Utiliser des réplicas en lecture seule pour décharger des charges de travail de requêtes en lecture seule
S’applique à : ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Dans le cadre d’une architecture haute disponibilité, chaque base de données unique ou chaque base de données du pool élastique des niveaux de service Premium et Critique pour l’entreprise sont automatiquement provisionnées avec un réplica principal en lecture-écriture et un ou plusieurs réplicas secondaires en lecture seule. Les réplicas secondaires sont approvisionnés avec la même taille de calcul que le réplica principal. La fonctionnalité Échelle horizontale en lecture vous permet de décharger les charges de travail en lecture seule à l'aide de la capacité de calcul de l'un des réplicas en lecture seule au lieu de les exécuter sur le réplica en lecture-écriture. De cette façon, certaines charges de travail en lecture seule peuvent être isolées des charges de travail en lecture-écriture et n’impacteront pas leurs performances. Cette fonctionnalité est destinée aux applications qui incluent des charges de travail en lecture seule séparées logiquement, telles que des analyses. Aux niveaux de service Premium et Critique pour l’entreprise, les applications peuvent bénéficier d’avantages en matière de performances en exploitant cette capacité supplémentaire sans coût supplémentaire.
La fonctionnalité Échelle horizontale en lecture est également disponible au niveau de service Hyperscale lorsqu'au moins un réplica secondaire est créé. Les réplicas nommés secondaires hyperscale permettent une mise à l’échelle indépendante, l’isolation de l’accès, l’isolation de la charge de travail, la prise en charge de divers scénarios de scale-out horizontal en lecture, et d’autres avantages. Plusieurs réplicas HA secondaires peuvent être utilisés pour équilibrer les charges de travail en lecture seule qui nécessitent plus de ressources qu'il n'en existe sur un réplica secondaire.
L’architecture à haute disponibilité des niveaux de service De base, Standard et Usage général n’inclut pas de réplica. La fonctionnalité de scale-out horizontal en lecture n’est pas disponible à ces niveaux de service. Toutefois, quand vous utilisez Azure SQL Database, les géoréplicas peuvent fournir des fonctionnalités similaires dans ces niveaux de service. Quand vous utilisez Azure SQL Managed Instance et des groupes de basculement, l’écouteur en lecture seule du groupe de basculement peut fournir des fonctionnalités similaires, respectivement.
Le diagramme suivant illustre la fonctionnalité de Premium et critique pour l’entreprise des bases de données et des instances managées.
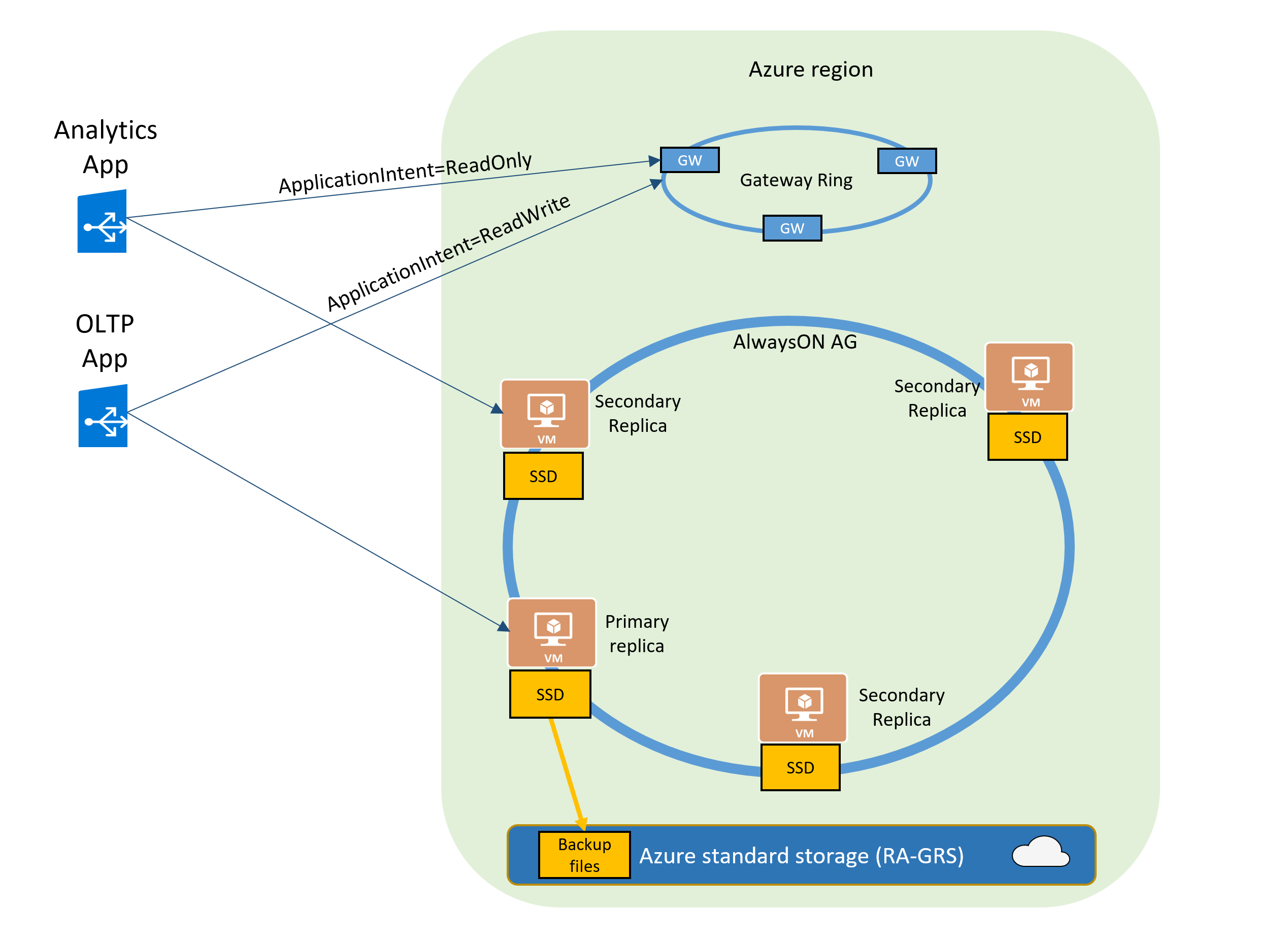
La fonctionnalité Échelle horizontale en lecture est activée par défaut sur les nouvelles bases de données Premium, Critique pour l’entreprise et Hyperscale.
Notes
L’échelle horizontale en lecture est toujours activée dans le niveau de service Vital pour l’entreprise de SQL Managed Instance, et pour les bases de données Hyperscale avec au moins une réplique secondaire.
Si votre chaîne de connexion SQL est configurée avec ApplicationIntent=ReadOnly, l’application est redirigée vers un réplica en lecture seule de cette base de données ou instance managée. Pour plus d’informations sur la manière d’utiliser la propriété ApplicationIntent, voir Spécification de l’intention de l’application.
Pour Azure SQL Database uniquement, si vous souhaitez vous assurer que l’application se connecte au réplica principal quel que soit le paramètre ApplicationIntent de la chaîne de connexion SQL, vous devez désactiver explicitement l’échelle horizontale en lecture lors de la création de la base de données ou de la modification de sa configuration. Par exemple, si vous mettez à niveau votre base de données du niveau Standard ou General Purpose au niveau Premium ou Business Critical et que vous voulez vous assurer que toutes vos connexions continuent d'aller vers le réplica primaire, désactivez le read scale-out. Pour plus d'informations sur la façon de le désactiver, consultez la rubrique Activer et désactiver le transfert en lecture.
Notes
Les fonctionnalités Magasin des requêtes et Générateur de profils SQL ne sont pas prises en charge sur les réplicas en lecture seule.
Cohérence des données
Les modifications apportées au réplica principal sont persistantes sur les réplicas en lecture seule de façon synchrone ou asynchrone, selon le type de réplica. Toutefois, pour tous les types de réplicas, les lectures d’un réplica en lecture seule sont toujours asynchrones par rapport au principal. Dans une session connectée à un réplica en lecture seule, les lectures sont toujours cohérentes au niveau transactionnel. Étant donné que la latence de propagation des données est variable, des réplicas différents peuvent retourner des données à des moments légèrement différents dans le temps par rapport au principal aux autres réplicas. Si un réplica en lecture seule devient indisponible et qu’une session se reconnecte, il peut se connecter à un réplica qui se trouve à un autre point dans le temps que le réplica d’origine. De même, si une application modifie des données dans une session en lecture-écriture sur le principal et les lit aussitôt après dans une session en lecture seule sur un réplica en lecture seule, il est possible que les dernières modifications ne soient pas visibles immédiatement.
La latence de propagation de données classique entre le réplica principal et les réplicas en lecture seule varie dans la plage de dizaines de millisecondes à un nombre de secondes à un chiffre. Toutefois, il n’existe aucune limite supérieure fixe sur la latence de propagation des données. Des conditions comme l’utilisation élevée des ressources sur le réplica peuvent augmenter considérablement la latence. Les applications qui requièrent la cohérence des données entre les sessions ou requièrent que les données validées soient lisibles immédiatement doivent utiliser le réplica principal.
Notes
La latence de propagation des données inclut le temps nécessaire pour envoyer et conserver (le cas échéant) les enregistrements de journal sur un réplica secondaire. Il inclut également le temps nécessaire pour la phase de restauration par progression (l’application) de ces enregistrements de journal sur les pages de données. Pour garantir la cohérence des données, les modifications ne sont pas visibles tant que l’enregistrement du journal de validation de transaction n’a pas été appliqué. Lorsque la charge de travail utilise des transactions plus volumineuses, la latence de propagation des données effective est augmentée.
Pour analyser la latence de propagation des données, consultez Analyse et résolution des problèmes de réplicas en lecture seule.
Se connecter à un réplica en lecture seule
Quand vous activez Échelle horizontale en lecture pour une base de données, l’option ApplicationIntent dans la chaîne de connexion fournie par le client détermine si la connexion est routée vers le réplica en écriture ou un réplica en lecture seule. Plus précisément, si la valeur ApplicationIntent est ReadWrite (valeur par défaut), la connexion est dirigée vers le réplica en lecture-écriture. Ce comportement est identique à celui qui se produit lorsque ApplicationIntent n’est pas inclus dans la chaîne de connexion. Si la valeur ApplicationIntent est ReadOnly, la connexion est acheminée vers un réplica en lecture seule.
Par exemple, la chaîne de connexion suivante connecte le client à un réplica en lecture seule (en remplaçant les éléments entre crochets pointus par les valeurs correctes pour votre environnement et en supprimant ces crochets) :
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Pour vous connecter à un réplica en lecture seule à l’aide de SQL Server Management Studio (SSMS), sélectionnez Options
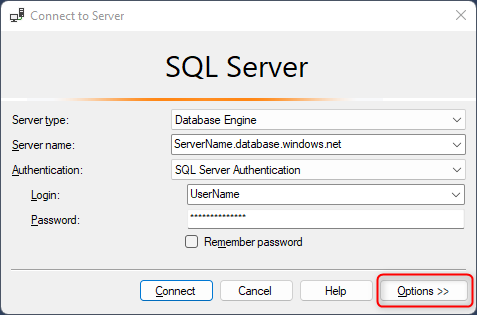
Sélectionnez Paramètres de connexion supplémentaires, entrez ApplicationIntent=ReadOnly, puis sélectionnez Se connecter
L’une des chaînes de connexion suivantes connecte le client à un réplica en lecture-écriture (en remplaçant les éléments entre crochets pointus par les valeurs correctes pour votre environnement et en supprimant ces crochets) :
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadWrite;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Vérifier que la connexion à un réplica en lecture seule est établie
Vous pouvez vérifier si vous êtes connecté à un réplica en lecture seule en exécutant la requête suivante dans le contexte de votre base de données. Elle retourne READ_ONLY quand vous êtes connecté à un réplica en lecture seule.
SELECT DATABASEPROPERTYEX(DB_NAME(), 'Updateability');
Notes
Aux niveaux de service Premium et Critique pour l'entreprise, vous ne pouvez accéder qu'à un seul réplica en lecture seule à la fois. Hyperscale prend en charge plusieurs réplicas en lecture seule.
Analyser et résoudre des problèmes de réplicas en lecture seule
Lorsqu'elles sont connectées à un réplica en lecture seule, les vues de gestion dynamique (DMV) reflètent l'état du réplica et peuvent être interrogées à des fins de surveillance et de dépannage. Le moteur de base de données fournit plusieurs affichages pour exposer un large éventail de données de surveillance.
Les vues suivantes sont couramment utilisées pour la surveillance et le dépannage des répliques :
| Nom | Objectif |
|---|---|
| sys.dm_db_resource_stats | Fournit des métriques sur l'utilisation des ressources au cours de la dernière heure, y compris sur le processeur, les E/S de données et l'utilisation des écritures de journal par rapport aux limites d'objectif de service. |
| sys.dm_os_wait_stats | Fournit des statistiques d'attente agrégées pour l'instance du moteur de base de données. |
| sys.dm_database_replica_states | Fournit des statistiques sur l'état d'intégrité et la synchronisation des réplicas. La taille de la file d’attente de restauration par progression et la vitesse de restauration par progression constituent des indicateurs de la latence de propagation des données sur le réplica en lecture seule. |
| sys.dm_os_performance_counters | Fournit les compteurs de performances du moteur de base de données. |
| sys.dm_exec_query_stats | Fournit des statistiques d'exécution par requête, telles que le nombre d'exécutions, le temps processeur utilisé, etc. |
| sys.dm_exec_query_plan() | Fournit les plans de requête mis en cache. |
| sys.dm_exec_sql_text() | Fournit un texte de requête pour un plan de requête mis en cache. |
| sys.dm_exec_query_profiles | Fournit la progression en temps réel pendant l'exécution des requêtes. |
| sys.dm_exec_query_plan_stats() | Fournit le dernier plan d'exécution réel connu, y compris les statistiques d'exécution relatives à une requête. |
| sys.dm_io_virtual_file_stats() | Fournit des statistiques de stockage IOPS, de débit et de latence pour tous les fichiers de base de données. |
Notes
Les vues de gestion dynamique sys.resource_stats et sys.elastic_pool_resource_stats de la base de données master logique renvoient les données d’utilisation des ressources du réplica principal.
Superviser les réplicas en lecture seule avec événements étendus
Il n’est pas possible de créer une session d’événements étendus durant une connexion à un réplica en lecture seule. Toutefois, dans Azure SQL Database et Azure SQL Managed Instance, les définitions des sessions d’Événements étendus figurant dans l’étendue de la base de données et qui ont été créées et modifiées sur le réplica principal se répliquent sur les réplicas en lecture seule, y compris les géo-réplicas, et capturent les événements sur les réplicas en lecture seule.
Dans Azure SQL Database, une session d’événements étendus sur un réplica en lecture seule basé sur une définition de session du réplica principal peut être démarrée et arrêtée indépendamment de la session sur le réplica principal.
Dans Azure SQL Managed Instance, pour démarrer une trace sur un réplica en lecture seule, vous devez d’abord démarrer la trace sur le réplica principal avant de pouvoir démarrer la trace sur le réplica en lecture seule. Si vous ne démarrez pas la trace sur le réplica principal, vous recevez l’erreur suivante lors de la tentative de démarrage de la trace sur le réplica en lecture seule :
Msg 3906, Niveau 16, État 2, Ligne 1 Échec de la mise à jour de la base de données « master », car la base de données est en lecture seule.
Après avoir démarré la trace d’abord sur le réplica principal, puis sur le réplica en lecture seule, vous pouvez arrêter la trace sur le réplica principal.
Pour supprimer une session d'événements sur un réplica en lecture seule, procédez comme suit :
- connecter Explorateur d'objets SSMS ou une fenêtre Requête vers le réplica en lecture seule.
- Arrêtez la session sur le réplica en lecture seule, soit en sélectionnant Arrêter la session dans le menu local de la session dans l'Explorateur d'objets, soit en exécutant
ALTER EVENT SESSION [session-name-here] ON DATABASE STATE = STOP;dans une fenêtre Requête. - Connectez l'Explorateur d'objets ou une fenêtre Requête au réplica principal.
- Supprimez la session sur le réplica principal, soit en sélectionnant Supprimer dans le menu local de la session, soit en exécutant
DROP EVENT SESSION [session-name-here] ON DATABASE;.
Niveau d'isolement des transactions sur les réplicas en lecture seule
Les transactions sur les réplicas en lecture seule utilisent toujours le niveau d’isolation des transactions d’instantané, quel que soit le niveau d’isolation des transactions de la session, et indépendamment des indicateurs de requête. L'isolement de capture instantanée utilise le contrôle de version de ligne pour éviter les scénarios où les lecteurs bloquent les enregistreurs.
Dans de rares cas, si une transaction d'isolement de capture instantanée accède à des métadonnées d'objet qui ont été modifiées dans une autre transaction simultanée, elle peut recevoir l'erreur 3961, « La transaction d'isolement de capture instantanée a échoué dans la base de données '%.*ls' car l'objet auquel l'instruction a eu accès a été modifié par une instruction DDL dans une autre transaction simultanée depuis le début de cette transaction. Elle est rejetée, car les métadonnées ne font pas l’objet d’une gestion des versions. Une mise à jour simultanée des métadonnées peut provoquer des incohérences si elle est combinée avec un isolement de capture instantanée. »
Requêtes longues sur les réplicas en lecture seule
Les requêtes exécutées sur des répliques en lecture seule doivent accéder aux métadonnées des objets référencés dans la requête (tables, index, statistiques, etc.) Dans de rares cas, si les métadonnées d'un objet sont modifiées sur la réplique primaire alors qu'une requête détient un verrou sur le même objet sur la réplique en lecture seule, la requête peut bloquer le processus qui applique les modifications de la réplique primaire à la réplique en lecture seule. Traduit avec www.DeepL.com/Translator (version gratuite) Si une telle requête devait s'exécuter pendant une longue période, elle entraînerait une désynchronisation importante entre le réplica en lecture seule et le réplica principal. Pour les répliques qui sont des cibles potentielles de basculement (répliques secondaires dans les niveaux de service Premium et Business Critical, répliques Hyperscale HA et toutes les répliques géographiques), cela retarderait également la récupération de la base de données si un basculement devait se produire, ce qui entraînerait des temps d'arrêt plus longs que prévu.
Si une requête de longue durée sur une réplique en lecture seule provoque directement ou indirectement ce type de blocage, elle peut être automatiquement interrompue pour éviter une latence excessive des données et un impact potentiel sur la disponibilité de la base de données. La session reçoit l’erreur 1219 « Votre session a été déconnectée en raison d'une opération DDL de priorité supérieure », ou l’erreur 3947 « La transaction a été abandonnée parce que le calcul secondaire n’a pas réussi à rattraper la phase de restauration par progression. Réessayez d’exécuter la transaction. »
Notes
Si vous recevez l'erreur 3961, 1219 ou 3947 lors de l'exécution de requêtes sur un réplica en lecture seule, relancez la requête. Sinon, évitez les opérations qui modifient les métadonnées des objets (changements de schémas, maintenance des index, mises à jour des statistiques, etc.) sur la réplique primaire pendant que les requêtes de longue durée s'exécutent sur les répliques secondaires.
Conseil
Aux niveaux de service Premium et Critique pour l’entreprise, en cas de connexion à un réplica en lecture seule, les colonnes redo_queue_size et redo_rate de la vue de gestion dynamique sys.dm_database_replica_states peuvent être utilisées pour surveiller le processus de synchronisation des données et servir d’indicateurs de latence de propagation des données sur le réplica en lecture seule.
Activer et désactiver l’échelle horizontale en lecture pour SQL Database
Pour SQL Managed Instance, le scale-out horizontal en lecture est automatiquement activé sur le niveau de service Critique pour l’entreprise, mais il n’est pas disponible dans le niveau de service Usage général. La désactivation et la réactivation du scale-out horizontal en lecture ne sont pas possibles.
Pour SQL Database, l’échelle horizontale en lecture est activée par défaut sur les niveaux de service Premium, Vital pour l’entreprise et Hyperscale. Le scale-out horizontal en lecture ne peut pas être activé dans les niveaux de service De base, Standard ou Usage général. La mise à l'échelle en lecture est automatiquement désactivée sur les bases de données Hyperscale configurées avec zéro réplique secondaire.
Pour les bases de données uniques et mises en pool dans Azure SQL Database, vous pouvez désactiver et réactiver l’échelle horizontale en lecture dans les niveaux de service Premium ou Vital pour l’entreprise à l’aide du Portail Azure et d’Azure PowerShell. Ces options ne sont pas disponibles pour SQL Managed Instance, car le scale-out horizontal en lecture ne peut pas être désactivé.
Notes
Pour les bases de données uniques et les bases de données de pool élastique, la possibilité de désactiver l'échelle horizontale en lecture est fournie à des fins de compatibilité descendante. L'échelle horizontale en lecture ne peut pas être désactivée sur les instances gérées de niveau Critique pour l'entreprise.
Portail Azure
Pour Azure SQL Database, vous pouvez gérer le paramètre de scale-out horizontal en lecture dans le volet de base de données Calcul + stockage, situé sous Paramètres. L’utilisation du portail Azure pour activer ou désactiver le scale-out horizontal en lecture n’est pas possible pour Azure SQL Managed Instance.
PowerShell
Important
Le module PowerShell Azure Resource Manager est toujours pris en charge, mais tous les développements à venir sont destinés au module Az.Sql. Le module Azure Resource Manager continuera à recevoir des résolutions de bogues jusqu’à au moins décembre 2020. Les arguments des commandes dans le module Az sont sensiblement identiques à ceux des modules Azure Resource Manager. Pour plus d’informations sur leur compatibilité, consultez Présentation du nouveau module Az Azure PowerShell.
La gestion de l’échelle horizontale en lecture dans Azure PowerShell nécessite la version d’Azure PowerShell de décembre 2016 ou plus récente. Pour obtenir la version de PowerShell la plus récente, consultez Azure PowerShell.
Dans Azure SQL Database, vous pouvez activer ou désactiver l’échelle horizontale en lecture dans Azure PowerShell en appelant l’applet de commande Set-AzSqlDatabase et en transmettant la valeur souhaitée (Enabled ou Disabled) pour le paramètre -ReadScale. La désactivation du scale-out horizontal en lecture pour SQL Managed Instance n’est pas possible.
Pour désactiver la fonctionnalité Échelle horizontale en lecture sur une base de données existante (en remplaçant les éléments entre crochets angulaires par les valeurs correctes pour votre environnement et en supprimant ces crochets) :
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled
Pour désactiver la fonctionnalité Échelle horizontale en lecture sur une base de données existante (en remplaçant les éléments entre crochets angulaires par les valeurs correctes pour votre environnement et en supprimant ces crochets) :
New-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled -Edition Premium
Pour réactiver la fonctionnalité Échelle horizontale en lecture sur une base de données existante (en remplaçant les éléments entre crochets angulaires par les valeurs correctes pour votre environnement et en supprimant ces crochets) :
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Enabled
API REST
Pour créer une base de données avec échelle horizontale en lecture désactivée, ou pour modifier le paramétrage d’une base de données existante, utilisez la méthode suivante avec la propriété readScale définie sur Enabled ou Disabled, comme dans l’exemple de requête suivant.
Method: PUT
URL: https://management.azure.com/subscriptions/{SubscriptionId}/resourceGroups/{GroupName}/providers/Microsoft.Sql/servers/{ServerName}/databases/{DatabaseName}?api-version= 2014-04-01-preview
Body: {
"properties": {
"readScale":"Disabled"
}
}
Pour plus d’informations, consultez Bases de données - Créer ou mettre à jour.
Utiliser la base de données tempdb sur un réplica en lecture seule
La base de données tempdb du réplica principal n’est pas répliquée sur les réplicas en lecture seule. Chaque réplica possède sa propre base de données tempdb générée lors de la création du réplica. Il vérifie que la base de données tempdb peut être mise à jour et modifiée pendant l'exécution de votre requête. Si votre charge de travail en lecture seule dépend de l'utilisation d'tempdbobjets, vous devez créer ces objets dans le cadre de la même charge de travail, tout en étant connecté à une réplique en lecture seule.
Utiliser le scale-out horizontal en lecture avec des bases de données géorépliquées
Les bases de données secondaires géo-répliquées ont la même architecture de haute disponibilité que les bases de données primaires. Si vous vous connectez à la base de données secondaire géorépliquée et que le scale-out horizontal en lecture est activé, vos sessions avec ApplicationIntent=ReadOnly sont routées vers l’un des réplicas haute disponibilité de la même façon que sur la base de données primaire accessible en écriture. Les sessions sans ApplicationIntent=ReadOnly sont routées vers le réplica principal de la base de données secondaire géorépliquée, qui est également en lecture seule.
De cette façon, la création d'une géo-réplique peut fournir plusieurs répliques supplémentaires en lecture seule pour une base de données primaire en lecture-écriture. Chaque géo-réplique supplémentaire fournit un autre ensemble de répliques en lecture seule. Des géo-réplicas peuvent être créés dans n'importe quelle région Azure, y compris dans la région de la base de données primaire.
Notes
Il n'y a pas de round-robin automatique ou tout autre routage équilibré en fonction de la charge entre les répliques d'une base de données secondaire géo-répliquée, à l'exception d'une géo-réplique Hyperscale avec plus d'une réplique HA. Dans ce cas, les sessions avec une intention de lecture seule sont distribuées sur toutes les répliques HA d'une géo-réplique.
Prise en charge des fonctionnalités sur les réplicas en lecture seule
Voici une liste des comportements de certaines fonctionnalités sur les réplicas en lecture seule :
- L’audit est activé automatiquement sur les réplicas en lecture seule. Pour plus d’informations sur la hiérarchie des dossiers de stockage, les conventions de nommage et le format des journaux, consultez Format des journaux d’audit SQL Database.
- Query Performance Insight s’appuie sur les données du Magasin des requêtes, qui à l’heure actuelle n’effectue pas le suivi de l’activité sur le réplica en lecture seule. Query Performance Insight n’affiche donc pas les requêtes qui s’exécutent sur le réplica en lecture seule.
- Le réglage automatique s’appuie sur le Magasin des requêtes (cf. document sur le réglage automatique). Il ne fonctionne que pour les charges de travail qui s’exécutent sur le réplica principal.
Étapes suivantes
- Pour plus d’informations sur l’offre SQL Database Hyperscale, voir Niveau de service Hyperscale.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour