Vue d’ensemble des groupes de basculement automatique et meilleures pratiques (Azure SQL Managed Instance)
S’applique à : ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Les groupes de basculement vous permettent de gérer la réplication et le basculement de toutes les bases de données utilisateur d’une instance gérée vers une autre région Azure. Cet article fournit une vue d’ensemble de la fonctionnalité de groupe de basculement avec les meilleures pratiques et recommandations pour l’utiliser avec Azure SQL Managed Instance.
Pour commencer à utiliser la fonctionnalité, consultez Configurer un groupe de basculement pour Azure SQL Managed Instance.
Vue d’ensemble
La fonctionnalité de groupes de basculement vous permet de gérer la réplication et le basculement de bases de données utilisateur d’une instance gérée vers une autre dans une autre région Azure. Les groupes de basculement sont conçus pour simplifier le déploiement et la gestion des bases de données géorépliquées à grande échelle.
Pour plus d’informations, consultez Haute disponibilité pour Azure SQL Managed Instance. Pour effectuer un géobasculement des données d’objectif de point (RPO) et de délai de récupération (RTO), consultez vue d’ensemble de la continuité d’activité.
Redirection de point de terminaison
Les groupes de basculement fournissent des points de terminaison d’écouteur de lecture-écriture et de lecture seule qui restent inchangés pendant les géobasculements. Vous ne devez pas modifier la chaîne de connexion de votre application après un géobasculement, car les connexions sont automatiquement acheminées vers la base de données primaire actuelle. Un géobasculement bascule toutes les bases de données secondaires du groupe dans le rôle principal. Une fois que le géobasculement se complète, l’enregistrement DNS est automatiquement mis à jour pour rediriger les points de terminaison vers la nouvelle région.
Déplacer des charges de travail en lecture seule
Pour réduire le trafic vers vos bases de données primaires, vous pouvez également utiliser les bases de données secondaires dans un groupe de basculement pour décharger les charges de travail en lecture seule. Utilisez l'écouteur en lecture seule pour diriger le trafic en lecture seule vers une base de données secondaire lisible.
Récupération d’une application
Pour arriver à une continuité d’activité totale, l’ajout d’une redondance de base de données régionale n’est qu’une partie de la solution. La récupération d’une application (service) de bout en bout après une défaillance catastrophique implique la récupération de tous les composants constituant le service et tous les services dépendants. En voici quelques exemples : logiciel client (il peut s’agir par exemple d’un navigateur avec un code JavaScript personnalisé), serveurs web frontaux, ressources de stockage et DNS. Il est essentiel que tous les composants résistent aux mêmes défaillances et redeviennent disponibles dans l'objectif de délai de récupération (RTO) de votre application. Par conséquent, vous devez identifier tous les services dépendants et comprendre les garanties et les fonctionnalités qu’ils fournissent. Ensuite, vous devez prendre les mesures appropriées pour vous assurer que votre service fonctionne pendant le basculement des services dont il dépend.
Stratégie de basculement
Les groupes de basculement prennent en charge deux stratégies de basculement :
- Client géré (recommandé) - Les clients peuvent effectuer un basculement d’un groupe lorsqu’ils remarquent une panne inattendue impactant une ou plusieurs bases de données dans le groupe de basculement. Lorsque vous utilisez des outils en ligne de commande tels que PowerShell, Azure CLI ou l’API Rest, la valeur de la stratégie de basculement pour le client géré est
manual. - Géré par Microsoft : en cas de panne généralisée qui a un impact sur une région primaire, Microsoft lance le basculement de tous les groupes de basculement affectés dont la stratégie de basculement est configurée pour être gérée par Microsoft. Le basculement géré par Microsoft ne sera pas lancé pour des groupes de basculement individuels ou un sous-ensemble de groupes de basculement dans une région. Lorsque vous utilisez des outils en ligne de commande tels que PowerShell, Azure CLI ou l’API Rest, la valeur de la stratégie de basculement pour géré par Microsoft est
automatic.
Chaque stratégie de basculement a un ensemble unique de cas d’usage et des attentes correspondantes sur l’étendue de basculement et la perte de données, comme le tableau suivant récapitule :
| Stratégie de basculement | Étendue de basculement | Cas d’usage | Perte de données potentielle |
|---|---|---|---|
| Managée par le client (Conseillé) |
Groupe(s) de basculement | Une ou plusieurs bases de données d’un ou plusieurs groupes de basculement sont affectées par une panne et deviennent indisponibles. Vous pouvez choisir de basculer. | Oui |
| Géré par Microsoft | Tous les groupes de basculement dans la région | Une panne généralisée dans un centre de données, une zone de disponibilité ou une région entraîne l’indisponibilité des bases de données et l’équipe de service Microsoft Azure SQL décide de déclencher un basculement forcé. Utilisez cette option uniquement lorsque vous souhaitez déléguer la responsabilité de récupération d’urgence à Microsoft et que l’application est tolérante au RTO (temps d’arrêt) d’au moins une heure ou plus. |
Oui |
Managée par le client
Dans de rares cas, la disponibilité prédéfinie ou la haute disponibilité n’est pas suffisante pour atténuer une panne, et vos bases de données dans un groupe de basculement peuvent ne pas être disponibles pendant une durée qui n’est pas acceptable pour le contrat de niveau de service (contrat SLA) des applications utilisant les bases de données. Les bases de données peuvent être indisponibles en raison d’un problème localisé qui n’a qu’un impact sur quelques bases de données, ou peut être au niveau du centre de données, de la zone de disponibilité ou de la région. Dans l’un de ces cas, pour restaurer la continuité d’activité, vous pouvez lancer un basculement forcé.
La définition de votre stratégie de basculement sur gérée par le client est vivement recommandée, car elle vous permet de contrôler quand lancer un basculement et restaurer la continuité d’activité. Vous pouvez lancer un basculement lorsque vous remarquez une panne inattendue impactant une ou plusieurs bases de données dans le groupe de basculement.
Géré par Microsoft
Avec une stratégie de basculement géré par Microsoft, la responsabilité de la récupération d’urgence est déléguée au service Azure SQL. Pour que le service Azure SQL lance un basculement forcé, les conditions suivantes doivent être remplies :
- Les pannes au niveau du centre de données, de la zone de disponibilité ou de la région causées par un événement de sinistre naturel, des modifications de configuration, des bogues logiciels ou des défaillances de composants matériels et de nombreuses bases de données de la région sont affectées.
- La période de grâce a expiré. Étant donné que la vérification de l’ampleur de la panne et son atténuation dépendent des actions humaines, la période de grâce ne peut pas être inférieure à une heure.
Lorsque ces conditions sont remplies, le service Azure SQL lance des basculements forcés pour tous les groupes de basculement de la région dont la stratégie de basculement est définie sur Microsoft gérée.
Important
Utilisez la politique de basculement géré par le client pour tester et implémenter vos plans de récupération d’urgence. Ne comptez pas sur le basculement géré par Microsoft, qui ne peut être exécuté par Microsoft que dans des circonstances extrêmes. Un basculement géré par Microsoft serait lancé pour tous les groupes de basculement de la région dont la politique de basculement est définie sur Microsoft gérée. Il ne peut pas être lancé pour un groupe de basculement individuel. Si vous avez besoin de la possibilité de basculer de manière sélective votre groupe de basculement, utilisez la politique de basculement gérée par le client.
Définissez la stratégie de basculement sur Microsoft gérée uniquement quand :
- Vous souhaitez déléguer la responsabilité de récupération d’urgence au service Azure SQL.
- L’application est tolérante à l’indisponibilité de votre base de données pendant au moins une heure ou plusieurs.
- Il est acceptable de déclencher des basculements forcés un certain temps après l’expiration de la période de grâce, car le temps réel du basculement forcé peut varier considérablement.
- Il est acceptable que toutes les bases de données au sein du groupe de basculement basculent, quelle que soit leur configuration de redondance de zone ou leur état de disponibilité. Bien que les bases de données configurées pour la redondance de zone soient résilientes aux défaillances zonales et puissent ne pas être affectées par une panne, elles seront toujours en échec si elles font partie d’un groupe de basculement avec une stratégie de basculement gérée par Microsoft.
- Il est acceptable d’avoir des basculements forcés de bases de données dans le groupe de basculement sans tenir compte de la dépendance de l’application à d’autres services ou composants Azure utilisés par l’application, ce qui peut entraîner une détérioration des performances ou une indisponibilité de l’application.
- Il est acceptable d’encourir une quantité inconnue de perte de données, car l’heure exacte du basculement forcé ne peut pas être contrôlée et ignore l’état de synchronisation des bases de données secondaires.
- Toutes les bases de donnée(s) primaire(s) et secondaire(s) du groupe de basculement et toutes les relations de réplication de zone géographique ont le même niveau de service, le même niveau de Capacité de calcul (approvisionné ou sans serveur) et la même taille de calcul (DTU ou vCores). Si l'objectif de niveau de service (SLO) de toutes les bases de données ne correspond pas, la stratégie de basculement sera éventuellement mise à jour de Microsoft Managed à Customer Managed par Azure SQL service.
Lorsqu’un basculement est déclenché par Microsoft, une entrée pour le nom de l’opération Basculement du groupe de basculement Azure SQL est ajouté au journal d’activité Azure Monitor. L’entrée inclut le nom du groupe de basculement sous Ressource et Événement lancé par un seul trait d’union (-) pour indiquer que le basculement a été lancé par Microsoft. Ces informations sont également disponibles dans la page Journal d’activité du nouveau serveur principal ou instance du Portail Azure.
Terminologie et fonctionnalités
Groupe de basculement (FOG)
Un groupe de basculement permet à toutes les bases de données utilisateur d'une instance gérée de basculer en tant qu'unité vers une autre région Azure si l'instance gérée primaire devient indisponible en raison d'une panne de la région primaire. Comme les groupes de basculement pour SQL Managed Instance contiennent toutes les bases de données utilisateur dans l'instance, un seul groupe de basculement peut être configuré sur une instance.
Important
Le nom du groupe de basculement doit être unique à l’échelle globale dans le domaine
.database.windows.net.Primaire
L’instance gérée qui héberge les bases de données primaires dans le groupe de basculement.
Secondaire
L’instance gérée qui héberge les bases de données secondaires dans le groupe de basculement. Le serveur logique secondaire ne peut pas être situé dans la même région Azure que le serveur logique primaire.
Important
Si une base de données contient des objets OLTP en mémoire, l’instance de géo-réplica primaire et secondaire doivent avoir des niveaux de service correspondants, car les objets OLTP en mémoire résident toujours en mémoire. Un niveau de service inférieur sur l’instance géo-réplica peut entraîner des problèmes de manque de mémoire. Si cela se produit, le réplica secondaire pourrait ne pas récupérer la base de données, ce qui entraîne l’indisponibilité de la base de données secondaire, ainsi que des objets OLTP en mémoire sur la base de données géo-secondaire. Cela pourrait ensuite entraîner l’échec du basculement. Pour éviter cela, assurez-vous que le niveau de service de l’instance géo-secondaire correspond à celui de la base de données primaire. Les mises à niveau des niveaux de service peuvent être des opérations dépendant de la taille des données, et peuvent prendre un certain temps.
Basculement (aucune perte de données)
Le basculement effectue une synchronisation de données complète entre les bases de données primaire et secondaire avant que la seconde ne bascule dans le rôle primaire. Cela empêche toute perte de données. Le basculement n’est possible que lorsque le serveur principal est accessible. Le basculement des appareils est utilisé dans les scénarios suivants :
- Simuler des récupérations d’urgence (DR) en production lorsque la perte de données n’est pas acceptable
- Déplacer la charge de travail vers une autre région
- Renvoyer la charge de travail vers la région primaire une fois la panne éliminée (restauration automatique)
Basculement forcé (perte de données potentielle)
Le basculement forcé bascule immédiatement la base de données secondaire vers le rôle primaire sans attendre que les modifications récentes soient propagées à partir de la base de données primaire. Cette opération peut occasionner une perte de données potentielle. Le basculement forcé est utilisé comme méthode de récupération pendant les pannes, lorsque la base de données primaire n’est pas accessible. Lorsque la panne est atténuée, l’ancienne base de données primaire se reconnecte automatiquement et devient une nouvelle base de données secondaire. Un basculement peut être exécuté pour la restauration automatique, en retournant les réplicas à leurs rôles primaires et secondaires d’origine.
Période de grâce avec perte de données
Étant donné que les données sont répliquées vers la base de données secondaire à l’aide d’une réplication asynchrone, le basculement forcé de groupes avec des stratégies de basculement gérés par Microsoft peut entraîner une perte de données. Vous pouvez personnaliser la stratégie de basculement en fonction de la tolérance de votre application à la perte de données. En configurant
GracePeriodWithDataLossHours, vous pouvez contrôler le délai observé par le service Azure SQL avant d’initier un basculement forcé qui peut entraîner une perte de données.
Zone DNS
ID unique qui est généré automatiquement lorsqu’une instance SQL Managed Instance est créée. Un certificat multidomaine (SAN) est approvisionné pour cette instance afin d’authentifier les connexions clientes effectuées auprès de toutes les instances présentes dans la même zone DNS. Les deux instances gérées d’un même groupe de basculement doivent partager la zone DNS.
Écouteur en lecture-écriture du groupe de basculement
Un enregistrement DNS CNAME qui pointe vers le serveur primaire actuel. Il est généré automatiquement lorsque le groupe de basculement est créé, et permet à la charge de travail en lecture-écriture de se reconnecter en toute transparence au serveur primaire une fois modifié après le basculement. Lorsque le groupe de basculement est créé sur une instance SQL Managed Instance, l’enregistrement DNS CNAME pour l’URL de l’écouteur est formé comme suit :
<fog-name>.<zone_id>.database.windows.net.Écouteur en lecture seule du groupe de basculement
Un enregistrement DNS CNAME qui pointe vers le serveur secondaire actuel. Il est créé automatiquement lorsque le groupe de basculement est créé et permet à la charge de travail SQL en lecture seule de se connecter en toute transparence au serveur secondaire une fois modifié après le basculement. Lorsque le groupe de basculement est créé sur une instance SQL Managed Instance, l’enregistrement DNS CNAME pour l’URL de l’écouteur est formé comme suit :
<fog-name>.secondary.<zone_id>.database.windows.net. Par défaut, le basculement de l’écouteur en lecture seule est désactivé, car il garantit que les performances du serveur principal ne sont pas affectées lorsque le serveur secondaire est hors connexion. Toutefois, cela signifie également que les sessions en lecture seule ne sont pas en mesure de se connecter tant que le serveur secondaire n’a pas été récupérée. Si vous ne pouvez pas tolérer des temps d’arrêt pour les sessions en lecture seule et que vous pouvez utiliser le serveur principal pour le trafic en lecture seule et en lecture-écriture au prix d’une dégradation potentielle des performances du serveur principal, vous pouvez activer le basculement pour l’écouteur en lecture seule en configurant la propriétéAllowReadOnlyFailoverToPrimary. Dans ce cas, le trafic en lecture seule est automatiquement redirigé vers le serveur principal si le serveur secondaire est indisponible.Remarque
La propriété
AllowReadOnlyFailoverToPrimaryn’a d’effet que si la stratégie de basculement gérée par Microsoft est activée et qu’un basculement forcé a été déclenché. Dans ce cas, si la propriété est définie sur True, le nouveau serveur principal servira les sessions en lecture-écriture et en lecture seule.
Architecture du groupe de basculement
Le groupe de basculement doit être configuré sur l’instance primaire, qu’il connectera à l’instance secondaire dans une autre région Azure. Toutes les bases de données utilisateur de l’instance seront répliquées sur l’instance secondaire. Les bases de données système telles que master et msdb ne sont pas répliquées.
Le diagramme suivant illustre la configuration standard d’une application cloud géoredondante avec une instance managée et un groupe de basculement :
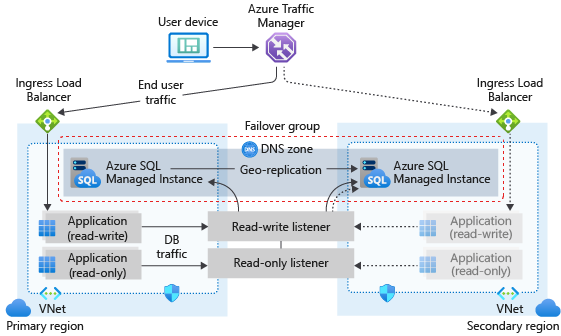
Si votre application utilise SQL Managed Instance comme niveau de données, suivez les directives générales et les meilleures pratiques décrites dans cet article lors de la conception des éléments en rapport avec la continuité d’activité.
Créer l’instance géosecondaire
Pour garantir une connectivité ininterrompue à l’instance SQL Managed Instance principale après le basculement, les instances principale et secondaire doivent se trouver dans la même zone DNS. Cela garantit que le même certificat multidomaine (SAN) peut être utilisé pour authentifier les connexions clientes avec les deux instances du groupe de basculement. Lorsque votre application est prête pour le déploiement en production, créez une instance SQL Managed Instance secondaire dans une autre région et assurez-vous qu’elle partage la même zone DNS que l’instance SQL Managed Instance principale. Vous pouvez y parvenir en spécifiant un paramètre facultatif au moment de la création. Si vous utilisez PowerShell ou l’API REST, le nom du paramètre facultatif est DNSZonePartner. Le nom du champ facultatif correspondant dans le portail Azure est Instance managée principale.
Important
La première instance gérée créée dans le sous-réseau détermine la zone DNS pour toutes les instances suivantes de ce même sous-réseau. Cela signifie que deux instances d’un même sous-réseau ne peuvent pas appartenir à des zones DNS différentes.
Pour plus d’informations sur la création de l’instance SQL Managed Instance secondaire dans la même zone DNS que l’instance principale, consultez Configurer un groupe de basculement pour Azure SQL Managed Instance.
Utiliser des régions jumelées
Déployez les deux instances managées dans des régions jumelées pour des raisons de performances. Les groupes de basculement SQL Managed Instance dans les régions jumelées offrent de meilleures performances par rapport aux régions non jumelées.
Azure SQL Managed Instance se conforme à une pratique de déploiement sécurisée qui garantit généralement que des régions Azure jumelées ne sont pas déployées en même temps. Toutefois, il n’est pas possible de prédire quelle région sera mise à niveau en premier ; ainsi l’ordre de déploiement n’est pas garanti. Parfois, votre instance principale est mise à niveau en premier, et parfois l’instance secondaire est mise à niveau en premier.
Dans les situations où Azure SQL Managed Instance fait partie d’un groupe de basculement et où les instances du groupe ne se trouvent pas dans des régions jumelées Azure, sélectionnez différentes planifications de fenêtres de maintenance pour votre base de données principale et secondaire. Par exemple, vous pouvez choisir une fenêtre de maintenance Jour ouvrable pour votre base de données géosecondaire et une fenêtre de maintenance Week-end pour votre base de données géoprimaire.
Activer et optimiser le flux de trafic de géoréplication entre les instances
La connectivité entre les sous-réseaux de réseau virtuel hébergeant les instances principale et secondaire doit être établie et gérée pour un flux de trafic de géoréplication ininterrompu. Il existe plusieurs façons de fournir une connectivité entre les instances parmi lesquelles vous pouvez choisir en fonction de la topologie et des stratégies de votre réseau :
L’appairage mondial de réseaux virtuels (VNet Peering) est la méthode recommandée pour établir la connectivité entre deux instances dans un groupe de basculement. Il fournit une connexion privée à faible latence et à bande passante élevée entre les réseaux virtuels appairés à l’aide de l’infrastructure principale de Microsoft. Aucun chiffrement supplémentaire et aucune connexion Internet publique, ni passerelle ne sont nécessaires pour que les réseaux virtuels d’homologues communiquent.
Amorçage initial
Lors de l’établissement d’un groupe de basculement entre des instances managées, il existe une phase d’amorçage initiale avant le démarrage de la réplication des données. La phase d’amorçage initiale est la partie de l’opération la plus longue et la plus coûteuse. Une fois l’amorçage initial terminé, les données sont synchronisées, puis seules les modifications de données ultérieures sont répliquées. Le temps nécessaire à l’amorçage initial dépend de la taille des données, du nombre de bases de données répliquées, de l’intensité de la charge de travail sur les bases de données primaires et de la vitesse de la liaison entre les réseaux virtuels hébergeant les instances principales et secondaires qui dépend principalement de la façon dont la connectivité est établie. Dans des circonstances normales et lorsque la connectivité est établie à l’aide du peering de réseaux virtuels globaux recommandé, la vitesse d’amorçage est de 360 Go par heure pour SQL Managed Instance. L’amorçage est effectué pour un lot de bases de données utilisateur en parallèle, pas nécessairement pour toutes les bases de données en même temps. Plusieurs lots peuvent être nécessaires s’il existe de nombreuses bases de données hébergées sur l’instance.
Si la vitesse de la liaison entre les deux instances est plus lente que nécessaire, la durée de l’amorçage risque d’être sensiblement affectée. Vous pouvez utiliser la vitesse d’amorçage indiquée, ainsi que le nombre de bases de données, la taille totale des données et la vitesse de liaison pour estimer la durée de la phase d’amorçage initiale avant le début de la réplication des données. Par exemple, pour une base de données unique de 100 Go, la phase d’amorçage initiale prendra environ 1,2 heure si la liaison est capable d’envoyer (push) 84 Go par heure, et si aucune autre base de données n’est en cours d’amorçage. Si la liaison ne peut transférer que 10 Go par heure, l’amorçage d’une base de données de 100 Go prendra environ 10 heures. S’il faut répliquer plusieurs bases de données, l’amorçage est effectué en parallèle et, lorsqu’il est associé à une vitesse de liaison lente, la phase d’amorçage initiale peut prendre beaucoup plus de temps. Cela est particulièrement vrai si l’amorçage parallèle des données de toutes les bases de données est supérieur à la bande passante de liaison disponible.
Important
Dans le cas d’une liaison à très faible vitesse ou occupée qui fait que la phase d’amorçage initiale prend des jours, la création d’un groupe de basculement peut se prolonger. Le processus de création sera automatiquement annulé après 6 jours.
Gérer le géobasculement dans une instance géosecondaire
Le groupe de basculement gère le géobasculement de toutes les bases de données sur l’instance managée principale. Lorsqu’un groupe est créé, chaque base de données de l’instance est automatiquement géorépliquée sur l’instance géosecondaire. Vous ne pouvez pas utiliser les groupes de basculement pour lancer le basculement partiel d’un sous-ensemble de bases de données.
Important
Si une base de données est abandonnée sur l’instance managée principale, elle est auss abandonnée automatiquement sur l’instance managée géosecondaire.
Utiliser l’écouteur en lecture-écriture (instance managée principale)
Pour les charges de travail en lecture-écriture, utilisez <fog-name>.zone_id.database.windows.net comme nom de serveur. Les connexions sont automatiquement dirigées vers la base de données primaire. Ce nom ne change pas après le basculement. Le géobasculement implique la mise à jour de l’enregistrement DNS de façon à ce que les nouvelles connexions clientes soient acheminées vers le nouveau serveur primaire seulement après l’actualisation du cache DNS. Étant donné que l’instance secondaire partage la même zone DNS que l’instance principale, l’application cliente peut se reconnecter à l’aide du même certificat SAN côté serveur. Les connexions clientes existantes doivent être arrêtées, puis recréées pour être acheminées vers le nouveau serveur principal. L’écouteur en lecture/écriture et l’écouteur en lecture seule ne peuvent pas être joints à l’aide du point de terminaison public pour une managed instance.
Utiliser l'écouteur en lecture seule (instance managée secondaire)
Si vous avez des charges de travail en lecture seule isolées logiquement qui sont tolérantes à la latence des données, vous pouvez les exécuter sur l’instance géosecondaire. Pour vous connecter directement à l’instance géosecondaire, utilisez <fog-name>.secondary.<zone_id>.database.windows.net comme nom de serveur.
Dans le niveau Critique pour l’entreprise, SQL Managed Instance prend en charge l’utilisation de réplicas en lecture seule pour décharger des charges de travail de requête en lecture seule, en utilisant le paramètre ApplicationIntent=ReadOnly dans la chaîne de connexion. Lorsque vous avez configuré une instance géorépliquée secondaire, vous pouvez utiliser cette fonction pour vous connecter à un réplica en lecture seule à l’emplacement primaire ou à l’emplacement géorépliqué :
- Pour vous connecter à un réplica en lecture seule à l’emplacement primaire, utilisez
ApplicationIntent=ReadOnlyet<fog-name>.<zone_id>.database.windows.net. - Pour vous connecter à un réplica en lecture seule à l’emplacement secondaire, utilisez
ApplicationIntent=ReadOnlyet<fog-name>.secondary.<zone_id>.database.windows.net.
L’écouteur en lecture/écriture et l’écouteur en lecture seule ne peuvent pas être joints via le point de terminaison public pour une instance gérée.
Dégradation potentielle des performances après le basculement
Une application Azure classique fait appel à plusieurs services Azure et inclut plusieurs composants. Le géobasculement du groupe de basculement est déclenché en fonction de l’état des seuls composants Azure SQL. Il peut arriver que les autres services Azure de la région primaire ne soient pas affectés par la panne et que leurs composants soient toujours disponibles dans cette région. Une fois que les bases de données primaires ont basculé vers la région secondaire, la latence entre les composants dépendants peut augmenter. Vérifiez que tous les composants de l’application sont redondants dans la région secondaire et basculez les composants de l’application en même temps que la base de données afin que les performances de l’application ne soient pas affectées par une latence inter-régionale plus élevée.
Perte potentielle de données après un basculement forcé
Si une panne se produit dans la région primaire, les transactions récentes n’ont peut-être pas été répliquées sur le site géo-secondaire et il peut y avoir une perte de données si un basculement forcé est effectué.
Mise à jour DNS
La mise à jour DNS de l’écouteur en lecture-écriture se produit immédiatement après que le basculement est initié. Cette opération n’entraîne pas de perte de données. Toutefois, le processus de basculement des rôles des bases de données peut prendre jusqu’à 5 minutes dans des conditions normales. En attendant, certaines bases de données de la nouvelle instance principale resteront en lecture seule. Si un basculement est initié à l’aide de PowerShell, l’opération permettant de basculer le rôle de réplica principal est synchrone. S’il est initié à l’aide du portail Azure, l’interface utilisateur indique la progression. S’il est démarré via l’API REST, utilisez le mécanisme d’interrogation standard d’Azure Resource Manager pour en surveiller la progression.
Important
Utilisez le basculement planifié manuel pour ramener le réplica principal à l’emplacement d’origine une fois que la panne qui a provoqué le géobasculement est réparée.
Faites des économies avec un réplica DR (reprise d’activité après sinistre) sans licence
Vous pouvez faire des économies sur les coûts de licence SQL Server en configurant votre instance managée secondaire pour qu’elle soit utilisée uniquement dans le cadre d’une reprise d’activité après sinistre. Pour réaliser cette configuration, consultez Configurer un réplica en attente sans licence pour Azure SQL Managed Instance.
Tant que l’instance secondaire n’est pas utilisée pour les charges de travail en lecture, Microsoft vous fournit gratuitement un nombre de vCores correspondant à l’instance principale. Vous êtes toujours facturé pour le calcul et le stockage utilisés par l’instance secondaire. Les groupes de basculement ne prennent en charge qu’un seul réplica. Il doit s’agir d’un réplica accessible en lecture ou d’un réplica DR exclusivement.
Activer les scénarios dépendant des objets des bases de données système
Les bases de données système ne sont pas répliquées vers l’instance secondaire dans un groupe de basculement. Pour permettre les scénarios qui dépendent des objets des bases de données système, assurez-vous de créer les mêmes objets sur l’instance secondaire et de les maintenir synchronisés avec ceux de l’instance primaire.
Par exemple, si vous envisagez d’utiliser les mêmes connexions sur l’instance secondaire, veillez à les créer avec un ID de sécurité identique.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Pour en savoir plus, consultez Réplication des connexions et des tâches de l’agent.
Synchronisation des propriétés des instances et des instances de stratégies de rétention
Les instances d’un groupe de basculement restent des ressources Azure distinctes, et aucune modification apportée à la configuration de l’instance primaire n’est automatiquement répliquée sur l’instance secondaire. Veillez à effectuer toutes les modifications pertinentes à la fois sur l’instance primaire et sur l’instance secondaire. Par exemple, si vous modifiez la redondance du stockage de sauvegarde ou la stratégie de rétention des sauvegardes à long terme sur l’instance primaire, veillez à la modifier également sur l’instance secondaire.
Mettre à l’échelle les instances
Vous pouvez effectuer un scale-up ou un scale-down des instances primaires et secondaires à une taille de calcul différente au sein du même niveau de service ou vers un autre niveau de service. Lors du scale-up au sein du même niveau de service, nous vous recommandons de commencer par la base de données géo-secondaire, puis de terminer avec la base de données primaire. Lors du scale-down au sein du même niveau de service, inversez l’ordre : commencez par la base de données primaire, puis terminez par la base de données secondaire. Quand vous faites passer une instance à un niveau de service supérieur ou inférieur, cette recommandation s’applique. La séquence d’opérations est appliquée lors de la mise à l’échelle du niveau de service et des vCores, ainsi que du stockage.
La séquence est recommandée dans le but spécifique d’éviter le problème de surcharge des bases de données géosecondaires avec une référence SKU inférieure. Celles-ci doivent alors être réalimentées dans le cadre du passage à une version ultérieure ou antérieure.
Important
- Pour les instances à l’intérieur d’un groupe de basculement, la modification du niveau de service vers ou depuis le niveau Usage général nouvelle génération n’est pas prise en charge. Vous devez d’abord supprimer le groupe de basculement avant de modifier l’une ou l’autre réplica, puis recréer le groupe de basculement une fois que la modification a pris effet.
- Un problème connu peut avoir un impact sur l’accessibilité de l’instance mise à l’échelle en utilisant l’écouteur de groupe de basculement associé.
Empêcher la perte de données critiques
En raison de la latence élevée des réseaux étendus, la géoréplication utilise un mécanisme de réplication asynchrone. La réplication asynchrone rend la possibilité de perte de données inévitable en cas de défaillance de la base de données primaire. Pour protéger les transactions critiques d’une perte de données, le développeur d’applications peut appeler la procédure stockée sp_wait_for_database_copy_sync immédiatement après la validation de la transaction. L’appel de sp_wait_for_database_copy_sync bloque le thread appelant jusqu’à ce que la dernière transaction validée ait été transmise et renforcée dans le journal des transactions de la base de données secondaire. Toutefois, il n’attend pas que les transactions transmises soient relues (réeffectuées) sur la base de données secondaire. sp_wait_for_database_copy_sync est limité à un lien de géoréplication spécifique. Tout utilisateur disposant de droits de connexion à la base de données primaire peut appeler cette procédure.
Pour éviter toute perte de données durant le géobasculement planifié lancé par l’utilisateur, la réplication passe automatiquement et temporairement en mode de réplication synchrone, puis effectue un basculement. La réplication revient ensuite en mode asynchrone une fois le géobasculement terminé.
Remarque
sp_wait_for_database_copy_sync empêche la perte de données après un géobasculement pour des transactions spécifiques, mais ne garantit pas une synchronisation complète pour l’accès en lecture. Le délai causé par un appel de procédure sp_wait_for_database_copy_sync peut être significatif et dépend de la taille du journal des transactions pas encore transmis à la base de données primaire au moment de l’appel.
État du groupe de basculement
Le groupe de basculement signale son état qui décrit l’état actuel de la réplication des données :
- Amorçage : Amorçage initial a lieu après la création du groupe de basculement, jusqu’à ce que toutes les bases de données utilisateur soient initialisées sur l’instance secondaire. Impossible de démarrer le processus de basculement lorsque le groupe de basculement est dans l’état d’amorçage, car les bases de données utilisateur ne sont pas encore copiées vers l’instance secondaire.
- Synchronisation : état habituel du groupe de basculement. Cela signifie que les modifications de données sur l’instance principale sont répliquées de façon asynchrone sur l’instance secondaire. Cet état ne garantit pas que les données sont entièrement synchronisées à tout moment. Des modifications de données de la base de données primaire peuvent toujours être répliquées sur la base de données secondaire en raison de la nature asynchrone du processus de réplication entre les instances dans le groupe de basculement. Les basculements automatiques et manuels peuvent être lancés alors que le groupe de basculement est dans l’état Synchronisation en cours.
- Basculement en cours : cet état indique qu’un processus de basculement automatique ou manuel est en cours. Aucune modification du groupe de basculement ou des basculements supplémentaires ne peut être lancée lorsque le groupe de basculement est dans cet état.
Restauration automatique
Lorsque les groupes de basculement sont configurés avec une stratégie de basculement gérée par Microsoft, le basculement forcé vers le serveur géosecondaire est lancé lors d’un scénario de catastrophe selon la période de grâce définie. La restauration automatique vers l’ancien serveur principal doit être lancée manuellement.
Interopérabilité des fonctionnalités
Sauvegardes
Une sauvegarde complète est effectuée dans les scénarios suivants :
- Avant le démarrage de l’amorçage initial, lors de la création d’un groupe de basculement.
- Après un basculement.
Une sauvegarde complète est une taille d’opération de données qui ne peut pas être ignorée ou différée, et peut prendre un certain temps. Le temps nécessaire à son exécution dépend de la taille des données, du nombre de bases de données et de l’intensité de la charge de travail sur les bases de données primaires. Une sauvegarde complète peut retarder significativement l’amorçage initial, et peut retarder ou empêcher une opération de basculement sur une nouvelle instance peu après un basculement.
Log Replay Service
Les bases de données migrées vers Azure SQL Managed Instance à l’aide de Log Replay Service (LRS) ne peuvent pas être ajoutées à un groupe de basculement tant que l’étape de basculement n’est pas exécutée. Une base de données migrée avec LRS est dans un état de restauration jusqu’au basculement, et les bases de données dans un état de restauration ne peuvent pas être ajoutées à un groupe de basculement. La tentative de création d’un groupe de basculement avec une base de données dans un état de restauration retarde la création du groupe de basculement jusqu’à ce que la restauration de la base de données se termine.
Réplication transactionnelle
L’utilisation de la réplication transactionnelle avec des instances qui se trouvent dans un groupe de basculement est prise en charge. Toutefois, si vous configurez la réplication avant d’ajouter votre instance gérée SQL dans un groupe de basculement, la réplication s’interrompt lorsque vous commencez à créer votre groupe de basculement, et le moniteur de réplication affiche l’état Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. La réplication reprend une fois le groupe de basculement créé.
Si une instance SQL Managed Instance de publication ou de distribution se trouve dans un groupe de basculement, l’administrateur de l’instance SQL Managed Instance doit nettoyer toutes les publications de l’ancienne instance principale et les reconfigurer sur la nouvelle instance principale après un basculement. Consultez le guide de réplication transactionnelle pour connaître les activités nécessaires dans ce scénario.
Autorisations et limites
Consultez la liste des autorisations et limitations avant de configurer un groupe de basculement.
Gérer programmatiquement des groupes de basculement
Les groupes de basculement peuvent aussi être gérés programmatiquement en utilisant Azure PowerShell, Azure CLI et l’API REST. Pour plus d’informations, révisez configurer le groupe de basculement.
Exercices de récupération d’urgence
La méthode recommandée pour effectuer une extraction de récupération d’urgence consiste à utiliser le basculement planifié manuel, conformément au tutoriel suivant : Tester le basculement.
L’exécution d’une extraction à l’aide d’un basculement forcé n’est pas recommandée, car cette opération ne fournit pas de garde-fous contre la perte de données. Néanmoins, il est possible d’obtenir un basculement forcé sans perte de données en garantissant que les conditions suivantes sont remplies avant de lancer le basculement forcé :
- La charge de travail est arrêtée sur l’instance managée principale.
- Toutes les transactions de longue durée sont terminées.
- Toutes les connexions clientes à l’instance managée principale ont été déconnectées.
- L’état du groupe de basculement est « Synchronisation ».
Vérifiez que les deux instances managées ont changé de rôle et que l’état du groupe de basculement passe de « Basculement en cours » à « Synchronisation » avant d’établir des connexions à la nouvelle instance managée principale et de démarrer la charge de travail en lecture-écriture.
Pour effectuer une restauration automatique sans perte de données vers les rôles d’instance managée d’origine, l’utilisation d’un basculement planifié manuel au lieu d’un basculement forcé est fortement recommandée. Pour poursuivre la restauration automatique forcée :
- Suivez les mêmes étapes que pour le basculement sans perte de données.
- Une durée d’exécution de restauration automatique plus longue est attendue si la restauration automatique forcée est exécutée peu après la fin du basculement forcé initial, car elle doit attendre la fin des opérations de sauvegarde automatiques en attente sur l’ancienne instance managée principale.
Contenu connexe
- Configurer un groupe de basculement
- Utiliser PowerShell pour ajouter une instance gérée à un groupe de basculement
- Configurer un réplica en attente sans licence pour Azure SQL Managed Instance
- Vue d’ensemble de la continuité d’activité avec Azure SQL Managed Instance
- Sauvegardes automatisées dans Azure SQL Managed Instance
- Restaurer une base de données à partir d’une sauvegarde dans Azure SQL Managed Instance