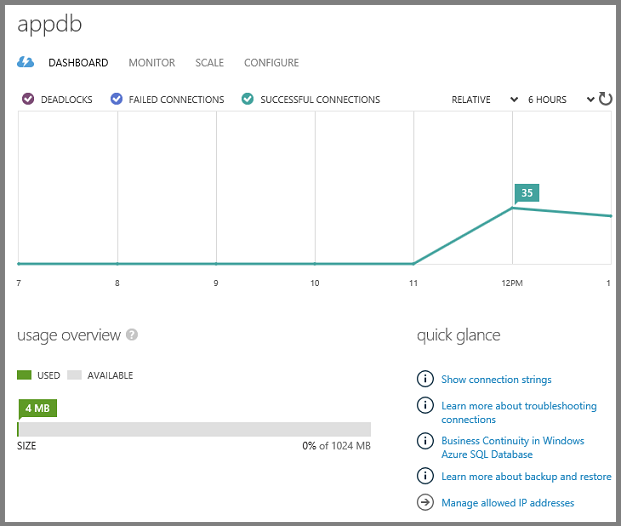
Vous pouvez gérer des bases de données dans le portail ou à l’aide de SQL Server outils que vous connaissez déjà, notamment SQL Server Management Studio (SSMS) et visual Studio Tools SQL Server Explorateur d'objets (SSOX) et server Explorer.
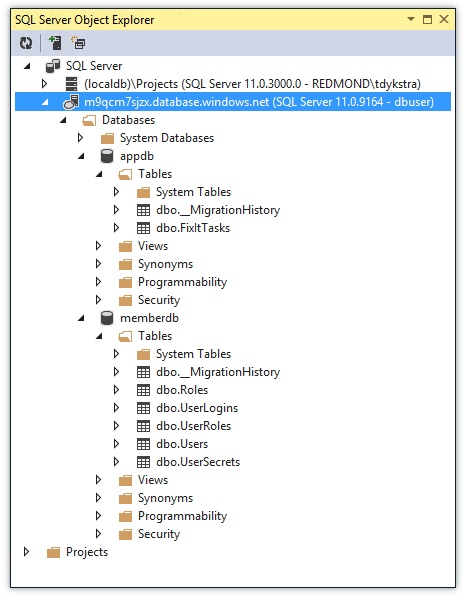
Une autre chose intéressante est le modèle tarifaire. Vous pouvez commencer le développement avec une base de données gratuite de 20 Mo, et une base de données de production commence à environ 5 $ par mois. Vous payez uniquement la quantité de données que vous stockez réellement dans la base de données, et non la capacité maximale. Vous n’avez pas besoin d’acheter une licence.
SQL Database est facile à mettre à l’échelle. Pour l’application Corriger le problème, la base de données que nous créons dans notre script d’automatisation est limitée à 1 gig. Si vous souhaitez le mettre à l’échelle jusqu’à 150 gig, vous pouvez simplement accéder au portail et modifier ce paramètre, ou exécuter une commande d’API REST. En quelques secondes, vous disposez d’une base de données de 150 gig dans laquelle vous pouvez déployer des données.
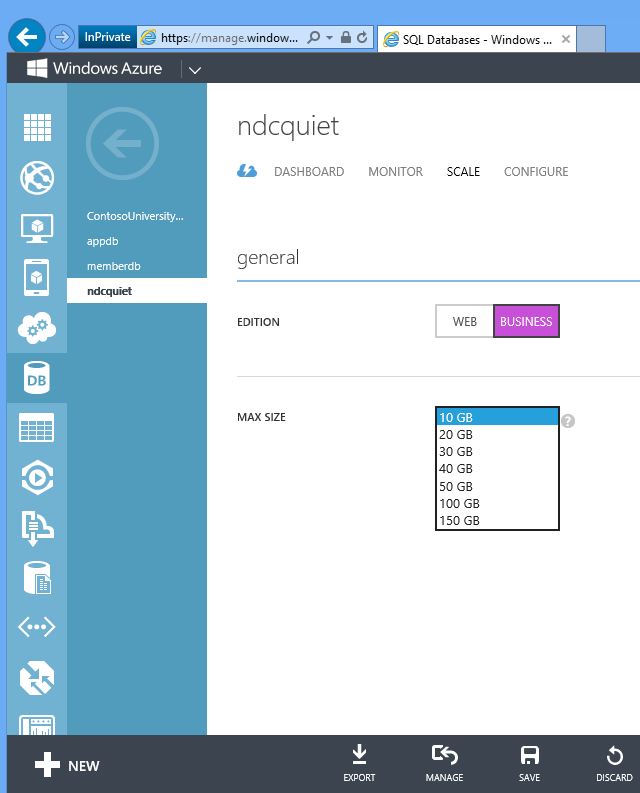
C’est la puissance du cloud pour mettre en place l’infrastructure rapidement et facilement et commencer à l’utiliser immédiatement.
L’application Corriger utilise deux bases de données SQL, une pour l’appartenance (authentification et autorisation) et une pour les données, et c’est tout ce que vous avez à faire pour les provisionner et les mettre à l’échelle. Vous avez vu précédemment comment approvisionner les bases de données via des scripts Windows PowerShell, et maintenant vous avez également vu à quel point il est facile de le faire dans le portail.
L’application Corriger accède à ces bases de données à l’aide d’Entity Framework, l’ORM (mappeur relationnel objet) recommandé par Microsoft pour les applications .NET. Un ORM est un excellent outil qui facilite la productivité des développeurs, mais la productivité se fait au détriment des performances dégradées dans certains scénarios. Dans une application cloud réelle, vous ne ferez pas le choix entre l’utilisation d’EF ou l’utilisation directe de ADO.NET. Vous utiliserez les deux. La plupart du temps, lorsque vous écrivez du code qui fonctionne avec la base de données, l’obtention de performances maximales n’est pas critique et vous pouvez tirer parti du codage et des tests simplifiés que vous obtenez avec Entity Framework. Dans les situations où la surcharge EF entraînerait des performances inacceptables, vous pouvez écrire et exécuter vos propres requêtes à l’aide de ADO.NET, idéalement en appelant des procédures stockées.
Quelle que soit la méthode que vous utilisez pour accéder à la base de données, vous souhaitez réduire autant que possible le « chattiness ». En d’autres termes, si vous pouvez obtenir toutes les données dont vous avez besoin dans un jeu de résultats de requête plus volumineux plutôt que des dizaines ou des centaines de plus petits, c’est généralement préférable. Par exemple, si vous devez répertorier les étudiants et les cours auxquels ils sont inscrits, il est généralement préférable d’obtenir toutes les données dans une requête de jointure plutôt que d’obtenir les étudiants dans une requête et d’exécuter des requêtes distinctes pour les cours de chaque étudiant.
Dans l’application Corriger, la FixItContext classe, qui dérive de la classe Entity Framework DbContext , identifie la base de données et spécifie les tables de la base de données. Le contexte spécifie un ensemble d’entités (table) pour les tâches, et le code transmet au contexte le nom de la chaîne de connexion. Ce nom fait référence à une chaîne de connexion définie dans le fichier Web.config.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
La chaîne de connexion dans le fichier Web.config est nommée appdb (pointant ici vers la base de données de développement locale) :
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
Entity Framework crée une table FixItTasks en fonction des propriétés incluses dans la classe d’entité FixItTask . Il s’agit d’une simple classe POCO (Plain Old CLR Object), ce qui signifie qu’elle n’hérite pas de ou n’a aucune dépendance avec Entity Framework. Mais Entity Framework sait comment créer une table basée sur celle-ci et exécuter des opérations CRUD (create-read-update-delete) avec elle.
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}
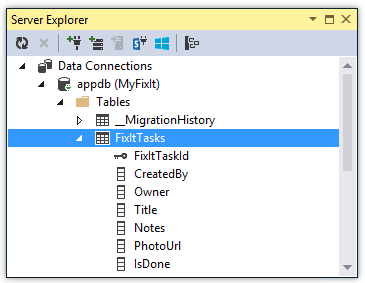
L’application Fix It inclut une interface de dépôt qu’elle utilise pour les opérations CRUD qui fonctionnent avec le magasin de données.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
Notez que les méthodes de dépôt sont toutes asynchrones, de sorte que tous les accès aux données peuvent être effectués de manière complètement asynchrone.
L’implémentation du référentiel appelle des méthodes asynchrones Entity Framework pour travailler avec les données, y compris les requêtes LINQ, ainsi que pour les opérations d’insertion, de mise à jour et de suppression. Voici un exemple de code pour la recherche d’une tâche de correction.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Vous remarquerez qu’il y a également du code de journalisation des erreurs et de minutage. Nous allons le voir plus loin dans le chapitre Surveillance et télémétrie.
Une bonne chose à propos de SQL Server et Azure SQL Base de données est que le modèle de programmation de base de données pour les deux est identique. Vous pouvez utiliser la plupart des mêmes compétences dans les deux environnements. Vous pouvez même utiliser une base de données SQL Server dans le développement et une SQL Database instance dans le cloud, c’est ainsi que l’application Fix It est configurée.
Vous pouvez également exécuter le même SQL Server dans le cloud que vous exécutez localement en l’installant sur des machines virtuelles IaaS. Pour certaines applications héritées, l’exécution de SQL Server dans une machine virtuelle peut être une meilleure solution. Étant donné qu’une base de données SQL Server s’exécute sur une machine virtuelle dédiée, elle dispose de plus de ressources qu’une base de données SQL Database qui s’exécute sur un serveur partagé. Cela signifie qu’une base de données SQL Server peut être plus volumineuse et toujours bien fonctionner. En général, plus la taille de la base de données et de la table est petite, meilleur est le cas d’usage pour SQL Database (PaaS).
Voici quelques instructions sur la façon de choisir entre les deux modèles.
| Azure SQL Database (PaaS) | SQL Server dans une machine virtuelle (IaaS) |
|---|---|
| Avantages : vous n’avez pas besoin de créer ou de gérer des machines virtuelles, de mettre à jour ou de corriger le système d’exploitation ou SQL ; Azure le fait pour vous. - Haute disponibilité intégrée, avec un contrat SLA au niveau de la base de données. - Faible coût total de possession (TCO), car vous payez uniquement pour ce que vous utilisez (aucune licence requise). - Convient pour gérer un grand nombre de bases de données plus petites (<=500 Go chacune). - Facile à créer dynamiquement de nouvelles bases de données pour activer le scale-out. | Pros : compatible avec les fonctionnalités des SQL Server locales. - Peut implémenter SQL Server haute disponibilité via AlwaysOn dans plus de 2 machines virtuelles, avec un contrat SLA au niveau de la machine virtuelle. - Vous avez un contrôle total sur la façon dont SQL est géré. - Peut réutiliser des licences SQL que vous possédez déjà, ou payer à l’heure pour une. - Convient pour la gestion de bases de données moins nombreuses, mais plus volumineuses (1 To+). |
| Inconvénients - Certaines lacunes de fonctionnalités par rapport aux SQL Server locales (absence d’intégration CLR, TDE, prise en charge de la compression, SQL Server Reporting Services, etc.) - Limite de taille de la base de données de 500 Go. | Inconvénients : Mises à jour/correctifs (système d’exploitation et SQL) sont de votre responsabilité - La création et la gestion des bases de données sont de votre responsabilité - Les IOPS de disque (opérations d’entrée/sortie par seconde) sont limitées à environ 8 000 (via 16 lecteurs de données). |
Si vous souhaitez utiliser SQL Server dans une machine virtuelle, vous pouvez utiliser votre propre licence SQL Server ou payer une par heure. Par exemple, dans le portail ou via l’API REST, vous pouvez créer une machine virtuelle à l’aide d’une image SQL Server.
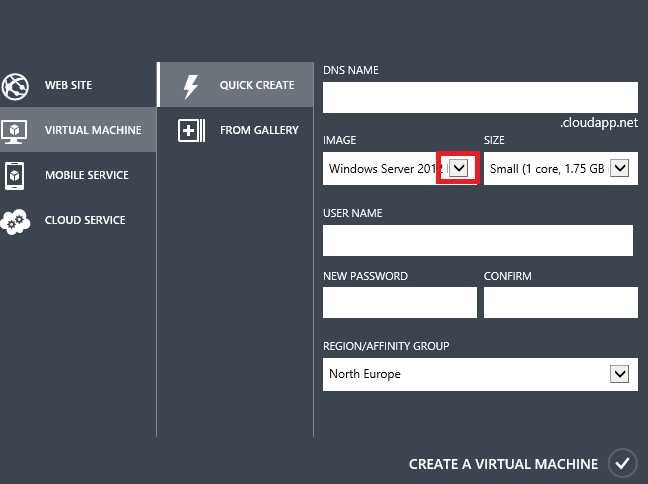
Lorsque vous créez une machine virtuelle avec une image SQL Server, nous notons le coût de la licence SQL Server par heure en fonction de votre utilisation de la machine virtuelle. Si vous avez un projet qui ne va s’exécuter que pendant quelques mois, il est moins cher de payer à l’heure. Si vous pensez que votre projet va durer des années, il est moins cher d’acheter la licence comme vous le faites normalement.
Le cloud computing permet de combiner et de mettre en correspondance des approches de stockage de données pour répondre au mieux aux besoins de votre application. Si vous créez une nouvelle application, réfléchissez attentivement aux questions répertoriées ici afin de choisir des approches qui continueront de fonctionner correctement lorsque votre application se développera. Le chapitre suivant explique certaines stratégies de partitionnement que vous pouvez utiliser pour combiner plusieurs approches de stockage de données.
Pour plus d'informations, consultez les ressources ci-dessous.
Choix d’une plateforme de base de données :
Choix entre SQL Server et SQL Database :
Utilisation d’Entity Framework et de SQL Database dans une application web ASP.NET
Utilisation de MongoDB sur Azure :
HDInsight (Hadoop sur Azure) :
Événements
31 mars, 23 h - 2 avr., 23 h
L’événement de la communauté Microsoft Fabric, Power BI, SQL et AI ultime. 31 mars au 2 avril 2025.
Inscrivez-vous aujourd’hui