Cet article présente un arbre de décision et des exemples d’options de haute disponibilité et de récupération d’urgence (DR) lors du déploiement d’applications IaaS (infrastructure-as-a-service) à l’aide d’Azure.
Architecture
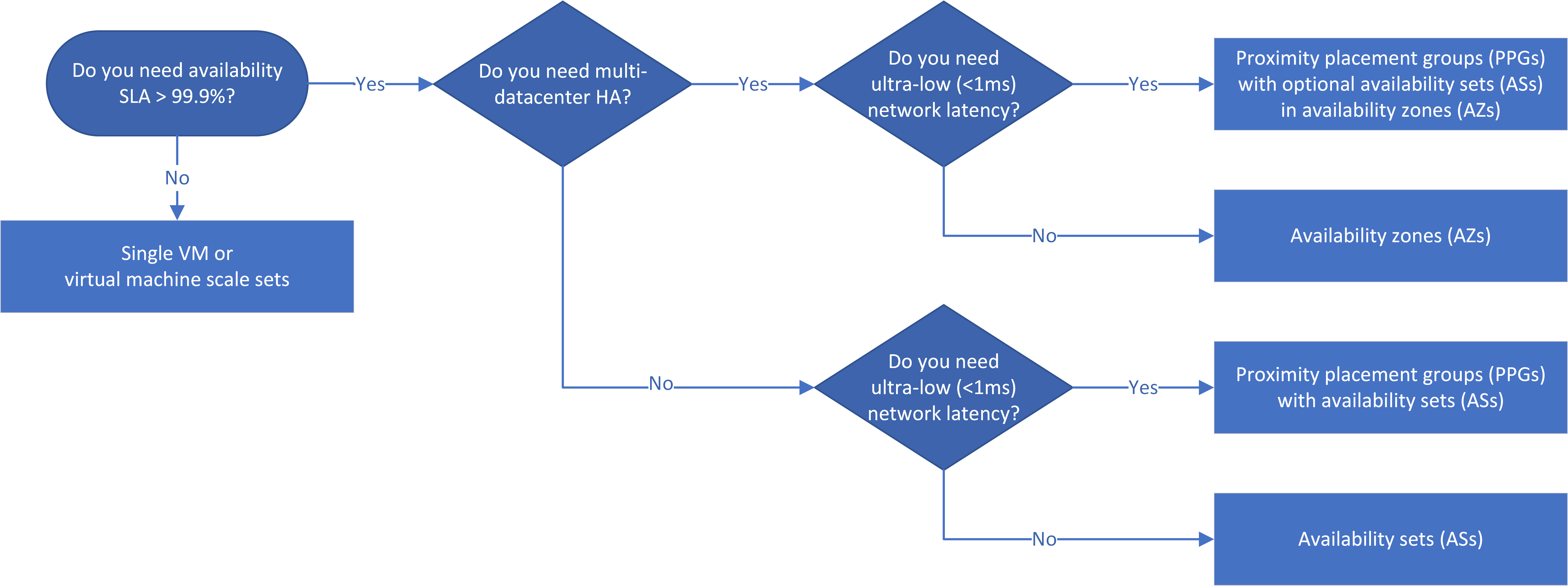
Workflow
Les groupes à haute disponibilité assurent la redondance et la disponibilité des machines virtuelles au sein d’un centre de données en répartissant les machines virtuelles sur plusieurs nœuds matériels isolés. Un sous-ensemble de machines virtuelles continue de fonctionner pendant les temps d’arrêt planifiés ou non de sorte que l’application entière reste disponible et opérationnelle.
Les zones de disponibilité sont des lieux physiques uniques qui couvrent les centres de données dans une région Azure. Chaque zone de disponibilité accède à un ou plusieurs centres de données qui disposent d’une alimentation, d’un refroidissement et d’un réseau indépendants, et chaque région Azure compatible avec une zone de disponibilité dispose d’un minimum de trois zones de disponibilité distinctes. La séparation physique des zones d’activité au sein d’une région protège les machines virtuelles déployées contre les défaillances des centres de données.
L’organigramme décisionnel reflète le principe selon lequel les applications HA doivent utiliser des zones de disponibilité si possible. Fonctionnant entre zones et entre centres de données, la haute disponibilité fournit un contrat SLA > 99,99 % en raison de la résilience aux défaillances du centre de donnes.
Il n’est pas garanti que les AS et les zones de disponibilité des différents niveaux d’application se trouvent dans les mêmes centres de données. Si la latence de l’application est une préoccupation majeure, vous devez regrouper les services dans un seul centre de données en utilisant les groupes de placement de proximité avec les zones de disponibilité et les (PPG) avec les zones de disponibilité et les AS.
Components
Autres solutions
Comme alternative à la récupération d’urgence régionale à l’aide d’Azure Site Recovery, si l’application peut répliquer des données en mode natif, vous pouvez implémenter la récupération d’urgence multirégionsà l’aide de serveurs de secours à niveau d’accès chaud ou à niveau d’accès froid, par exemple un cluster étendu pour la récupération d’urgence uniquement. Cette alternative n’est pas spécifiquement détaillée dans les exemples, mais pourrait être ajoutée à n’importe laquelle des solutions. Notez que la réplication entre régions est asynchrone et qu’une perte de données est attendue.
Si vous disposez de votre propre technologie de réplication des données, vous pouvez également l’utiliser pour créer une zone secondaire dans la région pour la récupération d’urgence. En fonction de la région de vos charges de travail, il peut également être possible d’utiliser Azure Site Recovery pour répliquer des éléments dans une autre zone, vous pouvez vérifier la disponibilité régionale et en savoir plus sur cette fonctionnalité dans Activer la récupération d’urgence de zone à zone pour les machines virtuelles Azure.
La haute disponibilité à plusieurs régions est possible, mais nécessite un équilibreur de charge global, tel que Front Door ou Traffic Manager. Pour en savoir plus, consultez Exécuter une application multiniveau dans plusieurs régions Azure pour la haute disponibilité.
Détails du scénario
Les architectures multiniveaux sont courantes dans les applications locales traditionnelles, elles constituent donc un choix naturel pour la migration d’applications locales vers le cloud ou pour le développement d’applications à la fois localement et dans le cloud. Les architectures multiniveaux sont généralement implémentées sous la forme d’applications IaaS divisées en niveaux logiques et en niveaux physiques, avec un niveau web ou de présentation supérieur, un niveau métier moyen et un niveau données.
Dans une application multiniveau, chaque niveau s’exécute sur un ensemble distinct de machines virtuelles. Les niveaux web et métier sont apatrides, ce qui signifie que n’importe quelle machine virtuelle du niveau peut traiter n’importe quelle requête pour ce niveau. Le niveau de données est une base de données répliquée, un stockage d’objets ou un stockage de fichiers. Plusieurs machines virtuelles à chaque niveau assurent la résilience en cas de défaillance de l’une d’entre elles, et les équilibreurs de charge répartissent les demandes entre les machines virtuelles.
Vous pouvez réduire les niveaux en ajoutant des machines virtuelles supplémentaires aux pools et utiliser les groupe de machines virtuelles identiques pour effectuer un scale-out automatique des machines virtuelles identiques. Comme vous utilisez des équilibreurs de charge, vous pouvez réduire les niveaux sans affecter le temps de fonctionnement de l’application.
Si le contrat de niveau de service (SLA) pour une application IaaS exige une disponibilité > 99 %, vous pouvez placer les machines virtuelles dans les ensembles de disponibilité, les zones de disponibilité et les groupes de placement de proximité pour configurer la haute disponibilité de l’application. Les solutions HA et DR que vous choisissez dépendent du contrat de niveau de service, des considérations de latence et des exigences régionales en matière de récupération d’urgence.
Cas d’usage potentiels
- Migrer une application multiniveau locale vers le cloud.
- Déployer une application multiniveau à la fois localement et dans le cloud.
- Configurer la haute disponibilité et la reprise d’activité pour une application IaaS.
Cette solution peut être utilisée pour n’importe quel secteur d’activité, y compris les scénarios suivants :
- Applications du secteur public
- Banque (secteur financier)
- Santé
Considérations
Les zones de disponibilité ne sont pas disponibles dans toutes les régions Azure.
Choisissez l’option de déploiement que vous souhaitez utiliser avant de générer la solution. Bien que possible, il n’est pas aisé de passer d’une option à une autre après le déploiement. Vous devez supprimer les machines virtuelles et les recréer à partir des disques managés sous-jacents, ce qui est un processus impliqué.
Assurez-vous que vous pouvez mapper votre application à la solution sélectionnée. De nombreux modèles et conceptions de résilience de la couche application n’entrent pas dans le cadre de cet arbre de décision.
Trois scénarios peuvent entraîner des redémarrages de machines virtuelles Azure : une tâche de maintenance matérielle non planifiée, un temps d’arrêt imprévu et une tâche de maintenance planifiée. Pour plus d’informations sur ces événements et les meilleures pratiques en matière de haute disponibilité afin de réduire leur impact, consultez Comprendre les redémarrages de machine virtuelle, la maintenance et les temps d’arrêt.
Machines virtuelles uniques
Si une application ne nécessite pas une disponibilité > 99,9 %, vous n’avez pas besoin de la configurer pour la haute disponibilité et vous pouvez déployer des machines virtuelles uniques. Vous pouvez utiliser des groupes de machines virtuelles identiques pour effectuer un scale-out automatique des machines virtuelles identiques. Déployez des machines virtuelles uniques sans spécifier de zone afin qu’elles soient réparties dans une région. Ces applications ont un contrat SLA de 99,9 % si vous utilisez des disques SSD Premium Azure.
Les machines virtuelles uniques utilisent la fonctionnalité de réparation de service par défaut intégrée dans tous les centres de données Azure. En cas de défaillance prévisible, cette fonctionnalité utilise généralement la migration en direct, mais lors d’événements imprévisibles, les machines virtuelles peuvent être redémarrées ou rendues indisponibles.
Haute disponibilité
Si l’application nécessite un SLA > 99,9 %, concevez l’application pour la haute disponibilité. Utilisez les zones de disponibilité si possible, car elles offrent une tolérance aux pannes des centres de données. Vous pouvez utiliser des AS au lieu de zones de disponibilité, mais l’utilisation d’AS réduit la disponibilité de 99,99 % à 99,95 %, car les AS ne tolèrent pas les défaillances des centres de données.
Les zones de disponibilité conviennent à de nombreux scénarios d’applications groupées, notamment les clusters SQL AlwaysOn, en utilisant les niveaux de haute disponibilité actif-actif, actif-passif ou une combinaison des deux niveaux de haute disponibilité à chaque niveau avec basculement rapide. La réplication synchrone est possible entre tous les nœuds du système de gestion de base de données (SGBD), en raison de la faible latence du réseau inter-zones. Vous pouvez également exécuter une configuration stretched-cluster entre les zones, qui a une latence plus élevée et prend en charge la réplication asynchrone.
Si vous souhaitez utiliser un arbitre de cluster basé sur une machine virtuelle, par exemple un témoin de partage de fichiers, placez-le dans la troisième zone de disponibilité, pour vous assurer que le quorum n’est pas perdu en cas de défaillance d’une zone. Vous pouvez également utiliser un témoin basé sur le cloud dans une autre région.
Toutes les machines virtuelles d’une zone de disponibilité résident dans un même domaine d’erreur et un même domaine de mise à jour, ce qui signifie qu’elles partagent une source d’énergie et un commutateur de réseau communs, et qu’elles peuvent tous être redémarrés simultanément. Si vous créez des machines virtuelles sur des zones de disponibilité différentes, vos machines virtuelles sont réparties efficacement entre les domaines et les UD de sorte qu’elles ne peuvent pas échouer ou être redémarrées simultanément. Si vous souhaitez disposer de machines virtuelles dans des zones redondantes, ainsi que de machines virtuelles inter-zones, vous devez placer les machines virtuelles d’AS dans des PPG pour vous assurer qu’elles ne seront pas toutes redémarrées en même temps. Même pour les charges de travail de machine virtuelle à instance unique qui ne sont pas redondantes aujourd’hui, vous pouvez toujours utiliser des AS dans les PPG pour permettre une croissance et une flexibilité futures.
Pour déployer des groupes de machines virtuelles identiques sur plusieurs zones de disponibilité, envisagez d’utiliser le mode d’orchestration, actuellement en préversion publique, qui permet de combiner domaines et zones de disponibilité.
Les zones de disponibilité avec les PPG internes de zone permettent d’obtenir l’une des latences réseau les plus basses d’Azure, et un contrat de niveau de service d’au moins 99,99 % grâce à la résilience de plusieurs centres de données. Utilisez la mise en réseau accélérée sur les machines virtuelles dans la mesure du possible.
Cette solution peut présenter un scénario dans lequel un service s’exécutant sur une machine virtuelle dans une zone doit interagir avec un service dans une autre zone. Par exemple, il peut y avoir un niveau web actif-actif et un niveau de base de données actif-passif entre les zones. Certaines requêtes franchissent des zones, ce qui entraîne une latence. Bien que la latence entre les zones soit toujours très faible, si vous devez garantir la latence la plus faible possible, conservez toutes les communications réseau entre les couches application à l’intérieur d’une zone.
Considérations relatives à la latence
La latence du réseau dépend, entre autres, de la distance physique entre les machines virtuelles déployées. Si une application nécessite une latence très faible entre niveaux, vous pouvez la déployer dans un centre de données unique en utilisant un PPG avec des AS pour chaque niveau. Si possible, utilisez la mise en réseau accélérée sur les machines virtuelles. Ce scénario autorise l’une des latences réseau les plus basses dans Azure et un contrat SLA de 99,95 %.
Vous pouvez utiliser les outils suivants pour avoir une meilleure idée des conditions de latence pour un large éventail de scénarios :
- Pour tester la latence entre les machines virtuelles, consultez Tester la latence du réseau des machines virtuelles.
- Pour tester la latence entre les zones, utilisez AvZone-Latency-Test. Ce test peut vous aider à déterminer quelles sont les zones logiques qui ont la plus faible latence pour votre abonnement.
- Pour tester la latence entre les régions Azure, utilisez http://www.azurespeed.com/. Cet outil régulièrement mis à jour peut être utile lorsque vous envisagez une réplication asynchrone entre régions.
Récupération d'urgence
Les considérations relatives à la récupération d’urgence incluent la disponibilité, la capacité de l’application à fonctionner dans un état sain et la durabilité des données, la préservation des données en cas de sinistre.
Le basculement à haute disponibilité doit être rapide, sans perte de données, et avoir un effet très limité sur le service. En revanche, un basculement de récupération d’urgence traditionnel peut être associé à un objectif de temps de récupération (RTO) plus long et à un objectif de point de récupération (RPO), il est asynchrone, avec une perte de données potentielle.
Vous pouvez tirer parti des zones de disponibilité à la fois en matière de haute disponibilité et de reprise après sinistre en utilisant une zone de disponibilité différente pour votre solution de reprise après sinistre. Les zones de disponibilité sont suffisamment proches pour permettre des connexions à faible latence avec d'autres zones de disponibilité (latence aller-retour inférieure à 2 ms). Cependant, elles sont suffisamment éloignées les unes des autres pour réduire la probabilité que des pannes locales ou des conditions météorologiques affectent plusieurs zones de disponibilité. Pour les charges de travail critiques, vous devriez envisager une solution qui utilise plusieurs régions en plus de plusieurs zones de disponibilité.
Azure Site Recovery vous permet de répliquer les machines virtuelles dans une autre région Azure pour la reprise d’activité et la continuité d’activité au niveau régional. Vous pouvez utiliser Azure Site Recovery pour récupérer vos applications en cas de panne de la région source, ou pour effectuer des analyses périodiques de récupération d’urgence afin de vous assurer que les exigences de conformité sont respectées.
Si votre application prend en charge Azure Site Recovery, vous pouvez fournir une solution de récupération d’urgence régionale pour une protection accrue si l’essentiel de l’application en a besoin. Toutefois, la haute disponibilité entre les zones et les centres de données peut être suffisante, car si une application est entièrement résiliente à la défaillance du centre de données, il ne doit y avoir aucun temps d’arrêt ni perte de données.
Optimisation des coûts
Il n’existe aucun coût supplémentaire pour les machines virtuelles déployées dans les zones de disponibilité. Il peut y avoir des frais supplémentaires de transfert de données entre machines virtuelles. Pour plus d’informations, consultez la page Tarification de la bande passante.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Shaun Croucher | Senior Consultant
Étapes suivantes
- Groupes à haute disponibilité
- Zones de disponibilité
- Groupes de machines virtuelles identiques
- Activer la reprise d’activité de zone à zone pour les machines virtuelles Azure
Ressources associées
- Style d’architecture multiniveau
- Application web multiniveau développée pour la haute disponibilité et la reprise d’activité sur Azure
- Exécuter une application web redondante interzone pour la haute disponibilité
- Exécuter une application web dans plusieurs régions Azure à des fins de haute disponibilité
- Exécuter une application multiniveau dans plusieurs régions Azure pour une haute disponibilité