Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les notebooks sont des environnements intégrés qui vous permettent de créer et de partager des documents avec du code en direct, des équations, des visualisations et du texte. L’intégration d’un notebook à un espace de travail Log Analytics vous permet de créer un processus en plusieurs étapes qui exécute du code à chaque étape en fonction des résultats de l’étape précédente. Vous pouvez utiliser ces processus simplifiés pour créer des pipelines Machine Learning, des outils d’analyse avancés, des guides de résolution des problèmes (TSG) pour les besoins de support, et bien plus encore.
L’intégration d’un notebook à un espace de travail Log Analytics vous permet également :
- D’exécuter des requêtes KQL et du code personnalisé dans n’importe quel langage.
- D’introduire de nouvelles fonctionnalités d’analytique et de visualisation, telles que de nouveaux modèles Machine Learning, des chronologies personnalisées et des arborescences de processus.
- D’intégrer des jeux de données en dehors des journaux Azure Monitor, tels qu’un ensemble de données local.
- De tirer parti des limites de service accrues à l’aide des limites de l’API de requête par rapport à la Portail Azure.
Dans ce tutoriel, vous allez apprendre à :
- D’intégrer un notebook à votre espace de travail Log Analytics à l’aide de la bibliothèque cliente de requête Azure Monitor et de la bibliothèque cliente Azure Identity
- D’explorer et visualiser les données de votre espace de travail Log Analytics dans un notebook
- D’ingérer des données de votre notebook dans une table personnalisée dans votre espace de travail Log Analytics (facultatif)
Pour obtenir un exemple de construction d’une pipeline Machine Learning pour analyser des données dans les journaux Azure Monitor à l’aide d’un notebook, consultez cet exemple de notebook : Détecter des anomalies dans les journaux Azure Monitor à l’aide de techniques d’apprentissage automatique.
Conseil
Pour contourner les limitations liées à l’API, fractionnez les requêtes plus volumineuses en plusieurs requêtes plus petites.
Prérequis
Pour ce didacticiel, vous avez besoin des éléments suivants :
Un espace de travail Azure Machine Learning avec une instance de calcul de processeur avec :
- Un notebook.
- Noyau défini sur Python 3.8 ou version ultérieure.
Les rôles et autorisations suivants :
Dans les journaux Azure Monitor : rôle Contributeur Logs Analytics pour lire et envoyer des données à votre espace de travail Logs Analytics. Pour plus d’informations, consultez Gérer l’accès aux espaces de travail Log Analytics.
Dans Azure Machine Learning :
- Rôle de propriétaire ou de contributeur au niveau du groupe de ressources, pour créer un espace de travail Azure Machine Learning si nécessaire.
- Rôle de contributeur sur l’espace de travail Azure Machine Learning dans lequel vous exécutez votre notebook.
Pour plus d’informations, consultez Gérer l’accès à un espace de travail Azure Machine Learning.
Outils et notebooks
Dans ce tutoriel, vous utilisez les outils suivants :
| Outil | Descriptif |
|---|---|
| Bibliothèque cliente de requête Azure Monitor | Vous permet d’exécuter des requêtes en lecture seule sur des données dans les journaux Azure Monitor. |
| Bibliothèque cliente Azure Identity | Permet aux clients SDK Azure de s’authentifier avec auprès de Microsoft Entra ID. |
| Bibliothèque cliente d’ingestion Azure Monitor | Vous permet d’envoyer des journaux personnalisés à Azure Monitor à l’aide de l’API Ingestion des journaux. Obligatoire pour ingérer des données analysées dans une table personnalisée dans votre espace de travail Log Analytics (facultatif) |
| Règle de collecte de données, point de terminaison de collecte de données et application inscrite | Obligatoire pour ingérer des données analysées dans une table personnalisée dans votre espace de travail Log Analytics (facultatif) |
Voici d’autres bibliothèques de requêtes que vous pouvez utiliser :
- La bibliothèque Kqlmagic vous permet d’exécuter des requêtes KQL directement à l’intérieur d’un notebook de la même façon que vous exécutez des requêtes KQL à partir de l’outil Log Analytics.
- La bibliothèque MSTICPY fournit des requêtes basées sur des modèles qui appellent des fonctionnalités intégrées de série chronologique et de Machine Learning KQL, et fournit des outils de visualisation avancés et des analyses de données dans l’espace de travail Log Analytics.
D’autres expériences de notebooks Microsoft pour l’analyse avancée sont les suivantes :
1. Intégrer votre espace de travail Log Analytics à votre notebook
Configurez votre notebook pour interroger votre espace de travail Log Analytics :
Installez les bibliothèques clientes Azure Monitor Query, Azure Identity et Azure Monitor Ingestion, ainsi que la bibliothèque d’analyse des données Pandas et la bibliothèque de visualisation Plotly :
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotlyDéfinissez la variable
LOGS_WORKSPACE_IDci-dessous sur l’ID de votre espace de travail Log Analytics. La variable est actuellement définie pour utiliser l’espace de travail de démonstration Azure Monitor, que vous pouvez utiliser pour faire la démonstration du notebook.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"LogsQueryClientConfigurez pour authentifier et interroger les journaux Azure Monitor.Ce code est configuré pour l’authentification
LogsQueryClientà l’aide deDefaultAzureCredential:from azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)LogsQueryClientprend généralement en charge l’authentification avec les informations d’identification du jeton Microsoft Entra. Toutefois, nous pouvons passer une stratégie d’authentification personnalisée pour activer l’utilisation des clés API. Cela permet au client d’interroger l’espace de travail de démonstration. La disponibilité et l’accès à cet espace de travail de démonstration sont susceptibles de changer. Nous vous recommandons donc d’utiliser votre propre espace de travail Log Analytics.Définissez une fonction d’assistance, appelée
query_logs_workspace, pour exécuter une requête donnée dans l’espace de travail Log Analytics et retourner les résultats sous la forme d’un DataFrame Pandas.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Explorer et visualiser les données de votre espace de travail Log Analytics dans votre notebook
Examinons certaines données de l’espace de travail en exécutant une requête à partir du notebook :
Cette requête vérifie la quantité de données (en mégaoctets) que vous avez ingérées dans chacune des tables (types de données) de votre espace de travail Log Analytics chaque heure au cours de la semaine écoulée :
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)Le DataFrame résultant montre l’ingestion horaire dans chacune des tables de l’espace de travail Log Analytics :
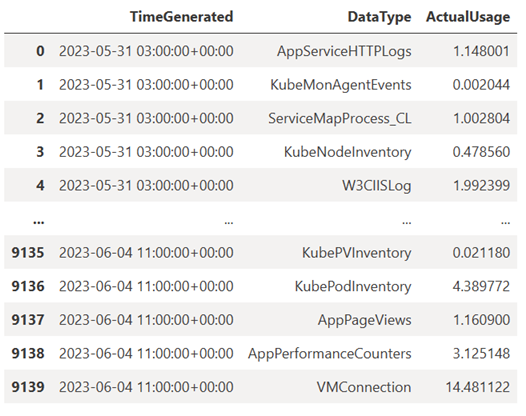
Maintenant, nous allons voir les données sous forme d’un graphique qui montre l’utilisation horaire de différents types de données au fil du temps, en fonction du DataFrame Pandas :
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()Le graphique résultant se présente comme suit :
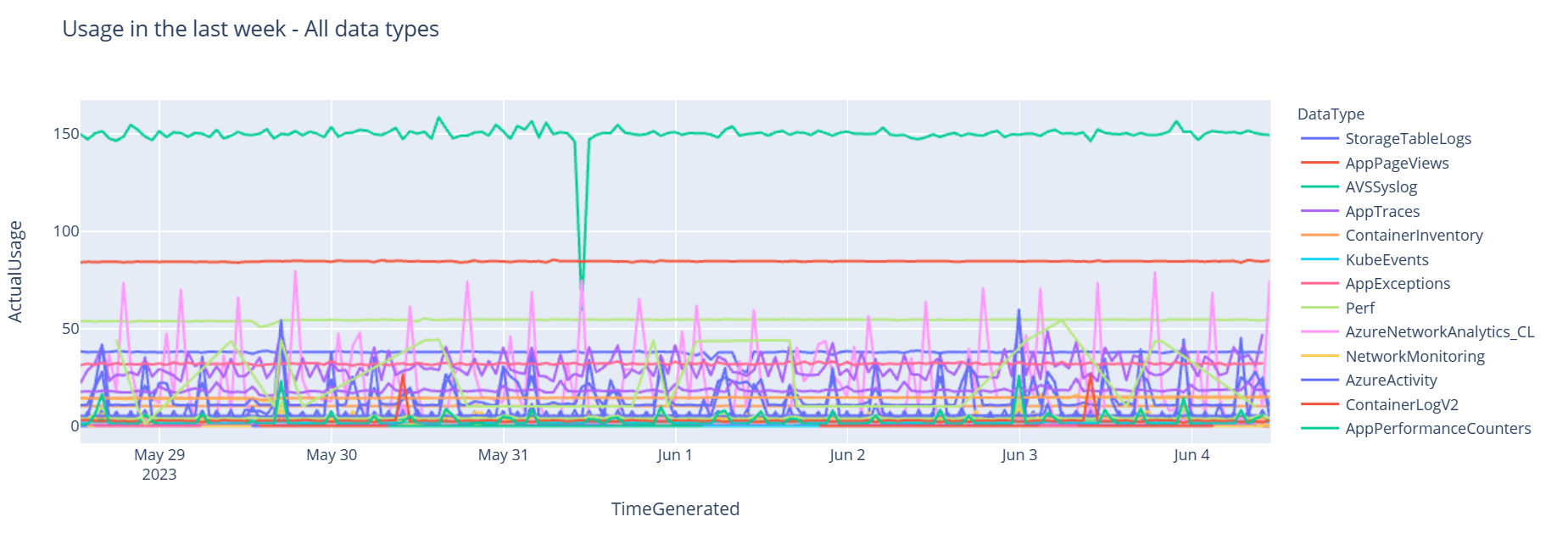
Vous avez interrogé et visualisé les données de journal à partir de votre espace de travail Log Analytics dans votre notebook.

3. Analyser des données
Par exemple, prenons les cinq premières lignes :
analyzed_df = df.head(5)
Pour obtenir un exemple de mise en œuvre de techniques de Machine Learning pour analyser des données dans les journaux Azure Monitor, consultez cet exemple de notebook : Détecter des anomalies dans les journaux Azure Monitor à l’aide de techniques d’apprentissage automatique.
4. Ingérer des données analysées dans une table personnalisée dans votre espace de travail Log Analytics (facultatif)
Envoyez vos résultats d’analyse à une table personnalisée dans votre espace de travail Log Analytics pour déclencher des alertes ou les rendre disponibles pour une analyse plus approfondie.
Pour envoyer des données à votre espace de travail Log Analytics, vous avez besoin d’une table personnalisée, d’un point de terminaison de collecte de données, d’une règle de collecte de données et d’une application Microsoft Entra inscrite avec l’autorisation d’utiliser la règle de collecte de données, comme expliqué dans Tutoriel : envoyer des données aux journaux Azure Monitor avec l’API d’ingestion des journaux (Portail Azure).
Lorsque vous créez votre table personnalisée :
Chargez cet exemple de fichier pour définir le schéma de table :
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
Définissez les constantes dont vous avez besoin pour l’API d’ingestion des journaux :
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comIngérer les données dans la table personnalisée de votre espace de travail Log Analytics :
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")Notes
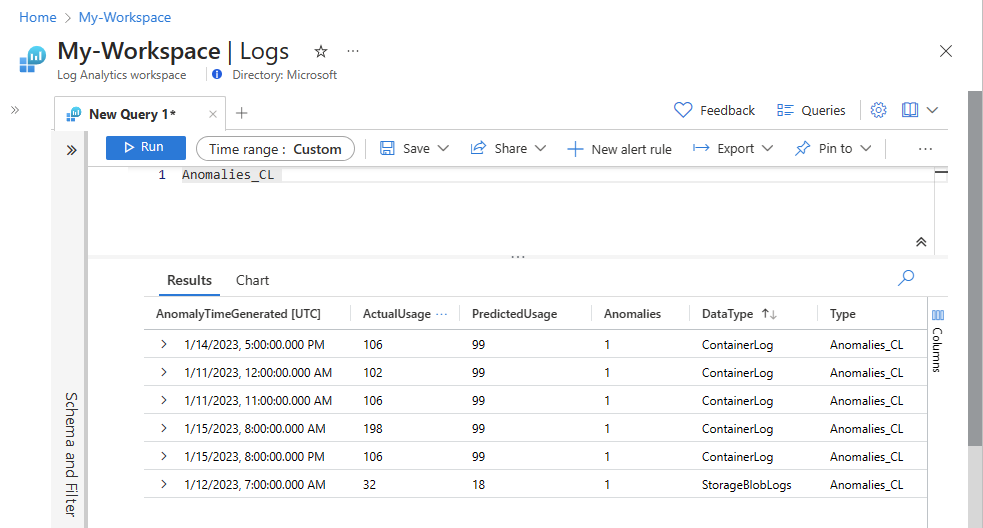
Lorsque vous créez une table dans votre espace de travail Log Analytics, l’affichage des données ingérées dans la table peut prendre jusqu’à 15 minutes.
Vérifiez que les données apparaissent maintenant dans votre table personnalisée.

Étapes suivantes
Pour en savoir plus sur les opérations suivantes :