Concevoir la communication interservice pour les microservices
La communication entre les microservices doit se révéler à la fois efficace et robuste. Or, étant donné que l’exécution d’une simple activité métier implique l’interaction d’un grand nombre de petits services, cet objectif peut représenter un véritable défi. Dans cet article, nous allons comparer les compromis induits par l'utilisation d'une messagerie asynchrone et par l'emploi d'API synchrones. Ensuite, nous étudierons certaines des difficultés liées à la conception de communications interservice résilientes.
Défis
Cette section répertorie quelques-uns des principaux défis en matière de communications interservice. Les mailles de services, décrites plus loin dans cet article, sont conçues pour vous aider à relever la plupart de ces défis.
Résilience. Il peut exister plusieurs dizaines ou même centaines d’instances d’un microservice donné. Une instance peut échouer pour plusieurs raisons. Il peut se produire un échec au niveau du nœud, par exemple une défaillance matérielle ou un redémarrage de machine virtuelle. Une instance peut se bloquer ou être submergée de requêtes et se trouver dans l’incapacité de traiter toute nouvelle requête. Tous ces événements sont susceptibles d’entraîner l’échec d’un appel réseau. Deux modèles de conception peuvent vous aider à accroître la résilience des appels réseau interservice :
Nouvelle tentative . Un appel réseau peut échouer en raison d’une erreur temporaire qui disparaît d’elle-même. Au lieu que l’opération échoue immédiatement, l’appelant doit généralement effectuer un nombre défini de nouvelles tentatives ou jusqu’à ce qu’un délai d’expiration configuré soit écoulé. Toutefois, si une opération n’est pas idempotente, les nouvelles tentatives peuvent produire des effets secondaires imprévus. Ainsi, il est possible que l’appel d’origine réussisse, mais que l’appelant n’obtienne jamais de réponse. Si l’appelant effectue une nouvelle tentative, l’opération risque d’être appelée deux fois. En règle générale, il est déconseillé de retenter l’exécution des méthodes POST ou PATCH, car le caractère idempotent de ces dernières n’est pas garanti.
Disjoncteur . Un nombre excessif de requêtes ayant échoué peut provoquer un goulot d’étranglement, car les requêtes en attente s’accumulent dans la file d’attente. Ces demandes bloquées peuvent contenir des ressources système critiques telles que la mémoire, des threads, les connexions de la base de données, etc. Cela peut provoquer une succession d’échecs. Le modèle Disjoncteur peut empêcher un service de tenter d’exécuter à plusieurs reprises une opération susceptible d’échouer.
Équilibrage de charge. Lorsque le service « A » appelle le service « B », la requête doit atteindre une instance en cours d’exécution du service « B ». Dans Kubernetes, le type de ressource Service fournit une adresse IP stable pour un groupe de pods. Le trafic réseau vers l’adresse IP du service est transféré à un pod au moyen de règles d’iptable. Par défaut, un pod aléatoire est choisi. Une maille de services (voir ci-dessous) peut fournir des algorithmes d’équilibrage de charge plus intelligents en fonction de la latence observée ou d’autres mesures.
Traçage distribué. Une même transaction peut s’étendre sur plusieurs services. Cette situation peut compliquer la surveillance des performances globales et de l’intégrité du système. Même si chaque service génère des journaux d’activité et des mesures, ces informations seront d’une utilité limitée si elles ne sont pas liées d’une manière ou d’une autre.
Contrôle de version des services. Lorsqu’une équipe déploie une nouvelle version d’un service, elle doit éviter d’interrompre tout autre service ou les clients externes qui dépendent de ce service. En outre, vous pouvez vouloir exécuter plusieurs versions d’un service côte à côte et acheminer les requêtes vers une version spécifique. Pour plus d’informations sur cet aspect, consultez la section Contrôle de version d’API.
Chiffrement TLS et authentification TLS mutuelle. Pour des raisons de sécurité, vous pouvez chiffrer le trafic entre les services avec TLS et utiliser l’authentification TLS mutuelle pour authentifier les appelants.
Comparaison entre messagerie synchrone et messagerie asynchrone
Les microservices peuvent utiliser deux modèles de messagerie de base pour communiquer avec d’autres microservices.
Communication synchrone. Dans ce modèle, un service appelle une API exposée par un autre service à l’aide d’un protocole tel que HTTP ou gRPC. Cette option constitue un modèle de messagerie synchrone, car l’appelant attend une réponse de la part du récepteur.
Transmission de message asynchrone. Dans ce modèle, un service envoie un message sans attendre de réponse, et un ou plusieurs services traitent ce message de façon asynchrone.
Il est important d’établir une distinction entre E/S asynchrone et protocole asynchrone. Le terme E/S asynchrone signifie que le thread appelant n’est pas bloqué pendant que l’E/S s’exécute. Cette approche est importante pour les performances, mais constitue un détail d’implémentation en termes d’architecture. Un protocole asynchrone signifie que l’expéditeur n’attend pas de réponse. HTTP est un protocole synchrone, même si un client HTTP peut utiliser des E/S asynchrones lorsqu’il envoie une requête.
Chaque modèle implique des compromis. Le modèle requête/réponse constitue un paradigme bien défini, de sorte que la conception d’une API peut sembler plus naturelle que celle d’un système de messagerie. Toutefois, la messagerie asynchrone confère certains avantages qui peuvent se révéler utiles dans une architecture de microservices :
Couplage réduit. L’expéditeur du message n’a pas besoin de disposer d’informations concernant le consommateur.
Abonnés multiples. Un modèle de publication/abonnement permet à plusieurs consommateurs de s’abonner à la réception d’événements. Consultez l’article Style d’architecture basée sur les événements.
Isolation des défaillances. Si le consommateur échoue, l’expéditeur peut toujours envoyer des messages. Ces messages seront récupérés une fois que l’état normal du consommateur aura été rétabli. Cette possibilité se révèle particulièrement utile dans une architecture de microservices, car chaque service possède son propre cycle de vie. Il est possible qu’un service devienne inaccessible ou soit remplacé par une version plus récente à un moment donné. Une messagerie asynchrone peut gérer les temps d’arrêt intermittents. En revanche, les API synchrones exigent que le service en aval soit disponible ; dans le cas contraire, l’opération échouera.
Réactivité. Un service en amont peut répondre plus rapidement s’il n’attend aucune réaction de la part des services en aval. Cette approche se révèle particulièrement utile dans une architecture de microservices. S’il existe une chaîne de dépendances entre les services (le service A appelle B, qui appelle C, et ainsi de suite), le temps d’attente inhérent aux appels synchrones risque d’augmenter la latence de manière inacceptable.
Nivellement de charge. Une file d’attente peut jouer le rôle de mémoire tampon pour niveler la charge de travail, afin que les récepteurs puissent traiter les messages à leur propre rythme.
Flux de travail. Il est possible de gérer un workflow à l’aide de files d’attente en créant des points de contrôle qui vérifient le message après chaque étape du workflow.
Toutefois, l’utilisation efficace d’une messagerie asynchrone soulève également certaines difficultés.
Couplage avec l’infrastructure de messagerie. L’utilisation d’une infrastructure de messagerie spécifique risque d’entraîner un couplage étroit avec cette infrastructure. Il sera alors difficile de passer à une autre infrastructure de messagerie par la suite.
Latence. La latence de bout en bout d’une opération peut devenir élevée si les files d’attente de messages deviennent saturées.
Coût : L’utilisation de hauts débits est susceptible d’augmenter le coût monétaire de l’infrastructure de messagerie de façon significative.
Complexité : La gestion d’une messagerie asynchrone n’est pas une tâche aisée. Par exemple, vous devez gérer les messages en double, soit en procédant à une déduplication, soit en rendant les opérations idempotentes. Il est également difficile d’implémenter la sémantique requête-réponse à l’aide d’une messagerie asynchrone. Pour envoyer une réponse, vous devez disposer d’une autre file d’attente, ainsi que d’un moyen de mettre en corrélation les messages de requête et de réponse.
Débit. Si les messages nécessitent une sémantique de file d’attente, la file d’attente peut devenir un goulot d’étranglement dans le système. Chaque message requiert au moins une opération de file d’attente et une opération d’enlèvement de la file d’attente. En outre, la sémantique de file d’attente requiert généralement un certain type de verrouillage au sein de l’infrastructure de messagerie. Si la file d’attente est un service géré, elle risque d’entraîner une latence supplémentaire, car la file d’attente est externe au réseau virtuel du cluster. Vous pouvez atténuer ces problèmes en traitant les messages par lot, mais cette approche complique le code. Si les messages ne nécessitent pas une sémantique de file d’attente, vous serez peut-être en mesure d’utiliser un flux d’événements plutôt qu’une file d’attente. Pour plus d’informations, consultez l’article Style d’architecture basée sur les événements.
Application Drone Delivery : Choix des modèles de messagerie
Cette solution utilise l’exemple Drone Delivery. Elle est idéale pour les secteurs de l’aérospatiale et de l’aviation.
En tenant compte de ces considérations, l’équipe de développement a effectué les choix de conception ci-après pour l’application Drone Delivery :
Le service Ingestion expose une API REST publique que les applications clientes utilisent pour planifier, mettre à jour ou annuler les livraisons.
Le service Ingestion utilise Event Hubs pour envoyer des messages asynchrones au service Scheduler. Les messages asynchrones sont nécessaires à l’implémentation du nivellement de charge requis pour l’ingestion.
Les services Account, Delivery, Package, Drone et Third-party Transport exposent tous des API REST internes. Le service Scheduler appelle ces API pour effectuer une requête utilisateur. L’utilisation d’API synchrones est notamment motivée par le fait que le service Scheduler a besoin d’obtenir une réponse de la part de chacun des services en aval. Un échec dans l’un des services en aval signifie que la totalité de l’opération a échoué. Toutefois, le temps de latence introduit par l’appel des services principaux constitue un problème potentiel.
Si l'un des services situés en aval présente un échec non temporaire, la totalité de la transaction doit être marquée comme ayant échoué. Pour gérer cette situation, le service Scheduler envoie un message asynchrone au service Supervisor pour permettre à ce dernier de planifier les transactions de compensation.
Le service Delivery expose une API publique que les clients peuvent utiliser pour obtenir l’état d’une livraison. Dans l'article Passerelles API, nous décrivons la façon dont une passerelle API peut masquer les services sous-jacents au client, afin que ce dernier n'ait pas besoin de savoir quelles sont les API exposées par les différents services.
Lorsqu’un drone est en vol, le service Drone envoie des événements qui contiennent l’emplacement et l’état actuels du drone. Le service Delivery écoute ces événements afin de suivre l’état d’une livraison.
Lorsque l’état d’une livraison change, le service Delivery envoie un événement d’état de livraison, tel que
DeliveryCreatedouDeliveryCompleted. Tous les services peuvent s’abonner à ces événements. Dans la conception actuelle, le service d’historique des livraisons est le seul abonné, mais il pourra y avoir d’autres abonnés par la suite. Par exemple, les événements peuvent transiter par un service d’analyse en temps réel. En outre, étant donné que le service Scheduler n’a pas besoin d’attendre de réponse, l’ajout d’autres abonnés n’a pas d’incidence sur le chemin du workflow principal.
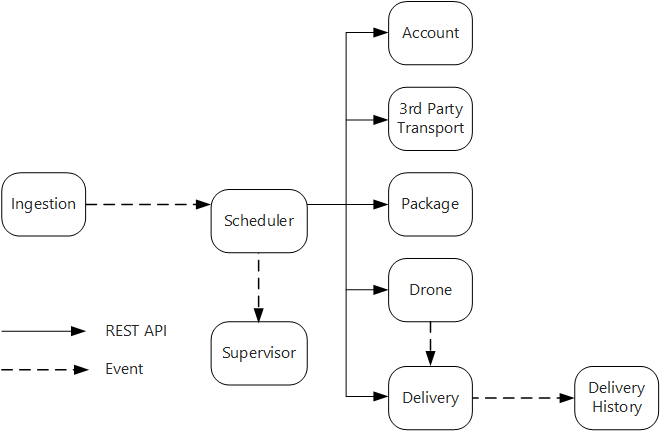
Notez que les événements d’état de livraison dérivent des événements d’emplacement de drone. Par exemple, lorsqu’un drone atteint un emplacement de livraison et dépose un package, le service Delivery traduit cette situation en événement DeliveryCompleted. Ceci constitue un exemple de pensée en termes de modèles de domaine. Comme indiqué précédemment, le système de gestion des drones (Drone Management) appartient à un contexte lié distinct. Les événements de drone véhiculent l’emplacement physique d’un drone. Les événements de livraison représentent quant à eux les changements d’état d’une livraison, ce qui constitue une entité métier différente.
Utilisation d’une maille de services
Une maille de services est une couche logicielle qui gère les communications interservice. Les mailles de services sont destinées à résoudre la plupart des difficultés répertoriées à la section précédente, et à décharger les microservices proprement dits de la responsabilité de ces aspects en déléguant cette responsabilité à une couche partagée. La maille de services joue le rôle d’un proxy qui intercepte les communications réseau entre les microservices du cluster. Actuellement, le concept de maille de services s'applique principalement aux orchestrateurs de conteneurs, plutôt qu'aux architectures serverless.
Notes
La maille de services est un exemple du modèle Ambassadeur, un service d’assistance qui envoie des requêtes réseau au nom de l’application.
Pour l’instant, les principales options de maillage de services dans Kubernetes sont Linkerd et Istio. Ces deux technologies évoluent rapidement. Toutefois, voici certaines des fonctionnalités que Linkerd et Istio ont en commun :
Équilibrage de charge au niveau session, basé sur les latences observées ou sur le nombre de requêtes en attente. Cette fonctionnalité peut améliorer les performances par rapport à l’équilibrage de charge de type Couche 4 fourni par Kubernetes.
Acheminement de couche 7 basé sur le chemin d’URL, l’en-tête d’hôte, la version d’API ou toute autre règle de niveau application.
Nouvelle tentative pour les requêtes ayant échoué. Une maille de services comprend les codes d’erreur HTTP et peut retenter automatiquement les requêtes ayant échoué. Vous pouvez configurer le nombre maximal de nouvelles tentatives, ainsi qu’un délai d’expiration afin de limiter la latence maximale.
Disjoncteur. Si une instance entraîne un échec continu des requêtes, la maille de services marquera temporairement cette instance comme non disponible. Au terme d’une période d’interruption, elle retentera d’utiliser l’instance. Vous pouvez configurer le disjoncteur en fonction de différents critères, tels que le nombre d’échecs consécutifs.
La maille de services capture les mesures relatives aux appels interservice, comme le volume de requêtes, la latence, les taux d’erreurs et de réussite, ainsi que les tailles de réponse. La maille de services permet également de procéder à un traçage distribué en ajoutant des informations de corrélation pour chaque tronçon dans une requête.
Authentification TLS mutuelle pour les appels interservice.
Avez-vous besoin d’une maille de services ? Cela dépend. En l'absence de maille de services, vous devrez tenir compte de chacun des défis mentionnés au début de cet article. Vous pouvez résoudre les problèmes de nouvelle tentative, de disjoncteur et de traçage distribué sans recourir à une maille de services ; toutefois, cette dernière épargne ces problèmes aux différents services en les transférant vers une couche dédiée. D'autre part, une maille de services augmente la complexité de l'installation et de la configuration du cluster. Cette approche peut avoir une incidence sur les performances, car les requêtes sont alors acheminées par le biais du proxy de la maille de services, et les services supplémentaires s’exécutent désormais sur chaque nœud du cluster. Vous devez donc procéder à un test de performances et de charge approfondi avant de déployer une maille de services en production.
Transactions distribuées
En matière de microservices, l'un des principaux défis consiste à gérer correctement les transactions qui couvrent plusieurs services. Souvent, dans ce type de scénario, c’est tout ou rien : si l’un des services participants échoue, la transaction tout entière doit échouer.
Il existe deux cas à prendre en compte :
Un service peut rencontrer un échec temporaire, tel qu'un délai d'expiration réseau. Il est souvent possible de résoudre ces erreurs en procédant simplement à une nouvelle tentative d’appel. Si l'échec de l'opération persiste après un certain nombre de tentatives, elle est considérée comme un échec non temporaire.
Un échec non temporaire a peu de chances de disparaître de lui-même. Les échecs non temporaires incluent les conditions d'erreur normales, comme une entrée non valide. Les échecs non temporaires englobent également les exceptions non prises en charge dans le code d’application ou le blocage d’un processus. Si ce type d’erreur se produit, la totalité de la transaction métier doit être marquée en tant qu’échec. Il peut se révéler nécessaire d’annuler d’autres étapes réussies de la même transaction.
Après un échec non temporaire, la transaction en cours peut se trouver en échec partiel, état qui implique qu'une ou plusieurs étapes ont déjà été correctement exécutées. Par exemple, si le service Drone avait déjà planifié un drone, le drone doit être annulé. Dans ce cas, l’application doit annuler les étapes qui ont réussi en utilisant une transaction de compensation. Dans certains cas, cette action doit être effectuée par un système externe ou même par un processus manuel. Dans votre conception, n’oubliez pas que les mesures de compensation sont également sujettes à des échecs.
Si la logique des transactions de compensation se révèle complexe, envisagez de créer un service distinct qui sera responsable de ce processus. Dans l’application Drone Delivery, le service Scheduler place les opérations ayant échoué dans une file d’attente dédiée. Un microservice distinct, appelé Supervisor, lit les données de cette file d’attente et appelle une API d’annulation sur les services qui nécessitent une compensation. Il s’agit d’une variante du modèle de superviseur de l’agent planificateur. Le service Supervisor peut également exécuter d’autres actions, telles qu’avertir l’utilisateur par texte ou par e-mail, ou envoyer une alerte à un tableau de bord des opérations.
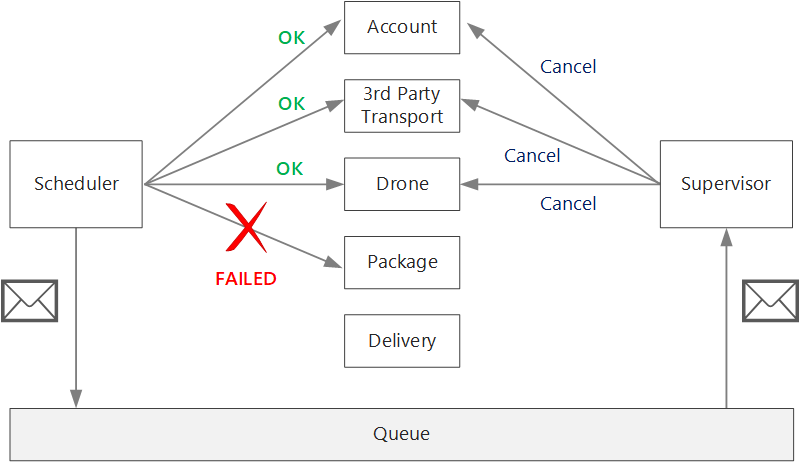
Le service Scheduler proprement dit peut faire l’objet d’une défaillance (par exemple, en raison du blocage d’un nœud). Dans ce cas, une nouvelle instance peut s'exécuter et prendre le relais. Toutefois, toutes les transactions qui étaient déjà en cours d’exécution au moment de l’incident devront être reprises.
Une approche consiste à enregistrer un point de contrôle dans un magasin durable après chaque étape du flux de travail. Si une instance du service Scheduler se bloque en plein milieu d'une transaction, une nouvelle instance peut utiliser le point de contrôle pour reprendre la transaction là où l'instance précédente s'est arrêtée. Cependant, l'écriture de points de contrôle peut entraîner une surcharge de performances.
Une autre option consiste à concevoir toutes les opérations comme étant idempotentes. Une opération est idempotente si elle peut être appelée plusieurs fois sans produire d’effets secondaires supplémentaires après le premier appel. Le service situé en aval doit ignorer les appels en double, ce qui signifie que le service doit être capable de détecter ceux-ci. Il n'est pas toujours simple d'implémenter une méthode idempotente. Pour plus d'informations, consultez Opérations idempotentes.
Étapes suivantes
Pour les microservices qui communiquent directement entre eux, il est important de créer des API bien conçues.