Antimodèle de récupération superflue
Les antimodèles sont des défauts de conception courants qui peuvent perturber votre logiciel ou vos applications dans des situations de stress et ne doivent pas être négligés. Dans un antimodèle de récupération superflue, les données plus que nécessaires sont récupérées pour une opération métier, ce qui entraîne souvent une surcharge d’E/S inutile et une réactivité réduite.
Exemples d’antimodèle de récupération superflue
Cet antimodèle peut se produire si l’application essaie de minimiser les demandes d’E/S en extrayant toutes les données dont elle peut avoir besoin. Ceci est souvent la conséquence de la surcompensation pour l’antimodèle d’E/S bavardes. Par exemple, une application peut extraire les détails de chaque produit dans une base de données. Mais l’utilisateur peut n’avoir besoin que d’un sous-ensemble de ces informations (certaines peuvent ne pas être pertinentes pour les clients) et n’a probablement pas besoin de voir la totalité des produits en même temps. Même si l’utilisateur parcourt l’intégralité du catalogue, il serait logique de paginer les résultats, en montrant par exemple 20 résultats à la fois.
Ce problème trouve aussi sa source dans des pratiques de programmation ou de conception médiocres. Par exemple, le code suivant utilise Entity Framework pour extraire les informations détaillées de chaque produit. Il filtre ensuite les résultats pour retourner uniquement un sous-ensemble des champs, en ignorant le reste. Vous trouverez l’exemple complet ici.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
Dans l’exemple suivant, l’application récupère les données pour effectuer une agrégation qui aurait pu être effectuée par la base de données. L’application calcule le total des ventes en obtenant tous les enregistrements pour toutes les commandes, puis calcule la somme sur ces enregistrements. Vous trouverez l’exemple complet ici.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
L’exemple suivant montre un problème subtil, provoqué par la façon dont Entity Framework utilise LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
L’application essaie de trouver les produits avec une SellStartDate de plus d’une semaine. Dans la plupart des cas, LINQ to Entities traduit une clause where pour une instruction SQL qui est exécutée par la base de données. Dans ce cas, toutefois, LINQ to Entities ne peut pas mapper la méthode AddDays à SQL. Au lieu de cela, chaque ligne à partir de la table Product est retournée et les résultats sont filtrés dans la mémoire.
L’appel à AsEnumerable est une indication qu’il existe un problème. Cette méthode convertit les résultats en une interface IEnumerable. Bien que IEnumerable prend en charge le filtrage, le filtrage est effectué côté client et non côté base de données. Par défaut, LINQ to Entities utilise IQueryable, qui passe la responsabilité de filtrage à la source de données.
Comment corriger un antimodèle de récupération superflue
Évitez l’extraction de grands volumes de données qui peuvent rapidement devenir obsolètes ou peuvent être ignorées et n’extrayez que les données nécessaires pour l’opération en cours.
Au lieu d’obtenir toutes les colonnes d’une table, puis de les filtrer, sélectionnez les colonnes dont vous avez besoin à partir de la base de données.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
De même, effectuez une agrégation dans la base de données et non dans la mémoire de l’application.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Quand vous utilisez Entity Framework, vérifiez que les requêtes LINQ sont résolues en utilisant l’interface IQueryable et non pas IEnumerable. Vous devrez peut-être ajuster la requête pour utiliser uniquement les fonctions qui peuvent être mappées à la source de données. L’exemple précédent peut être refactorisé pour supprimer la méthode AddDays de la requête, ce qui permet d’effectuer le filtrage depuis la base de données.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Considérations
Dans certains cas, vous pouvez améliorer les performances en partitionnant horizontalement les données. Si différentes opérations accèdent aux différents attributs des données, le partitionnement horizontal peut réduire la contention. Souvent, la plupart des opérations sont exécutées par rapport à un petit sous-ensemble des données, ainsi répartir cette charge peut améliorer les performances. Consultez Partitionnement des données.
Pour les opérations qui doivent prendre en charge les requêtes non liées, implémentez la pagination et n’extrayez qu’un nombre limité d’entités à la fois. Par exemple, si un client parcourt un catalogue de produits, vous pouvez afficher une page de résultats à la fois.
Lorsque cela est possible, tirez parti des fonctionnalités intégrées dans le magasin de données. Par exemple, les bases de données SQL fournissent généralement des fonctions d’agrégation.
Si vous utilisez un magasin de données qui ne prend pas en charge une fonction particulière, telle que l’agrégation, vous pouvez stocker le résultat calculé ailleurs et mettre à jour les valeurs lorsque les enregistrements sont ajoutés ou mis à jour, afin que l’application n’ait pas à recalculer la valeur chaque fois que cela est nécessaire.
Si vous voyez que les demandes extraient un grand nombre de champs, examinez le code source pour déterminer si tous ces champs sont nécessaires. Parfois, ces requêtes sont le résultat de requêtes
SELECT *de mauvaise conception.De même, les requêtes qui récupèrent un grand nombre d’entités peuvent démontrer que l’application ne filtre pas correctement les données. Vérifiez que toutes ces entités sont nécessaires. Utilisez le filtrage côté base de données dans la mesure du possible, par exemple, à l’aide de clauses
WHEREdans SQL.Le déchargement du traitement sur la base de données n’est pas toujours la meilleure option. N’utilisez cette stratégie que lorsque la base de données est conçue ou optimisée pour cela. La plupart des systèmes de base de données sont optimisés pour certaines fonctions, mais ne sont pas conçus pour servir de moteurs d’applications à usage général. Pour plus d’informations, consultez Antimodèle de base de données occupé.
Comment détecter un antimodèle de récupération superflue
Une récupération superflue se traduit par une latence élevée et un débit faible. Si les données sont récupérées à partir d’un magasin de données, une contention accrue est également probable. Les utilisateurs finals sont susceptibles de signaler des temps de réponse plus longs que d’habitude ou des échecs causés par l’expiration du délai d’attente des services. Ces échecs peuvent renvoyer des erreurs HTTP 500 (serveur interne) ou HTTP 503 (service indisponible). Examinez les journaux d’événements du serveur web, qui contiennent probablement des informations plus détaillées sur les causes et les circonstances de ces erreurs.
Les symptômes de cet antimodèle ainsi qu’une partie de la télémétrie obtenue peuvent être très similaires à ceux de l’antimodèle de persistance monolithique.
Vous pouvez procédez de la manière suivante pour identifier la cause :
- Identifiez les charges de travail ou les transactions lentes en effectuant des tests de charge, des analyses de processus ou d’autres méthodes de capture de données d’instrumentation.
- Observez les modèles de comportement exposés par le système. Existe-t-il des limites particulières en termes de transactions par seconde ou de volume d’utilisateurs ?
- Mettez en corrélation les instances des charges de travail lentes avec les modèles de comportement.
- Identifiez les banques de données utilisées. Pour chaque source de données, exécutez les données de télémétrie de niveau inférieur pour observer le comportement des opérations.
- Identifiez les requêtes à exécution lente qui font référence à ces sources de données.
- Effectuez une analyse de ressource spécifique des requêtes à exécution lente et déterminez comment les données sont utilisées et consommées.
Recherchez la présence des symptômes suivants :
- Demandes d’E/S fréquentes et de grande taille effectuées à la même ressource ou base de données.
- Contention dans un magasin de données ou dans une ressource partagée.
- Opération qui reçoit fréquemment des volumes importants de données sur le réseau.
- Applications et services attendant longtemps que les E/S se terminent.
Exemple de diagnostic
Les sections suivantes appliquent ces étapes pour les exemples précédents.
Identifier les charges de travail lentes
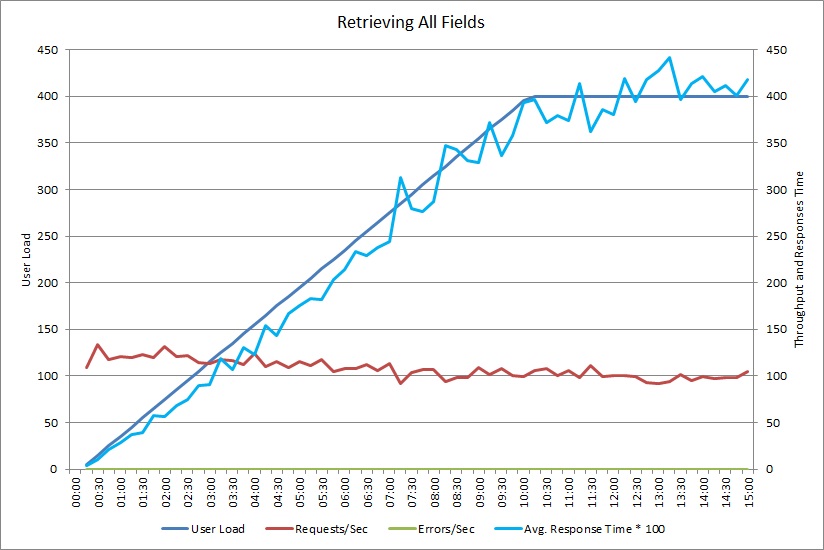
Ce graphique montre les résultats de performances d’un test de charge simulant jusqu’à 400 utilisateurs simultanés exécutant la méthode GetAllFieldsAsync illustrée précédemment. Le débit diminue lentement à mesure que la charge augmente. Le temps de réponse moyen augmente à mesure que la charge de travail augmente.
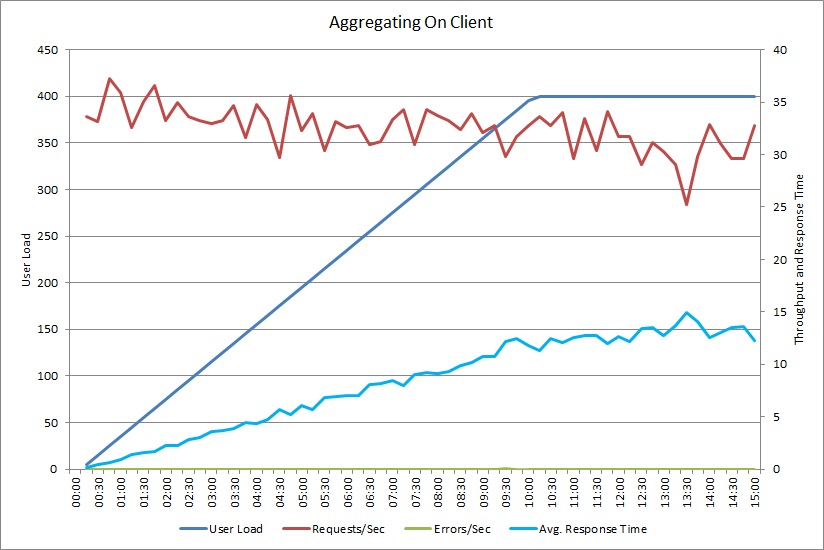
Un test de charge pour l’opération AggregateOnClientAsync montre un modèle semblable. Le volume de requêtes est relativement stable. Le temps de réponse moyen augmente avec la charge de travail, bien que plus lentement que le graphique précédent.
Mettre en corrélation les charges de travail lentes avec les modèles de comportement
Toute corrélation entre périodes régulières d’utilisation intensive et ralentissement des performances peut indiquer les zones posant problème. Examinez le profil de performance de fonctionnalités qui semble s’exécuter lentement, pour déterminer s’il correspond au test de charge effectué précédemment.
Effectuez un test de charge sur les mêmes fonctionnalités à l’aide des charges utilisateur basées sur les étapes, pour trouver le point où les performances diminuent de manière significative ou échouent complètement. Si ce point se situe dans les limites de votre utilisation réelle attendue, examinez la manière dont la fonctionnalité est implémentée.
Une opération lente n’est pas nécessairement un problème, si elle n’est pas en cours lorsque le système est sous tension, si elle n’est pas urgente et qu’elle n’affecte pas négativement les performances d’autres opérations importantes. Par exemple, la génération de statistiques opérationnelles mensuelles peut être une opération longue, mais elle peut probablement s’effectuer en traitement par lots et s’exécuter en tant que travail de priorité basse. En revanche, l’interrogation du catalogue de produits par les clients est une opération métier critique. Concentrez-vous sur la télémétrie générée par ces opérations critiques pour déterminer comment les performances varient au cours des périodes d’utilisation intensive.
Identifier les sources de données dans les charges de travail lentes
Si vous pensez qu’un service est médiocre en raison de la façon dont il récupère les données, examinez la façon dont l’application interagit avec les référentiels qu’elle utilise. Analysez le système réel pour voir quelles sources sont accessibles pendant les périodes de performance médiocre.
Pour chaque source de données, instrumentez le système afin de capturer les éléments suivants :
- La fréquence à laquelle chaque magasin de données est accessible.
- Le volume de données entrant et sortant de la banque de données.
- Le minutage de ces opérations, notamment la latence des demandes.
- La nature et la fréquence des erreurs qui se produisent pendant l’accès à chaque magasin de données sous une charge normale.
Comparez ces informations avec le volume de données renvoyé par l’application au client. Suivez le rapport entre le volume des données retournées par la banque de données et le volume de données retournées au client. S’il existe une disparité volumineuse, faites des recherches pour déterminer si l’application extrait des données dont elle n’a pas besoin.
Vous pourrez peut-être capturer ces données par l’observation du système réel et le suivi du cycle de vie de chaque demande de l’utilisateur, ou vous pouvez modéliser une série de charges de travail synthétiques et les exécuter sur un système de test.
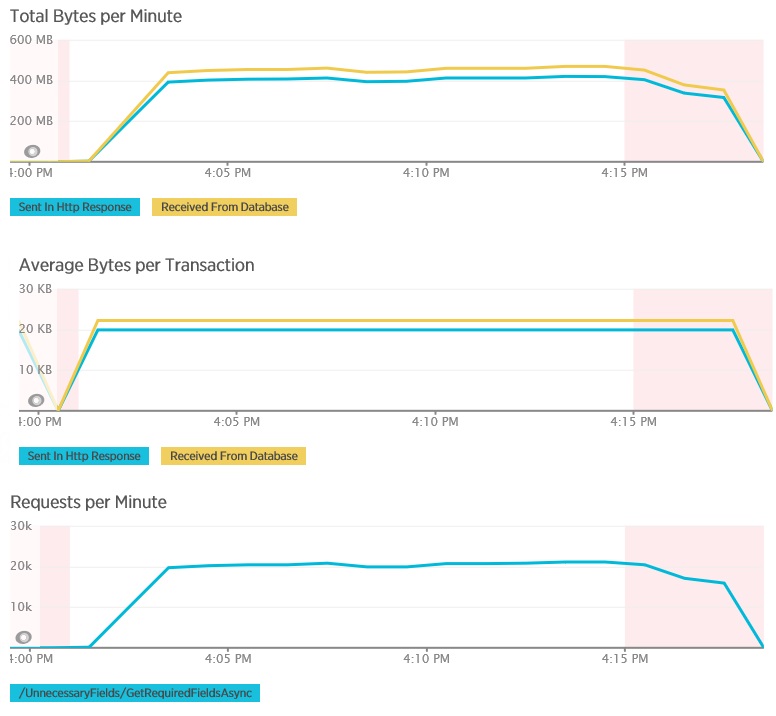
Les graphiques suivants montrent les données de télémétrie capturées à l’aide de l’APM New Relic pendant un test de charge de la méthode GetAllFieldsAsync. Notez la différence entre les volumes de données reçues à partir de la base de données et les réponses HTTP correspondantes.
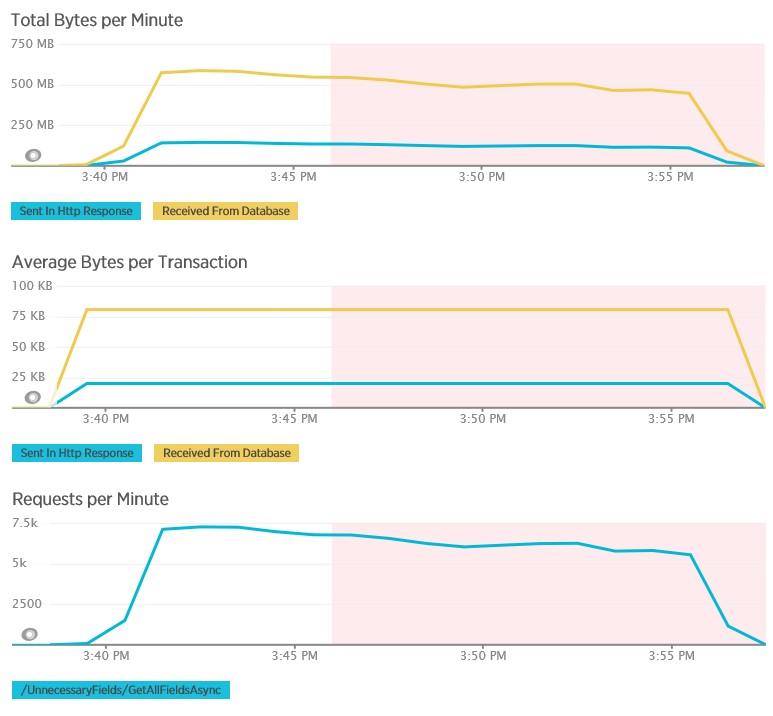
Pour chaque demande, la base de données a retourné 80 503 octets, mais la réponse au client ne contenait que 19 855 octets, environ 25 % de la taille de la réponse de la base de données. La taille des données retournées au client peut varier selon le format. Pour ce test de charge, le client a demandé des données JSON. Le test individuel à l’aide de XML (non affiché) a obtenu une taille de réponse de 35 655 octets, ou 44 % de la taille de la réponse de la base de données.
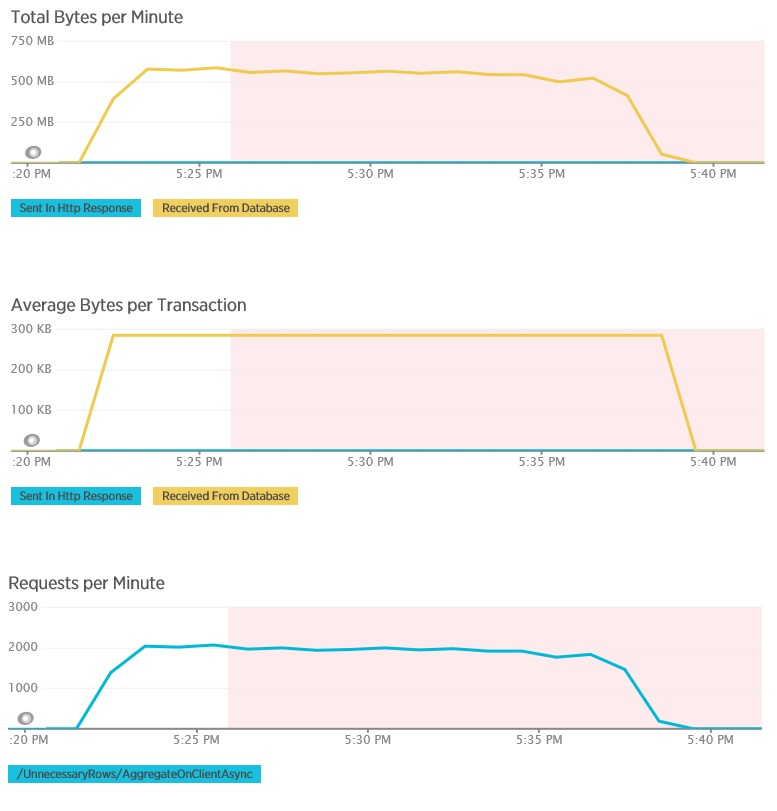
Le test de charge pour la méthode AggregateOnClientAsync affiche des résultats plus extrêmes. Dans ce cas, chaque test a exécuté une requête permettant d’extraire plus de 280 ko de données de la base de données, mais la réponse JSON était seulement de 14 octets. Les écarts importants constatés sont dus à la méthode qui calcule un résultat agrégé à partir d’un gros volume de données.
Identifier et analyser les requêtes lentes
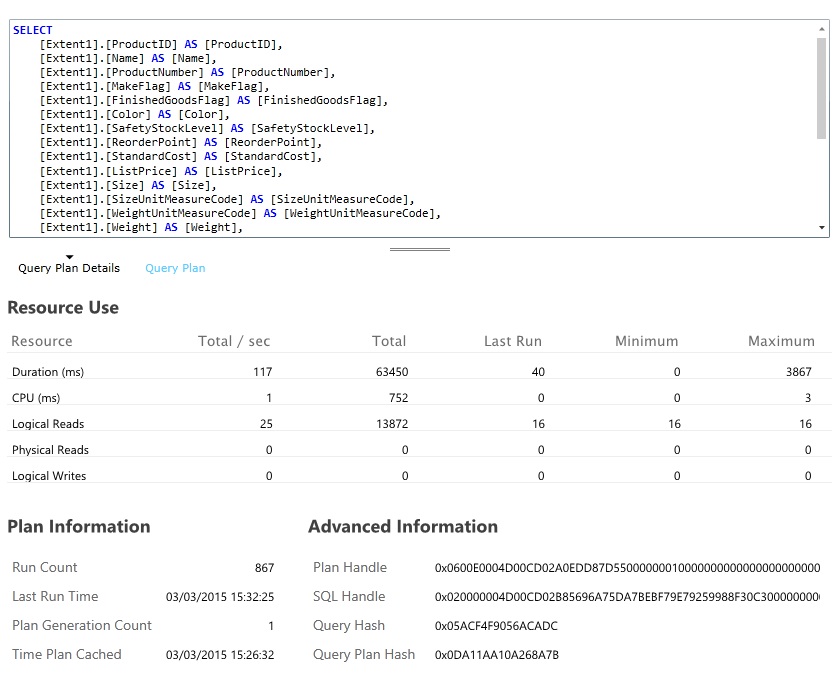
Recherchez les requêtes de base de données qui consomment le plus de ressources et prennent le plus de temps à s’exécuter. Vous pouvez ajouter la fonctionnalité d’instrumentation pour rechercher les heures de début et de fin pour de nombreuses opérations de base de données. De nombreux magasins de données fournissent également des informations détaillées sur la façon dont les requêtes sont effectuées et optimisées. Par exemple, le volet de performance des requêtes dans le portail de gestion Azure SQL Database permet de sélectionner une requête et d’afficher les informations de performances d’exécution détaillées. Voici la requête générée par l’opération GetAllFieldsAsync :
Implémenter la solution et vérifier le résultat
Après avoir modifié la méthode GetRequiredFieldsAsync pour utiliser une instruction SELECT côté base de données, le test de charge a montré les résultats suivants.
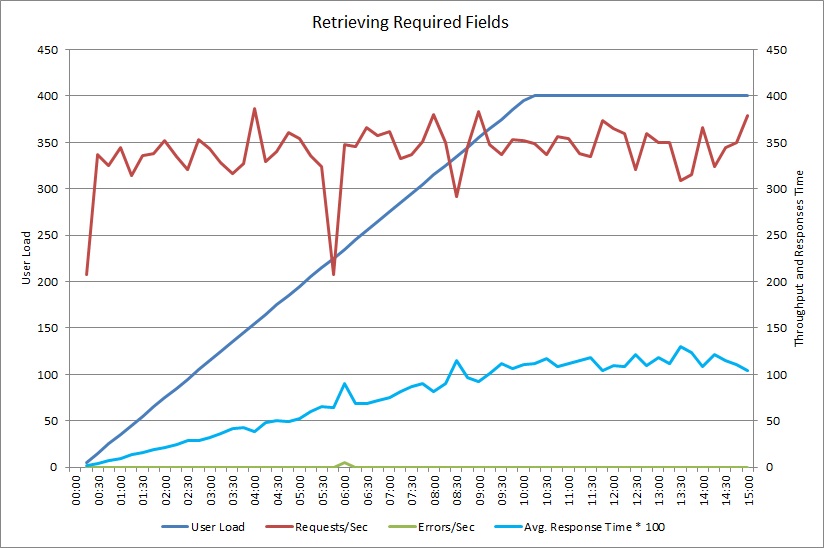
Ce test de charge a utilisé le même déploiement et la même charge de travail simulée de 400 utilisateurs simultanés que pour l’exemple précédant. Ce graphique indique une latence plus faible. Le temps de réponse augmente avec la charge d’environ 1,3 secondes, par rapport à 4 secondes dans le cas précédent. Le débit est également plus élevé avec 350 demandes par seconde par rapport à 100 plus tôt. Le volume des données récupérées à partir de la base de données correspond mieux à la taille des messages de réponse HTTP.
Le test de charge effectué à l’aide de la méthode AggregateOnDatabaseAsync génère les résultats suivants :
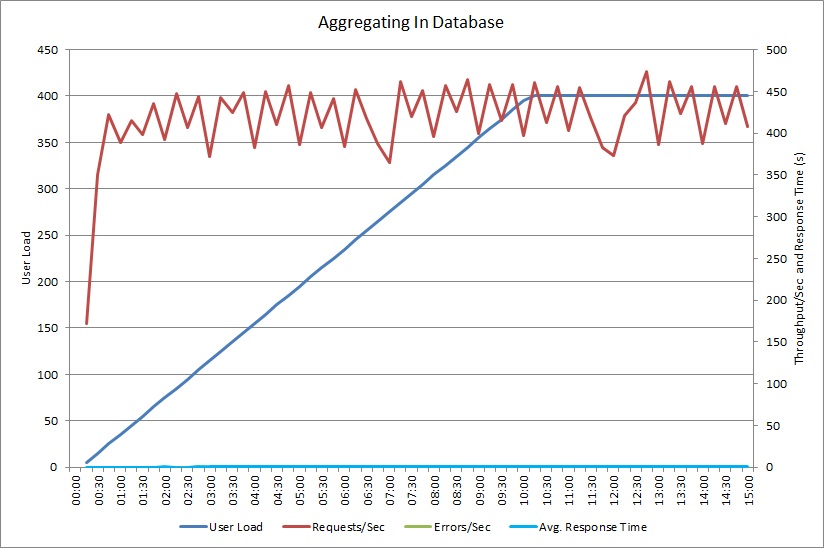
Le temps de réponse moyen est désormais minimal. Il s’agit d’une amélioration importante des performances, principalement par la réduction des E/S volumineuses à partir de la base de données.
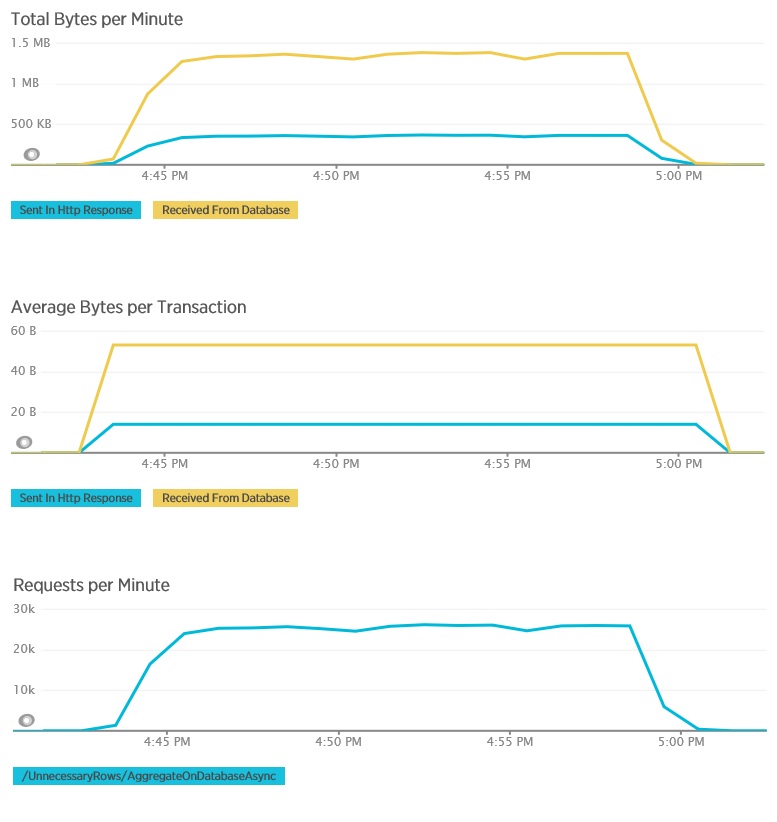
Voici les données de télémétrie correspondantes pour la méthode AggregateOnDatabaseAsync. La quantité de données récupérées à partir de la base de données a été considérablement réduite de plus de 280 ko par transaction à 53 octets. Par conséquent, le nombre maximal de demandes soutenues par minute a été augmenté, d’environ 2 000 à plus de 25 000.
Ressources associées
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour