Cet article décrit les meilleures pratiques pour surveiller le bon fonctionnement d’une application de microservices qui s’exécute sur Azure Kubernetes service (AKS). Les sujets spécifiques incluent la collecte de données de télémétrie, la surveillance de l’état d’un cluster, les métriques, la journalisation, la journalisation structurée et le suivi distribué. Ce dernier est illustré dans ce diagramme :

Téléchargez un fichier Visio de cette architecture.
Dans toute application complexe, il arrive toujours un moment où quelque chose pose problème. Dans une application de microservices, vous devez suivre le déroulement des opérations dans plusieurs douzaines, voire plusieurs centaines de services. Pour mieux comprendre ce qui se passe, vous devez collecter des données de télémétrie à partir de l’application. Les données de télémétrie peuvent être divisées en plusieurs catégories : journaux, traces et métriques.
Les journaux d’activité sont des enregistrements textuels des événements qui surviennent pendant l’exécution d’une application. Ils comprennent des éléments tels que les journaux d’activité d’application (déclarations de trace) et les journaux d’activité de serveur web. Les journaux d’activité se révèlent particulièrement utiles pour la forensique et l’analyse de la cause racine.
Les traces, aussi appelées opérations, relient les étapes d’une demande unique à travers plusieurs appels au sein de microservices et entre eux. Elles peuvent offrir une observabilité structurée des interactions entre les composants système. Les traces peuvent commencer tôt dans le processus de demande, par exemple dans l’interface utilisateur d’une application, et peuvent se propager via des services de réseau à travers un réseau de microservices qui traitent la demande.
- Les étendues sont des unités de travail au sein d’une trace. Chaque étendue est connectée à une seule trace et peut être imbriquée à d’autres étendues. Elles correspondent souvent à des demandes individuelles dans une opération interservice, mais elles peuvent aussi définir le travail dans les composants individuels d’un service. Les étendues permettent également de suivre les appels sortants d’un service à l’autre. (Parfois, les étendues sont appelées enregistrements de dépendance.)
Les métriques sont des valeurs numériques qui peuvent être analysées. Vous pouvez les utiliser pour observer un système en temps réel (ou quasiment en temps réel) ou pour analyser les tendances des performances au fil du temps. Pour comprendre un système de manière globale, vous devez collecter les métriques à différents niveaux de l’architecture, de l’infrastructure physique à l’application, notamment :
Les métriques au niveau du nœud, comprenant l’utilisation de l’UC, de la mémoire, du réseau, du disque et du système de fichiers. Les métriques du système vous aident à comprendre l’allocation des ressources pour chacun des nœuds du cluster et à corriger les valeurs hors norme.
Les métriques des conteneurs. Pour les applications conteneurisées, vous devez collecter les métriques au niveau du conteneur, et non uniquement au niveau de la machine virtuelle.
Les métriques d’une application. Ces métriques permettent de comprendre le comportement d’un service. Il s’agit par exemple du nombre de requêtes HTTP entrantes en file d’attente, de la latence des requêtes et de la longueur de la file d’attente des messages. Les applications peuvent également utiliser des métriques personnalisées spécifiques au domaine, comme le nombre de transactions commerciales traitées par minute.
Métriques des services dépendants. Les services font parfois appel à des services externes ou à des points de terminaison, comme les services PaaS ou SaaS gérés. Il se peut que des services tiers ne fournissent pas de données métriques. Si ce n’est pas le cas, vous devrez vous appuyer sur vos propres métriques d’application pour suivre les statistiques relatives à la latence et au taux d’erreur.
Utilisez Azure Monitor pour surveiller l’intégrité de vos clusters. La capture d’écran suivante montre un cluster qui présente des erreurs critiques dans les pods déployés par l’utilisateur :

À partir de là, vous pouvez approfondir l’analyse pour trouver le problème. Par exemple, si l’état du pod est ImagePullBackoff, Kubernetes n’a pas pu extraire l’image de conteneur à partir du Registre. Ce problème peut être dû à une balise de conteneur non valide ou à une erreur d’authentification lors d’une extraction du registre.
Si un conteneur se bloque, le conteneur State devient Waiting, avec un Reason de CrashLoopBackOff. Dans le cas d’un scénario classique, où un pod fait partie d’un jeu de réplicas et que la stratégie de nouvelle tentative est Always, ce problème ne s’affiche pas comme une erreur dans l’état du cluster. Toutefois, vous pouvez exécuter des requêtes ou configurer des alertes pour cette condition. Pour plus d’informations, consultez Comprendre les performances du cluster AKS avec Azure Monitor Container Insights.
Plusieurs classeurs spécifiques au conteneur sont disponibles dans le volet de classeurs d’une ressource AKS. Vous pouvez utiliser ces classeurs pour obtenir une vue d’ensemble rapide, pour résoudre des problèmes, pour gérer et pour obtenir des aperçus. La capture d’écran suivante montre une liste de classeurs disponibles par défaut pour les charges de travail AKS.

Nous vous recommandons d’utiliser Monitor pour collecter et afficher les métriques de vos clusters AKS et de tous les autres services Azure dépendants.
Pour les métriques de cluster et de conteneur, activez Azure Monitor Container Insights. Lorsque cette fonctionnalité est activée, Monitor collecte les métriques de mémoire et de processeur à partir des contrôleurs, des nœuds et des conteneurs via l’API Métriques Kubernetes. Pour plus d’informations sur les métriques disponibles dans Container Insights, consultez Comprendre les performances du cluster AKS avec Azure Monitor Container Insights.
Utilisez Application Insights pour activer les métriques d’application. Application Insights est un service de gestion des performances des applications (APM) extensible. Pour l’utiliser, vous installez un package d’instrumentation dans votre application. Ce package surveille l’application et envoie les données de télémétrie à Application Insights. Il peut également extraire les données de télémétrie de l’environnement hôte. Les données sont ensuite envoyées à Monitor. Application Insights intègre également des fonctions de mise en corrélation et de suivi des dépendances. (Voir Suivi distribué, plus loin dans cet article.)
Application Insights a un débit maximal qui est mesuré en événements par seconde, et il réduit la télémétrie si le taux de données dépasse la limite. Pour plus d’informations, consultez Limites d’Application Insights. Créez différentes instances de Application Insights pour chaque environnement, pour que les environnements de développement/test ne consomment pas les données de télémétrie prévues pour l’environnement de production.
Une seule opération peut générer plusieurs événements de télémétrie ; par conséquent, si une application est confrontée à un trafic dense, sa capture de télémétrie risque d’être ralentie. Pour atténuer ce problème, vous pouvez procéder à un échantillonnage afin de réduire le trafic de télémétrie. Le compromis est que vos métriques seront moins précises, à moins que l'instrumentation ne prenne en charge la pré-agrégation. Dans ce cas, il y aura moins d’exemples de trace pour la résolution des problèmes, mais les métriques conserve la précision. Pour plus d’informations, consultez l’article Échantillonnage dans Application Insights. Vous pouvez également réduire le volume de données en pré-agrégeant les métriques. Autrement dit, vous pouvez calculer des valeurs statistiques, telles que la moyenne et l’écart type, et envoyer ces valeurs au lieu de la télémétrie brute. Cet article de blog décrit une approche de l’utilisation d’Application Insights à l’échelle : Azure Monitoring et Analytics à grande échelle.
Si votre débit de données est suffisamment élevé pour déclencher la limitation de bande passante et que l’échantillonnage ou l’agrégation ne sont pas des solutions acceptables, vous pouvez exporter les métriques dans une base de données de série chronologique, comme Azure Data Explorer, Prometheus ou InfluxDB s’exécutant dans le cluster.
Azure Data Explorer est un service d’exploration de données natif Azure hautement évolutif pour les données de journaux et de télémétrie. Il prend en charge divers formats de données, un langage de requête riche et des connexions pour consommer des données dans des outils répandus comme Jupyter Notebook et Grafana. Azure Data Explorer dispose de connecteurs intégrés permettant d’ingérer les données de journaux et de métriques via Azure Event Hubs. Pour plus d’informations, consultez Ingérer et interroger des données de supervision dans Azure Data Explorer.
InfluxDB est un système basé sur la transmission de type push. Un agent doit transmettre (push) les métriques. Vous pouvez utiliser la pile TICK pour configurer la surveillance de Kubernetes. Ensuite, vous pouvez transmettre les métriques vers InfluxDB en utilisant l’agent Telegraf, qui collecte et rapporte les métriques. Vous pouvez utiliser InfluxDB pour des événements irréguliers et des types de données de chaîne.
Prometheus est un système basé sur l’extraction (pull). Il récupère régulièrement les métriques à partir d’emplacements configurés. Prometheus peut scraper les métriques générées par Azure Monitor ou kube-state-metrics. kube-state-metrics est un service qui collecte des métriques à partir du serveur d’API Kubernetes et les rend accessibles à Prometheus (ou à un système de récupération compatible avec un point de terminaison client Prometheus). Pour les métriques système, utilisez l’exportateur de nœuds, qui est un exportateur Prometheus pour les métriques système. Le système Prometheus prend en charge les données de type virgule flottante, mais non les données de type chaîne ; il se révèle donc adapté aux métriques système, mais pas aux journaux d’activité. Kubernetes Metrics Server est un aggrégateur de données d’utilisation des ressources pour l’ensemble du cluster.
Voici quelques-uns des problèmes généraux liés à la journalisation dans une application de microservices :
- Comprendre le traitement de bout en bout d’une demande du client, où plusieurs services peuvent être appelés pour gérer une requête unique.
- Consolider des journaux de plusieurs services en une seule vue agrégée.
- Analyser des journaux provenant de plusieurs sources, qui utilisent leurs propres schémas de journalisation ou n’ont pas de schéma particulier. Les journaux peuvent être générés par des composants tiers que vous ne contrôlez pas.
- Les architectures de microservices génèrent souvent un plus grand volume de journaux que les monolithes traditionnels, car il y a plus de services, d’appels réseau et d’étapes dans une transaction. Cela signifie que la journalisation elle-même peut constituer un goulot d’étranglement des performances ou des ressources pour l’application.
Les architectures basées sur Kubernetes présentent quelques défis supplémentaires :
- Les conteneurs peuvent se déplacer et être replanifiés.
- Kubernetes est doté d’une capacité d’abstraction de réseau qui utilise des adresses IP virtuelles et des mappages de port.
Voici l’approche standard de journalisation dans Kubernetes : d’abord, un conteneur écrit les journaux sur stdout et stderr. Puis le moteur de conteneur redirige ces flux vers un pilote de journalisation. Pour faciliter l’interrogation et éviter la perte éventuelle de données de journal si un nœud cesse de répondre, l’approche habituelle consiste à collecter les journaux de chaque nœud et à les envoyer vers un emplacement de stockage central.
Azure Monitor s’intègre à AKS pour prendre en charge cette approche. Monitor collecte les journaux de conteneurs et les envoie à un espace de travail Log Analytics. À partir de là, vous pouvez utiliser le Langage de requête Kusto pour écrire des requêtes dans les journaux agrégés. Par exemple, voici une requête Kusto pour afficher les journaux de conteneur pour un pod spécifié :
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure Monitor est un service géré, et la configuration d’un cluster AKS pour utiliser Monitor est un simple changement de configuration dans le modèle CLI ou Azure Resource Manager. (Pour plus d’informations, consultez Comment activer Azure Monitor Container insights.) Un autre avantage de l’utilisation d’Azure Monitor est qu’il consolide vos journaux AKS avec d’autres journaux de la plateforme Azure afin d’offrir une expérience de surveillance unifiée.
Azure Monitor est facturé par Go de données ingéré dans le service. (Consultez tarification d’Azure Monitor.) En cas de volumes élevés, le coût peut devenir un facteur à prendre en compte. De nombreuses alternatives Open Source sont disponibles pour l’écosystème Kubernetes. Par exemple, de nombreuses organisations utilisent Fluentd avec Elasticsearch. Fluentd est un collecteur de données Open Source, tandis qu’Elasticsearch est une base de données de documents utilisée pour la recherche. Si vous utilisez ces options, ne perdez pas de vue qu’elles nécessitent une configuration et une gestion supplémentaires du cluster. Pour une charge de travail de production, vous devrez peut-être faire des essais avec les paramètres de configuration. Vous devez également surveiller les performances de l’infrastructure de journalisation.
OpenTelemetry est une initiative multisectorielle qui vise à améliorer le traçage par la standardisation de l’interface entre les applications, les bibliothèques, les données de télémétrie et les collecteurs de données. Lorsque vous utilisez une bibliothèque et une infrastructure instrumentées avec OpenTelemetry, la plupart des opérations de traçage qui sont traditionnellement des opérations système sont prises en charge par les bibliothèques sous-jacentes, ce qui inclut les scénarios courants suivants :
- Journalisation des opérations de requête de base, telles que l’heure de début, l’heure de fin et la durée
- Exceptions levées
- Propagation de contexte (comme l’envoi d’un ID de corrélation dans les limites d’appels HTTP)
Au lieu de cela, les bibliothèques et les infrastructures de base qui gèrent ces opérations créent de riches structures de données interdépendantes d’étendue et de trace et les propagent dans les contextes. Avant OpenTelemetry, elles étaient généralement injectées sous forme de messages de journal spéciaux ou de structures de données propriétaires qui étaient propres à l’éditeur ayant créé les outils de supervision. OpenTelemetry encourage également un modèle de données d’instrumentation plus riche qu’une approche traditionnelle axée sur la journalisation, et les journaux sont plus utiles parce que les messages de journalisation sont liés aux traces et aux étendues où ils ont été générés. La recherche des journaux associés à une opération ou à une demande spécifique s’en trouve souvent facilitée.
La plupart des kits SDK Azure ont été instrumentés avec OpenTelemetry ou sont sur le point de l’implémenter.
Un développeur d’applications peut ajouter une instrumentation manuelle à l’aide des kits SDK OpenTelemetry pour effectuer les activités suivantes :
- Ajouter l’instrumentation lorsqu’une bibliothèque sous-jacente ne la propose pas.
- Enrichissez le contexte de trace en ajoutant des étendues pour exposer des unités de travail propres à une application (comme une boucle de commande qui crée une étendue pour le traitement de chaque ligne de commande).
- Enrichissez les étendues existantes avec des clés d’entité pour faciliter le suivi. (Par exemple, ajoutez une clé/valeur OrderID à la requête qui traite cette commande). Ces clés sont exposées par les outils de surveillance sous forme de valeurs structurées pour l’interrogation, le filtrage et l’agrégation (sans analyse des chaînes de message de journal ni recherche de combinaisons de séquences de messages de journal, comme c’était souvent le cas avec une approche axée prioritairement sur la journalisation).
- Propagez le contexte de trace en accédant aux attributs de trace et d’étendue, en injectant des traceIds dans les réponses et les charges utiles et/ou en lisant les traceIds des messages entrants, afin de créer des demandes et des étendues.
Pour en savoir plus sur l’instrumentation et les SDK OpenTelemetry, consultez la documentation OpenTelemetry.
Application Insights collecte les données élaborées d’OpenTelemetry et de ses bibliothèques d’instrumentation, et les capture dans un magasin de données efficace pour offrir une visualisation riche et une prise en charge des requêtes. Les bibliothèques d’instrumentation Application Insights basées sur OpenTelemetry, pour des langages comme .NET, Java, Node.js et Python, facilitent l’envoi de données de télémétrie vers Application Insights.
Si vous utilisez .NET Core, nous vous recommandons de considérer également la bibliothèque Application Insights pour Kubernetes. Cette bibliothèque enrichit les suivis Application Insights avec des informations supplémentaires sur les conteneurs, nœuds, pods, étiquettes et jeux de réplicas.
Application Insights mappe le contexte OpenTelemetry à son modèle de données interne :
- Trace -> Opération
- ID de trace -> ID d’opération
- Étendue -> Demande ou dépendance
Prenez en compte les considérations suivantes :
- Application Insights limite la télémétrie si le débit de données dépasse une limite maximale. Pour plus d’informations, consultez Limites d’Application Insights. Une seule opération peut générer plusieurs événements de télémétrie, de sorte que si une application connaît un volume de trafic élevé, elle est susceptible d’être ralentie.
- Comme Application Insights regroupe les données par lots, vous pouvez perdre un lot si un processus échoue en raison d’une exception non gérée.
- La facturation d’Application Insights est basée sur le volume de données. Pour plus d’informations, consultez l’article Gérer la tarification et le volume de données dans Application Insights.
Pour faciliter l’analyse des journaux, utilisez la journalisation structurée lorsque vous le pouvez. Lorsque vous utilisez la journalisation structurée, l’application écrit les journaux dans un format structuré, comme JSON, plutôt que de générer des chaînes de texte non structurées. De nombreuses bibliothèques de journalisation structurées sont disponibles. Par exemple, voici une instruction de journalisation qui utilise la bibliothèque Serilog pour .NET Core :
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
Ici, l’appel à LogInformation comprend les paramètres Id et DeliveryInfo. Lorsque vous utilisez la journalisation structurée, ces valeurs ne sont pas interpolées dans la chaîne de message. Au lieu de cela, la sortie du journal ressemble à ceci :
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Il s’agit d’une chaîne JSON, où le champ @t est un timestamp, @mt est la chaîne de message, et les paires clé/valeur restantes sont les paramètres. La mise en forme du format JSON facilite l’interrogation des données de façon structurée. Par exemple, la requête Log Analytics suivante, écrite dans le langage de requête Kusto, recherche les instances de ce message particulier à partir de tous les conteneurs nommés fabrikam-delivery :
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Si vous visualisez le résultat dans le portail Azure, vous pouvez voir que DeliveryInfo est un enregistrement structuré qui contient la représentation sérialisée du modèle DeliveryInfo :

Voici le code JSON de cet exemple :
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
De nombreux messages de journal marquent le début ou la fin d’une unité de travail, ou ils connectent une entité métier à un ensemble de messages et d’opérations pour la traçabilité. Dans de nombreux cas, il est préférable d’enrichir les objets d’étendue et de demande OpenTelemetry que de journaliser uniquement le début et la fin de l’opération. Ce faisant, vous ajoutez ce contexte à toutes les traces connectées aux opérations enfants, et vous placez ces informations dans l’étendue de l’opération complète. Les kits SDK OpenTelemetry pour différents langages prennent en charge la création d’étendues ou l’ajout d’attributs personnalisés aux étendues. Par exemple, le code suivant utilise le Kit de développement logiciel (SDK) Java OpenTelemetry, qui est pris en charge par Application Insights. Une étendue parente existante (par exemple, une étendue de demande associée à un appel de contrôleur REST et créée par l’infrastructure web utilisée) peut être enrichie avec un ID d’entité qui lui est associé, comme illustré ici :
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Ce code définit une clé ou une valeur dans l’étendue actuelle, qui est connectée à des opérations et à des messages de journal qui relèvent de cette étendue. La valeur apparaît dans l’objet de requête Application Insights, comme illustré ici :
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Cette technique devient plus efficace quand elle est utilisée avec les journaux, le filtrage et l’annotation des traces de journal avec le contexte d’étendue, comme illustré ici :
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Si vous utilisez une bibliothèque ou une infrastructure déjà instrumentée avec OpenTelemetry, elle gère la création d’étendues et de demandes, mais le code d’application risque également de créer des unités de travail. Par exemple, une méthode qui effectue une boucle dans un tableau d’entités qui exécute un travail sur chacune d’elles peut créer une étendue pour chaque itération de la boucle de traitement. Pour plus d’informations sur l’ajout d’instrumentation au code d’application et de bibliothèque, consultez la documentation sur l’instrumentation OpenTelemery.
L’un des défis quand vous utilisez des microservices est de comprendre le flux d’événements entre les services. Une même transaction peut impliquer des appels à plusieurs services.
Cet exemple décrit le cheminement d’une transaction distribuée à travers un ensemble de microservices. L’exemple est basé sur une application de livraison par drone.
Dans ce scénario, la transaction distribuée comprend les étapes suivantes :
- Le service d’ingestion place un message dans une file d’attente Azure Service Bus.
- Le service de workflow extrait le message de la file d’attente.
- Le service Workflow appelle trois services principaux pour traiter la requête (Drone Scheduler, Package et Delivery).
La capture d’écran suivante montre la cartographie d’application pour l’application de livraison par drone. Cette cartographie indique les appels à destination du point de terminaison de l’API publique qui génèrent un flux de travail impliquant cinq microservices.
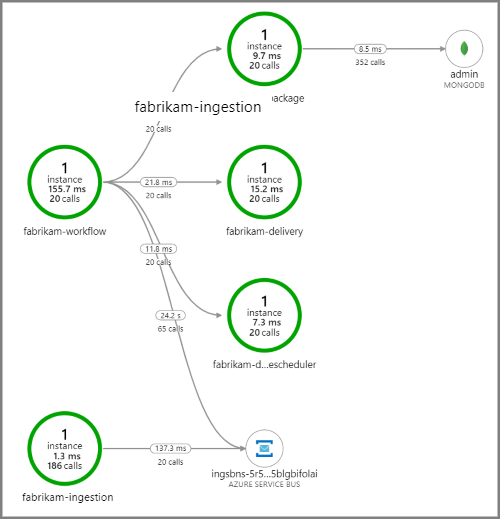
Les flèches reliant fabrikam-workflow et fabrikam-ingestion à une file d’attente Service Bus indiquent l’emplacement d’envoi et de réception des messages. Dans le diagramme, vous ne pouvez pas déterminer quel service envoie des messages et lequel reçoit. Les flèches indiquent simplement que les deux services appellent Service Bus. Toutefois, les informations sur le service qui envoie et celui qui reçoit sont disponibles dans les détails :
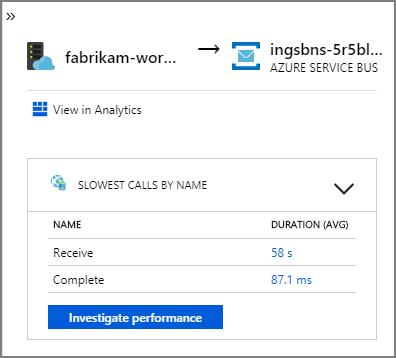
Étant donné que chaque appel inclut un ID d’opération, vous pouvez également afficher les étapes de bout en bout d’une transaction unique, y compris les informations de minutage et les appels HTTP à chaque étape. Voici la visualisation d’une telle transaction :

Cette visualisation montre les étapes du service d’ingestion vers la file d’attente, de la file d’attente vers le service de Workflow, et du service de Workflow vers les autres services principaux. La dernière étape survient lorsque le service de workflow marque le message Service Bus comme terminé.
Cet exemple montre les appels à un service principal qui échouent :
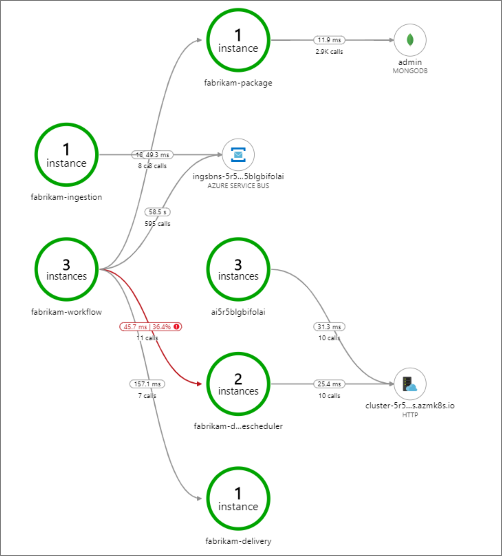
Cette cartographie montre qu’une grande partie (36%) des appels au service Drone Scheduler ont échoué au cours de la période de la requête. L’affichage transactionnel de bout en bout révèle qu’une exception se produit lorsqu’une requête HTTP PUT est envoyée au service :

Si vous explorez plus en détail, vous pouvez voir que l’exception est une exception de socket : « Aucun appareil ou adresse de ce type ».
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Cette exception suggère que le service principal n’est pas accessible. À ce stade, vous pouvez utiliser kubectl pour afficher la configuration du déploiement. Dans cet exemple, le nom d’hôte du service ne se résout pas en raison d’une erreur dans les fichiers de configuration Kubernetes. L’article Déboguer les services de la documentation Kubernetes contient des conseils pour le diagnostic de ce type d’erreur.
Voici quelques causes courantes d’erreurs.
- Bogues de code. Ces bogues peuvent apparaître comme suit :
- Des exceptions : examinez les journaux d’Application Insights pour afficher les détails d’une exception.
- Un processus échoue. examinez l’état du conteneur et du pod, puis affichez les journaux de conteneur ou les suivis d’Application Insights.
- Erreurs HTTP 5xx.
- Un épuisement des ressources :
- Recherchez la limitation (HTTP 429) ou les délais d’expiration des requêtes.
- Examinez les métriques de conteneur concernant le processeur, la mémoire et le disque.
- Examinez les paramètres de configuration des limites de ressource du conteneur et du POD.
- Une découverte des services : examinez la configuration du service Kubernetes et les mappages de port.
- Une incompatibilité d’API : recherchez les erreurs HTTP 400. Si les API sont versionnées, examinez la version appelée.
- Erreur dans l’extraction d’une image de conteneur. examinez la spécification du pod. Vérifiez aussi que le cluster est autorisé à effectuer une extraction à partir du registre de conteneurs.
- Problèmes RBAC.
En savoir plus sur les fonctionnalités de Azure Monitor qui prennent en charge la surveillance des applications sur AKS :