Qu’est-ce que l’observabilité du réseau Azure Kubernetes Service (AKS) ?
Kubernetes est un outil puissant qui permet de gérer les applications conteneurisées. Plus les environnements conteneurisés deviennent complexes, plus il peut être difficile d’identifier et de résoudre les problèmes de mise en réseau dans un cluster Kubernetes.
L’observabilité du réseau est une partie importante de la maintenance d’un cluster Kubernetes sain et performant. En collectant et en analysant des données sur le trafic réseau, vous pouvez obtenir des insights sur le fonctionnement de votre cluster et identifier les problèmes potentiels avant qu’ils ne provoquent des pannes ou une détérioration des performances.
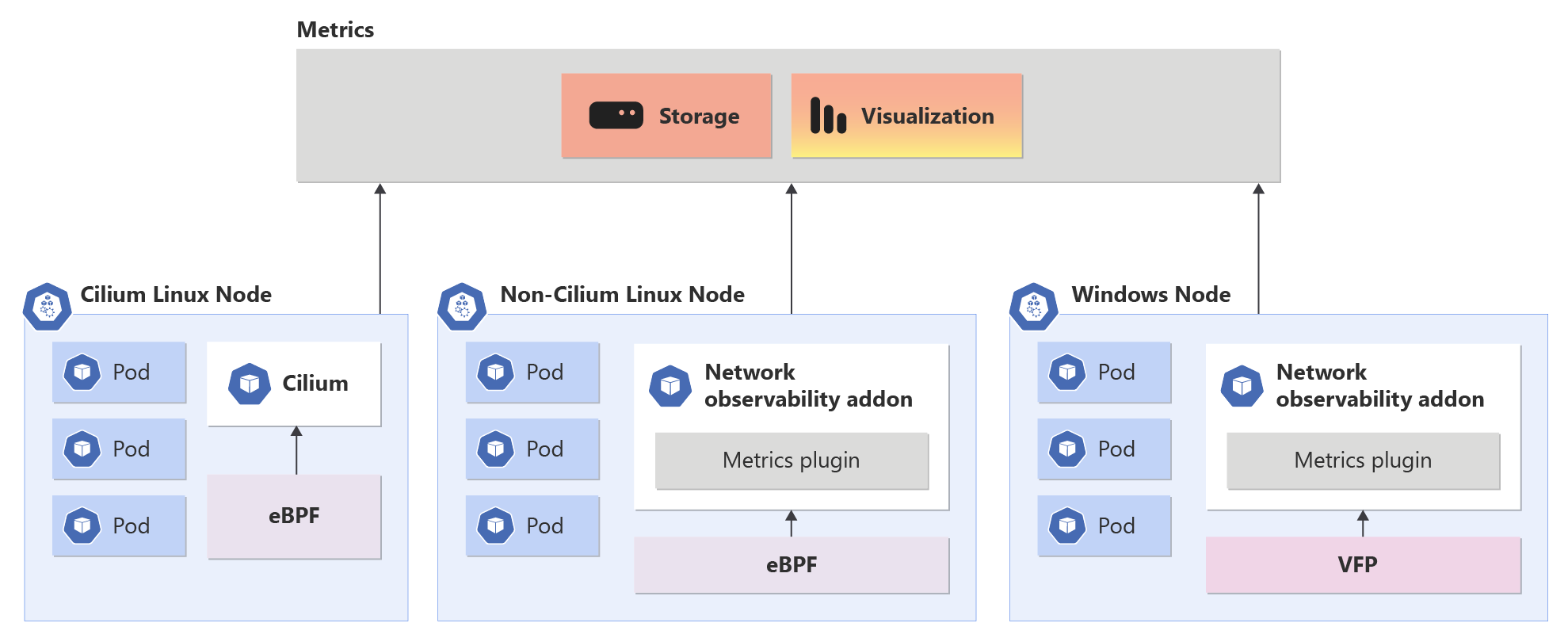
Vue d’ensemble du module complémentaire d’observabilité du réseau dans AKS
Le module complémentaire d’observabilité du réseau fonctionne en toute transparence sur les plans de données Cilium et non-Cilium. Il offre aux clients des fonctionnalités de niveau entreprise pour DevOps et SecOps. Cette solution permet aux administrateurs réseau de cluster, aux administrateurs de sécurité de cluster et aux ingénieurs DevOps de disposer d’un moyen centralisé pour surveiller les problèmes réseau dans votre cluster.
Quand le module complémentaire d’observabilité du réseau est activé, il permet la collecte et la conversion de mesures utiles au format Prometheus, qui peuvent ensuite être visualisées dans Grafana. Azure propose des offres pour Prometheus et Grafana managés.
Prometheus et Grafana managés par Azure : service managé fourni par Azure, prenant en charge l’infrastructure et la maintenance de Prometheus et de Grafana, ce qui vous permet de vous concentrer sur la configuration et la visualisation de vos métriques.
Prise en charge de plusieurs interfaces réseau de conteneur : le module complémentaire Observabilité du réseau prend en charge les plug-ins réseau Azure CNI et Kubenet.
Métriques
Le module complémentaire d’observabilité du réseau ne prend actuellement en charge que les mesures au niveau des nœuds. Les plans de données Cilium et Non-Cilium ont des métriques différentes, mais le tableau de bord Grafana fonctionne parfaitement pour les deux.
Toutes les mesures présentent les étiquettes suivantes :
clusterinstance(Nom du nœud)
Sur le plan de données Non-Cilium, le module complémentaire d’observabilité du réseau fournit des mesures sur les plateformes Linux et Windows. La table ci-dessous présente les différentes mesures générées.
| Nom de métrique | Description | Étiquettes supplémentaires | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Nombre total de paquets transférés | direction |
✅ | ✅ |
| networkobservability_forward_bytes | Nombre total d’octets transférés | direction |
✅ | ✅ |
| networkobservability_drop_count | Nombre total de paquets ignorés | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | Nombre total d’octets ignorés | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | Nombre de sockets TCP actuellement actifs par état TCP. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | Nombre de sockets TCP actuellement actifs par adresse IP/port distant. | address (IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | Statistiques de la connexion TCP (ex. : Delayed ACKs, TCPKeepAlive, TCPSackFailures) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | Nombre de paquets TCP par indicateur | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | Statistiques de la connexion IP | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | Statistiques de la connexion UDP | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | Nombre de sockets TCP actuellement actifs pour UDP | ✅ | ❌ | |
| networkobservability_interface_stats | Statistiques de l’interface. | InterfaceName, statistic |
✅ | ✅ |
Limites
- Les mesures au niveau du pod ne sont pas prises en charge.
Scale
Certaines limitations de mise à l’échelle s’appliquent quand vous utilisez Prometheus et Grafana gérés par Azure. Pour plus d’informations, consultez l’article Supprimer les métriques Prometheus à grande échelle dans Azure Monitor.
Étapes suivantes
Pour plus d’informations sur Azure Kubernetes Service (AKS), consultez l’article Qu’est-ce qu’Azure Kubernetes Service (AKS) ?.
Pour créer un cluster AKS disposant de l’observabilité du réseau et de Prometheus et Grafana managés par Azure, consultez l’article Configurer l’observabilité du réseau pour Azure Kubernetes Service (AKS) – Prometheus et Grafana managés par Azure.

Azure Kubernetes Service