Comprendre les langages de volume dans Azure NetApp Files
Le langage de volume (semblable aux paramètres régionaux système sur les systèmes d’exploitation clients) sur un volume Azure NetApp Files contrôle les langues et jeux de caractères pris en charge lors de l’utilisation de protocoles NFS et SMB. Azure NetApp Files utilise le langage de volume par défaut C.UTF-8, qui fournit un encodage UTF-8 compatible POSIX pour les jeux de caractères. Le langage C.UTF-8 prend en charge en mode natif les caractères avec une taille de 0 à 3 octets, ce qui comprend une majorité des langues du monde sur le plan multilingue de base (BMP) (y compris le japonais, l’allemand et la plupart des langues hébraïques et cyrilliques). Pour plus d’informations sur le plan BMP, consultez Unicode.
Les caractères en dehors de BMP dépassent parfois la taille de 3 octets prise en charge par Azure NetApp Files. Ils doivent donc utiliser la logique de paire de substitution, où plusieurs jeux d’octets de caractères sont combinés pour former de nouveaux caractères. Les symboles emoji, par exemple, appartiennent à cette catégorie et sont pris en charge dans Azure NetApp Files dans les scénarios où UTF-8 n’est pas appliqué, comme les clients Windows qui utilisent l’encodage UTF-16 ou NFSv3 qui n’applique pas UTF-8. NFSv4.x applique UTF-8, ce qui signifie que les caractères de paire de substitution ne s’affichent pas correctement lors de l’utilisation de NFSv4.x.
Un encodage non standard, tel que Shift-JIS et des caractères CJK moins courants, ne s’affichent pas non plus correctement lorsque UTF-8 est appliqué dans Azure NetApp Files.
Conseil
Vous devez envoyer et recevoir du texte à l’aide d’UTF-8 pour éviter les situations où les caractères ne peuvent pas être traduits correctement, ce qui peut entraîner la création ou le changement de nom de fichier ou les scénarios d’erreur de copie.
Les paramètres de langage de volume ne peuvent actuellement pas être modifiés dans Azure NetApp Files. Pour plus d’informations, consultez Comportements de protocoles avec des jeux de caractères spéciaux.
Pour connaître les bonnes pratiques, consultez Bonnes pratiques des jeux de caractères.
Encodage de caractères dans les volumes NFS et SMB Azure NetApp Files
Dans un environnement de partage de fichiers Azure NetApp Files, les noms de fichiers et de dossiers sont représentés par une série de caractères que les utilisateurs finaux lisent et interprètent. La façon dont ces caractères sont affichés dépend de la façon dont le client envoie et reçoit l’encodage de ces caractères. Par exemple, si un client envoie un encodage ASCII (American Standard Code for Information Interchange) hérité au volume Azure NetApp Files lors de son accès, il est limité à afficher uniquement les caractères pris en charge dans le format ASCII.
Par exemple, le caractère japonais pour les données est 資. Étant donné que ce caractère ne peut pas être représenté en ASCII, un client utilisant l’encodage ASCII affiche un « ? » au lieu de 資.
ASCII ne prend en charge que 95 caractères imprimables, principalement ceux trouvés dans la langue anglaise. Chacun de ces caractères utilise 1 octet, ce qui est pris en compte dans la longueur totale de chemin de fichier sur un volume Azure NetApp Files. Cela limite l’internationalisation des jeux de données, car les noms de fichiers peuvent avoir un large éventail de caractères non reconnus par ASCII, du japonais au cyrillique à l’emoji. Une norme internationale (ISO/IEC 8859) a tenté de prendre en charge davantage de caractères internationaux, mais a également eu ses limites. La plupart des clients modernes envoient et reçoivent des caractères à l’aide d’un type d’Unicode.
Unicode
En raison des limitations des encodages ASCII et ISO/IEC 8859, la norme Unicode a été établie afin que chacun puisse afficher la langue de sa région d’origine à partir de ses appareils.
- Unicode prend en charge plus d’un million de jeux de caractères en augmentant le nombre d’octets par caractère autorisé (jusqu’à 4 octets) et le nombre total d’octets autorisés dans un chemin de fichier, par opposition aux encodages plus anciens, comme ASCII.
- Unicode prend en charge la compatibilité descendante en réservant les 128 premiers caractères pour ASCII, tout en garantissant que les 256 premiers points de code sont identiques aux normes ISO/IEC 8859.
- Dans la norme Unicode, les jeux de caractères sont divisés en plans. Un plan est un groupe continu de 65 536 points de code. Au total, il existe 17 plans (0-16) dans la norme Unicode. La limite est de 17 en raison des limitations d’UTF-16.
- Le plan 0 est le plan multilingue de base (BMP). Ce plan contient les caractères les plus couramment utilisés dans plusieurs langues.
- Sur les 17 plans, seuls cinq se voient actuellement attribuer des jeux de caractères depuis Unicode version 15.1.
- Les plans 1-17 sont appelés plans multilingues supplémentaires (SMP) et contiennent des jeux de caractères moins utilisés, par exemple des systèmes d’écriture anciens tels que l’écriture cunéiforme et les hiéroglyphes ainsi que des caractères chinois/japonais/coréens (CJK) spéciaux.
- Pour connaître les méthodes permettant de voir les longueurs de caractères et les tailles de chemin, et de contrôler l’encodage envoyé à un système, consultez Conversion de fichiers en différents encodages.
Unicode utilise Unicode Transformation Format comme norme, UTF-8 et UTF-16 étant les deux formats principaux.
Plans Unicode
Unicode utilise 17 plans de 65 536 caractères (256 points de code multipliés par 256 zones dans le plan), le plan 0 étant le plan multilingue de base (BMP). Ce plan contient les caractères les plus couramment utilisés dans plusieurs langues. Étant donné que les langues et jeux de caractères du monde dépassent 65 536 caractères, d’autres plans sont nécessaires pour prendre en charge les jeux de caractères moins couramment utilisés.
Par exemple, le plan 1 (plans multilingues supplémentaires (SMP)) comprend des scripts historiques tels que l’écriture cunéiforme et les hiéroglyphes égyptiens ainsi que certains scripts Osage, Warang Citi, Adlam, Wancho et Toto. Le plan 1 inclut également certains symboles et caractères émoticône.
Le plan 2 (plan idéographique supplémentaire (SIP)) contient des idéogrammes unifiés chinois/japonais/coréens (CJK). Les caractères des plans 1 et 2 ont généralement une taille de 4 octets.
Par exemple :
- L’émoticône « Visage très souriant avec de grands yeux » « 😃 » dans le plan 1 a une taille de 4 octets.
- Le hiéroglyphe égyptien « 𓀀 » dans le plan 1 a une taille de 4 octets.
- Le caractère Osage « 𐒸 » dans le plan 1 a une taille de 4 octets.
- Le caractère CJK « 𫝁 » dans le plan 2 a une taille de 4 octets.
Étant donné que ces caractères sont tous > à 3 octets en taille, ils nécessitent l’utilisation de paires de substitution pour fonctionner correctement. Azure NetApp Files prend en charge en mode natif les paires de substitution, mais l’affichage des caractères varie en fonction du protocole utilisé, des paramètres régionaux du client et des paramètres de l’application d’accès du client distant.
UTF-8
UTF-8 utilise un encodage 8 bits et peut avoir jusqu’à 1 112 064 points de code (ou caractères). UTF-8 est l’encodage standard dans toutes les langues des systèmes d’exploitation Linux. Comme UTF-8 utilise l’encodage 8 bits, l’entier non signé maximal possible est 255 (2^8 – 1), qui est également la longueur maximale du nom de fichier pour cet encodage. UTF-8 est utilisé dans plus de 98 % des pages sur Internet, ce qui en fait de loin la norme d’encodage la plus adoptée. WHATWG (Web Hypertext Application Technology Working Group) estime qu’UTF-8 est « l’encodage obligatoire pour tout [texte] » et que, pour des raisons de sécurité, les applications de navigateur ne doivent pas utiliser UTF-16.
Les caractères au format UTF-8 utilisent chacun 1 à 4 octets, mais presque tous les caractères de toutes les langues utilisent entre 1 et 3 octets. Exemple :
- La lettre d’alphabet latin « A » utilise 1 octet. (Un des 128 caractères ASCII réservés)
- Un symbole de copyright « © » utilise 2 octets.
- Le caractère « ä » utilise 2 octets. (1 octet pour « a » + 1 octet pour le tréma)
- Le symbole Kanji japonais pour les données (資) utilise 3 octets.
- Un emoji de visage très souriant (😃) utilise 4 octets.
Les paramètres régionaux de langue peuvent utiliser un format UTF-8 standard d’ordinateur (C.UTF-8) ou un format plus spécifique à une région, comme en_US.UTF-8, ja.UTF-8, etc. Vous devez utiliser l’encodage UTF-8 pour les clients Linux lors de l’accès à Azure NetApp Files dans la mesure du possible. Depuis OS X, les clients macOS utilisent également UTF-8 pour son encodage par défaut et ne doivent pas être ajustés.
Les clients Windows utilisent UTF-16. Dans la plupart des cas, ce paramètre doit être laissé comme valeur par défaut pour les paramètres régionaux du système d’exploitation, mais les clients plus récents offrent la prise en charge bêta des caractères UTF-8 via une case à cocher. Les clients de terminal dans Windows peuvent également être ajustés pour utiliser UTF-8 dans PowerShell ou CMD en fonction des besoins. Pour plus d’informations, consultez Comportements à deux protocoles avec des jeux de caractères spéciaux.
UTF-16
UTF-16 utilise un encodage 16 bits et est capable d’encoder tous les 1 112 064 points de code Unicode. L’encodage pour UTF-16 peut utiliser une ou deux unités de code 16 bits, chacune de 2 octets en taille. Tous les caractères dans UTF-16 utilisent des tailles de 2 ou 4 octets. Les caractères dans UTF-16 qui utilisent 4 octets tirent parti des paires de substitution, qui combinent deux caractères distincts de 2 octets pour créer un caractère. Ces caractères supplémentaires se trouvent en dehors du plan BMP standard et dans l’un des autres plans multilingues.
UTF-16 est utilisé dans les systèmes d’exploitation Windows et les API, Java et JavaScript. Étant donné qu’il ne prend pas en charge la compatibilité descendante avec les formats ASCII, il n’a jamais gagné en popularité sur le web. UTF-16 ne constitue qu’environ 0,002 % de toutes les pages sur Internet. WHATWG (Web Hypertext Application Technology Working Group) estime qu’UTF-8 est « l’encodage obligatoire pour tout texte » et recommande aux applications de ne pas utiliser UTF-16 pour la sécurité du navigateur.
Azure NetApp Files prend en charge la plupart des caractères UTF-16, y compris les paires de substitution. Dans les cas où le caractère n’est pas pris en charge, les clients Windows signalent une erreur de type « Le nom de fichier que vous avez spécifié n’est pas valide ou est trop long ».
Gestion des jeux de caractères sur les clients distants
Les connexions à distance aux clients qui montent des volumes Azure NetApp Files (par exemple, les connexions SSH aux clients Linux pour accéder aux montages NFS) peuvent être configurées pour envoyer et recevoir des encodages de langage de volume spécifiques. L’encodage de langage envoyé au client via l’utilitaire de connexion à distance contrôle la façon dont les jeux de caractères sont créés et consultés. Par conséquent, une connexion à distance qui utilise un encodage de langage différent d’une autre connexion à distance (par exemple, deux fenêtres PuTTY différentes) peut afficher des résultats différents pour les caractères lors du listage des noms de fichiers et de dossiers dans le volume Azure NetApp Files. Dans la plupart des cas, cela ne crée pas d’écarts (par exemple, pour les caractères latins/anglais) mais, dans les cas de caractères spéciaux, tels que les emojis, les résultats peuvent varier.
Par exemple, l’utilisation d’un encodage d’UTF-8 pour la connexion à distance affiche des résultats prévisibles pour les caractères dans les volumes Azure NetApp Files, car C.UTF-8 est le langage du volume. Le caractère japonais pour « données » (資) s’affiche différemment en fonction de l’encodage envoyé par le terminal.
Encodage de caractères dans PuTTY
Lorsqu’une fenêtre PuTTY utilise UTF-8 (trouvée dans les paramètres de traduction de Windows), le caractère est représenté correctement pour un volume monté NFSv3 dans Azure NetApp Files :

Si la fenêtre PuTTY utilise un encodage différent, par exemple ISO-8859-1:1998 (Latin-1, Europe occidentale), le même caractère s’affiche différemment même si le nom de fichier est le même.

PuTTY, par défaut, ne contient pas d’encodages CJK. Il existe des correctifs disponibles pour ajouter ces ensembles de langues à PuTTY.
Encodages de caractères dans Bastion
Microsoft Azure recommande d’utiliser Bastion pour la connectivité à distance aux machines virtuelles dans Azure. Lorsque vous utilisez Bastion, l’encodage de langage envoyé et reçu n’est pas exposé dans la configuration, mais tire parti de l’encodage UTF-8 standard. Par conséquent, la plupart des jeux de caractères affichés dans PuTTY à l’aide d’UTF-8 doivent également être visibles dans Bastion, à condition que les jeux de caractères soient pris en charge dans le protocole utilisé.

Conseil
D’autres terminaux SSH peuvent être utilisés, tels que TeraTerm. TeraTerm fournit une gamme plus étendue de jeux de caractères pris en charge par défaut, notamment les encodages CJK et les encodages non standard tels que Shift-JIS.
Comportements de protocoles avec des jeux de caractères spéciaux
Les volumes Azure NetApp Files utilisent l’encodage UTF-8 et prennent en charge en mode natif les caractères qui ne dépassent pas 3 octets. Tous les caractères du jeu ASCII et UTF-8 s’affichent correctement, car ils tombent dans la plage de 1 à 3 octets. Par exemple :
- Le caractère d’alphabet latin A utilise 1 octet (l’un des 128 caractères ASCII réservés).
- Un symbole de copyright © utilise 2 octets.
- Le caractère « ä » utilise 2 octets (1 octet pour « a » et 1 octet pour le tréma)
- Le symbole Kanji japonais pour les données (資) utilise 3 octets.
Azure NetApp Files prend également en charge certains caractères qui dépassent 3 octets par le biais d’une logique de paire de substitution (par exemple, un emoji), à condition que l’encodage client et la version du protocole les prennent en charge. Pour plus d’informations sur les comportements de protocoles, consultez :
Comportements SMB
Dans les volumes SMB, Azure NetApp Files crée et conserve deux noms pour les fichiers ou répertoires dans n’importe quel répertoire qui a accès à partir d’un client SMB : le nom long d’origine et un nom au format 8.3.
Noms de fichiers dans SMB avec Azure NetApp Files
Lorsque les noms de fichiers ou de répertoires dépassent les octets de caractères autorisés ou utilisent des caractères non pris en charge, Azure NetApp Files génère un nom au format 8.3 comme suit :
- Il tronque le nom du fichier ou du répertoire d’origine.
- Il ajoute un tilde (~) et un chiffre (1-5) aux noms de fichiers ou de répertoires qui ne sont plus uniques après avoir été tronqués. S’il existe plus de cinq fichiers avec des noms non uniques, Azure NetApp Files crée un nom unique sans relation avec le nom d’origine. Pour les fichiers, Azure NetApp Files tronque l’extension de nom de fichier à trois caractères.
Par exemple, si un client NFS crée un fichier nommé specifications.html, Azure NetApp Files crée le nom de fichier specif~1.htm suivant le format 8.3. Si ce nom existe déjà, Azure NetApp Files utilise un autre chiffre à la fin du nom de fichier. Par exemple, si un client NFS crée ensuite un autre fichier nommé specifications\_new.html, le format 8.3 de specifications\_new.html est specif~2.htm.
Caractère spécial dans SMB avec Azure NetApp Files
Lors de l’utilisation de SMB avec des volumes Azure NetApp Files, les caractères qui dépassent 3 octets utilisés dans les noms de fichiers et de dossiers (y compris les émoticônes) sont autorisés en raison de la prise en charge des paires de substitution. Voici ce que l’Explorateur Windows voit pour les caractères en dehors du BMP sur un dossier créé à partir d’un client Windows lors de l’utilisation de l’anglais avec l’encodage UTF-16 par défaut.
Remarque
La police par défaut dans l’Explorateur Windows est Segoe UI. Les modifications de police peuvent affecter la façon dont certains caractères s’affichent sur les clients.

La façon dont les caractères s’affichent sur le client dépend de la police système, de la langue et des paramètres régionaux. En général, les caractères qui appartiennent au BMP sont pris en charge dans tous les protocoles, que l’encodage soit UTF-8 ou UTF-16.
Lorsque vous utilisez CMD ou PowerShell, la vue de jeu de caractères peut dépendre des paramètres de police. Ces utilitaires ont des choix de polices limités par défaut. CMD utilise Consolas comme police par défaut.
Les noms de fichiers peuvent ne pas s’afficher comme prévu en fonction de la police utilisée, car certaines consoles ne prennent pas en charge en mode natif Segoe UI ou d’autres polices qui affichent correctement des caractères spéciaux.
Ce problème peut être résolu sur les clients Windows à l’aide de PowerShell ISE, qui fournit une prise en charge de police plus robuste. Par exemple, la définition de PowerShell ISE sur Segoe UI affiche correctement les noms de fichiers avec des caractères pris en charge.

Toutefois, PowerShell ISE est conçu pour l’écriture de scripts, plutôt que pour la gestion des partages. Les versions plus récentes de Windows offrent le Terminal Windows, qui permet de contrôler les polices et les valeurs d’encodage.
Remarque
Utilisez la commande chcp pour afficher l’encodage du terminal. Pour obtenir la liste complète des pages de codes, consultez Identificateurs des pages de codes.

Si le volume est activé pour deux protocoles (NFS et SMB), vous pouvez observer des comportements différents. Pour plus d’informations, consultez Comportements à deux protocoles avec des jeux de caractères spéciaux.
Comportements NFS
La façon dont NFS affiche des caractères spéciaux dépend de la version de NFS utilisée, des paramètres régionaux du client, des polices installées et des paramètres du client de connexion à distance en cours d’utilisation. Par exemple, l’utilisation de Bastion pour accéder à un client Ubuntu peut gérer les affichages de caractères différemment d’un client PuTTY défini sur des paramètres régionaux différents sur la même machine virtuelle. Les exemples NFS suivants s’appuient sur ces paramètres régionaux pour la machine virtuelle Ubuntu :
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Comportement NFSv3
NFSv3 n’applique pas l’encodage UTF sur les fichiers et dossiers. Dans la plupart des cas, les jeux de caractères spéciaux ne doivent pas rencontrer de problèmes. Toutefois, le client de connexion utilisé peut affecter la façon dont les caractères sont envoyés et reçus. Par exemple, l’utilisation de caractères Unicode en dehors de BMP pour un nom de dossier dans le client de connexion Azure Bastion peut entraîner un comportement inattendu en raison du fonctionnement de l’encodage client.
Dans la capture d’écran suivante, Bastion ne peut pas copier et coller les valeurs dans l’invite CLI de l’extérieur du navigateur lors du nommage d’un répertoire sur NFSv3. Lorsque vous tentez de copier et coller la valeur de NFSv3Bastion𓀀𫝁😃𐒸, les caractères spéciaux s’affichent sous forme de guillemets dans l’entrée.

La commande copier/coller est autorisée sur NFSv3, mais les caractères sont créés en tant que valeurs numériques, ce qui affecte leur affichage :
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Cet affichage est dû à l’encodage utilisé par Bastion pour envoyer des valeurs de texte lors de la copie et du collage.
Lors de l’utilisation de PuTTY pour créer un dossier avec les mêmes caractères sur NFSv3, le nom du dossier est différent dans Bastion que lorsque Bastion a été utilisé pour le créer. L’émoticône s’affiche comme prévu (en raison des polices et paramètres régionaux installés), à la différence des autres caractères (comme le caractère Osage « 𐒸 »).

À partir d’une fenêtre PuTTY, les caractères s’affichent correctement :

Comportement NFSv4.x
NFSv4.x applique l’encodage UTF-8 dans les noms de fichiers et de dossiers conformément aux spécifications d’internationalisation RFC-8881.
Par conséquent, si un caractère spécial est envoyé avec un encodage non-UTF-8, NFSv4.x peut ne pas autoriser la valeur.
Dans certains cas, une commande peut être autorisée avec un caractère en dehors du plan multilingue de base (BMP), mais elle peut ne pas afficher la valeur après sa création.
Par exemple, l’émission de mkdir avec un nom de dossier incluant les caractères « 𓀀𫝁😃𐒸 » (caractères dans les plans multilingues supplémentaires (SMP) et le plan ideographique supplémentaire (SIP)) semble réussir dans NFSv4.x. Le dossier ne sera pas visible lors de l’exécution de la commande ls.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Le dossier existe dans le volume. La modification en nom de répertoire masqué fonctionne à partir du client PuTTY et un fichier peut être créé à l’intérieur de ce répertoire.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Une commande stat de PuTTY confirme également que le dossier existe :
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Même si l’existence du dossier est confirmée, les commandes génériques ne fonctionnent pas, car le client ne peut pas officiellement « voir » le dossier dans l’affichage.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 envoie une erreur au client lorsqu’il rencontre un caractère qui ne s’appuie pas sur l’encodage UTF-8.
Par exemple, lorsque vous utilisez Bastion pour tenter d’accéder au même répertoire que celui que nous avons créé à l’aide de PuTTY sur NFSv4.1, voici le résultat :
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL est couvert dans RFC-8881.
Étant donné que le dossier est accessible à partir de PuTTY (en raison de l’encodage envoyé et reçu), il peut être copié si le nom est spécifié. Après avoir copié ce dossier du volume Azure NetApp Files NFSv4.1 vers le volume Azure NetApp Files NFSv3, le nom du dossier s’affiche :
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
La même erreur NFS4ERR\_INVAL peut être observée si une conversion de fichier (avec iconv) en un format non-UTF-8 est tentée, telle que Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Pour plus d’informations, consultez Conversion de fichiers en différents encodages.
Comportements à deux protocoles
Azure NetApp Files permet aux volumes d’être accessibles à la fois par NFS et SMB via un accès à deux protocoles. En raison des grandes différences dans l’encodage de langage utilisé par NFS (UTF-8) et SMB (UTF-16), les jeux de caractères, les noms de fichiers et de dossiers et les longueurs de chemin peuvent avoir des comportements très différents entre les protocoles.
Affichage des fichiers et dossiers créés par NFS à partir de SMB
Quand Azure NetApp Files est utilisé pour l’accès à deux protocoles (SMB et NFS), un jeu de caractères non pris en charge par UTF-16 peut être utilisé dans un nom de fichier créé avec UTF-8 via NFS. Dans ces scénarios, lorsque SMB accède à un fichier avec des caractères non pris en charge, le nom est tronqué dans SMB à l’aide de la convention de nom de fichier court 8.3.
Fichiers créés par NFSv3 et comportements SMB avec des jeux de caractères
NFSv3 n’applique pas l’encodage UTF-8. Les caractères utilisant des encodages de langage non standard (tels que Shift-JIS) fonctionnent avec Azure NetApp Files lors de l’utilisation de NFSv3.
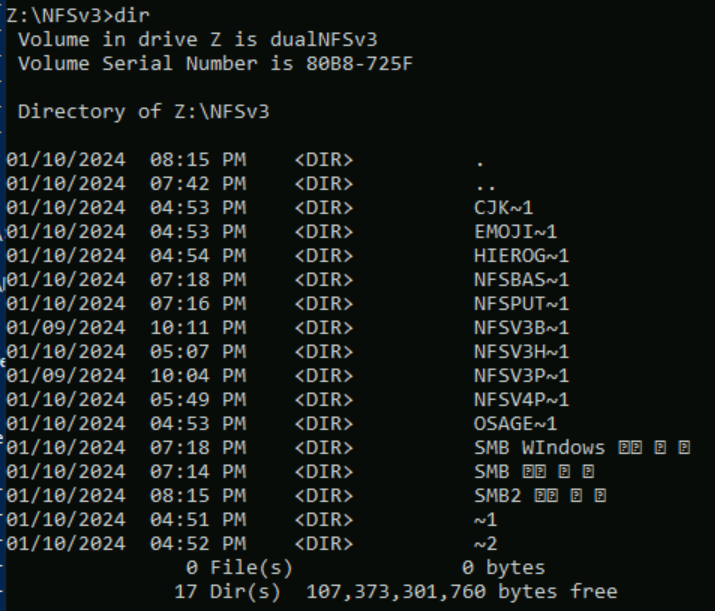
Dans l’exemple suivant, une série de noms de dossiers utilisant différents jeux de caractères à partir de différents plans dans Unicode ont été créés dans un volume Azure NetApp Files à l’aide de NFSv3. Quand ils sont consultés à partir de NFSv3, ils s’affichent correctement.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
À partir de SMB Windows, les dossiers contenant des caractères trouvés dans le BMP s’affichent correctement, mais les caractères en dehors de ce plan s’affichent avec le format de nom 8.3 en raison de la conversion UTF-8/UTF-16 incompatible pour ces caractères.
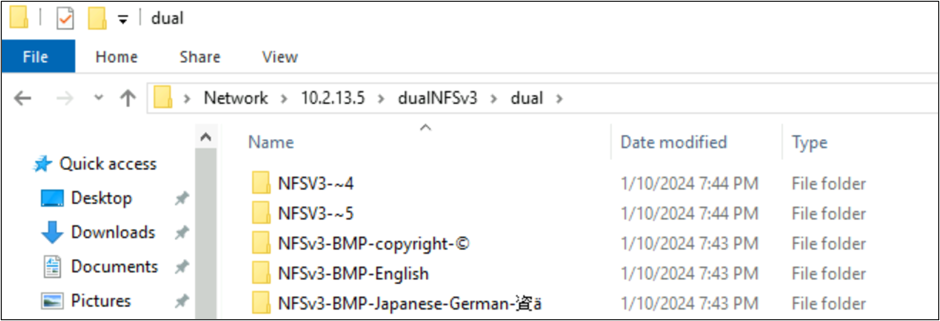
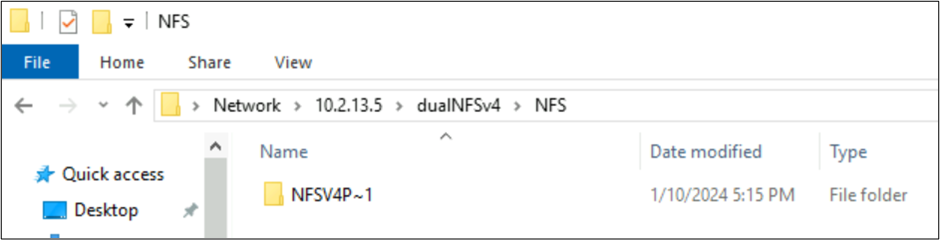
Fichiers créés par NFSv4.1 et comportements SMB avec des jeux de caractères
Dans les exemples précédents, un dossier nommé NFSv4 Putty 𓀀𫝁😃𐒸 a été créé sur un volume Azure NetApp Files sur NFSv4.1, mais n’était pas visible avec NFSv4.1. Toutefois, il peut être vu à l’aide de SMB. Le nom est tronqué dans SMB dans un format 8.3 pris en charge en raison des jeux de caractères non pris en charge créés à partir du client NFS et de la conversion UTF-8/UTF-16 incompatible pour les caractères dans différents plans Unicode.
Lorsqu’un nom de dossier utilise des caractères UTF-8 standard trouvés dans le BMP (anglais ou autre), SMB traduit correctement les noms.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
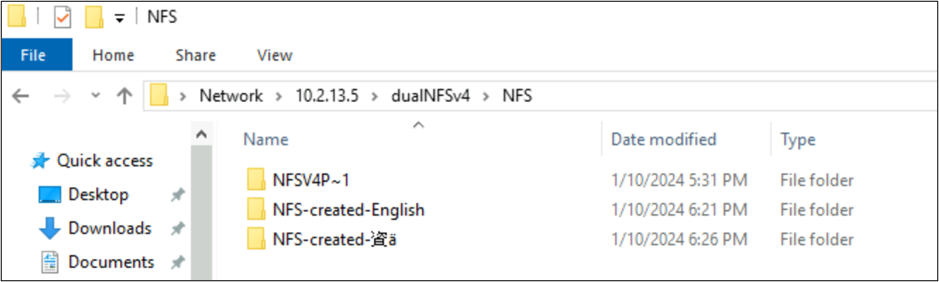
Fichiers et dossiers créés par SMB sur NFS
Les clients Windows sont le type principal de clients utilisés pour accéder aux partages SMB. Ces clients utilisent par défaut l’encodage UTF-16. Il est possible de prendre en charge certains caractères encodés en UTF-8 dans Windows en l’activant dans les paramètres de région :
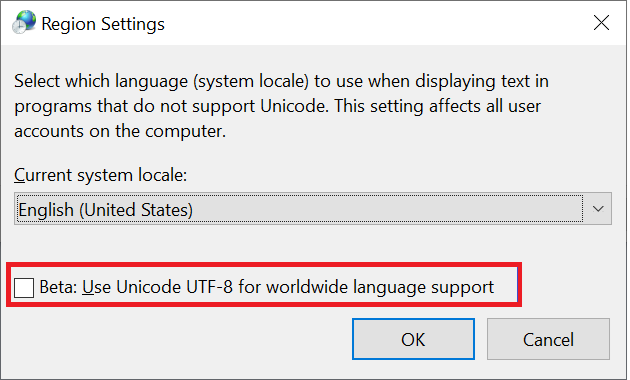
Lorsqu’un fichier ou un dossier est créé sur un partage SMB dans Azure NetApp Files, le jeu de caractères utilisé est encodé en UTF-16. Par conséquent, les clients utilisant l’encodage UTF-8 (tels que les clients NFS basés sur Linux) peuvent ne pas être en mesure de traduire correctement certains jeux de caractères, en particulier les caractères qui se trouvent en dehors du plan multilingue de base (BMP).
Comportement de caractères non pris en charge
Dans ces scénarios, lorsqu’un client NFS accède à un fichier créé à l’aide de SMB avec des caractères non pris en charge, le nom s’affiche sous la forme d’une série de valeurs numériques représentant les valeurs Unicode du caractère.
Par exemple, ce dossier a été créé dans l’Explorateur Windows à l’aide de caractères en dehors du BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
Sur NFSv3, le dossier créé par SMB s’affiche :
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Sur NFSv4.1, le dossier créé par SMB s’affiche comme suit :
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Comportement de caractères pris en charge
Lorsque les caractères se trouvent dans le BMP, il n’y a aucun problème entre les protocoles SMB et NFS, et leurs versions.
Par exemple, un nom de dossier créé à l’aide de SMB sur un volume Azure NetApp Files avec des caractères trouvés dans le BMP dans plusieurs langues (anglais, allemand, cyrillique, runique) s’affiche correctement dans tous les protocoles et versions.
- Latin de base « SMB »
- Grec « ͶΘΩ »
- Cyrillique « ЁЄЊ »
- Runique « ᚠᚱᛯ »
- Idéogrammes de compatibilité CJK « 豈滑虜 »
Voici comment le nom apparaît dans SMB :
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Voici comment le nom apparaît à partir de NFSv3 :
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Voici comment le nom apparaît à partir de NFSv4.1 :
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Conversion de fichiers en différents encodages
Les noms de fichiers et de dossiers ne sont pas les seules parties des objets du système de fichiers qui utilisent des encodages de langage. Le contenu du fichier (par exemple, des caractères spéciaux à l’intérieur d’un fichier texte) peut également jouer un rôle. Par exemple, si une tentative d’enregistrement d’un fichier est effectuée avec des caractères spéciaux dans un format incompatible, un message d’erreur peut être affiché. Dans ce cas, un fichier avec des caractères Katagana ne peut pas être enregistré dans ANSI, car ces caractères n’existent pas dans cet encodage.
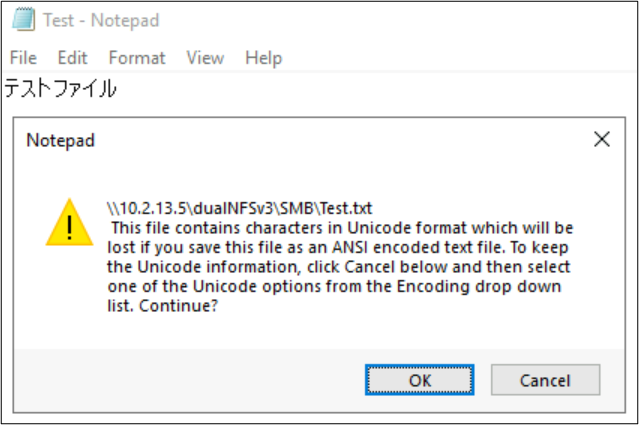
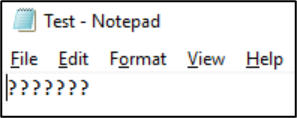
Une fois que ce fichier est enregistré dans ce format, les caractères sont convertis en points d’interrogation :
Les encodages de fichiers peuvent être consultés à partir de clients NAS. Sur les clients Windows, vous pouvez utiliser une application comme le Bloc-notes ou Notepad++ pour afficher un encodage d’un fichier. Si le sous-système Windows pour Linux (WSL) ou Git sont installés sur le client, la commande file peut être utilisée.
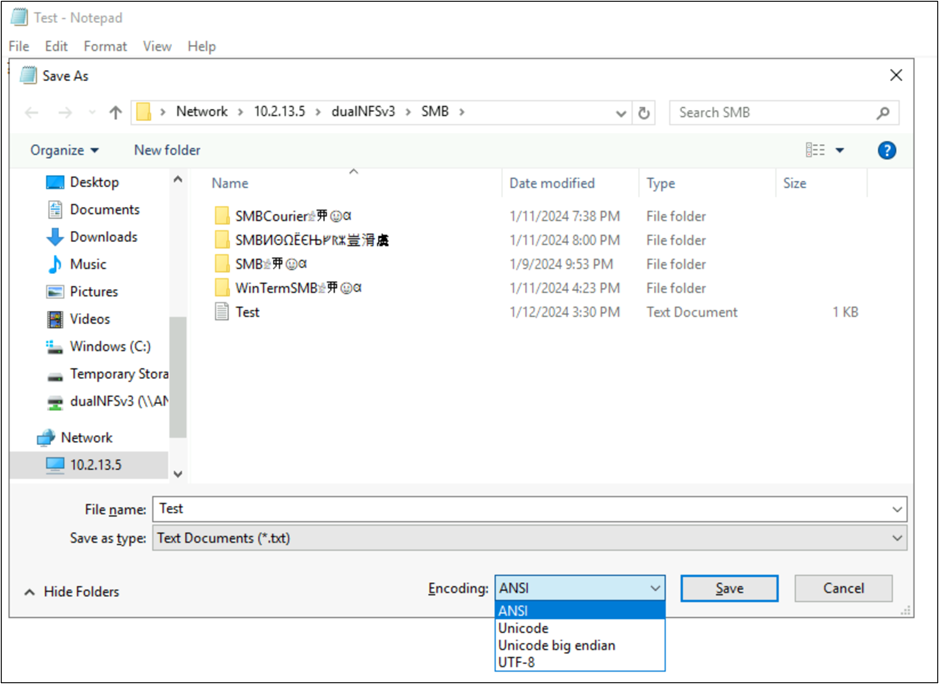
Ces applications vous permettent également de modifier l’encodage du fichier en enregistrant sous différents types d’encodages. De plus, PowerShell peut être utilisé pour convertir l’encodage sur des fichiers avec les applets de commande Get-Content et Set-Content.
Par exemple, le fichier utf8-text.txt est encodé en UTF-8 et contient des caractères en dehors du BMP. Comme UTF-8 est utilisé, les caractères sont affichés correctement.
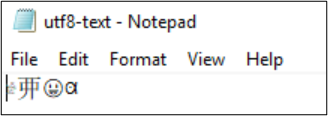
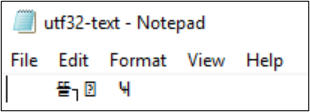
Si l’encodage est converti en UTF-32, les caractères ne s’affichent pas correctement.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
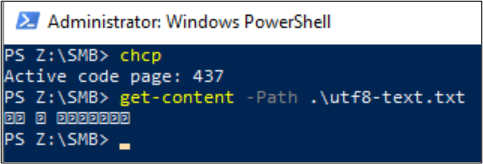
Get-Content peut également être utilisé pour afficher le contenu du fichier. Par défaut, PowerShell utilise l’encodage UTF-16 (page de codes 437) et les sélections de polices pour la console sont limitées. Par conséquent, le fichier au format UTF-8 avec des caractères spéciaux ne peut pas être affiché correctement :
Les clients Linux peuvent utiliser la commande file pour afficher l’encodage du fichier. Dans les environnements à deux protocoles, si un fichier est créé à l’aide de SMB, le client Linux utilisant NFS peut vérifier l’encodage du fichier.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
La conversion d’encodage de fichier peut être effectuée sur les clients Linux à l’aide de la commande iconv. Pour afficher la liste des formats d’encodage pris en charge, utilisez iconv -l.
Par exemple, le fichier encodé en UTF-8 peut être converti en UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Si le jeu de caractères sur le nom du fichier ou dans le contenu du fichier n’est pas pris en charge par l’encodage de destination, la conversion n’est pas autorisée. Par exemple, Shift-JIS ne peut pas prendre en charge les caractères dans le contenu du fichier.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Si un fichier a des caractères pris en charge par l’encodage, la conversion réussit. Par exemple, si le fichier contient les caractères Katagana テストファイル, la conversion Shift-JIS réussit sur NFS. Étant donné que le client NFS utilisé ici ne comprend pas Shift-JIS en raison des paramètres régionaux, l’encodage indique « unknown-8bit ».
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Étant donné que les volumes Azure NetApp Files prennent uniquement en charge la mise en forme compatible UTF-8, les caractères Katagana sont convertis en format illisible.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Quand vous utilisez NFSv4.x, la conversion est autorisée lorsque des caractères non conformes sont présents à l’intérieur du contenu du fichier, même si NFSv4.x applique l’encodage UTF-8. Dans cet exemple, un fichier encodé en UTF-8 avec des caractères Katagana sur un volume Azure NetApp Files affiche correctement le contenu d’un fichier.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Mais, une fois qu’il est converti, les caractères du fichier s’affichent de manière incorrecte en raison de l’encodage incompatible.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Si le nom du fichier contient des caractères non pris en charge pour UTF-8, la conversion réussit sur NFSv3, mais échoue sur NFSv4.x en raison de l’application UTF-8 de la version du protocole.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Bonnes pratiques des jeux de caractères
Lors de l’utilisation de caractères spéciaux ou de caractères en dehors du plan multilingue de base (BMP) standard sur les volumes Azure NetApp Files, certaines bonnes pratiques doivent être prises en compte.
- Étant donné que les volumes Azure NetApp Files utilisent le langage de volume UTF-8, l’encodage de fichier pour les clients NFS doit également utiliser l’encodage UTF-8 pour obtenir des résultats cohérents.
- Les jeux de caractères dans les noms de fichiers ou dans le contenu du fichier doivent être compatibles UTF-8 pour un affichage et une fonctionnalité appropriés.
- Étant donné que SMB utilise l’encodage de caractères UTF-16, les caractères en dehors du BMP peuvent ne pas s’afficher correctement sur NFS dans les volumes à deux protocoles. Dans la mesure du possible, réduisez l’utilisation de caractères spéciaux dans le contenu du fichier.
- Évitez d’utiliser des caractères spéciaux en dehors du BMP dans les noms de fichiers, en particulier lors de l’utilisation de NFSv4.1 ou de volumes à deux protocoles.
- Pour les jeux de caractères hors du BMP, l’encodage UTF-8 doit autoriser l’affichage des caractères dans Azure NetApp Files lors de l’utilisation d’un protocole de fichier unique (SMB uniquement ou NFS uniquement). Toutefois, les volumes à deux protocoles ne peuvent pas gérer ces jeux de caractères dans la plupart des cas.
- L’encodage non standard (tel que Shift-JIS) n’est pas pris en charge sur les volumes Azure NetApp Files.
- Les caractères de paire de substitution (tels qu’un emoji) sont pris en charge sur les volumes Azure NetApp Files.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour