Antimodèle E/S bavardes
L’effet cumulatif d’un grand nombre de demandes d’E/S peut avoir un impact significatif sur les performances et la réactivité.
Description du problème
Les appels réseau et les autres opérations d’E/S sont lents par nature si on les compare aux tâches de calcul. Chaque demande d’E/S a généralement une surcharge significative, et l’effet cumulatif de nombreuses opérations d’E/S peut ralentir le système. Voici certaines causes courantes d’E/S bavardes.
Lecture et écriture d’enregistrements individuels dans une base de données sous forme de demandes distinctes
L’exemple suivant lit à partir d’une base de données de produits. Il existe trois tables Product, ProductSubcategory, et ProductPriceListHistory. Le code récupère tous les produits d’une sous-catégorie, ainsi que les informations de tarification, en exécutant une série de requêtes :
- Interrogation de la sous-catégorie à partir de la table
ProductSubcategory. - Recherche de tous les produits de cette sous-catégorie en interrogeant la table
Product. - Pour chaque produit, interrogation des données de tarification à partir de la table
ProductPriceListHistory.
L’application utilise Entity Framework pour interroger la base de données. Vous trouverez l’exemple complet ici.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Cet exemple illustre le problème explicitement, mais parfois un O/RM peut masquer le problème, s’il extrait implicitement les enregistrements enfants un par un. Ce problème est appelé « Problème N+1 ».
Implémentation d’une opération logique unique sous forme de série de requêtes HTTP
Cela se produit souvent lorsque les développeurs tentent de suivre un paradigme orienté objet et de traiter des objets distants comme s’il s’agissait d’objets locaux dans la mémoire. Cela peut entraîner de trop nombreux allers-retours réseau. Par exemple, l’API web suivante expose les propriétés individuelles des objets User par le biais des méthodes GET HTTP individuelles.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Tandis que cette approche est techniquement correcte, la plupart des clients auront probablement besoin d’obtenir plusieurs propriétés pour chaque User, ce qui donne un code client qui ressemble à ce qui suit :
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Lecture et écriture sur un fichier du disque
Les E/S d’un fichier impliquent l’ouverture d’un fichier et le déplacement vers le point approprié avant la lecture ou l’écriture des données. Une fois l’opération terminée, le fichier peut être fermé pour économiser les ressources du système d’exploitation. Une application qui lit et écrit en permanence de petites quantités d’informations dans un fichier génère une surcharge d’E/S. Les petites requêtes en écriture peuvent également entraîner une fragmentation du fichier, ralentissant davantage les opérations d’E/S qui s’ensuivent.
L’exemple suivant utilise un FileStream pour écrire un objet Customer dans un fichier. La création de FileStream a pour effet d’ouvrir le fichier et sa suppression entraîne la fermeture de ce dernier. (l’instruction using supprime automatiquement l’objet FileStream.) Si l’application appelle cette méthode à plusieurs reprises lors de l’ajout de nouveaux clients, la surcharge d’E/S peut rapidement s’accumuler.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Comment corriger le problème
Réduire la quantité de requêtes d’E/S en plaçant les données dans des requêtes plus grandes et moins importantes en nombre.
Récupérer les données d’une base de données à l’aide d’une requête unique et non par le biais de plusieurs petites requêtes. Voici une version révisée du code qui extrait les informations de produit.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Suivez les principes de conception REST pour les API web. Voici une version révisée de l’API web de l’exemple précédent. Au lieu de méthodes GET distinctes pour chaque propriété, il existe une seule méthode GET qui renvoie User. Cela entraîne un corps de réponse plus important par requête. Toutefois, chaque client est susceptible d’effectuer moins d’appels d’API.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Pour les E/S de fichier, envisagez de placer les données en mémoire tampon et de les écrire dans un fichier sous la forme d’une seule opération. Cette approche réduit la surcharge liée à l’ouverture et à la fermeture répétée du fichier et permet de réduire la fragmentation du fichier sur le disque.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Considérations
Les deux premiers exemples effectuent moins d’appels d’E/S et chacun d’eux récupère plus d’informations. Vous devez faire un compromis entre ces deux facteurs. La réponse appropriée dépend des modèles d’utilisation réels. Par exemple, dans l’exemple d’API web, les clients ont souvent seulement besoin du nom d’utilisateur. Dans ce cas, il peut être utile de l’exposer sous la forme d’un appel d’API distinct. Pour plus d’informations, consultez l’antimodèle Récupération superflue.
Lors de la lecture des données, ne créez pas de requêtes d’E/S trop grandes. Une application doit récupérer uniquement les informations qu’elle est susceptible d’utiliser.
Parfois, cela permet de partitionner les informations d’un objet en deux blocs, un pour les données fréquemment sollicitées qui concerne la plupart des requêtes et un pour les données moins souvent sollicitées, qui sont rarement utilisées. Souvent les données fréquemment sollicitées constituent une petite partie de l’ensemble des données d’un objet. Par conséquent, le fait de renvoyer cette partie uniquement peut permettre de réduire la surcharge d’E/S.
Lors de l’écriture de données, évitez de verrouiller les ressources plus longtemps que nécessaire, pour réduire les risques de contention au cours d’une opération de longue durée. Si une opération d’écriture s’étend sur plusieurs magasins de données, fichiers ou services, il convient d’adopter une approche cohérente. Reportez-vous aux conseils en termes de cohérence des données.
Le fait de placer les données en mémoire tampon avant de les écrire les rend vulnérables en cas de blocage du processus. Si le débit de données connaît généralement des pics ou est relativement peu important, il peut être plus sûr de mettre les données en mémoire tampon dans une file d’attente durable externe, tels que desconcentrateurs d’événements.
Envisagez la mise en cache des données que vous récupérez à partir d’un service ou d’une base de données. Cela peut permettre de réduire le volume d’E/S en évitant de répéter les requêtes pour les mêmes données. Pour plus d’informations, consultez Bonnes pratiques de mise en cache.
Comment détecter le problème
Des E/S bavardes se traduisent par une latence élevée et un débit faible. Les utilisateurs finaux sont susceptibles de signaler des temps de réponse prolongés ou des défaillances causées par l’expiration du délai d’expiration des services, en raison d’une contention accrue des ressources d’E/S.
Vous pouvez procéder de la manière suivante pour identifier la cause des problèmes.
- Effectuez l’analyse du processus du système de production pour identifier les opérations pour lesquelles les temps de réponse sont médiocres.
- Effectuez un test de charge pour chaque opération identifiée à l’étape précédente.
- Lors des tests de charge, rassemblez les données de télémétrie concernant les requêtes d’accès aux données effectuées par chaque opération.
- Recueillez les statistiques détaillées de chaque requête envoyée à un magasin de données.
- Profilez l’application dans l’environnement de test pour déterminer les endroits où des goulots d’étranglement peuvent se produire.
Recherchez la présence des symptômes suivants :
- Un grand nombre de petites requêtes d’E/S effectuées pour le même fichier.
- Un grand nombre de petites requêtes de réseau effectuées par une instance d’application pour le même service.
- Un grand nombre de petites requêtes effectuées par une instance d’application pour le même magasin de données.
- Les applications et services sont de plus en plus liés aux E/S.
Exemple de diagnostic
Les sections suivantes appliquent ces étapes à l’exemple présenté plus haut qui interroge une base de données.
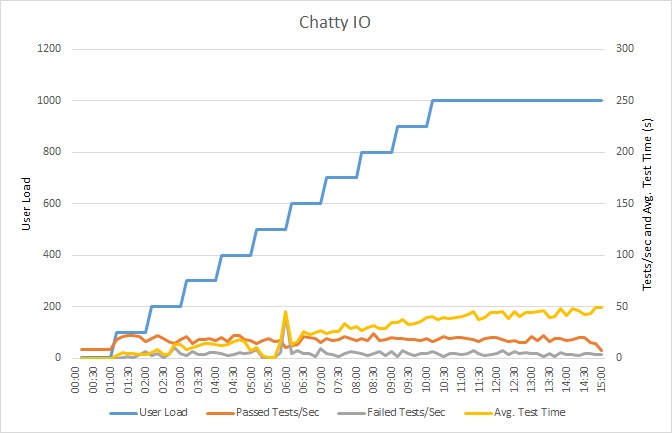
Effectuer un test de charge de l’application
Ce graphique montre les résultats du test de charge. Le temps de réponse médian est mesuré en dixièmes de seconde par requête. Le graphique présente une latence très élevée. Avec une charge de 1 000 utilisateurs, un utilisateur peut devoir attendre presque une minute pour voir les résultats d’une requête.
Remarque
L’application a été déployée sous forme d’application web Azure App Service à l’aide d’Azure SQL Database. Le test de charge a utilisé une charge de travail d’étape simulée pouvant atteindre 1 000 utilisateurs simultanés. La base de données a été configurée avec un pool de connexions prenant en charge jusqu’à 1 000 connexions simultanées afin de réduire le risque de voir la contention des connexions affecter les résultats.
Analyser l’application
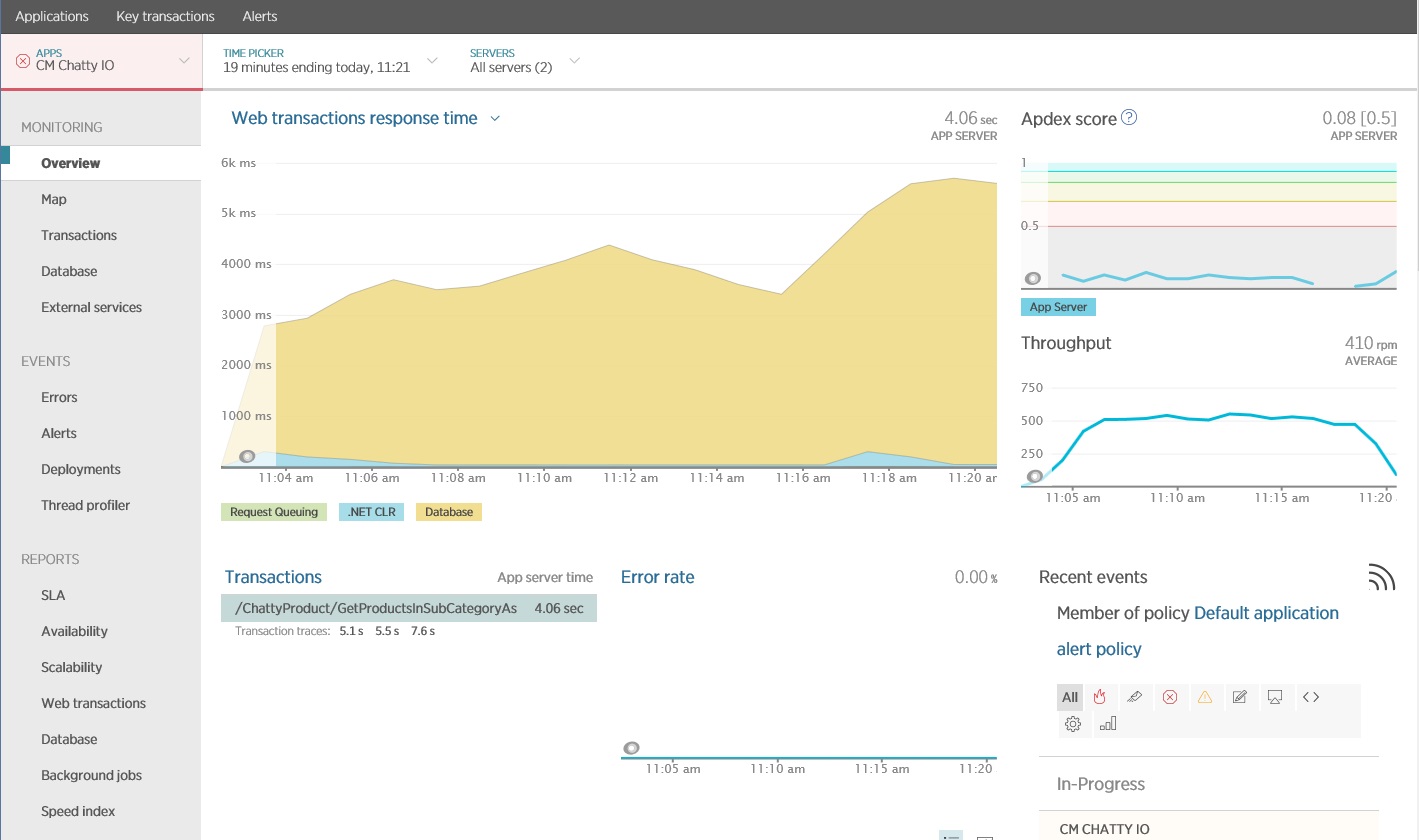
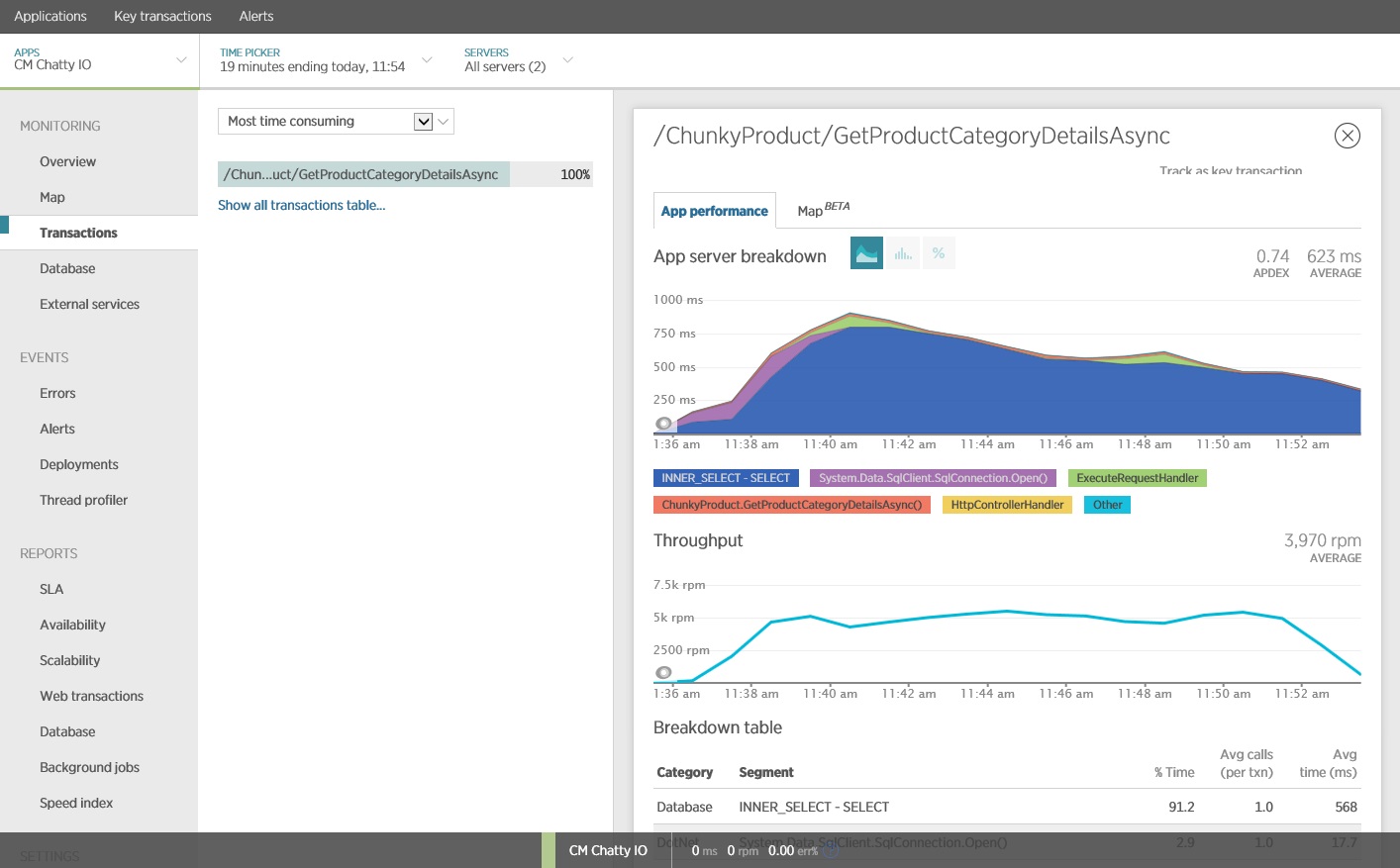
Vous pouvez utiliser un package d’analyse des performances d’application (APM) pour capturer et analyser les métriques clés permettant d’identifier les E/S bavardes. Les mesures importantes dépendent de la charge de travail d’E/S. Pour cet exemple, les requêtes d’ES/S intéressantes étaient celles de la base de données.
L’illustration suivante montre les résultats générés à l’aide de l’APM New Relic. Le temps de réponse moyen de la base de données a atteint un pic d’environ 5,6 secondes par requête lors de la charge de travail maximale. Le système a pu prendre en charge une moyenne de 410 requêtes par minute au cours du test.
Collecter des informations détaillées concernant l’accès aux données
Un examen approfondi des données d’analyse montre que l’application exécute trois instructions SQL SELECT différentes. Celles-ci correspondent aux requêtes générées par Entity Framework pour extraire des données à partir des tables ProductListPriceHistory, Product, et ProductSubcategory. En outre, la requête qui récupère des données de la table ProductListPriceHistory est de loin l’instruction SELECT la plus fréquemment exécutée par ordre de grandeur.
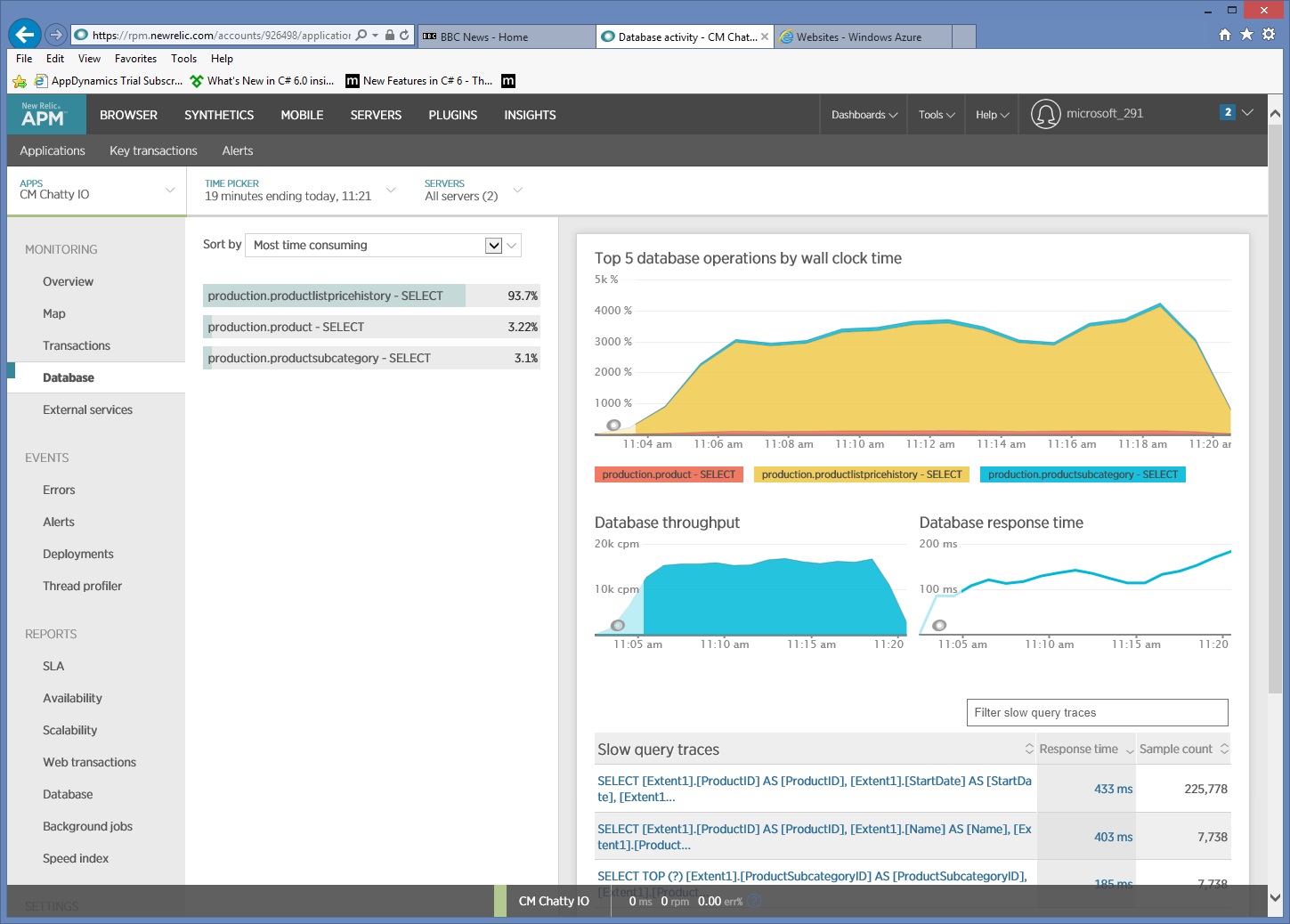
Il s’avère que la méthode GetProductsInSubCategoryAsync, présentée précédemment, exécute 45 requêtes SELECT. Chaque requête entraîne l’ouverture d’une nouvelle connexion SQL par l’application.
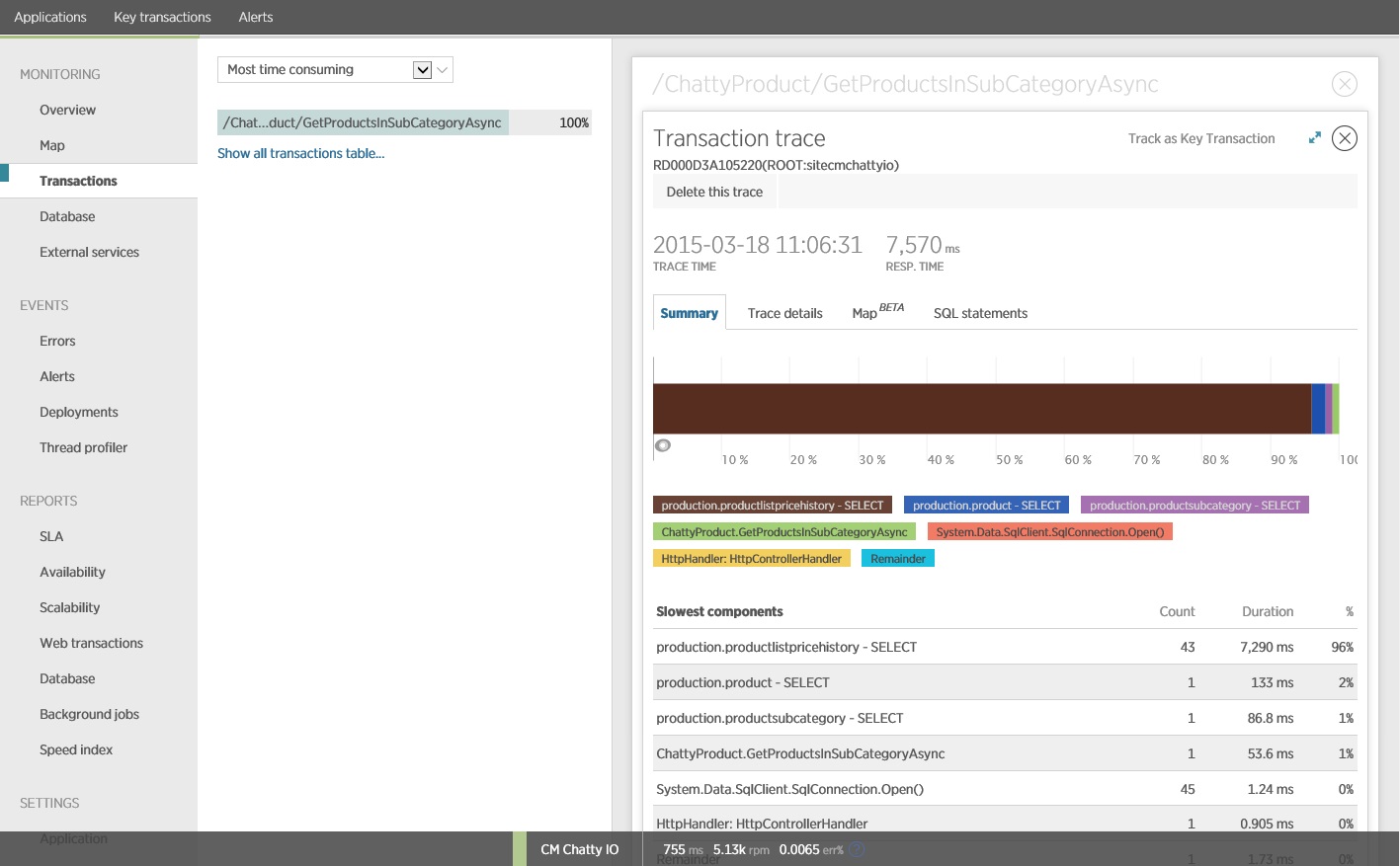
Remarque
Cette illustration montre les informations de suivi de l’instance la plus lente de l’opération GetProductsInSubCategoryAsync du test de charge. Dans un environnement de production, il est utile d’examiner les traces des instances les plus lentes, pour voir s’il existe un modèle suggérant un problème. Si vous vous contentez d’examiner les valeurs moyennes, vous pouvez négliger des problèmes qui pourraient s’aggraver en charge.
L’image suivante montre les instructions SQL réelles qui ont été émises. La requête qui extrait les informations de prix est exécutée pour chacun des produits de la sous-catégorie de produit. L’utilisation d’une jointure réduirait considérablement le nombre d’appels de la base de données.
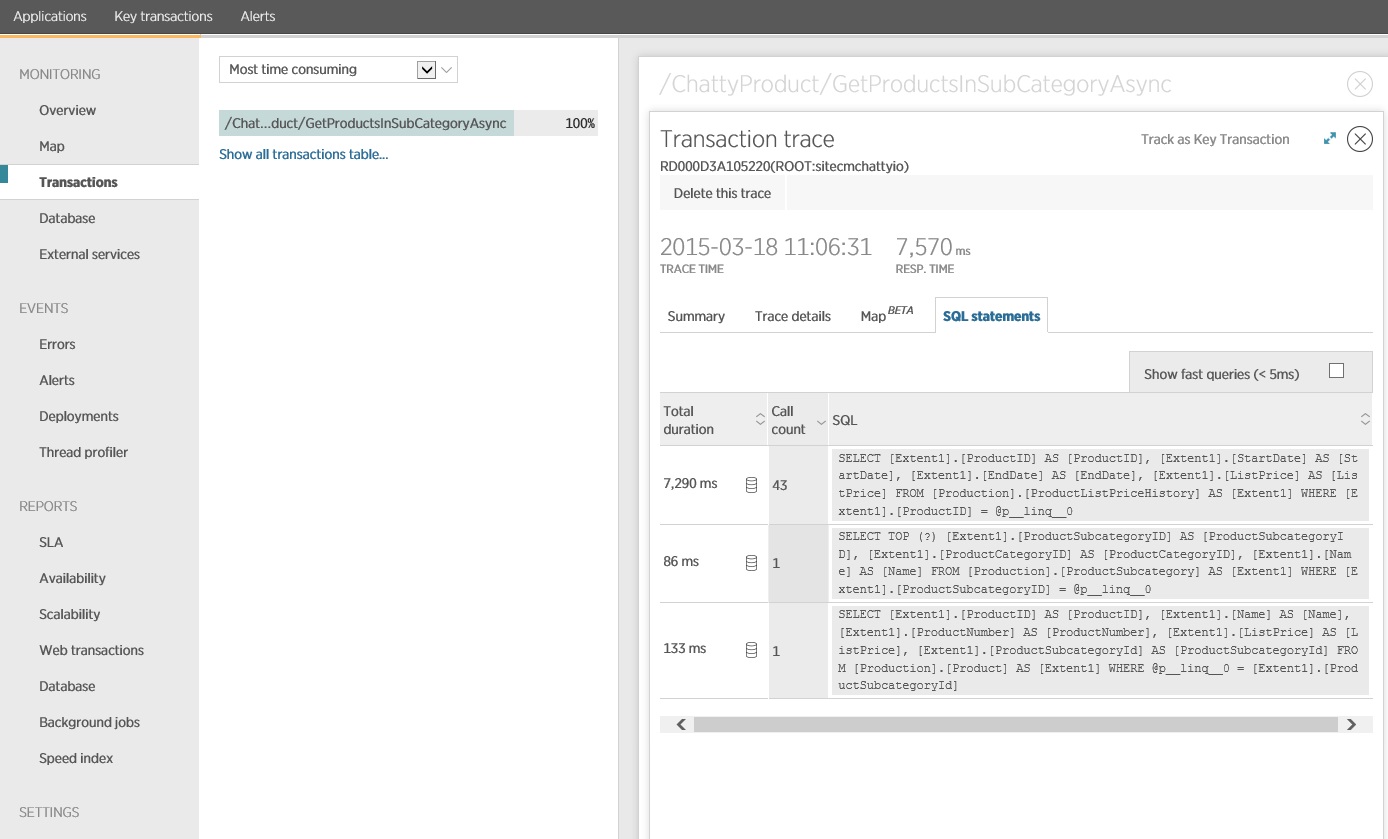
Si vous utilisez un O/RM, tel que Entity Framework, le suivi des requêtes SQL peut donner un aperçu de la manière dont le O/RM traduit les appels par programmation en instructions SQL et indiquer les zones où l’accès aux données peut être optimisé.
Implémenter la solution et vérifier le résultat
La réécriture de l’appel à Entity Framework a donné les résultats suivants.
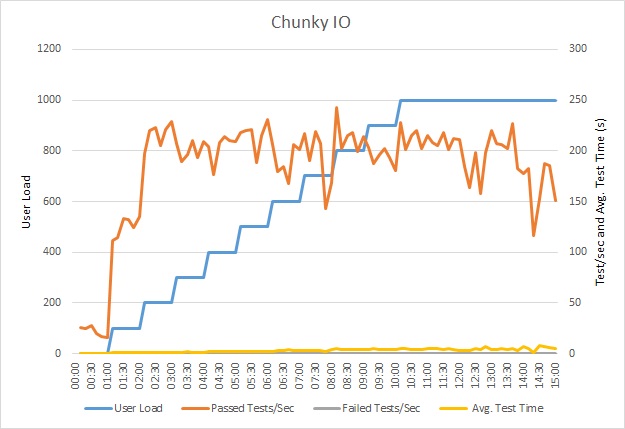
Ce test de charge a été effectué sur le même déploiement à l’aide du même profil de charge. Cette fois le graphique indique une latence plus faible. La durée moyenne de la requête pour 1 000 utilisateurs est comprise entre 5 et 6 secondes contre presque une minute.
Cette fois le système a pris en charge en moyenne 3 970 requêtes par minute, par rapport aux 410 du test précédent.
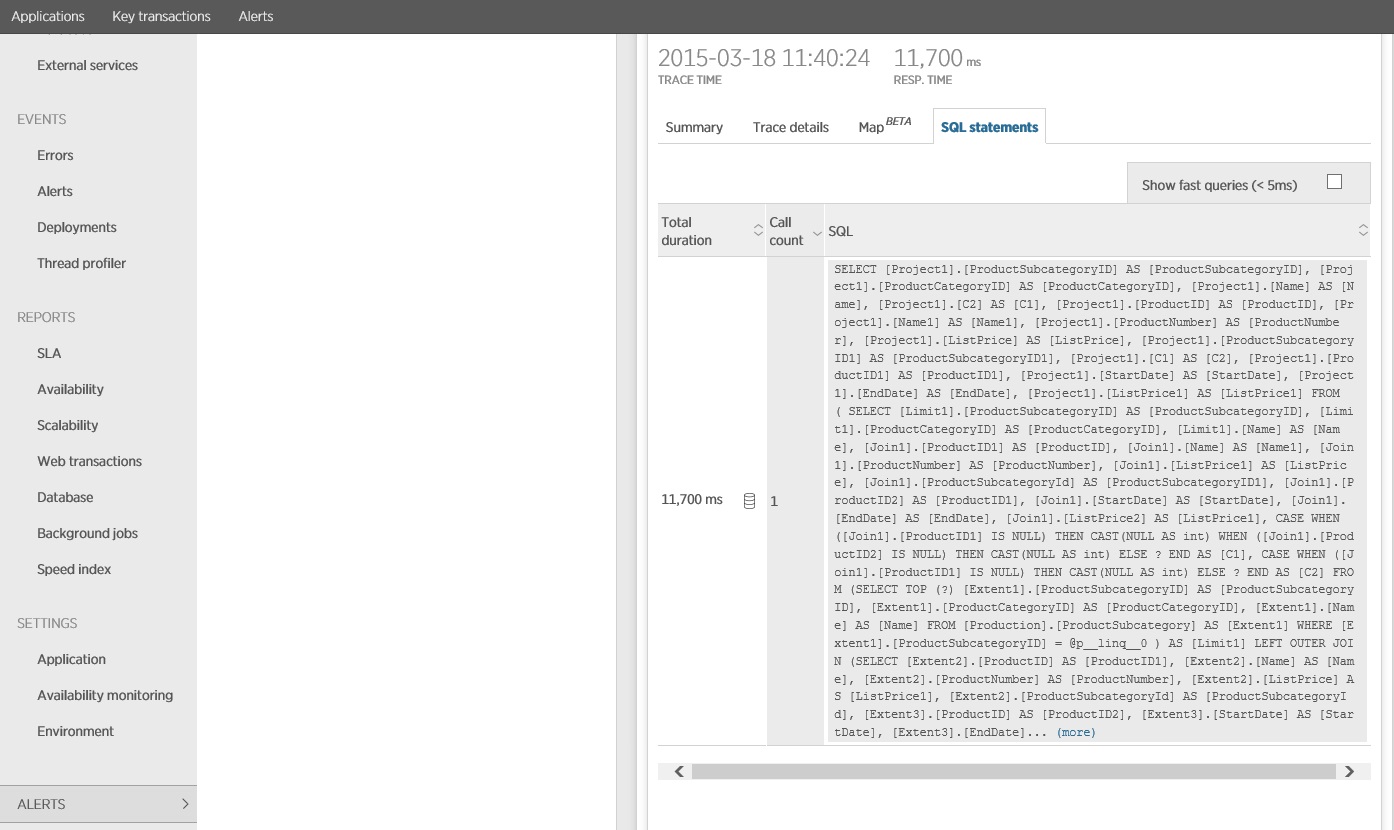
Le suivi de l’instruction SQL indique que toutes les données sont extraites dans une instruction SELECT unique. Bien que cette requête soit beaucoup plus complexe, elle est exécutée une seule fois par opération. Et tandis que des jointures complexes peuvent devenir coûteuses, les systèmes de base de données relationnelle sont optimisés pour ce type de requête.
Ressources associées
- Bonnes pratiques en matière de conception d’API
- Bonnes pratiques pour la mise en cache
- Data Consistency Primer (Manuel d’introduction à la cohérence des données)
- Antimodèle de récupération superflue
- Absence d’antimodèle de mise en cache
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour