Fonctionnalités multimodèles d’Azure SQL Database et SQL Managed Instance
S’applique à : ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Des bases de données multimodèles vous permettent de stocker et d’utiliser des données dans plusieurs formats, comme des données relationnelles, des graphiques, des documents JSON ou XML, des paires clé-valeur, des données spatiales, etc.
La famille de produits Azure SQL utilise un modèle relationnel qui offre les meilleures performances pour une variété d’applications à usage général. Toutefois, les produits Azure SQL comme Azure SQL Database et SQL Managed Instance ne sont pas limités aux données relationnelles. Azure SQL Database vous permet d’utiliser divers formats non relationnels étroitement intégrés dans le modèle relationnel.
Envisagez d’utiliser les fonctionnalités multimodèles d’Azure SQL Database dans les cas suivants :
- Vous disposez d’informations ou de structures qui sont mieux adaptées aux modèles NoSQL et vous ne souhaitez pas utiliser de bases de données NoSQL distinctes.
- Une majorité de vos données est appropriée pour le modèle relationnel, et vous avez besoin de modéliser certaines parties de vos données dans le style NoSQL.
- Vous souhaitez utiliser les nombreux langages Transact-SQL pour interroger et analyser à la fois les données relationnelles et les données NoSQL et les intégrer avec des outils et applications qui utilisent le langage SQL.
- Vous souhaitez appliquer des fonctionnalités de base de données comme les technologies en mémoire pour améliorer les performances de votre analyse ou le traitement de vos structures de données NoSQL. Vous pouvez utiliser la réplication transactionnelle ou des réplicas lisibles pour créer des copies de vos données et décharger certaines charges de travail analytiques de la base de données principale.
Les sections suivantes décrivent les fonctionnalités multimodèles les plus importantes d’Azure SQL.
Notes
Vous pouvez utiliser des expressions de chemin d’accès JSON, des expressions XQuery/XPath, des fonctions spatiales et des expressions d’interrogation de graphique dans la même requête Transact-SQL pour accéder à toutes les données stockées dans la base de données. Tout outil ou langage de programmation capable d’exécuter des requêtes Transact-SQL peut également utiliser cette interface de requête pour accéder à des données multimodèles. C’est la principale différence par rapport aux bases de données multimodèles comme Azure Cosmos DB, qui fournissent des API spécialisées pour les modèles de données.
Fonctionnalités de graphe
Les produits Azure SQL offrent des fonctionnalités de base de données de graphe pour modéliser des relations de plusieurs à plusieurs dans une base de données. Un graphique est une collection de nœuds (ou sommets) et d’arêtes (ou relations). Un nœud représente une entité (par exemple, une personne ou une organisation). Un périmètre représente une relation entre les deux nœuds qu’il connecte (par exemple, Mentions j’aime ou Amis).
Voici quelques fonctionnalités qui rendent une base de données de graphe unique :
- Les arêtes sont des entités de première classe dans une base de données de graphe. Elles peuvent être associées à des attributs ou des propriétés.
- Une simple arête peut connecter de manière flexible plusieurs nœuds dans une base de données de graphe.
- Vous pouvez facilement exprimer des critères spéciaux et des requêtes de navigation sur plusieurs tronçons.
- Vous pouvez facilement exprimer une fermeture transitive et des requêtes polymorphes.
Les fonctionnalités de relations entre graphes et d’interrogation de graphes sont intégrées dans Transact-SQL. Elles bénéficient des avantages liés à l’utilisation du moteur de base de données SQL Server en tant que le système fondamental de gestion de base de données. Les fonctionnalités de graphique utilisent des requêtes standard Transact-SQL améliorées avec l’opérateur de graphe MATCH pour interroger les données de graphe.
Une base de données relationnelle peut accomplir tout ce qu’une base de données de graphe peut. Toutefois, une base de données de graphe peut faciliter l’expression de certaines requêtes. Votre décision de choisir l’une plutôt que l’autre peut dépendre des facteurs suivants :
- Vous devez modéliser des données hiérarchiques dans lesquelles un nœud peut avoir plusieurs parents, vous ne pouvez donc pas utiliser le type de données hierarchyId.
- Votre application a des relations plusieurs-à-plusieurs complexes. À mesure que l’application évolue, de nouvelles relations sont ajoutées.
- Vous devez analyser des données et relations interconnectées.
- Vous souhaitez utiliser des conditions de recherche T-SQL spécifiques au graphe, comme SHORTEST_PATH.
Fonctionnalités JSON
Dans les produits Azure SQL, vous pouvez analyser et interroger des données représentées au format JavaScript Object Notation (JSON) , et d’exporter vos données relationnelles en tant que texte JSON. JSON est une fonctionnalité essentielle du moteur de base de données SQL Server.
Les fonctionnalités JSON vous permettent de placer des documents JSON dans des tables, de transformer des données relationnelles en documents JSON et de transformer des documents JSON en données relationnelles. Vous pouvez utiliser le langage standard Transact-SQL amélioré avec les fonctions JSON pour analyser des documents. Vous pouvez également utiliser des index non mis en cluster, des index ColumnStore ou des tables mémoire optimisées pour optimiser vos requêtes.
JSON est un format de données largement répandu pour l’échange de données dans des applications mobiles et web modernes. JSON est également utilisé pour stocker des données semi-structurées dans des fichiers journaux ou des bases de données NoSQL. Nombreux sont les services web REST qui retournent des résultats sous forme de texte JSON ou qui acceptent des données au format JSON.
La plupart des services Azure ont des points de terminaison REST qui retournent ou consomment du JSON. Ces services incluent Recherche cognitive Azure, Stockage Azure et Azure Cosmos DB.
Si vous avez du texte JSON, vous pouvez extraire des données de JSON ou vérifier que JSON est correctement formaté à l’aide des fonctions intégrées JSON_VALUE, JSON_QUERY et ISJSON. Les autres fonctions sont :
- JSON_MODIFY : permet de mettre à jour les valeurs à l’intérieur du texte JSON.
- OPENJSON : peut transformer un tableau d’objets JSON en un ensemble de lignes pour des opérations d’interrogation et d’analyse plus avancées. Toute requête SQL peut être exécutée sur le jeu de résultats retourné.
- FOR JSON : vous permet de convertir les données stockées dans vos tables relationnelles au format de texte JSON.
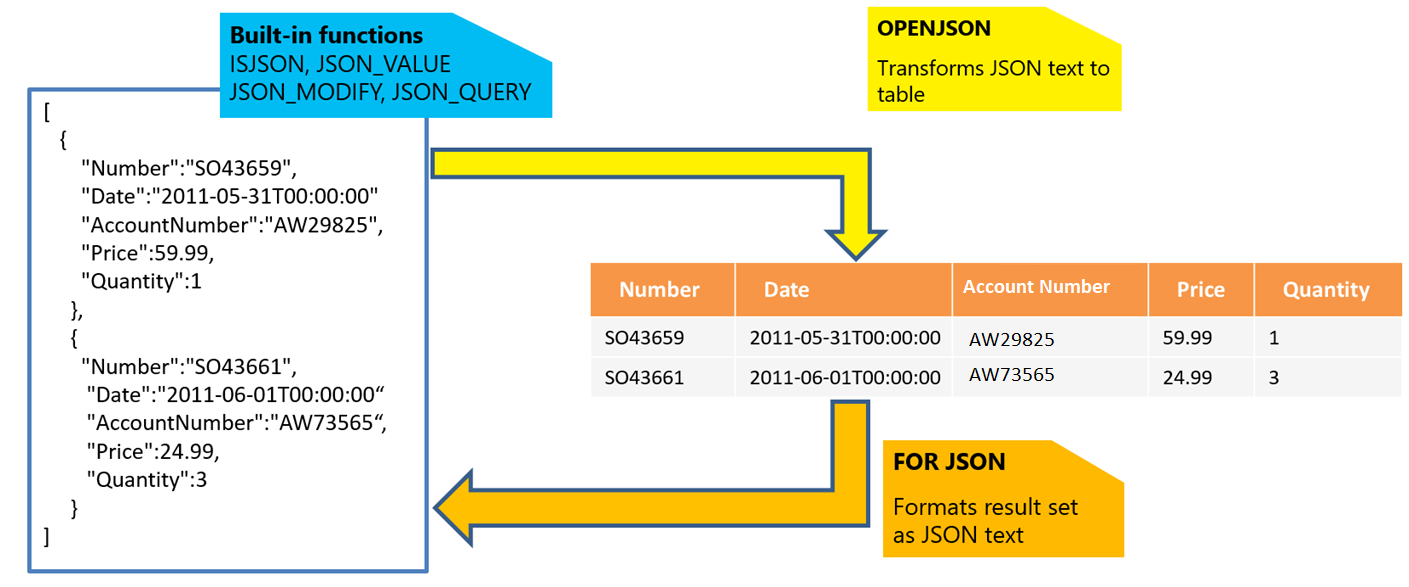
Pour plus d'informations, consultez Utiliser des données JSON.
Vous pouvez utiliser des modèles de document au lieu de modèles relationnels dans certains cas bien spécifiques :
- Une normalisation élevée du schéma n’apporte pas d’avantages significatifs, car vous accédez à tous les champs d’objets en même temps, et ne mettez jamais à jour les parties normalisées des objets. Par ailleurs, le modèle normalisé augmente la complexité de vos requêtes en raison du nombre important de tables que vous devez joindre pour obtenir les données.
- Vous travaillez avec des applications qui utilisent en mode natif des documents JSON qui sont des modèles de communication ou de données, et vous ne souhaitez pas introduire de couches supplémentaires qui transforment des données relationnelles en JSON et inversement.
- Vous devez simplifier votre modèle de données en dénormalisant les tables enfant ou les modèles Entité-Objet-Valeur.
- Vous devez charger ou exporter des données stockées au format JSON sans outil supplémentaire analysant les données.
Fonctionnalités XML
Les fonctionnalités XML vous permettent de stocker et indexer des données XML dans votre base de données, ainsi que d’utiliser des opérations XQuery/XPath natives pour travailler avec des données XML. Les produits Azure SQL ont un type de données XML spécialisé et intégré et des fonctions de requête qui traitent des données XML.
Le moteur de base de données SQL Server offre une plateforme puissante pour le développement d’applications dédiées à la gestion des données semi-structurées. La prise en charge de XML est intégrée dans tous les composants du moteur de base de données et inclut :
- La possibilité de stocker des valeurs XML en mode natif dans une colonne de type de données XML qui peut être typée en fonction d’une collection de schémas XML, ou laissée non-typée. Vous pouvez indexer la colonne XML.
- La possibilité de spécifier une requête XQuery sur des données XML stockées dans des colonnes et des variables du type XML. Vous pouvez utiliser les fonctionnalités XQuery dans n’importe quelle requête Transact-SQL pour accéder à un modèle de données que vous utilisez dans votre base de données.
- Indexation automatique de tous les éléments des documents XML en utilisant l’index XML primaire. Ou vous pouvez spécifier les chemins exacts qui doivent être indexés à l’aide de l’index XML secondaire.
OPENROWSET, qui permet le chargement en masse de données XML.- La possibilité de transformer des données relationnelles au format XML.
Vous pouvez utiliser des modèles de document au lieu de modèles relationnels dans certains cas bien spécifiques :
- Une normalisation élevée du schéma n’apporte pas d’avantages significatifs, car vous accédez à tous les champs d’objets en même temps, et ne mettez jamais à jour les parties normalisées des objets. Par ailleurs, le modèle normalisé augmente la complexité de vos requêtes en raison du nombre important de tables que vous devez joindre pour obtenir les données.
- Vous travaillez avec des applications qui utilisent en mode natif des documents XML qui sont des modèles de communication ou de données, et vous ne souhaitez pas introduire de couches supplémentaires qui transforment des données relationnelles en JSON et inversement.
- Vous devez simplifier votre modèle de données en dénormalisant les tables enfant ou les modèles Entité-Objet-Valeur.
- Vous devez charger ou exporter des données stockées au format XML sans outil supplémentaire analysant les données.
Fonctionnalités spatiales
Données spatiales représentent des informations sur l’emplacement physique et la forme d’objets. Ces objets peuvent être des emplacements de points ou des objets plus complexes, tels que des pays/régions, des routes ou des lacs.
Azure SQL prend en charge deux types de données spatiales :
- Le type géométrique représente des données dans un système de coordonnées euclidien (plat).
- Le type géographique représente des données dans un système de coordonnées terrestres.
Les fonctionnalités spatiales dans Azure SQL vous permettent de stocker les données géométriques et géographiques. Vous pouvez utiliser des objets spatiaux dans Azure SQL pour analyser et interroger des données représentées au format JSON, et exporter vos données relationnelles sous forme de texte JSON. Ces objets spatiaux incluent Point, LineString et Polygon. Azure SQL fournit également des index spatiaux spécialisés permettant d’améliorer les performances de vos requêtes spatiales.
La prise en charge spatiale est une fonctionnalité essentielle du moteur de base de données SQL Server.
Paires clé-valeur
Les produits Azure SQL n’ont pas de types ou structures spécialisés qui prennent en charge les paires clé-valeur, car les structures clé-valeur peuvent être représentées en mode natif sous forme de tables relationnelles standard :
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
Vous pouvez personnaliser cette structure clé-valeur selon vos besoins sans contrainte. À titre d’exemple, la valeur peut être un document XML au lieu du type nvarchar(max). Si la valeur est un document JSON, vous pouvez utiliser une contrainte CHECK qui vérifie la validité du contenu JSON. Vous pouvez placer n’importe quel nombre de valeurs associées à une clé dans les colonnes supplémentaires. Par exemple :
- Ajoutez des index et des colonnes calculés pour simplifier et optimiser l’accès aux données.
- Définissez la table en tant que table à mémoire optimisée et à schéma uniquement pour obtenir de meilleures performances.
Pour un exemple de la façon dont un modèle relationnel peut être utilisé efficacement comme solution de paire clé-valeur dans la pratique, consultez Comment bwin utilise la technologie OLTP en mémoire de SQL Server 2016 pour atteindre des performances et un nombre d’utilisateurs sans précédent. Dans cette étude de cas, bwin a utilisé un modèle relationnel pour sa solution de mise en cache ASP.NET pour obtenir 1,2 million de lots par seconde.
Étapes suivantes
Les capacités multimodèles sont des fonctionnalités essentielles du moteur de base de données SQL Server partagées entre les produits Azure SQL. Pour en savoir plus sur ces fonctionnalités, consultez ces articles :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour