Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Front Door
Azure
Le modèle d’empreinte de déploiement implique l’approvisionnement, la gestion et la surveillance d’un groupe hétérogène de ressources pour héberger et faire fonctionner plusieurs charges de travail ou locataires. Chaque copie individuelle est appelée tampon, ou parfois une unité de service, une unité d’échelle ou une cellule. Dans un environnement multi-locataire, chaque empreinte ou unité d’échelle peut servir un nombre prédéfini de clients. Plusieurs empreintes peuvent être déployées pour mettre à l’échelle la solution presque de manière linéaire et servir un nombre croissant de locataires. Cette approche contribue à améliorer la scalabilité de votre solution, vous permet de déployer des instances dans plusieurs régions et de séparer vos données client.
Note
Pour plus d’informations sur la conception de solutions multi-locataire pour Azure, consultez Architecturer des solutions multi-locataire sur Azure..
Contexte et problème
Lors de l’hébergement d’une application dans le cloud, il est important de prendre en compte les performances et la fiabilité de votre application. Si vous hébergez une seule instance de votre solution, vous pouvez être soumis aux limitations suivantes :
- Limites de mise à l’échelle. Le déploiement d’une seule instance de votre application peut entraîner des limites naturelles de mise à l’échelle. Par exemple, vous pouvez utiliser des services dotés de limites en termes de nombre de connexions entrantes, de noms d’hôtes, de sockets TCP ou d’autres ressources.
- Mise à l’échelle non linéaire ou coût. Certains composants de votre solution peuvent ne pas être mis à l’échelle de manière linéaire selon le nombre de requêtes ou la quantité de données. Une baisse soudaine des performances ou une augmentation du coût une fois un seuil atteint peut en effet se manifester. Par exemple, vous pouvez utiliser une base de données et vous rendre compte que le coût marginal lié à l’ajout d’une capacité supplémentaire (scale-up) devient prohibitif et qu’un scale-out constitue une stratégie plus économique.
- Séparation des clients. Vous pourriez avoir besoin de garder les données de certains clients isolées de celles d’autres clients. De même, il se peut que certains de vos clients nécessitent plus de ressources système que d’autres et que vous envisagiez de les regrouper sur différents ensembles d’infrastructure.
- Gestion des instances mono-locataire et multi-locataire. Vous pouvez avoir pour clients de grandes entreprises qui ont besoin de leurs propres instances indépendantes de votre solution. Vous pouvez également avoir un groupe de très petites entreprises clientes qui peuvent partager un déploiement multi-locataire.
- Configuration requise en matière de déploiement complexe. Vous devrez peut-être déployer des mises à jour de votre service de manière contrôlée et de les déployer dans différents sous-ensembles de votre base de clients à des moments différents.
- Fréquence de mise à jour. Certains de vos clients peuvent tolérer des mises à jour fréquentes de votre système, tandis que d’autres, sensibles au risque, peuvent souhaiter des mises à jour moins fréquentes du système qui prend en charge leurs requêtes. Il peut s’avérer judicieux de faire en sorte que ces clients soient déployés dans des environnements isolés.
- Restrictions géographiques ou géopolitiques. Pour concevoir l’architecture à des fins de faible latence ou pour respecter les exigences en matière de souveraineté des données, vous pouvez déployer certains de vos clients dans des régions spécifiques.
Ces limitations s’appliquent souvent aux fournisseurs de logiciel indépendants qui créent des software as a service (SaaS) fréquemment conçus pour être multi-locataire. Toutefois, les mêmes limitations peuvent également s’appliquer à d’autres scénarios.
Solution
Pour éviter ces problèmes, envisagez de regrouper des ressources dans des unités d’échelle et de provisionner plusieurs copies de vos empreintes. Chaque unité d’échelle hébergera et servira un sous-ensemble de vos locataires. Les empreintes fonctionnent indépendamment les unes des autres et peuvent être déployées et mises à jour indépendamment. Une même région géographique peut contenir une empreinte, voire plusieurs, pour permettre un scale-out horizontal dans la région. Les empreintes contiennent un sous-ensemble de vos clients.
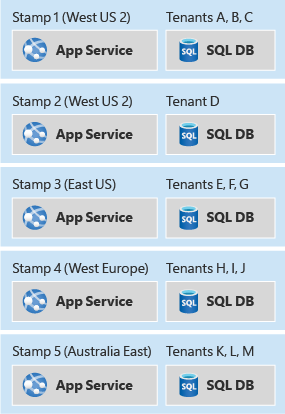
Les empreintes de déploiement peuvent s’appliquer si votre solution utilise des composants IaaS (infrastructure as a service) ou PaaS (platform as a service), voire une combinaison des deux. En général, les charges de travail IaaS requièrent plus d’intervention en termes de mise à l’échelle et, dès lors, le modèle peut s’avérer utile à des fins de scale-out.
Les tampons peuvent être utilisés pour implémenter des anneaux de déploiement. Si différents clients souhaitent recevoir des mises à jour de service à différentes fréquences, ils peuvent être regroupés sur différentes empreintes, et chaque empreinte peut contenir des mises à jour déployées à des cadences différentes.
Étant donné que les tampons s’exécutent indépendamment les uns des autres, les données sont implicitement partitionnées. En outre, une seule empreinte peut utiliser un partitionnement supplémentaire pour permettre, en interne, la scalabilité et l’élasticité au sein de l’empreinte.
Le modèle d’empreinte de déploiement est utilisé en interne par de nombreux services Azure, notamment App Service, Azure Stack et Stockage Azure.
Les tampons de déploiement sont liés, mais distincts des géodes. Dans une architecture d’empreinte de déploiement, plusieurs instances indépendantes de votre système sont déployées et contiennent un sous-ensemble de vos clients et utilisateurs. Dans geodes, toutes les instances peuvent traiter les requêtes émanant des différents utilisateurs, mais cette architecture est souvent plus complexe à concevoir et à générer. Vous pouvez également envisager de combiner les deux modèles dans une solution. L’approche du routage du trafic décrite plus loin dans cet article illustre un scénario hybride.
Deployment
En raison de la complexité inhérente au déploiement de copies identiques des mêmes composants, le suivi des bonnes pratiques DevOps est essentiel pour la bonne implémentation de ce modèle. Envisagez de décrire votre infrastructure en tant que code, par exemple à l’aide de Bicep, de modèles Azure Resource Manager JSON (modèles ARM), Terraform et de scripts. Une telle approche vous permet de veiller à ce que le déploiement de chaque empreinte soit prévisible et puisse être reproduit. Elle permet également de réduire les éventuelles erreurs humaines, telles que les incompatibilités accidentelles de la configuration entre les empreintes.
Vous pouvez déployer automatiquement des mises à jour sur toutes les étapes en parallèle, auquel cas vous pouvez envisager des technologies telles que Bicep ou des modèles de Resource Manager pour coordonner le déploiement de votre infrastructure et de vos applications. Vous pouvez aussi choisir de déployer progressivement les mises à jour sur certaines empreintes, puis sur d’autres. Envisagez d’utiliser un outil de gestion des mises en production comme Azure Pipelines ou GitHub Actions pour orchestrer les déploiements sur chaque instance. Pour plus d’informations, consultez les pages suivantes :
Examinez attentivement la topologie des abonnements et des groupes de ressources Azure correspondant à vos déploiements :
- En règle générale, un abonnement contient toutes les ressources d’une seule solution. En conséquence, envisagez d’utiliser un abonnement unique pour toutes les empreintes. Cela étant, certains services Azure imposent des quotas d’abonnement et, si vous utilisez ce modèle pour effectuer un important scale-out, vous devrez peut-être envisager de déployer des empreintes dans différents abonnements.
- Les groupes de ressources sont généralement utilisés pour déployer des composants présentant le même cycle de vie. Si vous prévoyez de déployer des mises à jour sur toutes vos empreintes en même temps, envisagez d’utiliser un seul groupe de ressources pour contenir tous les composants de toutes vos empreintes, et recourez aux conventions d’affectation de noms de ressources et balises pour identifier les composants appartenant à chaque empreinte. Sinon, si vous prévoyez de déployer des mises à jour sur chaque empreinte indépendamment, envisagez de déployer chaque empreinte dans son propre groupe de ressources.
Planification de la capacité
Utilisez les tests de charge et de performances pour déterminer la charge approximative pouvant être prise en charge par une empreinte. Les métriques de charge peuvent être basées sur le nombre de clients/locataires qu’une seule empreinte peut prendre en charge ou sur les mesures des services que les composants de l’empreinte émettent. Assurez-vous de disposer d’une instrumentation suffisante pour mesurer quand une empreinte donnée approche sa capacité, et déployer rapidement de nouvelles empreintes pour répondre à la demande.
Routage du trafic
Le modèle d’empreinte de déploiement fonctionne parfaitement si chaque empreinte est traitée indépendamment. Par exemple, si Contoso déploie la même application API sur plusieurs empreintes, elle peut envisager d’utiliser DNS pour acheminer le trafic vers l’empreinte qui convient :
-
unit1.aus.myapi.contoso.comachemine le trafic vers l’empreinteunit1dans une région australienne. -
unit2.aus.myapi.contoso.comachemine le trafic vers l’empreinteunit2dans une région australienne. -
unit1.eu.myapi.contoso.comachemine le trafic vers l’empreinteunit1dans une région européenne.
Les clients doivent ensuite se connecter à l’empreinte qui convient.
Si un seul point d’entrée est requis pour tout le trafic, un service de routage du trafic peut être utilisé pour résoudre l’empreinte d’une requête, d’un client ou d’un locataire donné. Le service de routage du trafic dirige le client vers l’URL correspondant au groupe de serveurs (par exemple en utilisant un code d’état de réponse HTTP 302). Il peut aussi faire office de proxy inverse et transférer le trafic vers le groupe de serveurs approprié, sans l’indiquer au client.
Concevoir un service de routage du trafic peut s’avérer complexe, notamment lorsqu’une solution s’exécute dans plusieurs régions. Envisagez de déployer le service de routage du trafic dans plusieurs régions (voire dans chaque région où les empreintes sont déployées), puis de vous assurer que le magasin de données (mappage des locataires aux empreintes) est synchronisé. Le composant de routage du trafic peut lui-même être une instance du modèle geode.
Par exemple, le service Gestion des API Azure peut être déployé pour jouer un rôle dans le service de routage du trafic. Il peut déterminer le tampon approprié pour une requête en recherchant des données dans une collection Azure Cosmos DB stockant le mappage entre les locataires et les tampons. Gestion des API peut ensuite définir dynamiquement l’URL du serveur principal pour le service d’API de l’empreinte correspondante.
Pour activer la géo-localisation des requêtes et la géo-redondance du service de routage du trafic, le service Gestion des API peut être déployé dans plusieurs régions, ou Azure Front Door peut être utilisé pour diriger le trafic vers l’instance la plus proche. Front Door peut être configuré avec un pool principal, ce qui permet aux requêtes d’être dirigées vers l’instance de gestion des API disponible la plus proche. Si votre application n’est pas exposée via HTTP/S, vous pouvez utiliser un équilibreur de charge Azure interrégion pour distribuer des appels entrants vers des équilibreurs de charge Azure régionaux. Les fonctionnalités de distribution mondiale d’Azure Cosmos DB peuvent être utilisées pour veiller à ce que les informations de mappage soient à jour dans chaque région.
Si un service de routage du trafic est inclus dans votre solution, déterminez s’il agit en tant que passerelle et peut donc effectuer un déchargement de passerelle pour les autres services, tels que la validation de jeton, la limitation et l’autorisation.
Exemple d’architecture de routage du trafic
Considérez l’exemple suivant d’architecture de routage du trafic, qui utilise Azure Front Door, Gestion des API Azure et Azure Cosmos DB pour le routage du trafic global, puis une série de groupes de serveurs spécifiques à une région :
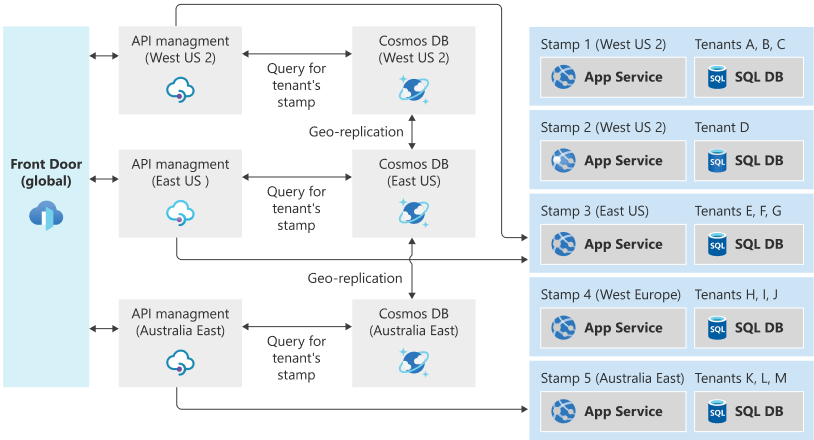
Supposons qu’un utilisateur se trouve normalement à New York. Ses données sont stockées dans le groupe de serveurs 3, dans la région USA Est.
Si l’utilisateur va en Californie, puis accède au système, sa connexion est susceptible d’être routée via la région USA Ouest 2, car c’est la région la plus proche de l’endroit où se trouve géographiquement quand il fait la demande. Cependant, la demande doit être traitée au final par le groupe de serveurs 3, car c’est là que ses données sont stockées. Le système de routage du trafic garantit que la demande est routée vers le groupe de serveurs correct.
Problèmes et considérations
Prenez en compte les points suivants quand vous choisissez comment implémenter ce modèle :
- Processus de déploiement. Lors du déploiement de plusieurs empreintes, il est vivement conseillé de disposer de processus de déploiement automatisés et entièrement reproductibles. Envisagez d’utiliser des modèles Bicep, JSON ARM ou des modules Terraform pour définir de manière déclarative vos tampons et pour maintenir la cohérence des définitions.
- Opérations d’horodatage croisé. Lorsque votre solution est déployée indépendamment sur plusieurs empreintes, il peut s’avérer plus difficile de répondre à des questions telles que « Combien de clients avons-nous sur toutes nos empreintes ? » Il peut être nécessaire d’exécuter des requêtes sur chaque empreinte et d’agréger les résultats. Vous pouvez également envisager de faire en sorte que toutes les empreintes publient des données dans un entrepôt centralisé afin de créer des rapports consolidés.
- Déterminer des stratégies de scale-out. Les empreintes ont une capacité limitée, qui peut être définie à l’aide d’une métrique de proxy, telle que le nombre de locataires susceptibles d’être déployés sur l’empreinte. Il est important de surveiller la capacité disponible et la capacité utilisée pour chaque empreinte, et de déployer de manière proactive des empreintes supplémentaires afin d’y diriger de nouveaux clients.
- Nombre minimal d’empreintes. Lorsque vous utilisez le modèle Empreinte de déploiement, il est recommandé de déployer au moins deux empreintes de votre solution. Si vous déployez une seule empreinte, il est facile d’effectuer des hypothèses codées en dur accidentellement dans votre code ou configuration qui ne s’appliquent pas lorsque vous effectuez un scale-out.
- Cost. Le modèle d’empreinte de déploiement implique le déploiement de plusieurs copies de votre composant d’infrastructure, ce qui augmente généralement le coût d’utilisation de votre solution.
- Déplacement entre empreintes. Chaque empreinte est déployée et utilisée indépendamment. En conséquence, déplacer des clients entre ces empreintes peut s’avérer difficile. Votre application a besoin d’une logique personnalisée pour transmettre les informations relatives à un client donné à une autre empreinte, puis supprimer les informations du locataire de l’empreinte d’origine. Ce processus peut nécessiter un fond de panier à des fins de communication entre les empreintes, ce qui augmente la complexité de la solution globale.
- Routage du trafic. Comme décrit plutôt dans cet article, le routage du trafic vers l’empreinte qui convient pour une requête donnée peut nécessiter un composant supplémentaire afin de résoudre les clients vers les empreintes. Ce composant, à son tour, peut nécessiter une haute disponibilité.
- Composants partagés. Certains composants peuvent être partagés entre les empreintes. Par exemple, si vous disposez d’une application monopage partagée pour tous les locataires, envisagez de la déployer dans une seule région et d’utiliser Azure CDN pour la répliquer globalement.
Quand utiliser ce modèle
Ce modèle est utile dans les situations suivantes :
- Limites naturelles en termes de scalabilité. Par exemple, si certains composants ne peuvent pas ou ne doivent pas être mis à l’échelle au-delà d’un certain nombre de clients ou de requêtes, envisagez d’effectuer un scale-out à l’aide d’empreintes.
- Condition requise pour séparer certains locataires des autres. Si des clients ne peuvent être déployés dans une empreinte multi-locataire avec d’autres clients pour des raisons de sécurité, ils peuvent être déployés sur leur propre empreinte isolée.
- Besoin de disposer plusieurs locataires sur différentes versions de votre solution en même temps.
- Applications multirégions dans lesquelles les données et le trafic de chaque locataire doivent être dirigés vers une région spécifique.
- Souhait d’atteindre une certaine résilience en cas de pannes. Les empreintes étant indépendants les unes des autres, si une panne affecte une seule empreinte, les locataires déployés sur d’autres empreintes ne doivent pas être affectés. Cette isolation permet de contenir le « rayon d’impact » d’un incident ou d’une panne.
Ce modèle n’est pas adapté aux points suivants :
- Solutions simples ne nécessitant pas de mise à l’échelle importante.
- Systèmes pouvant facilement faire l’objet d’un scale-out ou scale-in dans une même instance, par exemple en augmentant la taille de la couche d’application ou la capacité réservée pour les bases de données et le niveau de stockage.
- Solutions dans lesquelles les données doivent être répliquées sur toutes les instances déployées. Considérez le modèle de géode pour ce scénario.
- Solutions dans lesquelles seuls certains composants doivent être mis à l’échelle. Par exemple, déterminez si votre solution peut être mise à l’échelle en partitionnement le magasin de données plutôt qu’en déployant une nouvelle copie de tous les composants de la solution.
- Solutions constituées exclusivement de contenu statique, tel qu’une application JavaScript frontale. Envisagez de stocker ce contenu dans un compte de stockage et à l’aide d’Azure CDN.
Conception de la charge de travail
Un architecte doit évaluer la façon dont le modèle d’empreintes de déploiement peut être utilisé dans la conception de leurs charges de travail pour se conformer aux objectifs et principes abordés dans les piliers d’Azure Well-Architected Framework. Par exemple:
| Pillar | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| L’excellence opérationnelle permet de fournir une qualité de charge de travail grâce à des processus standardisés et à la cohésion de l’équipe. | Ce modèle prend en charge les objectifs d’infrastructure immuables, les modèles de déploiement avancés et peut faciliter les pratiques de déploiement sécurisé. - OE 05 Infrastructure en tant que code - OE :11 Pratiques de déploiement sécurisé |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Ce schéma s’aligne souvent sur les unités d’échelle définies dans votre charge de travail : lorsqu’une capacité supplémentaire est nécessaire au-delà de ce qu’une seule unité d’échelle fournit, une empreinte de déploiement supplémentaire est déployée pour la mise à l’échelle. - PE :05 Mise à l’échelle et partitionnement |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Technologies de prise en charge
- Infrastructure en tant que code. Par exemple, Bicep, modèles Resource Manager, Azure CLI, Terraform, PowerShell, Bash.
- Azure Front Door, qui peut acheminer le trafic vers une empreinte spécifique ou un service de routage du trafic.
Contributors
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- John Downs | Ingénieur logiciel principal, modèles Azure & Pratiques
Autres contributeurs :
- Daniel Larsen | Ingénieur client principal, FastTrack pour Azure
- Angel Lopez | Ingénieur logiciel senior, modèles et pratiques Azure
- Paul Salvatori | Ingénieur client principal, FastTrack for Azure
- Arsen Vladimirskiy | Ingénieur client principal, FastTrack for Azure
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Ressources associées
- Le partitionnement peut également être utilisé pour facilement effectuer un scale-out de votre niveau de données. Les stamps partitionnent implicitement leurs données, mais le partitionnement ne nécessite pas d’empreinte de déploiement. Pour plus d’informations, consultez le modèle de partitionnement.
- Si un service de routage du trafic est déployé, les modèles de routage de passerelle et de déchargement de passerelle peuvent être utilisés ensemble pour tirer le meilleur profit de ce composant.