Applications cloud évolutives et ingénierie de fiabilité du site (SRE)
Le succès de votre solution cloud dépend de sa fiabilité. La fiabilité peut être définie de manière générale comme la probabilité que le système fonctionne comme prévu, dans les conditions environnementales spécifiées et dans un délai spécifié. L’ingénierie de fiabilité du site (SRE) est un ensemble de principes et de pratiques pour créer des systèmes logiciels évolutifs et hautement fiables. De plus en plus, l’ingénierie de fiabilité du site est utilisée lors de la conception de services numériques pour garantir une plus grande fiabilité.
Pour plus d’informations sur les stratégies d’ingénierie de fiabilité du site, consultez AZ-400 : Développer une stratégie d’ingénierie de fiabilité du site (SRE).
Cas d’usage potentiels
Les concepts décrits dans cet article s’appliquent aux éléments suivants :
- Services cloud basés sur des API.
- Applications web accessibles au public.
- Charges de travail basées sur l’IoT ou sur les événements.
Architecture

Téléchargez un fichier PowerPoint de cette architecture.
L’architecture considérée ici est celle d’une plateforme d’API évolutive. La solution comprend plusieurs microservices qui utilisent un vaste éventail de bases de données et de services de stockage, notamment des solutions SaaS telles que Dynamics 365 et Microsoft 365.
Cet article examine une solution qui gère des cas d’utilisation de niveau supérieur pour les places de marché et le commerce électronique afin de démontrer les blocs illustrés dans le diagramme. Les cas d’usage sont les suivants :
- Navigation dans les produits.
- Inscription et connexion.
- Affichage de contenu tel que des articles d’actualité.
- Gestion de commande et d’abonnement.
Des applications clientes telles que des applications web, des applications mobiles, voire des applications de service consomment les services de plateforme d’API via un chemin d’accès unifié, https://api.contoso.com.
Composants
- Azure Front Door fournit un point d’entrée unifié et sécurisé pour toutes les demandes adressées à la solution. Pour plus d’informations, consultez Vue d’ensemble de l’architecture de routage.
- La Gestion des API Azure fournit une couche de gouvernance en plus de toutes les API publiées. Vous pouvez utiliser des stratégies de Gestion des API Azure pour appliquer des fonctionnalités supplémentaires à la couche API, telles que des restrictions d’accès, la mise en cache et la transformation de données. API Management prend en charge l’autoscaling dans les niveaux Standard et Premium.
- Azure Kubernetes service (AKS) est l’implémentation Azure de clusters Kubernetes open source. En tant que service Kubernetes hébergé, Azure gère des tâches critiques telles que le monitoring de l’intégrité et la maintenance. Sachant qu’Azure gère les maîtres Kubernetes, vous n’assurer la gestion et la maintenance que des nœuds agents. Dans cette architecture, tous les microservices sont déployés dans AKS.
- Azure Application Gateway est une application délivrant un service de contrôleur. Elle fonctionne au niveau de la couche 7, la couche application, et a différentes fonctionnalités d’équilibrage de charge. L’Application Gateway Ingress Controller (AGIC) est une application Kubernetes qui permet aux clients d’Azure Kubernetes Service (AKS) d’utiliser le load-balancer L7 Application Gateway natif d’Azure pour exposer des logiciels cloud à Internet. La mise à l’échelle automatique et la redondance de zone sont prises en charge dans la référence SKU v2.
- stockage Azure, Azure Data Lake Storage, Azure Cosmos DB et Azure SQL peuvent stocker des contenus structurés et non structurés. Vous pouvez créer des conteneurs et bases de données Azure Cosmos DB avec un débit de mise à l’échelle automatique.
- Microsoft Dynamics 365 est une offre SaaS (Software as a Service) de Microsoft qui fournit plusieurs applications métier pour le service clientèle, les ventes, le marketing et la finance. Dans cette architecture, Dynamics 365 est principalement utilisé pour la gestion des catalogues de produits et pour la gestion du service clientèle. Les unités d’échelle apporte une résilience aux applications Dynamics 365.
- Microsoft 365 (anciennement Office 365) est utilisé comme système de gestion de contenu d’entreprise basé sur Microsoft 365 SharePoint dans Microsoft 365. Il est utilisé pour créer, gérer et publier du contenu, tel que des éléments multimédias et des documents.
Autres solutions
Étant donné que cette solution utilise une architecture basée sur des microservices hautement évolutive, envisagez les alternatives suivantes pour le plan de calcul :
- Azure Functions pour les services d’API serverless
- Azure Spring Apps pour les microservices basés sur Java
Fiabilité appropriée
Le degré de fiabilité requis pour une solution dépend du contexte métier. Un magasin de vente au détail qui est ouvert pendant 14 heures et qui atteint le pic d’utilisation du système durant cette période, a des exigences différentes de celles d’une entreprise en ligne qui accepte des commandes à toute heure. Les pratiques SRE peuvent être adaptées pour atteindre le niveau de fiabilité approprié.
La fiabilité est définie et mesurée à l'aide d'objectifs de niveau de service (SLO) qui définissent le niveau cible de fiabilité d'un service. Atteindre le niveau cible garantit que la satisfaction des consommateurs. Les objectifs SLO peuvent évoluer ou changer en fonction des besoins de l’entreprise. Toutefois, les propriétaires de service doivent mesurer constamment la fiabilité par rapport aux SLO afin de détecter d’éventuels problèmes et de prendre des mesures correctives. Les SLO sont généralement définis en tant que pourcentage d’accomplissement sur une période.
Une autre terme important à noter est celui de SLI pour indicateur de niveau de service, qui est la métrique utilisée pour calculer le SLO. Les SLI sont basés sur des Insights dérivées de données capturées à mesure que le client utilise le service. Les SLI sont toujours mesurés du point de vue d’un client.
Les SLO et SLI vont toujours de pair et sont généralement définis de manière itérative. Les SLO sont pilotés par des objectifs d’entreprise clés, tandis que les SLI sont pilotés par ce que qu’il est possible de mesurer lors de l’implémentation du service.
La relation entre la métrique surveillée, le SLI et le SLO est illustrée ci-dessous :
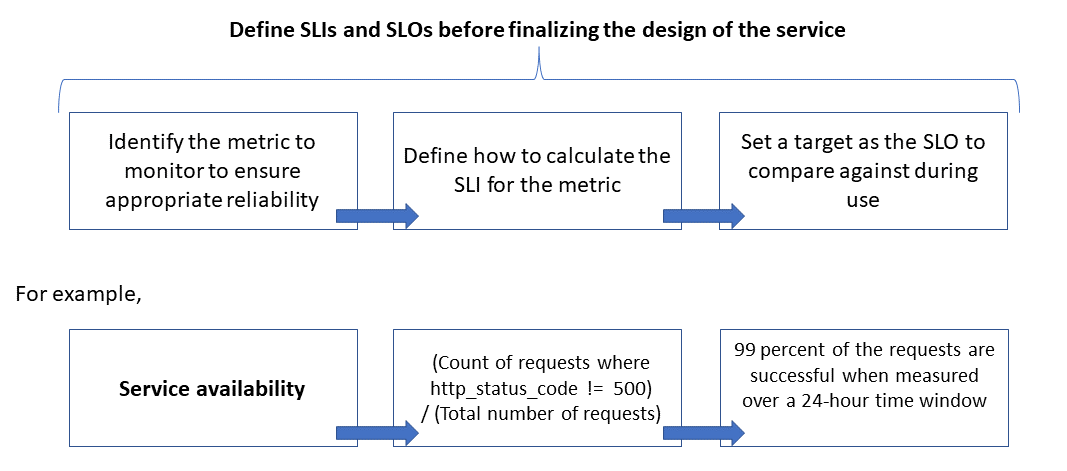
Cela est décrit plus en détail dans Définir des métriques de SLI pour calculer des SLO.
Modélisation des attentes en matière de mise à l’échelle et de performances
Pour un système logiciel, les performances font généralement référence à la réactivité globale d’un système lors de l’exécution d’une action dans un délai spécifié, alors que l’évolutivité, ou scalabilité, est la capacité du système à gérer des charges utilisateur accrues sans nuire aux performances.
Un système est considéré comme évolutif si les ressources sous-jacentes sont rendues disponibles de façon dynamique pour prendre en charge une augmentation de charge. Les applications cloud doivent être conçues pour la mise à l’échelle, et le volume de trafic est parfois difficile à prédire. Des pics saisonniers peuvent augmenter les exigences de mise à l’échelle, en particulier quand un service gère les demandes de plusieurs locataires.
Il est recommandé de concevoir des applications afin que les ressources cloud changent d’échelle automatiquement en fonction des besoins afin répondre à la charge. Fondamentalement, le système doit s’adapter à l’augmentation de la charge de travail en approvisionnant ou en allouant des ressources de manière incrémentielle afin de répondre à la demande. L’extensibilité concerne non seulement les instances de calcul, mais aussi d’autres éléments tels que le stockage de données et l’infrastructure de messagerie.
Cet article explique comment garantir une fiabilité appropriée pour une application cloud en effectuant une modélisation d’échelle et de performances des scénarios de charge de travail, et en utilisant les résultats pour définir les analyses, les SLI et les SLO.
Considérations
Pour obtenir des conseils sur la création d’applications évolutives et fiables, reportez-vous aux piliers Fiabilité et Efficacité des performances de l’Azure Well-Architected Framework.
Cet article explique comment appliquer les techniques de modélisation de la scalabilité et des performances pour affiner l’architecture et la conception de la solution. Ces techniques identifient les modifications apportées aux flux de transaction pour optimiser l’expérience utilisateur. Basez vos décisions techniques sur les exigences non fonctionnelles de la solution. Le processus est le suivant :
- Identifiez les exigences de scalabilité.
- Modélisez la charge attendue.
- Définissez les SLI et SLO pour les scénarios utilisateur.
Notes
Azure Application Insights, qui fait partie d’Azure Monitor, est un puissant outil de gestion des performances des applications (APM) que vous pouvez facilement intégrer avec vos applications afin d’envoyer des données de télémétrie et d’analyser les métriques spécifiques de l’application. Il fournit également des tableaux de bord prêts à l’emploi et un explorateur de métriques que vous pouvez utiliser pour analyser les données afin d’explorer des besoins métier.
Capturer les exigences de scalabilité
Supposons les métriques de charge maximale suivantes :
- Nombre de consommateurs qui utilisent la plateforme d’API : 1,5 million
- Consommateurs actifs par heure (30 pour cent de 1,5 million) : 450 000
- Pourcentage de charge pour chaque activité :
- Navigation dans les produits : 75 pour cent
- Inscription, dont la création de profil, et connexion : 10 pour cent
- Gestion des commandes et des abonnements : 10 pour cent
- Affichage de contenu : 5 pour cent
La charge produit les exigences de mise à l’échelle suivantes, sous une charge maximale normale, pour les API hébergées par la plateforme :
- Microservice de produit : environ 500 demandes par seconde (RPS)
- Microservice de profil : environ 100 RPS
- Microservice de commandes et de paiement : environ 100 RPS
- Microservice de contenu : environ 50 RPS
Ces exigences de mise à l’échelle ne prennent pas en compte les pics saisonniers et aléatoires, ou les pics pendant des événements spéciaux tels que des promotions marketing. Lors des pics, l’exigence de mise à l’échelle pour certaines activités de l’utilisateur est jusqu’à 10 fois supérieure à la charge maximale normale. Gardez ces contraintes et attentes à l’esprit lorsque vous opérez des choix de conception pour les microservices.
Définir les métriques de SLI pour calculer les SLO
Les métriques de SLI indiquent le degré auquel un service offre une expérience satisfaisante, et peuvent être exprimées comme le rapport entre les bons événements et le nombre total d’événements.
Pour un service d’API, les événements font référence aux métriques spécifiques de l’application capturées lors de l’exécution en tant que données de télémétrie ou traitées. Cet exemple présente les métriques de SLI suivantes :
| Métrique | Descriptif |
|---|---|
| Disponibilité | Indique si la demande a été servie par l’API |
| Latence | Temps nécessaire à l’API pour traiter la demande et retourner une réponse |
| Débit | Nombre de demandes gérées par l’API |
| Taux de réussite | Nombre de demandes gérées avec succès par l’API |
| Taux d’erreur | Nombre d’erreurs pour les demandes gérées par l’API |
| Actualisation | Nombre de fois que l’utilisateur a reçu les données les plus récentes pour les opérations de lecture sur l’API, bien que le magasin de données sous-jacent soit mis à jour avec une certaine latence d’écriture |
Notes
Veillez à identifier les autres SLI éventuels, qui sont importants pour votre solution.
Voici quelques exemples de SLI :
- (Nombre de demandes honorées en moins de 1 000 ms) / (nombre de demandes)
- (Nombre de résultats de recherche qui retournent, en maximum trois secondes, tous les produits publiés dans le catalogue) / (nombre de recherches)
Après avoir défini les SLI, déterminez les événements de télémétrie à capturer pour les mesurer. Par exemple, pour mesurer la disponibilité, vous capturez des événements afin d’indiquer si le service d’API a traité une demande avec succès. Pour les services basés sur HTTP, la réussite ou l’échec sont indiquées par des codes d’état HTTP. La conception et l’implémentation de l’API doivent fournir les codes appropriés. En général, les métriques SLI sont une entrée importante pour l’implémentation de l’API.
Pour les systèmes basés sur le cloud, vous pouvez obtenir certaines des mesures à l’aide de la prise en charge des diagnostics et de la surveillance disponibles pour les ressources. Azure Monitor est une solution complète pour collecter et analyser la télémétrie de vos environnements services cloud et agir en conséquence. Selon vos exigences de SLI, davantage de données de surveillance peuvent être capturées pour calculer les métriques.
Utiliser des distributions de centile
Certains SLI sont calculés à l’aide d’une technique de distribution de centile. Cela produit de meilleurs résultats si des valeurs hors norme peuvent fausser d’autres techniques telles que des distributions moyennes ou médianes.
Par exemple, considérez que la métrique est la latence des demandes d’API et que trois secondes sont le seuil pour des performances optimales. Les temps de réponse triés pour une heure de demandes d’API indiquent que peu de demandes prennent plus de trois secondes et que la plupart reçoivent des réponses dans la limite du seuil. Il s’agit du comportement attendu du système.
La distribution de centile est destinée à exclure les valeurs hors norme provoquées par des problèmes intermittents. Par exemple, si les réponses appropriées du service se trouvent dans le 90e ou 95e centile, le SLO est considéré comme atteint.
Choisir des périodes de mesure appropriées
La période de mesure pour la définition d’un SLO est très importante. Il doit capturer l’activité, non l’inactivité, pour que les résultats soient significatifs pour l’expérience utilisateur. Cette fenêtre peut être de cinq minutes à 24 heures en fonction de la façon dont vous souhaitez surveiller et calculer la métrique de SLI.
Établir un processus de gouvernance des performances
Les performances d’une API doivent être gérées de son lancement à sa dépréciation ou son retrait. Un processus de gouvernance robuste doit être en place pour s’assurer que les problèmes de performances sont détectés et résolus tôt, avant qu’ils provoquent une panne majeure qui affecte l’activité.
Voici les éléments de la gouvernance des performances :
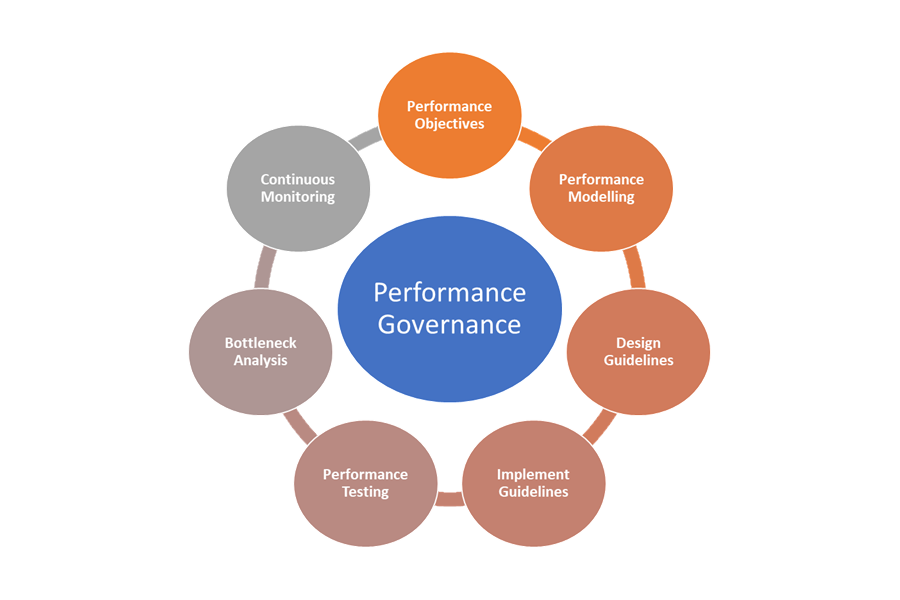
- Objectifs de performances : définissez les SLO de performances ambitieux pour les scénarios d’entreprise.
- Modélisation des performances : identifiez les flux de travail et transactions vitaux pour l’entreprise, et conduisez la modélisation pour comprendre les implications liées aux performances. Capturez ces informations à un niveau granulaire pour obtenir des prédictions plus précises.
- Concevoir des directives : préparez des directives de conception des performances et recommandez les modifications appropriées du flux de travail. Assurez-vous que les équipes comprennent ces directives.
- Implémenter les directives : implémentez les directives de conception des performances pour les composants de la solution, y compris l’instrumentation pour capturer les métriques. Effectuez des examens de conception des performances. Il est essentiel de suivre cela en utilisant les éléments du backlog d’architecture pour les différentes équipes.
- Test des performances : effectuez des tests de charge et de stress conformément à la distribution du profil de charge pour capturer les métriques liées à l’intégrité de la plateforme. Vous pouvez également effectuer ces tests pour une charge limitée afin d’évaluer les exigences en matière d’infrastructure de la solution.
- Analyse des goulots d’étranglement : utilisez l’inspection du code et les révisions du code pour identifier, analyser et supprimer des goulots d’étranglement de performances dans différents composants. Identifiez les améliorations de mise à l’échelle horizontale ou verticale requises pour prendre en charge les pics de charge.
- Surveillance continue : établissez une infrastructure de surveillance et d’alerte continue dans le cadre des processus de DevOps. Assurez-vous que les équipes concernées sont averties lorsque les temps de réponse sont sensiblement dégradés par rapport aux benchmarks.
- Gouvernance des performances : établissez une gouvernance des performances comprenant des processus et des équipes bien définis pour soutenir le SLO de performances. Effectuez le suivi de la conformité après chaque version pour éviter toute dégradation due aux mises à niveau de build. Effectuez régulièrement des examens pour évaluer toute charge supplémentaire afin d’identifier les mises à niveau de la solution.
Veillez à répéter les étapes tout au long du développement de votre solution dans le cadre du processus d’élaboration progressive.
Suivre les objectifs et les attentes en matière de performances dans votre backlog
Effectuez le suivi de vos objectifs de performances pour vous assurer qu’ils sont atteints. Capturez des témoignages d’utilisateur précis et détaillés pour effectuer le suivi. Cela permet de s’assurer que les équipes de développement font des activités de gouvernance des performances une priorité élevée.
Établir des SLO ambitieux pour la solution cible
Voici des exemples de SLO ambitieux pour la solution de plateforme d’API considérée :
- Répond à 95 % de toutes les demandes de lecture d’une journée dans un délai d’une seconde.
- Répond à 95 % de toutes les demandes de création et de mise à jour d’une journée dans un délai de trois secondes.
- Répond à 99 % de toutes les demandes d’une journée en cinq secondes, sans aucun défaillance.
- Répond à 99,9 % de toutes les demandes d’une journée dans un délai de cinq minutes.
- Moins d’un pour cent des demandes au cours de la période de pointe d’une heure ont été rejetées.
Les SLO peuvent être adaptés en réponse à des exigences d’application spécifiques. Toutefois, il est essentiel d’être suffisamment précis pour avoir la clarté nécessaire pour garantir la fiabilité.
Mesurer les SLO initiaux basés sur les données des journaux
Les journaux d’analyse sont créés automatiquement quand le service d’API est en cours d’utilisation. Supposons qu’une semaine de données affiche ce qui suit :
- Demandes : 123 456
- Demandes fructueuses : 123 204
- Latence du 90e centile : 497 ms
- Latence du 95e centile : 870 ms
- Latence du 99e centile : 1 024 ms
Ces données produisent les SLIs initiaux suivants :
- Disponibilité = (123 204 / 123 456) = 99,8 pour cent
- Latence = au moins 90 pour cent des demandes ont été traitées dans un délai de 500 ms
- Latence = environ 98 pour cent des demandes ont été traitées dans un délai de 1 000 ms
Supposons que, lors de la planification, la cible SLO de latence ambitieuse est que 90 pour cent des demandes sont traitées dans un délai de 500 ms, avec un taux de réussite de 99 pour cent sur une période d’une semaine. Les données de journal vous pouvez permettent d’identifier facilement si la cible de SLO a été atteinte. Si vous effectuez ce type d’analyse pendant quelques semaines, vous pouvez commencer à observer les tendances relatives à la conformité du SLO.
Conseils pour l’atténuation des risques techniques
Utilisez la liste de vérification suivante des pratiques recommandées pour atténuer les risques liés à la scalabilité et aux performances :
- Conception pour la mise à l’échelle et les performances.
- Veillez à capturer les exigences de mise à l’échelle pour chaque scénario utilisateur et charge de travail, y compris le caractère saisonnier et les pics.
- Effectuer une modélisation des performances pour identifier les contraintes et les goulots d’étranglement du système
- Gérez la dette technique.
- Effectuez un suivi complet des métriques de performances.
- Envisagez d’utiliser des scripts pour exécuter des outils tels que K6.io, Karate et JMeter sur votre environnement intermédiaire de développement avec une plage de charges utilisateur de 50 à 100 RPS, par exemple. Cela permet de fournir des informations dans les journaux afin de détecter des problèmes de conception et d’implémentation.
- Intégrez les scripts de test automatisés dans le cadre de vos processus de déploiement continu (CD) pour détecter les arrêts de build.
- Pensez production.
- Ajustez les seuils de mise à l’échelle automatique comme indiqué par les statistiques d’intégrité.
- Préférez les techniques de mise à l’échelle horizontale plutôt que verticale.
- Soyez proactif avec la mise à l’échelle pour gérer le caractère saisonnier.
- Préférez le déploiement basé sur des sonneries.
- Utilisez des budgets d’erreurs pour expérimenter.
Tarifs
La fiabilité, l’efficacité des performances et l’optimisation des coûts vont de pair. Les services Azure qui sont utilisés dans l’architecture aident à réduire les coûts, car ils sont mis à l’échelle automatiquement pour s’adapter à la modification des charges utilisateur.
Pour AKS, vous pouvez commencer par démarrer avec des machines virtuelles de taille standard pour le pool de nœuds. Vous pouvez ensuite surveiller les besoins en ressources lors du développement ou de la production, et ajuster en conséquence.
L’optimisation des coûts est un pilier du Microsoft Azure Well-Architected Framework. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts. Pour estimer le coût des produits et configurations Azure, consultez la calculatrice de prix.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Subhajit Chatterjee | Ingénieur logiciel principal
Étapes suivantes
- Documentation Azure
- Cadre Well-Architected Microsoft Azure
- Style d’architecture de microservices
- Penser la conception des applications pour effectuer un scale-out
- Choisir un service de calcul Azure pour votre application
- Architecture de microservices sur Azure Kubernetes Service
- Qu’est-ce qu’Azure Front Door ?
- En savoir plus sur la Gestion des API
- Qu’est-ce qu’un contrôleur d’entrée Application Gateway ?
- Azure Kubernetes Service
- Application Gateway v2 avec mise à l'échelle automatique et redondance interzone
- Mettre à l’échelle automatiquement un cluster pour répondre à des demandes d’applications sur Azure Kubernetes Service (AKS)
- Créer des conteneurs et des bases de données Azure Cosmos DB en débit de mise à l’échelle automatique
- Documentation de Microsoft Dynamics 365
- Documentation de Microsoft 365
- Documentation sur l’ingénierie SRE
- AZ-400 : Développer une stratégie d’ingénierie de fiabilité de site (SRE)
- Application Web de base avec redondance de zone