Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous fournit les meilleures pratiques relatives à la préparation d’échantillons vocaux de haute qualité pour l’optimisation de la voix professionnelle. Pour comprendre comment les données sont traitées et les conditions minimales requises pour l’acceptation des données, reportez-vous au chargement de vos données.
La création d’une voix professionnelle de haute qualité à partir de zéro n’est pas une entreprise décontractée. Le composant central d’une voix personnalisée est une grande collection d’échantillons audio de parole humaine. Il est essentiel que ces enregistrements audio soient de haute qualité. Choisissez un talent vocal ayant une expérience dans ces types d’enregistrements, et enregistrez-le en faisant appel à un ingénieur spécialisé disposant d’un matériel professionnel.
Mais avant de pouvoir effectuer ces enregistrements, vous avez besoin d’un script, c’est-à-dire les mots qui sont énoncés par votre artiste vocal pour créer les échantillons audio.
L’enregistrement d’une voix professionnelle implique de nombreux petits détails très importants. Ce guide est une feuille de route détaillant le processus qui vous aidera à obtenir des résultats homogènes.
Conseils relatifs à la préparation des données pour une sortie vocale de haute qualité
Une voix personnalisée hautement naturelle dépend de plusieurs facteurs, comme la qualité et la taille de vos données d’entraînement.
La qualité de vos données d’entraînement est un facteur primordial. Par exemple, dans le même jeu d’entraînement, un volume cohérent, une vitesse de parole, une tonalité de parole et un style de parole sont essentiels pour créer une voix personnalisée de haute qualité. Vous devez également éviter les bruits de fond dans l’enregistrement, et vous assurer que le script et l’enregistrement correspondent. Pour vous assurer de la qualité de vos données, vous devez respecter les critères de sélection du script et les exigences d’enregistrement.
En ce qui concerne la taille des données d’apprentissage, dans la plupart des cas, vous pouvez créer une voix personnalisée raisonnable avec 300 énoncés. Selon nos tests, l’ajout de données d’entraînement supplémentaires dans la plupart des langues n’améliore pas nécessairement la tonalité naturelle de la voix elle-même (testée à l’aide du score MOS). Toutefois, avec plus de données d’entraînement qui couvrent plus d’instances de mots, vous avez une probabilité plus élevée de réduire le ratio des éléments non satisfaisants de la voix, tels que les défauts, pour la sortie vocale. Pour entendre à quoi ressemblent les éléments insatisfaisants de la voix, reportez-vous aux exemples GitHub.
Dans certains cas, vous pouvez souhaiter un personnage vocal avec des caractéristiques uniques. Par exemple, un personnage de dessin animé a besoin d’une voix avec un style d’élocution spécial, ou une voix dynamique dans l’intonation. Dans ce cas, nous vous recommandons de préparer au moins 1 000 énoncés (idéalement, 2 000) et de les enregistrer dans un studio d’enregistrement professionnel. Pour en savoir plus sur l’amélioration de la qualité de votre modèle vocal, consultez les caractéristiques et les limitations relatives à l’utilisation de la voix personnalisée.
Rôles lors d’un enregistrement vocal
Il existe quatre rôles de base dans un projet d’enregistrement vocal personnalisé :
| Role | Objectif |
|---|---|
| Voix professionnelle | La voix de cette personne constitue la base de la voix personnalisée. |
| Ingénieur du son | Surveille les aspects techniques de l’enregistrement et commande le matériel d’enregistrement. |
| Directeur | Prépare le script et dirige l’enregistrement de la voix professionnelle. |
| Éditeur | Finalise les fichiers audio et les prépare pour le chargement sur le service Speech. |
Une même personne peut remplir plusieurs rôles. Ce guide part du principe que vous tenez le rôle de directeur et recrutez à la fois l’artiste vocal et l’ingénieur du son. Si vous souhaitez effectuer vous-même les enregistrements, cet article fournit certaines informations sur le rôle d’ingénieur du son. Le rôle d’éditeur n’est nécessaire qu’après la session d’enregistrement. En attendant, le directeur ou l’ingénieur du son peut remplir ce rôle.
Choisir votre voix professionnelle
Les acteurs spécialisés dans la voix off ou le doublage, l’animation radio ou la présentation de journaux sont de bons candidats. Choisissez une personne dont la voix naturelle vous plaît. Il est possible de créer une voix de « personnage » unique, mais il est plus difficile pour la plupart des acteurs de reproduire cette voix de manière cohérente, et cet effort risque d’entraîner une déformation de la voix. Le principal facteur quant au choix de la voix professionnelle est l’homogénéité. Vos enregistrements pour le même style de voix doivent donner l’impression qu’ils ont été réalisés le même jour et dans la même pièce. Pour tendre à cet idéal, vous devez suivre de bonnes pratiques en matière d’enregistrement et d’ingénierie.
Votre artiste vocal doit être capable de parler à un débit, à un niveau de volume, à une hauteur et sur un ton constants avec une diction nette. L’artiste doit aussi être capable de contrôler ses variations de tonalité, ses émotions ou ses tics de langage. L’enregistrement d’échantillons vocaux est une activité plus fatigante que d’autres types de travail vocal. La plupart des artistes vocaux sont capables d’effectuer des enregistrements pendant deux ou trois heures par jour seulement. Limitez les sessions à trois ou quatre jours par semaine, en accordant si possible un jour de repos entre deux sessions.
Travaillez avec votre artiste vocal pour créer un personnage qui définit le ton global et le niveau d’émotion de la voix personnalisée. Vous définissez les styles de parole pour votre personnage et demandez à votre artiste vocal de lire le script d’une manière qui s’aligne sur vos styles souhaités. Veillez à ce que le style de parole reste cohérent tout au long des enregistrements pour un jeu de données d’apprentissage.
Par exemple, un personnage naturellement optimiste laisse transparaître son optimisme dans sa voix. Toutefois, cette personnalité doit être constamment exprimée dans tous les enregistrements pour un jeu de données d’apprentissage. Écoutez les voix existantes pour vous faire une idée de ce que vous recherchez.
Conseil
En règle générale, vous devez garder la propriété des enregistrements vocaux que vous effectuez. Votre acteur devrait travailler sous contrat dans le cadre de votre projet.
Créer un script
Le point de départ de toute session d’enregistrement vocal personnalisée est le script, qui contient les énoncés à prononcer par votre talent vocal. Le terme « énoncés » englobe les phrases complètes et les expressions plus courtes. La création d’une voix personnalisée nécessite au moins 300 énoncés enregistrés en tant que données d’apprentissage.
Les énoncés de votre script peuvent provenir de n’importe quelle source : fiction, non-fiction, transcription de discours, bulletin d’informations ou tout autre document imprimé. Pour obtenir une brève description des potentiels problèmes juridiques, consultez la section « Aspects juridiques ». Vous pouvez également écrire votre propre texte.
Vos énoncés n’ont pas besoin de provenir de la même source, du même type de source ou d’être liés d’une manière ou d’une autre. Toutefois, si vous comptez utiliser des expressions spécifiques (par exemple, « Vous vous êtes connecté avec succès ») dans votre application de reconnaissance vocale, veillez à les inclure dans votre script. Il donne à votre voix personnalisée une meilleure chance de prononçant bien ces expressions.
Il est recommandé que les scripts d’enregistrement comprennent à la fois des phrases générales et des phrases propres à un domaine. Par exemple, si vous prévoyez d’enregistrer 2 000 phrases, 1 000 d’entre elles peuvent être des phrases générales, 1 000 autres peuvent être des phrases de votre domaine cible ou du cas d’utilisation de votre application.
Nous fournissons des exemples de scripts dans les domaines « Général », « Conversation » et « Service client » pour chaque langue afin de vous aider à préparer vos scripts d’enregistrement. Vous pouvez utiliser ces scripts partagés Microsoft pour vos enregistrements directement ou les utiliser comme référence pour créer le vôtre.
Critères de sélection des scripts
Voici quelques instructions générales que vous pouvez suivre pour créer un bon corpus (échantillons audio enregistrés) pour le réglage de la voix professionnelle.
Pour la plupart des cas d’usage, les phrases sont recommandées pour être comprises entre 2 et 15 secondes, contenant 5 à 30 mots pour les langues latines ou 4 à 80 mots pour les langues non latines. Essayez d’équilibrer votre script pour inclure divers types de phrases et longueurs. Vérifiez que votre script n’inclut pas de phrases en double.
Si votre cas d’usage nécessite un accent élevé sur les questions, les exclamations ou un mélange de phrases particulièrement longues et courtes, il est recommandé d’inclure une bonne partie des phrases en tant que questions ou exclamations, ainsi que des phrases très courtes et des phrases plus longues jusqu’à 20 secondes de longueur.
Pour savoir comment équilibrer les différents types de phrases, reportez-vous au tableau suivant :
Types de phrases Couverture Phrases d’affirmation Les phrases affirmatives doivent représenter entre 70 et 80 % du script. Court mot/expression Les scripts de mots/phrases courts doivent également représenter environ 10 % du nombre total d’énoncés, avec 5 à 7 mots par cas.
Les mots ou expressions courts doivent être séparés par des virgules pour aider à rappeler aux talents vocaux de s’interrompre brièvement lors de la lecture.Phrases de questions (facultatif) Les phrases interrogatives doivent constituer environ 10 à 20 % de votre script de domaine, dont 5 à 10 % de tonalités montantes et 5 à 10 % de tonalités descendantes.
Ces phrases sont requises si vous souhaitez que la voix générée transmette avec précision des questions.Phrases d’exclamation (facultatif) Les phrases exclamatives doivent constituer environ 10 à 20 % de votre script.
Ces phrases sont requises si vous souhaitez que la voix générée transmette avec précision les exclamations.Remarque
Vous pouvez estimer le nombre de mots dans une phrase en supposant un taux de parole en mots par seconde en fonction de votre langue.
Voici les meilleures pratiques :
- Couverture équilibrée des catégories grammaticales, comme les verbes, les substantifs, les adjectifs, etc.
- Couverture équilibrée des prononciations. Incluez toutes les lettres de A à Z pour que le moteur de synthèse vocale apprenne à prononcer chaque lettre dans votre style.
- Scripts lisibles et compréhensibles pour la personne qui lit.
- Évitez d’utiliser trop de modèles similaires pour les mots/expressions, comme « facile » et « plus facile ».
- Incluez des formats différents pour les nombres : adresse, unité, téléphone, quantité, date, etc., dans tous les types de phrases.
- Incluez des phrases orthographiques si c’est quelque chose que votre voix personnalisée lit. Par exemple, « l’orthographe du mot Pomme est P O M M E ».
Remarque
Pour le mode de traitement contextuel, qui fournit des intonations plus naturelles et de meilleures fonctionnalités conversationnelles :
- Utilisez du texte au niveau du paragraphe plutôt que du texte au niveau de la phrase pour les enregistrements. Cette approche permet de capturer le flux de parole naturelle entre les phrases et de préserver les informations contextuelles.
- Chaque enregistrement doit idéalement comporter plus de 30 secondes (contenant plus de 60 mots pour les langues latines ou 160 mots pour les langues non latines).
- Un ensemble d’entraînement contextuel avec plus de 30 minutes d'audio au total ou 300 énoncés peut être utilisé pour entraîner une voix personnalisée.
Ne placez pas plusieurs phrases sur une seule ligne ou dans un seul énoncé. Séparez chaque ligne par énoncé.
Vérifiez que la phrase est nette. En général, n’incluez pas trop de mots non standard tels que des nombres ou des abréviations, car ils sont difficiles à lire. Certaines applications peuvent nécessiter de lire beaucoup de nombres ou d’acronymes. Dans ce cas, vous pouvez inclure ces mots, mais en les normalisant dans leur forme parlée.
Voici quelques-unes des meilleures pratiques, par exemple :
- Pour les lignes avec des abréviations, au lieu de « càd », écrivez « c’est-à-dire ».
- Pour les lignes comportant des chiffres, au lieu de « 18 », utilisez « dix-huit ».
- Pour les lignes avec des acronymes, au lieu de « ABC », écrivez « A B C ».
Veillez à ce que votre artiste vocal prononce ces mots d’une façon attendue. Assurez la cohérence de votre script et des enregistrements au cours du processus d’entraînement.
Votre script doit inclure un grand nombre de mots et de phrases variées, avec un large éventail de longueurs, de structures et de tons.
Vérifiez attentivement que le script ne contient pas d’erreurs. Si possible, demandez aussi à un tiers d’effectuer cette vérification. Quand vous parcourez le script avec votre artiste vocal, vous pouvez éventuellement détecter d’autres erreurs.
Différence entre le script d’artiste vocal et le script d’entraînement
Le script d’entraînement peut différer du script d’artiste vocal, en particulier pour les scripts qui contiennent des chiffres, des symboles, des abréviations, une date et une heure. Les scripts préparés pour l’artiste vocal doivent suivre les conventions de lecture natives, telles que 50 % et 45 $. Les scripts utilisés pour l’entraînement doivent être normalisés de façon à correspondre à l’enregistrement audio, comme cinquante pour cent et quarante-cinq dollars.
Remarque
Nous fournissons des exemples de scripts pour l’artiste vocal sur GitHub. Pour utiliser les exemples de scripts pour l’entraînement, vous devez les normaliser en fonction des enregistrements de votre artiste vocal avant de charger le fichier.
Le tableau suivant montre la différence entre les scripts pour artiste vocal et le script normalisé pour l’entraînement.
| Catégorie | Exemple de script d’artiste vocal | Exemple de script d’entraînement (normalisé) |
|---|---|---|
| Chiffres | 123 | cent vingt-trois |
| Symboles | 50 % | cinquante pour cent |
| Abréviation | Dès que possible | dès que possible |
| Date et heure | 3 mars à 17h00 | Trois mars à dix-sept heures |
Défauts typiques d’un script
La qualité médiocre du script peut nuire aux résultats de l’apprentissage. Pour obtenir des résultats d’entraînement de haute qualité, il est essentiel d’éviter les défauts.
Les défauts de script figurent généralement dans les catégories suivantes :
| Catégorie | Exemple |
|---|---|
| Contenu dénué de sens. | « Les idées vertes décolorées dorment furieusement. » |
| Phrases incomplètes. | -« Ceci était mon dernier Réveillon » (sans objet, aucune signification spécifique) - « Ils sont déjà amusant (sans guillemets à la fin, ce n’est pas une phrase complète) |
| Faute de frappe dans les phrases. | - Commencer par une minuscule - Aucune ponctuation de fin si nécessaire - Faute d’orthographe - Ponctuation manquante : aucun point à la fin (sauf un titre d’actualité) - Terminer par des symboles, sauf virgule, question, exclamation - Format incorrect, par exemple : - 45$ (doit être $45) - Pas d’espace ou espace excessif entre les mots/la ponctuation |
| La duplication dans un format similaire, une par modèle est suffisante. | -« À présent 13h00 à New York » -« À présent 14h00 à New York » -« À présent 15h00 à New York » -« À présent 13h00 à Seattle » -« À présent 13h00 à Washington D.C. » |
| Mots étrangers rares : seuls les mots étrangers couramment utilisés sont acceptables dans le script. | En anglais, il est possible d’utiliser le mot français « faux » dans le langage courant, mais une expression française comme « coincer la bulle » est plutôt rare. |
| Emoji ou tout autre symbole peu courant |
Format de script
Ce script sera utilisé lors des sessions d’enregistrement et vous pouvez le configurer comme vous le souhaitez. Créez le fichier texte exigé par Speech Studio séparément.
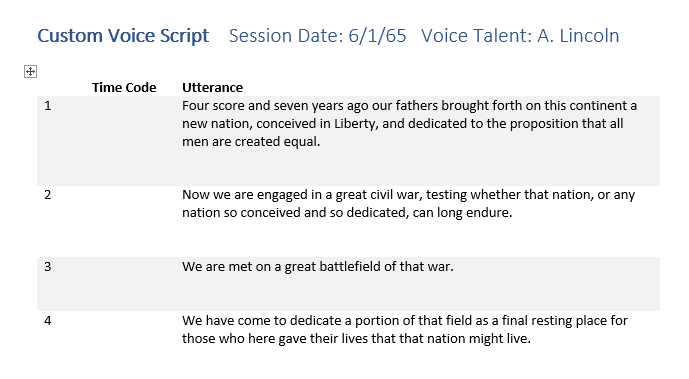
Un format de script de base contient trois colonnes :
- Le numéro de l’énoncé, à partir de 1. Cette numérotation aide toutes les personnes dans le studio à accéder directement à un énoncé précis (« reprenons l’énoncé 356 »). Vous pouvez utiliser la fonctionnalité de numérotation de paragraphe de Microsoft Word pour numéroter automatiquement les lignes du tableau.
- Une colonne vide où vous inscrivez le numéro de la prise ou le code temporel de chaque énoncé, pour vous aider à le repérer dans l’enregistrement terminé.
- Le texte de l’énoncé lui-même.
Remarque
La plupart des studios enregistrent de courts segments appelés « prises ». Chaque prise contient généralement de 10 à 24 énoncés. Le simple fait de noter le nombre de prises suffira pour trouver un énoncé plus tard. Si vous enregistrez dans un studio qui souhaite effectuer des enregistrements plus longs, utilisez plutôt des codes temporels. Le studio sera équipé d’un large écran indiquant le code.
Laissez suffisamment d’espace après chaque ligne pour y noter vos remarques. Veillez à ce qu’aucun énoncé n’apparaisse sur deux pages. Numérotez les pages et imprimez votre script sur le recto de chaque page.
Imprimez trois copies du script : une pour l’artiste vocal, une pour l’ingénieur du son et l’autre pour le directeur (vous). Utilisez un trombone plutôt que des agrafes : un acteur expérimenté sépare les pages pour éviter de faire du bruit en les feuilletant.
Déclaration de l’artiste vocal
Pour entraîner une voix neuronale, vous devez créer un profil de talent vocal avec un fichier audio enregistré par le talent vocal consentant à l’utilisation de ses données vocales pour affiner un modèle vocal professionnel. Quand vous préparez votre script d’enregistrement, veillez à inclure la déclaration suivante.
Aspects juridiques
Conformément à la législation, la lecture par un acteur d’un texte protégé par un copyright est un travail impliquant la rémunération de l’auteur du texte. Ces performances ne seront pas reconnaissables dans le produit final, la voix personnalisée. Pourtant, le droit d’utiliser un travail protégé par un copyright à cet effet n’est pas bien établi. Microsoft ne peut pas fournir de conseils juridiques à ce sujet ; consultez votre propre conseiller juridique.
Heureusement, il est possible d’éviter totalement ces problèmes. Il existe de nombreuses sources de texte que vous pouvez utiliser sans licence ou autorisation.
| Source du texte | Descriptif |
|---|---|
| Corpus CMU Arctic | Environ 1 100 phrases sélectionnées provenant d’œuvres libres de droits et destinées spécifiquement à des projets de synthèse vocale. C’est un excellent point de départ. |
| Œuvres libres de droits |
Il s’agit en général, d’œuvres publiées avant 1923. En anglais, le projet Gutenberg propose des dizaines de milliers de ces œuvres. Vous pouvez vous concentrer sur des œuvres plus récentes car leur contenu est plus proche de l’anglais moderne. |
| Œuvres gouvernementales | Les œuvres créées par l’état fédéral des États-Unis ne sont pas soumises au droit d’auteur, mais cela peut être le cas dans d’autres pays/régions. |
| Domaine public | Œuvres pour lesquelles le droit d’auteur est explicitement exclu ou dédié au domaine public. Certaines juridictions interdisent tout renoncement total au droit d’auteur. |
| Œuvres cédées sous licence | Œuvres distribuées sous licence comme Creative Commons ou la Licence de documentation libre GNU (GFDL). Wikipédia utilise une licence GFDL. Toutefois, certaines licences peuvent imposer des restrictions sur les performances du contenu sous licence susceptibles d’affecter la création d’un modèle vocal personnalisé. Lisez donc attentivement la licence. |
Enregistrement de votre script
Enregistrez votre script dans un studio d’enregistrement professionnel spécialisé dans le travail de la voix. Ce type de studio est équipé d’une cabine d’enregistrement, d’un équipement approprié et d’un personnel compétent formé à son utilisation. Il est recommandé de ne pas lésiner sur l’enregistrement.
Discutez de votre projet avec l’ingénieur du son chargé de l’enregistrement et écoutez ses conseils. L’enregistrement doit avoir peu voire aucune compression de plage dynamique (maximum 4:1). Il est essentiel que l’audio affiche un volume homogène et un rapport signal/bruit élevé, tout en étant exempt de sons parasites.
Exigences en matière d’enregistrement
Pour obtenir des résultats de haute qualité en termes d’apprentissage, respectez les conditions suivantes lors de l’enregistrement ou de la préparation des données :
Clair et bien prononcé
Vitesse naturelle : pas trop lente ou trop rapide entre les fichiers audio.
Volume, prosodie et pause appropriés : stabilité dans la même phrase ou entre les phrases, pause correcte pour la ponctuation.
Aucun bruit lors de l’enregistrement
Ajuster à votre conception de personnage
Pas d’accent incorrect : ajuster à la conception cible
Aucune prononciation incorrecte
Vous pouvez vous référer à la spécification ci-dessous pour préparer les échantillons audio en tant que meilleure pratique.
| Propriété | Valeur |
|---|---|
| Format de fichier | *.wav, Mono |
| Taux d’échantillonnage | 24 kHz |
| Format d’échantillonnage | 16 bits, PCM |
| Niveaux de volume de pointe | -3 dB à -6 dB |
| SNR | >35 dB |
| Silence | -Il doit y avoir un silence (recommandé de 100 ms) au début et à la fin, mais pas plus de 200 ms – Silence entre des mots ou des expressions <-30 dB – Silence dans l’onde après le dernier mot prononcé <-60 dB |
| Bruit ambiant ou écho | – Le niveau de bruit au début de l’onde avant de parler < -70 dB |
Remarque
Vous pouvez enregistrer à une fréquence d’échantillonnage et une profondeur de bits plus élevées, par exemple au format PCM 48 kHz 24 bits. Pendant le réglage précis de l’audio professionnel, nous allons l’échantillonner à 24 KHz 16 bits PCM automatiquement.
Un rapport signal/bruit (SNR) supérieur indique un bruit plus faible dans votre contenu audio. Vous pouvez généralement atteindre un SNR supérieur à 35 en effectuant les enregistrements dans un studio professionnel. Un contenu audio dont le SNR est inférieur à 20 peut entraîner un niveau de bruit conséquent dans la voix générée.
N’hésitez pas à réenregistrer les énoncés affichant un faible score de prononciation ou un mauvais ratio signal / bruit. Si vous ne pouvez pas réenregistrer, envisagez d’exclure ces énoncés de vos données.
Erreurs audio typiques
Pour obtenir des résultats d’apprentissage de haute qualité, il est fortement recommandé d’éviter les erreurs audio. Les erreurs audio se classent généralement dans les catégories suivantes :
Le fichier audio ne correspond pas à l’ID de script.
Le format du fichier WAR est illisible et non valide.
Le taux d’échantillonnage audio est inférieur à 16 KHz. Il est recommandé que le taux d’échantillonnage du fichier .wav soit supérieur ou égal à 24 kHz pour une voix neuronale de haute qualité.
La valeur maximale du volume n’est pas comprise entre -3 dB (70 % du volume maximal) et -6 dB (50 %).
Dépassement de la forme d’onde : la forme d’onde est coupée à sa valeur maximale, et donc incomplète.
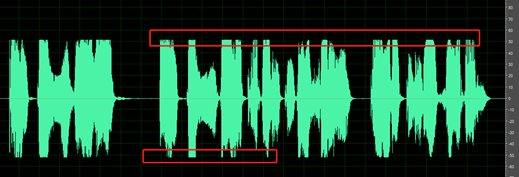
Les parties silencieuses de l’enregistrement ne sont pas propres ; vous pouvez entendre des sons tels que le bruit ambiant, des bruits de bouche et de l’écho.
Par exemple, l’audio ci-dessous contient le bruit ambiant entre les énoncés.
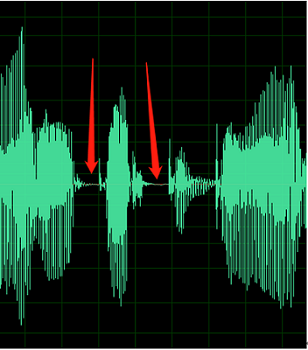
L’exemple ci-dessous contient des signes de décalage DC ou d’écho.
Le volume global est trop faible. Vos données sont marquées comme un problème si le volume est inférieur à-18 dB (10 % du volume maximal). Assurez-vous que tous les fichiers audio soient au même niveau de volume.
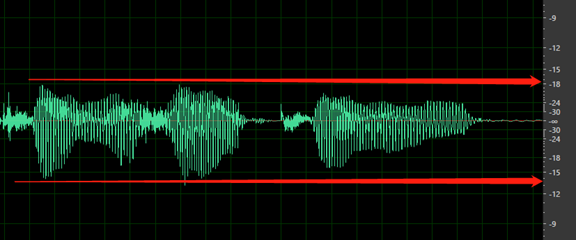
Aucun silence avant le premier mot ou après le dernier mot. En outre, le silence de début ou de fin ne doit pas être supérieur à 200 ms ou inférieur à 100 ms.
Faites-le vous-même
Si vous voulez effectuer vous-même l’enregistrement au lieu de faire appel à un studio d’enregistrement, voici quelques conseils pour bien démarrer. Avec la popularité croissante des enregistrements à domicile et des podcasts, il est plus facile que jamais de trouver des conseils et des ressources en ligne pour réussir ses enregistrements.
Pour votre cabine d’enregistrement, choisissez une petite pièce, sans écho notable ni « tonalité de pièce ». Elle doit être aussi silencieuse et insonorisée que possible. Vous pouvez fixer aux murs des rideaux afin de réduire l’écho et de neutraliser ou d’étouffer le son de la pièce.
Utilisez un microphone à condenseur studio de haute qualité (un « micro » pour faire plus court) adapté à l’enregistrement vocal. Les micros Sennheiser, AKG voire les derniers modèles Zoom produisent de bons résultats. Vous pouvez acheter un micro ou en louer un dans une entreprise de location de matériel audio-vidéo. Recherchez un modèle doté d’une interface USB. Ce type de micro combine de façon optimale un microphone, un préampli et un convertisseur analogique-numérique, ce qui simplifie la connexion.
Vous pouvez également utiliser un microphone analogique. De nombreuses entreprises de location proposent des microphones « vintage » réputés pour la qualité de la voix qu’ils reproduisent. Un système analogique professionnel utilise des connecteurs XLR équilibrés plutôt que les prises d’un quart de pouce (1/4”) dont sont équipés les systèmes grand public. Si vous optez pour un système analogique, vous aurez également besoin d’un préampli et d’une interface audio pour ordinateur avec ces connecteurs.
Installez le microphone sur un support ou sur un pied, puis placez un filtre anti-pop devant le microphone pour supprimer le bruit des consonnes occlusives comme « p » et « b ». Certains microphones sont munis d’un système de suspension qui les isole des vibrations du support, ce qui est utile.
L’acteur doit se tenir à une distance constante du microphone. Collez sur le sol des bandes pour lui indiquer la position idéale. S’il préfère travailler assis, surveillez tout particulièrement la distance par rapport au micro et évitez tout bruit de chaise.
Posez le script sur un pupitre. Évitez toute inclinaison de pupitre qui risquerait de réverbérer le son vers le microphone.
La personne qui commande l’équipement (l’ingénieur du son) doit se trouver dans un local distinct de la cabine d’enregistrement où se trouve l’acteur, et disposer d’un moyen de communiquer avec lui (circuit d’ordre).
L’enregistrement doit contenir le moins de bruit possible, avec un objectif de -80 dB.
Écoutez attentivement l’enregistrement d’un silence dans votre cabine et identifiez la source des éventuels bruits afin de les supprimer. Les sources courantes de bruit sont les orifices de ventilation, les ballasts de néons, la circulation environnante et les ventilateurs des équipements (même un petit notebook peut avoir des ventilateurs). Les microphones et les câbles peuvent générer un bruit électrique (un bourdonnement ou un sifflement) s’ils sont placés à proximité d’une climatisation. Un bourdonnement peut également être dû à une boucle de masse, présente quand un appareil est raccordé à plusieurs circuits électriques.
Conseil
Dans certains cas, vous pouvez utiliser un égaliseur ou un plug-in logiciel de réduction du bruit pour éliminer le bruit de vos enregistrements, même s’il est toujours préférable de le supprimer à sa source.
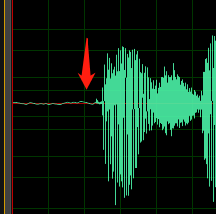
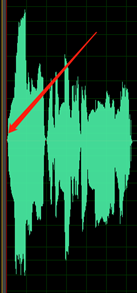
Réglez les niveaux afin d’utiliser au maximum la plage dynamique disponible de l’enregistrement numérique sans saturation. Cela signifie que vous devez régler le son à un niveau élevé, mais pas si élevé qu’il en devient déformé. L’image suivante montre un exemple de forme d’onde d’un bon enregistrement :
Ici, la majeure partie de la plage (hauteur) est utilisée, mais les pics les plus élevés du signal n’atteignent pas le haut ou le bas de la fenêtre. Vous pouvez également constater que la latence dans l’enregistrement ressemble à une fine ligne horizontale, indiquant un faible niveau de bruit. Cet enregistrement comporte une plage dynamique et un rapport signal/bruit acceptables.
Enregistrez directement sur l’ordinateur par le biais d’une interface audio de haute qualité ou d’un port USB, en fonction du micro que vous utilisez. Pour un système analogique, gardez une chaîne audio simple : micro, préampli, interface audio, ordinateur. Vous pouvez acheter à un prix raisonnable une licence des logiciels Avid Pro Tools et Adobe Audition. Si votre budget est extrêmement serré, essayez la version gratuite d’Audacity.
Effectuez un enregistrement de type 44,1 kHz 16 bits monophonique (qualité CD) ou plus. Si votre équipement le permet, utilisez un échantillonnage 48 kHz 24 bits pour obtenir un son exceptionnel. Vous réduisez l’échantillonnage à 24 kHz 16 bits avant de l’envoyer à Speech Studio. Mais il est préférable de disposer d’un enregistrement original de haute qualité, si des modifications s’avèrent nécessaires.
Dans l’idéal, différentes personnes occupent les rôles de directeur, ingénieur du son et acteur. N’essayez pas de tout faire vous-même. Faute de mieux, une même personne peut endosser le costume de directeur et d’ingénieur du son.
Avant la session
Pour éviter toute perdre de temps au studio, parcourez le script avec votre acteur avant la session d’enregistrement. À mesure qu’il se familiarise avec le texte, l’acteur apprend à prononcer correctement les éventuels mots inconnus.
Remarque
La plupart des studios d’enregistrement sont équipés d’un écran électronique pour afficher les scripts dans la cabine d’enregistrement. Dans ce cas, saisissez vos notes directement dans le document du script. Mais conservez une copie papier pour prendre des notes pendant la session. Les ingénieurs du son demandent aussi souvent une copie papier. Et gardez toujours une troisième copie imprimée en secours pour l’acteur, au cas où l’ordinateur tombe en panne.
L’acteur vous demandera parfois de lui préciser le mot à mettre en relief dans un énoncé (« mot opérationnel »). Dites-lui que vous souhaitez une lecture naturelle, sans mise en relief particulière. Une mise en relief peut être ajoutée lorsque la reconnaissance vocale est synthétisée : elle ne doit pas faire partie de l’enregistrement d’origine.
Demandez à l’acteur de prononcer distinctement tous les mots. Chaque mot du script doit être prononcé. Aucun son ne doit être omis ou avalé, comme c’est souvent le cas dans une conversation informelle, sauf si le script a été écrit dans ce sens.
| Texte écrit | Prononciation informelle indésirable |
|---|---|
| ne vous abandonnera jamais | ne vous abandonnera jamais |
| il y a quatre lumières | il y a quatre lumières |
| comment est la météo aujourd’hui | comment est la météo aujourd’hui |
| dire bonjour à mon petit ami | Dis bonjour à mon petit ami |
L’acteur ne doit pas ajouter de pause entre chaque mot. La phrase doit toujours être prononcée de façon naturelle, même si elle sonne un peu formelle. La maîtrise de cette nuance peut demander du temps.
La session d'enregistrement
Créez un enregistrement de référence, ou fichier de correspondance, d’un énoncé standard en début de session. Demandez à l’acteur de répéter cette ligne à chaque page environ. À chaque fois, comparez le nouvel enregistrement et la référence. Cet exercice aide l’acteur à conserver un niveau constant de volume, de tempo et d’intonation. Pendant ce temps, l’ingénieur du son peut utiliser le fichier de correspondance comme référence pour les niveaux et l’homogénéité globale du son.
Le fichier de correspondance est particulièrement important pour reprendre l’enregistrement après une pause ou à une date ultérieure. Jouez plusieurs fois ce fichier à l’acteur afin de le faire répéter, jusqu’à ce que les deux versions se ressemblent.
Pour enregistrer un corpus avec un style spécifique, choisissez soigneusement les scripts qui présentent le style souhaité. Pendant l’enregistrement, assurez-vous que l’artiste vocal reste cohérent en ce qui concerne le volume, le tempo, la tonalité et le ton pour obtenir des enregistrements qui incarnent le style prévu.
Demandez à l’acteur de respirer profondément et de faire une pause avant chaque énoncé. Enregistrez quelques secondes de silence entre les énoncés. Les mots doivent être prononcés de la même façon chaque fois qu’ils apparaissent, en prenant en compte le contexte.
Enregistrez environ cinq secondes de silence avant le premier enregistrement pour capturer la « tonalité de la pièce ». Cette pratique permet à Speech Studio d’atténuer les bruits parasites.
Conseil
Comme vous avez avant tout besoin de l’artiste vocal, vous pouvez effectuer un enregistrement monophonique (monocanal) de ces lignes. Mais s’il s’agit d’un enregistrement en stéréo, vous pouvez utiliser le second canal pour capturer le son provenant de la salle de contrôle et écouter ainsi les discussions concernant des lignes ou des prises particulières. Supprimez cette piste de la version chargée dans Speech Studio.
Écoutez attentivement, à l’aide d’un casque, les enregistrements de la voix professionnelle. Vous devez obtenir une diction naturelle et une prononciation claire, sans bruits parasites. N’hésitez pas à demander à l’acteur de répéter un énoncé, si vous estimez que ces critères ne sont pas remplis.
Conseil
Si vous utilisez un grand nombre d’énoncés, un seul énoncé peut ne pas avoir d’effet notable sur la voix personnalisée résultante. Il peut être plus rapide de noter simplement les énoncés avec des problèmes, de les exclure de votre jeu de données et de voir comment votre voix personnalisée s’avère. Vous pouvez toujours revenir au studio et enregistrer les exemples manqués ultérieurement.
Pour chaque énoncé, notez sur le script le numéro de la prise ou le code temporel. Demandez également à l’ingénieur du son de marquer si possible chaque énoncé dans les métadonnées ou le « cue sheet » de l’enregistrement.
Faites régulièrement des pauses et proposez une boisson à l’acteur pour maintenir une bonne qualité de voix.
Après la session
Les studios d’enregistrement modernes travaillent sur ordinateur. À la fin de la session, vous recevez un ou plusieurs fichiers audio, pas une bande. Ces fichiers sont probablement au format WAV ou AIFF en qualité CD (44,1 kHz 16 bits) ou plus. Un échantillonnage 24 kHz 16 bits est courant et recommandé. Le taux d’échantillonnage par défaut d’une voix personnalisée est de 24 KHz. Nous vous recommandons d’utiliser un taux d’échantillonnage de 24 kHz ou supérieur pour vos données d’apprentissage. Les taux d’échantillonnage plus élevés, par exemple 96 kHz, ne sont généralement pas nécessaires.
Avec Speech Studio, chaque énoncé fourni doit être dans son propre fichier. Chaque fichier audio fourni par le studio contient plusieurs énoncés. Par conséquent, la principale tâche de post-production consiste à diviser les enregistrements et à les préparer pour l’envoi. L’ingénieur du son de l’enregistrement peut avoir placé des marqueurs dans le fichier (ou créé un « cue sheet » distinct) pour indiquer où chaque énoncé commence.
Utilisez vos notes pour identifier exactement vos prises, puis un utilitaire de montage comme Avid Pro Tools, Adobe Audition ou la version gratuite d’Audacity pour copier chaque énoncé dans un nouveau fichier.
Écoutez attentivement chaque fichier. À ce stade, vous pouvez modifier les petits sons indésirables que vous avez manqués pendant l’enregistrement, par exemple un léger bruit de bouche avant une ligne, mais veillez à ne pas supprimer l’énoncé. Si vous ne pouvez pas corriger un fichier, supprimez-le de votre jeu de données et prenez note de cette opération.
Convertissez chaque fichier au format 16 bits et à un taux d’échantillonnage de 24 kHz ou supérieur avant l’enregistrement et, si vous avez enregistré les conversations du studio, supprimez le second canal. Enregistrez chaque fichier au format WAV, puis nommez les fichiers à l’aide des numéros d’énoncé de votre script.
Pour finir, créez la transcription qui associe chaque fichier WAV à une version texte de l’énoncé correspondant. La section Entraîner votre modèle vocal comprend les détails relatifs au format nécessaire. Vous pouvez copier le texte directement à partir de votre script. Créez ensuite un fichier Zip contenant les fichiers WAV et la transcription du texte.
Archivez les enregistrements originaux dans un endroit sûr afin de pouvoir les réutiliser ultérieurement si nécessaire. Conservez également votre script et vos notes.
Étapes suivantes
Vous êtes prêt à charger vos enregistrements et à créer votre voix personnalisée.