Mise en cache distribuée (création d’applications Real-World cloud avec Azure)
par Rick Anderson, Tom Dykstra
Télécharger le projet de correction ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps avec Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer avec succès des applications web pour le cloud. Pour plus d’informations sur le livre électronique, consultez le premier chapitre.
Le chapitre précédent a examiné la gestion des erreurs temporaires et mentionné la mise en cache comme stratégie de disjoncteur. Ce chapitre fournit plus d’informations sur la mise en cache, notamment sur le moment où l’utiliser, les modèles courants pour l’utiliser et la façon de l’implémenter dans Azure.
Qu’est-ce que la mise en cache distribuée ?
Un cache fournit un accès à débit élevé et à faible latence aux données d’application couramment utilisées, en stockant les données en mémoire. Pour une application cloud, le type de cache le plus utile est le cache distribué, ce qui signifie que les données ne sont pas stockées sur la mémoire du serveur web individuel, mais sur d’autres ressources cloud, et que les données mises en cache sont mises à la disposition de tous les serveurs web d’une application (ou d’autres machines virtuelles cloud utilisées par l’application).
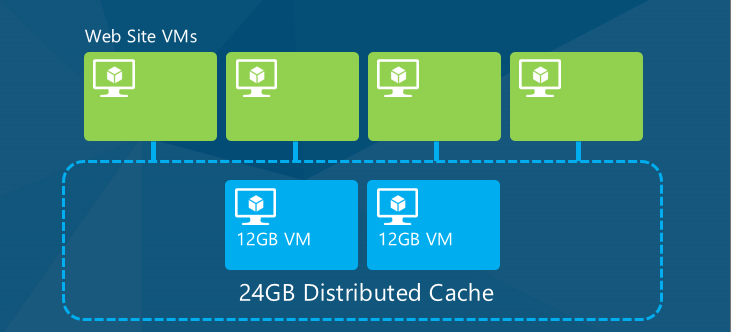
Lorsque l’application est mise à l’échelle en ajoutant ou en supprimant des serveurs, ou lorsque des serveurs sont remplacés en raison de mises à niveau ou d’erreurs, les données mises en cache restent accessibles à chaque serveur qui exécute l’application.
En évitant l’accès aux données à latence élevée d’un magasin de données persistant, la mise en cache peut considérablement améliorer la réactivité des applications. Par exemple, la récupération de données à partir du cache est beaucoup plus rapide que celle d’une base de données relationnelle.
L’un des avantages secondaires de la mise en cache est la réduction du trafic vers le magasin de données persistant, ce qui peut entraîner des coûts inférieurs lorsque des frais de sortie de données sont facturés pour le magasin de données persistant.
Quand utiliser la mise en cache distribuée
La mise en cache fonctionne mieux pour les charges de travail d’application qui font plus de lecture que d’écriture de données, et lorsque le modèle de données prend en charge la clé/valeur organization que vous utilisez pour stocker et récupérer des données dans le cache. Il est également plus utile lorsque les utilisateurs de l’application partagent un grand nombre de données communes ; par exemple, le cache n’offre pas autant d’avantages si chaque utilisateur récupère généralement des données propres à cet utilisateur. Un catalogue de produits peut être un exemple où la mise en cache peut être très utile, car les données ne changent pas fréquemment et tous les clients examinent les mêmes données.
L’avantage de la mise en cache devient de plus en plus mesurable plus une application est mise à l’échelle, à mesure que les limites de débit et les retards de latence du magasin de données persistants deviennent de plus en plus limités sur les performances globales de l’application. Toutefois, vous pouvez implémenter la mise en cache pour d’autres raisons que les performances. Pour les données qui ne doivent pas être parfaitement à jour lorsqu’elles sont présentées à l’utilisateur, l’accès au cache peut servir de disjoncteur lorsque le magasin de données persistant ne répond pas ou n’est pas disponible.
Stratégies populaires de remplissage des caches
Pour pouvoir récupérer des données à partir du cache, vous devez d’abord les stocker à cet emplacement. Il existe plusieurs stratégies pour obtenir des données dont vous avez besoin dans un cache :
À la demande / Mise à l’écart du cache
L’application tente de récupérer des données à partir du cache, et lorsque le cache n’a pas les données (une « absence »), l’application stocke les données dans le cache afin qu’elles soient disponibles la prochaine fois. La prochaine fois que l’application essaie d’obtenir les mêmes données, elle trouve ce qu’elle recherche dans le cache (un « accès »). Pour empêcher l’extraction des données mises en cache qui ont changé sur la base de données, vous invalidez le cache lorsque vous apportez des modifications au magasin de données.
Envoi de données d’arrière-plan
Les services en arrière-plan poussent les données dans le cache selon une planification régulière, et l’application extrait toujours du cache. Cette approche fonctionne parfaitement avec des sources de données à latence élevée qui ne nécessitent pas que vous renvoyiez toujours les données les plus récentes.
Disjoncteur
L’application communique normalement directement avec le magasin de données persistants, mais lorsque le magasin de données persistant rencontre des problèmes de disponibilité, l’application récupère les données du cache. Les données ont peut-être été placées dans le cache à l’aide de la stratégie d’envoi de données en arrière-plan ou de mise en cache. Il s’agit d’une stratégie de gestion des erreurs plutôt que d’une stratégie d’amélioration des performances.
Pour maintenir les données dans le cache à jour, vous pouvez supprimer les entrées de cache associées lorsque votre application crée, met à jour ou supprime des données. Si votre application peut parfois obtenir des données légèrement obsolètes, vous pouvez vous appuyer sur un délai d’expiration configurable pour définir une limite d’ancienneté des données de cache.
Vous pouvez configurer l’expiration absolue (durée depuis la création de l’élément de cache) ou l’expiration décalée (durée depuis le dernier accès à un élément de cache). L’expiration absolue est utilisée lorsque vous dépendez du mécanisme d’expiration du cache pour éviter que les données ne deviennent trop obsolètes. Dans l’application Corriger, nous allons supprimer manuellement les éléments de cache obsolètes et utiliser l’expiration glissante pour conserver les données les plus à jour dans le cache. Quelle que soit la stratégie d’expiration que vous choisissez, le cache supprime automatiquement les éléments les plus anciens (le moins récemment utilisé ou LRU) lorsque la limite de mémoire du cache est atteinte.
Exemple de code cache-aside pour l’application Fix It
Dans l’exemple de code suivant, nous case activée d’abord le cache lors de la récupération d’une tâche de correction. Si la tâche se trouve dans le cache, nous la renvoyons ; si elle est introuvable, nous l’obtenons à partir de la base de données et la stockons dans le cache. Les modifications que vous apporteriez pour ajouter la mise en cache à la FindTaskByIdAsync méthode sont mises en surbrillance.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
string hitMiss = "Hit";
try
{
fixItTask = (FixItTask)cache.Get(id.ToString());
if (fixItTask == null)
{
fixItTask = await db.FixItTasks.FindAsync(id);
cache.Put(id.ToString(), fixItTask);
hitMiss = "Miss";
}
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed,
"cache {0}, id={1}", hitMiss, id);
}
catch (Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Lorsque vous mettez à jour ou supprimez une tâche de correction, vous devez invalider (supprimer) la tâche mise en cache. Sinon, les tentatives ultérieures de lecture de cette tâche continueront d’obtenir les anciennes données du cache.
public async Task UpdateAsync(FixItTask taskToSave)
{
Stopwatch timespan = Stopwatch.StartNew();
try
{
cache.Remove(taskToSave.FixItTaskId.ToString());
db.Entry(taskToSave).State = EntityState.Modified;
await db.SaveChangesAsync();
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.UpdateAsync", timespan.Elapsed, "taskToSave={0}", taskToSave);
}
catch (Exception e)
{
log.Error(e, "Error in FixItTaskRepository.UpdateAsync(taskToSave={0})", taskToSave);
}
}
Il s’agit d’exemples pour illustrer le code de mise en cache simple ; La mise en cache n’a pas été implémentée dans le projet de correction téléchargeable.
Services de mise en cache Azure
Azure propose les services de mise en cache suivants : Cache Redis Azure et Cache managé Azure. Le cache Redis Azure est basé sur le open source le cache Redis populaire et constitue le premier choix pour la plupart des scénarios de mise en cache.
ASP.NET l’état de session à l’aide d’un fournisseur de cache
Comme mentionné dans le chapitre sur les meilleures pratiques de développement web, il est recommandé d’éviter d’utiliser l’état de session. Si votre application nécessite l’état de session, la meilleure pratique consiste à éviter le fournisseur en mémoire par défaut, car cela n’active pas le scale-out (plusieurs instances du serveur web). Le fournisseur d’état de session ASP.NET SQL Server permet à un site qui s’exécute sur plusieurs serveurs web d’utiliser l’état de session, mais il entraîne un coût de latence élevé par rapport à un fournisseur en mémoire. La meilleure solution si vous devez utiliser l’état de session consiste à utiliser un fournisseur de cache, tel que le fournisseur d’état de session pour Azure Cache.
Résumé
Vous avez vu comment l’application Fix It peut implémenter la mise en cache afin d’améliorer le temps de réponse et la scalabilité, et pour permettre à l’application de continuer à répondre aux opérations de lecture lorsque la base de données n’est pas disponible. Dans le chapitre suivant , nous allons montrer comment améliorer davantage la scalabilité et faire en sorte que l’application continue d’être réactive pour les opérations d’écriture.
Ressources
Pour plus d’informations sur la mise en cache, consultez les ressources suivantes.
Documentation
- Cache Azure. Documentation MSDN officielle sur la mise en cache dans Azure.
- Modèles et pratiques Microsoft - Conseils Azure. Consultez Guide de mise en cache et modèle Cache-Aside.
- Sécurité des défaillances : Conseils pour les architectures cloud résilientes. Livre blanc par Marc Mercuri, Ulrich Homann et Andrew Townhill. Consultez la section relative à la mise en cache.
- Meilleures pratiques pour la conception de Large-Scale Services sur Azure Services cloud. Heure standard Livre blanc par Mark Simms et Michael Thomassy. Consultez la section relative à la mise en cache distribuée.
- Mise en cache distribuée sur le chemin de la scalabilité. Un article plus ancien (2009) de MSDN Magazine, mais une introduction clairement écrite à la mise en cache distribuée en général; va plus loin que les sections de mise en cache des livres blancs FailSafe et Best Practices.
Vidéos
- FailSafe : création de Services cloud évolutifs et résilients. Série en neuf parties par Ulrich Homann, Marc Mercuri et Mark Simms. Présente une vue de niveau 400 de l’architecture des applications cloud. Cette série se concentre sur la théorie et les raisons pour lesquelles; Pour plus d’informations, consultez la série Building Big de Mark Simms. Consultez la discussion sur la mise en cache dans l’épisode 3 à partir de 1:24:14.
- Création d’un grand projet : leçons tirées des clients Azure - Partie I. Simon Davies parle de la mise en cache distribuée à partir de 46:00. Similaire à la série Failsafe, mais passe en plus de détails. La présentation a été donnée le 31 octobre 2012, de sorte qu’elle ne couvre pas le service de mise en cache de Web Apps dans Azure App Service qui a été introduit en 2013.
Exemple de code
- Principes de base du service cloud dans Azure. Exemple d’application qui implémente la mise en cache distribuée. Consultez le billet de blog associé Principes de base du service cloud – Mise en cache.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour