Comprendre les longueurs de chemin dans Azure NetApp Files
La longueur de fichier et de chemin fait référence au nombre de caractères Unicode dans un chemin de fichier, y compris les répertoires. Cette limite est prise en compte dans les longueurs de caractères individuels, qui sont déterminées par la taille du caractère en octets. Par exemple, NFS et SMB autorisent les composants de chemin de 255 octets. Le format d’encodage de fichier d’ASCII utilise un encodage 8 bits, ce qui signifie que les composants de chemin de fichier (par exemple, un nom de fichier ou de dossier) dans ASCII peuvent comporter jusqu’à 255 caractères, puisque les caractères ASCII ont une taille de 1 octet.
Le tableau suivant présente les longueurs de composant et de chemin prises en charge dans les volumes Azure NetApp Files :
| Composant | NFS | SMB |
|---|---|---|
| Taille de composant de chemin | 255 octets | 255 octets |
| Taille de longueur de chemin | Illimité | Valeur par défaut : 255 octets Maximum dans les versions ultérieures de Windows : 32 767 octets |
| Taille maximale de chemin pour une transversale | 4 096 octets | 255 octets |
Remarque
Les volumes à deux protocoles utilisent la valeur maximale la plus faible.
Si un nom de partage SMB est \\SMB-SHARE, le nom de partage ajoute 11 caractères Unicode à la longueur du chemin, car chaque caractère a une taille de 1 octet. Si le chemin d’accès à un fichier spécifique est \\SMB-SHARE\apps\archive\file, il s’agit de 29 caractères Unicode ; chaque caractère, y compris les barres obliques, a une taille de 1 octet. Pour les montages NFS, les mêmes concepts s’appliquent. Le chemin de montage /AzureNetAppFiles est de 17 caractères Unicode de 1 octet chacun.
Azure NetApp Files prend en charge la même longueur de chemin pour les partages SMB que les serveurs Windows modernes prennent en charge : jusqu’à 32 767 octets. Toutefois, selon la version du client Windows, certaines applications ne peuvent pas prendre en charge les chemins de plus de 260 octets. Les composants de chemin individuels (les valeurs entre les barres obliques, telles que les noms de fichier ou de dossier) prennent en charge jusqu’à 255 octets. Par exemple, un nom de fichier utilisant la lettre A majuscule latine (qui occupe 1 octet par caractère) dans un chemin de fichier dans Azure NetApp Files ne peut pas dépasser 255 caractères.
# mkdir 256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
mkdir: cannot create directory ‘256charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa’: File name too long
# mkdir 255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# ls | grep 255
255charsaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Distinction des tailles de caractères
L’utilitaire Linux uniutils peut être utilisé pour rechercher la taille d’octet des caractères Unicode en tapant plusieurs instances de l’instance de caractère et en affichant le champ octets.
Exemple 1 : La lettre A majuscule latine est incrémentée de 1 octet chaque fois qu’elle est utilisée (à l’aide d’une seule valeur hexadécimale de 41, qui se trouve dans la plage 0-255 de caractères ASCII).
# printf %b 'AAA' | uniname
character byte UTF-32 encoded as glyph name
0 0 000041 41 A LATIN CAPITAL LETTER A
1 1 000041 41 A LATIN CAPITAL LETTER A
2 2 000041 41 A LATIN CAPITAL LETTER A
Résultat 1 : Le nom AAA utilise 3 octets sur 255.
Exemple 2 : Le caractère japonais 字 incrémente 3 octets par instance. Cela peut également être calculé par les 3 valeurs de code hexadécimales distinctes (E5, AD, 97) sous le champ encodé en tant que. Chaque valeur hexadécimale représente 1 octet :
# printf %b '字字字' | uniname
character byte UTF-32 encoded as glyph name
0 0 005B57 E5 AD 97 字 CJK character Nelson 1281
1 3 005B57 E5 AD 97 字 CJK character Nelson 1281
2 6 005B57 E5 AD 97 字 CJK character Nelson 1281
Résultat 2 : Un fichier nommé 字字字 utilise 9 octets sur 255.
Exemple 3 : La lettre Ä avec tréma utilise 2 octets par instance (C3 + 84).
# printf %b 'ÄÄÄ' | uniname
character byte UTF-32 encoded as glyph name
0 0 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
1 2 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
2 4 0000C4 C3 84 Ä LATIN CAPITAL LETTER A WITH DIAERESIS
Résultat 3 : Un fichier nommé ÄÄÄ utilise 6 octets sur 255.
Exemple 4 : Un caractère spécial, tel que l’emoji 😃, se situe dans une plage non définie qui dépasse les 0 à 3 octets utilisés pour les caractères Unicode. Par conséquent, il utilise une paire de substitution pour son encodage de caractères. Dans ce cas, chaque instance du caractère utilise 4 octets.
# printf %b '😃😃😃' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F603 F0 9F 98 83 😃 Character in undefined range
1 4 01F603 F0 9F 98 83 😃 Character in undefined range
2 8 01F603 F0 9F 98 83 😃 Character in undefined range
Résultat 4 : Un fichier nommé 😃😃😃 utilise 12 octets sur 255.
La plupart des emojis se situent dans la plage de 4 octets, mais peuvent atteindre 7 octets. Parmi plus d’un millier d’emojis standard, environ 180 figurent dans le plan multilingue de base (BMP), ce qui signifie qu’ils peuvent être affichés comme texte ou emoji dans Azure NetApp Files, en fonction de la prise en charge du type de langue par le client.
Pour plus d’informations sur le plan BMP et d’autres plans Unicode, consultez Comprendre les langages de volume dans Azure NetApp Files.
Impact de l’octet de caractère sur les longueurs de chemin
Bien qu’une longueur de chemin soit considérée comme le nombre de caractères d’un nom de fichier ou de dossier, il s’agit en fait de la taille des octets pris en charge dans le chemin. Étant donné que chaque caractère ajoute une taille d’octet à un nom, différents jeux de caractères dans différentes langues prennent en charge différentes longueurs de nom de fichier.
Examinez les scénarios suivants :
Un fichier ou un dossier répète le caractère d’alphabet latin A pour son nom de fichier. (par exemple, AAAAAAAA)
Comme A utilise 1 octet et que 255 octets est la limite de taille du composant de chemin, 255 instances de A sont autorisées dans un nom de fichier.
Un fichier ou dossier répète le caractère japonais 字 dans son nom.
Étant donné que 字 a une taille de 3 octets, la limite de longueur du nom de fichier est de 85 instances de 字 (3 octets * 85 = 255 octets) ou un total de 85 caractères.
Un fichier ou dossier répète l’emoji de visage très souriant (😃) dans son nom.
Un emoji de visage très souriant (😃) utilise 4 octets, ce qui signifie qu’un nom de fichier avec uniquement cet emoji permettrait un total de 64 caractères (255 octets/4 octets).
- Un fichier ou un dossier utilise une combinaison de caractères différents (autrement dit, Name字😃).
Lorsque des caractères différents avec des tailles d’octets différentes sont utilisés dans un nom de fichier ou de dossier, la taille d’octet de chaque caractère est prise en compte dans la longueur du fichier ou du dossier. Le nom de fichier ou de dossier Name字😃 utiliserait 1+1+1+1+3+4 octets (11 octets) de la longueur totale de 255 octets.
Concepts d’emojis spéciaux
Des emojis spéciaux, tels qu’un emoji drapeau, existent sous la classification BMP : l’emoji s’affiche sous forme de texte ou d’image en fonction de la prise en charge du client. Lorsqu’un client ne prend pas en charge la désignation d’image, il utilise plutôt des désignations textuelles régionales.
Par exemple, le drapeau États-Unis utilise les caractères « us » (qui ressemblent aux caractères latins U+S, mais sont en fait des caractères spéciaux qui utilisent des encodages différents). Uniname affiche les différences entre les caractères.
# printf %b 'US' | uniname
character byte UTF-32 encoded as glyph name
0 0 000055 55 U LATIN CAPITAL LETTER U
1 1 000053 53 S LATIN CAPITAL LETTER S
# printf %b '🇺🇸' | uniname
character byte UTF-32 encoded as glyph name
0 0 01F1FA F0 9F 87 BA 🇺 Character in undefined range
1 4 01F1F8 F0 9F 87 B8 🇸 Character in undefined range
Les caractères désignés pour les emojis drapeaux se traduisent par des images de drapeaux dans les systèmes pris en charge, mais restent en tant que valeurs de texte dans les systèmes non pris en charge. Ces caractères utilisent 4 octets par caractère pour un total de 8 octets lorsqu’un emoji drapeau est utilisé. Par conséquent, un total de 31 emojis drapeaux sont autorisés dans un nom de fichier (255 octets/8 octets).
Limites de chemin SMB
Par défaut, les serveurs Windows et les clients prennent en charge les longueurs de chemin jusqu’à 260 octets, mais les longueurs de chemin de fichier réelles sont plus courtes en raison des métadonnées ajoutées aux chemins Windows tels que la valeur <NUL> et les informations de domaine.
Lorsqu’une limite de chemin est dépassée dans Windows, une boîte de dialogue s’affiche :
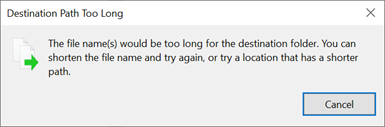
Les longueurs de chemin SMB peuvent être étendues lors de l’utilisation de Windows 10/Windows Server 2016 version 1607 ou ultérieure en modifiant une valeur de Registre comme indiqué dans Limitation de la longueur maximale du chemin. Lorsque cette valeur est modifiée, les longueurs de chemin peuvent s’étendre jusqu’à 32 767 octets (moins les valeurs de métadonnées).
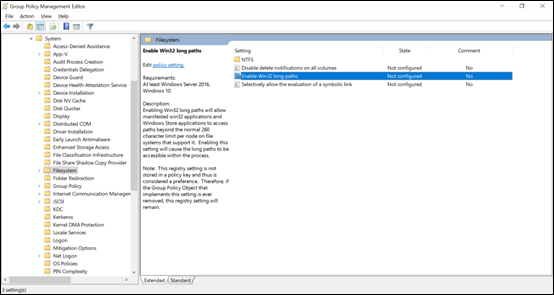
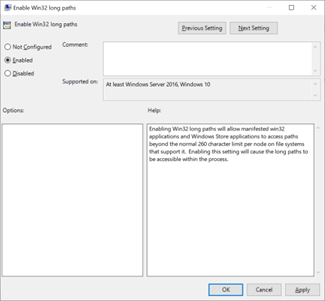
Une fois cette fonctionnalité activée, vous devez accéder au partage SMB à l’aide de \\?\ dans le chemin pour autoriser des longueurs de chemin plus longues. Cette méthode ne prend pas en charge les chemins UNC. Par conséquent, le partage SMB doit être mappé à une lettre de lecteur.
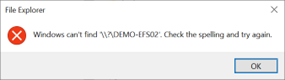
L’utilisation de \\?\Z: à la place autorise l’accès et prend en charge des chemins de fichiers plus longs.

Remarque
Windows CMD ne prend actuellement pas en charge l’utilisation de \\?\.
Solution de contournement si la longueur maximale du chemin ne peut pas être augmentée
Si la longueur maximale du chemin ne peut pas être activée dans l’environnement Windows ou si les versions du client Windows sont trop basses, il existe une solution de contournement. Vous pouvez monter le partage SMB plus en profondeur dans la structure de répertoires pour réduire la longueur du chemin interrogé.
Par exemple, au lieu de mapper \\NAS-SHARE\AzureNetAppFiles à Z:, mappez \\NAS-SHARE\AzureNetAppFiles\folder1\folder2\folder3\folder4 à Z:.
Limites de chemin NFS
Les limites de chemin NFS avec les volumes Azure NetApp Files ont la même limite de 255 octets pour les composants de chemin individuels. Toutefois, chaque composant est évalué un par un et peut traiter jusqu’à 4 096 octets par demande avec une longueur de chemin totale presque illimitée. Par exemple, si chaque composant de chemin est de 255 octets, un client NFS peut évaluer jusqu’à 15 composants par demande (y compris les caractères /). Par conséquent, une demande cd vers un chemin au-delà de la limite de 4 096 octets génère un message d’erreur « Nom de fichier trop long ».
Dans la plupart des cas, les caractères Unicode sont de 1 octet ou moins, de sorte que la limite de 4 096 octets correspond à 4 096 caractères. Si un caractère est de taille supérieure à 1 octet, la longueur du chemin est inférieure à 4 096 caractères. Les caractères dont la taille est supérieure à 1 octet comptent plus par rapport au nombre total de caractères que ceux avec une taille de 1 octet.
La longueur maximale du chemin peut être interrogée à l’aide de la commande getconf PATH_MAX /NFSmountpoint.
Remarque
La limite est définie dans le fichier limits.h sur le client NFS. Vous ne devez pas ajuster ces limites.
Considérations relatives aux volumes à deux protocoles
Lors de l’utilisation d’Azure NetApp Files pour l’accès à deux protocoles, la différence entre la façon dont les longueurs de chemin sont gérées dans les protocoles NFS et SMB peut créer des incompatibilités entre les fichiers et dossiers. Par exemple, SMB Windows prend en charge jusqu’à 32 767 caractères dans un chemin (à condition que la fonctionnalité de chemin long soit activée sur le client SMB), mais la prise en charge de NFS peut dépasser ce montant. Par conséquent, si une longueur de chemin est créée dans NFS qui dépasse la prise en charge de SMB, les clients ne peuvent pas accéder aux données une fois la longueur maximale du chemin atteinte. Dans ces cas, veillez à prendre en compte les limites de fin inférieures des longueurs de chemin de fichier entre les protocoles lors de la création de noms de fichiers et de dossiers (et la profondeur du chemin de dossier) ou à mapper les partages SMB plus près du chemin de dossier souhaité pour réduire la longueur du chemin.
Au lieu de mapper le partage SMB au niveau supérieur du volume pour accéder au chemin \\share\folder1\folder2\folder3\folder4, envisagez de mapper le partage SMB à l’intégralité du chemin \\share\folder1\folder2\folder3\folder4. Par conséquent, un mappage de lettre de lecteur à Z: atterrit dans le dossier souhaité et réduit la longueur du chemin de Z:\folder1\folder2\folder3\folder4\file à Z:\file.
Considérations relatives aux caractères spéciaux
Les volumes Azure NetApp Files utilisent un type de langage C.UTF-8, qui couvre de nombreux pays et langues, notamment l’allemand, le cyrillique, l’hébreu et la plupart des caractères chinois/japonais/coréens (CJK). Les caractères de texte les plus courants dans Unicode sont de 3 octets ou moins. Les caractères spéciaux, tels que les emojis, les symboles musicaux et les symboles mathématiques, sont souvent supérieurs à 3 octets. Certains utilisent la logique de paire de substitution UTF-16.
Si vous utilisez un caractère qu’Azure NetApp Files ne prend pas en charge, vous pouvez voir un avertissement demandant un autre nom de fichier.
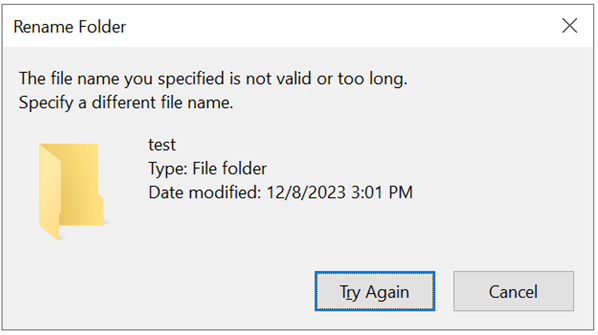
Le nom n’est pas trop long. L’erreur résulte en fait de la taille d’octet de caractère trop grande pour le volume Azure NetApp Files à utiliser sur SMB. Il n’existe aucune solution de contournement dans Azure NetApp Files pour cette limitation. Pour plus d’informations sur la gestion des caractères spéciaux dans Azure NetApp Files, consultez Comportements de protocoles avec des jeux de caractères spéciaux.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour