Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à : Azure SQL Database
Serverless est un niveau de calcul destiné aux bases de données uniques d’Azure SQL Database qui met automatiquement à l’échelle les calculs en fonction de la demande en charge de travail, et facture la quantité de calcul utilisée par seconde. Le niveau de calcul serverless met aussi automatiquement en pause les bases de données pendant les périodes d’inactivité, quand seul le stockage est facturé, et reprend leur exécution automatiquement avec l’activité. Le niveau de calcul serverless est disponible dans le niveau de service General Purpose et le niveau de service Hyperscale.
Remarque
La pause automatique et la reprise automatique ne sont actuellement prises en charge que dans le niveau de service Usage général.
Vue d’ensemble
Une plage de mise à l’échelle automatique de calcul et un retard de mise en pause automatique sont des paramètres importants pour le niveau de calcul serverless. La configuration de ces paramètres déterminent l’expérience de performances de base de données et le coût du calcul.
Configuration des performances
- Les quantités minimale et maximale de vCores sont des paramètres configurables qui définissent la plage de la capacité de calcul disponible pour la base de données. Les limites en mémoire et E/S sont proportionnelles à la plage de vCore spécifiée.
- Le délai de mise en pause automatique est un paramètre configurable qui définit la durée pendant laquelle la base de données doit être inactive avant d’être automatiquement mise en pause. La base de données est automatiquement reprise lorsque la connexion suivante ou une autre activité se produit. Vous pouvez également désactiver la mise en pause automatique.
Coût
Le coût d’une base de données serverless correspond à la somme du coût de calcul et du coût de stockage. Le coût de stockage est déterminé de la même façon que dans le niveau de calcul provisionné.
- Quand l’utilisation du calcul est comprise dans les limites minimales et maximales configurées, le coût du calcul est basé sur le nombre de vCores et la mémoire utilisée.
- Quand l’utilisation du calcul est inférieure aux limites minimales configurées, le coût du calcul est basé sur le nombre minimal de vCores et la mémoire minimale configurée.
- Quand la base de données est en pause, le coût du calcul est égal à zéro et seuls les coûts de stockage sont facturés.
Pour plus de détails sur les coûts, consultez Facturation.
Scénarios
Serverless est optimisé pour le rapport qualité-prix pour les bases de données uniques avec des modèles d'utilisation intermittents et imprévisibles, pouvant supporter un certain délai d'activation du calcul après des périodes d'inactivité. Par opposition, le niveau de calcul provisionné présente un rapport prix/performance optimisé pour une base de données unique ou plusieurs bases de données dans des pools élastiques avec une utilisation moyenne plus élevée, ce qui ne peut se permettre aucun délai lors du préchauffage informatique.
Scénarios adaptés à l’informatique sans serveur
- Les bases de données uniques avec des modèles d’utilisation intermittente et non prévisible, entrecoupée de périodes d’inactivité, et une utilisation moyenne moins élevée des fonctions de calcul dans le temps.
- Les bases de données uniques dans le niveau de calcul provisionné sont souvent mises à l’échelle. Les clients qui préfèrent déléguer cette mise à l’échelle du calcul confient cette tâche au service.
- Les nouvelles bases de données uniques sans historique d’utilisation où la taille de calcul est difficile ou impossible à estimer avant le déploiement dans une base de données Azure SQL.
Scénarios adaptés au calcul approvisionné
- Les bases de données uniques avec des modèles d’utilisation plus régulière et prévisible, et une utilisation du calcul moyenne plus élevée dans le temps.
- Les bases de données qui ne peuvent pas tolérer des compromis sur les performances résultant de réductions de la mémoire plus fréquentes ou de délais dans la reprise après une mise en pause.
- Plusieurs bases de données avec des modèles d’utilisation intermittente et imprévisible qui peuvent être regroupées dans des pools élastiques pour un rapport prix/performances optimisé.
Comparer les niveaux de calcul
Le tableau suivant résume les différences entre le niveau de calcul serverless et le niveau de calcul provisionné :
| Calcul serverless | Calcul provisionné | |
|---|---|---|
| Modèle d’utilisation des bases de données | Utilisation intermittente et imprévisible avec une utilisation moyenne du calcul moins élevée dans le temps. | Modèles d’utilisation plus régulière avec une utilisation moyenne du calcul plus élevée dans le temps, ou plusieurs bases de données regroupées dans des pools élastiques. |
| Effort pour gérer les performances : | Moins grand | Plus grand |
| Scalabilité du calcul | Automatique | Manuel |
| Réactivité du calcul. | Baisse après les périodes d'inactivité | Immédiat |
| Niveau de détail de facturation | Par seconde | À l’heure |
Modèle d’achat et niveau de service
Le tableau suivant décrit la prise en charge du mode serverless en fonction du modèle d’achat, des niveaux de service et du matériel :
| Catégorie | Pris en charge | Non pris en charge |
|---|---|---|
| Modèle d’achat | vCore | DTU |
| Niveau de service |
Usage général Hyperscale |
Critique pour l’entreprise |
| Matériel | Série Standard (Gen5) | Tout autre matériel |
Mise à l’échelle automatique
Réactivité de la mise à l’échelle
Les bases de données serverless sont exécutées sur un ordinateur avec une capacité suffisante pour satisfaire la demande de ressources sans interruption pour une quantité de calcul demandée, dans les limites définies par la valeur maximale des vCores. Parfois, un équilibrage de charge se produit automatiquement si l’ordinateur ne parvient pas à satisfaire les besoins en ressources en quelques minutes. Par exemple, si la demande en ressources est de quatre vCores, mais que seuls deux vCores sont disponibles, un délai de quelques minutes peut être nécessaire pour équilibrer la charge avant de fournir les quatre vCores demandés. La base de données reste en ligne au cours de l’équilibrage de charge, sauf pendant une courte période à la fin de l’opération lorsque les connexions sont supprimées.
Gestion de la mémoire
Dans les deux niveaux de service Usage général et Hyperscale, la mémoire des bases de données serverless est récupérée plus fréquemment que pour les bases de données de calcul provisionnées. Il est important de tenir compte de ce comportement pour maîtriser les coûts dans le serverless et peut affecter les performances.
Récupération du cache
Contrairement aux bases de données de calcul provisionné, la mémoire du cache SQL est récupérée d'une base de données serverless lorsque l'utilisation du processeur ou du cache actif est faible.
- L’utilisation du cache actif est considérée comme faible quand la taille totale des dernières entrées du cache utilisées tombe sous un certain seuil, pendant une période donnée.
- Quand la récupération du cache est déclenchée, la taille de cache cible est réduite de façon incrémentielle à une fraction de sa taille précédente, et la récupération continue uniquement si l’utilisation reste faible.
- S’il y a une récupération du cache, la stratégie de sélection des entrées du cache à supprimer est la même que celle utilisée pour les bases de données de calcul provisionné quand la mémoire est fortement sollicitée.
- La taille du cache n’est jamais réduite en deçà de la limite de mémoire minimale telle que définie par le nombre minimal de vCores.
Dans les bases de données à calcul serverless et provisionné, les entrées de cache peuvent être supprimées si toute la mémoire disponible est utilisée.
Quand l’utilisation du processeur est faible, l’utilisation du cache actif peut rester élevée en fonction du modèle d’utilisation et empêcher la récupération de la mémoire. Il peut y avoir aussi des délais supplémentaires après l’arrêt de l’activité de l’utilisateur avant la récupération de la mémoire en raison des processus d’arrière-plan réguliers répondant à l’activité utilisateur précédente. Par exemple, les opérations de suppression et les tâches de nettoyage du Magasin des requêtes génèrent des enregistrements fantômes marqués pour suppression, mais qui ne sont pas physiquement supprimés tant que le processus de nettoyage des éléments fantômes n’est pas exécuté. Le nettoyage des éléments fantômes peut impliquer la lecture de pages de données dans le cache.
Alimentation du cache
La taille du cache mémoire SQL augmente à mesure que des données sont extraites du disque, de la même manière et au même rythme que pour des bases de données provisionnées. Quand la base de données est occupée, le cache est autorisé à grossir sans contrainte tant que de la mémoire est disponible.
Gestion du cache de disque
Dans le niveau de service Hyperscale pour les niveaux de calcul serverless et approvisionné, chaque réplica de calcul utilise un cache RBPEX (Resilient Buffer Pool Extension), qui stocke les pages de données sur le disque SSD local pour améliorer les performances d’E/S. Toutefois, dans le niveau de calcul serverless pour Hyperscale, le cache RBPEX pour chaque réplica de calcul augmente et diminue automatiquement en réponse à l’augmentation et à la diminution de la demande en charge de travail. La taille maximale du cache RBPEX peut atteindre trois fois la mémoire maximale configurée pour la base de données. Pour plus d’informations sur la mémoire maximale et les limites de mise à l’échelle automatique RBPEX en mode serverless, consultez Limites de ressources Hyperscale serverless.
Mise en pause automatique et reprise automatique
La mise en pause automatique et la reprise automatique serverless ne sont prises en charge qu’au niveau Usage général.
Mise en pause automatique
Une mise en pause automatique est déclenchée si toutes les conditions suivantes sont remplies pendant la durée du délai de mise en pause automatique :
- Nombre de sessions = 0
- Processeur = 0 pour la charge de travail utilisateur exécutée dans le pool de ressources utilisateur
Une option permet de désactiver la mise en pause automatique si vous le souhaitez.
Les fonctionnalités suivantes ne soutiennent pas la mise en pause automatique, mais soutiennent la mise à l’échelle automatique. Si l’une des fonctionnalités suivantes est utilisée, la mise en pause automatique doit être désactivée et la base de données reste en ligne quelle que soit sa durée d’inactivité :
- Géoréplication (géoréplication active et groupes de basculement).
- Rétention de sauvegardes à long terme (LTR).
- Base de données de synchronisation utilisée dans SQL Data Sync. Contrairement aux bases de données de synchronisation, les bases de données hub et membre prennent en charge la mise en pause automatique.
- Alias DNS créé pour le serveur logique contenant une base de données sans serveur.
- Elastic Jobs, la base de données serverless avec mise en pause automatique n'est pas prise en charge comme Base de données de tâches. Les bases de données serverless ciblées par les travaux élastiques prennent en charge la mise en pause automatique. Les connexions de travaux relancent une base de données.
La mise en pause automatique est temporairement indisponible durant le déploiement de certaines mises à jour de service pour lesquelles la base de données doit être en ligne. Dans ce cas, la mise en pause automatique est réactivée dès que la mise à jour du service est terminée.
Résolution des problèmes de mise en pause automatique
Si la mise en pause automatique est activée et que les fonctionnalités qui bloquent la suspension automatique ne sont pas utilisées, mais qu’une base de données ne s’interrompt pas automatiquement après la période de retard, les sessions d’application ou d’utilisateur peuvent empêcher la suspension automatique.
Pour voir si des sessions d’application ou utilisateur sont actuellement connectées à la base de données, connectez-vous à la base de données à l’aide de n’importe quel outil client et exécutez la requête suivante :
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Conseil
Après avoir exécuté la requête, veillez à vous déconnecter de la base de données. Sinon, la session ouverte utilisée par la requête empêche la suspension automatique.
- Si le jeu de résultats n’est pas vide, cela signifie que des sessions empêchent actuellement la mise en pause automatique.
- Si le jeu de résultats est vide, il est toujours possible que des sessions aient été ouvertes précédemment, peut-être durant une brève période, pendant le délai de pause automatique. Pour vérifier l’activité pendant la période de retard, vous pouvez utiliser Audit pour Azure SQL Database et Azure Synapse Analytics et examiner les données d’audit pour la période appropriée.
Important
La présence de sessions ouvertes, avec ou sans utilisation simultanée du processeur dans le pool de ressources utilisateur, est la raison la plus courante pour laquelle une base de données serverless n’est pas mise en pause automatique comme prévu.
Reprise automatique
La reprise automatique est déclenchée si l’une des conditions suivantes est remplie à un moment donné :
| Fonctionnalité | Déclencheur de reprise automatique |
|---|---|
| Authentification et autorisation | Connexion |
| Détection de menaces | Activation/désactivation des paramètres de détection des menaces au niveau de la base de données ou du serveur. Modification des paramètres de détection des menaces au niveau de la base de données ou du serveur. |
| Découverte et classification des données | Ajout, modification, suppression ou affichage des étiquettes de sensibilité |
| Audit | Affichage des enregistrements d’audit. Mise à jour ou affichage de la politique d’audit. |
| Masquage de données | Ajout, modification, suppression ou affichage des règles de masquage des données |
| Chiffrement transparent des données | Visualisation de l'état ou du statut du chiffrement transparent des données |
| Évaluation des vulnérabilités | Analyses initiées manuellement et analyses périodiques si activées |
| Magasin de données sur les requêtes et les performances | Modification ou affichage des paramètres du Magasin des requêtes |
| Recommandations sur les performances | Affichage ou application des recommandations en matière de performances |
| Réglage automatique | Application et vérification des recommandations de réglage automatique telles que l’indexation automatique |
| Copie de base de données | Création d’une base de données comme copie. Exportation vers un fichier BACPAC. |
| Synchronisation des données SQL | Synchronisation entre les bases de données hub et membre qui s’exécutent selon une planification configurable ou qui sont exécutées manuellement |
| Modification de certaines métadonnées de base de données | Ajout de nouvelles balises de base de données. Changement du nombre maximal de vCores, du nombre minimal de vCores ou du délai de mise en pause automatique. |
| SQL Server Management Studio (SSMS) | Lorsque vous utilisez des versions de SSMS antérieures à 18.1 et que vous ouvrez une nouvelle fenêtre de requête pour toute base de données du serveur, tout base de données du même serveur qui ont été mises en pause automatique est reprise. Ce comportement ne se produit pas si vous utilisez SSMS version 18.1 ou ultérieure. |
La supervision, la gestion ou d’autres solutions qui effectuent l’une de ces opérations déclenchent la reprise automatique. La reprise automatique est également déclenchée durant le déploiement de certaines mises à jour de service pour lesquelles la base de données doit être en ligne.
Connectivité
Si une base de données serverless est mise en pause, la première tentative de connexion reprend la base de données et retourne une erreur indiquant que la base de données n’est pas disponible (code d’erreur 40613). Une fois la base de données reprise, réessayez la connexion pour établir la connectivité. Les clients de base de données qui suivent les recommandations relatives à la logique de nouvelle tentative de connexion ne devraient pas avoir besoin d’être modifiés. Pour les options et les recommandations relatives à la logique de réessai de connexion, voir :
- Logique de réessai de connexion dans SqlClient
- Logique de réessai de connexion de base de données SQL avec Entity Framework Core
- Logique de réessai de connexion dans SQL Database avec Entity Framework 6
- Logique de nouvelle tentative de connexion dans SQL Database à l’aide d’ADO.NET
Latence
La latence pour la reprise automatique d'une base de données serverless est généralement d'environ une minute pour la reprise automatique et de l'ordre de une à dix minutes après l'expiration de la période de délai pour la mise en pause automatique.
Chiffrement transparent des données géré par le client (BYOK)
Suppression ou révocation d'une clé
Si vous utilisez chiffrement transparent des données géré par le client (BYOK) et que la suppression ou la révocation de la clé se produit alors que la base de données serverless est déjà mise en pause automatique, alors la base de données reste en pause automatique. Dans ce cas, après la reprise de la base de données, la base de données devient inaccessible pendant 10 minutes environ. Une fois que la base de données devient inaccessible, le processus de récupération est le même que pour les bases de données de calcul provisionnées. Si la base de données serverless est en ligne lors de la suppression ou de la révocation d’une clé, elle devient également inaccessible après environ 10 minutes, de la même façon qu’avec les bases de données de calcul approvisionnées.
Rotation des clés
Si vous utilisez le chiffrement transparent des données géré par le client (BYOK), et que la mise en pause automatique serverless est activée, la base de données est reprise automatiquement à chaque rotation des clés. La base de données sera ensuite suspendue automatiquement lorsque les conditions de suspension automatique sont satisfaites.
Créer une base de données serverless
La création d’une base de données ou le déplacement d’une base de données existante dans un niveau de calcul serverless suivent le même modèle que la création d’une nouvelle base de données dans un niveau de calcul provisionné et impliquent les deux étapes suivantes :
Spécifiez l’objectif de service. L’objectif du service précise le niveau de service, la configuration matérielle et le nombre maximal de vCores. Pour connaître les options d’objectif de service, consultez Limites des ressources serverless.
Si vous le souhaitez, spécifiez un nombre minimal de vCores et un délai de mise en pause automatique différents des valeurs par défaut. Le tableau suivant présente les valeurs disponibles pour ces paramètres.
Paramètre Choix des valeurs Valeur par défaut Nombre minimal de vCores Dépend du nombre maximal de vCores configuré. Voir Limites des ressources. 0,5 vCore Délai de pause automatique Minimum : 15 minutes
Maximum : 10 080 minutes (sept jours)
Incréments : 1 minute
Désactiver la mise en pause automatique : -160 minutes
Les exemples suivants créent une base de données dans le niveau de calcul sans serveur.
Utiliser le portail Azure
Consultez Démarrage rapide : Créez une base de données unique dans Azure SQL Database à l’aide du portail Azure .
Utiliser PowerShell
- Usage général
- Hyperscale
Créez une nouvelle base de données sans serveur à usage général avec l'exemple PowerShell suivant :
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Utiliser l’interface de ligne de commande Microsoft Azure
- Usage général
- Hyperscale
Créez une base de données à usage général serverless avec l’exemple Azure CLI suivant :
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Utiliser Transact-SQL (T-SQL)
Lorsque vous utilisez T-SQL pour créer une base de données serverless, les valeurs par défaut sont appliquées pour le nombre minimal de vCores et le délai de pause automatique. Leurs valeurs peuvent être modifiées ultérieurement à partir du portail Azure ou via l’API, notamment PowerShell, Azure CLI et REST.
Pour plus d'informations, voir CREATE DATABASE.
- Usage général
- Hyperscale
Créez une nouvelle base de données serverless à usage général avec l'exemple T-SQL suivant :
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Déplacer une base de données entre les niveaux de calcul ou de service
Une base de données peut être déplacée entre le niveau de calcul provisionné et le niveau de calcul sans serveur.
Une base de données serverless peut également être déplacée du niveau de service à usage général vers le niveau de service Hyperscale. Pour plus d’informations, consultez Convertir une base de données existante enHyperscale .
Lors du déplacement d’une base de données entre les niveaux de calcul, spécifiez le paramètre modèle de calcul comme Serverless ou Provisioned lorsque vous utilisez PowerShell ou Azure CLI, ou SERVICE_OBJECTIVE lorsque vous utilisez T-SQL. Consultez les limites des ressources pour identifier l’objectif de service approprié.
Les exemples suivants permettent de déplacer une base de données existante de l’informatique provisionnée vers l’informatique sans serveur.
Utiliser PowerShell
- Usage général
- Hyperscale
Déplacez une base de données de calcul général qui est provisionnée vers le niveau de calcul serverless avec l'exemple PowerShell suivant :
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Utiliser l’interface de ligne de commande Microsoft Azure
- Usage général
- Hyperscale
Déplacez une base de données Usage général de calcul approvisionnée vers le niveau de calcul serverless avec l’exemple Azure CLI suivant :
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Utiliser Transact-SQL (T-SQL)
Lorsque vous utilisez T-SQL pour déplacer une base de données entre les niveaux de calcul, les valeurs par défaut sont appliquées pour le nombre minimal de vCores et le délai de pause automatique. Leurs valeurs peuvent ensuite être modifiées à partir du portail Azure ou via l’API, notamment PowerShell, Azure CLI et REST. Pour en savoir plus, voir ALTER DATABASE.
- Usage général
- Hyperscale
Déplacez une base de données Usage général de calcul approvisionnée vers le niveau de calcul serverless avec l’exemple T-SQL suivant :
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modifier la configuration sans serveur
Utiliser PowerShell
Utilisez Set-AzSqlDatabase pour modifier le maximum ou le minimum de vCores et le délai de mise en pause automatique. Utilisez les arguments MaxVcore, MinVcore, et AutoPauseDelayInMinutes. La fonctionnalité serverless de mise en pause automatique n'est pas prise en charge dans le niveau Hyperscale, donc l'argument de délai de pause automatique ne s'applique qu'au niveau General Purpose.
Utiliser l’interface de ligne de commande Microsoft Azure
Utilisez az sql db update pour modifier le nombre maximal ou minimal de vCores et le délai de mise en pause automatique. Utilisez les arguments capacity, min-capacity, et auto-pause-delay. La fonctionnalité serverless de mise en pause automatique n'est pas prise en charge dans le niveau Hyperscale, donc l'argument de délai de pause automatique ne s'applique qu'au niveau General Purpose.
Écran
Ressources utilisées et facturées
Les ressources d’une base de données serverless sont comprennent le package d’application, l’instance SQL et les entités du pool de ressources utilisateur.
Package d’application
Le package d'application est la frontière extérieure de la gestion des ressources d'une base de données, que celle-ci soit dans un niveau de calcul sans serveur ou provisionné. Le package d’application contient l’instance SQL et des services externes tels que la recherche en texte intégral, qui comprennent ensemble toutes les ressources utilisateur et système utilisées par une base de données dans SQL Database. En règle générale, l’instance SQL domine l’utilisation globale des ressources sur le package d’application.
Pool de ressources utilisateur
Le pool de ressources utilisateur représente une limite interne en termes de gestion des ressources d’une base de données, que celle-ci soit dans un niveau de calcul serverless ou provisionné. Le pool de ressources utilisateur délimite le processeur et les E/S pour la charge de travail utilisateur générée par les requêtes DDL CREATE et ALTER, ainsi que les requêtes DML INSERT, UPDATE, DELETE, MERGE et SELECT. Ces requêtes représentent généralement la proportion la plus importante de l’utilisation dans le package d’application.
Métriques
Le tableau suivant inclut les métriques de supervision de l’utilisation des ressources du package d’application et du pool de ressources utilisateur d’une base de données serverless, y compris tous les réplicas géographiques :
| Entité | Métrique | Descriptif | Unités |
|---|---|---|---|
| Package d’application | Pourcentage du CPU de l'application | Pourcentage de vCores utilisés par l’application par rapport au nombre maximal de vCores autorisé pour l’application. Pour Hyperscale serverless, cette métrique est exposée pour tous les réplicas principaux, les réplicas nommés et les réplicas géographiques. | Pourcentage |
| Package d’application | application_processeur_facturé | Volume de calcul facturé pour l’application pendant la période de rapport. Le montant payé pendant cette période est le produit de cette métrique et du prix unitaire d’un vCore. Les valeurs de cette métrique sont déterminées par l’agrégation de la quantité maximale du processeur utilisé et de la mémoire utilisée par seconde. Si la quantité utilisée est inférieure à la quantité minimale provisionnée tel que définie par le nombre minimal de vCores et la mémoire minimale, la quantité minimale provisionnée est facturée. Pour comparer le processeur à la mémoire à des fins de facturation, la mémoire est normalisée en unités de vCores en remettant à l’échelle la quantité de mémoire en Go à 3 Go par vCore. Pour Hyperscale serverless, cette métrique est exposée pour le réplica principal et tous les réplicas nommés. |
Secondes de vCore |
| Package d’application | app_cpu_billed_HA_replicas | Uniquement applicable à la version serverless de Hyperscale. Somme des calculs facturés sur toutes les applications pour les réplicas haute disponibilité au cours de la période de reporting. Cette somme est limitée aux réplicas haute disponibilité appartenant au réplica principal ou aux réplicas haute disponibilité appartenant à un réplica nommé donné. Avant de calculer cette somme sur les réplicas haute disponibilité, la quantité de calcul facturée pour un réplica haute disponibilité individuel est déterminée de la même manière que pour le réplica principal ou un réplica nommé. Pour Hyperscale serverless, cette métrique est exposée pour tous les réplicas principaux, les réplicas nommés et les réplicas géographiques. Le montant payé pendant la période de reporting est le produit de cette métrique et du prix unitaire d’un vCore. | Secondes de vCore |
| Package d’application | pourcentage_mémoire_app | Pourcentage de mémoire utilisée par l’application par rapport à la mémoire maximale autorisée pour l’application. Pour Hyperscale serverless, cette métrique est exposée pour tous les réplicas principaux, les réplicas nommés et les réplicas géographiques. | Pourcentage |
| Pool de ressources utilisateur | pourcentage de CPU | Pourcentage de vCores utilisés par la charge de travail utilisateur par rapport au nombre maximal de vCores autorisé pour la charge de travail utilisateur. | Pourcentage |
| Pool de ressources utilisateur | données_IO_pourcent | Pourcentage d’IOPS de données utilisées par la charge de travail utilisateur par rapport au nombre maximal d’IOPS de données autorisé pour la charge de travail utilisateur. | Pourcentage |
| Pool de ressources utilisateur | log_IO_percent | Pourcentage de Mo/s de journal utilisés par la charge de travail utilisateur par rapport au nombre maximal de Mo/s de journal autorisé pour la charge de travail utilisateur. | Pourcentage |
| Pool de ressources utilisateur | pourcentage_des_travailleurs | Pourcentage de workers utilisés par la charge de travail utilisateur par rapport au nombre maximal de workers autorisé pour la charge de travail utilisateur. | Pourcentage |
| Pool de ressources utilisateur | pourcentage_de_sessions | Pourcentage de sessions utilisées par la charge de travail utilisateur par rapport au nombre maximal de sessions autorisé pour la charge de travail utilisateur. | Pourcentage |
État de mise en pause et de reprise
Dans le cas d’une base de données serverless avec la mise en pause automatique activée, l’état signalé inclut les valeurs suivantes :
| Statut | Descriptif |
|---|---|
| En ligne | La base de données est en ligne. |
| Suspension en cours | La base de données passe de l’état En ligne à Suspendue. |
| Suspendu | La base de données est suspendue. |
| Reprise en cours | La base de données passe de l’état Suspendu à En ligne. |
Utiliser le portail Azure
Dans le portail Azure, l’état de la base de données est affiché dans la page Vue d’ensemble de la base de données et la page Vue d’ensemble du serveur. En outre, dans le portail Azure, l’historique des événements de suspension et de reprise d’une base de données sans serveur peut être consulté dans le Journal d’activité.
Utiliser PowerShell
Affichez l’état actuel de la base de données à l’aide de l’exemple PowerShell suivant :
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Utiliser l’interface de ligne de commande Microsoft Azure
Affichez l’état actuel de la base de données à l’aide de l’exemple Azure CLI suivant :
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Limites des ressources
Pour connaître les limites de ressources, consultez Niveau de calcul serverless.
Facturation
Le volume de calcul facturé pour une base de données serverless correspond à la quantité maximale de processeur et de mémoire utilisée par seconde. Si la quantité de processeur et de mémoire est inférieure à la quantité minimale provisionnée pour chaque ressource, la quantité provisionnée est facturée. Pour comparer le processeur à la mémoire à des fins de facturation, la mémoire est normalisée en unités de vCores en remettant à l’échelle le nombre de Go à 3 Go par vCore.
- Ressource facturée : Processeur et mémoire
- Montant facturé : prix unitaire d’un vCore * nombre maximal (nombre minimal de vCores, vCores utilisés, Go de mémoire minimale * 1/3, Go de mémoire utilisée * 1/3)
- Fréquence de facturation : À la seconde
Le prix unitaire d’un vCore est le coût par vCore et par seconde.
Reportez-vous à la page de tarification Azure SQL Database pour les prix spécifiques à l'unité dans une région donnée.
La quantité de calcul facturée en mode serverless pour une base de données Usage général ou un réplica principal ou nommé Hyperscale est exposée par la métrique suivante :
- Métrique : app_cpu_billed (secondes de vCore)
- Définition : nombre maximal (nombre minimal de vCores, vCores utilisés, Go de mémoire minimale * 1/3, Go de mémoire utilisée * 1/3)
- Fréquence de reporting : par minute en fonction des mesures par seconde agrégées sur une minute.
La quantité de calcul facturée en mode serverless pour les réplicas Hyperscale haute disponibilité appartenant au réplica principal ou à tout réplica nommé est exposée par la métrique suivante :
- Métrique : app_cpu_billed_HA_replicas (secondes de vCore)
- Définition : somme maximale (nombre minimal de vCores, vCores utilisés, Go de mémoire minimale * 1/3, Go de mémoire utilisée * 1/3) pour tous les réplicas haute disponibilité appartenant à leur ressource parente.
- Ressource parente et point de terminaison de métrique : le réplica principal et tout réplica nommé exposent chacun séparément cette métrique, qui mesure le calcul facturé pour tous les réplicas haute disponibilité associés.
- Fréquence de reporting : par minute en fonction des mesures par seconde agrégées sur une minute.
Facturation minimale du calcul
Si une base de données serverless est suspendue, la facturation du calcul est égale à zéro. Si une base de données sans serveur n'est pas mise en pause, alors la facturation minimale du calcul ne peut être inférieure à la quantité de vCores basée sur le maximum (nombre minimal de vCores, mémoire minimale en Go * ⅓).
Exemples :
- Prenons une base de données serverless dans le niveau Usage général non mise en pause et configurée avec 8 vCores maximum et 1 vCore minimum, correspondant à 3,0 Go de mémoire minimum. La facturation minimale du calcul se base alors sur max (1 vCore, 3,0 Go × 1 vCore/3 Go) = 1 vCore.
- Prenons une base de données serverless dans le niveau Usage général non mise en pause et configurée avec 4 vCores maximum et 0,5 vCore minimum, correspondant à 2,1 Go de mémoire minimum. La facturation minimale du calcul se base alors sur le maximum (0,5 vCore, 2,1 Go × 1 vCore/3 Go) = 0,7 vCore.
- Supposez qu’une base de données serverless dans le niveau Hyperscale possède un réplica principal avec un réplica haute disponibilité et un réplica nommé sans réplica haute disponibilité. Supposons que chaque réplica est configuré avec 8 vCores maximum et 1 vCore minimum, correspondant à 3 Go de mémoire minimum. La facture de calcul minimale pour le réplica principal, le réplica haute disponibilité et le réplica nommé est pour chacun basée sur le nombre maximal (1 vCore, 3 Go * 1 vCore / 3 Go) = 1 vCore.
La Calculatrice de prix Azure SQL Database pour le serverless peut aider à déterminer la mémoire minimale configurable en fonction du nombre maximal et minimal de vCores configurés. En règle générale, si le nombre minimal de vCores configuré est supérieur à 0,5 vCore, la facturation minimale du calcul est indépendante de la mémoire minimale configurée et se base uniquement sur le nombre minimal de vCores configurés.
Exemples de scénarios
- Usage général
- Hyperscale
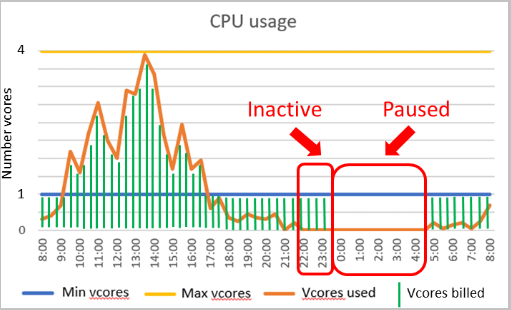
Prenons l’exemple d’une base de données serverless dans le niveau Usage général configurée avec 1 vCore minimum et 4 vCores maximum. Cette configuration représente environ 3 Go de mémoire minimum et 12 Go de mémoire maximum. Supposons que le délai de mise en pause automatique est défini à six heures et que la charge de travail de la base de données est active durant les deux premières heures d’une période de 24 heures, mais qu’elle reste inactive le reste du temps.
Dans ce cas de figure, la base de données est facturée pour le calcul et le stockage pendant les huit premières heures. Même si la base de données devient inactive après la deuxième heure, elle continue d’être facturée pour le calcul durant les six heures suivantes, selon le calcul minimal provisionné quand la base de données est en ligne. Seul le stockage est facturé pendant le reste de la période de 24 heures où la base de données est mise en pause.
Plus précisément, les coûts de calcul dans cet exemple sont calculés de la façon suivante :
| Intervalle de temps | vCores utilisés par seconde | Go utilisés par seconde | Dimension de calcul facturée | Secondes de vCore facturées dans l’intervalle de temps |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | vCores utilisés | 4 vCores * 3 600 secondes = 14 400 vCore secondes |
| 1:00-2:00 | 1 | 12 | Mémoire utilisée | 12 Go * 1/3 * 3 600 secondes = 14 400 vCore secondes |
| 2:00-8:00 | 0 | 0 | Mémoire minimale provisionnée | 3 Go * 1/3 * 21 600 secondes = 21 600 vCore secondes |
| 8:00-24:00 | 0 | 0 | Aucun calcul facturé pendant la mise en pause | 0 seconde de vCore |
| Total de secondes de vCore facturées sur 24 heures | 50 400 secondes de vCore |
Supposons que le prix de l’unité de calcul soit de 0,000145 $/vCore/seconde. Ensuite, le calcul facturé pour cette période de 24 heures est le produit du prix unitaire de calcul et des secondes vCore facturées : 0,000145 $/vCore/seconde * 50 400 vCore secondes ~ 7,31 $.
Azure Hybrid Benefit et réservations
Les remises Azure Hybrid Benefit (AHB) et Réservations Azure ne s’appliquent pas au niveau de calcul serverless.
Régions disponibles
Pour connaître la Disponibilité Serverless par région pour Azure SQL Database, consultez Disponibilité Serverless par région pour Azure SQL Database.
Contenu connexe
- Pour bien commencer, consultez Démarrage rapide : Créer une base de données unique – Azure SQL Database.
- Pour connaître les choix de niveau de service serverless, consultez Usage général et Hyperscale.