Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Quand une requête d’utilisateur trouve une correspondance dans une base de connaissances, QnA Maker renvoie des réponses pertinentes, ainsi qu’un score de confiance. Ce score indique la probabilité que la réponse corresponde à la requête de l’utilisateur.
Un score de confiance est une valeur comprise de 0 à 100. Un score de 100 est probablement une correspondance exacte, tandis qu’un score de 0 signifie qu’aucune réponse correspondante n’a été trouvée. Plus le score et élevé, plus la réponse est fiable. Plusieurs réponses peuvent correspondre à une requête donnée. Dans ce cas, les réponses sont retournées dans l’ordre décroissant du score de confiance.
L’exemple ci-dessous présente une entité QnA avec 2 questions.

Pour l’exemple ci-dessus, vous pouvez vous attendre à des scores tels que ceux de l’exemple de plage de scores ci-dessous, pour différents types de requêtes utilisateur :
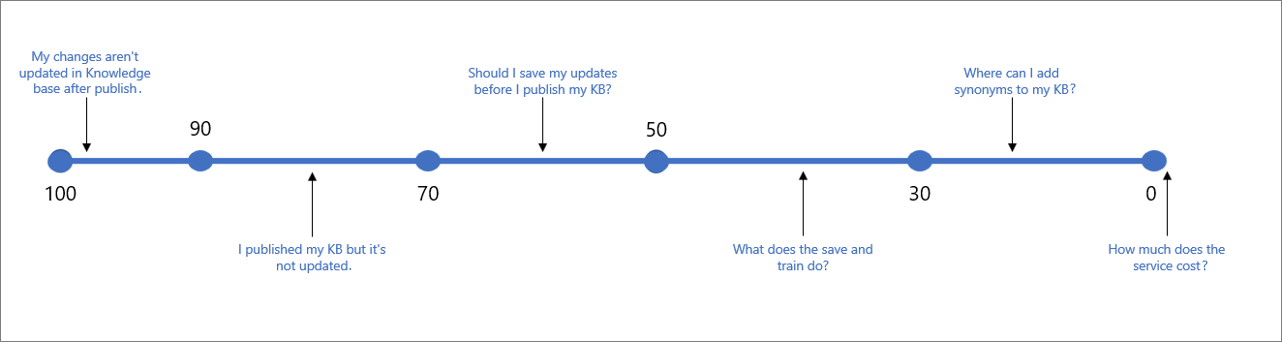
Le tableau suivant indique la confiance généralement associée à un score donné.
| Valeur du score | Signification du score | Exemple de requête |
|---|---|---|
| 90 - 100 | Correspondance presque exacte entre la requête de l’utilisateur et une question de la base de connaissances | « Mes modifications ne sont pas mises à jour dans la base de connaissances après publication » |
| > 70 | Niveau de confiance élevé, généralement une bonne réponse correspondant complètement à la requête de l’utilisateur | « J’ai publié ma base de connaissances, mais elle n’est pas à jour » |
| 50 - 70 | Confiance moyenne, généralement une assez bonne réponse correspondant à l’intention principale de la requête de l’utilisateur | « Dois-je enregistrer mes mises à jour avant de publier ma base de connaissances ? » |
| 30–50 | Confiance faible, généralement une réponse connexe correspondance partiellement l’intention de la requête de l’utilisateur | « Que font l’enregistrement et l’apprentissage ? » |
| < 30 | Confiance très faible, généralement une réponse ne correspondant pas à la requête de l’utilisateur, à l’exception de certains mots ou expressions | « Où puis-je ajouter des synonymes à ma base de connaissances » |
| 0 | Aucune correspondance, donc aucune réponse retournée. | « Combien coûte le service ? » |
Choisir un seuil de score
Le tableau ci-dessus présente les scores attendus sur la plupart des bases de connaissances. Cependant, comme chaque base de connaissances est différente et qu’elle comporte différents types de mots, d’intentions et d’objectifs, nous vous recommandons de tester et de choisir le seuil qui vous convient le mieux. Par défaut, le seuil est défini sur 0, afin que toutes les réponses possibles soient retournées. Le seuil recommandé qui devrait fonctionner pour la plupart des bases de connaissances est 50.
Lorsque vous choisissez votre seuil, n’oubliez pas l’équilibre entre exactitude et couverture, et ajustez votre seuil à vos besoins.
Si l’exactitude (ou précision) est primordiale pour votre scénario, augmentez votre seuil. Ainsi, chaque fois que vous retournerez une réponse, celle-ci sera beaucoup plus FIABLE et susceptible d’être celle qu’attendent les utilisateurs. Dans ce cas, vous risquez de laisser davantage de questions sans réponse. Exemple : si vous fixez le seuil à 70, vous risquez de passer à côté d’exemples ambigus tels que « qu’est-ce qu’enregistrer et former ? ».
Si la couverture (ou rappel) est primordiale et que vous souhaitez répondre au plus grand nombre possible de questions, même si la réponse n’a qu’une relation très vague ou lointaine avec la question, ABAISSEZ le seuil. Cela signifie qu’il pourrait y avoir davantage de cas où la réponse ne correspond pas à la requête réelle de l’utilisateur, mais fournit des informations vaguement associées à la question. Par exemple : si vous définissez le seuil sur 30, vous pouvez donner des réponses aux requêtes comme « Où puis-je modifier ma base de connaissances ? »
Notes
Les nouvelles versions de QnA Maker incluent des améliorations à la logique de notation, et pourraient affecter votre seuil. Chaque fois que vous mettez à jour le service, assurez-vous de tester et d’ajuster le seuil si nécessaire. Vous pouvez vérifier votre version du service QnA ici et voir comment obtenir les dernières mises à jour ici.
Définir le seuil
Définissez le score de seuil en tant que propriété du corps JSON de l’API GenerateAnswer. Cela signifie que vous le définissez pour chaque appel à GenerateAnswer.
À partir de Bot Framework, définissez le score au niveau de l’objet options avec C# ou Node.js.
Améliorer les scores de confiance
Pour améliorer le score de confiance d’une réponse spécifique à une question de l’utilisateur, vous pouvez ajouter la question de l’utilisateur à la base de connaissances en tant que question alternative liée à cette réponse. Vous pouvez également utiliser des altérations d’un mot (ignorant la casse) pour ajouter des synonymes aux mots clés dans votre base de connaissances.
Scores de confiance similaires
Lorsque plusieurs réponses ont un score de confiance similaire, il est probable que la question était trop générique et donc mise en correspondance à probabilité égale avec plusieurs réponses. Essayez de mieux structurer vos Questions et réponses afin que chaque entité QnA ait une intention distincte.
Différences entre les scores de confiance entre le test et la production
Le score de confiance d’une réponse peut changer sensiblement entre le test et la version publiée de la base de connaissances, même si le contenu est le même. En effet, le contenu de la base de connaissances de test et de la base de connaissances publiée se trouvent dans des index Azure AI Search différents.
L’index de test contient toutes les paires QnA de vos bases de connaissances. Lors de l’interrogation de l’index de test, la requête s’applique à l’ensemble de l’index, puis les résultats sont limités à la partition de cette base de connaissances spécifique. Si les résultats de la requête de test ont un impact négatif sur votre capacité à vérifier la base de connaissances, vous pouvez :
- organiser votre base de connaissances à l’aide d’un des éléments suivants :
- 1 ressource limitée à 1 Ko : limitez votre ressource QnA unique (et l’index de test Azure AI Search résultant) à une base de connaissances unique.
- 2 ressources (1 pour le test, 1 pour la production) : avoir deux ressources QnA Maker, en utilisant l’une pour le test (avec ses propres index de test et de production) et l’autre pour le produit (ayant également ses propres index de test et de production)
- et toujours utilisez les mêmes paramètres, tels que top lorsque vous interrogez à la fois votre base de connaissances de test et celle de production
Quand vous publiez une base de connaissances, ses contenus de questions/réponses se déplacent de l’index de test vers un index de production dans Recherche Azure. Découvrez le fonctionnement de l’opération de publication.
Si vous avez une base de connaissances dans différentes régions, chacune d’elles utilise son propre index de Azure AI Search. Étant donné que différents index sont utilisés, les scores ne seront pas exactement les mêmes.
Aucune correspondance trouvée
Si aucune bonne correspondance n’est trouvée par la fonction de classement, le score de confiance de 0,0 ou « None » est retourné, et la réponse par défaut est « Aucune bonne correspondance trouvée dans la base de connaissances ». Vous pouvez remplacer cette réponse par défaut dans le code du bot ou de l’application appelant le point de terminaison. Vous pouvez également définir la réponse de remplacement dans Azure, et cela modifie la valeur par défaut pour toutes les bases de connaissances déployées dans un service QnA Maker particulier.