Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La grande variété de systèmes et d’appareils au niveau de l’atelier peut compliquer la configuration de la charge de travail. Cet article fournit des approches pour la résoudre.
Contexte et problème
Les entreprises manufacturières, dans le cadre de leur parcours de transformation numérique, se concentrent de plus en plus sur la création de solutions logicielles qui peuvent être réutilisées en tant que fonctionnalités partagées. En raison de la variété d’appareils et de systèmes au niveau de l’atelier, les charges de travail modulaires sont configurées pour prendre en charge différents protocoles, pilotes et formats de données. Parfois même plusieurs instances d’une charge de travail sont exécutées avec différentes configurations dans le même emplacement de périphérie. Pour certaines charges de travail, les configurations sont mises à jour plusieurs fois par jour. Par conséquent, la gestion de la configuration est de plus en plus importante pour la montée en puissance des solutions de périphérie.
Solution
Il existe quelques caractéristiques courantes de la gestion de la configuration pour les charges de travail edge :
- Il existe plusieurs points de configuration qui peuvent être regroupés en couches distinctes, telles que la source logicielle, le pipeline CI/CD, le locataire cloud et l’emplacement de périphérie :
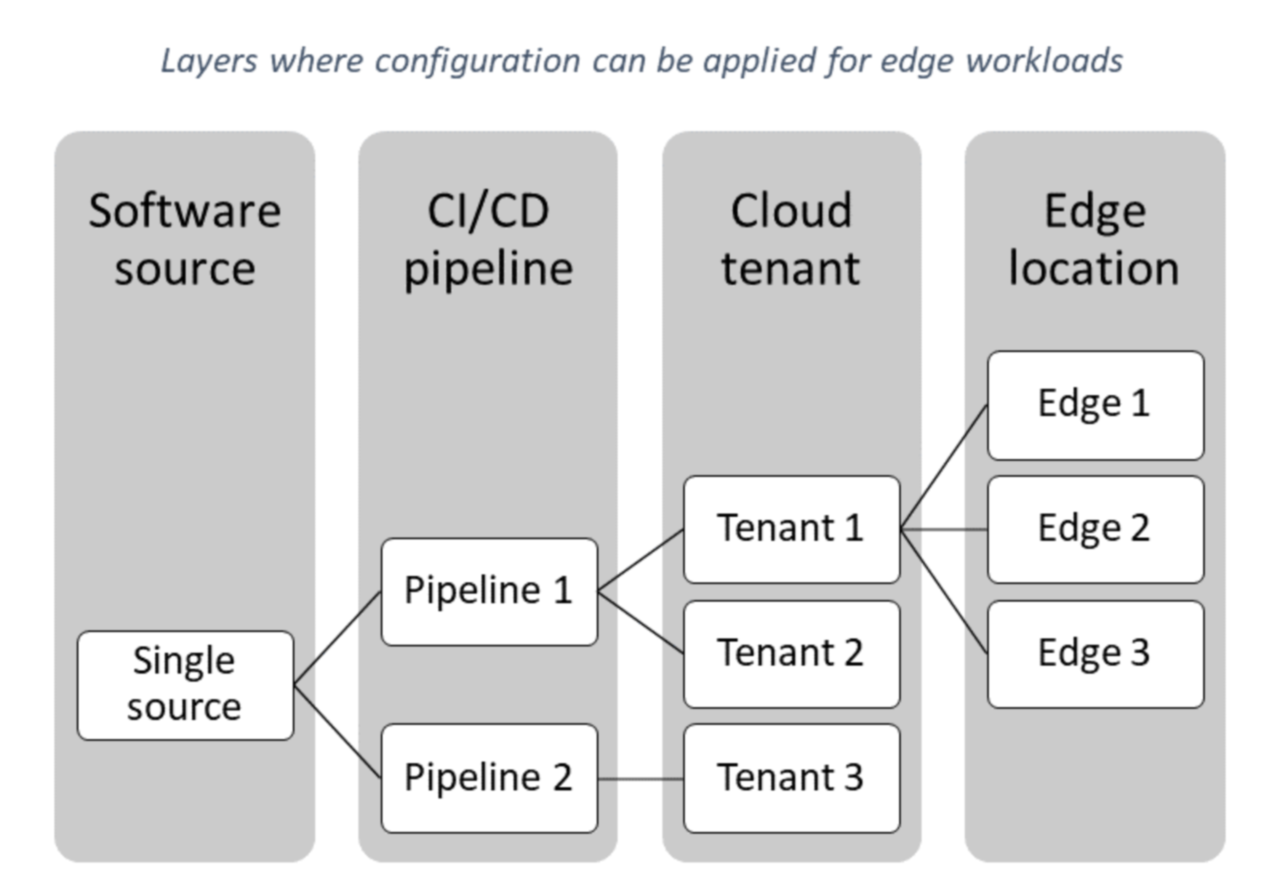
- Les différentes couches peuvent être mises à jour par différentes personnes.
- Quelle que soit la façon dont les configurations sont mises à jour, elles doivent être soigneusement suivies et auditées.
- Pour assurer la continuité d’activité, il est nécessaire que les configurations soient accessibles hors connexion à la périphérie.
- Il est également nécessaire qu’il existe une vue globale des configurations disponibles sur le cloud.
Problèmes et considérations
Tenez compte des points suivants lors de la décision d’implémenter ce modèle :
- L’autorisation des modifications lorsque la périphérie n’est pas connectée au cloud augmente considérablement la complexité de la gestion de la configuration. Il est possible de répliquer les modifications dans le cloud, mais il existe des défis avec :
- Authentification de l’utilisateur, car elle s’appuie sur un service cloud tel que Microsoft Entra ID.
- Résolution des conflits après reconnexion, si les charges de travail reçoivent des configurations inattendues nécessitant une intervention manuelle.
- L’environnement de périphérie peut avoir des contraintes liées au réseau si la topologie est conforme aux exigences ISA-95. Vous pouvez surmonter ces contraintes en sélectionnant une technologie qui offre une connectivité entre les couches, telles que les hiérarchies d’appareils dans Azure IoT Edge.
- Si la configuration au moment de l’exécution est découplée des versions logicielles, les modifications de configuration doivent être gérées séparément. Pour offrir des fonctionnalités d’historique et de restauration, vous devez stocker les configurations passées dans un magasin de données dans le cloud.
- Une erreur dans une configuration, telle qu’un composant de connectivité configuré pour un point de terminaison inexistant, peut interrompre la charge de travail. Par conséquent, il est important de traiter les modifications de configuration lorsque vous traitez d’autres événements de cycle de vie de déploiement dans la solution d’observabilité, afin que les tableaux de bord d’observabilité puissent aider à mettre en corrélation les erreurs système aux modifications de configuration. Pour plus d’informations sur l’observabilité, consultez le guide de supervision cloud : Observabilité.
- Comprendre les rôles que jouent les magasins de données cloud et edge dans la continuité de l’activité. Si le magasin de données cloud est la source unique de vérité, les charges de travail de périphérie doivent être en mesure de restaurer les états prévus à l’aide de processus automatisés.
- Pour la résilience, le magasin de données edge doit agir en tant que cache hors connexion. Cela est prioritaire sur les considérations relatives à la latence.
Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
- Il est nécessaire de configurer des charges de travail en dehors du cycle de publication du logiciel.
- Différentes personnes doivent pouvoir lire et mettre à jour des configurations.
- Les configurations doivent être disponibles même s’il n’existe aucune connexion au cloud.
Exemples de charges de travail :
- Solutions qui se connectent aux ressources au niveau de l’atelier pour l’ingestion de données ( OPC Publisher, par exemple) et commande et contrôle
- Tâches d'apprentissage automatique pour la maintenance prédictive
- Charges de travail d'apprentissage automatique qui inspectent la qualité en temps réel sur la ligne de fabrication.
Exemples
La solution permettant de configurer des charges de travail edge pendant l’exécution peut être basée sur un contrôleur de configuration externe ou un fournisseur de configuration interne.
Variation du contrôleur de configuration externe
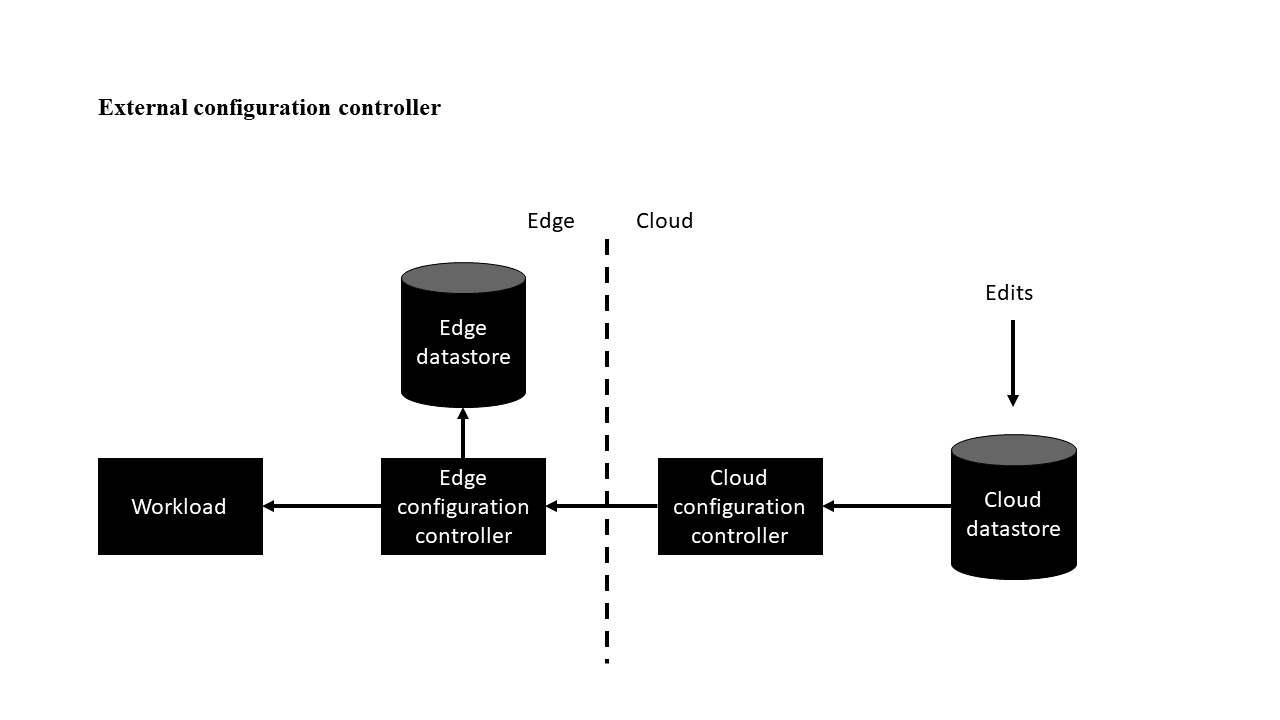
Cette variante a un contrôleur de configuration externe à la charge de travail. Le rôle du composant du contrôleur de configuration cloud consiste à envoyer (push) les modifications du magasin de données cloud à la charge de travail via le contrôleur de configuration de périphérie. La périphérie contient également un magasin de données afin que le système fonctionne même lorsqu’il est déconnecté du cloud.
Avec IoT Edge, le contrôleur de configuration en périphérie peut être implémenté en tant que module, et les configurations peuvent être appliquées à l'aide de "module twins". Le jumeau de module a une limite de taille ; si la configuration dépasse cette limite, la solution peut être étendue avec le stockage de Blob Azure ou en répartissant des charges utiles plus lourdes sur des méthodes directes.
Les avantages de cette variante sont les suivants :
- La charge de travail elle-même n’a pas à connaître le système de configuration. Cette fonctionnalité est requise si le code source de la charge de travail n’est pas modifiable, par exemple lors de l’utilisation d’un module à partir de la Place de marché Azure IoT Edge.
- Il est possible de modifier la configuration de plusieurs charges de travail en même temps en coordonnant les modifications via le contrôleur de configuration cloud.
- Une validation supplémentaire peut être implémentée dans le cadre du pipeline d’envoi, par exemple pour valider l’existence de points de terminaison en périphérie avant d’envoyer la configuration à la charge de travail.
Variante du fournisseur de configuration interne
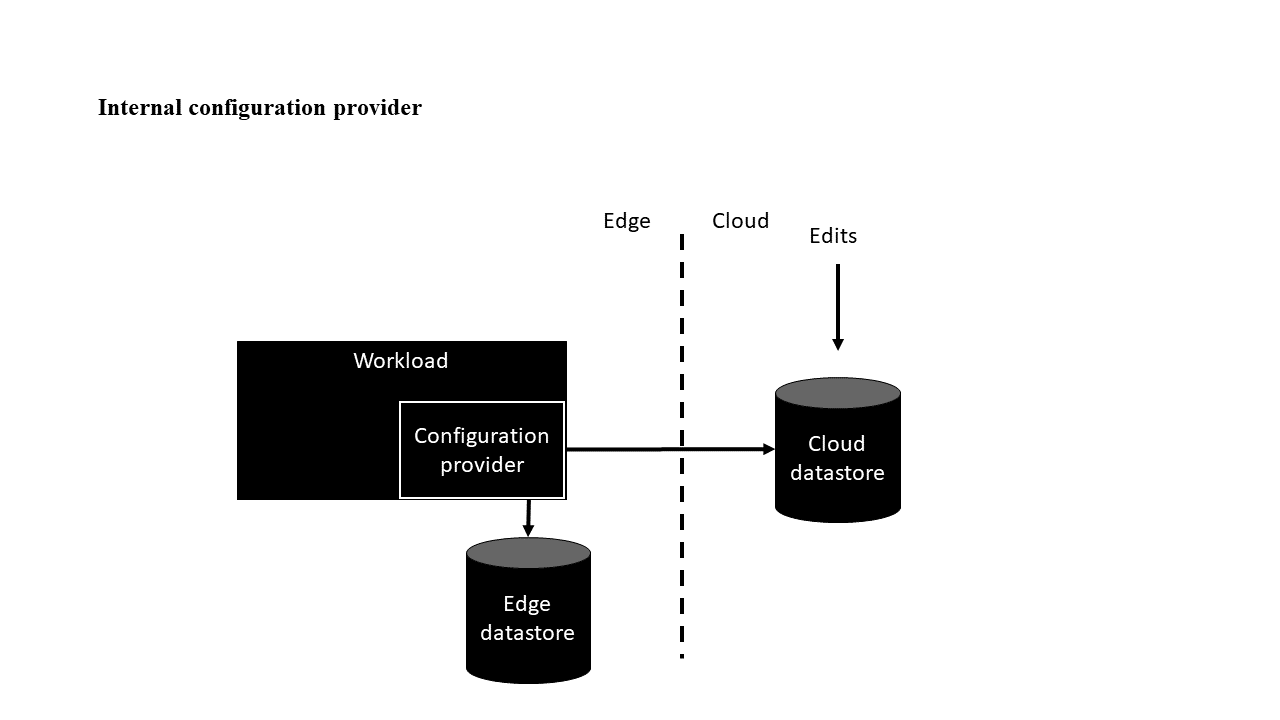
Dans la variante du fournisseur de configuration interne, la charge de travail extrait les configurations d’un fournisseur de configuration. Pour obtenir un exemple d’implémentation, consultez Implémenter un fournisseur de configuration personnalisé dans .NET. Cet exemple utilise C#, mais d’autres langages peuvent être utilisés.
Dans cette variante, les charges de travail ont des identificateurs uniques afin que le même code source s’exécutant dans différents environnements puisse avoir différentes configurations. Une façon de construire un identificateur consiste à concaténer la relation hiérarchique de la charge de travail à un regroupement de niveau supérieur tel qu’un locataire. Pour IoT Edge, il peut s’agir d’une combinaison du groupe de ressources Azure, du nom du hub IoT, du nom de l’appareil IoT Edge et de l’identificateur de module. Ces valeurs forment ensemble un identificateur unique qui fonctionne en tant que clé dans les magasins de données.
Bien que la version du module puisse être ajoutée à l’identificateur unique, il est courant de conserver les configurations entre les mises à jour logicielles. Si la version fait partie de l’identificateur, l’ancienne version de la configuration doit alors être migrée avec une implémentation supplémentaire.
Les avantages de cette variante sont les suivants :
- Autre que les magasins de données, la solution ne nécessite pas de composants, ce qui réduit la complexité.
- La logique de migration à partir d’anciennes versions incompatibles peut être gérée dans l’implémentation de la charge de travail.
Solutions basées sur IoT Edge
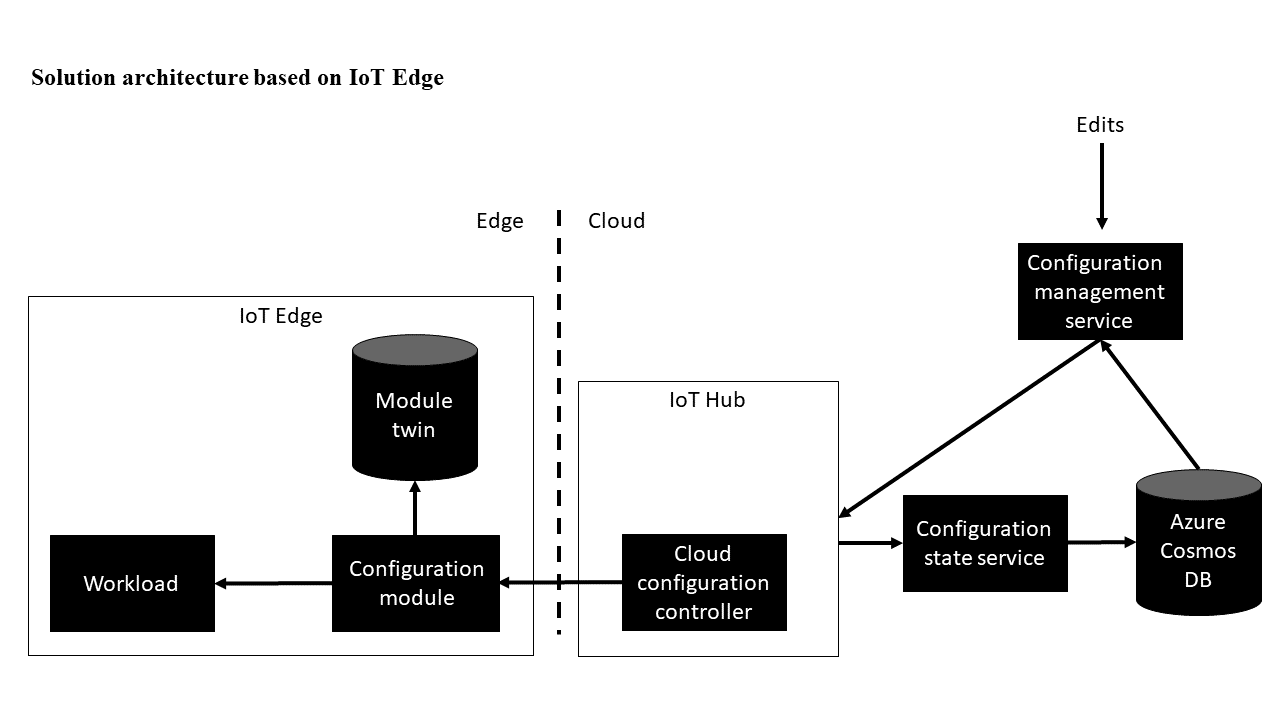
Le composant cloud de l’implémentation de référence IoT Edge se compose d’un hub IoT agissant comme contrôleur de configuration cloud. La fonctionnalité de jumeau de module Azure IoT Hub propage les modifications de configuration et les informations sur la configuration actuellement appliquée à l’aide des propriétés souhaitées et signalées du jumeau de module. Le service de gestion de la configuration agit comme source des configurations. Il peut également s’agir d’une interface utilisateur pour la gestion des configurations, d’un système de build et d’autres outils utilisés pour créer des configurations de charge de travail.
Une base de données Azure Cosmos DB stocke toutes les configurations. Il peut interagir avec plusieurs hubs IoT et fournit l’historique de configuration.
Une fois qu’un appareil edge indique via les propriétés signalées qu’une configuration a été appliquée, le service d’état de configuration note l’événement dans l’instance de base de données.
Lorsqu’une nouvelle configuration est créée dans le service de gestion de la configuration, elle est stockée dans Azure Cosmos DB et les propriétés souhaitées du module edge sont modifiées dans le hub IoT où réside l’appareil. La configuration est ensuite transmise par IoT Hub à l’appareil edge. Le module de périphérie est censé appliquer la configuration et signaler l’état de la configuration par le biais du jumeau de module. Le service d’état de configuration écoute ensuite les événements de modification du jumeau. S’il détecte qu’un module signale une modification de l’état de configuration, il enregistre la modification correspondante dans la base de données Azure Cosmos DB.
Le composant edge peut utiliser le contrôleur de configuration externe ou le fournisseur de configuration interne. Dans l’une ou l’autre implémentation, la configuration est transmise dans les propriétés souhaitées du jumeau de module ou, si de grandes configurations doivent être transmises, les propriétés souhaitées du jumeau de module contiennent une URL vers stockage Blob Azure ou vers un autre service qui peut être utilisé pour récupérer la configuration. Le module indique ensuite dans les propriétés signalées du jumeau de module si la nouvelle configuration a été appliquée et la configuration actuellement appliquée.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Heather Camm | Responsable du programme senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Azure IoT Edge
- Qu’est-ce qu’Azure IoT Edge ?
- Azure IoT Hub
- Concepts IoT et Azure IoT Hub
- Azure Cosmos DB
- Bienvenue dans Azure Cosmos DB
- Stockage Blob Azure
- Présentation du stockage Blob Azure