L'accélération des cycles de mise en production constitue l'un des principaux avantages des architectures de microservices. Mais sans un processus efficace d'intégration et de livraison continues, vous n'obtiendrez pas l'agilité attendue des microservices. Cet article décrit ces obstacles et recommande certaines stratégies pour les surmonter.
Que sont l'intégration et la livraison continues (CI/CD) ?
Lorsque l'on parle de CI/CD (intégration continue/livraison continue), on parle en réalité de plusieurs processus connexes : intégration continue, livraison continue et déploiement continu.
Intégration continue. Les modifications du code sont fréquemment fusionnées dans la branche principale. Les processus de génération et de test automatisés garantissent que le code de la branche principale est toujours de qualité production.
Livraison continue. Les modifications de code qui franchissent le processus CI sont automatiquement publiées dans un environnement de type production. Si le déploiement au sein de l’environnement de production réelle peut nécessiter une approbation manuelle, il est automatisé. L’objectif est de toujours disposer d’un code prêt à être déployé en production.
Déploiement continu. Les modifications de code qui franchissent les deux étapes précédentes sont automatiquement déployées en production.
Voici certains objectifs d’un processus CI/CD robuste pour une architecture de microservices :
Chaque équipe peut générer et déployer ses propres services de manière indépendante, sans affecter ou interrompre d’autres équipes.
Avant d’être déployée en production, une nouvelle version d’un service est déployée sur les environnements de développement/test/assurance qualité à des fins de validation. Des critères de qualité sont appliqués à chaque étape.
Une nouvelle version d'un service peut être déployée aux côtés de la version précédente.
Des stratégies de contrôle d’accès suffisantes sont en place.
Pour les charges de travail conteneurisées, vous pouvez approuver les images conteneur déployées en production.
En quoi un pipeline CI/CD robuste est-il important ?
Dans une application monolithique classique, un pipeline unique de conception génère le fichier exécutable de l'application. L’ensemble des tâches de développement alimentent ce pipeline. Si un bogue de priorité élevée est identifié, un correctif doit être intégré, testé puis publié, ce qui peut retarder la sortie des nouvelles fonctionnalités. Vous pouvez atténuer ces problèmes en vous dotant de modules correctement rationalisés et en valorisant des branches de fonctionnalités destinées à réduire l'incidence des modifications de code. Toutefois, à mesure que l’application devient plus complexe, en parallèle de l’ajout des fonctionnalités, le processus de publication d’un monolithe a tendance à se fragiliser et présente des risques de rupture.
Si une approche de microservices est suivie, vous ne déplorez jamais une longue chaîne de publication au sein de laquelle les équipes interviennent tour à tour. L’équipe qui développe le service « A » peut publier une mise à jour à tout moment, sans attendre que les modifications de l’équipe du service « B » soient fusionnées, testées et déployées.
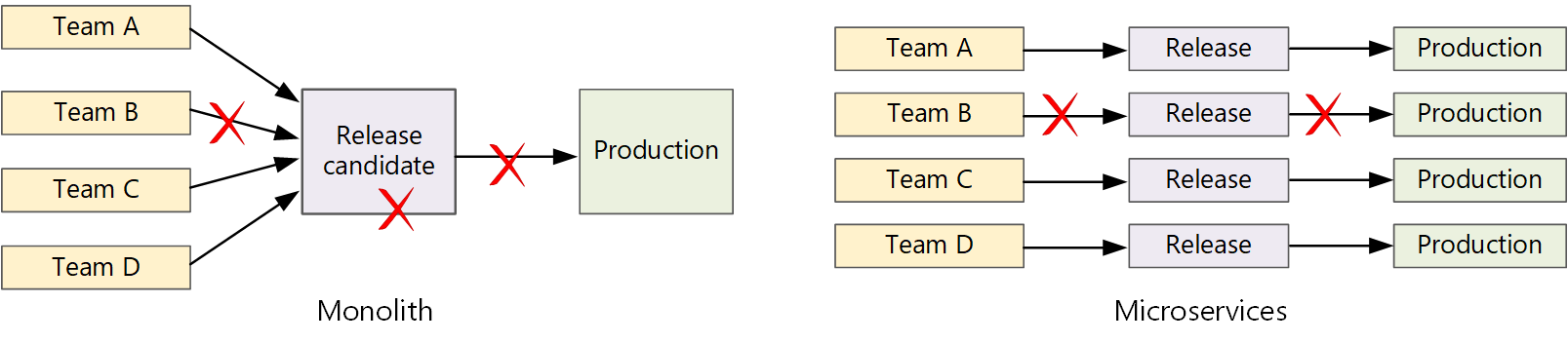
Pour parvenir à une mise en production rapide, votre pipeline de mise en production doit être automatisé et il doit être très fiable afin de réduire les risques. Si vous procédez à des mises en production une ou plusieurs fois par jour, les régressions ou les interruptions de service doivent être rares. En même temps, en cas de déploiement d’une mauvaise mise à jour, vous devez disposer d’un moyen fiable pour revenir vers une version antérieure du service.
Défis
De nombreuses bases de code indépendantes et réduites. Chaque équipe est responsable de la création de son propre service, associé à un pipeline de génération spécifique. Dans certaines organisations, les équipes peuvent utiliser des référentiels de code séparés. Ainsi, parfois, l'expertise en matière de génération de système est partagée entre les équipes, sans que quiconque au sein de l'organisation ne sache comment déployer l'application entière. Par exemple, que se passe-t-il en cas de récupération d’urgence, si vous devez déployer rapidement vers un nouveau cluster ?
Atténuation : Prévoyez un pipeline unifié et automatisé pour la création et le déploiement de services afin que ces connaissances ne restent pas « cachées » au sein de chaque équipe.
Langues et infrastructures multiples. Si chaque équipe utilise sa propre combinaison de technologies, il peut s’avérer difficile de créer un processus de génération unique fonctionnant dans tous les services de l’organisation. Le processus de génération doit être suffisamment souple pour que chaque équipe puisse opter pour la langue ou l’infrastructure de son choix.
Atténuation : Conteneurisez le processus de génération pour chaque service. De cette façon, le système de génération doit simplement être capable d'exécuter les conteneurs.
Intégration et test de charge. Chaque équipe publiant les mises à jour à son propre rythme, la mise en œuvre d’une approche de test robuste de bout en bout peut présenter des difficultés, plus particulièrement quand des interdépendances entre services sont identifiées. En outre, l'exécution d'un cluster de production intégral peut s'avérer onéreuse. Il est donc peu probable que chacune des équipes exécute son propre cluster à l'échelle de la production simplement pour la phase de test.
Gestion des mises en production. Chaque équipe doit être en mesure de déployer une mise à jour en production. Cela ne signifie pas que tous les membres doivent être autorisés à le faire. Cependant, une organisation disposant d’un rôle centralisé de gestionnaire des versions peut constater un ralentissement de ses déploiements.
Atténuation : Plus le processus d’intégration et de livraison continue est automatisé et fiable, moins la nécessité d’une autorité centrale se fait sentir. Ceci dit, vous pouvez avoir plusieurs stratégies, adaptées à la fois à la publication des modifications majeures de fonctionnalités et des correctifs mineurs. La décentralisation n'est pas synonyme de gouvernance zéro.
Mises à jour de service. Lorsque vous mettez à jour un service vers une nouvelle version, il ne doit pas perturber les autres services qui en dépendent.
Atténuation : Utilisez des techniques de déploiement telles que Blue-Green et Canary pour les changements non cassants. Pour les changements d'API cassants, déployez la nouvelle version aux côtés de la version précédente. Les services qui utilisent l'ancienne API pourront ainsi être mis à jour et testés pour la nouvelle API. Consultez Mise à jour des services ci-dessous.
Référentiel unique ou référentiels multiples
Avant de créer un workflow CI/CD, vous devez savoir comment la base de code est structurée et gérée.
- Les équipes travaillent-elles dans des référentiels distincts ou dans un même référentiel (référentiel unique) ?
- Quelle est votre stratégie de création de branche ?
- Qui peut envoyer (push) du code en production ? Existe-t-il un rôle de gestionnaire de mise en production ?
L’approche « dépôt unique » est de plus en plus utilisée, mais les deux approches ont des avantages et des inconvénients.
| Dépôt unique | Dépôts multiples | |
|---|---|---|
| Avantages | Partage du code Code et outils plus faciles à standardiser Code plus facile à refactoriser Découvrabilité - une même vue du code |
Propriété clairement établie par équipe Potentiellement moins de conflits de fusion Aide à appliquer le découplage des microservices |
| Défis | Les modifications apportées au code partagé peuvent affecter plusieurs microservices Plus grand risque de conflits de fusion Les outils doivent être adaptés pour une grande base de code Contrôle d’accès Processus de déploiement plus complexe |
Partage du code plus difficile Standards de codage plus difficiles à appliquer Gestion des dépendances Base de code diffuse, découvrabilité faible Manque d’infrastructure partagée |
Mise à jour des services
Il existe différentes stratégies de mise à jour d’un service déjà en production. Nous présentons ici trois options courantes : mise à jour propagée, déploiement bleu-vert et contrôle de la validité de la mise en production.
Mises à jour propagées
Dans une mise à jour propagée, vous déployez de nouvelles instances d’un service ; ces nouvelles instances reçoivent immédiatement les requêtes. À mesure que les nouvelles instances arrivent, les anciennes instances sont supprimées.
Exemple. Dans Kubernetes, les mises à jour propagées correspondent au comportement par défaut lorsque vous mettez à jour les spécifications des pods pour un déploiement. Le contrôleur de déploiement crée un nouveau jeu de réplicas pour les pods mis à jour. Ensuite, il promeut le nouveau jeu en rétrogradant l’ancien, ceci pour garantir le maintien d’un nombre souhaité de réplicas. Les anciens pods ne sont pas supprimés avant que les nouveaux ne soient prêts. Kubernetes conserve un historique de la mise à jour, ce qui vous permet d'annuler une mise à jour si besoin.
Exemple. Azure Service Fabric utilise la stratégie de mise à jour propagée par défaut. Cette stratégie est idéale pour déployer une version d'un service comportant de nouvelles fonctionnalités sans modifier les API existantes. Service Fabric lance le déploiement d'une mise à niveau en mettant à jour le type d'application vers un sous-ensemble des nœuds ou un domaine de mise à jour. Il procède ensuite à une restauration par progression vers le domaine de mise à jour suivant jusqu'à ce que tous les domaines soient mis à niveau. Si un domaine ne se met pas à jour, le type d'application revient à la version précédente sur tous les domaines. Sachez qu'un type d'application comportant plusieurs services (si tous les services sont mis à jour dans le cadre du déploiement d'une mise à niveau) est susceptible d'échouer. Si un service ne se met pas à jour, l'ensemble de l'application revient à la version précédente et les autres services ne sont pas mis à jour.
L’une des difficultés liées aux mises à jour propagées est la confusion régnant durant le processus de mise à jour. À ce stade, une combinaison de versions anciennes et nouvelles exécute et reçoit le trafic. Pendant cette période, une requête peut être dirigée vers l’une ou l’autre des versions.
Pour les changements d'API cassants, une bonne pratique consiste à prendre en charge les deux versions côte à côte jusqu'à ce que tous les clients de la version précédente soient mis à jour. Consultez Gestion des versions d'API.
Déploiement bleu-vert
Dans un déploiement bleu-vert, il est possible de déployer la nouvelle version en parallèle de la version précédente. Une fois la nouvelle version validée, vous basculez simultanément l’ensemble du trafic de l’ancienne version vers la nouvelle. Après le basculement, vous vérifiez l’absence de problèmes dans l’application. Si une erreur survient, vous pouvez revenir à l’ancienne version. En supposant qu’il n’existe aucun problème, vous pouvez supprimer l’ancienne version.
Avec une application monolithique ou multiniveau plus traditionnelle, un déploiement bleu-vert est généralement synonyme d’approvisionnement de deux environnements identiques. Vous déployez alors la nouvelle version dans un environnement intermédiaire, avant de rediriger le trafic client vers l’environnement intermédiaire, par exemple, en échangeant les adresses IP virtuelles. Dans une architecture de microservices, les mises à jour se produisent au niveau du microservice. Généralement, vous devez donc déployer la mise à jour dans le même environnement et utiliser un mécanisme de détection de service pour l'échange.
Exemple. Dans Kubernetes, il n’est pas nécessaire d’approvisionner un cluster distinct pour procéder à des déploiements bleu-vert. Ici, vous pouvez valoriser des sélecteurs. Créez une nouvelle ressource de déploiement avec une nouvelle spécification de pods et un jeu différent d’étiquettes. Créez ce déploiement, sans supprimer le déploiement précédent ni modifier le service pointant vers lui. Une fois que les nouveaux pods sont exécutés, vous pouvez mettre à jour le sélecteur du service en fonction du nouveau déploiement.
L'un des inconvénients du déploiement Blue-green est que pendant la mise à jour, vous exécutez deux fois plus de pods pour le service (l'actuel et le suivant). Si les pods nécessitent un volume important d’UC ou de ressources de mémoire, il vous faudra éventuellement effectuer temporairement un scale-out du cluster pour prendre en charge efficacement la consommation de ressources.
Contrôle la validité de la mise en production
Durant un contrôle de la validité de la mise en production, vous déployez une version mise à jour à un nombre réduit de clients. Ensuite, vous analysez le comportement du nouveau service avant de procéder à un déploiement plus large vers l’ensemble des clients. Ainsi, vous contrôlez la mise en œuvre progressive du processus, observez les données réelles et identifiez les problèmes avant que l’ensemble des clients ne soient affectés.
La gestion de cette version est plus complexe que celle des versions bleu-vert et propagée, dans la mesure où vous devez diriger dynamiquement les requêtes vers différentes versions du service.
Exemple. Dans Kubernetes, vous pouvez configurer un service pour une prise en charge de deux jeux de réplicas (un pour chaque version), avant de modifier manuellement au besoin la quantité de réplicas. Toutefois, cette approche présente une granularité plutôt grossière, en raison de la manière dont la charge de Kubernetes s’équilibre entre les pods. Par exemple, si vous disposez d'un total de 10 réplicas, vous ne pouvez modifier le trafic que par incréments de 10 %. Si vous avez recours à une maille de service, vous pouvez solliciter les règles d’acheminement dédiées pour implémenter une stratégie de publication plus sophistiquée.
Étapes suivantes
- Parcours d’apprentissage : Définir et implémenter l’intégration continue
- Formation : Introduction à la livraison continue
- Architecture de microservices
- Pourquoi utiliser une approche de microservices pour la conception d’applications ?