Gestion des erreurs temporaires (création d’applications cloud Real-World avec Azure)
par Rick Anderson, Tom Dykstra
Télécharger corriger le projet ou télécharger le livre électronique
Le livre électronique Building Real World Cloud Apps with Azure est basé sur une présentation développée par Scott Guthrie. Il explique 13 modèles et pratiques qui peuvent vous aider à développer des applications web pour le cloud. Pour plus d’informations sur le livre électronique, consultez le premier chapitre.
Lorsque vous concevez une application cloud réelle, l’une des choses à prendre en compte est la façon de gérer les interruptions de service temporaires. Ce problème est particulièrement important dans les applications cloud, car vous êtes tellement dépendant des connexions réseau et des services externes. Vous pouvez souvent obtenir de petits problèmes qui sont généralement autoréparables, et si vous n’êtes pas prêt à les gérer intelligemment, ils entraîneront une mauvaise expérience pour vos clients.
Causes des défaillances temporaires
Dans l’environnement cloud, vous constaterez que les échecs et les abandons connexions aux bases de données se produisent régulièrement. C’est en partie parce que vous utilisez plus d’équilibreurs de charge par rapport à l’environnement local où votre serveur web et votre serveur de base de données ont une connexion physique directe. En outre, parfois, lorsque vous êtes dépendant d’un service multilocataire, vous voyez les appels au service devenir plus lents ou expirer, car quelqu’un d’autre qui utilise le service le frappe lourdement. Dans d’autres cas, vous pouvez être l’utilisateur qui touche le service trop fréquemment, et le service vous limite délibérément ( refuse les connexions) afin de vous empêcher d’affecter négativement d’autres locataires du service.
Utiliser une logique de nouvelle tentative/back-off intelligente pour atténuer l’effet des échecs temporaires
Au lieu de lever une exception et d’afficher une page d’erreur ou non disponible pour votre client, vous pouvez reconnaître les erreurs qui sont généralement temporaires et réessayer automatiquement l’opération qui a entraîné l’erreur, dans l’espoir que vous réussirez avant longtemps. La plupart du temps, l’opération réussit au deuxième essai, et vous récupérerez après l’erreur sans que le client ait jamais été au courant qu’il y avait un problème.
Il existe plusieurs façons d’implémenter une logique de nouvelle tentative intelligente.
Le groupe Microsoft Patterns & Practices a un bloc d’application de gestion des erreurs temporaires qui fait tout pour vous si vous utilisez ADO.NET pour l’accès SQL Database (pas via Entity Framework). Il vous suffit de définir une stratégie pour les nouvelles tentatives (le nombre de nouvelles tentatives d’une requête ou d’une commande et la durée d’attente entre les tentatives) et d’encapsuler votre code SQL dans un bloc à l’aide .
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH prend également en charge Azure In-Role Cache et Service Bus.
Lorsque vous utilisez Entity Framework, vous ne travaillez généralement pas directement avec des connexions SQL. Vous ne pouvez donc pas utiliser ce package Patterns and Practices, mais Entity Framework 6 génère ce type de logique de nouvelle tentative directement dans l’infrastructure. De la même manière, vous spécifiez la stratégie de nouvelle tentative, puis EF utilise cette stratégie chaque fois qu’il accède à la base de données.
Pour utiliser cette fonctionnalité dans l’application Corriger le problème, il nous suffit d’ajouter une classe qui dérive de DbConfiguration et d’activer la logique de nouvelle tentative.
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }Pour SQL Database exceptions que l’infrastructure identifie comme des erreurs généralement temporaires, le code indiqué indique à EF de réessayer l’opération jusqu’à 3 fois, avec un délai d’arrêt exponentiel entre les nouvelles tentatives et un délai maximal de 5 secondes. La sauvegarde exponentielle signifie qu’après chaque nouvelle tentative ayant échoué, elle attendra plus longtemps avant de réessayer. Si trois tentatives de ligne échouent, une exception est levée. La section suivante sur les disjoncteurs explique pourquoi vous souhaitez un back-off exponentiel et un nombre limité de nouvelles tentatives.
Vous pouvez rencontrer des problèmes similaires lorsque vous utilisez le service Stockage Azure, comme l’application Corriger pour les objets blob, et l’API cliente de stockage .NET implémente déjà le même type de logique. Vous spécifiez simplement la stratégie de nouvelle tentative, ou vous n’avez même pas besoin de le faire si vous êtes satisfait des paramètres par défaut.
Disjoncteurs
Il existe plusieurs raisons pour lesquelles vous ne voulez pas réessayer trop de fois sur une période trop longue :
- Un trop grand nombre d’utilisateurs retenant constamment des demandes ayant échoué peuvent dégrader l’expérience des autres utilisateurs. Si des millions de personnes effectuent toutes des demandes de nouvelle tentative répétées, vous pouvez lier les files d’attente de distribution IIS et empêcher votre application de traiter les demandes qu’elle pourrait autrement gérer correctement.
- Si tout le monde effectue une nouvelle tentative en raison d’une défaillance du service, il peut y avoir tellement de demandes mises en file d’attente que le service est inondé lorsqu’il commence à récupérer.
- Si l’erreur est due à la limitation et qu’il existe une fenêtre de temps que le service utilise pour la limitation, les nouvelles tentatives continues peuvent déplacer cette fenêtre vers l’extérieur et entraîner la poursuite de la limitation.
- Vous pouvez avoir un utilisateur qui attend qu’une page web soit affichée. Faire patienter trop longtemps peut être plus ennuyeux que de les conseiller relativement rapidement à réessayer plus tard.
La sauvegarde exponentielle résout certains de ces problèmes en limitant la fréquence des nouvelles tentatives qu’un service peut obtenir à partir de votre application. Mais vous devez également avoir des disjoncteurs : cela signifie qu’à un certain seuil de nouvelle tentative, votre application cesse de réessayer et effectue d’autres actions, telles que l’une des actions suivantes :
- Secours personnalisé. Si vous ne pouvez pas obtenir un cours de l’action de Reuters, peut-être que vous pouvez l’obtenir de Bloomberg ; ou si vous ne pouvez pas obtenir des données à partir de la base de données, vous pouvez peut-être les obtenir à partir du cache.
- Échec silencieux. Si ce dont vous avez besoin à partir d’un service n’est pas tout ou rien pour votre application, il vous suffit de retourner null lorsque vous ne pouvez pas obtenir les données. Si vous affichez une tâche De correction et que le service Blob ne répond pas, vous pouvez afficher les détails de la tâche sans l’image.
- Échec rapide. Erreur de l’utilisateur pour éviter d’inonder le service de demandes de nouvelle tentative qui pourraient entraîner une interruption du service pour d’autres utilisateurs ou étendre une fenêtre de limitation. Vous pouvez afficher un message convivial « réessayer ultérieurement ».
Il n’existe aucune stratégie de nouvelle tentative universelle. Vous pouvez réessayer plus de fois et attendre plus longtemps dans un processus de travail en arrière-plan asynchrone que dans une application web synchrone où un utilisateur attend une réponse. Vous pouvez attendre plus longtemps entre les nouvelles tentatives pour un service de base de données relationnelle que pour un service de cache. Voici quelques exemples de stratégies de nouvelle tentative recommandées pour vous donner une idée de la façon dont les nombres peuvent varier. (« Fast First » signifie aucun délai avant la première nouvelle tentative.
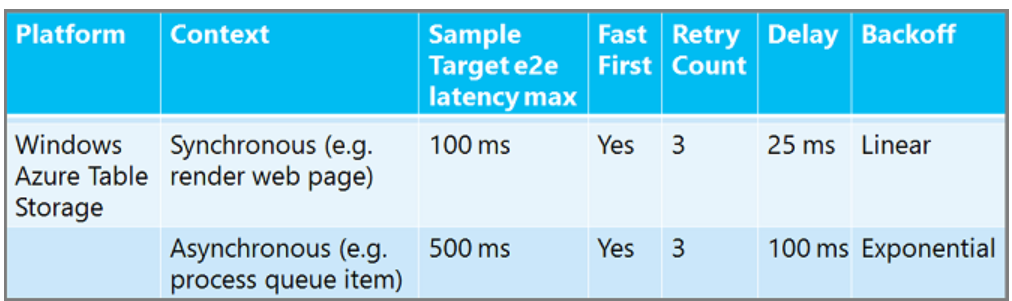
Pour obtenir SQL Database conseils de stratégie de nouvelle tentative, consultez Résoudre les erreurs temporaires et les erreurs de connexion à SQL Database.
Résumé
Une stratégie de nouvelle tentative/back-off peut aider à rendre les erreurs temporaires invisibles pour le client la plupart du temps, et Microsoft fournit des frameworks que vous pouvez utiliser pour réduire votre travail en implémentant une stratégie, que vous utilisiez ADO.NET, Entity Framework ou le service Stockage Azure.
Dans le chapitre suivant, nous allons voir comment améliorer les performances et la fiabilité à l’aide de la mise en cache distribuée.
Ressources
Pour plus d’informations, consultez les ressources suivantes :
Documentation
- Meilleures pratiques pour la conception de Large-Scale Services sur Azure Services cloud. Livre blanc de Mark Simms et Michael Thomassy. Similaire à la série Failsafe, mais va dans plus de détails. Consultez la section Télémétrie et diagnostics.
- Failsafe : Conseils pour les architectures cloud résilientes. Livre blanc de Marc Mercuri, Ulrich Homann et Andrew Townhill. Version de page web de la série de vidéos FailSafe.
- Modèles et pratiques Microsoft - Conseils Azure. Consultez Modèle de nouvelle tentative, Modèle superviseur de l’agent scheduler.
- Entity Framework - Résilience de connexion/logique de nouvelle tentative. Comment utiliser et personnaliser la fonctionnalité de gestion des erreurs temporaires d’Entity Framework 6.
- Résilience de connexion et interception de commandes avec Entity Framework dans une application MVC ASP.NET. Quatrième d’une série de tutoriels en neuf parties, vous montre comment configurer la fonctionnalité de résilience de connexion EF 6 pour SQL Database.
Vidéos
- FailSafe : création de Services cloud évolutifs et résilients. Série en neuf parties par Ulrich Homann, Marc Mercuri et Mark Simms. Présente des concepts de haut niveau et des principes architecturaux d’une manière très accessible et intéressante, avec des histoires tirées de l’expérience de l’équipe de conseil à la clientèle Microsoft (CAT) avec des clients réels. Voir la discussion sur les disjoncteurs dans l’épisode 3 à partir de 40h55.
- Création d’une grande taille : leçons apprises des clients Azure - Partie II. Mark Simms parle de la conception de l’échec, de la gestion des erreurs temporaires et de l’instrumentation de tout.
Exemple de code
- Principes de base du service cloud dans Azure. Exemple d’application créé par l’équipe de conseil à la clientèle Microsoft Azure qui montre comment utiliser le bloc de gestion des erreurs temporaires (TFH) de la bibliothèque d’entreprise . Pour plus d’informations, consultez Couche d’accès aux données de Cloud Service Fundamentals - Gestion des erreurs temporaires. TFH est recommandé pour l’accès à la base de données à l’aide de ADO.NET directement (sans utiliser Entity Framework).
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour