Vue d’ensemble de la mise à l’échelle automatique de cluster dans Azure Kubernetes Service (AKS)
Pour suivre le rythme des demandes applicatives d’Azure Kubernetes Service (ACS), vous devrez sans doute ajuster le nombre de nœuds qui exécutent vos charges de travail. Le composant de mise à l’échelle automatique de cluster peut surveiller les pods de votre cluster qui ne peuvent pas être planifiés en raison de contraintes de ressources. Lorsque la mise à l’échelle automatique détecte des pods non planifiés, elle augmente le nombre de nœuds dans le pool de nœuds pour répondre à la demande de l’application. Les nœuds sont également régulièrement vérifiés. En l’absence de pods planifiés, le nombre de nœuds est réduit au besoin.
Cet article vous aide à comprendre le fonctionnement de l’autoscaler de cluster dans AKS. Il fournit également de l’aide, des bonnes pratiques et des considérations pour la configuration de l’autoscaler de cluster pour vos charges de travail AKS. Si vous souhaitez activer, désactiver ou mettre à jour l’autoscaler de cluster pour vos charges de travail AKS, consultez Utiliser l’autoscaler de cluster dans AKS.
À propos du programme de mise à l’échelle automatique de cluster
Les clusters ont souvent besoin d’un moyen de se mettre à l’échelle automatiquement pour s’ajuster au changement des demandes d’application, comme hors des heures de travail et les soirées ou les week-ends. Les clusters AKS peuvent être mis à l’échelle des manières suivantes :
- Le programme de mise à l’échelle automatique de cluster vérifie régulièrement les pods qui ne peuvent pas être planifiés sur les nœuds en raison de contraintes de ressources. Le cluster augmente alors automatiquement le nombre de nœuds. La mise à l’échelle manuelle est désactivée lorsque vous utilisez le programme de mise à l’échelle automatique de cluster. Pour plus d’informations, consultez Comment le scale-up fonctionne-t-il ?.
- Le programme de mise à l’échelle automatique de pods élastique utilise le serveur de mesures d’un cluster Kubernetes pour surveiller la demande en ressources de pods. Si une application a besoin de davantage de ressources, le nombre de pods est automatiquement augmenté pour répondre à la demande.
- L’autoscaler de pod vertical définit automatiquement les demandes de ressources et les limites sur les conteneurs par charge de travail en fonction de l’utilisation passée pour garantir que les pods sont planifiés sur les nœuds qui disposent des ressources de processeur et de mémoire requises.
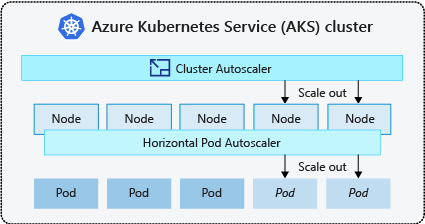
Il est courant d’activer l’autoscaler de cluster pour les nœuds, ainsi que l’autoscaler de pod vertical ou l’autoscaler de pod horizontal pour les pods. Quand vous activez la mise à l’échelle automatique de cluster, elle applique les règles de mise à l’échelle spécifiées si la taille du pool de nœuds est inférieure au nombre de nœuds minimum, jusqu’au nombre de nœuds maximum. L’autoscaler de cluster attend, pour prendre effet, qu’un nouveau nœud soit nécessaire dans le pool de nœuds ou qu’un nœud puisse être supprimé de manière sécurisée du pool de nœuds actuel. Pour plus d’informations, consultez Comment le scale-down fonctionne-t-il ?
Meilleures pratiques et considérations
- Lors de l’implémentation de zones de disponibilité avec l’autoscaler de cluster, nous vous recommandons d’utiliser un pool de nœuds unique pour chaque zone. Vous pouvez définir le paramètre
--balance-similar-node-groupssurTruepour maintenir une distribution équilibrée des nœuds entre les zones de vos charges de travail pendant les opérations de scale-up. Lorsque cette approche n’est pas implémentée, les opérations de scale-down peuvent perturber l’équilibre des nœuds entre les zones. - Pour les clusters avec plus de 400 nœuds, nous vous recommandons d’utiliser Azure CNI ou Superposition Azure CNI.
- Pour exécuter efficacement des charges de travail simultanément sur des pools de nœuds Spot et fixes, envisagez d’utiliser des développeurs prioritaires. Cette approche vous permet de planifier des pods en fonction de la priorité du pool de nœuds.
- Faites preuve de prudence lors de l’attribution de requêtes de processeur/mémoire sur des pods. L’autoscaler de cluster effectue un scale-up en fonction des pods en attente plutôt que de la pression du processeur/de la mémoire sur les nœuds.
- Pour les clusters hébergeant simultanément des charges de travail longues, comme des applications web, et des charges de travail courtes/rafales, nous vous recommandons de les séparer en pools de nœuds distincts avec des développeurs de règles d’affinité/ ou d’utiliser PodDisruptionBudget pour éviter les opérations inutiles de drainage ou de scale-down des nœuds. La spécification de l’annotation cluster-autoscaler.kubernetes.io/safe-to-evict: "false" sur la spécification de pod empêche également la suppression des pods. Utilisez cette annotation avec précaution, car elle peut entraîner des problèmes de mise à l’échelle automatique du cluster quand un nœud est drainé et qu’un pod en cours d’exécution comprend cette annotation.
- Dans un pool de nœuds avec autoscaler, effectuez un scale-down des nœuds en supprimant des charges de travail, au lieu de réduire manuellement le nombre de nœuds. Cela peut être problématique si le pool de nœuds est déjà à capacité maximale ou s’il existe des charges de travail actives s’exécutant sur les nœuds, ce qui peut entraîner un comportement inattendu par la mise à l’échelle automatique de cluster.
- Les nœuds ne sont pas mis à l’échelle si les pods ont une valeur PriorityClass inférieure à -10. La priorité -10 est réservée aux pods en surapprovisionnement. Pour plus d’informations, consultez Utilisation de l’autoscaler de cluster avec la priorité et la préemption de pod.
- Ne combinez pas d’autres mécanismes de mise à l’échelle automatique de nœud, tels que les autoscalers de groupe de machines virtuelles identiques, avec l’autoscaler de cluster.
- L’autoscaler de cluster ne pourra sans doute pas effectuer un scale-down si les pods ne peuvent pas être déplacés, notamment dans les situations suivantes :
- Un pod créé directement et non pris en charge par un objet de contrôleur, par exemple, un déploiement ou un jeu de réplicas.
- Un budget d’interruption de pods (PDB) qui est trop restrictif et n’autorise pas la diminution du nombre de pods en dessous d’un certain seuil.
- Un pod utilise des sélecteurs de nœud ou l’anti-affinité qui ne peuvent pas être respectés s’ils sont planifiés sur un autre nœud. Pour plus d'informations, consultez Quels types de pods peuvent empêcher l’autoscaler de cluster de supprimer un nœud ?.
Important
N’apportez pas de modifications aux nœuds individuels dans les pools de nœuds automatiquement mis à l’échelle. Tous les nœuds du même groupe de nœuds doivent avoir une capacité uniforme, des étiquettes, des teintes et des pods système qui s’exécutent sur eux.
- Le générateur de mise à l’échelle automatique du cluster n’est pas responsable de l’application d’un « nombre maximal de nœuds » dans un pool de nœuds de cluster, quelle que soit la planification des pods. Si un acteur non-cluster de mise à l’échelle automatique définit le nombre de pools de nœuds sur un nombre au-delà du nombre maximal configuré du générateur de mise à l’échelle automatique du cluster, le générateur de mise à l’échelle automatique du cluster ne supprime pas automatiquement les nœuds. Les comportements de scale-down de la mise à l’échelle automatique du cluster restent limités à la suppression de nœuds qui n’ont aucun pod planifié. L’objectif unique de la configuration maximale du nombre de nœuds du cluster est d’appliquer une limite supérieure pour les opérations de scale-up. Elle n’a aucun effet sur les considérations relatives au scale-down.
Profil d’autoscaler de cluster
Le profil d’autoscaler de cluster est un ensemble de paramètres qui contrôlent le comportement de l’autoscaler de cluster. Vous pouvez configurer le profil d’autoscaler de cluster lorsque vous créez un cluster ou mettez à jour un cluster existant.
Optimisation du profil d’autoscaler de cluster
Vous devez affiner les paramètres de profil d’autoscaler de cluster en fonction de vos scénarios de charge de travail spécifiques tout en tenant compte des compromis entre les performances et les coûts. Cette section fournit des exemples illustrant ces compromis.
Il est important de noter que les paramètres de profil d’autoscaler de cluster sont à l’échelle du cluster et appliqués à tous les pools de nœuds avec mise à l’échelle automatique. Toutes les actions de mise à l’échelle qui se produisent dans un pool de nœuds peuvent affecter le comportement de mise à l’échelle automatique d’autres pools de nœuds, ce qui peut entraîner des résultats inattendus. Veillez à appliquer des configurations de profil cohérentes et synchronisées sur tous les pools de nœuds pertinents pour vous assurer d’obtenir les résultats souhaités.
Exemple 1 : optimisation des performances
Pour les clusters qui gèrent des charges de travail substantielles et en rafale avec un focus principal sur les performances, nous vous recommandons d’augmenter scan-interval et de diminuer scale-down-utilization-threshold. Ces paramètres permettent de traiter plusieurs opérations de mise à l’échelle en un seul appel, d’optimiser le temps de mise à l’échelle et d’utiliser des quotas de lecture/écriture de calcul. Il permet également d’atténuer le risque d’opérations de scale-down rapides sur des nœuds sous-utilisés, ce qui améliore l’efficacité de la planification des pods. Augmentez également ok-total-unready-count et max-total-unready-percentage.
Pour les clusters avec des pods daemonset, nous vous recommandons de définir ignore-daemonsets-utilization sur true, ce qui ignore efficacement l’utilisation des nœuds par les pods daemonset et réduit les opérations de scale-down inutiles. Voir Profil des charges de travail en rafale
Exemple 2 : optimisation du coût
Si vous souhaitez un profil optimisé pour les coûts, nous vous recommandons de définir les configurations de paramètres suivantes :
- Réduisez
scale-down-unneeded-time, c’est-à-dire le temps pendant lequel un nœud doit être inutilisé avant qu’il ne soit éligible à un scale-down. - Réduisez
scale-down-delay-after-add, c’est-à-dire le temps d’attente après l’ajout d’un nœud avant de l’envisager pour un scale-down. - Augmentez
scale-down-utilization-threshold, c’est-à-dire le seuil d’utilisation pour supprimer des nœuds. - Augmentez
max-empty-bulk-delete, c’est-à-dire le nombre maximal de nœuds qui peuvent être supprimés dans un seul appel. - Définissez
skip-nodes-with-local-storagesur false. - Augmenter
ok-total-unready-countetmax-total-unready-percentage.
Problèmes courants et recommandations en matière d’atténuation
Affichez les échecs de mise à l’échelle et les événements de scale-up non déclenchés par le biais de l’interface CLI ou du portail.
Opérations de scale-up qui ne se déclenchent pas
| Causes courantes | Recommandations en matière d’atténuation |
|---|---|
| Conflits d’affinité de nœud PersistentVolume, qui peuvent survenir lors de l’utilisation de l’autoscaler de cluster avec plusieurs zones de disponibilité ou lorsque la zone d’un pod ou du volume persistant diffère de la zone du nœud. | Utilisez un pool de nœuds par zone de disponibilité et activez --balance-similar-node-groups. Vous pouvez également définir le champ volumeBindingMode sur WaitForFirstConsumer dans la spécification du pod pour empêcher le volume d’être lié à un nœud jusqu’à la création d’un pod utilisant le volume. |
| Conflits d’affinité entre l’affinité de nœud/les teintes et tolérances | Évaluez les teintes affectées à vos nœuds et passez en revue les tolérances définies dans vos pods. Si nécessaire, ajustez les teintes et les tolérances pour vous assurer que vos pods peuvent être planifiés efficacement sur vos nœuds. |
Échecs d’opération de scale-up
| Causes courantes | Recommandations en matière d’atténuation |
|---|---|
| Épuisement des adresses IP dans le sous-réseau | Ajoutez un autre sous-réseau dans le même réseau virtuel et ajoutez un autre pool de nœuds dans le nouveau sous-réseau. |
| Épuisement du quota de base | Le quota de base approuvé a été épuisé. Demandez une augmentation du quota. L’autoscaler de cluster entre dans un état de backoff exponentiel dans le groupe de nœuds spécifique lorsqu’il rencontre plusieurs tentatives de scale-up ayant échoué. |
| Taille maximale du pool de nœuds | Augmentez les nœuds max sur le pool de nœuds ou créez un pool de nœuds. |
| Demandes/appels dépassant la limite de débit | Consultez Erreurs 429 Trop de demandes. |
Échecs d’opération de scale-down
| Causes courantes | Recommandations en matière d’atténuation |
|---|---|
| Pod empêchant le drainage de nœud/Impossible d’éliminer le pod | • Affichez les types de pods qui peuvent empêcher le scale-down. • Pour les pods utilisant le stockage local, tel que hostPath et emptyDir, définissez l’indicateur de profil d’autoscaler de cluster skip-nodes-with-local-storage sur false. • Dans la spécification du pod, définissez l’annotation cluster-autoscaler.kubernetes.io/safe-to-evict sur true. • Vérifiez votre PDB, car il est peut-être restrictif. |
| Taille minimale du pool de nœuds | Réduisez la taille minimale du pool de nœuds. |
| Demandes/appels dépassant la limite de débit | Consultez Erreurs 429 Trop de demandes. |
| Opérations d’écriture verrouillées | N’apportez aucune modification au groupe de ressources AKS complètement managé (consultez Stratégies de prise en charge AKS). Supprimez ou réinitialisez les verrous de ressources que vous avez précédemment appliqués au groupe de ressources. |
Autres problèmes
| Causes courantes | Recommandations en matière d’atténuation |
|---|---|
| PriorityConfigMapNotMatchedGroup | Veillez à ajouter tous les groupes de nœuds nécessitant une mise à l’échelle automatique au fichier de configuration du développeur. |
Pool de nœuds en backoff
Le pool de nœuds en backoff a été introduit dans la version 0.6.2 et entraîne la mise à l’échelle automatique du cluster à partir de la mise à l’échelle d’un pool de nœuds après une défaillance.
Selon la durée pendant laquelle les opérations de mise à l’échelle ont rencontré des défaillances, il peut s’écouler jusqu’à 30 minutes avant une autre tentative. Vous pouvez réinitialiser l’état de backoff du pool de nœuds en désactivant puis en réactivant la mise à l’échelle automatique.

Azure Kubernetes Service