Conseils sur la surveillance et les diagnostics
Les applications et services distribués exécutés dans le cloud sont, par leur nature, des éléments complexes de logiciels qui comprennent de nombreuses parties mobiles. Dans un environnement de production, il est important de pouvoir suivre la façon dont les utilisateurs utilisent votre système, tracent l’utilisation des ressources et surveillent généralement l’intégrité et les performances de votre système. Vous pouvez utiliser ces informations comme aide au diagnostic pour détecter et corriger les problèmes, et également aider à identifier des problèmes potentiels et les empêcher de se produire.
Scénarios de supervision et de diagnostic
Vous pouvez utiliser la supervision pour obtenir un aperçu du fonctionnement d’un système. La surveillance est un élément essentiel du maintien des objectifs de qualité de service. Les scénarios courants de collecte des données de surveillance sont les suivants :
- S’assurer que le système reste sain.
- Suivi de la disponibilité du système et de ses éléments de composant.
- Maintenir les performances pour garantir que le débit du système ne se dégrade pas de manière inattendue à mesure que le volume de travail augmente.
- Garantie que le système répond à tous les contrats de niveau de service (SLA) établis avec les clients.
- Protection de la confidentialité et de la sécurité du système, des utilisateurs et de leurs données.
- Suivi des opérations effectuées à des fins d’audit ou de réglementation.
- Surveillance de l’utilisation quotidienne du système et de la détection des tendances susceptibles d’entraîner des problèmes s’ils ne sont pas résolus.
- Suivi des problèmes qui se produisent, du rapport initial à l’analyse des causes possibles, de la correction, des mises à jour logicielles et du déploiement conséquents.
- Suivi des opérations et débogage des versions logicielles.
Remarque
Cette liste n’est pas destinée à être exhaustive. Ce document se concentre sur ces scénarios en tant que situations les plus courantes pour effectuer une surveillance. Il peut y avoir d’autres personnes moins courantes ou spécifiques à votre environnement.
Les sections suivantes décrivent ces scénarios plus en détail. Les informations relatives à chaque scénario sont présentées au format suivant :
- Vue d’ensemble du scénario.
- Exigences classiques de ce scénario.
- Données d’instrumentation brutes requises pour prendre en charge le scénario et les sources possibles de ces informations.
- Comment ces données brutes peuvent être analysées et combinées pour générer des informations de diagnostic significatives.
Surveillance de la santé
Un système est sain s’il est en cours d’exécution et capable de traiter les demandes. L’objectif de la surveillance de l’intégrité est de générer un instantané de l’intégrité actuelle du système afin de pouvoir vérifier que tous les composants du système fonctionnent comme prévu.
Conditions requises pour la surveillance de l’intégrité
Un opérateur doit être alerté rapidement (en quelques secondes) si une partie du système est considérée comme non saine. L’opérateur doit pouvoir déterminer quelles parties du système fonctionnent normalement et quelles parties rencontrent des problèmes. L’intégrité du système peut être mise en surbrillance via un système de lumière du trafic :
- Rouge pour défectueux (le système s’est arrêté)
- Jaune pour une intégrité partielle (le système s’exécute avec des fonctionnalités réduites)
- Vert pour une santé complète
Un système complet de surveillance de l’intégrité permet à un opérateur d’explorer le système pour afficher l’état d’intégrité des sous-systèmes et des composants. Par exemple, si le système global est représenté comme partiellement sain, l’opérateur doit pouvoir effectuer un zoom avant et déterminer quelle fonctionnalité n’est actuellement pas disponible.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Les données brutes requises pour prendre en charge la surveillance de l’intégrité peuvent être générées à la suite des éléments suivants :
- Suivi de l’exécution des demandes utilisateur. Ces informations peuvent être utilisées pour déterminer les demandes qui ont réussi, qui ont échoué et combien de temps chaque demande prend.
- Surveillance des utilisateurs synthétiques. Ce processus simule les étapes effectuées par un utilisateur et suit une série prédéfinie d’étapes. Les résultats de chaque étape doivent être capturés.
- Journalisation des exceptions, des erreurs et des avertissements. Ces informations peuvent être capturées à la suite d’instructions de trace incorporées dans le code de l’application, ainsi que la récupération d’informations à partir des journaux d’événements de tous les services référencés par le système.
- Surveillance de l’intégrité des services tiers que le système utilise. Cette surveillance peut nécessiter la récupération et l’analyse des données d’intégrité que ces services fournissent. Ces informations peuvent prendre différents formats.
- Surveillance des points de terminaison. Ce mécanisme est décrit plus en détail dans la section « Supervision de la disponibilité ».
- Collecte d’informations sur les performances ambiantes, telles que l’utilisation du processeur en arrière-plan ou l’activité d’E/S (y compris le réseau).
Analyse des données d’intégrité
L’objectif principal de la surveillance de l’intégrité est d’indiquer rapidement si le système est en cours d’exécution. L’analyse à chaud des données immédiates peut déclencher une alerte si un composant critique est détecté comme défectueux. (Il ne répond pas à une série consécutive de pings, par exemple.) L’opérateur peut ensuite effectuer l’action corrective appropriée.
Un système plus avancé peut inclure un élément prédictif qui effectue une analyse à froid sur les charges de travail récentes et actuelles. Une analyse à froid peut repérer les tendances et déterminer si le système est susceptible de rester sain ou si le système aura besoin de ressources supplémentaires. Cet élément prédictif doit être basé sur des métriques de performances critiques, telles que :
- Taux de requêtes dirigées vers chaque service ou sous-système.
- Temps de réponse de ces demandes.
- Volume de données entrantes et sortantes de chaque service.
Si la valeur d’une métrique dépasse un seuil défini, le système peut déclencher une alerte pour permettre à un opérateur ou une mise à l’échelle automatique (le cas échéant) de prendre les mesures préventives nécessaires pour maintenir l’intégrité du système. Ces actions peuvent impliquer l’ajout de ressources, le redémarrage d’un ou plusieurs services qui échouent ou l’application d’une limitation aux demandes de priorité inférieure.
Surveillance de la disponibilité
Un système vraiment sain exige que les composants et les sous-systèmes qui composent le système soient disponibles. La surveillance de la disponibilité est étroitement liée à la surveillance de l’intégrité. Toutefois, alors que la surveillance de l’intégrité fournit une vue immédiate de l’intégrité actuelle du système, la surveillance de la disponibilité concerne le suivi de la disponibilité du système et de ses composants pour générer des statistiques sur le temps d’activité du système.
Dans de nombreux systèmes, certains composants (tels qu’une base de données) sont configurés avec une redondance intégrée pour permettre un basculement rapide en cas d’erreur grave ou de perte de connectivité. Dans l’idéal, les utilisateurs ne doivent pas savoir qu’une telle défaillance s’est produite. Toutefois, du point de vue de la surveillance de la disponibilité, il est nécessaire de recueillir autant d’informations que possible sur ces échecs pour déterminer la cause et prendre des mesures correctives pour les empêcher de se récurriser.
Les données requises pour suivre la disponibilité peuvent dépendre d’un certain nombre de facteurs de niveau inférieur. Bon nombre de ces facteurs peuvent être spécifiques à l’application, au système et à l’environnement. Un système de surveillance efficace capture les données de disponibilité qui correspondent à ces facteurs de bas niveau, puis les agrège pour donner une image globale du système. Par exemple, dans un système de commerce électronique, la fonctionnalité métier qui permet à un client de passer des commandes peut dépendre du référentiel où les détails de la commande sont stockés et du système de paiement qui gère les transactions monétaires pour le paiement de ces commandes. La disponibilité de la partie de placement de commande du système est donc une fonction de la disponibilité du référentiel et du sous-système de paiement.
Conditions requises pour la surveillance de la disponibilité
Un opérateur doit également être en mesure d’afficher la disponibilité historique de chaque système et sous-système, et d’utiliser ces informations pour repérer les tendances susceptibles d’entraîner l’échec périodique d’un ou de plusieurs sous-systèmes. (Les services commencent-ils à échouer à un moment donné de la journée qui correspond aux heures de traitement maximales ?)
Une solution de supervision doit fournir une vue immédiate et historique de la disponibilité ou de l’indisponibilité de chaque sous-système. Il doit également être capable d’alerter rapidement un opérateur lorsqu’un ou plusieurs services échouent ou lorsque les utilisateurs ne peuvent pas se connecter aux services. Il s’agit non seulement de surveiller chaque service, mais également d’examiner les actions effectuées par chaque utilisateur si ces actions échouent lorsqu’ils tentent de communiquer avec un service. Dans une certaine mesure, un degré de défaillance de connectivité est normal et peut être dû à des erreurs temporaires. Mais il peut être utile de permettre au système de déclencher une alerte pour le nombre de défaillances de connectivité à un sous-système spécifié qui se produisent pendant une période spécifique.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Comme pour la surveillance de l’intégrité, les données brutes requises pour prendre en charge la surveillance de la disponibilité peuvent être générées en raison de la surveillance et de la journalisation des exceptions, erreurs et avertissements pouvant se produire. En outre, les données de disponibilité peuvent être obtenues à partir de l’analyse des points de terminaison. L’application peut exposer un ou plusieurs points de terminaison d’intégrité, chacun testant l’accès à une zone fonctionnelle au sein du système. Le système de surveillance peut effectuer un test ping sur chaque point de terminaison en suivant une planification définie et en collectant les résultats (réussite ou échec).
Tous les délais d’expiration, les échecs de connectivité réseau et les tentatives de nouvelle tentative de connexion doivent être enregistrés. Toutes les données doivent être horodatées.
Analyse des données de disponibilité
Les données d’instrumentation doivent être agrégées et corrélées pour prendre en charge les types d’analyse suivants :
- Disponibilité immédiate du système et des sous-systèmes.
- Taux d’échec de disponibilité du système et des sous-systèmes. Dans l’idéal, un opérateur doit être en mesure de mettre en corrélation les défaillances avec des activités spécifiques : qu’est-ce qui se passait quand le système a échoué ?
- Vue historique des taux d’échec du système ou de tous les sous-systèmes sur une période spécifiée et la charge sur le système (nombre de demandes d’utilisateur, par exemple) lorsqu’une défaillance s’est produite.
- Raisons de l’indisponibilité du système ou de tous les sous-systèmes. Par exemple, les raisons peuvent être que le service n’est pas en cours d’exécution, que la connectivité a perdu, qu’elle soit connectée, qu’elle expire, et qu’elle retourne des erreurs.
Vous pouvez calculer le pourcentage de disponibilité d’un service sur une période donnée à l’aide de la formule suivante :
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Cela est utile à des fins de contrat SLA. (La surveillance du contrat SLA est décrite plus en détail plus loin dans cette aide.) La définition du temps d’arrêt dépend du service. Par exemple, Visual Studio Team Services Build Service définit le temps d’arrêt comme la période (minutes cumulées totales) pendant laquelle le service de build n’est pas disponible. Une minute est considérée comme indisponible si toutes les requêtes HTTP continues adressées au service de build pour effectuer des opérations initiées par le client tout au long de la minute entraînent un code d’erreur ou ne retournent pas de réponse.
Monitoring des performances
À mesure que le système est placé sous plus de contraintes (en augmentant le volume d’utilisateurs), la taille des jeux de données auxquels ces utilisateurs accèdent augmente et la possibilité de défaillance d’un ou plusieurs composants devient plus probable. Souvent, l’échec des composants est précédé d’une diminution des performances. Si vous êtes en mesure de détecter une telle diminution, vous pouvez prendre des mesures proactives pour remédier à la situation.
Les performances du système dépendent d’un certain nombre de facteurs. Chaque facteur est généralement mesuré par le biais d’indicateurs de performance clés (KPI), tels que le nombre de transactions de base de données par seconde ou le volume de requêtes réseau qui sont correctement serviceées dans un délai de temps spécifié. Certains de ces indicateurs de performance clés peuvent être disponibles en tant que mesures de performances spécifiques, tandis que d’autres peuvent être dérivés d’une combinaison de métriques.
Remarque
Déterminer les performances médiocres ou bonnes nécessite que vous compreniez le niveau de performance auquel le système doit être capable de s’exécuter. Cela nécessite d’observer le système pendant qu’il fonctionne sous une charge classique et de capturer les données pour chaque indicateur de performance clé sur une période donnée. Cela peut impliquer l’exécution du système sous une charge simulée dans un environnement de test et la collecte des données appropriées avant de déployer le système dans un environnement de production.
Vous devez également vous assurer que la surveillance à des fins de performances ne devient pas un fardeau pour le système. Vous pouvez peut-être ajuster dynamiquement le niveau de détail des données collectées par le processus d’analyse des performances.
Conditions requises pour l’analyse des performances
Pour examiner les performances du système, un opérateur doit généralement voir les informations qui incluent :
- Taux de réponse pour les demandes utilisateur.
- Nombre de requêtes utilisateur simultanées.
- Volume du trafic réseau.
- Taux de réalisation des transactions commerciales.
- Temps de traitement moyen pour les demandes.
Il peut également être utile de fournir des outils permettant à un opérateur d’aider à repérer les corrélations, telles que :
- Nombre d’utilisateurs simultanés par rapport aux temps de latence des requêtes (combien de temps nécessaire pour commencer le traitement d’une demande une fois que l’utilisateur l’a envoyée).
- Nombre d’utilisateurs simultanés par rapport au temps de réponse moyen (combien de temps nécessaire pour effectuer une demande après le traitement).
- Volume de requêtes par rapport au nombre d’erreurs de traitement.
En plus de ces informations fonctionnelles de haut niveau, un opérateur doit être en mesure d’obtenir une vue détaillée des performances de chaque composant du système. Ces données sont généralement fournies via des compteurs de performances de bas niveau qui effectuent le suivi des informations telles que :
- Utilisation de la mémoire.
- Nombre de threads.
- Temps de traitement du processeur.
- Longueur de la file d’attente de la demande.
- Taux et erreurs d’E/S de disque ou réseau.
- Nombre d’octets écrits ou lus.
- Indicateurs d’intergiciel, tels que la longueur de la file d’attente.
Toutes les visualisations doivent permettre à un opérateur de spécifier une période. Les données affichées peuvent être un instantané de la situation actuelle ou une vue historique des performances.
Un opérateur doit être en mesure de déclencher une alerte en fonction de toute mesure de performances pour n’importe quelle valeur spécifiée pendant tout intervalle de temps spécifié.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Vous pouvez collecter des données de performances de haut niveau (débit, nombre d’utilisateurs simultanés, nombre de transactions commerciales, taux d’erreur, et ainsi de suite) en surveillant la progression des demandes des utilisateurs à mesure qu’ils arrivent et passent par le système. Cela implique l’incorporation d’instructions de suivi à des points clés dans le code de l’application, ainsi que des informations de minutage. Toutes les erreurs, exceptions et avertissements doivent être capturés avec des données suffisantes pour les mettre en corrélation avec les demandes qui les ont provoquées. Le journal IIS (Internet Information Services) est une autre source utile.
Si possible, vous devez également capturer des données de performances pour tous les systèmes externes utilisés par l’application. Ces systèmes externes peuvent fournir leurs propres compteurs de performances ou d’autres fonctionnalités pour demander des données de performances. Si cela n’est pas possible, enregistrez des informations telles que l’heure de début et l’heure de fin de chaque requête adressée à un système externe, ainsi que l’état (réussite, échec ou avertissement) de l’opération. Par exemple, vous pouvez utiliser une approche de chronomètre pour les demandes de temps : démarrez un minuteur au démarrage de la demande, puis arrêtez le minuteur une fois la requête terminée.
Les données de performances de bas niveau pour les composants individuels d’un système peuvent être disponibles via des fonctionnalités et des services tels que les compteurs de performances Windows et les diagnostics Azure.
Analyse des données de performances
La majeure partie du travail d’analyse consiste à agréger les données de performances par type de demande utilisateur ou par sous-système ou service auquel chaque requête est envoyée. Un exemple de demande d’utilisateur consiste à ajouter un élément à un panier d’achat ou à effectuer le processus de paiement dans un système de commerce électronique.
Une autre exigence courante consiste à résumer les données de performances dans les centiles sélectionnés. Par exemple, un opérateur peut déterminer les temps de réponse pour 99 % des demandes, 95 % des demandes et 70 % des demandes. Il peut y avoir des cibles SLA ou d’autres objectifs définis pour chaque centile. Les résultats en cours doivent être signalés en quasi-temps réel pour aider à détecter les problèmes immédiats. Les résultats doivent également être agrégés plus longtemps à des fins statistiques.
En cas de problèmes de latence affectant les performances, un opérateur doit être en mesure d’identifier rapidement la cause du goulot d’étranglement en examinant la latence de chaque étape effectuée par chaque requête. Les données de performances doivent donc fournir un moyen de mettre en corrélation les mesures de performances pour chaque étape afin de les lier à une demande spécifique.
Selon les exigences de visualisation, il peut être utile de générer et de stocker un cube de données qui contient des vues des données brutes. Ce cube de données peut permettre l’interrogation et l’analyse ad hoc complexes des informations de performances.
Surveillance de la sécurité
Tous les systèmes commerciaux qui incluent des données sensibles doivent implémenter une structure de sécurité. La complexité du mécanisme de sécurité est généralement une fonction de la sensibilité des données. Dans un système qui exige que les utilisateurs soient authentifiés, vous devez enregistrer :
- Toutes les tentatives de connexion, qu’elles échouent ou réussissent.
- Toutes les opérations effectuées par et les détails de toutes les ressources accessibles par un utilisateur authentifié.
- Lorsqu’un utilisateur termine une session et se déconnecte.
La surveillance peut être en mesure de détecter les attaques sur le système. Par exemple, un grand nombre de tentatives de connexion ayant échoué peuvent indiquer une attaque par force brute. Une augmentation inattendue des requêtes peut être le résultat d’une attaque par déni de service distribué (DDoS). Vous devez être prêt à surveiller toutes les demandes adressées à toutes les ressources, quelle que soit la source de ces demandes. Un système qui a une vulnérabilité de connexion peut exposer accidentellement des ressources au monde extérieur sans exiger qu’un utilisateur se connecte réellement.
Conditions requises pour la surveillance de la sécurité
Les aspects les plus critiques de la surveillance de la sécurité doivent permettre à un opérateur de procéder rapidement :
- Détecter les tentatives d’intrusion par une entité non authentifiée.
- Identifiez les tentatives effectuées par les entités pour effectuer des opérations sur les données pour lesquelles elles n’ont pas été autorisées à accéder.
- Déterminez si le système, ou une partie du système, est attaqué à l’extérieur ou à l’intérieur. (Par exemple, un utilisateur authentifié malveillant peut tenter de mettre le système hors service.)
Pour prendre en charge ces exigences, un opérateur doit être averti si :
- Un compte effectue des tentatives de connexion ayant échoué répétées au cours d’une période spécifiée.
- Un compte authentifié tente à plusieurs reprises d’accéder à une ressource interdite pendant une période spécifiée.
- Un grand nombre de requêtes non authentifiées ou non autorisées se produisent pendant une période spécifiée.
Les informations fournies à un opérateur doivent inclure l’adresse hôte de la source pour chaque requête. Si des violations de sécurité proviennent régulièrement d’une plage d’adresses particulière, ces hôtes peuvent être bloqués.
Une partie clé de la maintenance de la sécurité d’un système est en mesure de détecter rapidement les actions qui s’écartent du modèle habituel. Des informations telles que le nombre de demandes de connexion ayant échoué ou réussies peuvent être affichées visuellement pour vous aider à détecter s’il existe un pic d’activité à un moment inhabituel. (Par exemple, les utilisateurs se connectent à 3h00 et effectuent un grand nombre d’opérations lorsque leur journée de travail commence à 9h00). Ces informations peuvent également être utilisées pour configurer la mise à l’échelle automatique basée sur le temps. Par exemple, si un opérateur observe qu’un grand nombre d’utilisateurs se connectent régulièrement à un moment donné de la journée, l’opérateur peut organiser le démarrage de services d’authentification supplémentaires pour gérer le volume de travail, puis arrêter ces services supplémentaires lorsque le pic est passé.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
La sécurité est un aspect englobant de la plupart des systèmes distribués. Les données pertinentes sont susceptibles d’être générées à plusieurs points dans un système. Vous devez envisager d’adopter une approche SIEM (Security Information and Event Management) pour collecter les informations liées à la sécurité résultant des événements déclenchés par l’application, l’équipement réseau, les serveurs, les pare-feu, les logiciels antivirus et d’autres éléments de prévention des intrusions.
La surveillance de la sécurité peut incorporer des données à partir d’outils qui ne font pas partie de votre application. Ces outils peuvent inclure des utilitaires qui identifient les activités d’analyse des ports par des agences externes ou des filtres réseau qui détectent les tentatives d’accès non authentifié à votre application et à vos données.
Dans tous les cas, les données collectées doivent permettre à un administrateur de déterminer la nature de toute attaque et de prendre les contre-mesures appropriées.
Analyse des données de sécurité
Une fonctionnalité de surveillance de la sécurité est la variété de sources à partir desquelles les données se produisent. Les différents formats et le niveau de détail nécessitent souvent une analyse complexe des données capturées pour les lier à un thread cohérent d’informations. En dehors des cas les plus simples (par exemple, la détection d’un grand nombre de connexions ayant échoué ou de tentatives répétées d’accès non autorisé aux ressources critiques), il peut ne pas être possible d’effectuer un traitement automatisé complexe des données de sécurité. Au lieu de cela, il peut être préférable d’écrire ces données, horodatées, mais autrement sous sa forme d’origine, dans un référentiel sécurisé pour permettre une analyse manuelle d’experts.
Surveillance du contrat SLA
De nombreux systèmes commerciaux qui prennent en charge les clients payants garantissent les performances du système sous la forme de contrats SLA. Essentiellement, les contrats SLA indiquent que le système peut gérer un volume de travail défini dans un délai convenu et sans perdre d’informations critiques. La surveillance du contrat SLA s’inquiète de s’assurer que le système peut répondre à des contrats SLA mesurables.
Remarque
La surveillance des contrats SLA est étroitement liée à la surveillance des performances. Mais alors que la surveillance des performances s’inquiète de s’assurer que le système fonctionne de manière optimale, la surveillance du contrat SLA est régie par une obligation contractuelle qui définit ce que signifie de manière optimale .
Les contrats SLA sont souvent définis en termes de :
- Disponibilité globale du système. Par exemple, une organisation peut garantir que le système sera disponible pour 99,9 % du temps. Cela équivaut à pas plus de 9 heures de temps d’arrêt par an, soit environ 10 minutes par semaine.
- Débit opérationnel. Cet aspect est souvent exprimé sous la forme d’une ou plusieurs marques d’eau élevées, telles que la garantie que le système peut prendre en charge jusqu’à 100 000 requêtes utilisateur simultanées ou gérer 10 000 transactions commerciales simultanées.
- Temps de réponse opérationnel. Le système peut également garantir le taux de traitement des demandes. Par exemple, 99 % de toutes les transactions commerciales se termineront dans les 2 secondes, et aucune transaction unique ne prendra plus de 10 secondes.
Remarque
Certains contrats pour les systèmes commerciaux peuvent également inclure des contrats SLA pour le support client. Par exemple, toutes les demandes de support technique déclenchent une réponse dans un délai de cinq minutes, et que 99 % de tous les problèmes seront entièrement résolus dans un délai de 1 jour ouvré. Le suivi efficace des problèmes (décrit plus loin dans cette section) est essentiel à la réunion des contrats SLA tels que ceux-ci.
Conditions requises pour la surveillance du contrat SLA
Au niveau le plus élevé, un opérateur doit être en mesure de déterminer en un clin d’œil si le système rencontre les contrats SLA convenus ou non. Et si ce n’est pas le cas, l’opérateur doit être en mesure d’explorer et d’examiner les facteurs sous-jacents pour déterminer les raisons des performances inférieures.
Les indicateurs généraux typiques qui peuvent être représentés visuellement sont les suivants :
- Pourcentage de temps d’activité du service.
- Débit de l’application (mesuré en termes de transactions ou d’opérations réussies par seconde).
- Nombre de demandes d’application réussies/défaillantes.
- Nombre d’erreurs d’application et système, d’exceptions et d’avertissements.
Tous ces indicateurs doivent être filtrés par une période spécifiée.
Une application cloud comprend probablement un certain nombre de sous-systèmes et de composants. Un opérateur doit pouvoir sélectionner un indicateur de haut niveau et voir comment il est composé à partir de l’intégrité des éléments sous-jacents. Par exemple, si le temps de fonctionnement du système global tombe en dessous d’une valeur acceptable, un opérateur doit pouvoir effectuer un zoom avant et déterminer quels éléments contribuent à cette défaillance.
Remarque
La durée de fonctionnement du système doit être définie avec soin. Dans un système qui utilise la redondance pour garantir la disponibilité maximale, les instances individuelles d’éléments peuvent échouer, mais le système peut rester fonctionnel. Le temps de fonctionnement du système tel qu’il est présenté par la surveillance de l’intégrité doit indiquer la durée de fonctionnement agrégée de chaque élément et non pas nécessairement si le système s’est réellement arrêté. En outre, les défaillances peuvent être isolées. Ainsi, même si un système spécifique n’est pas disponible, le reste du système peut rester disponible, bien qu’avec une fonctionnalité réduite. (Dans un système de commerce électronique, une défaillance dans le système peut empêcher un client de passer des commandes, mais le client peut toujours être en mesure de parcourir le catalogue de produits.)
À des fins d’alerte, le système doit pouvoir déclencher un événement si l’un des indicateurs de haut niveau dépasse un seuil spécifié. Les détails de niveau inférieur des différents facteurs qui composent l’indicateur de haut niveau doivent être disponibles sous forme de données contextuelles pour le système d’alerte.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Les données brutes requises pour prendre en charge la surveillance du contrat SLA sont similaires aux données brutes requises pour l’analyse des performances, ainsi que certains aspects de la surveillance de l’intégrité et de la disponibilité. (Pour plus d’informations, consultez ces sections.) Vous pouvez capturer ces données en procédant comme suit :
- Exécution de la surveillance des points de terminaison.
- Journalisation des exceptions, des erreurs et des avertissements.
- Suivi de l’exécution des demandes utilisateur.
- Surveillance de la disponibilité des services tiers que le système utilise.
- Utilisation de métriques et de compteurs de performances.
Toutes les données doivent être chronométrées et horodatées.
Analyse des données sla
Les données d’instrumentation doivent être agrégées pour générer une image des performances globales du système. Les données agrégées doivent également prendre en charge l’exploration pour permettre l’examen des performances des sous-systèmes sous-jacents. Par exemple, vous devez être en mesure de :
- Calculez le nombre total de requêtes utilisateur pendant une période spécifiée et déterminez le taux de réussite et d’échec de ces demandes.
- Combinez les temps de réponse des demandes utilisateur pour générer une vue globale des temps de réponse système.
- Analysez la progression des demandes utilisateur pour décomposer le temps de réponse global d’une requête en temps de réponse des éléments de travail individuels de cette demande.
- Déterminez la disponibilité globale du système sous la forme d’un pourcentage de temps d’activité pendant une période spécifique.
- Analysez le pourcentage de disponibilité des composants et services individuels dans le système. Cela peut impliquer l’analyse des journaux générés par des services tiers.
De nombreux systèmes commerciaux sont tenus de signaler des chiffres réels sur les performances par rapport aux contrats SLA convenus pour une période spécifiée, généralement un mois. Ces informations peuvent être utilisées pour calculer des crédits ou d’autres formes de remboursement pour les clients si les contrats sla ne sont pas remplis pendant cette période. Vous pouvez calculer la disponibilité d’un service à l’aide de la technique décrite dans la section Analyse des données de disponibilité.
À des fins internes, une organisation peut également suivre le nombre et la nature des incidents qui ont provoqué l’échec des services. Apprendre à résoudre ces problèmes rapidement, ou à les éliminer complètement, aidera à réduire les temps d’arrêt et à répondre aux contrats SLA.
Processus d'audit
Selon la nature de l’application, il peut y avoir des réglementations légales ou légales qui spécifient les exigences d’audit des opérations des utilisateurs et l’enregistrement de tous les accès aux données. L’audit peut fournir des preuves qui relient les clients à des demandes spécifiques. La non-répudiation est un facteur important dans de nombreux systèmes d’entreprise électroniques pour aider à maintenir la confiance entre un client et l’organisation responsable de l’application ou du service.
Conditions requises pour l’audit
Un analyste doit être en mesure de suivre la séquence d’opérations métier que les utilisateurs effectuent afin de pouvoir reconstruire les actions des utilisateurs. Il peut s’agir simplement d’une question de dossier, ou dans le cadre d’une enquête judiciaire.
Les informations d’audit sont très sensibles. Il inclut probablement des données qui identifient les utilisateurs du système, ainsi que les tâches qu’ils effectuent. Pour cette raison, les informations d’audit prendront probablement la forme de rapports qui sont disponibles uniquement pour les analystes approuvés plutôt que comme un système interactif qui prend en charge l’exploration des opérations graphiques. Un analyste doit pouvoir générer une plage de rapports. Par exemple, les rapports peuvent répertorier toutes les activités des utilisateurs se produisant pendant une période donnée, détailler la chronologie de l’activité pour un seul utilisateur ou répertorier la séquence d’opérations effectuées sur une ou plusieurs ressources.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Les principales sources d’informations pour l’audit peuvent inclure :
- Système de sécurité qui gère l’authentification utilisateur.
- Tracez les journaux qui enregistrent l’activité de l’utilisateur.
- Journaux de sécurité qui effectuent le suivi de toutes les demandes réseau identifiables et non identifiables.
Le format des données d’audit et la façon dont elles sont stockées peuvent être pilotées par les exigences réglementaires. Par exemple, il peut ne pas être possible de nettoyer les données de quelque manière que ce soit. (Il doit être enregistré dans son format d’origine.) L’accès au référentiel où il est conservé doit être protégé pour empêcher toute falsification.
Analyse des données d’audit
Un analyste doit pouvoir accéder aux données brutes dans son intégralité, sous sa forme d’origine. Outre la nécessité de générer des rapports d’audit courants, les outils d’analyse de ces données sont susceptibles d’être spécialisés et conservés en externe au système.
Surveillance de l’utilisation
La surveillance de l’utilisation suit la façon dont les fonctionnalités et les composants d’une application sont utilisés. Un opérateur peut utiliser les données collectées pour :
Déterminez les fonctionnalités fortement utilisées et déterminez les points d’accès potentiels dans le système. Les éléments à trafic élevé peuvent tirer parti du partitionnement fonctionnel ou même de la réplication pour répartir la charge plus uniformément. Un opérateur peut également utiliser ces informations pour déterminer quelles caractéristiques sont rarement utilisées et sont des candidats possibles à la mise hors service ou au remplacement dans une version ultérieure du système.
Obtenez des informations sur les événements opérationnels du système en cours d’utilisation normale. Par exemple, dans un site de commerce électronique, vous pouvez enregistrer les informations statistiques sur le nombre de transactions et le volume de clients qui sont responsables d’eux. Ces informations peuvent être utilisées pour la planification de la capacité à mesure que le nombre de clients augmente.
Détecter (éventuellement indirectement) la satisfaction des utilisateurs avec les performances ou les fonctionnalités du système. Par exemple, si un grand nombre de clients dans un système de commerce électronique abandonnent régulièrement leurs paniers d’achat, cela peut être dû à un problème avec la fonctionnalité de paiement.
Générez des informations de facturation. Une application commerciale ou un service multilocataire peut facturer aux clients les ressources qu’ils utilisent.
Appliquer des quotas. Si un utilisateur d’un système multilocataire dépasse son quota payant de temps de traitement ou d’utilisation des ressources pendant une période spécifiée, son accès peut être limité ou le traitement peut être limité.
Conditions requises pour la surveillance de l’utilisation
Pour examiner l’utilisation du système, un opérateur doit généralement voir les informations qui incluent :
- Nombre de requêtes traitées par chaque sous-système et dirigées vers chaque ressource.
- Travail effectué par chaque utilisateur.
- Volume de stockage de données occupé par chaque utilisateur.
- Ressources auxquelles chaque utilisateur accède.
Un opérateur doit également être en mesure de générer des graphiques. Par exemple, un graphique peut afficher les utilisateurs les plus affamés de ressources, ou les ressources ou fonctionnalités système les plus fréquemment sollicitées.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
Le suivi de l’utilisation peut être effectué à un niveau relativement élevé. Il peut noter les heures de début et de fin de chaque requête et la nature de la requête (lecture, écriture, etc., en fonction de la ressource en question). Vous pouvez obtenir ces informations en procédant comme suit :
- Suivi de l’activité utilisateur.
- Capture de compteurs de performances qui mesurent l’utilisation de chaque ressource.
- Surveillance de la consommation des ressources par chaque utilisateur.
À des fins de contrôle, vous devez également être en mesure d’identifier les utilisateurs responsables de l’exécution des opérations et des ressources utilisées par ces opérations. Les informations collectées doivent être suffisamment détaillées pour permettre une facturation précise.
Suivi des problèmes
Les clients et d’autres utilisateurs peuvent signaler des problèmes si des événements ou comportements inattendus se produisent dans le système. Le suivi des problèmes concerne la gestion de ces problèmes, en les associant à des efforts visant à résoudre les problèmes sous-jacents du système et à informer les clients des solutions possibles.
Conditions requises pour le suivi des problèmes
Les opérateurs effectuent souvent un suivi des problèmes à l’aide d’un système distinct qui leur permet d’enregistrer et de signaler les détails des problèmes que les utilisateurs signalent. Ces détails peuvent inclure les tâches que l’utilisateur essayait d’effectuer, les symptômes du problème, la séquence d’événements et les messages d’erreur ou d’avertissement émis.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
La source de données initiale pour les données de suivi des problèmes est l’utilisateur qui a signalé le problème en premier lieu. L’utilisateur peut être en mesure de fournir des données supplémentaires telles que :
- Vidage sur incident (si l’application inclut un composant qui s’exécute sur le bureau de l’utilisateur).
- Capture instantanée d’écran.
- Date et heure auxquelles l’erreur s’est produite, ainsi que d’autres informations environnementales telles que l’emplacement de l’utilisateur.
Ces informations peuvent être utilisées pour aider l’effort de débogage et aider à construire un backlog pour les futures versions du logiciel.
Analyse des données de suivi des problèmes
Différents utilisateurs peuvent signaler le même problème. Le système de suivi des problèmes doit associer des rapports courants.
La progression de l’effort de débogage doit être enregistrée par rapport à chaque rapport de problème. Lorsque le problème est résolu, le client peut être informé de la solution.
Si un utilisateur signale un problème qui a une solution connue dans le système de suivi des problèmes, l’opérateur doit être en mesure d’informer immédiatement l’utilisateur de la solution.
Opérations de suivi et débogage des versions logicielles
Lorsqu’un utilisateur signale un problème, l’utilisateur n’est souvent conscient que de l’effet immédiat qu’il a sur ses opérations. L’utilisateur peut uniquement signaler les résultats de sa propre expérience à un opérateur responsable de la maintenance du système. Ces expériences ne sont généralement qu’un symptôme visible d’un ou plusieurs problèmes fondamentaux. Dans de nombreux cas, un analyste devra explorer la chronologie des opérations sous-jacentes pour établir la cause racine du problème. Ce processus est appelé analyse de la cause racine.
Remarque
L’analyse de la cause racine peut révéler des inefficacités dans la conception d’une application. Dans ces situations, il peut être possible de retravailler les éléments affectés et de les déployer dans le cadre d’une version ultérieure. Ce processus nécessite un contrôle prudent et les composants mis à jour doivent être surveillés de près.
Configuration requise pour le suivi et le débogage
Pour le suivi d’événements inattendus et d’autres problèmes, il est essentiel que les données de surveillance fournissent suffisamment d’informations pour permettre à un analyste de remonter aux origines de ces problèmes et de reconstruire la séquence d’événements qui se sont produits. Ces informations doivent être suffisantes pour permettre à un analyste de diagnostiquer la cause racine des problèmes. Un développeur peut ensuite apporter les modifications nécessaires pour les empêcher de se périodiquer.
Exigences en matière de sources de données, d’instrumentation et de collecte de données
La résolution des problèmes peut impliquer le suivi de toutes les méthodes (et de leurs paramètres) appelées dans le cadre d’une opération pour créer une arborescence qui représente le flux logique via le système lorsqu’un client effectue une requête spécifique. Les exceptions et les avertissements générés par le système en raison de ce flux doivent être capturés et enregistrés.
Pour prendre en charge le débogage, le système peut fournir des hooks qui permettent à un opérateur de capturer des informations d’état à des points essentiels du système. Ou bien, le système peut fournir des informations détaillées détaillées au fur et à mesure que les opérations sélectionnées progressent. La capture de données à ce niveau de détail peut imposer une charge supplémentaire sur le système et doit être un processus temporaire. Un opérateur utilise ce processus principalement lorsqu’une série d’événements très inhabituelle se produit et est difficile à répliquer, ou lorsqu’une nouvelle version d’un ou plusieurs éléments dans un système nécessite une surveillance minutieuse pour s’assurer que les éléments fonctionnent comme prévu.
Pipeline de surveillance et de diagnostic
La surveillance d’un système distribué à grande échelle constitue une difficulté importante. Chacun des scénarios décrits dans la section précédente ne doit pas nécessairement être pris en compte séparément. Il est probable qu’il y ait un chevauchement important dans les données de surveillance et de diagnostic requises pour chaque situation, bien que ces données puissent être traitées et présentées de différentes manières. Pour ces raisons, vous devez avoir une vue holistique de la surveillance et des diagnostics.
Vous pouvez envisager l’ensemble du processus de surveillance et de diagnostic en tant que pipeline qui comprend les étapes indiquées dans la figure 1.
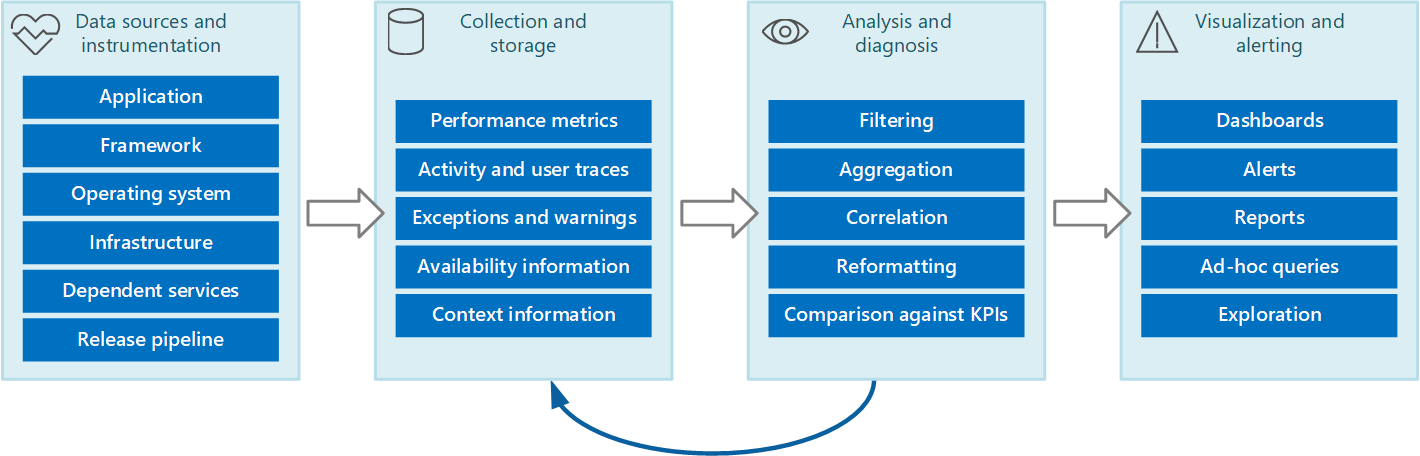
Figure 1 : étapes du pipeline de surveillance et de diagnostic.
La figure 1 met en évidence la façon dont les données pour la surveillance et les diagnostics peuvent provenir de diverses sources de données. Les étapes d’instrumentation et de collecte sont concernées par l’identification des sources à partir desquelles les données doivent être capturées, en déterminant les données à capturer, comment les capturer et comment mettre en forme ces données afin qu’elles puissent être facilement examinées. L’étape d’analyse/diagnostic prend les données brutes et l’utilise pour générer des informations significatives qu’un opérateur peut utiliser pour déterminer l’état du système. L’opérateur peut utiliser ces informations pour prendre des décisions sur les actions possibles à entreprendre, puis alimenter les résultats dans les phases d’instrumentation et de collecte. La phase de visualisation/d’alerte présente une vue consommable de l’état du système. Il peut afficher des informations en quasi temps réel à l’aide d’une série de tableaux de bord. Il peut également générer des rapports, des graphiques et des graphiques pour fournir une vue historique des données qui peuvent aider à identifier les tendances à long terme. Si des informations indiquent qu’un indicateur de performance clé est susceptible de dépasser les limites acceptables, cette étape peut également déclencher une alerte à un opérateur. Dans certains cas, une alerte peut également être utilisée pour déclencher un processus automatisé qui tente d’effectuer des actions correctives, telles que la mise à l’échelle automatique.
Notez que ces étapes constituent un processus de flux continu où les étapes se produisent en parallèle. Dans l’idéal, toutes les phases doivent être configurables dynamiquement. À certains moments, en particulier lorsqu’un système a été récemment déployé ou rencontre des problèmes, il peut être nécessaire de collecter des données étendues sur une base plus fréquente. À d’autres moments, il devrait être possible de rétablir le niveau de base des informations essentielles pour vérifier que le système fonctionne correctement.
En outre, l’ensemble du processus de surveillance doit être considéré comme une solution en direct et en cours qui est soumise à un réglage précis et à des améliorations à la suite de commentaires. Par exemple, vous pouvez commencer par mesurer de nombreux facteurs pour déterminer l’intégrité du système. L’analyse au fil du temps peut entraîner un affinement lorsque vous ignorez les mesures qui ne sont pas pertinentes, ce qui vous permet de vous concentrer plus précisément sur les données dont vous avez besoin tout en réduisant le bruit d’arrière-plan.
Sources de données de surveillance et de diagnostic
Les informations que le processus de surveillance utilise peuvent provenir de plusieurs sources, comme illustré dans la figure 1. Au niveau de l’application, les informations proviennent des journaux de trace incorporés dans le code du système. Les développeurs doivent suivre une approche standard pour suivre le flux de contrôle par le biais de leur code. Par exemple, une entrée à une méthode peut émettre un message de trace qui spécifie le nom de la méthode, l’heure actuelle, la valeur de chaque paramètre et toute autre information pertinente. L’enregistrement des heures d’entrée et de sortie peut également s’avérer utile.
Vous devez enregistrer toutes les exceptions et avertissements, et vous assurer de conserver une trace complète des exceptions et avertissements imbriqués. Dans l’idéal, vous devez également capturer des informations qui identifient l’utilisateur qui exécute le code, ainsi que des informations de corrélation d’activité (pour suivre les demandes à mesure qu’elles passent par le système). Vous devez également consigner les tentatives d’accès à toutes les ressources telles que les files d’attente de messages, les bases de données, les fichiers et d’autres services dépendants. Ces informations peuvent être utilisées à des fins de contrôle et d’audit.
De nombreuses applications utilisent des bibliothèques et des frameworks pour effectuer des tâches courantes telles que l’accès à un magasin de données ou la communication sur un réseau. Ces infrastructures peuvent être configurables pour fournir leurs propres messages de suivi et informations de diagnostic brutes, telles que les taux de transaction et les échecs de transmission des données.
Remarque
De nombreux frameworks modernes publient automatiquement des événements de performances et de trace. La capture de ces informations est simplement une question de fournir un moyen de récupérer et de stocker ces informations là où elles peuvent être traitées et analysées.
Le système d’exploitation sur lequel l’application s’exécute peut être une source d’informations à l’échelle du système de bas niveau, telles que des compteurs de performances qui indiquent les taux d’E/S, l’utilisation de la mémoire et l’utilisation du processeur. Les erreurs du système d’exploitation (telles que l’échec de l’ouverture d’un fichier correctement) peuvent également être signalées.
Vous devez également prendre en compte l’infrastructure et les composants sous-jacents sur lesquels votre système s’exécute. Les machines virtuelles, les réseaux virtuels et les services de stockage peuvent toutes être des sources de compteurs de performances importants au niveau de l’infrastructure et d’autres données de diagnostic.
Si votre application utilise d’autres services externes, tels qu’un serveur web ou un système de gestion de base de données, ces services peuvent publier leurs propres informations de trace, journaux et compteurs de performances. Par exemple, les vues de gestion dynamique SQL Server pour le suivi des opérations effectuées sur une base de données SQL Server et les journaux de trace IIS pour enregistrer les demandes adressées à un serveur web.
À mesure que les composants d’un système sont modifiés et que de nouvelles versions sont déployées, il est important de pouvoir attribuer des problèmes, des événements et des métriques à chaque version. Ces informations doivent être liées au pipeline de mise en production afin que les problèmes liés à une version spécifique d’un composant puissent être suivis rapidement et rectifiés.
Les problèmes de sécurité peuvent se produire à tout moment dans le système. Par exemple, un utilisateur peut tenter de se connecter avec un ID d’utilisateur ou un mot de passe non valide. Un utilisateur authentifié peut essayer d’obtenir un accès non autorisé à une ressource. Ou un utilisateur peut fournir une clé non valide ou obsolète pour accéder aux informations chiffrées. Les informations relatives à la sécurité pour les demandes réussies et ayant échoué doivent toujours être journalisées.
La section Instrumenter une application contient des conseils supplémentaires sur les informations que vous devez capturer. Toutefois, vous pouvez utiliser diverses stratégies pour collecter ces informations :
Surveillance de l’application/du système. Cette stratégie utilise des sources internes au sein de l’application, des infrastructures d’application, du système d’exploitation et de l’infrastructure. Le code de l’application peut générer ses propres données de surveillance à des points notables pendant le cycle de vie d’une demande cliente. L’application peut inclure des instructions de suivi qui peuvent être activées ou désactivées de manière sélective à mesure que les circonstances le dictent. Il peut également être possible d’injecter des diagnostics dynamiquement à l’aide d’une infrastructure de diagnostics. Ces frameworks fournissent généralement des plug-ins qui peuvent s’attacher à différents points d’instrumentation dans votre code et capturer des données de trace à ces points.
En outre, votre code ou l’infrastructure sous-jacente peut déclencher des événements à des points critiques. Les agents de surveillance configurés pour écouter ces événements peuvent enregistrer les informations d’événement.
Surveillance des utilisateurs réels. Cette approche enregistre les interactions entre un utilisateur et l’application et observe le flux de chaque demande et réponse. Ces informations peuvent avoir un objectif à deux fois : elles peuvent être utilisées pour mesurer l’utilisation par chaque utilisateur, et elles peuvent être utilisées pour déterminer si les utilisateurs reçoivent une qualité de service appropriée (par exemple, des temps de réponse rapides, une faible latence et des erreurs minimales). Vous pouvez utiliser les données capturées pour identifier les zones de préoccupation où les défaillances se produisent le plus souvent. Vous pouvez également utiliser les données pour identifier les éléments où le système ralentit, éventuellement en raison de points d’accès dans l’application ou d’une autre forme de goulot d’étranglement. Si vous implémentez cette approche avec soin, il peut être possible de reconstruire les flux des utilisateurs via l’application à des fins de débogage et de test.
Important
Vous devez prendre en compte les données capturées par la surveillance des utilisateurs réels afin qu’elles soient très sensibles, car elles peuvent inclure des documents confidentiels. Si vous enregistrez des données capturées, stockez-les en toute sécurité. Si vous souhaitez utiliser les données à des fins de supervision ou de débogage des performances, supprimez d’abord toutes les données personnelles.
Surveillance des utilisateurs synthétiques. Dans cette approche, vous écrivez votre propre client de test qui simule un utilisateur et effectue une série configurable mais classique d’opérations. Vous pouvez suivre les performances du client de test pour déterminer l’état du système. Vous pouvez également utiliser plusieurs instances du client de test dans le cadre d’une opération de test de charge pour établir la façon dont le système répond sous contrainte et quel type de sortie de surveillance est généré dans ces conditions.
Remarque
Vous pouvez implémenter la surveillance des utilisateurs réels et synthétiques en incluant du code qui trace et times l’exécution des appels de méthode et d’autres parties critiques d’une application.
Profilage. Cette approche est principalement destinée à la surveillance et à l’amélioration des performances des applications. Au lieu de fonctionner au niveau fonctionnel de la surveillance des utilisateurs réels et synthétiques, il capture les informations de niveau inférieur à mesure que l’application s’exécute. Vous pouvez implémenter le profilage à l’aide de l’échantillonnage périodique de l’état d’exécution d’une application (déterminant l’élément de code exécuté par l’application à un moment donné). Vous pouvez également utiliser l’instrumentation qui insère des sondes dans le code à des junctures importants (par exemple, le début et la fin d’un appel de méthode) et enregistre les méthodes qui ont été appelées, à quel moment et combien de temps chaque appel a pris. Vous pouvez ensuite analyser ces données pour déterminer quelles parties de l’application peuvent entraîner des problèmes de performances.
Surveillance des points de terminaison. Cette technique utilise un ou plusieurs points de terminaison de diagnostic que l’application expose spécifiquement pour activer la surveillance. Un point de terminaison fournit un chemin d’accès au code d’application et peut retourner des informations sur l’intégrité du système. Différents points de terminaison peuvent se concentrer sur différents aspects de la fonctionnalité. Vous pouvez écrire votre propre client de diagnostic qui envoie des demandes périodiques à ces points de terminaison et assimiler les réponses. Pour plus d’informations, consultez le modèle de surveillance des points de terminaison d’intégrité.
Pour une couverture maximale, vous devez utiliser une combinaison de ces techniques.
Instrumentage d’une application
L’instrumentation est une partie essentielle du processus de surveillance. Vous pouvez prendre des décisions significatives sur les performances et l’intégrité d’un système uniquement si vous capturez d’abord les données qui vous permettent de prendre ces décisions. Les informations que vous collectez à l’aide de l’instrumentation doivent être suffisantes pour vous permettre d’évaluer les performances, de diagnostiquer les problèmes et de prendre des décisions sans que vous deviez vous connecter à un serveur de production distant pour effectuer le suivi (et le débogage) manuellement. Les données d’instrumentation comprennent généralement des métriques et des informations écrites dans les journaux de suivi.
Le contenu d’un journal de suivi peut être le résultat de données textuelles écrites par l’application ou les données binaires créées à la suite d’un événement de trace, si l’application utilise le suivi d’événements pour Windows (ETW). Ils peuvent également être générés à partir de journaux système qui enregistrent des événements provenant de parties de l’infrastructure, comme un serveur web. Les messages de journal textuels sont souvent conçus pour être lisibles par l’homme, mais ils doivent également être écrits dans un format qui permet à un système automatisé de les analyser facilement.
Vous devez également catégoriser les journaux. N’écrivez pas toutes les données de trace dans un journal unique, mais utilisez des journaux distincts pour enregistrer la sortie de trace à partir de différents aspects opérationnels du système. Vous pouvez ensuite filtrer rapidement les messages de journal en lisant le journal approprié plutôt que de devoir traiter un seul fichier long. N’écrivez jamais d’informations qui ont des exigences de sécurité différentes (telles que les informations d’audit et le débogage des données) dans le même journal.
Remarque
Un journal peut être implémenté en tant que fichier sur le système de fichiers, ou il peut être conservé dans un autre format, tel qu’un objet blob dans le stockage d’objets blob. Les informations de journal peuvent également être conservées dans un stockage plus structuré, comme les lignes d’une table.
Les métriques sont généralement une mesure ou un nombre d’aspects ou de ressources dans le système à un moment spécifique, avec une ou plusieurs balises ou dimensions associées (parfois appelées échantillon). Une seule instance d’une métrique n’est généralement pas utile en isolation. Au lieu de cela, les métriques doivent être capturées au fil du temps. Le problème clé à prendre en compte est les métriques que vous devez enregistrer et la fréquence à laquelle vous devez procéder. La génération de données pour les métriques peut trop souvent imposer une charge supplémentaire importante sur le système, tandis que la capture de métriques peu fréquentes peut vous entraîner à manquer les circonstances qui entraînent un événement significatif. Les considérations varient d’une métrique à l’autre. Par exemple, l’utilisation du processeur sur un serveur peut varier considérablement de la seconde à la seconde, mais l’utilisation élevée devient un problème uniquement s’il est de longue durée sur un certain nombre de minutes.
Informations sur la corrélation des données
Vous pouvez facilement surveiller des compteurs de performances individuels au niveau du système, capturer des métriques pour les ressources et obtenir des informations de suivi d’application à partir de différents fichiers journaux. Toutefois, certaines formes de surveillance nécessitent l’étape d’analyse et de diagnostic dans le pipeline de surveillance pour mettre en corrélation les données récupérées à partir de plusieurs sources. Ces données peuvent prendre plusieurs formes dans les données brutes, et le processus d’analyse doit être fourni avec suffisamment de données d’instrumentation pour pouvoir mapper ces différentes formes. Par exemple, au niveau de l’infrastructure d’application, une tâche peut être identifiée par un ID de thread. Dans une application, le même travail peut être associé à l’ID utilisateur de l’utilisateur qui effectue cette tâche.
En outre, il est peu probable qu’il existe un mappage 1:1 entre les threads et les requêtes utilisateur, car les opérations asynchrones peuvent réutiliser les mêmes threads pour effectuer des opérations au nom de plusieurs utilisateurs. Pour compliquer davantage les questions, une seule requête peut être gérée par plusieurs threads à mesure que l’exécution transite par le système. Si possible, associez chaque requête à un ID d’activité unique propagé via le système dans le cadre du contexte de la requête. (La technique de génération et d’inclusion d’ID d’activité dans les informations de trace dépend de la technologie utilisée pour capturer les données de trace.)
Toutes les données de surveillance doivent être horodatées de la même façon. Pour une cohérence, enregistrez toutes les dates et toutes les heures à l’aide du temps universel coordonné. Cela vous aidera à suivre plus facilement les séquences d’événements.
Remarque
Les ordinateurs fonctionnant dans différents fuseaux horaires et réseaux peuvent ne pas être synchronisés. Ne dépendez pas de l’utilisation des horodatages seuls pour la corrélation des données d’instrumentation qui s’étendent sur plusieurs machines.
Informations à inclure dans les données d’instrumentation
Tenez compte des points suivants lorsque vous décidez des données d’instrumentation que vous devez collecter :
Assurez-vous que les informations capturées par les événements de trace sont lisibles par les ordinateurs et les personnes. Adoptez des schémas bien définis pour ces informations afin de faciliter le traitement automatisé des données de journal sur les systèmes et de fournir une cohérence aux opérations et au personnel d’ingénierie lisant les journaux. Incluez des informations environnementales, telles que l’environnement de déploiement, l’ordinateur sur lequel le processus est en cours d’exécution, les détails du processus et la pile des appels.
Activez le profilage uniquement si nécessaire, car il peut imposer une surcharge importante sur le système. Le profilage à l’aide d’enregistrements d’instrumentation enregistre un événement (tel qu’un appel de méthode) chaque fois qu’il se produit, tandis que l’échantillonnage enregistre uniquement les événements sélectionnés. La sélection peut être basée sur le temps (une fois toutes les n secondes) ou sur une fréquence (une fois par requête). Si des événements se produisent très fréquemment, le profilage par instrumentation peut entraîner trop de charge et affecter lui-même les performances globales. Dans ce cas, l’approche d’échantillonnage peut être préférable. Toutefois, si la fréquence des événements est faible, l’échantillonnage peut les manquer. Dans ce cas, l’instrumentation peut être la meilleure approche.
Fournissez un contexte suffisant pour permettre à un développeur ou à un administrateur de déterminer la source de chaque requête. Cela peut inclure une forme d’ID d’activité qui identifie une instance spécifique d’une requête. Il peut également inclure des informations qui peuvent être utilisées pour mettre en corrélation cette activité avec le travail de calcul effectué et les ressources utilisées. Notez que ce travail peut traverser les limites du processus et de l’ordinateur. Pour le contrôle, le contexte doit également inclure (directement ou indirectement par le biais d’autres informations corrélées) une référence au client qui a provoqué la demande. Ce contexte fournit des informations précieuses sur l’état de l’application au moment où les données de surveillance ont été capturées.
Enregistrez toutes les requêtes, ainsi que les emplacements ou régions à partir desquels ces demandes sont effectuées. Ces informations peuvent aider à déterminer s’il existe des points d’accès spécifiques à l’emplacement. Ces informations peuvent également être utiles pour déterminer s’il faut repartitionner une application ou les données qu’elle utilise.
Enregistrez et capturez attentivement les détails des exceptions. Souvent, les informations de débogage critiques sont perdues en raison d’une mauvaise gestion des exceptions. Capturez les détails complets des exceptions levées par l’application, y compris les exceptions internes et d’autres informations de contexte. Incluez la pile des appels si possible.
Soyez cohérent dans les données que les différents éléments de votre application capturent, car cela peut vous aider à analyser les événements et à les mettre en corrélation avec les demandes utilisateur. Envisagez d’utiliser un package de journalisation complet et configurable pour collecter des informations, plutôt que selon les développeurs pour adopter la même approche qu’ils implémentent différentes parties du système. Collectez des données à partir de compteurs de performances clés, telles que le volume d’E/S en cours d’exécution, l’utilisation du réseau, le nombre de requêtes, l’utilisation de la mémoire et l’utilisation du processeur. Certains services d’infrastructure peuvent fournir leurs propres compteurs de performances spécifiques, tels que le nombre de connexions à une base de données, le taux d’exécution des transactions et le nombre de transactions qui réussissent ou échouent. Les applications peuvent également définir leurs propres compteurs de performances spécifiques.
Journalisez tous les appels effectués vers des services externes, tels que des systèmes de base de données, des services web ou d’autres services au niveau du système qui font partie de l’infrastructure. Enregistrez des informations sur le temps nécessaire pour effectuer chaque appel, ainsi que la réussite ou l’échec de l’appel. Si possible, capturez des informations sur toutes les tentatives de nouvelle tentative et les échecs pour toutes les erreurs temporaires qui se produisent.
Garantir la compatibilité avec les systèmes de télémétrie
Dans de nombreux cas, les informations produites par l’instrumentation sont générées sous la forme d’une série d’événements et transmises à un système de télémétrie distinct pour le traitement et l’analyse. Un système de télémétrie est généralement indépendant de toute application ou technologie spécifique, mais il s’attend à ce que les informations suivent un format spécifique généralement défini par un schéma. Le schéma spécifie efficacement un contrat qui définit les champs de données et les types que le système de télémétrie peut ingérer. Le schéma doit être généralisé pour permettre l’arrivée de données à partir d’une gamme de plateformes et d’appareils.
Un schéma commun doit inclure des champs communs à tous les événements d’instrumentation, tels que le nom de l’événement, l’heure de l’événement, l’adresse IP de l’expéditeur et les détails requis pour la corrélation avec d’autres événements (tels qu’un ID d’utilisateur, un ID d’appareil et un ID d’application). N’oubliez pas que n’importe quel nombre d’appareils peut déclencher des événements. Par conséquent, le schéma ne doit pas dépendre du type d’appareil. En outre, différents appareils peuvent déclencher des événements pour la même application ; l’application peut prendre en charge l’itinérance ou une autre forme de distribution inter-appareils.
Le schéma peut également inclure des champs de domaine pertinents pour un scénario particulier commun entre différentes applications. Il peut s’agir d’informations sur les exceptions, les événements de démarrage et de fin de l’application, ainsi que la réussite ou l’échec des appels d’API de service web. Toutes les applications qui utilisent le même ensemble de champs de domaine doivent émettre le même ensemble d’événements, ce qui permet de créer un ensemble de rapports et d’analyses communs.
Enfin, un schéma peut contenir des champs personnalisés pour capturer les détails des événements spécifiques à l’application.
Meilleures pratiques pour instrumenter des applications
La liste suivante récapitule les meilleures pratiques pour instrumenter une application distribuée s’exécutant dans le cloud.
Facilitez la lecture et l’analyse des journaux. Utilisez la journalisation structurée si possible. Soyez concis et descriptif dans les messages de journal.
Dans tous les journaux, identifiez la source et fournissez des informations de contexte et de minutage à mesure que chaque enregistrement de journal est écrit.
Utilisez le même fuseau horaire et le même format pour tous les horodatages. Cela permet de mettre en corrélation des événements pour les opérations qui s’étendent sur le matériel et les services exécutés dans différentes régions géographiques.
Classez les journaux et écrivez des messages dans le fichier journal approprié.
Ne divulguez pas d’informations sensibles sur le système ou les informations personnelles sur les utilisateurs. Nettoyez ces informations avant de les enregistrer, mais assurez-vous que les détails pertinents sont conservés. Par exemple, supprimez l’ID et le mot de passe de toutes les chaînes de connexion de base de données, mais écrivez les informations restantes dans le journal afin qu’un analyste puisse déterminer que le système accède à la base de données appropriée. Journaliser toutes les exceptions critiques, mais permettre à l’administrateur d’activer et de désactiver la journalisation pour des niveaux inférieurs d’exceptions et d’avertissements. En outre, capturez et journaliser toutes les informations logiques de nouvelle tentative. Ces données peuvent être utiles pour surveiller l’intégrité temporaire du système.
Tracez les appels de processus, tels que les demandes adressées à des services web externes ou des bases de données.
Ne mélangez pas les messages de journal avec différentes exigences de sécurité dans le même fichier journal. Par exemple, n’écrivez pas les informations de débogage et d’audit dans le même journal.
À l’exception des événements d’audit, assurez-vous que tous les appels de journalisation sont des opérations fire-and-forget qui ne bloquent pas la progression des opérations métier. Les événements d’audit sont exceptionnels, car ils sont essentiels pour l’entreprise et peuvent être classés comme une partie fondamentale des opérations commerciales.
Assurez-vous que la journalisation est extensible et n’a aucune dépendance directe sur une cible concrète. Par exemple, au lieu d’écrire des informations à l’aide de System.Diagnostics.Trace, définissez une interface abstraite (telle que ILogger) qui expose les méthodes de journalisation et qui peut être implémentée par n’importe quel moyen approprié.
Assurez-vous que toutes les journaux d’enregistrement ne sont pas sécurisées et ne déclenchent jamais d’erreurs en cascade. La journalisation ne doit lever aucune exception.
Traitez l’instrumentation comme un processus itératif continu et examinez régulièrement les journaux d’activité, pas seulement lorsqu’il y a un problème.
Collecte et stockage de données
L’étape de collecte du processus de surveillance concerne la récupération des informations générées par l’instrumentation, la mise en forme de ces données afin de faciliter l’utilisation de l’étape d’analyse/diagnostic et l’enregistrement des données transformées dans un stockage fiable. Les données d’instrumentation que vous collectez à partir de différentes parties d’un système distribué peuvent être conservées dans divers emplacements et avec différents formats. Par exemple, votre code d’application peut générer des fichiers journaux de trace et générer des données de journal des événements d’application, tandis que les compteurs de performances qui surveillent les aspects clés de l’infrastructure que votre application utilise peuvent être capturés via d’autres technologies. Tous les composants et services tiers utilisés par votre application peuvent fournir des informations d’instrumentation dans différents formats, à l’aide de fichiers de trace distincts, de stockage d’objets blob ou même d’un magasin de données personnalisé.
La collecte de données est souvent effectuée via un service de collecte qui peut s’exécuter de manière autonome à partir de l’application qui génère les données d’instrumentation. La figure 2 illustre un exemple de cette architecture, mettant en évidence le sous-système de collecte de données d’instrumentation.
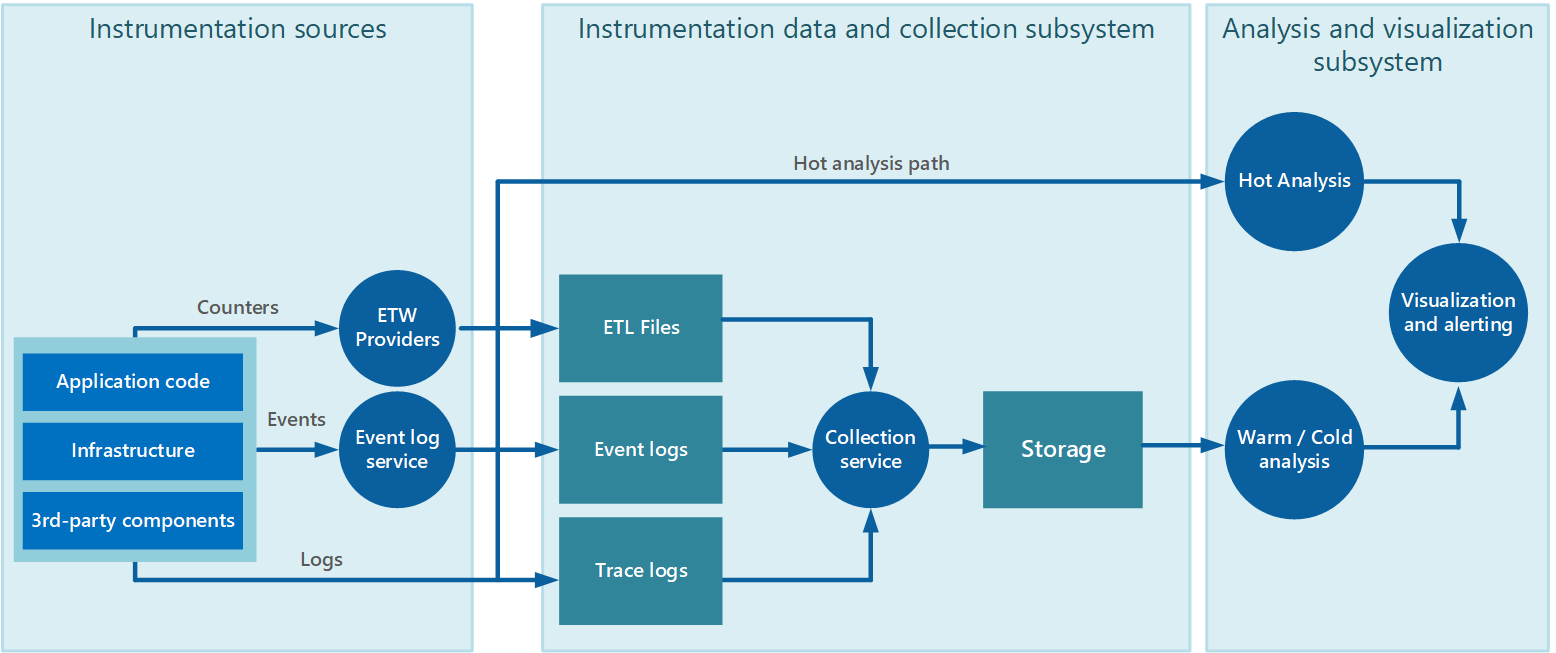
Figure 2 : collecte des données d’instrumentation.
Notez qu’il s’agit d’une vue simplifiée. Le service de collecte n’est pas nécessairement un processus unique et peut comporter de nombreuses parties constituantes s’exécutant sur différents ordinateurs, comme décrit dans les sections suivantes. En outre, si l’analyse de certaines données de télémétrie doit être effectuée rapidement (analyse à chaud, comme décrit dans la section Prise en charge de l’analyse chaude, chaude et froide plus loin dans ce document), les composants locaux qui fonctionnent en dehors du service de collecte peuvent effectuer immédiatement les tâches d’analyse. La figure 2 illustre cette situation pour les événements sélectionnés. Après le traitement analytique, les résultats peuvent être envoyés directement au sous-système de visualisation et d’alerte. Les données soumises à une analyse chaude ou froide sont conservées dans le stockage pendant qu’elles attendent le traitement.
Pour les applications et services Azure, Azure Diagnostics fournit une solution possible pour capturer des données. Diagnostics Azure collecte des données à partir des sources suivantes pour chaque nœud de calcul, l’agrège, puis le charge dans Stockage Azure :
- Journaux IIS
- Journaux des demandes ayant échoué IIS
- Journaux des événements Windows
- Compteurs de performances
- Vidages sur incident
- Journaux d’activité d’infrastructure de diagnostics Azure
- Journaux d’activité d’erreurs personnalisés
- .NET EventSource
- Suivi d’événements pour Windows basé sur les manifestes
Pour plus d’informations, consultez l’article Azure : Telemetry Basics and Troubleshooting.
Stratégies de collecte des données d’instrumentation
Compte tenu de la nature élastique du cloud et d’éviter la nécessité de récupérer manuellement les données de télémétrie à partir de chaque nœud du système, vous devez organiser le transfert des données vers un emplacement central et consolidé. Dans un système qui s’étend sur plusieurs centres de données, il peut être utile de collecter, consolider et stocker des données sur une base régionale par région, puis d’agréger les données régionales dans un système central unique.
Pour optimiser l’utilisation de la bande passante, vous pouvez choisir de transférer des données moins urgentes en blocs, en tant que lots. Toutefois, les données ne doivent pas être retardées indéfiniment, en particulier si elles contiennent des informations sensibles dans le temps.
Extraction et envoi (push) de données d’instrumentation
Le sous-système de collecte de données d’instrumentation peut récupérer activement les données d’instrumentation des différents journaux et d’autres sources pour chaque instance de l’application (le modèle d’extraction). Il peut également agir en tant que récepteur passif qui attend que les données soient envoyées à partir des composants qui constituent chaque instance de l’application (le modèle Push).
Une approche de l’implémentation du modèle collecteur consiste à utiliser des agents de surveillance qui s’exécutent localement avec chaque instance de l’application. Un agent de surveillance est un processus distinct qui récupère régulièrement (pulls) les données de télémétrie collectées au niveau du nœud local et écrit ces informations directement dans le stockage centralisé que toutes les instances du partage d’application. Il s’agit du mécanisme implémenté par Azure Diagnostics. Chaque instance d’un rôle web ou de travail Azure peut être configurée pour capturer des informations de diagnostic et d’autres informations de trace stockées localement. L’agent de surveillance qui s’exécute en même temps que chaque instance copie les données spécifiées dans Stockage Azure. L’article Activation des diagnostics dans Les services cloud Azure et les machines virtuelles fournit plus de détails sur ce processus. Certains éléments, tels que les journaux IIS, les vidages sur incident et les journaux d’erreurs personnalisés, sont écrits dans le stockage d’objets blob. Les données du journal des événements Windows, des événements ETW et des compteurs de performances sont enregistrées dans le stockage de tables. La figure 3 illustre ce mécanisme.
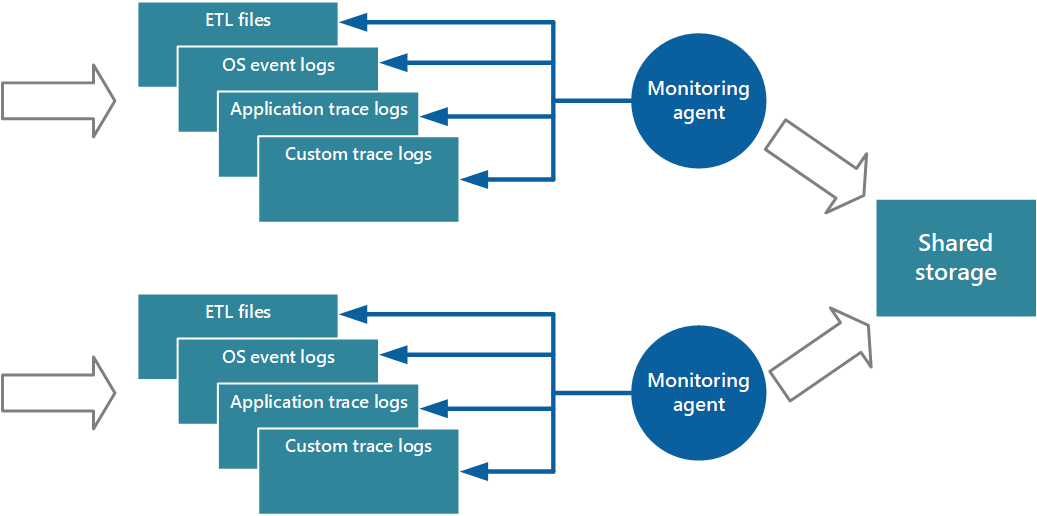
Figure 3 : Utilisation d’un agent de surveillance pour extraire des informations et écrire dans un stockage partagé.
Remarque
L’utilisation d’un agent de surveillance est idéale pour capturer des données d’instrumentation qui sont naturellement extraites d’une source de données. Voici un exemple d’informations provenant de vues de gestion dynamique SQL Server ou de la longueur d’une file d’attente Azure Service Bus.
Il est possible d’utiliser l’approche décrite simplement pour stocker les données de télémétrie pour une application à petite échelle s’exécutant sur un nombre limité de nœuds dans un emplacement unique. Toutefois, une application cloud globale complexe et hautement évolutive peut générer d’énormes volumes de données à partir de centaines de rôles web et de travail, de partitions de base de données et d’autres services. Cette inondation de données peut facilement submerger la bande passante d’E/S disponible avec un emplacement central unique. Par conséquent, votre solution de télémétrie doit être évolutive pour l’empêcher d’agir comme un goulot d’étranglement au fur et à mesure que le système se développe. Dans l’idéal, votre solution doit incorporer un degré de redondance pour réduire les risques de perte d’informations de surveillance importantes (telles que l’audit ou les données de facturation) si une partie du système échoue.
Pour résoudre ces problèmes, vous pouvez implémenter la mise en file d’attente, comme illustré dans la figure 4. Dans cette architecture, l’agent de surveillance local (s’il peut être configuré de manière appropriée) ou le service de collecte de données personnalisé (si ce n’est pas le cas) publie des données dans une file d’attente. Un processus distinct s’exécutant de manière asynchrone (le service d’écriture de stockage dans la figure 4) prend les données de cette file d’attente et les écrit dans le stockage partagé. Une file d’attente de messages convient à ce scénario, car elle fournit une sémantique « au moins une fois » qui permet de s’assurer que les données mises en file d’attente ne seront pas perdues après sa publication. Vous pouvez implémenter le service d’écriture de stockage à l’aide d’un rôle de travail distinct.
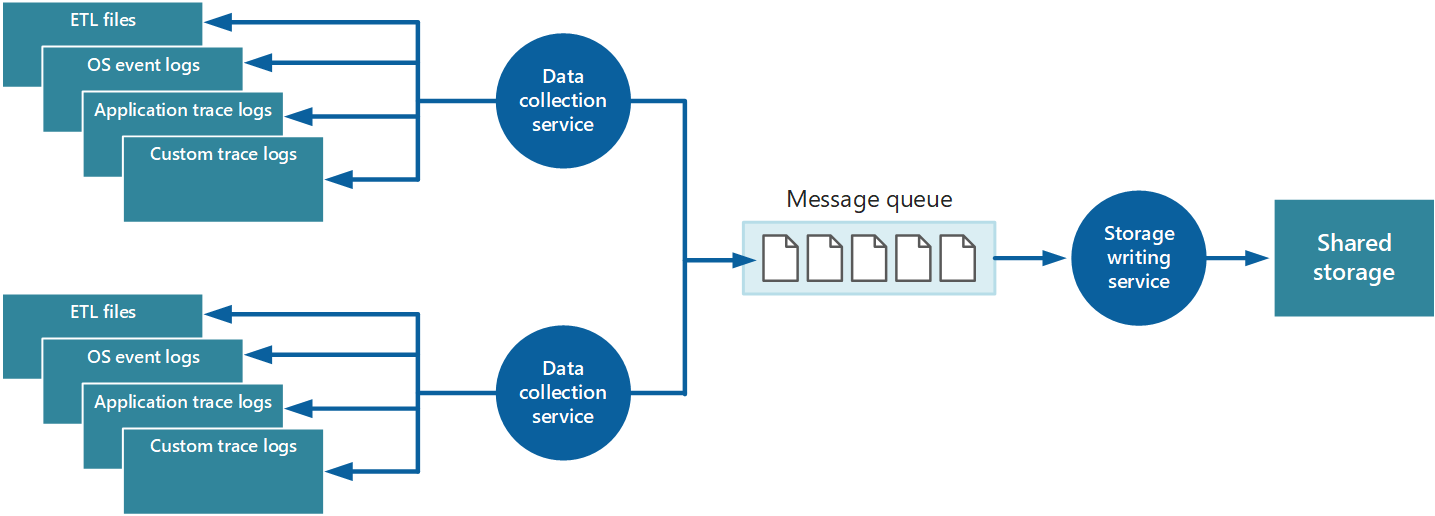
Figure 4 : Utilisation d’une file d’attente pour mettre en mémoire tampon les données d’instrumentation.
Le service de collecte de données local peut ajouter des données à une file d’attente immédiatement après sa réception. La file d’attente agit en tant que mémoire tampon, et le service d’écriture de stockage peut récupérer et écrire les données à son propre rythme. Par défaut, une file d’attente fonctionne sur une base de première entrée et de première sortie. Toutefois, vous pouvez hiérarchiser les messages pour les accélérer dans la file d’attente s’ils contiennent des données qui doivent être gérées plus rapidement. Pour plus d’informations, consultez le modèle File d’attente prioritaire. Vous pouvez également utiliser différents canaux (tels que les rubriques Service Bus) pour diriger les données vers différentes destinations en fonction de la forme de traitement analytique nécessaire.
Pour la scalabilité, vous pouvez exécuter plusieurs instances du service d’écriture de stockage. S’il existe un volume élevé d’événements, vous pouvez utiliser un hub d’événements pour distribuer les données à différentes ressources de calcul pour le traitement et le stockage.
Consolidation des données d’instrumentation
Les données d’instrumentation récupérées par le service de collecte de données à partir d’une seule instance d’une application donnent une vue localisée de l’intégrité et des performances de cette instance. Pour évaluer l’intégrité globale du système, il est nécessaire de consolider certains aspects des données dans les vues locales. Vous pouvez effectuer cette opération une fois que les données ont été stockées, mais dans certains cas, vous pouvez également l’obtenir à mesure que les données sont collectées. Au lieu d’être écrites directement dans le stockage partagé, les données d’instrumentation peuvent passer par un service de consolidation des données distinct qui combine les données et agit comme un processus de filtrage et de nettoyage. Par exemple, les données d’instrumentation qui incluent les mêmes informations de corrélation, telles qu’un ID d’activité, peuvent être fusionnées. (Il est possible qu’un utilisateur commence à effectuer une opération métier sur un nœud, puis qu’il soit transféré vers un autre nœud en cas d’échec du nœud, ou selon la configuration de l’équilibrage de charge.) Ce processus peut également détecter et supprimer toutes les données dupliquées (toujours une possibilité si le service de télémétrie utilise des files d’attente de messages pour envoyer des données d’instrumentation vers le stockage). La figure 5 illustre un exemple de cette structure.
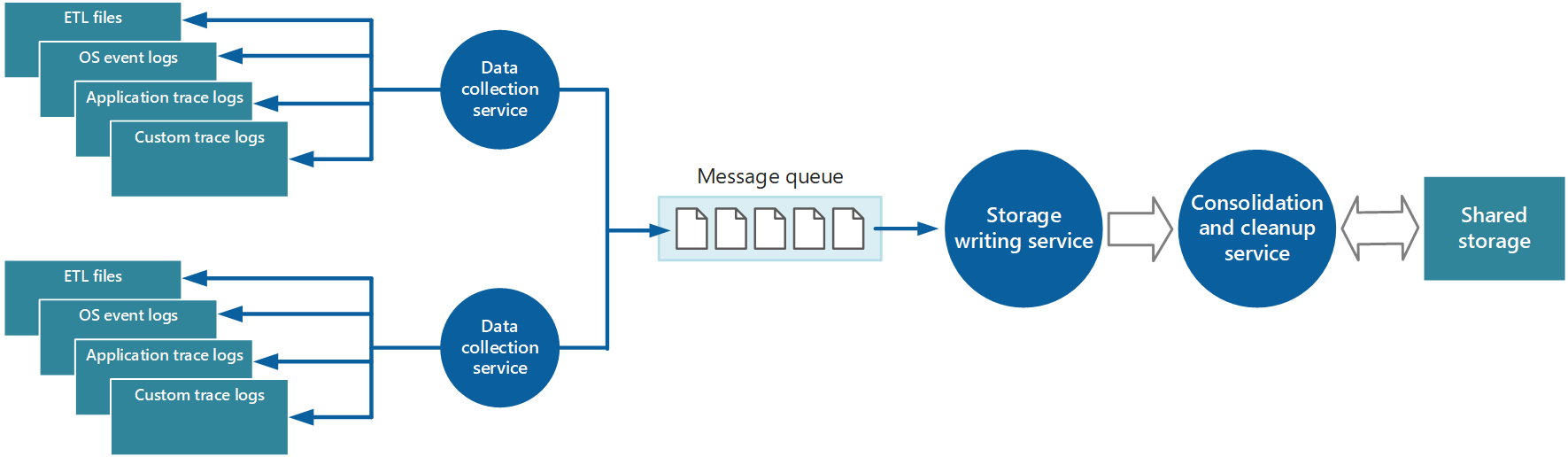
Figure 5 : Utilisation d’un service distinct pour consolider et nettoyer les données d’instrumentation.
Stockage des données d’instrumentation
Les discussions précédentes ont montré une vue plutôt simpliste de la façon dont les données d’instrumentation sont stockées. En réalité, il peut être judicieux de stocker les différents types d’informations à l’aide de technologies qui conviennent le mieux à la façon dont chaque type est susceptible d’être utilisé.
Par exemple, le stockage d’objets blob et de tables Azure présente des similitudes dans la façon dont ils sont accessibles. Mais ils ont des limitations dans les opérations que vous pouvez effectuer en les utilisant, et la granularité des données qu’ils contiennent est assez différente. Si vous devez effectuer des opérations analytiques supplémentaires ou exiger des fonctionnalités de recherche en texte intégral sur les données, il peut être plus approprié d’utiliser le stockage de données qui fournit des fonctionnalités optimisées pour des types spécifiques de requêtes et d’accès aux données. Par exemple:
- Les données de compteur de performances peuvent être stockées dans une base de données SQL pour activer l’analyse ad hoc.
- Les journaux de trace peuvent être mieux stockés dans Azure Cosmos DB.
- Les informations de sécurité peuvent être écrites dans HDFS.
- Les informations qui nécessitent une recherche en texte intégral peuvent être stockées via Elasticsearch (qui peut également accélérer les recherches à l’aide de l’indexation enrichie).
Vous pouvez implémenter un service supplémentaire qui récupère régulièrement les données à partir du stockage partagé, des partitions et filtre les données en fonction de son objectif, puis les écrit dans un ensemble approprié de magasins de données, comme indiqué dans la figure 6. Une autre approche consiste à inclure cette fonctionnalité dans le processus de consolidation et de nettoyage et à écrire les données directement dans ces magasins, car elles sont récupérées plutôt que de les enregistrer dans une zone de stockage partagée intermédiaire. Chaque approche présente ses avantages et ses inconvénients. L’implémentation d’un service de partitionnement distinct réduit la charge sur le service de consolidation et de nettoyage, et permet au moins une partie des données partitionnés d’être régénérées si nécessaire (en fonction de la quantité de données conservées dans le stockage partagé). Toutefois, il consomme des ressources supplémentaires. En outre, il peut y avoir un délai entre la réception des données d’instrumentation de chaque instance d’application et la conversion de ces données en informations exploitables.
Figure 6 : partitionnement des données en fonction des exigences analytiques et de stockage.
Les mêmes données d’instrumentation peuvent être requises à plusieurs fins. Par exemple, les compteurs de performances peuvent être utilisés pour fournir une vue historique des performances du système au fil du temps. Ces informations peuvent être combinées avec d’autres données d’utilisation pour générer des informations de facturation client. Dans ces situations, les mêmes données peuvent être envoyées à plusieurs destinations, telles qu’une base de données de documents qui peut servir de magasin à long terme pour conserver des informations de facturation et un magasin multidimensionnel pour gérer des analyses de performances complexes.
Vous devez également tenir compte de l’urgence des données. Les données qui fournissent des informations pour les alertes doivent être accessibles rapidement. Elles doivent donc être conservées dans un stockage de données rapide et indexées ou structurées pour optimiser les requêtes effectuées par le système d’alerte. Dans certains cas, il peut être nécessaire pour le service de télémétrie qui collecte les données sur chaque nœud pour mettre en forme et enregistrer des données localement afin qu’une instance locale du système d’alerte puisse rapidement vous avertir des problèmes. Les mêmes données peuvent être distribuées au service d’écriture de stockage affiché dans les diagrammes précédents et stockées de manière centralisée si elles sont également requises à d’autres fins.
Les informations utilisées pour une analyse plus prise en compte, pour la création de rapports et pour repérer les tendances historiques sont moins urgentes et peuvent être stockées de manière à prendre en charge l’exploration de données et les requêtes ad hoc. Pour plus d’informations, consultez la section Prise en charge de l’analyse chaude, chaude et froide plus loin dans ce document.
Rotation des journaux et rétention des données
L’instrumentation peut générer des volumes considérables de données. Ces données peuvent être conservées à plusieurs endroits, en commençant par les fichiers journaux bruts, les fichiers de trace et d’autres informations capturées à chaque nœud dans la vue consolidée, nettoyée et partitionnée de ces données conservées dans un stockage partagé. Dans certains cas, une fois les données traitées et transférées, les données sources brutes d’origine peuvent être supprimées de chaque nœud. Dans d’autres cas, il peut être nécessaire ou simplement utile d’enregistrer les informations brutes. Par exemple, les données générées à des fins de débogage peuvent être mieux laissées disponibles sous sa forme brute, mais peuvent ensuite être ignorées rapidement une fois que des bogues ont été rectifiés.
Les données de performances ont souvent une durée de vie plus longue afin qu’elles puissent être utilisées pour repérer les tendances des performances et pour la planification de la capacité. La vue consolidée de ces données est généralement conservée en ligne pendant une période limitée pour permettre un accès rapide. Après cela, il peut être archivé ou ignoré. Les données collectées pour le contrôle et la facturation des clients doivent peut-être être enregistrées indéfiniment. En outre, les exigences réglementaires peuvent dicter que les informations collectées à des fins d’audit et de sécurité doivent également être archivées et enregistrées. Ces données sont également sensibles et peuvent devoir être cryptées ou autrement protégées pour éviter toute falsification. Vous ne devez jamais enregistrer les mots de passe des utilisateurs ou d’autres informations susceptibles d’être utilisées pour valider la fraude d’identité. Ces détails doivent être nettoyés à partir des données avant leur stockage.
Échantillonnage inférieur
Il est utile de stocker des données historiques pour vous permettre d’identifier les tendances à long terme. Au lieu d’enregistrer les anciennes données dans son intégralité, il peut être possible de réduire l’échantillon des données afin de réduire sa résolution et d’économiser des coûts de stockage. Par exemple, au lieu d’économiser des indicateurs de performances minute par minute, vous pouvez consolider les données de plus d’un mois pour former une vue horaire par heure.
Meilleures pratiques pour collecter et stocker des informations de journalisation
La liste suivante récapitule les meilleures pratiques pour capturer et stocker les informations de journalisation :
L’agent de surveillance ou le service de collecte de données doit s’exécuter en tant que service hors processus et doit être simple à déployer.
Toutes les sorties de l’agent de surveillance ou du service de collecte de données doivent être un format indépendant de l’ordinateur, du système d’exploitation ou du protocole réseau. Par exemple, émettez des informations dans un format auto-décrivant tel que JSON, MessagePack ou Protobuf plutôt que ETL/ETW. L’utilisation d’un format standard permet au système de construire des pipelines de traitement ; les composants qui lisent, transforment et envoient des données au format convenu peuvent être facilement intégrés.
Le processus de surveillance et de collecte de données doit être sécurisé et ne doit pas déclencher de conditions d’erreur en cascade.
En cas de défaillance temporaire lors de l’envoi d’informations à un récepteur de données, l’agent de surveillance ou le service de collecte de données doit être prêt à réorganiser les données de télémétrie afin que les informations les plus récentes soient envoyées en premier. (L’agent de surveillance/le service de collecte de données peut choisir de supprimer les données plus anciennes, ou de l’enregistrer localement et de le transmettre ultérieurement pour rattraper, à sa propre discrétion.)
Analyse des données et diagnostic des problèmes
Une partie importante du processus de surveillance et de diagnostics analyse les données collectées pour obtenir une image du bien-être global du système. Vous devez avoir défini vos propres indicateurs de performance clés et métriques de performances, et il est important de comprendre comment vous pouvez structurer les données collectées pour répondre à vos besoins d’analyse. Il est également important de comprendre comment les données capturées dans différentes métriques et fichiers journaux sont corrélées, car ces informations peuvent être essentielles pour suivre une séquence d’événements et aider à diagnostiquer les problèmes qui surviennent.
Comme décrit dans la section Consolidation des données d’instrumentation, les données de chaque partie du système sont généralement capturées localement, mais elles doivent généralement être combinées avec les données générées sur d’autres sites qui participent au système. Ces informations nécessitent une corrélation minutieuse pour s’assurer que les données sont combinées avec précision. Par exemple, les données d’utilisation d’une opération peuvent s’étendre sur un nœud qui héberge un site web auquel un utilisateur se connecte, un nœud qui exécute un service distinct accessible dans le cadre de cette opération et le stockage de données conservé sur un autre nœud. Ces informations doivent être liées pour fournir une vue globale de la ressource et du traitement de l’utilisation de l’opération. Certains prétraitements et filtrages de données peuvent se produire sur le nœud sur lequel les données sont capturées, tandis que l’agrégation et la mise en forme sont plus susceptibles de se produire sur un nœud central.
Prise en charge de l’analyse chaude, chaude et froide
L’analyse et la reformatage des données à des fins de visualisation, de création de rapports et d’alertes peuvent être un processus complexe qui consomme son propre ensemble de ressources. Certaines formes de surveillance sont critiques dans le temps et nécessitent une analyse immédiate des données pour être efficace. C’est ce qu’on appelle l’analyse à chaud. Par exemple, citons les analyses requises pour les alertes et certains aspects de la surveillance de la sécurité (par exemple, la détection d’une attaque sur le système). Les données requises à ces fins doivent être rapidement disponibles et structurées pour un traitement efficace. Dans certains cas, il peut être nécessaire de déplacer le traitement d’analyse vers les nœuds individuels où les données sont conservées.
D’autres formes d’analyse sont moins critiques et peuvent nécessiter un calcul et une agrégation une fois les données brutes reçues. C’est ce qu’on appelle l’analyse chaude. L’analyse des performances se situe souvent dans cette catégorie. Dans ce cas, un événement de performances unique isolé est peu susceptible d’être statistiquement significatif. (Il peut être dû à un pic ou à un glitch soudain.) Les données d’une série d’événements doivent fournir une image plus fiable des performances du système.
L’analyse chaude peut également être utilisée pour diagnostiquer les problèmes de santé. Un événement d’intégrité est généralement traité par le biais d’une analyse à chaud et peut déclencher immédiatement une alerte. Un opérateur doit pouvoir explorer les raisons de l’événement d’intégrité en examinant les données du chemin chaud. Ces données doivent contenir des informations sur les événements menant au problème qui a provoqué l’événement d’intégrité.
Certains types de surveillance génèrent des données plus à long terme. Cette analyse peut être effectuée à une date ultérieure, éventuellement selon une planification prédéfinie. Dans certains cas, l’analyse peut avoir besoin d’effectuer un filtrage complexe de grands volumes de données capturées sur une période donnée. C’est ce qu’on appelle l’analyse froide. L’exigence clé est que les données sont stockées en toute sécurité une fois qu’elles ont été capturées. Par exemple, la surveillance et l’audit de l’utilisation nécessitent une image précise de l’état du système à des moments réguliers, mais ces informations d’état ne doivent pas nécessairement être disponibles pour le traitement immédiatement après sa collecte.
Un opérateur peut également utiliser l’analyse à froid pour fournir les données pour l’analyse prédictive de l’intégrité. L’opérateur peut collecter des informations historiques sur une période spécifiée et l’utiliser conjointement avec les données d’intégrité actuelles (récupérées à partir du chemin d’accès chaud) pour repérer les tendances susceptibles de provoquer bientôt des problèmes d’intégrité. Dans ces cas, il peut être nécessaire de déclencher une alerte afin que des mesures correctives puissent être prises.
Corrélation des données
Les données capturées par l’instrumentation peuvent fournir un instantané de l’état du système, mais l’objectif de l’analyse est de rendre ces données exploitables. Par exemple:
- Qu’est-ce qui a provoqué un chargement d’E/S intense au niveau du système à un moment spécifique ?
- Est-ce le résultat d’un grand nombre d’opérations de base de données ?
- Cela est-il reflété dans les temps de réponse de la base de données, le nombre de transactions par seconde et les temps de réponse de l’application au même moment ?
Dans ce cas, une action corrective susceptible de réduire la charge peut être de partitionner les données sur d’autres serveurs. En outre, les exceptions peuvent survenir en raison d’une erreur dans n’importe quel niveau du système. Une exception dans un niveau déclenche souvent une autre erreur dans le niveau ci-dessus.
Pour ces raisons, vous devez être en mesure de mettre en corrélation les différents types de données de surveillance à chaque niveau pour produire une vue globale de l’état du système et des applications qui s’exécutent dessus. Vous pouvez ensuite utiliser ces informations pour prendre des décisions sur le fonctionnement acceptable ou non du système et déterminer ce qui peut être fait pour améliorer la qualité du système.
Comme décrit dans la section Informations sur la corrélation des données, vous devez vous assurer que les données d’instrumentation brutes incluent des informations de contexte et d’ID d’activité suffisantes pour prendre en charge les agrégations requises pour la corrélation des événements. En outre, ces données peuvent être conservées dans différents formats, et il peut être nécessaire d’analyser ces informations pour les convertir dans un format standardisé pour l’analyse.
Résolution et diagnostic des problèmes
Le diagnostic nécessite la possibilité de déterminer la cause des erreurs ou un comportement inattendu, y compris l’exécution d’une analyse de la cause racine. Les informations requises incluent généralement :
- Informations détaillées des journaux d’événements et des traces, soit pour l’ensemble du système, soit pour un sous-système spécifié pendant une fenêtre de temps spécifiée.
- Effectuez les traces de pile résultant d’exceptions et d’erreurs de tout niveau spécifié qui se produit dans le système ou dans un sous-système spécifié pendant une période spécifiée.
- Vidages sur incident pour tous les processus ayant échoué n’importe où dans le système ou pour un sous-système spécifié pendant une fenêtre de temps spécifiée.
- Les journaux d’activité enregistrent les opérations effectuées par tous les utilisateurs ou pour les utilisateurs sélectionnés pendant une période spécifiée.
L’analyse des données à des fins de résolution des problèmes nécessite souvent une compréhension technique approfondie de l’architecture système et des différents composants qui composent la solution. Par conséquent, un grand degré d’intervention manuelle est souvent nécessaire pour interpréter les données, établir la cause des problèmes et recommander une stratégie appropriée pour les corriger. Il peut s’avérer judicieux de stocker une copie de ces informations dans son format d’origine et de le rendre disponible pour l’analyse à froid par un expert.
Visualisation des données et déclenchement d’alertes
Un aspect important de tout système de surveillance est la possibilité de présenter les données de telle manière qu’un opérateur peut rapidement repérer les tendances ou problèmes. Il est également important de pouvoir informer rapidement un opérateur si un événement important s’est produit, ce qui peut nécessiter une attention particulière.
La présentation des données peut prendre plusieurs formes, notamment la visualisation à l’aide de tableaux de bord, d’alertes et de création de rapports.
Visualisation à l’aide de tableaux de bord
La façon la plus courante de visualiser les données consiste à utiliser des tableaux de bord qui peuvent afficher des informations sous la forme d’une série de graphiques, de graphiques ou d’une autre illustration. Ces éléments peuvent être paramétrés et un analyste doit être en mesure de sélectionner les paramètres importants (tels que la période) pour toute situation spécifique.
Les tableaux de bord peuvent être organisés hiérarchiquement. Les tableaux de bord de niveau supérieur peuvent donner une vue globale de chaque aspect du système, mais permettre à un opérateur d’explorer les détails. Par exemple, un tableau de bord qui représente l’E/S disque global du système doit permettre à un analyste d’afficher les taux d’E/S pour chaque disque individuel afin de déterminer si un ou plusieurs appareils spécifiques comptent pour un volume disproportionné de trafic. Dans l’idéal, le tableau de bord doit également afficher des informations connexes, telles que la source de chaque requête (l’utilisateur ou l’activité) qui génère cette E/S. Ces informations peuvent ensuite être utilisées pour déterminer si (et comment) répartir la charge de manière plus homogène entre les appareils, et si le système s’exécuterait mieux si d’autres appareils ont été ajoutés.
Un tableau de bord peut également utiliser le codage de couleurs ou d’autres indications visuelles pour indiquer des valeurs qui apparaissent anormales ou qui se trouvent en dehors d’une plage attendue. Utilisation de l’exemple précédent :
- Un disque avec un taux d’E/S qui approche de sa capacité maximale sur une période prolongée (un disque chaud) peut être mis en surbrillance en rouge.
- Un disque avec un taux d’E/S qui s’exécute régulièrement à sa limite maximale sur de courtes périodes (un disque chaud) peut être mis en surbrillance en jaune.
- Un disque présentant une utilisation normale peut être affiché en vert.
Notez que pour qu’un système de tableau de bord fonctionne efficacement, il doit disposer des données brutes à utiliser. Si vous créez votre propre système de tableau de bord ou si vous utilisez un tableau de bord développé par une autre organisation, vous devez comprendre les données d’instrumentation que vous devez collecter, à quels niveaux de granularité et comment il doit être mis en forme pour que le tableau de bord consomme.
Un bon tableau de bord n’affiche pas seulement les informations, il permet également à un analyste de poser des questions ad hoc sur ces informations. Certains systèmes fournissent des outils de gestion qu’un opérateur peut utiliser pour effectuer ces tâches et explorer les données sous-jacentes. En fonction du référentiel utilisé pour contenir ces informations, il peut être possible d’interroger ces données directement ou de les importer dans des outils tels que Microsoft Excel pour une analyse et des rapports supplémentaires.
Remarque
Vous devez restreindre l’accès aux tableaux de bord au personnel autorisé, car ces informations peuvent être sensibles commercialement. Vous devez également protéger les données sous-jacentes des tableaux de bord pour empêcher les utilisateurs de les modifier.
Déclenchement d’alertes
L’alerte est le processus d’analyse des données d’analyse et d’instrumentation et de génération d’une notification si un événement significatif est détecté.
Les alertes permettent de s’assurer que le système reste sain, réactif et sécurisé. Il s’agit d’une partie importante de n’importe quel système qui garantit les performances, la disponibilité et la confidentialité aux utilisateurs sur lesquels les données peuvent avoir besoin d’être exécutées immédiatement. Un opérateur doit peut-être être averti de l’événement qui a déclenché l’alerte. Les alertes peuvent également être utilisées pour appeler des fonctions système telles que la mise à l’échelle automatique.
Les alertes dépendent généralement des données d’instrumentation suivantes :
- Événements de sécurité. Si les journaux des événements indiquent que des échecs d’authentification ou d’autorisation répétés se produisent, le système peut être attaqué et un opérateur doit être informé.
- Mesures de performances. Le système doit rapidement répondre si une métrique de performances particulière dépasse un seuil spécifié.
- Informations de disponibilité. Si une erreur est détectée, il peut être nécessaire de redémarrer rapidement un ou plusieurs sous-systèmes, ou de basculer vers une ressource de sauvegarde. Les erreurs répétées dans un sous-système peuvent indiquer des problèmes plus graves.
Les opérateurs peuvent recevoir des informations d’alerte à l’aide de nombreux canaux de remise tels que l’e-mail, un appareil de pagineur ou un sms. Une alerte peut également inclure une indication de la façon dont une situation est critique. De nombreux systèmes d’alerte prennent en charge les groupes d’abonnés, et tous les opérateurs membres du même groupe peuvent recevoir le même ensemble d’alertes.
Un système d’alerte doit être personnalisable et les valeurs appropriées des données d’instrumentation sous-jacentes peuvent être fournies en tant que paramètres. Cette approche permet à un opérateur de filtrer les données et de se concentrer sur ces seuils ou combinaisons de valeurs qui sont intéressantes. Notez que dans certains cas, les données d’instrumentation brutes peuvent être fournies au système d’alerte. Dans d’autres situations, il peut être plus approprié de fournir des données agrégées. (Par exemple, une alerte peut être déclenchée si l’utilisation du processeur pour un nœud a dépassé 90 % au cours des 10 dernières minutes). Les détails fournis au système d’alerte doivent également inclure toutes les informations de synthèse et de contexte appropriées. Ces données peuvent contribuer à réduire la possibilité que les événements faux positifs déclenchent une alerte.
Rapports
Le reporting est utilisé pour générer une vue globale du système. Il peut incorporer des données historiques en plus des informations actuelles. Les exigences de création de rapports elles-mêmes appartiennent à deux grandes catégories : les rapports opérationnels et les rapports de sécurité.
Les rapports opérationnels incluent généralement les aspects suivants :
- Agrégation de statistiques que vous pouvez utiliser pour comprendre l’utilisation des ressources du système global ou des sous-systèmes spécifiés pendant une fenêtre de temps spécifiée.
- Identifier les tendances d’utilisation des ressources pour le système global ou des sous-systèmes spécifiés au cours d’une période spécifiée.
- Surveillance des exceptions qui se sont produites dans le système ou dans les sous-systèmes spécifiés pendant une période spécifiée.
- Déterminer l’efficacité de l’application en termes de ressources déployées et comprendre si le volume de ressources (et leur coût associé) peut être réduit sans affecter inutilement les performances.
Les rapports de sécurité concernent le suivi de l’utilisation du système par les clients. Il peut inclure :
- Audit des opérations utilisateur. Cela nécessite l’enregistrement des requêtes individuelles effectuées par chaque utilisateur, ainsi que des dates et des heures. Les données doivent être structurées pour permettre à un administrateur de reconstruire rapidement la séquence d’opérations effectuées par un utilisateur sur une période spécifiée.
- Suivi de l’utilisation des ressources par l’utilisateur. Cela nécessite l’enregistrement de la façon dont chaque demande d’un utilisateur accède aux différentes ressources qui composent le système et pendant combien de temps. Un administrateur doit pouvoir utiliser ces données pour générer un rapport d’utilisation par l’utilisateur sur une période spécifiée, éventuellement à des fins de facturation.
Dans de nombreux cas, les processus de traitement par lots peuvent générer des rapports selon une planification définie. (La latence n’est pas normalement un problème.) Mais elles devraient également être disponibles pour la génération sur une base ad hoc si nécessaire. Par exemple, si vous stockez des données dans une base de données relationnelle telle qu’Azure SQL Database, vous pouvez utiliser un outil tel que SQL Server Reporting Services pour extraire et mettre en forme des données et les présenter sous la forme d’un ensemble de rapports.
Étapes suivantes
- vue d’ensemble d’Azure Monitor
- Analyser, diagnostiquer et dépanner Microsoft Azure Storage
- Vue d’ensemble des alertes dans Microsoft Azure
- Afficher les notifications d’intégrité du service à l’aide du Portail Azure
- Qu’est-ce qu’Application Insights ?
- Diagnostics de performances pour les machines virtuelles Azure
- Télécharger et installer SQL Server Data Tools (SSDT) pour Visual Studio
Ressources associées
- Les conseils de mise à l’échelle automatique décrivent comment réduire la surcharge de gestion en réduisant la nécessité pour un opérateur de surveiller en permanence les performances d’un système et de prendre des décisions sur l’ajout ou la suppression de ressources.
- Le modèle de supervision des points de terminaison d’intégrité décrit comment implémenter des vérifications fonctionnelles au sein d’une application auxquelles les outils externes peuvent accéder via des points de terminaison exposés à intervalles réguliers.
- Le modèle file d’attente prioritaire montre comment hiérarchiser les messages mis en file d’attente afin que les demandes urgentes soient reçues et puissent être traitées avant les messages moins urgents.