Fournisseur de stockage Azure (Azure Functions)
Ce document décrit les caractéristiques du fournisseur de stockage Azure Durable Functions, avec un focus sur les aspects des performances et de l’extensibilité. Le fournisseur de stockage Azure est le fournisseur par défaut. Il stocke les états d’instance et les files d’attente dans un compte Stockage Azure (classique).
Notes
Pour plus d’informations sur les options de fournisseur de stockage prises en charge pour Durable Functions et leur comparaison, consultez la documentation sur les fournisseurs de stockage Durable Functions.
Dans le fournisseur de stockage Azure, toutes les exécutions de fonction sont pilotées par les files d’attente stockage Azure. L’historique et l’état de l’entité et de l’orchestration sont stockés dans des tables Azure. Les objets blob Azure et les baux d’objets blob sont utilisés pour distribuer des instances d’orchestration et des entités entre plusieurs instances d’application (également appelées Workers ou simplement machines virtuelles). Cette section décrit plus en détail les différents artefacts de Stockage Azure et leur impact sur les performances et l’évolutivité.
Représentation de stockage
Un hub de tâches conserve durablement tous les états d’instance et tous les messages. Pour obtenir une vue d’ensemble rapide de la façon dont ces éléments sont utilisés pour suivre la progression d’une orchestration, consultez l’exemple d’exécution du hub de tâches.
Le fournisseur de Stockage Azure représente le hub de tâches dans le stockage à l’aide des composants suivants :
- Entre deux et trois tables Azure. Deux tables sont utilisées pour représenter les historiques et les états d’instance. Si le gestionnaire de partitions de table est activé, une troisième table est introduite pour stocker les informations de partition.
- Une file d’attente Azure stocke les messages d’activité.
- Une ou plusieurs files d’attente Azure stockent les messages d’instance. Chacune de ces dénommées files d’attente de contrôle représente une partition affectée à un sous-ensemble de tous les messages d’instance, en fonction du hachage de l’ID d’instance.
- Quelques conteneurs de blob supplémentaires utilisés pour les blobs de bail et/ou les messages volumineux.
Par exemple, un hub de tâches nommé xyz avec PartitionCount = 4 contient les files d’attente et les tables suivantes :

Ensuite, nous décrivons ces composants et le rôle qu’ils jouent plus en détail.
Table d’historique
La table d’historique est une table de stockage Azure qui contient les événements d’historique de toutes les instances d’orchestration au sein d’un hub de tâches. Le nom de la table apparaît sous la forme TaskHubNameHistory. Au fur et à mesure que des instances sont exécutées, de nouvelles lignes sont ajoutées à cette table. La clé de partition de la table provient de l’ID d’instance de l’orchestration. Par défaut, les ID d’instance sont aléatoires, ce qui garantit une distribution optimale des partitions internes dans Stockage Azure. La clé de ligne de ce tableau est un numéro de séquence utilisé pour classer les événements d’historique.
Lorsqu’une instance d’orchestration doit être exécutée, les lignes correspondantes de la table d’historique sont chargées en mémoire à l’aide d’une requête de plage dans une partition de table unique. Ces événements d’historique sont ensuite relus dans le code de fonction d’orchestrateur pour revenir à l’état contrôlé précédemment. L’utilisation de l’historique d’exécution permettant de régénérer l’état de cette façon est influencée par le modèle d’approvisionnement en événements.
Conseil
Les données d’orchestration stockées dans la table d’historique incluent les charges utiles de sortie des fonctions d’activité ou orchestrator secondaire. Les charges utiles des événements externes sont également stockées dans la table d’historique. Étant donné que l’historique complet est chargé en mémoire chaque fois qu’un orchestrateur doit s’exécuter, un historique suffisamment volumineux peut entraîner une sollicitation importante de la mémoire sur une machine virtuelle donnée. La longueur et la taille de l’historique de l’orchestration peuvent être réduites en fractionnant les grandes orchestrations en plusieurs sous-orchestrations ou en réduisant la taille des sorties retournées par l’activité et les fonctions orchestrator secondaires qu’elle appelle. Vous pouvez également réduire l’utilisation de la mémoire en diminuant limitations d’accès concurrentiel par machine virtuelle pour limiter le nombre d’orchestrations chargées en mémoire simultanément.
Table d’instances
La table d’instances contient les états de toutes les instances d’orchestration et d’entité au sein d’un hub de tâches. Au fur et à mesure que des instances sont créées, des lignes sont ajoutées à cette table. La clé de partition de cette table est l’ID d’instance de l’orchestration ou la clé d’entité, et la clé de ligne est une chaîne vide. Il y a une ligne par instance d’orchestration ou d’entité.
Cette table est utilisée pour répondre aux demandes de requête d’instance provenant du code et aux appels de l’API HTTP de requête d’état. Sa cohérence avec le contenu de la table d’historique mentionnée précédemment est conservée. L’utilisation d’une table de stockage Azure distincte pour satisfaire les opérations de requête d’instance de cette façon est influencée par le modèle de séparation des responsabilités en matière de commande et de requête (CQRS).
Conseil
Le partitionnement de la table Instances permet au service informatique de stocker des millions d’instances d’orchestration sans aucun impact notable sur les performances ou la mise à l’échelle du runtime. Toutefois, le nombre d’instances peut avoir un impact significatif sur les performances des requêtes sur plusieurs instances. Pour contrôler la quantité de données stockées dans ces tables, pensez à purger régulièrement les anciennes données d’instance.
Partitions de table
Remarque
Cette table s’affiche dans le hub de tâches uniquement lorsque Table Partition Manager est activé. Pour l’appliquer, configurez le paramètre useTablePartitionManagement dans host.json de votre application.
La table Partitions stocke les états de partitions pour l’application Durable Functions et est utilisée pour distribuer les partitions entre les workers de votre application. Il existe une ligne par partition.
Files d’attente
Les fonctions d’orchestrateur, d’entité et d’activité sont toutes déclenchées par des files d’attente internes dans le hub de tâches de l’application de fonction. Cette utilisation des files d’attente apporte des garanties de livraison de messages « au moins une fois » fiables. Il existe deux types de file d’attente dans Fonctions durables : la file d’attente de contrôle et la file d’attente des éléments de travail.
File d’attente des éléments de travail
Il existe une file d’attente des éléments de travail par hub de tâches dans Fonctions durables. Il s’agit d’une file d’attente de base qui se comporte comme toute autre file d’attente queueTrigger dans Azure Functions. Cette file d’attente permet de déclencher des fonctions d’activité sans état en enlevant un message de la file d’attente à la fois. Chacun de ces messages contient des entrées de fonction d’activité et des métadonnées supplémentaires, par exemple la fonction à exécuter. Quand une application Durable Functions est étendue à plusieurs machines virtuelles, ces dernières rivalisent entre elles pour acquérir les tâches de la file d’attente des éléments de travail.
File(s) d’attente de contrôle
Il existe plusieurs files d’attente de contrôle par hub de tâches dans Fonctions durables. Une file d’attente de contrôle est plus sophistiquée et complexe que la file d’attente des éléments de travail. Les files d’attente de contrôle servent à déclencher les fonctions d’orchestrateur ou d’entité avec état. Dans la mesure où les instances de fonction d’orchestrateur et d’entité sont des singletons avec état, il est important que chaque orchestration ou entité soit traitée uniquement par un seul Worker à la fois. Pour appliquer cette contrainte, chaque instance de l’orchestration ou entité est affectée à une seule file d’attente de contrôle. Ces files d’attente de contrôle font l’objet d’un équilibrage de la charge entre les Workers pour que chaque file d’attente soit traitée uniquement par un seul Worker à la fois. Vous trouverez plus d’informations sur ce comportement dans les sections suivantes.
Les files d’attente de contrôle contiennent différents types de message couvrant le cycle de vie de l’orchestration, tels que des messages de contrôle d’orchestrateurs, des messages de réponse de fonctions d’activité et des messages de minuteurs. Au maximum, 32 messages seront enlevés d’une file d’attente de contrôle lors d’une seule interrogation. Ces messages contiennent des données de charge utile ainsi que des métadonnées, et notamment l’instance d’orchestration de destination. Si plusieurs messages enlevés de la file d’attente sont prévus pour la même instance d’orchestration, ils seront traités en tant que lot.
Les messages de file d’attente de contrôle sont constamment interrogés à l’aide d’un thread en arrière-plan. La taille de lot de chaque interrogation de file d’attente est contrôlée par le paramètre controlQueueBatchSize dans host.json et a une valeur par défaut de 32 (la valeur maximale prise en charge par les files d’attente Azure). Le nombre maximal de messages de file d’attente de contrôle prérécupérés qui sont mis en mémoire tampon est contrôlé par le paramètre controlQueueBufferThreshold dans host.json. La valeur par défaut de controlQueueBufferThreshold varie en fonction de divers facteurs, notamment le type de plan d’hébergement. Pour plus d’informations sur ces paramètres, consultez la documentation du schéma host.json.
Conseil
L’augmentation de la valeur de controlQueueBufferThreshold permet à une seule orchestration ou entité de traiter des événements plus rapidement. Toutefois, l’augmentation de cette valeur peut également entraîner une utilisation de la mémoire plus élevée. Plus l’utilisation de la mémoire est importante, plus le nombre de messages dans la file d’attente est important, en partie en raison de la récupération d’un plus grand nombre d’historiques d’orchestration dans la mémoire. La réduction de la valeur de controlQueueBufferThreshold peut donc être un moyen efficace de réduire l’utilisation de la mémoire.
Interrogation de file d'attente
L’extension Tâche durable implémente un algorithme d’interruption exponentiel et aléatoire pour réduire l’effet de l’interrogation de file d’attente inactive sur les coûts de transactions de stockage. Lorsqu’un message est trouvé, le moteur d’exécution recherche immédiatement un autre message. Lorsqu’aucun message n’est trouvé, il attend un certain temps avant de réessayer. Après plusieurs échecs de tentatives d’obtention d’un message de file d’attente, le temps d’attente continue à augmenter jusqu’à ce qu’il atteigne le délai d’attente maximal par défaut (30 secondes).
Le délai maximal d’interrogation est configurable via la propriété maxQueuePollingInterval dans le fichier host.json. Une valeur plus élevée de cette propriété peut entraîner une plus grande latence lors du traitement des messages. Les latences plus élevées ne devraient survenir qu'après des périodes d'inactivité. Une valeur plus faible de cette propriété peut entraîner une augmentation des coûts de stockage en raison d’un nombre plus important de transactions de stockage.
Notes
Lorsqu’il est exécuté dans les plans Consommation et Premium d’Azure Functions, le contrôleur de mise à l'échelle Azure Functions interrogera chaque contrôle et chaque file d'attente des éléments de travail toutes les 10 secondes. Cette interrogation supplémentaire est nécessaire pour déterminer quand activer les instances d'application de fonction et pour prendre des décisions de mise à l'échelle. Au moment d’écrire ces lignes, cet intervalle de 10 secondes est constant et ne peut pas être configuré.
Retards de début de l’orchestration
Les instances d’orchestration sont démarrées en plaçant un message ExecutionStarted dans l’une des files d’attente de contrôle du hub de tâches. Dans certaines conditions, vous pouvez observer des délais de plusieurs secondes entre le moment où l’exécution d’une orchestration est planifiée et le moment où elle commence à s’exécuter. Pendant ce laps de temps, l’instance d’orchestration reste dans l’état Pending. Il existe deux causes possibles pour ce retard :
Files d’attente de contrôle en backlog : Si la file d’attente de contrôle de cette instance contient un grand nombre de messages, cela peut prendre du temps avant que le message
ExecutionStartedne soit reçu et traité par le runtime. Les backlogs de messages peuvent se produire lorsque des orchestrations traitent un grand nombre d’événements simultanément. Les événements qui se trouvent dans la file d’attente de contrôle incluent les événements de début d’orchestration, les saisies semi-automatiques d’activité, les minuteurs durables, l’achèvement et les événements externes. Si ce retard se produit dans des circonstances normales, envisagez de créer un hub de tâches avec un plus grand nombre de partitions. La configuration d’un plus grand nombre de partitions entraîne la création par le runtime d’autres files d’attente de contrôle pour la distribution de la charge. Chaque partition correspond à une relation de type 1:1 avec une file d’attente de contrôle et 16 partitions au maximum.Retards d’interrogation de secours : Une autre cause courante des retards d’orchestration est le comportement d’interrogation de secours précédemment décrit pour les files d’attente de contrôle. Toutefois, ce retard est attendu uniquement en cas de Scale-out d’une application sur plusieurs instances. S’il n’existe qu’une seule instance d’application ou si l’instance d’application qui démarre l’orchestration est également la même instance qui interroge la file d’attente de contrôle cible, il n’y aura pas de retard d’interrogation de la file d’attente. Les retards d’interrogation de secours peuvent être réduits en mettant à jour les paramètres host.json, comme décrit précédemment.
Objets blob
Dans la plupart des cas, Durable Functions n’utilise pas de blobs Stockage Azure pour conserver les données. Toutefois, les files d’attente et les tables ont des limites de taille qui peuvent empêcher Durable Functions de conserver toutes les données requises dans une ligne de stockage ou un message en file d’attente. Par exemple, lorsqu’une donnée devant être conservée dans une file d’attente est supérieure à 45 ko lorsqu’elle est sérialisée, Durable Functions compresse les données et les stocke dans un blob à la place. Lorsque des données persistantes sont ainsi stockées dans un blob, Durable Functions stocke une référence à ce blob dans la ligne de la table ou dans le message en file d’attente. Lorsque Durable Functions doit récupérer les données, il les récupère automatiquement à partir du blob. Ces blobs sont stockés dans le conteneur de blobs <taskhub>-largemessages.
Considérations relatives aux performances
Les étapes supplémentaires de compression et d’opération de blob pour les messages volumineux peuvent être coûteuses en termes de coûts de l’UC et de latence d’E/S. En outre, Durable Functions doit charger les données persistantes en mémoire et peut le faire pour de nombreuses exécutions de fonction différentes en même temps. En conséquence, la persistance des charges utiles de données volumineuses peut également entraîner une utilisation élevée de la mémoire. Pour réduire au minimum la surcharge de mémoire, envisagez de conserver les charges utiles de données volumineuses manuellement (par exemple, dans Stockage Blob) et de transmettre plutôt des références à ces données. De cette façon, votre code peut charger les données uniquement lorsque cela est nécessaire pour éviter les charges redondantes lors des relectures des fonctions d’orchestrateur. Toutefois, le stockage des charges utiles sur les disques locaux n’est pas recommandé, car la disponibilité de l’état sur disque n’est pas garantie, les fonctions pouvant s’exécuter sur différentes machines virtuelles tout au long de leur durée de vie.
Sélection du compte de stockage
Les files d’attente, les tables et les objets blob utilisés par Durable Functions sont créés dans un compte de stockage Azure configuré. Le compte à utiliser peut être spécifié à l’aide du paramètre durableTask/storageProvider/connectionStringName(ou du paramètre durableTask/azureStorageConnectionStringName dans Durable Functions 1.x) dans le fichier host.json.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
S’il n’est pas spécifié, le compte de stockage AzureWebJobsStorage par défaut est utilisé. Pour les charges de travail sensibles aux performances, il est toutefois recommandé de configurer un compte de stockage non défini par défaut. Fonctions durables utilise beaucoup le stockage Azure, et l’utilisation d’un compte de stockage dédié distingue l’usage du stockage Fonctions durables et l’usage interne par l’hôte Azure Functions.
Notes
Des comptes Stockage Azure standard à usage général sont requis lors de l’utilisation du fournisseur Stockage Azure. Tous les autres types de compte de stockage ne sont pas pris en charge. Nous vous recommandons vivement d’utiliser des comptes de stockage à usage général v1 hérités pour Durable Functions. Les comptes de stockage v2, plus récents, peuvent être beaucoup plus onéreux pour les charges de travail de Durable Functions. Pour plus d’informations sur les types de comptes de stockage Azure, consultez l’article Vue d’ensemble du compte de stockage.
Mise à l’échelle de l’orchestrateur
Bien qu’il soit possible d’effectuer un scale-out à l’infini des fonctions d’activité en ajoutant plus de machines virtuelles de manière élastique, chaque instance d’orchestrateur et entité est contrainte d’occuper une seule partition, et le nombre maximal de partitions est limité par le paramètre partitionCount dans votre host.json.
Notes
En règle générale, les fonctions d’orchestrateur sont conçues pour être légères et elles ne requièrent pas une grande puissance de calcul. Il n’est donc pas nécessaire de créer un grand nombre de partitions de file d’attente de contrôle pour obtenir un haut débit pour les orchestrations. Le travail lourd doit être principalement effectué dans les fonctions d’activité sans état, qui peuvent être mises à l’échelle à l’infini.
Le nombre de files d’attente de contrôle est défini dans le fichier host.json. L’exemple suivant d’extrait de code host.json définit la propriété durableTask/storageProvider/partitionCount (ou durableTask/partitionCountdans Durable Functions 1.x) sur 3. Notez qu’il existe autant de files d’attente de contrôle que de partitions.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Un hub de tâches peut être configuré avec 1 à 16 partitions. Si ce paramètre n’est pas spécifié, le nombre de partitions par défaut s’élève à 4.
Dans les scénarios à faible trafic, votre application fait l’objet d’un scale-in. Ainsi, les partitions sont gérées par un petit nombre de Workers. Prenons l’exemple du diagramme ci-dessous.
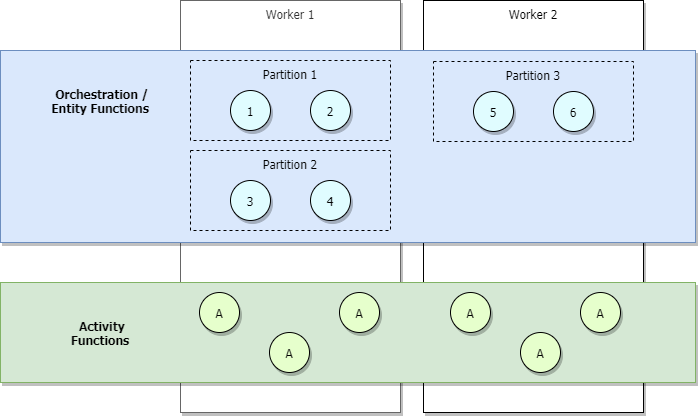
Dans le diagramme précédent, nous voyons que la charge des orchestrateurs 1 à 6 est équilibrée entre les partitions. De même, les partitions, tout comme les activités, font l’objet d’un équilibrage de charge entre les Workers. La charge des partitions est équilibrée entre les Workers, quel que soit le nombre d’orchestrateurs qui démarrent.
Si vous utilisez les plans Consommation ou Élastique Premium d’Azure Functions, ou si la mise à l’échelle automatique basée sur l’équilibrage de charge est configurée, davantage de Workers sont alloués au fur et à mesure que le trafic augmente, ce qui finit par entraîner un équilibrage de la charge entre tous les Workers. Si nous continuons le scale-out, chaque partition finit par être gérée par un seul Worker. En revanche, les activités continuent de faire l’objet d’un équilibrage de charge parmi tous les Workers. Cela est illustré dans l’image ci-dessous.
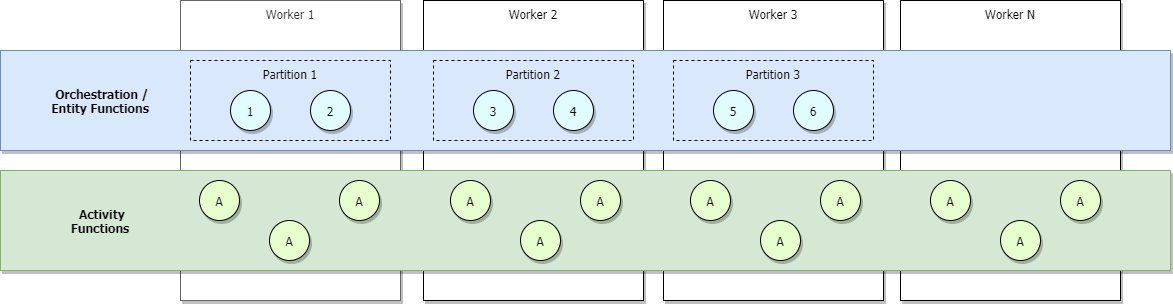
La limite supérieure du nombre maximal d’orchestrations actives simultanées à un moment donné est égale au nombre de Workers alloués à votre application multiplié par la valeur de maxConcurrentOrchestratorFunctions. Cette limite supérieure peut être rendue plus précise quand vos partitions font l’objet d’un scale-out complet parmi les Workers. Quand un scale-out complet est effectué et que chaque Worker n’a qu’une seule instance d’hôte Functions, le nombre maximal d’instances d’orchestrateur simultanées actives est égal au nombre de partitions multiplié par la valeur de maxConcurrentOrchestratorFunctions.
Notes
Dans ce contexte, active signifie qu’une orchestration ou une entité est chargée en mémoire et traite de nouveaux événements. Si l’orchestration ou l’entité attend un plus grand nombre d’événements, comme la valeur de retour d’une fonction d’activité, elle est déchargée de la mémoire et n’est plus considérée comme active. Les orchestrations et les entités sont ensuite rechargées dans la mémoire uniquement lorsqu’il y a de nouveaux événements à traiter. Il n’existe aucun nombre maximal pratique d’orchestrations ou d’entités totales pouvant être exécutées sur une seule machine virtuelle, même si elles sont toutes à l’état « En cours d’exécution ». La seule limitation est le nombre d’instances d’entité ou d’orchestration actives simultanément.
L’image ci-dessous illustre un scénario de scale-out complet où des orchestrateurs supplémentaires sont ajoutés. Certains d’entre eux sont inactifs, et sont représentés en gris.
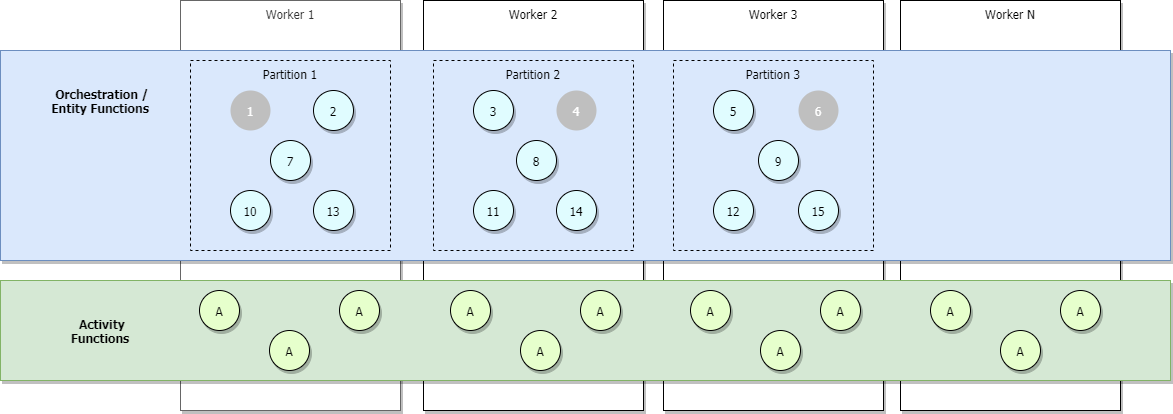
Durant le scale-out, des baux de file d’attente de contrôle peuvent être redistribués parmi les instances d’hôte Functions pour garantir une distribution uniforme des partitions. Ces baux sont implémentés de manière interne en tant que baux du service Stockage blob Azure. Ils permettent de garantir que chaque instance de l’orchestration ou entité s’exécute sur une seule instance d’hôte à la fois. Si un hub de tâches est configuré avec trois partitions (et donc trois files d’attente de contrôle), les instances de l’orchestration et les entités peuvent faire l’objet d’un équilibrage de charge sur les trois instances d’hôte détenant un bail. Il est possible d’ajouter des machines virtuelles supplémentaires pour augmenter la capacité d’exécution de la fonction d’activité.
Le diagramme suivant illustre la façon dont l’hôte Azure Functions interagit avec les entités de stockage dans un environnement mis à l’échelle.
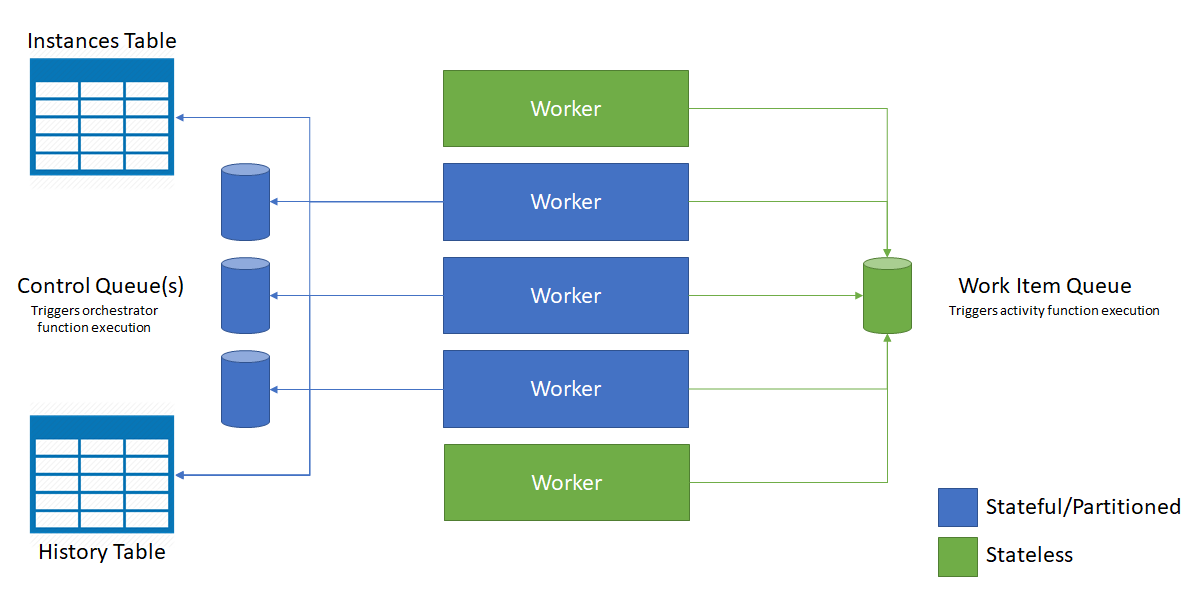
Comme indiqué dans le diagramme précédent, toutes les machines virtuelles sont en concurrence pour les messages de la file d’attente des éléments de travail. Toutefois, seules trois machines virtuelles peuvent acquérir les messages des files d’attente de contrôle, et chacune d’elles verrouille une file d’attente de contrôle.
Les instances d’orchestration et les entités sont réparties sur toutes les instances de file d’attente de contrôle. La répartition s’effectue par hachage de l’ID d’instance de l’orchestration ou de la paire nom/clé de l’entité. Les ID d’instance d’orchestration par défaut sont des GUID aléatoires, ce qui garantit la bonne répartition des instances sur toutes les files d’attente de contrôle.
En règle générale, les fonctions d’orchestrateur sont conçues pour être légères et elles ne requièrent pas une grande puissance de calcul. Il n’est donc pas nécessaire de créer un grand nombre de partitions de file d’attente de contrôle pour obtenir un haut débit pour les orchestrations. Le travail lourd doit être principalement effectué dans les fonctions d’activité sans état, qui peuvent être mises à l’échelle à l’infini.
Sessions étendues
Les sessions étendues sont un mécanisme de mise en cache qui maintient les orchestrations et les entités en mémoire même après qu'elles ont fini de traiter les messages. Généralement, l’activation des sessions étendues entraîne la baisse des E/S sur le magasin durable sous-jacent et un meilleur débit global.
Vous pouvez activer les sessions étendues en paramétrant durableTask/extendedSessionsEnabled sur true dans le fichier host.json. Le paramètre durableTask/extendedSessionIdleTimeoutInSeconds peut être utilisé pour contrôler la durée pendant laquelle une session inactive sera conservée en mémoire :
Functions 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Functions 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Ce paramètre présente deux inconvénients potentiels à connaître :
- Il y a une augmentation globale de l’utilisation de la mémoire de l’application de fonction, car les instances inactives ne sont pas déchargées de la mémoire aussi rapidement.
- Le débit peut diminuer globalement s’il existe plusieurs exécutions simultanées, distinctes et de courte durée de fonctions d’orchestrateur et d’entité.
Par exemple, si durableTask/extendedSessionIdleTimeoutInSeconds est défini sur 30 secondes, un épisode de fonction d’orchestrateur ou d’entité de courte durée qui s’exécute en moins de 1 seconde occupe tout de même la mémoire pendant 30 secondes. Il est également comptabilisé dans le quota durableTask/maxConcurrentOrchestratorFunctions mentionné précédemment et empêche potentiellement l’exécution d’autres fonctions d’orchestrateur ou d’entité.
Les effets spécifiques des sessions étendues sur les fonctions d’orchestrateur et d’entité sont décrits dans les sections suivantes.
Notes
Les sessions étendues ne sont actuellement prises en charge que dans les langages .NET, comme C# ou F#. La définition de extendedSessionsEnabled sur true pour d’autres plateformes peut entraîner des problèmes d’exécution, tels que l’exécution en mode silencieux de l’activité et des fonctions déclenchées par orchestration.
Relecture de la fonction d’orchestrateur
Comme mentionné précédemment, les fonctions d’orchestrateur sont relues à l’aide du contenu de la table d’historique. Par défaut, le code de fonction d’orchestrateur est relu chaque fois qu’un lot de messages est enlevé d’une file d’attente de contrôle. Même si vous utilisez le modèle fan-out/fan-in et vous attendez à ce que toutes les tâches soient terminées (par exemple, en utilisant Task.WhenAll() en .NET, context.df.Task.all() en JavaScript ou context.task_all() en Python), des relectures se produisent à mesure que des lots de réponses de tâche sont traités. Lorsque des sessions étendues sont activées, les instances de fonction d’orchestrateur sont conservées en mémoire plus longtemps et les nouveaux messages peuvent être traités sans une relecture complète de l’historique.
L’amélioration des performances des sessions étendues est le plus souvent observée dans les situations suivantes :
- Lorsqu’il existe un nombre limité d’instances d’orchestration s’exécutant simultanément.
- Lorsque des orchestrations ont un grand nombre d’actions séquentielles (par exemple, des centaines d’appels de fonction d’activité) qui se terminent rapidement.
- Lorsque des orchestrations exécutent une distribution ramifiée (fan-out) et un traitement de réponse parallèle (fan-in) sur un grand nombre d’actions qui se terminent à peu près au même moment.
- Lorsque des fonctions d’orchestrateur doivent traiter des messages volumineux ou effectuer un traitement de données gourmand en ressources UC.
Dans toutes les autres situations, il n’y a généralement pas d’amélioration notable des performances pour les fonctions d’orchestrateur.
Notes
Ces paramètres doivent être utilisés uniquement après le développement et le test complets d’une fonction d’orchestrateur. Le comportement de réexécution agressif par défaut peut être utile pour détecter les violations des contraintes du code de la fonction d’orchestrateur lors du développement, et est donc désactivé par défaut.
Cibles de performance
Le tableau suivant présente les nombres de débit maximal attendus pour les scénarios décrits dans la section Objectifs de performances de l’article Performances et mise à l’échelle .
Le terme « instance » fait référence à l’instance unique d’une fonction d’orchestrateur en cours d’exécution sur une petite machine virtuelle (A1) unique dans Azure App Service. Dans tous les cas, il est supposé que les sessions étendues sont activées. Les résultats réels peuvent varier selon le travail de l’UC ou des E/S effectué par le code de fonction.
| Scénario | Débit maximal |
|---|---|
| Exécution d’activité séquentielle | 5 activités par seconde et par instance |
| Exécution d’activité parallèle (fan-out) | 100 activités par seconde et par instance |
| Traitement de réponse parallèle (fan-in) | 150 réponses par seconde et par instance |
| Traitement d’événements externes | 50 événements par seconde et par instance |
| Traitement des opérations d’entité | 64 opérations par seconde |
Si vous n’obtenez pas les débits que vous attendiez et si l’utilisation de l’UC et de la mémoire semble correcte, vérifiez l’intégrité de votre compte de stockage. L’extension Fonctions durables peut placer une charge importante sur un compte de stockage Azure, et des charges suffisamment élevées peuvent entraîner la limitation du compte de stockage.
Conseil
Dans certains cas, vous pouvez augmenter considérablement le débit des événements externes, d’entrée d’activités et des opérations d’entité en augmentant la valeur du paramètre controlQueueBufferThreshold dans host.json. Si vous augmentez cette valeur au-delà de celle par défaut, le fournisseur de stockage de Durable Task Framework utilise davantage de mémoire pour prérécupérer ces événements de manière plus agressive, ce qui réduit les retards associés à la mise en file d’attente des messages des files d’attente de contrôle de Stockage Azure. Pour plus d’informations, consultez la documentation de référence host.json.
Traitement à haut débit
L’architecture principale de Stockage Azure impose certaines limitations sur les performances théoriques et l’extensibilité maximales de Durable Functions. Si votre test montre que Durable Functions sur Stockage Azure ne répond pas à vos besoins de débit, vous devez plutôt envisager d’utiliser le fournisseur de stockage Netherite pour Durable Functions.
Pour comparer le débit réalisable pour différents scénarios de base, consultez la section Scénarios de base de la documentation du fournisseur de stockage Netherite.
Le stockage principal Netherite a été conçu et développé par Microsoft Research. Il utilise Azure Event Hubs et la technologie de base de données FASTER en plus d’objets blob de pages Azure. La conception de Netherite permet un traitement à débit beaucoup plus élevé des orchestrations et des entités par rapport aux autres fournisseurs. Dans certains scénarios de test, le débit a augmenté d’un ordre de grandeur supérieur à celui du fournisseur Stockage Azure par défaut.
Pour plus d’informations sur les options de fournisseur de stockage prises en charge pour Durable Functions et leur comparaison, consultez la documentation sur les fournisseurs de stockage Durable Functions.