Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le déclencheur Azure SQL utilise la fonctionnalité Suivi des changements SQL pour monitorer les changements d’une table SQL, et déclencher une fonction quand une ligne est créée, mise à jour ou supprimée. Pour plus d’informations sur la configuration du suivi des changements à utiliser avec le déclencheur Azure SQL, consultez Configurer le suivi des changements. Pour plus d’informations sur les détails de configuration de l’extension Azure SQL pour Azure Functions, consultez la Vue d’ensemble de la liaison SQL.
Les décisions de mise à l’échelle du déclencheur Azure SQL pour les plans Consommation et Premium sont effectuées via la mise à l’échelle basée sur la cible. Pour plus d’informations, consultez la mise à l’échelle basée sur la cible et passez en revue les options d’hébergement Azure Functions.
Remarque
La prise en charge des plans consommation nécessite la version v3.1.284 ou ultérieure des liaisons Azure SQL pour Azure Functions.
Vue d’ensemble des fonctionnalités
La liaison de déclencheur Azure SQL utilise une boucle d’interrogation pour vérifier si des changements ont été apportés, ce qui déclenche la fonction utilisateur lorsque des changements sont détectés. À un niveau élevé, la boucle ressemble à cela :
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Les modifications sont traitées dans l’ordre dans lequel elles ont été apportées, les modifications les plus anciennes étant traitées en premier. Quelques remarques sur le processus de modification :
- Si les modifications apportées à plusieurs lignes sont effectuées à la fois l’ordre exact qu’ils sont envoyés à la fonction est basé sur l’ordre retourné par la fonction CHANGETABLE
- Les modifications sont « traitées par lots» pour une ligne. Si plusieurs modifications sont apportées à une ligne entre chaque itération de la boucle, il n’existe qu’une seule entrée de modification pour cette ligne qui présente la différence entre le dernier état traité et l’état actuel
- Si des modifications sont apportées à un ensemble de lignes, puis si un autre ensemble de modifications est apporté à la moitié de ces mêmes lignes, alors la moitié des lignes qui n’a pas été modifiée une deuxième fois est traitée en premier. Cette logique de traitement est due à la remarque ci-dessus sur les modifications par lots. Le déclencheur voit uniquement la « dernière » modification apportée et l’utilise pour gérer l’ordre dans lequel il les traite
Remarque
Le suivi des changements Azure SQL peut détecter des modifications au niveau des lignes dans les tables utilisant des technologies de chiffrement telles que Always Encrypted ou Transparent Data Encryption (TDE). Cependant, le déclencheur Azure SQL ne déchiffre pas et n’expose pas les valeurs de colonnes chiffrées dans la charge utile de changement. Le déclencheur peut détecter qu’un changement a eu lieu mais ne peut pas accéder aux données déchiffrées de ces colonnes.
Pour plus d’informations sur le suivi des modifications et la façon dont il est utilisé par des applications telles que les déclencheurs Azure SQL, consultez Utiliser le suivi des modifications.
Important
Pour une sécurité optimale, vous devez utiliser l’ID Microsoft Entra avec des identités managées pour les connexions entre Functions et Azure SQL Database. Les identités managées sécurisent votre application en éliminant les secrets de vos déploiements d’applications, tels que les informations d’identification dans les chaîne de connexion, les noms de serveur et les ports utilisés. Vous pouvez apprendre à utiliser des identités managées dans ce tutoriel, connecter une application de fonction à Azure SQL avec des liaisons d’identité managée et SQL.
Exemple d’utilisation
D’autres exemples du déclencheur Azure SQL sont disponibles dans le dépôt GitHub.
Les exemples font référence à une classe ToDoItem et à une table de base de données correspondante :
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Le suivi des changements est activé sur la base de données et sur la table :
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Le déclencheur SQL est lié à un IReadOnlyList<SqlChange<T>>, une liste d’objets SqlChange avec chacun deux propriétés :
-
Item : l’élément qui a changé. Le type de l’élément doit suivre le schéma de table de la classe
ToDoItem. -
Operation : valeur de l’enum
SqlChangeOperation. Les valeurs possibles sont :Insert,UpdateetDelete.
L’exemple suivant montre une fonction C# appelée en cas de changements sur la table ToDo :
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Exemple d’utilisation
D’autres exemples du déclencheur Azure SQL sont disponibles dans le dépôt GitHub.
L’exemple fait référence à une classe ToDoItem, à une table SqlChangeToDoItem, à un enum SqlChangeOperation et à une table de base de données correspondante :
Dans un fichier ToDoItem.java distinct :
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
Dans un fichier SqlChangeToDoItem.java distinct :
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
Dans un fichier SqlChangeOperation.java distinct :
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Le suivi des changements est activé sur la base de données et sur la table :
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Le déclencheur SQL est lié à un SqlChangeToDoItem[], un tableau d’objets SqlChangeToDoItem avec chacun deux propriétés :
-
item : élément qui a changé. Le type de l’élément doit suivre le schéma de table de la classe
ToDoItem. -
operation : valeur de l’enum
SqlChangeOperation. Les valeurs possibles sont :Insert,UpdateetDelete.
L’exemple suivant montre une fonction Java qui est appelée quand des changements sont apportés à la table ToDo :
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Exemple d’utilisation
D’autres exemples du déclencheur Azure SQL sont disponibles dans le dépôt GitHub.
L’exemple fait référence à une table de base de données ToDoItem :
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Le suivi des changements est activé sur la base de données et sur la table :
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Le déclencheur SQL est lié à todoChanges, une liste d’objets avec chacun deux propriétés :
- item : élément qui a changé. La structure de l’élément suit le schéma de la table.
-
operation : les valeurs possibles sont
Insert,UpdateetDelete.
L’exemple suivant montre une fonction PowerShell qui est appelée quand des changements sont apportés à la table ToDo.
L’exemple suivant montre une liaison de données dans le fichier function.json :
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
La section configuration décrit ces propriétés.
Voici un exemple de code PowerShell pour la fonction dans le fichier run.ps1 :
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Exemple d’utilisation
D’autres exemples du déclencheur Azure SQL sont disponibles dans le dépôt GitHub.
L’exemple fait référence à une table de base de données ToDoItem :
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Le suivi des changements est activé sur la base de données et sur la table :
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Le déclencheur SQL est lié à un todoChanges, un tableau d’objets avec chacun deux propriétés :
- item : élément qui a changé. La structure de l’élément suit le schéma de la table.
-
operation : les valeurs possibles sont
Insert,UpdateetDelete.
L’exemple suivant montre une fonction JavaScript qui est appelée quand des changements sont apportés à la table ToDo.
L’exemple suivant montre une liaison de données dans le fichier function.json :
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
La section configuration décrit ces propriétés.
Voici un exemple de code JavaScript pour la fonction dans le fichier index.js :
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Exemple d’utilisation
D’autres exemples du déclencheur Azure SQL sont disponibles dans le dépôt GitHub.
L’exemple fait référence à une table de base de données ToDoItem :
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
Le suivi des changements est activé sur la base de données et sur la table :
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
Le déclencheur SQL est lié à un todoChanges variable, une liste d’objets avec chacun deux propriétés :
- item : élément qui a changé. La structure de l’élément suit le schéma de la table.
-
operation : les valeurs possibles sont
Insert,UpdateetDelete.
L’exemple suivant montre une fonction Python qui est appelée quand des changements sont apportés à la table ToDo.
Voici un exemple de code Python pour le fichier function_app.py :
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Attributs
La bibliothèque C# utilise l’attribut SqlTrigger pour déclarer le déclencheur SQL sur la fonction, qui a les propriétés suivantes :
| Propriété d’attribut | Descriptif |
|---|---|
| Nom_de_table | Obligatoire. Nom de la table monitorée par le déclencheur. |
| ConnectionStringSetting | Obligatoire. Nom d’un paramètre d’application qui contient la chaîne de connexion de la base de données contenant la table monitorée en raison des modifications. Le nom du paramètre de la chaîne de connexion correspond au paramètre d’application (dans local.settings.json pour le développement local) qui contient la chaîne de connexion à l’instance SQL ou Azure SQL. |
| LeasesTableName | Optionnel. Nom de la table utilisée pour stocker les baux. S'il n'est pas spécifié, le nom de la table des baux sera Leases_{FunctionId}_{TableId}. Plus d'informations sur la façon dont cela est généré peuvent être trouvées ici. |
Commentaires
Dans la bibliothèque du runtime des fonctions Java, utilisez l’annotation @SQLTrigger (com.microsoft.azure.functions.sql.annotation.SQLTrigger) sur les paramètres dont la valeur proviendrait d’Azure SQL. Cette annotation prend en charge les éléments suivants :
| Élément | Descriptif |
|---|---|
| nom | Obligatoire. Nom du paramètre auquel le déclencheur est lié. |
| tableName | Obligatoire. Nom de la table monitorée par le déclencheur. |
| connectionStringSetting | Obligatoire. Nom d’un paramètre d’application qui contient la chaîne de connexion de la base de données contenant la table monitorée en raison des modifications. Le nom du paramètre de la chaîne de connexion correspond au paramètre d’application (dans local.settings.json pour le développement local) qui contient la chaîne de connexion à l’instance SQL ou Azure SQL. |
| LeasesTableName | Optionnel. Nom de la table utilisée pour stocker les baux. S'il n'est pas spécifié, le nom de la table des baux sera Leases_{FunctionId}_{TableId}. Plus d'informations sur la façon dont cela est généré peuvent être trouvées ici. |
Paramétrage
Le tableau suivant décrit les propriétés de configuration de liaison que vous définissez dans le fichier function.json.
| Propriété function.json | Descriptif |
|---|---|
| nom | Obligatoire. Nom du paramètre auquel le déclencheur est lié. |
| type | Obligatoire. Cette propriété doit être définie sur sqlTrigger. |
| direction | Obligatoire. Cette propriété doit être définie sur in. |
| tableName | Obligatoire. Nom de la table monitorée par le déclencheur. |
| connectionStringSetting | Obligatoire. Nom d’un paramètre d’application qui contient la chaîne de connexion de la base de données contenant la table monitorée en raison des modifications. Le nom du paramètre de la chaîne de connexion correspond au paramètre d’application (dans local.settings.json pour le développement local) qui contient la chaîne de connexion à l’instance SQL ou Azure SQL. |
| LeasesTableName | Optionnel. Nom de la table utilisée pour stocker les baux. S'il n'est pas spécifié, le nom de la table des baux sera Leases_{FunctionId}_{TableId}. Plus d'informations sur la façon dont cela est généré peuvent être trouvées ici. |
Configuration facultative
Les paramètres facultatifs suivants peuvent être configurés pour le déclencheur SQL pour le développement local ou pour les déploiements cloud.
host.json
Cette section décrit les paramètres de configuration disponibles pour cette liaison dans la version 2.x et les versions ultérieures. Les paramètres dans le fichier host.json s’appliquent à toutes les fonctions dans une instance de l’application de fonction. Pour plus d’informations sur les paramètres de configuration des applications de fonction, consultez host.json référence pour Azure Functions.
| Réglage | Par défaut | Descriptif |
|---|---|---|
| MaxBatchSize | 100 | Nombre maximal de modifications traitées à chaque itération de la boucle du déclencheur avant d’être envoyées à la fonction déclenchée. |
| PollingIntervalMs | 1 000 | Délai en millisecondes entre le traitement de chaque lot de changements. (1 000 ms est de 1 seconde) |
| MaxChangesPerWorker | 1 000 | Limite supérieure du nombre de changements en attente dans la table utilisateur autorisés pour chaque worker d’application. Si le nombre de modifications dépasse cette limite, cela peut entraîner un scale-out. Le paramètre s’applique uniquement aux applications de fonction Azure avec la mise à l’échelle pilotée par le runtime activée. |
Exemple de fichier host.json
Voici un exemple de fichier host.json avec les paramètres facultatifs :
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
Le fichier local.settings.json stocke des paramètres d’application et des paramètres utilisés par des outils de développement locaux. Les paramètres dans le fichier local.settings.json sont uniquement utilisés lorsque vous exécutez votre projet localement. Lorsque vous publiez votre projet sur Azure, veillez également à ajouter tous les paramètres requis aux paramètres de l’application pour l’application de fonction.
Important
Étant donné que le fichier local.settings.json peut contenir des secrets, comme des chaînes de connexion, vous ne devez jamais le stocker dans un référentiel à distance. Les outils qui prennent en charge Functions permettent de synchroniser les paramètres du fichier local.settings.json avec les paramètres d’application dans l’application de fonction où votre projet est déployé.
| Réglage | Par défaut | Descriptif |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | Nombre maximal de modifications traitées à chaque itération de la boucle du déclencheur avant d’être envoyées à la fonction déclenchée. |
| Sql_Trigger_PollingIntervalMs | 1 000 | Délai en millisecondes entre le traitement de chaque lot de changements. (1 000 ms est de 1 seconde) |
| Sql_Trigger_MaxChangesPerWorker | 1 000 | Limite supérieure du nombre de changements en attente dans la table utilisateur autorisés pour chaque worker d’application. Si le nombre de modifications dépasse cette limite, cela peut entraîner un scale-out. Le paramètre s’applique uniquement aux applications de fonction Azure avec la mise à l’échelle pilotée par le runtime activée. |
Exemple de fichier local.settings.json
Voici un exemple de fichier local.settings.json avec les paramètres facultatifs :
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Configurer le suivi des changements (obligatoire)
La configuration du suivi des changements à utiliser avec le déclencheur Azure SQL nécessite deux étapes. Ces étapes peuvent être effectuées à partir de n’importe quel outil SQL prenant en charge l’exécution de requêtes, notamment Visual Studio Code ou SQL Server Management Studio.
Activez le suivi des changements sur la base de données SQL, en remplaçant
your database namepar le nom de la base de données où se trouve la table à monitorer :ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);L’option
CHANGE_RETENTIONindique la période de conservation des informations de suivi des changements (historique des changements). La conservation de l’historique des changements par la base de données SQL pourrait affecter la fonctionnalité du déclencheur. Par exemple, si la fonction Azure est désactivée pendant plusieurs jours, puis reprise, la base de données contiendra les changements qui se sont produits au cours des deux derniers jours dans l’exemple de configuration ci-dessus.L’option
AUTO_CLEANUPest utilisée pour activer ou désactiver la tâche de nettoyage qui supprime les anciennes informations de suivi des changements. Si un problème temporaire empêche l’exécution du déclencheur, la désactivation du nettoyage automatique peut être utile pour mettre en pause la suppression des informations antérieures à la période de conservation jusqu’à ce que le problème soit résolu.Plus d’informations sur les options de suivi des changements sont disponibles dans ladocumentation SQL.
Activez le suivi des changements sur la table, en remplaçant
your table namepar le nom de la table à monitorer (et en changeant le schéma le cas échéant) :ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;Le déclencheur doit avoir un accès en lecture sur la table dont les changements sont monitorés et sur les tables système de suivi des changements. Chaque déclencheur de fonction a une table de suivi des modifications associée et loue une table dans un schéma
az_func. Ces tables sont créées par le déclencheur si elles n’existent pas. Plus d’informations sur ces structures de données sont disponibles dans la documentation de la bibliothèque de liaisons Azure SQL.
Activer la mise à l’échelle pilotée par le runtime
Éventuellement, vos fonctions peuvent être mises à l’échelle automatiquement en fonction du nombre de modifications en attente de traitement dans la table utilisateur. Pour permettre à vos fonctions de se mettre à l’échelle correctement sur le plan Premium en cas d’utilisation de déclencheurs SQL, vous devez activer le monitoring de l’échelle du runtime.
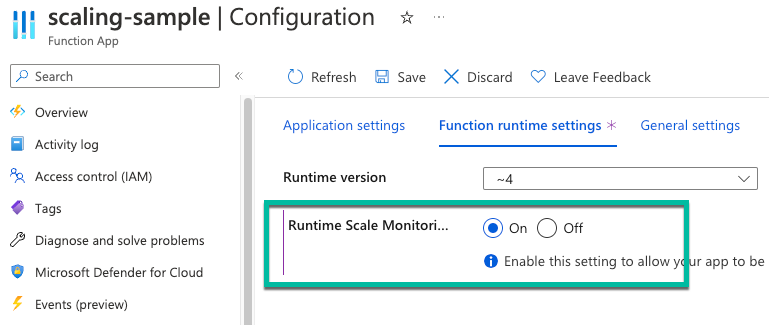
Dans le portail Azure, dans votre application de fonction, sélectionnez Configuration.
Sous l’onglet Paramètres du runtime de fonction , pour l’analyse de l’échelle du runtime, sélectionnez Activé.
Prise en charge des nouvelles tentatives
Des informations supplémentaires sur la prise en charge des nouvelles tentatives du déclencheur SQL et les tables de baux sont disponibles dans le référentiel GitHub.
Nouvelles tentatives de démarrage
Si une exception se produit au démarrage, le runtime hôte tente automatiquement de redémarrer l’écouteur du déclencheur avec une stratégie de backoff exponentiel. Ces nouvelles tentatives se poursuivent jusqu’à ce que l’écouteur soit correctement démarré ou que le démarrage soit annulé.
Nouvelles tentatives de connexion interrompues
Si la fonction démarre correctement, mais qu’une erreur provoque l’arrêt de la connexion (par exemple, le serveur se met hors connexion), la fonction continue d’essayer d’ouvrir la connexion jusqu’à ce que la fonction soit arrêtée ou que la connexion aboutisse. Si la connexion est rétablie avec succès, elle récupère les modifications de traitement là où elle s’est arrêtée.
Notez que ces nouvelles tentatives sont en dehors de la logique de nouvelle tentative de connexion intégrée que SqlClient peut être configurée avec les ConnectRetryCount options et ConnectRetryIntervalchaîne de connexion. Les nouvelles tentatives de connexion inactif intégrées sont d’abord tentées et si celles-ci ne parviennent pas à se reconnecter, alors la liaison de déclencheur tente de rétablir la connexion elle-même.
Nouvelles tentatives d’exception de fonction
Si une exception se produit dans la fonction utilisateur lors du traitement des modifications, alors le lot de lignes en cours de traitement est retenté dans 60 secondes. D’autres modifications sont traitées normalement pendant cette période, mais les lignes du lot à l’origine de l’exception sont ignorées jusqu’à ce que le délai d’expiration se soit écoulé.
Si l’exécution de la fonction échoue cinq fois dans une ligne pour une ligne donnée, alors cette ligne est complètement ignorée pour toutes les modifications futures. Étant donné que les lignes d’un lot ne sont pas déterministes, les lignes d’un lot ayant échoué peuvent se retrouver dans des lots différents dans les appels suivants. Cela signifie que toutes les lignes du lot ayant échoué ne seront pas nécessairement ignorées. Si d’autres lignes dans le lot étaient celles à l’origine de l’exception, les « bonnes » lignes pourraient se retrouver dans un autre lot qui n’échoue pas dans les appels futurs.