Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce tutoriel vous guide tout au long de la création et de l’exécution d’un pipeline Azure Data Factory qui exécute une charge de travail Azure Batch. Un script Python s’exécute sur les nœuds Batch pour obtenir une entrée de valeurs séparées par des virgules (CSV) à partir d’un conteneur Stockage Blob Azure, manipuler les données et écrire la sortie dans un autre conteneur de stockage. Vous utilisez Batch Explorer pour créer un pool et des nœuds Batch ainsi que l’Explorateur Stockage Azure pour utiliser les conteneurs et les fichiers de stockage.
Dans ce tutoriel, vous allez apprendre à :
- Utiliser Batch Explorer pour créer un pool et des nœuds Batch.
- Utiliser l’Explorateur Stockage pour créer des conteneurs de stockage et charger des fichiers d’entrée.
- Développer un script Python pour manipuler les données d’entrée et produire une sortie.
- Créez un pipeline Data Factory qui exécute la charge de travail Batch.
- Utiliser Batch Explorer pour examiner les fichiers journaux de sortie.
Prérequis
- Compte Azure avec un abonnement actif. Si vous n’en avez pas, créez un compte gratuit.
- Un compte Batch et un compte Stockage Azure lié. Vous pouvez créer les comptes à l’aide de l’une des méthodes suivantes : Portail Azure | Azure CLI | Bicep | Modèle ARM | Terraform.
- Une instance Data Factory. Pour créer la fabrique de données, suivez les instructions fournies dans Créer une fabrique de données.
- Batch Explorer téléchargé et installé.
- L’Explorateur Stockage téléchargé et installé.
-
Python 3.8 ou supérieur, avec le package azure-storage-blob installé à l'aide de
pip. - Le jeu de données d’entrée iris.csv téléchargé depuis GitHub.
Utiliser Batch Explorer pour créer un pool et des nœuds Batch
Utilisez Batch Explorer pour créer un pool de nœuds de calcul afin d’exécuter votre charge de travail.
Connectez-vous à Batch Explorer avec vos informations d’identification Azure.
Sélectionnez votre compte Batch.
Sélectionnez Pools dans la barre latérale gauche, puis sélectionnez l’icône + pour ajouter un pool.
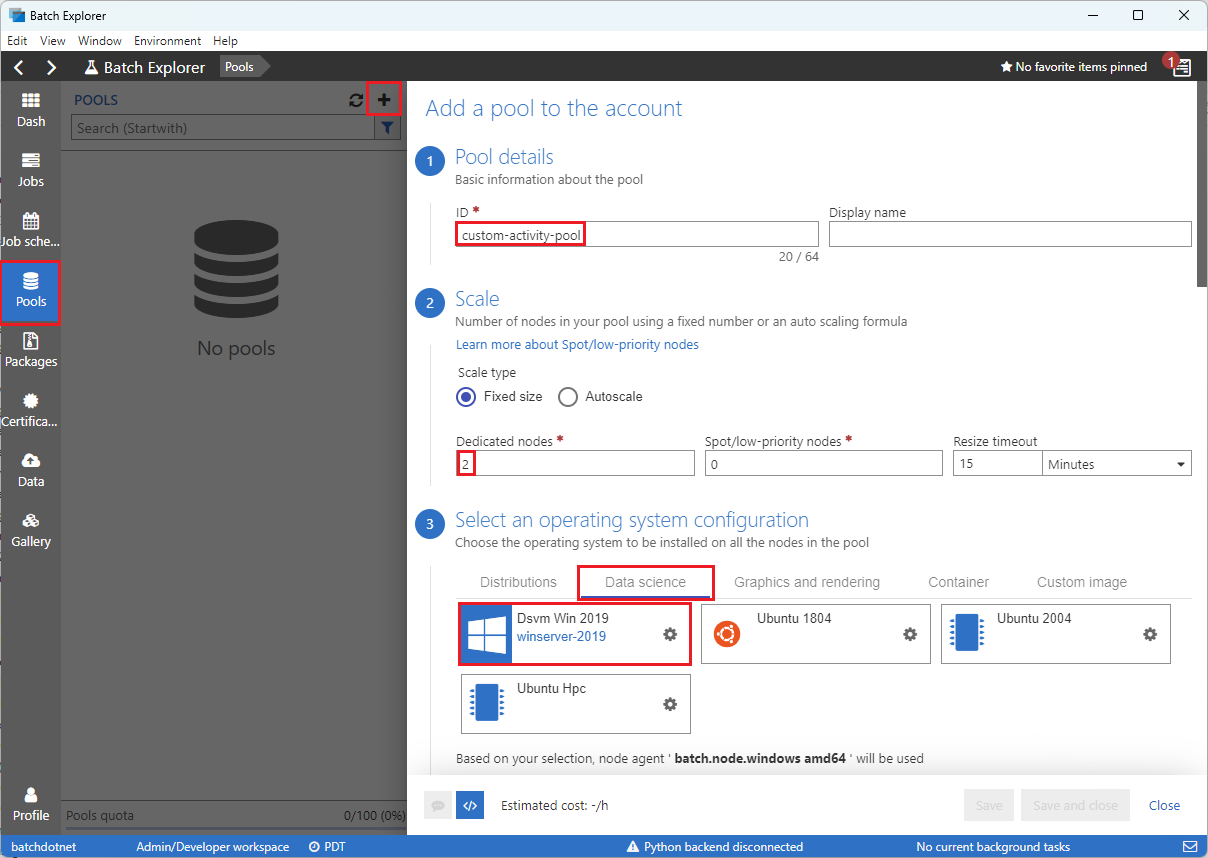
Remplissez le formulaire Ajouter un pool au compte comme suit :
- Sous ID, saisissez custom-activity-pool.
- Sous Nœuds dédiés, entrez 2.
- Pour Sélectionner une configuration de système d’exploitation, sélectionnez l’onglet Science des données, puis sélectionnez Dsvm Win 2019.
- Pour Choisir une taille de machine virtuelle, sélectionnez Standard_F2s_v2.
- Pour Tâche de démarrage, sélectionnez Ajouter une tâche de démarrage.
Dans l’écran de la tâche de démarrage, sous Ligne de commande, entrez
cmd /c "pip install azure-storage-blob pandas", puis sélectionnez Sélectionner. Cette commande installe le packageazure-storage-blobsur chaque nœud à mesure qu’il démarre.
Sélectionnez Enregistrer et fermer.

Utiliser l’Explorateur de Stockage pour créer des conteneurs de blobs
Utilisez l’Explorateur Stockage pour créer des conteneurs d’objets blob afin de stocker les fichiers d’entrée et de sortie, puis chargez vos fichiers d’entrée.
- Connectez-vous à l’Explorateur Stockage avec vos informations d’identification Azure.
- Dans la barre latérale gauche, recherchez et développez le compte de stockage lié à votre compte Batch.
- Cliquez avec le bouton droit sur Conteneurs d’objets blob, puis sélectionnez Créer un conteneur d’objets blob, ou sélectionnez Créer un conteneur d’objets blob à partir d’Actions en bas de la barre latérale.
- Entrez input dans le champ d’entrée.
- Créez un autre conteneur d’objets blob nommé output.
- Sélectionnez le conteneur input, puis sélectionnez Charger>Charger des fichiers dans le volet droit.
- Dans l’écran Charger des fichiers, sous Fichiers sélectionnés, sélectionnez les points de suspension ... en regard du champ d’entrée.
- Accédez à l’emplacement du fichier iris.csv téléchargé, sélectionnez Ouvrir, puis Charger.

Développer un script Python
Le script Python suivant charge le fichier de jeu de données iris.csv à partir de votre conteneur input de l’Explorateur Stockage, manipule les données et enregistre les résultats dans le conteneur output.
Le script doit utiliser la chaîne de connexion pour le compte de stockage Azure lié à votre compte Batch. Pour obtenir la chaîne de connexion :
- Dans le portail Azure, recherchez et sélectionnez le nom du compte de stockage lié à votre compte Batch.
- Dans la page du compte de stockage, sélectionnez Clés d’accès dans le volet de navigation gauche sous Sécurité + réseau.
- Sous key1, sélectionnez Afficher en regard de Chaîne de connexion, puis sélectionnez l’icône Copier pour copier la chaîne de connexion.
Collez la chaîne de connexion dans le script suivant, en remplaçant l’espace réservé <storage-account-connection-string>. Enregistrez le script en tant que fichier nommé main.py.
Important
L’exposition des clés de compte dans la source de l’application n’est pas recommandée pour l’utilisation en production. Vous devez restreindre l’accès aux informations d’identification et y faire référence dans votre code à l’aide de variables ou d’un fichier de configuration. Il est préférable de stocker les clés de compte Batch et de stockage dans Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Pour plus d’informations sur l’utilisation du Stockage Blob Azure, reportez-vous à la documentation Stockage Blob Azure.
Exécutez le script localement pour tester et valider les fonctionnalités.
python main.py
Le script doit produire un fichier de sortie nommé iris_setosa.csv qui contient uniquement les enregistrements de données pour lesquels « Species » a pour valeur « setosa ». Après avoir vérifié qu’il fonctionne correctement, chargez le fichier de script main.py dans votre conteneur input de l’Explorateur Stockage.
Configurer un pipeline Data Factory
Créez et validez un pipeline Data Factory qui utilise votre script Python.
Obtenir les informations de compte
Le pipeline de Data Factory utilise les noms de vos comptes Batch et de stockage, les valeurs des clés de compte et le point de terminaison de votre compte Batch. Pour vous procurer ces informations à partir du portail Azure :
Dans la barre recherche Azure, recherchez et sélectionnez le nom de votre compte Batch.
Sur la page de votre compte Batch, sélectionnez Clés dans le volet de navigation de gauche.
Sur la page Clés, copiez les valeurs suivantes :
- Compte Batch
- Point de terminaison de compte
- Clé d’accès primaire
- Nom du compte de stockage
- Key1
Créer et exécuter le pipeline
Si Azure Data Factory Studio n’est pas déjà en cours d’exécution, sélectionnez Lancer studio dans votre page Data Factory dans le portail Azure.
Dans Data Factory Studio, sélectionnez l’icône de crayon Créer dans le volet de navigation gauche.
Sous Ressources de fabrique, sélectionnez l’icône +, puis sélectionnez Pipeline.
Dans le volet Propriétés à droite, remplacez le nom du pipeline par Exécuter Python.
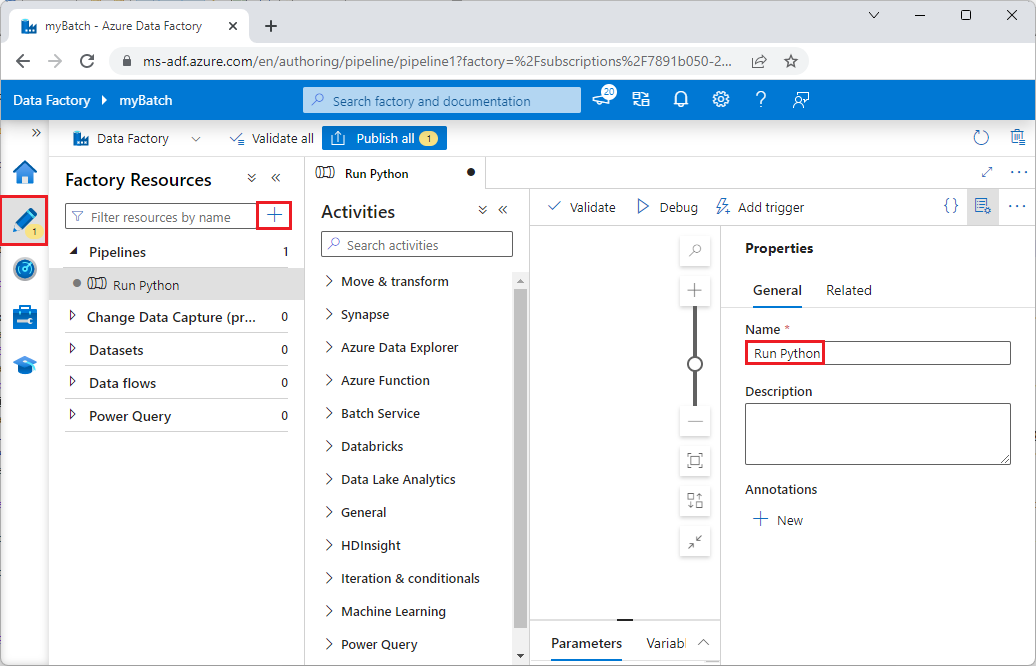
Dans le volet Activités, déroulez Service Batch et faites glisser l’activité Personnalisé vers la surface de l'éditeur de pipeline.
Sous le canevas du concepteur, sous l’onglet Général, entrez testPipeline sous Nom.
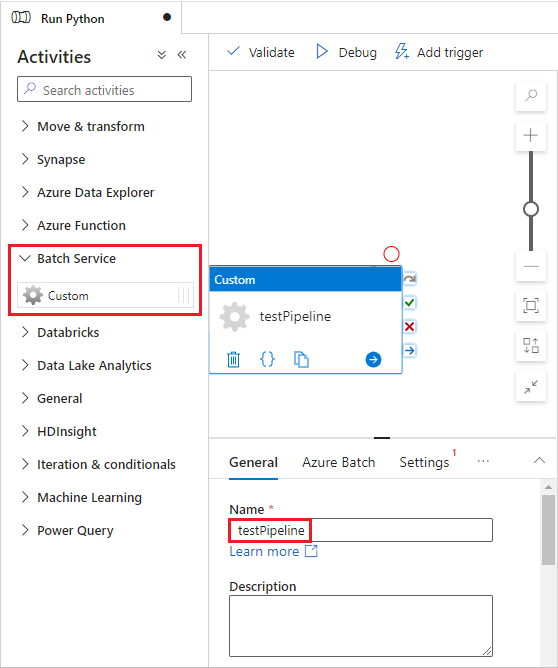
Sélectionnez l’onglet Azure Batch, puis sélectionnez Nouveau.
Remplissez le formulaire Nouveau service lié comme suit :
- Nom : entrez un nom pour le service lié, par exemple AzureBatch1.
- Clé d’accès : entrez la clé d’accès primaire que vous avez copiée à partir de votre compte Batch.
- Nom du compte : entrez le nom de votre compte Batch.
-
URL Batch : entrez le point de terminaison de compte que vous avez copié à partir de votre compte Batch, par exemple
https://batchdotnet.eastus.batch.azure.com. - Nom du pool : entrez custom-activity-pool, le pool que vous avez créé dans Batch Explorer.
- Nom du service lié au compte de stockage : sélectionnez Nouveau. Dans l’écran suivant, entrez un Nom pour le service de stockage lié, par exemple AzureBlobStorage1, sélectionnez votre abonnement Azure et votre compte de stockage lié, puis sélectionnez Créer.
En bas de l’écran Nouveau service lié Batch, sélectionnez Tester la connexion. Quand la connexion est correctement effectuée, sélectionnez Créer.
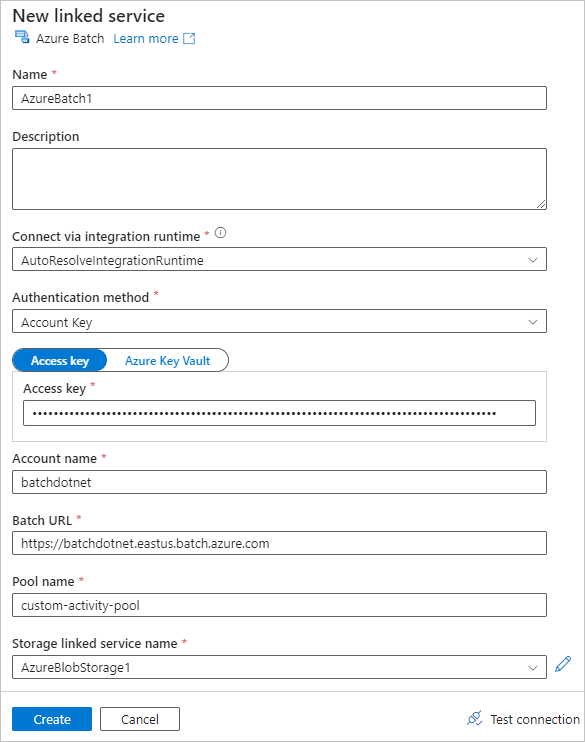
Sélectionnez l’onglet Paramètres et entrez ou sélectionnez les paramètres suivants :
-
Commande : entrez
cmd /C python main.py. - Service lié aux ressources : sélectionnez le service de stockage lié que vous avez créé, tel qu’AzureBlobStorage1, puis testez la connexion pour vous assurer qu’elle réussit.
- Chemin du dossier : sélectionnez l’icône de dossier, puis sélectionnez le conteneur input et sélectionnez OK. Les fichiers de ce dossier sont téléchargés à partir du conteneur vers les nœuds des pools avant l’exécution du script Python.
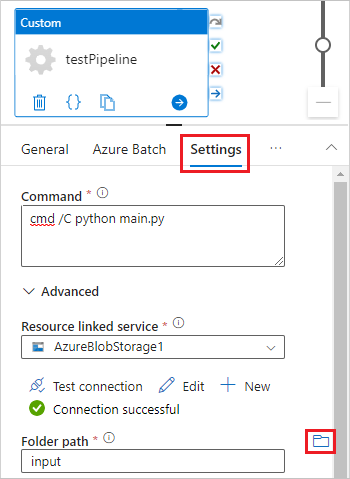
-
Commande : entrez
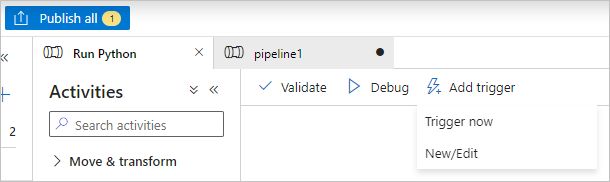
Sélectionnez Valider dans la barre d’outils du pipeline pour valider celui-ci.
Sélectionnez Déboguer pour tester le pipeline et vérifier qu’il fonctionne correctement.
Sélectionnez Publier tout pour publier le pipeline.
Sélectionnez Ajouter un déclencheur, puis sélectionnez Déclencher maintenant pour exécuter le pipeline ou Nouveau/Modifier pour le planifier.

Utiliser Batch Explorer pour visualiser les fichiers journaux
Si l’exécution de votre pipeline génère des avertissements ou des erreurs, vous pouvez utiliser Batch Explorer pour consulter les fichiers de sortie stdout.txt et stderr.txt pour plus d’informations.
- Dans Batch Explorer, sélectionnez Travaux dans la barre latérale gauche.
- Sélectionnez le travail adfv2-custom-activity-pool.
- Sélectionnez une tâche pour laquelle un code de sortie d’échec a été retourné.
- Affichez les fichiers stdout.txt et stderr.txt pour investiguer et diagnostiquer votre problème.
Nettoyer les ressources
Les comptes, travaux et tâches Batch sont gratuits, mais les nœuds de calcul entraînent des frais même s’ils n’exécutent pas de travaux. Il est préférable d’allouer des pools de nœuds uniquement en fonction des besoins et de les supprimer quand vous en avez terminé. La suppression de pools supprime toutes les sorties des tâches sur les nœuds et les nœuds eux-mêmes.
Les fichiers d’entrée et de sortie restent dans le compte de stockage et peuvent entraîner des frais. Quand vous n’avez plus besoin des fichiers, vous pouvez supprimer les fichiers ou conteneurs. Quand vous n’avez plus besoin de votre compte Batch ou de votre compte de stockage lié, vous pouvez les supprimer.
Étapes suivantes
Dans ce tutoriel, vous avez appris à utiliser un script Python avec Batch Explorer, l’Explorateur Stockage et Data Factory pour exécuter une charge de travail Batch. Pour plus d’informations sur Data Factory, consultez Qu’est-ce qu’Azure Data Factory ?