Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() Azure SQL Database
Azure SQL Database
Cet article fournit une vue d’ensemble de la gestion des ressources pour Azure SQL Database. Il fournit des informations sur ce qui se passe quand les limites de ressources sont atteintes et décrit les mécanismes de gouvernance des ressources utilisés pour appliquer ces limites.
Pour connaître les limites de ressources spécifiques par niveau tarifaire pour les bases de données uniques, reportez-vous aux rubriques suivantes :
- Limites de ressources basées sur des unités DTU : base de données unique
- Limites de ressources basées sur des vCore : base de données unique
Pour connaître les limites de ressources des pools élastiques, reportez-vous à l’une des options suivantes :
- Limites de ressources basées sur des unités DTU : pools élastiques
- Limites de ressources basées sur des vCore : pools élastiques
Pour les limites de capacité du pool SQL dédié dans Azure Synapse Analytics, consultez :
Limites de vCores par abonnement par région
À compter de mars 2024, les abonnements ont les limites de vCores suivantes par région et par abonnement :
| Type d’abonnement | Limites de vCore par défaut |
|---|---|
| Contrat Entreprise (EA) | 2000 |
| Essais gratuits | 10 |
| Microsoft for Startups | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| Paiement à l’utilisation | 150 |
Tenez compte des éléments suivants :
- Ces limites s’appliquent à la fois aux abonnements nouveaux et existants.
- Les bases de données et pools élastiques approvisionnés avec le modèle d’achat DTU sont également comptabilisés par rapport au quota vCore, et inversement. Chaque vCore consommé est considéré comme équivalent à 100 DTU consommés pour le quota au niveau du serveur.
- Les limites par défaut incluent les vCores configurés pour les bases de données de calcul approvisionnées/ pools élastiques et les max vCores configurés pour bases de données serverless.
- Vous pouvez utiliser l’appel d’API REST Utilisations de l’abonnement - Obtenir pour déterminer l’utilisation actuelle de vCores pour votre abonnement.
- Pour demander un quota de vCores supérieur à la valeur par défaut, envoyez une nouvelle demande de support dans le Portail Azure. Pour plus d’informations, consultez Augmentations de quota de demandes pour Azure SQL Database et SQL Managed Instance.
Limites du serveur logique
| Ressource | Limite |
|---|---|
| Bases de données par serveur logique | 5 000 |
| Nombre par défaut de serveurs logiques par abonnement dans une région | 250 |
| Nombre maximal de serveurs logiques par abonnement dans une région | 250 |
| Nombre maximal de pools élastiques par serveur logique | Limité par le nombre de DTU ou de vCores. Par exemple, si chaque pool contient 1 000 unités DTU, alors un serveur peut prendre en charge 54 pools. |
Important
Le nombre de bases de données approchant la limite par serveur logique, ce qui suit peut se produire :
- Augmentation de latence dans l’exécution de requêtes sur la base de données
master. Cela inclut les vues de statistiques d’utilisation des ressources telles quesys.resource_stats. - Augmentation de latence des opérations de gestion et le rendu des points de vue de portails qui impliquent des bases de données sur le serveur.
Que se passe-t-il lorsque les limites de ressources sont atteintes ?
Processeur de calcul
Quand l’utilisation du processeur de calcul de la base de données est élevée, la latence des requêtes augmente et celles-ci peuvent même arriver à expiration. Dans ces conditions, les requêtes pourraient être mises en file d’attente par le service et reçoivent des ressources pour leur exécution lorsque des ressources se libèrent.
Si vous observez une utilisation élevée des calculs, voici certaines des options d’atténuation à votre disposition :
- Augmenter la taille de calcul de la base de données ou du pool élastique pour fournir plus de ressources de calcul à la base de données. Consultez Mise à l’échelle des ressources d’une base de données unique et Mise à l'échelle des ressources d’un pool élastique.
- Optimiser les requêtes pour réduire l’utilisation des ressources du processeur de chaque requête. Pour plus d’informations, consultez la page Paramétrage/Compréhension de requêtes.
Stockage
Lorsque l’espace de données utilisé atteint la limite maximale de taille de données, soit au niveau de la base de données, soit au niveau du pool élastique, insère et met à jour qui augmentent la taille des données échouent, et les clients reçoivent un message d’erreur . Les instructions SELECT et DELETE ne sont pas affectées.
Aux niveaux de service Premium et Critique pour l'entreprise, les clients reçoivent également un message d'erreur si la consommation de stockage combinée des données, du journal des transactions et de tempdb pour une seule base de données ou un pool élastique dépasse la taille maximale prévue pour le stockage local. Pour plus d'informations, consultez Gouvernance de l'espace de stockage.
Si vous observez une utilisation élevée de l’espace de stockage, vos options d’atténuation sont les suivantes :
- Augmentez la taille maximale des données de la base de données ou du pool élastique, ou effectuez un scale-up vers un objectif de service offrant une limite plus élevée en termes de taille maximale des données. Consultez Mise à l’échelle des ressources d’une base de données unique et Mise à l'échelle des ressources d’un pool élastique.
- Si la base de données est dans un pool élastique, vous pouvez également déplacer la base de données en dehors du pool afin que son espace de stockage ne soit pas partagé avec d’autres bases de données.
- Réduire une base de données afin de récupérer l’espace inutilisé. Pour plus d’informations, consultez Gérer l’espace de fichiers pour les bases de données.
- Dans les pools élastiques, la réduction d'une base de données offre plus de stockage aux autres bases de données du pool.
- Vérifiez si l'utilisation intensive de l'espace est due à un pic de la taille du magasin PVS (Persistent Version Store). PVS fait partie de chaque base de données et est utilisé pour implémenter récupération de base de données accélérée. Pour déterminer la taille actuelle de PVS, consultez Résoudre les problèmes de récupération de base de données accélérée. Une grande taille de PVS est souvent due à une transaction qui reste ouverte pendant une longue période (plusieurs heures), ce qui empêche le nettoyage des anciennes versions des lignes dans le magasin PVS.
- Pour les bases de données et les pools élastiques des niveaux de service Premium et Critique pour l'entreprise qui consomment de grandes quantités de stockage, vous pourriez recevoir une erreur de type Espace insuffisant, même si l'espace utilisé dans la base de données ou le pool élastique est inférieur à la limite définie en termes de taille de données maximale. Cela peut se produire si
tempdbou les fichiers journaux des transactions consomment une grande quantité de stockage proche de la limite de stockage local. Basculez la base de données ou le pool élastique pour réinitialisertempdbsur sa taille inférieure initiale, ou réduisez le journal des transactions pour abaisser la consommation du stockage local.
Sessions, workers et demandes
Les sessions, workers et demandes sont définis comme suit :
- Une session représente un processus connecté au moteur de base de données.
- Une requête est la représentation logique d’une requête ou d’un lot. Une demande est émise par un client connecté à une session. Au fil du temps, plusieurs demandes peuvent être émises sur la même session.
- Un thread de travail, également appelé Worker ou thread, est une représentation logique d’un thread de système d’exploitation. Une demande peut avoir de nombreux workers lorsqu’elle est exécutée avec un plan d’exécution de requête parallèle, ou un seul worker lorsqu’elle est exécutée avec un plan d’exécution en série (à thread unique). Les workers sont également tenus de prendre en charge des activités en dehors des requêtes : par exemple, un worker est requis pour traiter une demande de connexion lors de l’ouverture d’une session.
Pour plus d’informations sur ces concepts, consultez le guide d’architecture des thread et des tâches.
Le nombre maximal de rôles de travail est déterminé par le niveau de service et la taille de calcul. Lorsque les limites de sessions ou de workers sont atteintes, les nouvelles requêtes sont refusées et les clients reçoivent un message d’erreur. Si le nombre de connexions peut être contrôlé par l’application, le nombre de workers simultanés est souvent plus difficile à estimer et à contrôler. Cela est particulièrement vrai pendant les pics de charge lorsque les limites de ressources de base de données sont atteintes et que les rôles de travail s’accumulent en raison de requêtes durables, de chaînes de blocage volumineuses ou d’un parallélisme excessif de requêtes.
Notes
L’offre initiale d’Azure SQL Database prenait en charge uniquement les requêtes à thread unique. À ce moment-là, le nombre de demandes était toujours équivalent au nombre de workers. Le message d’erreur 10928 dans la base de données Azure SQL contient le libellé The request limit for the database is *N* and has been reached à des fins de compatibilité descendante uniquement. La limite atteinte est en réalité le nombre de workers.
Si votre paramètre de degré de parallélisme (MAXDOP) est égal à zéro ou est supérieur à un, le nombre de workers peut être beaucoup plus élevé que le nombre de requêtes, et la limite pourrait être atteinte beaucoup plus tôt que lorsque MAXDOP est égal à 1.
- En savoir plus sur l’erreur 10928 dans les Erreurs de gouvernance des ressources.
- Pour en savoir plus sur l'épuisement des limites des demandes, consultez les erreurs 10928 et 10936.
Vous pouvez limiter les risques d’approcher ou atteindre des limites des workers ou des sessions des façons suivantes :
- Augmenter le niveau de service ou la taille de calcul du pool élastique ou de la base de données. Consultez Mise à l’échelle des ressources d’une base de données unique et Mise à l'échelle des ressources d’un pool élastique.
- Optimisation des requêtes pour réduire l’utilisation des ressources si la raison de l’augmentation des workers est un conflit pour les ressources de calcul. Pour plus d’informations, consultez la page Paramétrage/Compréhension de requêtes.
- Optimisation de la charge de travail des requêtes afin de réduire le nombre d’occurrences et la durée du blocage des requêtes. Pour plus d’informations, consultez Comprendre et résoudre les problèmes de blocage.
- Réduction du paramètre MAXDOP, le cas échéant.
Recherchez les limites pour les workers et les sessions Azure SQL Database par niveau de service et taille de calcul :
- Limites de ressources pour des bases de données uniques suivant le modèle d’achat vCore
- Limites de ressources pour les pools élastiques suivant le modèle d’achat vCore
- Limites de ressources pour des bases de données uniques suivant le modèle d’achat DTU
- limites de ressources pour les pools élastiques à l’aide du modèle d’achat DTU
En savoir plus sur la résolution d’erreurs spécifiques pour les limites des sessions ou des workers dans les erreurs de gouvernance des ressources.
Connexions externes
Le nombre de connexions simultanées à des points de terminaison externes effectuées via sp_invoke_external_rest_endpoint est limité à 10 % des threads de travail, avec une limite stricte de 150 workers maximum.
Mémoire
Contrairement à d’autres ressources (processeur, workers, stockage), l’atteinte de la limite de mémoire n’affecte pas négativement les performances des requêtes et ne provoque pas d’erreurs et d’échecs. Comme décrit en détail dans guide d’architecture de gestion de la mémoire, le moteur de base de données utilise souvent toutes les mémoires disponibles, par conception. La mémoire est principalement utilisée pour la mise en cache des données, afin d’éviter un accès au stockage plus lent. Ainsi, une utilisation plus importante de la mémoire améliore généralement les performances des requêtes, les lectures étant plus rapides à partir de la mémoire qu’à partir du stockage.
Après le démarrage du moteur de base de données, quand la charge de travail commence à lire les données à partir du stockage, le moteur de base de données met en cache les données en mémoire de façon intensive. Après cette période initiale de démarrage, il est courant et normal que les colonnes avg_memory_usage_percent et avg_instance_memory_percent dans sys.dm_db_resource_stats et l'indicateur Azure Monitor sql_instance_memory_percent soient proches de 100 %, en particulier pour les bases de données qui ne sont pas inactives et qui n'occupent pas tout l'espace de la mémoire.
Notes
L'indicateur sql_instance_memory_percent reflète la consommation totale de la mémoire sur le moteur de base de données. Cet indicateur peut ne pas atteindre 100 % même lorsque des charges de travail à forte intensité sont en cours d'exécution. Cette situation s'explique par le fait qu'une petite partie de la mémoire disponible est réservée à des allocations de mémoire critiques autres que le cache de données, telles que les piles de conversation et les modules exécutables.
Outre le cache de données, la mémoire est utilisée dans d’autres composants du moteur de base de données. En cas de demande de mémoire et si toute la mémoire disponible a été utilisée par le cache de données, le moteur de base de données réduit la taille du cache de données afin de libérer de la mémoire pour d’autres composants, et augmente dynamiquement le cache de données quand d’autres composants libèrent de la mémoire.
Dans de rares cas, une charge de travail suffisamment exigeante peut entraîner une insuffisance de mémoire, entraînant des erreurs de mémoire insuffisante. Les erreurs de mémoire insuffisante peuvent se produire à n’importe quel niveau d’utilisation de la mémoire compris entre 0 % et 100 %. Les erreurs de mémoire insuffisante sont plus susceptibles de se produire sur de plus petites tailles de calcul qui ont des limites de mémoire proportionnellement plus petites, et/ou avec des charges de travail qui utilisent davantage de mémoire pour le traitement des requêtes, par exemple dans les pools élastiques denses.
Si vous obtenez des erreurs de mémoire insuffisante, les options d’atténuation sont les suivantes :
- Examinez les détails de la condition de mémoire insuffisante dans sys.dm_os_out_of_memory_events.
- Augmenter le niveau de service ou la taille de calcul du pool élastique ou de la base de données. Consultez Mise à l’échelle des ressources d’une base de données unique et Mise à l'échelle des ressources d’un pool élastique.
- Optimiser les requêtes et la configuration pour réduire l’utilisation de la mémoire. Les solutions courantes sont décrites dans le tableau suivant.
| Solution | Descriptif |
|---|---|
| Réduire la taille des allocations de mémoire | Pour plus d’informations sur les allocations de mémoire, consultez le billet de blog Understanding SQL Server memory grants. Une solution courante pour éviter des allocations de mémoire excessivement volumineuses consiste à maintenir statistiques à jour. Cela aboutit à des estimations plus précises de la consommation de mémoire par le moteur de requête, ce qui évite les grandes allocations de mémoire. Par défaut, dans les bases de données utilisant le niveau de compatibilité 140 et les niveaux supérieurs, le moteur de base de données peut ajuster automatiquement la taille d’allocation de mémoire à l’aide du retour d’allocation de mémoire en mode batch. De même, dans les bases de données utilisant les niveaux de compatibilité 150 et supérieurs, le moteur de base de données utilise également le Retour d’allocation de mémoire en mode ligne, pour les requêtes en mode ligne plus courantes. Cette fonctionnalité intégrée permet d’éviter les erreurs de mémoire insuffisante en raison de grandes allocations de mémoire. |
| Réduire la taille du cache du plan de requête | Le moteur de base de données met en cache les plans de requête en mémoire, afin d’éviter de compiler un plan de requête pour chaque exécution de requête. Pour éviter l’augmentation du cache du plan de requête provoquée par des plans de mise en cache qui ne sont utilisés qu’une seule fois, veillez à utiliser des requêtes paramétrables et à activer OPTIMIZE_FOR_AD_HOC_WORKLOADS Configuration étendue à la base de données. |
| Réduire la taille de la mémoire des verrous | Le moteur de base de données utilise de la mémoire pour les verrous. Dans la mesure du possible, évitez les grandes transactions qui peuvent acquérir un grand nombre de verrous et provoquer une consommation de mémoire de verrous élevée. |
Consommation de ressources par les charges de travail utilisateur et les processus internes
Azure SQL Database nécessite des ressources de calcul pour mettre en œuvre des fonctionnalités de service essentielles telles que la haute disponibilité et la récupération d’urgence, la sauvegarde et la restauration de base de données, la surveillance, le magasin de requêtes, le réglage automatique, etc. Le système met de côté une partie limitée des ressources globales pour ces processus internes à l’aide de mécanismes de gouvernance des ressources, et les autres ressources restent donc disponibles pour les charges de travail utilisateur. Parfois, quand des processus internes n’utilisent pas les ressources de calcul, le système les met à disposition des charges de travail utilisateur.
La consommation d’UC et de mémoire totale par les charges de travail utilisateur et les processus internes est signalée dans les vues sys.dm_db_resource_stats et sys.resource_stats des colonnes avg_instance_cpu_percent et avg_instance_memory_percent. Ces données sont également signalées via les métriques Azure Monitor sql_instance_cpu_percent et sql_instance_memory_percent, pour les sql_instance_cpu_percent et les sql_instance_memory_percent au niveau du pool.
Notes
Les métriques Azure Monitor sql_instance_cpu_percent et sql_instance_memory_percent sont disponibles depuis juillet 2023. Elles sont complètement équivalentes aux métriques sqlserver_process_core_percent et sqlserver_process_memory_percent précédemment disponibles, respectivement. Les deux dernières métriques restent disponibles, mais seront supprimées à l’avenir. Pour éviter une interruption dans l’analyse de la base de données, n’utilisez pas les anciennes métriques.
Ces métriques ne sont pas disponibles pour les bases de données utilisant des objectifs de service De base, S1 et S2. Les mêmes données sont disponibles dans les vues de gestion dynamique suivantes.
La consommation d’UC et de mémoire par les charges de travail utilisateur dans chaque base de données est signalée dans les vues sys.dm_db_resource_stats et sys.resource_stats des colonnes avg_cpu_percent et avg_memory_usage_percent. Pour les pools élastiques, la consommation de ressources au niveau du pool est indiquée dans la vue sys.elastic_pool_resource_stats (pour les scénarios de rapports historiques) et dans la vue sys.dm_elastic_pool_resource_stats pour le monitoring en temps réel. La consommation de processeur de la charge de travail utilisateur est également signalée via la métrique Azure Monitor cpu_percent, pour les cpu_percent et les pools élastiques au niveau du pool.
Une répartition plus détaillée de la consommation récente des ressources par les charges de travail utilisateur et les processus internes est indiquée dans les vues sys.dm_resource_governor_resource_pools_history_ex et sys.dm_resource_governor_workload_groups_history_ex. Pour plus d’informations sur les pools de ressources et les groupes de charges de travail référencés dans ces vues, consultez Gouvernance des ressources. Ces vues signalent l’utilisation des ressources par les charges de travail utilisateur et par des processus internes spécifiques dans les pools de ressources et les groupes de charges de travail associés.
Conseil
Dans le cadre du monitoring ou du dépannage des performances de charges de travail, il est important de prendre en compte la consommation du processeur par l’utilisateur (avg_cpu_percent, cpu_percent) et la consommation totale du processeur par les charges de travail des utilisateurs et les processus internes (avg_instance_cpu_percent, sql_instance_cpu_percent). Les performances peuvent être sensiblement affectées si l’une de ces métriques est comprise entre 70 et 100 %.
La consommation d’UC de l’utilisateur est définie sous la forme d’un pourcentage de la limite d’UC de la charge de travail de l’utilisateur dans chaque objectif de service. De même, la consommation d’UC totale est définie comme pourcentage de la limite d’UC pour toutes les charges de travail. Étant donné que les deux limites sont différentes, l’utilisateur et la consommation totale du processeur sont mesurées à différentes échelles et ne sont pas directement comparables entre elles.
Si la consommation d’UC par l’utilisateur atteint 100 %, cela signifie que la charge de travail de l’utilisateur utilise entièrement la capacité d’UC disponible dans l’objectif de service sélectionné, même si la consommation d’UC totale reste inférieure à 100 %.
Quand la consommation d’UC totale atteint la plage de 70-100 %, il est possible de voir le débit de charge de travail de l’utilisateur s’aplanir et la latence des requêtes augmenter, même si la consommation d’UC par l’utilisateur reste inférieure à 100 %. La probabilité que cela se produise est supérieure lors de l’utilisation de plus petits objectifs de service avec une allocation modérée des ressources de calcul, mais avec des charges de travail utilisateur relativement intenses, par exemple dans des pools élastiques denses. Cela peut également se produire avec des objectifs de service plus petits lorsque les processus internes nécessitent temporairement davantage de ressources, par exemple lors de la création d’un réplica de la base de données ou de la sauvegarde de la base de données.
De même, lorsque consommation de l’UC utilisateur atteint la plage de 70 à 100%, le débit de charge de travail utilisateur aplatit et la latence des requêtes augmente, même si consommation totale du processeur est bien inférieure à sa limite.
Quand la consommation d’UC par l’utilisateur ou la consommation d’UC totale est élevée, les options d’atténuation sont les mêmes que celles indiquées précédemment dans la section UC de calcul et incluent l’augmentation de l’objectif de service et/ou l’optimisation de la charge de travail utilisateur.
Notes
Même sur une base de données ou un pool élastique complètement inactifs, la consommation totale du processeur n’est jamais nulle en raison des activités du moteur de base de données en arrière-plan. Elle peut varier dans une large plage en fonction des activités en arrière-plan spécifiques, de la taille de calcul et de la charge de travail utilisateur précédente.
Gouvernance des ressources
Pour appliquer des limites de ressources, Azure SQL Database utilise une implémentation de la gouvernance des ressources basée sur Resource Governor SQL Server, modifié et étendu pour s’exécuter dans le cloud. Dans SQL Database, il existe plusieurs listes de ressources partagées et groupes de charges de travail, avec des limites de ressources définies au niveau des pools et des groupes pour fournir une base de données en tant que service équilibrée. La charge de travail utilisateur et les charges de travail internes sont classées dans des listes de ressources partagées et des groupes de charges de travail distincts. La charge de travail utilisateur sur les réplicas primaires et secondaires accessibles en lecture, y compris les géoréplicas, est classée dans la liste de ressources partagées SloSharedPool1 et dans le groupe de charges de travail UserPrimaryGroup.DBId[N], où [N] correspond à la valeur de l’ID de base de données. En outre, il existe plusieurs listes de ressources partagées et groupes de charges de travail pour différentes charges de travail internes.
Outre l’utilisation de Resource Governor pour régir les ressources au sein du moteur de base de données, Azure SQL Database utilise également les objets de traitement Windows pour la gouvernance des ressources au niveau du processus et les Outils de gestion de ressources pour serveur de fichiers (FSRM) Windows pour la gestion des quotas de stockage.
La gouvernance des ressources Azure SQL Database est hiérarchique par nature. De haut en bas, les limites sont appliquées au niveau du système d’exploitation et au niveau du volume de stockage à l’aide des mécanismes de gouvernance des ressources du système d’exploitation et de Resource Governor, puis au niveau de la liste de ressources partagées à l’aide de Resource Governor, et enfin au niveau du groupe de charge de travail à l’aide de Resource Governor. Les limites de gouvernance des ressources en vigueur pour la base de données ou le pool élastique actuels sont rapportées dans l’affichage sys.dm_user_db_resource_governance.
Gouvernance des E/S de données
La gouvernance des E/S de données est un processus d’Azure SQL Database utilisé pour limiter les E/S physiques en lecture et en écriture sur les fichiers de données d’une base de données. Les limites IOPS sont définies pour chaque niveau de service afin de réduire l’effet de « voisinage bruyant », d’assurer une allocation des ressources équitable dans un service multilocataire et de rester dans les limites des capacités du matériel et du stockage sous-jacents.
Pour les bases de données uniques, les limites du groupe de charge de travail sont appliquées à toutes les E/S de stockage de la base de données. Pour les pools élastiques, les limites de groupe de charges de travail s’appliquent à chaque base de données dans le pool. En outre, la limite du pool de ressources s’applique également aux E/S cumulatives du pool élastique. Dans tempdb, les E/S sont soumises aux limites des groupes de charge de travail, à l’exception des niveaux de service De base, Standard et Usage général, où des limites d’E/S de tempdb plus élevées s’appliquent. En général, les limites des listes de ressources partagées peuvent ne pas être réalisables par la charge de travail sur une base de données (unique ou en pool), car les limites des groupes de charge de travail sont inférieures à celles des listes de ressources partagées et restreignent l’IOPS ou le débit plus tôt. Toutefois, les limites du pool peuvent être atteintes par la charge de travail combinée sur plusieurs bases de données pour le même pool.
Par exemple, si une requête génère 1 000 IOPS sans gouvernance des ressources d’E/S, mais que la limite maximale d’IOPS du groupe de charge de travail est définie sur 900 IOPS, la requête ne peut pas générer plus de 900 IOPS. Toutefois, si la limite maximale d’IOPS de la liste de ressources partagées est définie sur 1 500 IOPS et que le nombre total d’E/S de tous les groupes de charge de travail associés à la liste de ressources partagées dépasse 1 500 IOPS, les E/S de la même requête peuvent être réduites sous la limite du groupe de travail de 900 IOPS.
Les valeurs maximales d’IOPS et de débit renvoyées par l’affichage sys.dm_user_db_resource_governance agissent comme limites/seuils, et non comme garanties. En outre, la gouvernance des ressources ne garantit pas une latence de stockage spécifique. Les meilleurs latence, IOPS et débit possibles pour une charge de travail utilisateur donnée dépendent non seulement des limites de gouvernance des ressources d’E/S, mais également de la combinaison des tailles d’E/S utilisées et des fonctionnalités du stockage sous-jacent. SQL Database utilise des opérations d’E/S dont la taille varie entre 512 octets et 4 Mo. Dans le cadre de l’application des limites d’IOPS, chaque E/S est comptabilisée, quelle que soit sa taille, à l’exception des bases de données ayant des fichiers de données dans Stockage Azure. Dans ce cas, les E/S de plus de 256 Ko sont comptabilisées comme plusieurs E/S de 256 Ko afin de les aligner sur la comptabilisation des E/S de Stockage Azure.
Pour les bases de données De base, Standard et Usage général, qui utilisent des fichiers de données dans Stockage Azure, la valeur de primary_group_max_io peut ne pas être réalisable si une base de données ne dispose pas de suffisamment de fichiers de données pour fournir de manière cumulative ce nombre d’IOPS, si les données ne sont pas distribuées de manière égale entre les fichiers ou si le niveau de performance des blobs sous-jacents restreint l’IOPS ou le débit au-dessous des limites de gouvernance des ressources. De même, avec de petites opérations d’E/S de journaux générées par les validations fréquentes de transactions, la valeur de primary_max_log_rate peut ne pas être réalisable par une charge de travail en raison de la limite d’IOPS sur le blob Stockage Azure sous-jacent. Pour les bases de données utilisant Stockage Premium Azure, Azure SQL Database utilise des blobs de stockage suffisamment volumineux pour obtenir l’IOPS ou le débit nécessaires, quelle que soit la taille de la base de données. Pour les bases de données plus volumineuses, plusieurs fichiers de données sont créés pour augmenter la capacité totale d’IOPS ou de débit.
Les valeurs d’utilisation des ressources comme avg_data_io_percent et avg_log_write_percent, indiquées dans les vues sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats et sys.elastic_pool_resource_stats, sont calculées en pourcentages des limites maximales de gouvernance des ressources. Ainsi, quand des facteurs autres que la gouvernance des ressources limitent l’IOPS/le débit, il est possible de voir les courbes d’IOPS/de débit s’aplatir et les latences qui augmentent à mesure que la charge de travail augmente, même si l’utilisation des ressources signalée reste inférieure à 100 %.
Pour surveiller les IOPS, le débit et la latence en lecture et écriture par fichier de base de données, utilisez la fonction sys.dm_io_virtual_file_stats(). Cette fonction couvre toutes les E/S de la base de données, notamment les E/S en arrière-plan qui ne sont pas prises en compte pour avg_data_io_percent, mais utilise l’IOPS et le débit du stockage sous-jacent et peut avoir un impact sur la latence de stockage observée. La fonction indique une latence supplémentaire qui peut être introduite par la gouvernance des ressources d’E/S pour les lectures et écritures, respectivement dans les colonnes io_stall_queued_read_ms et io_stall_queued_write_ms.
Gouvernance relative au taux de journalisation des transactions
Ce type de gouvernance est un processus utilisé dans Azure SQL Database pour réduire les taux d’ingestions élevés des charges de travail de type bulk Insert, opérations SELECT INTO et création d’index. Ces limites font l’objet d’un suivi et sont appliquées à une vitesse inférieure à la seconde, selon le rythme de génération des enregistrements de journal, ce qui limite le débit quel que soit le nombre d’E/S générées sur les fichiers de données. Les taux de génération du journal des transactions sont actuellement mis à l’échelle de façon linéaire jusqu’à un point dépendant du matériel et du niveau de service.
Les taux de journalisation sont configurés de sorte qu’il soit possible de les obtenir et de les maintenir dans un large éventail de scénarios, tandis que l’ensemble du système peut gérer ses fonctionnalités avec un impact réduit sur la charge utilisateur. La gouvernance des taux de journalisation garantit que les sauvegardes de fichier journal des transactions respectent les SLA publiés en matière de récupérabilité. Cette gouvernance empêche également un backlog excessif sur les réplicas secondaires, ce qui pourrait autrement entraîner un temps d’arrêt plus long que prévu pendant les basculements.
Les E/S physiques réelles pour les fichiers journaux des transactions ne sont pas régies ou limitées. Lorsque des enregistrements de journaux sont générés, chaque opération est évaluée, dans le but de déterminer si elle doit être différée afin que le taux de journalisation maximum souhaité soit maintenu (en Mo/s par seconde). Les retards ne sont pas ajoutés quand les enregistrements de journaux sont vidés dans le stockage : la gouvernance du taux de journalisation est appliquée lors de la génération du taux de journalisation lui-même.
Les taux de génération de journaux réels imposés lors de l’exécution sont influencés par des mécanismes de commentaires, ce qui réduit temporairement les taux de journalisation disponibles afin de permettre au système de se stabiliser. La gestion de l’espace des fichiers journaux, l’absence d’exécution en cas de saturation de l’espace de journalisation disponible et les mécanismes de réplication des données peuvent réduire temporairement les limites totales du système.
La mise en forme du trafic de l’administrateur des taux de journalisation est présentée par le biais des types d’attente suivants (exposés dans les vues sys.dm_exec_requests et sys.dm_os_wait_stats) :
| Type d’attente | Remarques |
|---|---|
LOG_RATE_GOVERNOR |
Limitation appliquée aux bases de données |
POOL_LOG_RATE_GOVERNOR |
Limitation appliquée aux pools |
INSTANCE_LOG_RATE_GOVERNOR |
Limitation appliquée aux niveaux d’instances |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Contrôle des commentaires, réplication physique des groupes de disponibilité dans la section Critique pour l’entreprise/Premium ne suivant pas |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Contrôle des commentaires, limitation de taux pour éviter une condition de saturation de l’espace de journalisation |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Contrôle des commentaires relatifs à la géoréplication, limitation du taux de journalisation pour éviter une latence élevée des données et une indisponibilité des zones géographiques secondaires |
Lorsque vous rencontrez une limite de taux de journalisation qui entrave l’évolutivité du système, envisagez les options suivantes :
- Montez en puissance vers un niveau de service supérieur afin d’obtenir le taux de consignation maximal d’un niveau de service, ou basculez vers un autre niveau de service.
- Pour le matériel optimisé pour la mémoire premium et la série Premium, le niveau de service approvisionné Hyperscale fournit un taux de journalisation de 150 Mio/s par base de données et 150 Mio/s par pool élastique.
- Pour d’autres séries matérielles, le niveau de service Hyperscale fournit un débit de journal de 100 Mio/s par base de données et 125 Mio/s par pool élastique.
- Si les données en cours de chargement sont temporaires, telles que des données de processus de site dans un processus ETL, vous pouvez les charger dans la base de données
tempdb(qui présente une journalisation minimale). - Pour des scénarios d’analyse, chargez dans une table columnstore en cluster, ou une table avec des index qui utilisent la compression de données. Cela réduit le taux de consignation requis. Cette technique augmente l’utilisation de l’UC et s’applique uniquement aux jeux de données qui bénéficient d’index columnstore en cluster ou de la compression de données.
Gouvernance de l’espace de stockage
Dans les niveaux de service Premium et Critique pour l’entreprise, les données client, notamment les fichiers de données, les fichiers journaux de transactions et les fichiers tempdb, sont stockées sur le disque de stockage SSD local de l’ordinateur qui héberge la base de données ou le pool élastique. Le stockage SSD local offre des IOPS et un débit élevés, ainsi qu'une faible latence des E/S. Outre les données clients, le stockage local est utilisé pour le système d'exploitation, le logiciel de gestion, les données de surveillance et les journaux, ainsi que d'autres fichiers nécessaires au fonctionnement du système.
La taille du stockage local est limitée et dépend des capacités matérielles, qui déterminent la valeur maximale de stockage local, ou le stockage local réservé aux données client. Cette limite est définie pour optimiser le stockage des données client, tout en garantissant un fonctionnement sûr et fiable du système. Pour connaître la valeur maximale de stockage local de chaque objectif de service, consultez la documentation consacrée aux limites de ressources des bases de données uniques et des pools élastiques.
Vous pouvez également accéder à cette valeur, ainsi qu'à la quantité de stockage local actuellement utilisée par une base de données ou un pool élastique, en utilisant la requête suivante :
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Colonne | Descriptif |
|---|---|
server_name |
Nom du serveur logique |
database_name |
Nom de la base de données |
slo_name |
Nom de l'objectif de service, génération matérielle comprise |
user_data_directory_space_quota_mb |
Valeur maximale de stockage local, en Mo |
user_data_directory_space_usage_mb |
Consommation actuelle de stockage local par les fichiers de données, les fichiers journaux de transactions et les fichiers tempdb, en Mo. Mise à jour toutes les cinq minutes. |
Cette requête doit être exécutée dans la base de données utilisateur, et non dans la base de données master. Pour les pools élastiques, la requête peut être exécutée dans n'importe quelle base de données du pool. Les valeurs signalées s'appliquent à l'ensemble du pool.
Important
Aux niveaux de service Premium et Critique pour l'entreprise, si la charge de travail tente d'augmenter la consommation de stockage local combinée des fichiers de données, des fichiers journaux de transactions et des fichiers tempdb au-delà de la limite maximale de stockage local, une erreur de type Espace insuffisant se produit. Cela se produit même si l’espace utilisé dans un fichier de base de données n’a pas atteint la taille maximale du fichier.
Un disque de stockage SSD local est également utilisé par les bases de données dans les niveaux de service autres que Premium et Critique pour l’entreprise pour la base de données tempdb et le cache RBPEX Hyperscale. À mesure que des bases de données sont créées, supprimées et que leur taille augmente ou diminue, la consommation totale du stockage local d'une machine fluctue. Si le système détecte que le stockage local disponible sur un ordinateur est faible et qu’une base de données ou un pool élastique risque de manquer d’espace, il déplace la base de données ou le pool élastique vers un autre ordinateur disposant de suffisamment de stockage local.
Ce déplacement s’effectue en ligne, de la même manière qu’une opération de mise à l’échelle d’une base de données, et a un impact similaire, notamment un bref basculement (quelques secondes) à la fin de l’opération. Ce basculement met fin aux connexions ouvertes et restaure les transactions, ce qui peut affecter les applications qui utilisent la base de données à ce moment-là.
Comme toutes les données sont copiées sur des volumes de stockage local situé sur différentes machines, le déplacement de bases de données plus volumineuses aux niveaux de service Premium et Critique pour l'entreprise peut prendre un temps considérable. Pendant ce temps, si la consommation d'espace local par une base de données ou un pool élastique, ou par la base de données tempdb, augmente rapidement, le risque de manquer d'espace s’accroît. Le système lance le déplacement de la base de données de façon équilibrée afin de réduire les risques d'erreurs dues au manque d'espace tout en évitant les basculements inutiles.
Tailles tempdb
Les limites de taille pour tempdb dans Azure SQL Database dépendent du modèle d’achat et de déploiement.
Pour en savoir plus, consultez les limites de taille de tempdb pour :
- Modèle d’achat vCore : bases de données uniques, bases de données mises en pool
- Modèle d’achat DTU : bases de données uniques, bases de données groupées.
Matériel précédemment disponible
Cette section contient des détails sur le matériel précédemment disponible.
- Le matériel Gen4 a été mis hors service et n’est plus disponible pour le provisionnement, le scale-up ni le scale-down. Migrez votre base de données vers un matériel d’une génération prise en charge pour bénéficier de plus grandes possibilités en matière de scalabilité des vCores et du stockage, de performances réseau accélérées, de meilleures performances d’E/S et d’une latence minimale. Pour plus d’informations, consultez La prise en charge a pris fin pour le matériel Gen4 sur Azure SQL Database.
Vous pouvez vous servir d’Azure Resource Graph Explorer pour identifier toutes les ressources Azure SQL Database qui utilisent actuellement du matériel Gen4, ou bien vérifier le matériel exploité par les ressources pour un serveur logique spécifique sur le Portail Azure.
Vous devez au minimum disposer d’autorisations read sur l’objet ou le groupe d’objets Azure pour voir les résultats dans l’Explorateur Azure Resource Graph.
Pour utiliser l’Explorateur Resource Graph afin d’identifier les ressources Azure SQL qui utilisent toujours du matériel Gen4, effectuez les étapes suivantes :
Accédez au portail Azure.
Recherchez
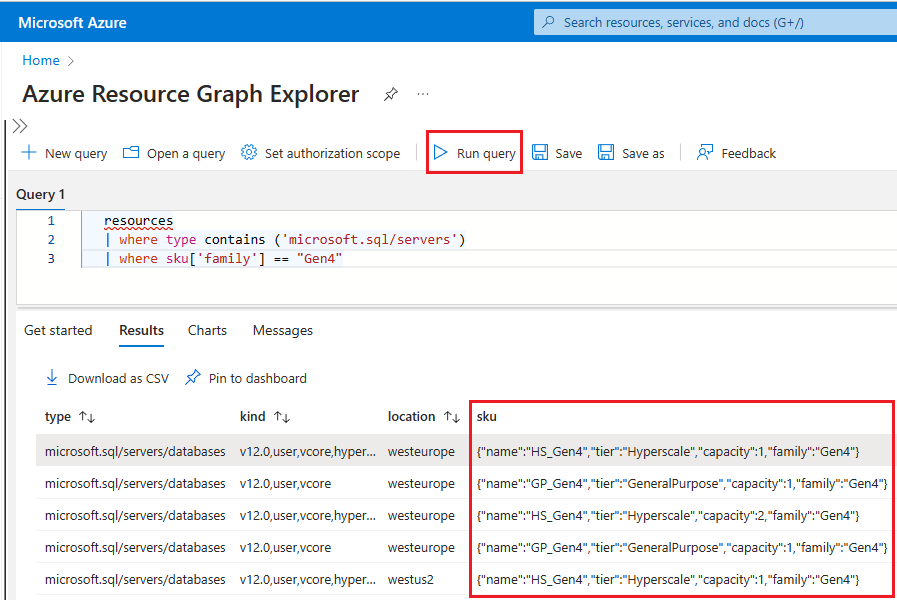
Resource graphdans la zone de recherche, puis choisissez le service Explorateur Resource Graph dans les résultats de la recherche.Dans la fenêtre de requête, tapez la requête suivante, puis sélectionnez Exécuter la requête :
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Le volet Résultats affiche toutes les ressources actuellement déployées dans Azure qui utilisent du matériel Gen4.
Pour vérifier le matériel utilisé par les ressources sur un serveur logique spécifique dans Azure, effectuez les étapes suivantes :
- Accédez au portail Azure.
- Recherchez
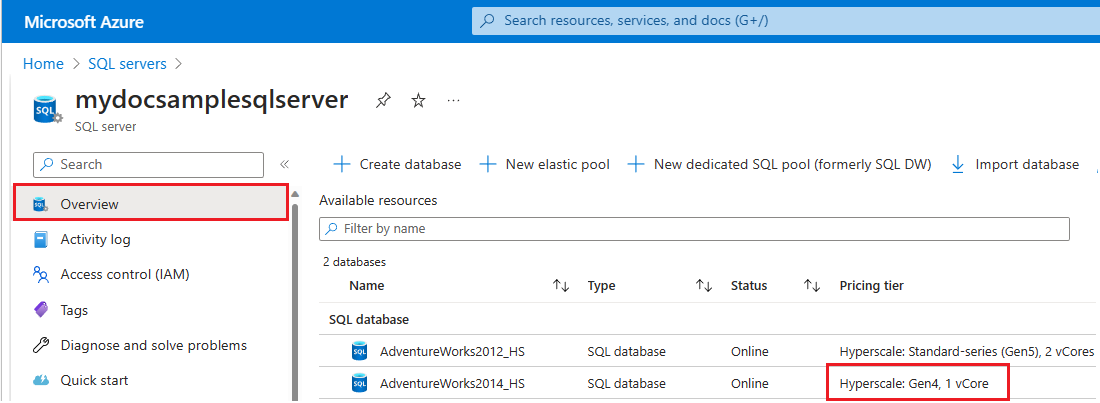
SQL serversdans la zone de recherche, puis choisissez Serveurs SQL dans les résultats de la recherche pour ouvrir la page Serveurs SQL et afficher tous les serveurs du ou des abonnements choisis. - Sélectionnez le serveur souhaité pour ouvrir la page Vue d’ensemble du serveur.
- Faites défiler la page jusqu’aux ressources disponibles, puis consultez la colonne Niveau tarifaire des ressources qui utilisent du matériel Gen4.
Pour migrer des ressources vers du matériel de série standard, consultez Modifier le matériel.
Contenu connexe
- Pour plus d’informations sur les limites générales d’Azure, consultez Abonnement Azure et limites, quotas et contraintes du service.
- Pour plus d’informations sur les DTU et eDTU, consultez DTU et eDTU.
- Pour plus d’informations sur les limites de taille de
tempdb, consultez les rubriques relatives aux bases de données uniques vCore, aux bases de données vCore groupées, aux bases de données DTU uniques, et aux bases de données DTU groupées.