Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
De nombreux éditeurs de logiciels indépendants (ISV) pensent à passer de la livraison de logiciels locaux à un modèle de livraison basé sur le cloud et saaS (software-as-a-service). Chez Microsoft, nous avons parcouru ce parcours avec un grand nombre de nos produits, et nous sommes invités à partager nos expériences réelles et les leçons clés que nous avons apprises le long de la route.
Notre objectif avec cet article est de donner une vue d’ensemble de la façon dont ce parcours a joué lorsque nous avons créé Microsoft Dynamics 365. Nous décrivons le processus de réflexion que nous avons suivi et les principaux facteurs pour chacune des décisions majeures que nous avons prises. Nous espérons que ce document donne un aperçu de l’évolution de notre produit à mesure que nous sommes passés de la livraison de logiciels locaux à un produit SaaS hyperscale utilisé par des millions d’utilisateurs dans des milliers d’organisations. Nous espérons qu’en lisant ce document, vous pouvez apprendre à partir de nos expériences et planifier votre propre parcours vers SaaS. Bien que le parcours Microsoft avec Dynamics 365 puisse être unique, nous pensons que les leçons et principes que nous avons appris peuvent toujours fournir des insights précieux pour les organisations de toute taille qui planifient leur propre transition vers un modèle SaaS.
Un bref historique de notre voyage
Microsoft Dynamics a une histoire approfondie en tant qu’ensemble de produits locaux. Nous avons adopté le cloud pour tous les nombreux avantages qu’il offre, et nous savions que notre technologie et notre modèle d’entreprise devaient s’adapter au fur et à mesure que nous nous sommes déplacés vers la fourniture de SaaS.
La première décision que nous avons prise était le choix entre la création de quelque chose de nouveau ou l’évolution de nos applications locales en services cloud. Pour Dynamics 365, nous avons cru deux choses. Tout d’abord, il y avait suffisamment de valeur dans les modèles de données et la logique métier que nous avions créés et validés avec des milliers de clients qu’il valait la peine d’évoluer nos solutions existantes. Deuxièmement, l’architecture en couches et l’infrastructure de plateforme de nos produits locaux fournissaient les bons leviers pour nous permettre d’adopter une grande architecture cloud plus rapidement que de commencer à partir de zéro. La combinaison de valeur et de vitesse, ainsi que la compréhension que nous pourrions adopter les principes natifs du cloud, a fait passer à SaaS basé sur le cloud et l’amélioration continue le bon choix pour Dynamics 365. D’autres organisations peuvent avoir des priorités différentes et se présenter à une autre stratégie.
Au début, nous avons décidé de nous concentrer sur la création du meilleur produit que nous pouvions créer sur la plateforme Microsoft Azure. Les plateformes cloud s’améliorent rapidement et nous voulions tirer parti de la richesse d’une plateforme au lieu de répartir nos ressources sur plusieurs clouds. D’autres fournisseurs SaaS peuvent prendre différentes décisions en fonction de leurs propres situations. Par exemple, un fournisseur de plateforme horizontale peut créer des logiciels permettant aux clients d’utiliser sur plusieurs clouds. Il est donc judicieux qu’ils aient une présence sur chacune de ces plateformes cloud. Mais un développeur d’applications SaaS peut choisir de se concentrer sur un cloud et d’obtenir les avantages de se concentrer sur ce fournisseur de cloud et son évolution. Pour Dynamics 365, nous savions que l’intégration sur Microsoft Azure nous donnerait une expérience plus intégrée et transparente tout en conservant une sécurité robuste et des performances élevées.
Comme nous avons commencé à explorer profondément la plateforme Azure et à planifier notre parcours SaaS, nous avons appris à exploiter et à mettre à l’échelle une plateforme de planification massive des ressources d’entreprise (ERP) dans le cloud. En même temps, Azure est devenu plus riche et plus capable, et il a introduit de nouvelles fonctionnalités que nous n’avons pas pu imaginer. Nous savions que l’évolution constante du cloud signifiait que notre migration ne serait pas une chose ponctuelle. Au lieu de cela, nous avons pensé à l’amélioration continue à chaque étape de notre parcours. L’amélioration continue affecte tout ce que nous faisons et, au début de notre parcours, nous avons dû apporter des modifications significatives, de notre architecture globale à la façon dont nous avons traité les requêtes de base de données. Nous faisons constamment évoluer notre solution pour tirer le meilleur parti de ce que le cloud permet. Nous avons adopté l’architecture de microservice et nous utilisons l’IA générative dans le cadre de notre évolution continue. Ces approches et technologies sont plus faciles à créer, déployer et exploiter quand vous utilisez une plateforme cloud puissante comme Microsoft Azure.
Un ingrédient essentiel de l’amélioration continue dans le cloud est la télémétrie. Avec des données de télémétrie efficaces, vous pouvez comprendre comment l’application est utilisée et comment elle s’exécute, même au niveau des fonctionnalités individuelles. La télémétrie fournit des insights qui vous permettent de résoudre les problèmes en sachant ce qui s’est passé au lieu de suivre des approches locales traditionnelles telles que la reproduction du problème et du débogage. La télémétrie vous permet également de prendre des décisions d’ingénierie basées sur des données réelles et de confirmer les hypothèses de produit par le biais d’expérimentations et de données. La création d’une infrastructure de télémétrie ainsi que les stratégies appropriées concernant les données conservées et la durée pendant laquelle elles sont gérées est un élément qui doit être effectué le plus tôt possible.
Comprendre les stratégies de classification et de rétention des données gérées par votre application nécessite également une attention supplémentaire dans le cadre du parcours vers SaaS. En tant que fournisseur SaaS, vos responsabilités en vertu des lois actuelles et émergentes sur la confidentialité des données diffèrent de celles que vous aviez lorsque vous fournissiez des logiciels que les clients déployaient et exécutaient eux-mêmes. Il est essentiel de comprendre les réglementations en matière de confidentialité des données qui s’appliquent à vous en tant que fournisseur SaaS. Vous devez également obtenir vos processus de classification et de rétention des données en place au début de votre parcours cloud.
Comment nous avons préparé le voyage
Définition d’un MVP
Notre stratégie s’est concentrée sur la création d’un produit minimum viable (MVP) afin que nous puissions obtenir la solution aux clients le plus rapidement possible et commencer à découvrir les défis uniques et les opportunités de SaaS. Ce focus était un choix stratégique. Nous pensons que l’apprentissage et l’itération rapides sont essentiels dans le cloud et que la définition du MVP est un point de départ.
Le terme produit minimum viable est souvent mal compris. Il est important de considérer que les deux attributs du MVP sont tout aussi importants :
- Minimum : déterminez le moyen le plus rapide de commencer à générer de la valeur pour vos clients. Plus vos clients utilisent votre solution, plus vous commencez à apprendre comment ils l’utilisent et comment vous pouvez continuer à l’améliorer.
- Viable : il est essentiel que vous étenduez votre produit afin qu’il soit assez complet pour que quelqu’un obtienne une valeur réelle à partir de celui-ci. Au départ, vous choisissez un sous-ensemble des fonctionnalités globales que vous prévoyez de générer. La sélection du sous-ensemble approprié est importante : si vous êtes trop minimal pour être viable, les clients n’utilisent pas le produit et vous n’obtenez pas les commentaires dont vous avez besoin pour évoluer.
Pour Dynamics 365, nous nous sommes concentrés sur la création d’un produit prêt à être utilisé par les clients dès son lancement. Ensuite, nous avons appris comment les clients en ont tiré parti, et nous avons reçu une grande quantité de commentaires et de données télémétriques. Nous avons utilisé ces données pour informer notre parcours de produit, itérer et le rendre meilleur et mieux au fur et à mesure que nous avons progressé.
Notre stratégie était de créer un produit que les nouveaux clients aimeraient. Bien que nous étions intentionnels de rendre les migrations des clients locaux existants plus faciles, la migration était un objectif secondaire par rapport à la création d’un produit moderne. Cette stratégie signifiait que nos nouveaux clients auraient une expérience complète dans Dynamics 365 dès le début. Ils nous ont également fourni des commentaires inestimables, et ils l’ont fait avec l’avantage des yeux frais. Ils n’ont pas déjà été fortement investis dans les produits Dynamics locaux. Ils nous ont donc aidés à créer un produit qui était vraiment natif du cloud et une offre SaaS complète. Comme nous avons continué d’améliorer et d’étendre nos capacités, nous avons finalement atteint le point où l’ensemble de fonctionnalités était un super-ensemble des produits locaux. À ce stade, nous pourrions commencer à prendre en charge la transition de nos clients existants de la version locale vers Dynamics 365 plus avancé.
Nous avons consciemment choisi cette stratégie, car nous savions qu’elle fonctionnerait bien pour un système ERP. Dans d’autres produits, il peut être possible de choisir un sous-ensemble des fonctionnalités du produit à déplacer en premier, puis d’ajouter d’autres fonctionnalités au fil du temps. Mais dans un ERP, les composants sont étroitement interconnectés. Le produit n’est pas utile tant qu’il n’existe pas un ensemble de fonctionnalités sur tous ces composants, offrant ainsi aux clients une expérience utile de bout en bout. L’étendue MVP est une tranche horizontale de fonctionnalités sur chaque composant. Nous avons décidé de sélectionner un ensemble croisé de fonctionnalités qui prenaient en charge les cas d’usage des nouveaux clients :
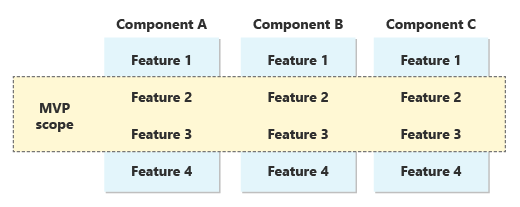
Pour d'autres solutions, il peut être judicieux de délimiter un MVP comme un composant dans son ensemble. Il est important de prendre une décision consciente sur la stratégie que vous suivez lorsque vous commencez votre propre parcours vers SaaS. La clé est que le livrable initial sur le marché devrait être aussi petit que possible, tout en étant suffisamment complet pour obtenir une utilisation réelle.
Comme nous avons planifié et amélioré, nous avons gardé à l’esprit que les attentes des clients étaient en constante évolution, aussi. Au lieu de migrer notre produit dans son état actuel exact, nous avons plutôt planifié ce dont les clients auraient besoin au moment où nous avions un produit prêt à être utilisé. Un parcours vers SaaS couplé à une migration cloud est souvent un effort à long terme, prenant des mois ou même des années. Il est important de ne pas perdre de vue les changements dans la demande des clients pendant ce temps. Sinon, vous pouvez consacrer beaucoup d’efforts à la création d’un élément qui ne répond pas entièrement aux besoins des clients lorsqu’il arrive finalement.
Utilisation, satisfaction des clients et coûts
Le chiffre d’affaires des logiciels locaux est généralement reconnu au moment où la transaction de vente se produit, et la responsabilité du déploiement et de l’adoption réussis repose avec le client. Avec un modèle d’abonnement SaaS cloud, les clients commencent souvent par licencer quelques sièges et n’étendent leur abonnement qu’une fois la solution éprouvée. Tous les sièges qu’ils achètent, mais ne sont pas utilisés sont un risque, car ils peuvent être annulés lors du prochain anniversaire de l’abonnement. Par conséquent, avec la transition vers SaaS, nous avons modifié les métriques principales que nous avons utilisées pour stimuler notre activité.
Dans le monde local des logiciels sous licence, le principal objectif était le chiffre d’affaires. Dans le cloud, le focus était sur l’utilisation et la satisfaction des clients. Ces métriques sont devenues les indicateurs de progression du chiffre d’affaires et de la croissance des revenus. Nous avons consacré des efforts à réduire le temps nécessaire au déploiement réussi, à fournir une visibilité des licences achetées mais inutilisées, et à maintenir une grande satisfaction entre les rôles utilisateur et métier. Dès le début, nous nous concentrons sur la création de produits que les clients aiment utiliser. Nous savons de l’expérience que lorsque les clients obtiennent de la valeur à l’aide du produit, le chiffre d’affaires suit. En hiérarchisant l’expérience client et l’utilisation, nous définissons les bases d’une stratégie commerciale réussie.
Lorsque vous créez SaaS, le coût des biens vendus (COGS) compte beaucoup, en particulier lorsque vous effectuez une mise à l’échelle et que vos coûts augmentent également. Mais il est préférable de hiérarchiser la satisfaction et l’utilisation en premier. Si vous fournissez une bonne expérience client, vous pouvez optimiser les coûts de livraison du service en utilisant plus efficacement vos ressources et en tirant parti de nouvelles fonctionnalités de plateforme. Si l’expérience n’est pas suffisante, l’utilisation sera inférieure et vous aurez moins de clients à satisfaire. Ainsi, lorsque nous examinons nos progrès, nous nous concentrons sur trois indicateurs de performance clés, dans l’ordre d’importance :
- Satisfaction des clients : nos clients aiment-ils l’expérience d’utilisation du produit ? Qu’est-ce que leurs commentaires ?
- Utilisation : combien d’utilisateurs avons-nous ? Combien d’abonnements avons-nous ? Notre utilisation s’accélère-t-elle ? Quel est le temps entre l’achat et l’utilisation ? Comment encourager les clients à utiliser tous les abonnements qu’ils achètent ?
- COGS : Combien coûte-t-il pour servir nos clients ?
Il est également important de réfléchir à la façon dont un produit SaaS génère des revenus. Les clients doivent comprendre comment ils paient pour le service, et le modèle de tarification doit être judicieux pour eux. Dans de nombreuses solutions SaaS métier à entreprise, le nombre d’utilisateurs que le client a est un excellent indicateur des ressources consommées lorsque les utilisateurs utilisent le système. Plus les utilisateurs qui utilisent activement le système, plus les ressources système sont nécessaires pour leur donner une bonne expérience. Le coût pour le client reflète ce fait. Les clients ont une compréhension intuitive d’une structure tarifaire basée sur l’utilisateur.
Toutefois, il existe certaines situations où le nombre d’utilisateurs ne donne pas une bonne indication des ressources consommées par le client. Par exemple, lorsque l’équipe marketing d’un client envoie un grand nombre de messages pour une campagne d’e-mail, il peut arriver qu’un seul utilisateur envoie des millions de messages électroniques. De même, un processus en arrière-plan, et non un utilisateur, importe les détails de commande. Il est important que les clients comprennent les métriques pour lesquelles ils sont facturés et peuvent prédire leur facture. Vous pouvez choisir d’utiliser des compteurs comme le nombre de contacts auxquels ils envoient des messages électroniques ou le nombre de lignes de commande qu’ils traitent chaque mois.
Architecture de Dynamics 365
Identité, authentification et autorisation
Les applications métier telles que Dynamics 365 gèrent les données métier à valeur élevée et automatisent les activités métier critiques. Il est essentiel de s’assurer que seuls les utilisateurs autorisés ont accès aux données et aux actions du système. En utilisant l’ID Microsoft Entra, les entreprises peuvent gérer l’accès à Dynamics 365 avec les mêmes outils et plateformes qu’elles utilisent déjà dans leur patrimoine informatique. Les clients peuvent tirer parti des fonctionnalités de sécurité avancées telles que l’accès conditionnel sans travailler davantage sur notre part. Les fonctionnalités permettant de sécuriser leur système Dynamics continuent d’évoluer avec l’investissement continu de Microsoft dans la plateforme Entra.
Dynamics 365 affecte des utilisateurs aux rôles et attribue des autorisations pour des données et des actions spécifiques à ces rôles. Cette approche suit un modèle courant de gestion de l’autorisation au-delà de l’authentification utilisateur fournie par Entra. Cette approche offre également la possibilité pour Dynamics 365 d’appliquer des exigences métier recommandées comme la séparation des tâches.
Modèle de gestion locative
Chaque organisation qui utilise Dynamics 365 s’attend à ce que leurs données soient conservées et isolées de l’accès par d’autres organisations. Nous modélisons chaque organisation en tant que locataire, et chaque locataire dispose de nombreux utilisateurs qui peuvent chacun utiliser les produits et travailler avec les données de l’organisation. Le partage des ressources réduit les composants de coût de l’exécution des services, mais le partage doit être équilibré par rapport aux exigences pour garantir les niveaux attendus d’isolation du locataire. Heureusement, la plateforme Azure fournit des fonctionnalités enrichies pour permettre aux fournisseurs d’applications d’équilibrer les coûts au fur et à mesure qu’ils fournissent une isolation requise.
Par exemple, nous avons estimé qu’il était important de conserver les données métier de chaque locataire dans une base de données SQL distincte. Cette séparation nous permet, entre autres, d’implémenter Azure SQL Transparent Data Encryption (TDE) avec des clés gérées par le client, un composant important de nos promesses d’approbation d’entreprise concernant les données. Azure SQL, notamment les pools élastiques, nous offre une rentabilité tout en autorisant une base de données distincte par client. Outre l’augmentation des coûts d’infrastructure, la décision de conserver une base de données distincte par locataire augmente la complexité de la gestion. Il n’existe pas suffisamment d’administrateurs de base de données pour gérer manuellement les bases de données à l’échelle du service Dynamics, ce qui a entraîné un investissement significatif dans l’automatisation des tâches de gestion. Pour plus d’informations sur le fonctionnement de Dynamics 365 avec des bases de données à grande échelle, consultez Exécution de bases de données 1M sur Azure SQL pour un fournisseur SaaS volumineux : Microsoft Dynamics 365 et Power Platform.
Pour chaque niveau de notre solution, notre stratégie a été d’utiliser des fonctionnalités de plateforme Azure natives pour appliquer l’isolation du locataire et fournir une mise à l’échelle et une résilience tout en obtenant simultanément des gains d’efficacité des coûts où nous pouvons. Nous examinons toujours les endroits où nous pouvons optimiser notre système, tout en hiérarchisant la sécurité des locataires et en fournissant une expérience client exceptionnelle.
Tampons de déploiement
Dynamics 365 fonctionne à hyperscale. Il y a des centaines de milliers de clients, avec des millions d’utilisateurs, chacun en fonction de nos produits. Ces chiffres continuent de croître au fil du temps. Les solutions SaaS doivent généralement être conçues pour être mises à l’échelle et doivent prendre en charge les clients à travers la planète.
Dans le cloud, il est essentiel de passer de scale-up à scale-out dans la mesure du possible. Si une demande supplémentaire peut être satisfaite en ajoutant davantage de nœuds (scale-out) au lieu de rendre les nœuds existants plus puissants (scale-up) et que cette relation est proche de linéaire, une approche basée sur le scale-out offre le potentiel de générer une échelle encore plus élevée. Dynamics 365 utilise un modèle scale-out au niveau de l’application. La supervision intégrée détecte l’augmentation de la charge pour des locataires spécifiques et ajoute davantage de nœuds pour répondre à la demande.
Conjointement avec votre modèle de locataire et votre architecture scale-out, vous pouvez suivre le modèle Empreintes de déploiement, chaque empreinte prenant en charge un ensemble de clients. Lorsqu’un tampon approche de sa capacité maximale, vous pouvez approvisionner un nouveau tampon et commencer à déployer de nouveaux clients là-bas. En utilisant des timbres, vous pouvez soutenir la croissance continue des clients et vous pouvez étendre votre présence régionale à de nouvelles zones géographiques.
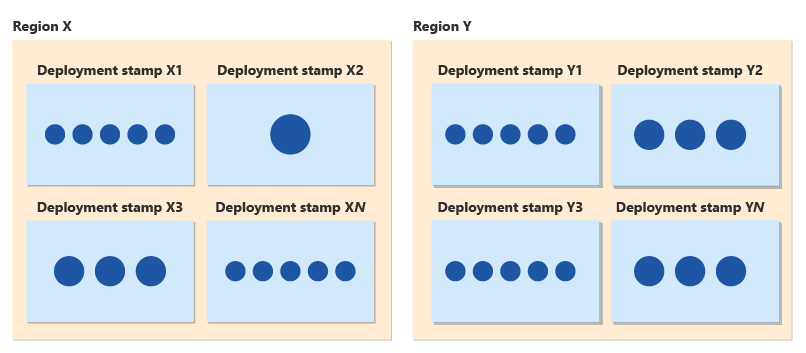
En utilisant des tampons de déploiement, vous bénéficiez également d’avantages en matière de fiabilité. Vous pouvez déployer progressivement nos mises à jour et les processus de déploiement sécurisés vous aident à déployer progressivement des modifications dans une flotte mondiale. Chaque tampon est indépendant d’autres, donc si un tampon rencontre un problème, seul le sous-ensemble des clients alloués à ce tampon est affecté. Les empreintes vous aident à réduire le rayon d’explosion d’un problème ou d’une erreur et à contribuer à une stratégie globale de récupération d’urgence.
Comme pour chaque décision architecturale, basez votre utilisation des tampons de déploiement sur vos besoins métier. Le déploiement d’un tampon nécessite le déploiement d’un ensemble d’infrastructure pour le prendre en charge. Si la taille minimale d’un tampon est trop grande, il est difficile de justifier le déploiement d’un nouveau tampon sur un nouveau marché, car vous devez d’abord atteindre une masse critique de clients. Il est également important de comprendre comment la croissance de vos clients affecte leur utilisation du produit, car à mesure qu’ils augmentent, ils utilisent davantage de ressources du tampon. Ces considérations sont aussi importantes pour un petit éditeur de logiciels indépendants que pour une plateforme hyperscale comme Dynamics 365.
Plans de contrôle et configuration
Lorsqu’un éditeur de logiciels indépendants passe à un modèle de distribution SaaS basé sur le cloud, l’un des changements les plus spectaculaires est qu’il prend en charge le fonctionnement du service. Dans la plupart des logiciels locaux, les services informatiques des clients sont responsables du déploiement, de la configuration et de la gestion des systèmes. Les clients eux-mêmes s’occupent des systèmes de surveillance et prennent des décisions sur le moment où déployer des mises à jour. Ils sont également responsables de l’exécution de toutes les étapes impliquées. Souvent, les partenaires d’intégration de services spécialisés aident les clients à exploiter des produits complexes dans leur environnement. Le fournisseur de logiciels devient responsable de toutes ces activités sur tous ses clients en passant à un modèle cloud et SaaS. Avec la transition vers software as a service, il est nécessaire de créer le service ISV et d’un plan de contrôle pour automatiser le travail d’intégration et de gestion des locataires. Les plans de contrôle et l’automatisation sont importants, même avec un nombre relativement faible de clients.
Il est recommandé de concevoir un plan de contrôle résilient, fiable et hautement disponible. Trop souvent, les plans de contrôle sont traités comme un après-coup dans le parcours de création d’un produit SaaS. Mais si un plan de contrôle n’est pas conçu avec le même soin que le reste du produit, il risque de présenter un point de défaillance unique. Sans attention appropriée à la résilience du plan de contrôle, une défaillance du plan de contrôle peut affecter tous les clients.
Dans Dynamics 365, nous avons un plan de contrôle au niveau du service, qui gère les opérations telles que l’intégration de nouveaux locataires. Nous disposons également d’un plan de contrôle au niveau du client, qui permet à l’équipe d’administration d’un client de lancer des activités de maintenance et de modifier les configurations elles-mêmes, car elles peuvent effectuer ces opérations via le service.
Personnalisation et extensibilité
Une proposition de valeur principale du modèle SaaS est que tous les clients exécutent une version du code de service. Lorsque les clients exécutent une version du code de service, les problèmes sont identifiés et résolus une seule fois, et tous les clients bénéficient rapidement de ces solutions. L’objectif est de pouvoir évoluer en permanence la version du service sans que les clients n’ont à planifier le test et le déploiement des mises à jour.
Pour obtenir cet avantage, il existe de nombreuses modifications requises par rapport à l’exécution de logiciels dans le monde local. Par exemple, vous devez planifier des processus et des procédures pour réduire la probabilité de régressions.
Dans la transformation Dynamics 365, un domaine dans lequel nous avons investi était le développement d’extensibilité basée sur des modèles riches. Les applications ERP demandent l’extensibilité pour prendre en charge l’intégration à d’autres systèmes métier critiques et répondre aux besoins fonctionnels uniques des clients spécifiques. Au lieu de la personnalisation au niveau du code source, qui était typique des applications locales, nous avons introduit des fonctionnalités permettant d’étendre des modèles de données via des métadonnées spécifiques au locataire et de déclencher une logique étendue en fonction des événements qui se produisent dans le système.
Nous avons ajouté des fonctionnalités d’isolation et de gouvernance pour protéger le service et d’autres locataires contre les problèmes dans la logique étendue d’un autre locataire. Notre approche a donné aux clients le niveau d’extensibilité requis, mais leur a permis de continuer à utiliser la même version de produit. En outre, les mises à jour peuvent être fournies au produit sans que les clients n’ont à fusionner nos modifications et à reconstruire leur code pour que leurs extensions fonctionnent avec des versions plus récentes du produit.
La personnalisation peut ne pas être requise pour chaque produit, mais si un produit le requiert, la personnalisation devient un facteur de conception critique. Vous devez répondre à l’exigence sans compromettre les principaux avantages du modèle SaaS. Cette exigence était un focus significatif pour Dynamics 365. L’extensibilité pilotée par le modèle a conservé la proposition de valeur SaaS et amélioré la capacité des clients à créer et à maintenir leurs extensions.
Comment nous avons conçu Dynamics 365 pour la résilience
Comme vous considérez votre modèle de déploiement sur Azure, un composant essentiel à prendre en compte est votre résilience s’il existe des problèmes dans un service dépendant, par exemple, un problème de mise en réseau, un problème d’alimentation ou la maintenance d’une machine virtuelle. Dans le monde local, où l’infrastructure sert un seul locataire client, de nombreux clients s’appuient sur des stratégies de haute disponibilité pour chaque composant d’infrastructure. Toutefois, lorsque vous envisagez la résilience à l’échelle du cloud, la haute disponibilité est souvent nécessaire, mais pas suffisante. À grande échelle, des échecs surviennent.
Une zone de focus principale pour Dynamics 365 vise aujourd’hui à cibler la redondance entre les zones de disponibilité Azure afin de permettre aux services Dynamics critiques de continuer de fonctionner en toute transparence, même si une panne affecte un centre de données ou une zone de disponibilité entière.
Pour appliquer cet état d’esprit à votre propre solution, il existe certaines pratiques importantes à suivre.
- Veillez à investir dans des outils de surveillance pour identifier rapidement les problèmes. Avec SaaS, vos clients s’attendent à connaître les pannes et à s’engager rapidement pour restaurer le service.
- Utilisez des fonctionnalités de plateforme telles que les zones de disponibilité et la redondance de zone si elles conviennent à votre service.
- Concevez vos applications pour la résilience à chaque couche. Par exemple, il est important de prendre en compte d’autres meilleures pratiques cloud telles que l’utilisation de tentatives de réexécution, d'interrupteurs automatiques et de coupe-circuits, et l’adoption de pratiques de communication asynchrones. Ces pratiques peuvent maintenir votre service en bonne santé même si d’autres services dont vous dépendez sont soumis au stress.
- Tenez compte de la disponibilité de votre plan de contrôle, en particulier parce qu’il a un rôle dans la récupération de votre solution lorsque les ressources d’infrastructure sont affectées.
- Lorsque vous avez implémenté des fonctionnalités de résilience, exécutez des tests. Vous ne savez jamais si vos plans et fonctionnalités sont complets jusqu’à ce que vous essayiez de les utiliser. Il peut être utile d’exercer vos processus de basculement dans le cadre de vos activités de maintenance normales, ce qui peut vous donner à la fois une approche de la maintenance sans temps d’arrêt et une validation de vos mécanismes de basculement.
Le pilier de fiabilité d’Azure Well-Architected Framework fournit d’excellents conseils sur ces sujets.
Comment nous nous sommes adaptés à un environnement cloud
Dynamics 365 a évolué vers une architecture sophistiquée native pour le cloud, mais il est courant que les éditeurs de logiciels indépendants effectuent des transitions plus limitées, en mode lift-and-shift, depuis des environnements locaux vers le cloud. Nous avons discuté du modèle de définition d’un MVP pour obtenir rapidement votre service SaaS dans les mains des clients, ce qui commence le cycle d’apprentissage et d’amélioration continue. Mais il y a un équilibre. Lift-and-shift devrait vraiment être Lift, shift, and adapt.
Plus haut dans cet article, nous avons discuté de la conception pour la résilience avec les zones de disponibilité et d’autres meilleures pratiques cloud. Il existe d’autres domaines où les modèles de conception locaux courants entraînent également des défis ou des coûts plus élevés dans le cloud. Par exemple, dans les applications locales, il est courant de stocker des objets volumineux binaires dans une base de données relationnelle. Par exemple, vous pouvez stocker un document PDF lié à une commande client dans le cadre de la commande client dans une base de données SQL. Dans le monde local, cette approche simplifie la cohérence entre les sauvegardes et les fonctions de restauration à un point dans le temps. Toutefois, dans le cloud, les objets volumineux stockés dans la base de données peuvent être coûteux. En outre, les objets blob de stockage Azure facilitent le stockage des grands objets binaires, et une logique simple est requise pour maintenir des sauvegardes cohérentes.
Il est important de réfléchir aux choses que vous devez faire dans le cadre d’une transformation cloud. Vous devez effectuer ces opérations qui produisent un produit cloud plus fort. Mais vous devez également l’utiliser comme opportunité d’accéder rapidement au marché et de commencer le cycle vertueux de l’apprentissage et de l’amélioration continue.
Le cloud peut également rendre entièrement nouvelles solutions pratiques qui n’étaient pas une option dans un environnement local. L’un des processus les plus gourmands en performances dans un système ERP est la planification des ressources de fabrication ou MRP II. MRP II examine l’inventaire en main, les commandes entrantes et sortantes attendues et les exigences de fabrication. Ensuite, il détermine ce qu’une entreprise doit acheter ou faire pour satisfaire les commandes attendues. Dans Dynamics local, cette fonctionnalité a été implémentée dans le code d’application qui a fonctionné directement sur le magasin relationnel. La fonction de planification a consommé beaucoup de capacité système et s’est exécutée pendant une longue période. Dans les premières versions cloud, la fonctionnalité locale a été mise à l’avant inchangée, mais avec les mêmes défis de mise à l’échelle et de performances. Ensuite, il y a quelques années, nous avons introduit un nouveau microservice en mémoire qui pourrait effectuer la même exécution de planification dans une fraction du temps et sans impact sur les performances. Important, étant donné que le microservice est un cœur essentiel d’un système de fabrication, nous l’avons introduit comme une fonctionnalité que les clients pouvaient choisir d’accepter après avoir vérifié dans leurs environnements de bac à sable qu’il a produit les résultats corrects. À mesure que d’autres clients ont pivoté vers le nouveau microservice, nous avons déclenché des efforts pour permettre à chaque client d’utiliser le microservice afin que l’ancienne fonctionnalité puisse être déconseillée. Avec MRP II devenant quelque chose qui pourrait être exécuté en quelques minutes à tout moment, les organisations pourraient être plus agiles. Le cloud a rendu la création et la connexion d’un microservice en mémoire pratique, et de bons principes d’ingénierie SaaS ont permis même à cette partie la plus critique du service d’évoluer sans perturber les clients.
Comment nous avons migré des clients existants vers le cloud
La migration d’une base de client existante peut être le moyen le plus rapide de développer un service cloud à mettre à l’échelle. Toutefois, lorsque nous avons apporté Dynamics 365 au cloud, nous nous sommes concentrés initialement sur les nouveaux clients. Il y avait deux raisons clés :
- Cette approche nous a permis de mesurer si nous avions fourni une solution SaaS qui s'impose par ses propres mérites et pas simplement une solution attrayante pour des clients sur site à la recherche d’une migration cloud simple.
- Nous pourrions nous concentrer sur le MVP et différer les tâches telles que la création d’outils pour la migration des clients existants.
Après avoir vu la traction avec de nouveaux clients, nous avons ensuite pu nous concentrer sur la migration des clients locaux existants.
Nous avons constaté que les clients ont souvent peur du coût et de la complexité du déplacement. Il était important que nous fournissions des outils qui réduisent le coût et suppriment les facteurs inconnus. Nous avons développé des outils pour faciliter l’analyse de l’effort de migration de leurs données vers de nouveaux schémas qui avaient évolué dans notre produit cloud et pour comprendre l’impact de la migration sur les extensions et les intégrations du client. Nous avons également constaté qu’il était utile de créer d’autres outils et programmes qui mettent des limites autour du temps et du coût de migration.
Le passage au cloud offre uniquement des avantages aux clients en supprimant une grande partie du fardeau de gestion des systèmes auxquels ils font face avec des produits locaux, mais la mise en évidence des avantages de votre version cloud est également un facteur de motivation important.
Comment nous avons appris à utiliser Dynamics 365 en tant que SaaS
Une fois que vous avez défini un MVP et effectué l’ingénierie pour soulever, déplacer et adapter, vous devez vous concentrer sur l’exploitation du service SaaS pour le compte de vos clients. Cette transformation est énorme. Dans le monde local, les fournisseurs de logiciels créent et expédient les logiciels, les intégrateurs de systèmes le déploient et l’organisation informatique du client ou le fournisseur externalisé l’exécute. Avec SaaS, non seulement le fournisseur SaaS est principalement responsable de l’exploitation du service, mais il est également responsable de son fonctionnement pour des centaines à des milliers de clients en même temps.
Nous avons appris beaucoup en exploitant Dynamics 365 dans le cloud pour un grand nombre croissant de clients.
Surveiller: en tant que fournisseur de services, les clients s’attendent à détecter les problèmes d’intégrité des services avant qu’ils ne le fassent, et ils s’attendent à ce que vous travailliez immédiatement sur des résolutions. Un problème de santé ne se pose pas uniquement lorsque le service est arrêté. La vue d’un client d’un service défectueux inclut le service qui s’exécute lentement ou se comporte de manière incorrecte. Il est essentiel que vous développiez des outils de surveillance adéquats : ce développement fait partie de votre service, et non pas un accessoire facultatif.
Communiquer : dans le monde local, le client peut voir son équipe informatique travailler sur un problème. Dans le cloud, ils ne peuvent pas. Il est essentiel de communiquer lorsque vous détectez un problème de santé du service, de continuer à informer sur la progression de la résolution et de confirmer le tout est OK une fois le problème résolu. La nature des communications varie selon la gravité du problème. Votre pipeline de communications fait également partie intégrante de votre service SaaS et vous devez vous assurer que les communications peuvent réussir même lorsque les parties principales de l’infrastructure de votre service SaaS sont compromises.
Vue complète de la pile : dans le monde local, le fournisseur d’applications est généralement responsable du composant d’application et le client possède l’infrastructure sous-jacente. Dans le cloud, vous êtes responsable de l’ensemble du stack. Si le service a un problème d’intégrité, le client vous demande de détecter, de communiquer et de réparer, si le problème se trouve dans l’application ou dans la plateforme cloud sur laquelle il s’exécute.
Automatiser : si les humains sont tenus d’effectuer des étapes manuelles dans le fonctionnement du service, les erreurs seront inévitablement faites. Toutes les actions possibles doivent être automatisées et journalisées. Si une action est requise sur suffisamment de nœuds de service, l’automatisation est la seule option. Un excellent exemple est l’administration de base de données pour Dynamics 365. Avec notre décision de conserver les données de chaque locataire dans une base de données Azure SQL distincte, nous avons besoin de développer l’automatisation pour gérer toutes les tâches généralement effectuées par une DBA, par exemple, la maintenance d’index et l’optimisation des requêtes. Pour plus d’informations sur la gestion des bases de données à grande échelle, consultez Exécution de bases de données 1M sur Azure SQL pour un fournisseur SaaS volumineux.
Déploiement sécurisé : dans la mesure du possible, les modifications doivent suivre un processus de déploiement sécurisé. Tout d’abord, les modifications sont introduites dans des environnements à faible risque ( par exemple, une région cloud avec seulement des clients plus petits ou des charges de travail moins critiques). Ensuite, ils passent à un groupe de clients légèrement plus volumineux, plus complexes, et ainsi de suite, jusqu’à ce que tous les clients aient été mis à jour. À chaque étape, la surveillance doit être effectuée pour déterminer si la modification réussit. En cas de problème, le processus doit arrêter le déploiement des modifications et atténuer les problèmes, ou le restaurer là où il a déjà été déployé. Les pratiques de déploiement sécurisées s’appliquent aux modifications de code et de configuration. Pour plus d’informations, consultez L’avancement des pratiques de déploiement sécurisé.
Gestion des incidents en direct : pour nous, un incident de site en direct signifie qu’un client rencontre un problème avec notre service en production qui nécessite un engagement d’ingénierie. Il peut s’agir d’un problème de santé que nous détectons ou d’un problème signalé par le client que nos équipes d'assistance ne peuvent pas résoudre seules. L'excellence du fonctionnement en direct est cruciale pour le succès du SaaS. Voici quelques points clés de notre expérience :
- L’équipe d’ingénierie doit gérer les incidents de site en direct. Auparavant, de nombreuses entreprises disposaient d’opérations distinctes ou d’équipes d’ingénierie de support. Nous avons fait un choix explicite pour que nos équipes d’ingénierie principales couvrent les incidents de site en direct. Ils ont la meilleure expertise, et le fait de voir les problèmes de première main inspire la bonne créativité et l’énergie nécessaire pour stimuler un progrès réel et rapide, ainsi que des conceptions futures améliorées. Il s’agit d’un élément qui doit être pris en compte lors de la planification des planifications de développement, mais il génère de grands résultats.
- Le leadership en cas d’incident en direct est une compétence, et il est difficile de le reconnaître, de le former, d’apprendre à l’embaucher et de le récompenser.
- La priorité doit être la détection, l’isolation et l’atténuation. Récupérez la santé du client, puis vous inquiétez des améliorations à long terme.
Apprenez et améliorez : Quelqu’un a dit une fois : « Ne jamais gaspiller une bonne crise ». Chaque incident en direct est une opportunité d’améliorer. Une fois l’atténuation terminée, assurez-vous que vous demandez comment détecter des problèmes similaires plus rapidement, comment corriger le problème sous-jacent pour le résoudre entièrement, comment réduire l’impact des problèmes similaires, si d’autres problèmes similaires peuvent exister ailleurs dans le service et comment empêcher toute la classe de problèmes. La hiérarchisation de ces actions correctives améliore la qualité du service et réduit la demande d’incidents de site réel futurs. La qualité du service doit s’améliorer au fil du temps, sinon à mesure que vous augmentez, l’impact de chaque problème est également plus élevé.
Déplacement à gauche: les problèmes qui nécessitent l’engagement de l’équipe en direct sont coûteux. Il faut du temps pour que les problèmes leur parviennent, et l'équipe du site en direct est une ressource rare qui doit être disponible pour les problèmes critiques de service et les tâches de gestion prioritaires.
Dans la mesure du possible, la meilleure solution élimine complètement un problème, suivie rapidement de la détection automatisée et de l’atténuation automatisée. Lorsque cela n’est pas possible, le déplacement vers la gauche permet d’aider l’équipe de support de première ligne à détecter et corriger le problème ou à effectuer la tâche, voire mieux, à permettre au client d’auto-servir et d’effectuer la tâche elle-même. Le diagramme suivant montre comment les cas de support commencent par un client, accédez à une équipe de support de première ligne, puis à l’équipe d’ingénierie. Une flèche indique que nous décalons l’action de résolution vers la gauche pour réduire l’impact des incidents.

Gardez les choses standard : il peut être tentant d’atténuer un problème en effectuant des arrangements spéciaux pour un client. À grande échelle, tout ce qui est spécial devient un cas limite qui provoque l'échec de quelque chose d'autre. Visez à conserver tous les locataires à l’aide du code, des paramètres et de la configuration standard.
Innovation continue
Tout au long de cet article, nous avons parlé de la nécessité d’obtenir votre produit dans le cloud et de commencer le cycle vertueux de l’apprentissage continu et de l’amélioration continue. L’innovation continue est une attente pour la plupart des produits SaaS. Mais lorsqu’un produit SaaS est le successeur d’un produit local de longue date, il faut probablement une gestion significative des changements pour préparer les clients à l’innovation continue.
Voici trois domaines clés de notre transformation Dynamics 365 :
Maintenance avec quasi zéro temps d'arrêt : À mesure que le nombre de clients dans différentes entreprises et sites augmente, il devient impossible de trouver des fenêtres de maintenance universellement acceptables. Vous devez créer une maturité d’ingénierie afin que les activités de maintenance puissent se produire pendant que le système est en ligne. En particulier, le déploiement des mises à jour de service doit se produire avec un temps d’arrêt aussi proche de zéro que possible.
Éliminer les régressions : il faut la confiance des clients pour dépendre d’un service stratégique avec une stratégie d’innovation continue. Cette confiance se gagne goutte à goutte avec chaque jour de fonctionnement réussi et chaque mise à jour de service sans accroc. Malheureusement, il est perdu dans les compartiments, rapidement et en grandes quantités, avec n’importe quelle régression, peu importe la taille. Il est utile de faire tout ce que vous pouvez faire pour éliminer les régressions dans le processus d’ingénierie, en particulier en utilisant des processus de déploiement sécurisés.
Indicateurs de fonctionnalité : l’équipe Dynamics 365 a investi largement dans une infrastructure d’indicateurs de fonctionnalité . Un indicateur de fonctionnalité peut être activé ou désactivé pour l’ensemble du service, pour les sous-ensembles de locataires ou même pour un seul locataire. En utilisant des indicateurs de fonctionnalité, nous allons activer l’introduction de nouvelles fonctionnalités sans perturber le fonctionnement des processus métier critiques pris en charge par Dynamics 365.
Voici comment les indicateurs de fonctionnalité peuvent vous aider :
- Un correctif de sécurité ou de performances simple peut être introduit avec l’indicateur activé par défaut. Tout le monde devrait bénéficier immédiatement du changement.
- Quelque chose qui modifie l’expérience d’un utilisateur, un processus métier ou le comportement d’une API visible en externe est introduit avec l’indicateur désactivé par défaut.
- La modification d’un indicateur de fonctionnalité modifie efficacement le code qui s’exécute, de sorte que les modifications d’indicateur de fonctionnalité doivent également être gérées par le biais d’un déploiement sécurisé. Par exemple, supposons que vous introduisez un correctif pour un problème et que vous désactivez l’indicateur de fonctionnalité pour le correctif par défaut. Vous pouvez activer l’indicateur pour les clients qui ont signalé le bogue d’origine. Vous pouvez ensuite progresser lentement en activant l’indicateur sur les anneaux étendus des clients jusqu’à ce qu’il soit activé pour tout le monde.
- Si un correctif est introduit lorsque l’indicateur est activé par défaut et que le correctif a un problème, il peut logiquement être restauré instantanément en désactivant l’indicateur.
- Les indicateurs de fonctionnalité peuvent également être utilisés pour divulguer de manière sélective les fonctionnalités en préversion ou pour masquer de manière sélective les fonctionnalités des nouveaux clients dans le cadre d’un processus de dépréciation.
- Vous pouvez fournir une visibilité des nouveaux indicateurs de fonctionnalités et des paramètres d’indicateur de fonctionnalité spécifiques au locataire aux équipes de support de première ligne et de site en direct. Ces informations aident les équipes à régler ou à exclure rapidement une nouvelle modification de fonctionnalité lorsqu’elles examinent un problème. Si nécessaire, les équipes peuvent également ajuster les paramètres des indicateurs de fonctionnalité pour atténuer le problème.
- Enfin, vous devez gérer le cycle de vie des indicateurs de fonctionnalités pour empêcher que la base de code devienne ingérable. Établissez un processus de suppression des indicateurs de fonctionnalité du code une fois qu’ils sont entièrement déployés et prouvés.
Conclusion
La transition d’un produit local vers SaaS nécessite des modifications significatives dans chaque partie de la façon dont vous fournissez des logiciels aux clients, et dans toutes les parties de votre entreprise. Les changements culturels sont aussi importants que les changements techniques : passer d’une cadence de publication locale occasionnelle à une cadence de mise en production régulière est un changement majeur, et l’adoption d’une culture et des processus en direct prend des efforts. Vous devez vous assurer que votre équipe est bien préparée pour le parcours et que vous développez votre pool de talents au-delà des ingénieurs pour vous assurer que vous avez des personnes qui savent exploiter SaaS à grande échelle.
De nombreuses organisations ne survivent pas aux transitions de cette ampleur, surtout si un nouveau concurrent déjà natif du cloud apparaît. Pour vous configurer pour réussir, vous devez définir avec soin un MVP, l’obtenir en production le plus rapidement possible, puis itérer et améliorer rapidement. Le processus de transition est souvent le plus difficile, il est donc judicieux de faire la transition vers le cloud le plus rapidement possible.
Voici des considérations clés que nous espérons que vous retirez de nos expériences et certaines des décisions que vous devez prendre pour votre propre voyage.
- Décidez de votre propre chemin. Si vous disposez d’une application existante avec des fonctionnalités enrichies et une base de client locale établie, il peut être judicieux de passer à un modèle SaaS basé sur le cloud. Le parcours de chaque produit est différent et vous devez prendre en compte les décisions et les questions séparément, en fonction de vos propres besoins. Inspirez-vous d’autres voyages, mais forgez votre propre chemin.
- Déterminez une stratégie. Avoir un produit avec des clients établis signifie que vous devez décider comment créer vos priorités. Vous pouvez vous concentrer sur la création d’un produit qui fonctionne bien pour les nouveaux clients immédiatement. Vous pouvez vous concentrer sur la migration de votre base de clients existante vers votre nouveau service le plus rapidement possible. La raison pour laquelle vous vous déplacez et votre capacité à apporter des modifications significatives influence la direction que vous prenez.
- Déterminez si vous allez utiliser un cloud unique ou multicloud. Déterminez s’il est plus judicieux de créer sur un cloud unique ou de répartir vos efforts d’ingénierie sur plusieurs clouds. Si vous créez un composant de plateforme, une stratégie multicloud peut être logique. Si vous créez une application, une stratégie à cloud unique peut offrir des avantages sur l’utilisation d’une plateforme cohérente et intégrée.
- Planifiez spécifiquement le cloud. Une approche lift-and-shift pour migrer vers le cloud n’est pas suffisante. Vous devez planifier la façon de tirer parti de l’élasticité du cloud et de l’exploitation d’un service dans un environnement cloud. L’automatisation, la résilience, la mise à l’échelle, la sécurité, les performances et l’observabilité sont toutes des considérations importantes. Vous n’avez pas besoin de tout faire en amont, mais vous devez connaître la destination afin de pouvoir planifier une feuille de route.
- Planifiez spécifiquement pour le SaaS. Un modèle métier SaaS est différent par rapport à une approche de livraison de logiciels locale. Les clients attendent des comptes d’évaluation, des modèles de facturation compréhensibles, un service entièrement géré et une mise à l’échelle dynamique en fonction de leurs besoins.
- Atterrir, apprendre, et itérer. Planifiez la portée d'un MVP, identifiez les gains de base que vous pouvez atteindre, puis atteignez-les rapidement. Une fois que vous y êtes, engagez-vous à l’amélioration continue.
- Lorsque vous êtes dans le cloud, tirez parti de celui-ci. Le cloud fournit de nombreuses fonctionnalités que les solutions locales n’ont pas. Les fonctionnalités incluent une grande échelle, l’élasticité et la possibilité d’utiliser des composants de plateforme cloud pour créer et itérer rapidement sur vos idées. Réfléchissez à la façon dont vous pouvez utiliser des technologies telles que l’IA générative, les microservices et d’autres approches difficiles à utiliser en dehors d’un environnement cloud.
- Devenez le service informatique du client. Les attentes des clients évoluent lorsque vous fournissez un service de bout en bout. Planifiez la façon dont vous pouvez déplacer vers la gauche. Assurez-vous que vous disposez d’une fonctionnalité complète de supervision et d’auto-guérison.
- Découvrez l’utilisation des clients. Lorsque vous exécutez un service, vous collectez une grande quantité de données utiles sur la façon dont les clients utilisent votre produit. Adoptez une culture des données. Découvrez vos clients, ce qu’ils font et comment ils le font. Expérimentez et soyez suffisamment agile pour modifier votre approche lorsque les données indiquent que quelque chose n’est pas comme prévu.
- Fournissez une valeur continue via les mises à jour. Réfléchissez au moment et à la façon de déployer des mises à jour. Prévoyez de résoudre les problèmes rapidement ou de revenir aux versions précédentes. Déterminez comment gérer les modifications disruptives. Évitez les modifications ponctuelles pour des clients spécifiques, car chaque point de différence est l’occasion d’un problème.
La plus grande leçon que nous avons apprise est que le parcours vers SaaS ne se termine jamais. Une feuille de route de produit est un document vivant qui évolue constamment. Vous avez toujours de nombreux éléments dans le backlog pour améliorer votre produit, à la fois pour ajouter de nouvelles fonctionnalités et pour améliorer la façon dont vous utilisez et fournissez le produit. La livraison de SaaS nécessite une amélioration continue de vos processus, un investissement en qualité et une vigilance pour vous assurer que vous fournissez un service fiable, sécurisé, performant et fiable pour vos clients. Les avancées technologiques, telles que l’IA générative, offrent une formidable opportunité pour vous de fournir des fonctionnalités qui étaient inimaginables avant.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
- Mike Ehrenberg | Directeur technique, Microsoft Dynamics
- John Downs | Ingénieur logiciel principal
- Arsen Vladimirsky | Ingénieur client principal