Utiliser Azure Databricks dans l'analytique à l'échelle du cloud dans Azure
Azure Databricks est une plateforme d’analytique données optimisée pour la plateforme Microsoft Azure Cloud Services. Azure Databricks offre deux environnements pour développer des applications qui consomment des quantités importantes de données :
Azure Databricks SQL Analytics, qui permet d’exécuter des requêtes SQL ad hoc rapides sur votre lac de données.
Azure Databricks Data Science et Engineering (parfois simplement appelé « Espace de travail ») est une plateforme d’analytique basée sur Apache Spark. Cette plateforme est intégrée à Azure pour offrir une configuration en un seul clic, des workflows simplifiés et un espace de travail interactif qui permettent aux ingénieurs Données, aux scientifiques des données et aux ingénieurs Machine Learning de collaborer.
Pour l’analytique à l’échelle du cloud, nous allons nous concentrer sur Azure Databricks Data Science et Engineering.
Vue d’ensemble
Vous avez la possibilité de déployer deux espaces de travail partagés pour chaque zone d’atterrissage de données que vous déployez. Un espace de travail dédié à l’ingestion agnostique des données et un autre dédié à l’analytique.
- L’espace de travail Ingénierie Azure Databricks pour l’ingestion et le traitement se connectent à Azure Data Lake via des principaux de service Azure. Elle est appelée par l’ingestion agnostique des données.
- L’espace de travail d’analytique Azure Databricks peut être provisionné pour l’ensemble des scientifiques de données et les équipes d’exploitation des données. Cet espace de travail se connecte à Azure Data Lake en utilisant l’authentification directe Microsoft Entra. Vous partagez l’espace de travail Science des données et analytique Azure Databricks dans la zone d’atterrissage des données avec tous les utilisateurs qui ont accès à l’espace de travail.
Si vous avez un moteur d’ingestion agnostique des données automatisé, l’espace de travail Ingénierie Azure Databricks utilise à la fois l’instance Azure Key Vault créée dans le groupe de ressources Metadata Service Azure pour l’exécution de pipelines d’ingestion des données du format brut au format enrichi.
L’espace de travail d’analytique Azure Databricks doit avoir des stratégies de cluster qui nécessitent la création de clusters à forte concurrence. Ce type de cluster permet l’exploration du lac de données en utilisant des informations d’identification d’authentification directe Microsoft Entra. Pour plus d’informations, consultez Contrôle d’accès et configurations de lacs de données dans Azure Data Lake Storage.
Configurer Azure Databricks
Le déploiement Azure Databricks est en partie basé sur des paramètres via un modèle Azure Resource Manager et des scripts YAML. Il nécessite également une intervention manuelle pour configurer tous les espaces de travail.
Tous les espaces de travail Azure Databricks doivent utiliser le plan Premium, qui fournit les fonctionnalités requises suivantes :
- Mise à l’échelle automatique optimisée du calcul
- Authentification directe avec des informations d’identification Microsoft Entra
- Authentification conditionnelle
- Contrôle d’accès en fonction du rôle pour les notebooks, les clusters, les travaux et les tables
- Journaux d’audit
Pour s’aligner sur l’analytique à l’échelle du cloud, nous conseillons que tous les espaces de travail disposent des options de déploiement par défaut suivantes :
- Les espaces de travail Azure Databricks se connectent à une instance de metastore Apache Hive externe dans la zone d’atterrissage des données.
- Configurez chaque espace de travail pour envoyer la journalisation des diagnostics Databricks à Azure Log Analytics dans databricks-monitoring-rg
- Implémentez des stratégies de cluster pour limiter la possibilité de créer des clusters basés sur un ensemble de règles. Pour plus d’informations, consultez Gérer les stratégies de cluster.
- Définissez plusieurs stratégies de cluster. Dans le cadre du processus d’intégration, attribuez à chaque groupe cible l’autorisation d’utilisation par l’équipe d’exploitation de la zone d’atterrissage des données. Par défaut, l’autorisation de création de cluster est accordée uniquement à l’équipe d’exploitation. Plusieurs équipes ou groupes ont l’autorisation d’utiliser des stratégies de cluster.
- Utilisez les stratégies de cluster en association avec les pools Azure Databricks pour réduire le temps de démarrage et de mise à l’échelle automatique du cluster en conservant un ensemble d’instances inactives et prêtes à l’emploi. Pour plus d'informations, consultez Pools.
- Récupérez tous les secrets opérationnels Azure Databricks, tels que les informations d’identification SPN et les chaînes de connexion, à partir d’une instance Azure Key Vault.
- Configurez une application d’entreprise distincte par espace de travail pour une utilisation avec SCIM (système pour la gestion des identités inter-domaines). Créez un lien vers l’espace de travail Azure Databricks pour contrôler l’accès et les autorisations d’accès à chaque espace de travail. Pour plus d’informations, consultez Provisionner des utilisateurs et des groupes en utilisant SCIM et Configurer le provisionnement SCIM pour Microsoft Entra ID.
Avertissement
Si vous ne configurez pas d’espace de travail Azure Databricks pour utiliser l’interface Azure Databricks SCIM, cela a un impact sur la façon dont vous fournissez des contrôles de sécurité. Vous passez d’un processus automatisé à un processus manuel, ce qui interrompt tous les pipelines CI/CD de déploiement.
Les options de contrôle d’accès suivantes sont définies pour tous les espaces de travail Databricks :
- Contrôle de visibilité de l’espace de travail : activé (valeur par défaut : désactivé)
- Contrôle de visibilité du cluster : activé (valeur par défaut : désactivé)
- Contrôle de visibilité du travail : activé (valeur par défaut : désactivé)
Vous pouvez activer les options suivantes pour l’espace de travail d’analytique Azure Databricks :
- Exportation du notebook : désactivée (valeur par défaut : activée)
- Fonctionnalités du presse-papiers de la table de notebook : désactivées (valeur par défaut : activées)
- Contrôle d’accès à la table : activé (valeur par défaut : désactivé)
- Accès conditionnel Microsoft Entra
Déployer Azure Databricks
Si vous déployez les espaces de travail Azure Databricks dans le cadre d’un nouveau déploiement de la zone d’atterrissage des données. L’illustration suivante montre l’exemple de flux de travail de déploiement d’un environnement Azure Databricks dans l’analytique à l’échelle du cloud.
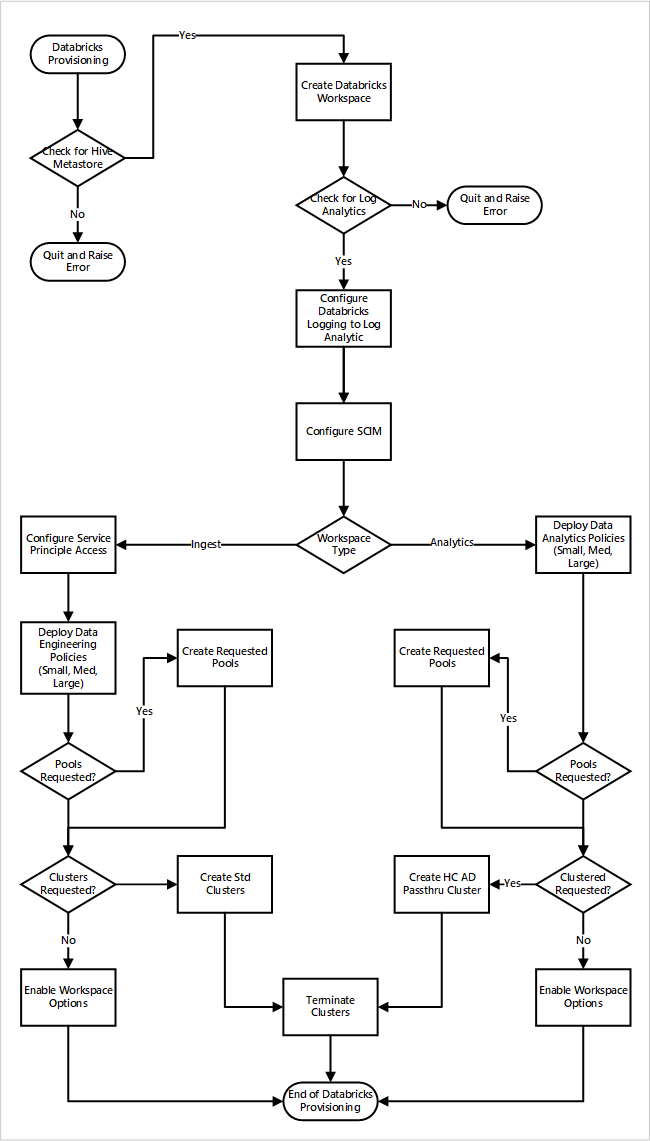
- Le processus de provisionnement commence par vérifier qu’une instance de metastore Apache Hive existe dans la zone d’atterrissage des données. S’il ne parvient pas à trouver le metastore Apache Hive, il se ferme et génère une erreur.
- Une fois qu’il a trouvé le metastore Apache Hive, un espace de travail est créé.
- Le processus recherche un espace de travail Log Analytics dans la zone d’atterrissage des données. S’il ne parvient pas à trouver l’espace de travail Log Analytics, il se ferme et génère une erreur.
- Pour chaque espace de travail, il crée une application Microsoft Entra et configure SCIM.
Pour l’espace de travail d’ingestion Azure Databricks :
- Le processus configure l’espace de travail avec l’accès au principal du service.
- Les stratégies d’engineering données qui ont été définies par l’équipe d’exploitation de la plateforme de données sont déployées.
- Si l’équipe d’exploitation de la zone d’atterrissage des données a demandé des pools ou des clusters Databricks, ceux-ci peuvent être intégrés dans le processus de déploiement.
- Elle active les options d’espace de travail propres à l’espace de travail Ingénierie Azure Databricks.
Pour l’espace de travail d’analytique Azure Databricks :
- Le processus déploie les stratégies d’analytique données qui ont été définies par l’équipe d’exploitation de la plateforme de données.
- Si l’équipe d’exploitation de la zone d’atterrissage des données a demandé des pools ou des clusters Databricks, ceux-ci peuvent être intégrés dans le processus de déploiement.
- Elle active les options d’espace de travail propres à l’espace de travail Ingénierie Azure Databricks.
Metastore Hive externe
Dans un déploiement d’espace de travail Azure Databricks :
- Un nouveau script init global configure les paramètres du metastore Apache Hive pour tous les clusters. Ce script est géré par la nouvelle API Scripts init globaux.
La nouvelle API Scripts init globaux est en préversion publique. Les fonctionnalités en préversion publique dans Azure Databricks sont prêtes pour les environnements de production et sont prises en charge par l’équipe de support technique. Pour plus d'informations, consultez Publication des préversions d’Azure Databricks.
- Cette solution utilise Azure Database pour MySQL pour stocker l’instance de metastore Apache Hive. Cette base de données a été choisie pour sa rentabilité et sa haute compatibilité avec Apache Hive.
Étapes suivantes
L’analytique à l’échelle du cloud prend en compte les recommandations suivantes pour l’intégration d’Azure Databricks :