Contrôle d’accès et configurations des lacs de données dans Azure Data Lake Storage Gen2
Utilisez cet article pour vous aider à évaluer et à comprendre les mécanismes de contrôle d’accès dans Azure Data Lake Storage Gen2. Ces mécanismes comprennent le contrôle d’accès en fonction du rôle (RBAC) et les listes de contrôle d’accès (ACL). Vous allez découvrir :
- Comment évaluer l’accès entre RBAC Azure et les listes de contrôle d’accès (ACL)
- Comment configurer le contrôle en utilisant un de ces mécanismes ou les deux
- Comment appliquer les mécanismes de contrôle d’accès aux modèles d’implémentation des lacs de données
Vous avez besoin d’une connaissance de base des conteneurs de stockage, des groupes de sécurité, d’Azure RBAC et des ACL. Pour délimiter la discussion, nous faisons référence à une structure générique de lac de données de zones brutes, enrichies et organisées.
Vous pouvez utiliser ce document avec la gestion de l’accès aux données.
Utilisation des rôles Azure RBAC intégrés
Le stockage Azure présente deux couches d’accès : le management des services et les données. Les abonnements et les comptes de stockage sont accessibles via la couche de management des services. Les conteneurs, objets blob et autres ressources de données sont accessibles via la couche de données. Par exemple, si vous souhaitez obtenir la liste des comptes de stockage depuis Azure, envoyez une requête au point de terminaison de gestion. Si vous souhaitez obtenir la liste des systèmes de fichiers, dossiers ou fichiers d’un compte de stockage, envoyez une demande à un point de terminaison de service.
Les rôles peuvent contenir des autorisations d’accès à ces couches de données ou de gestion. Le rôle Lecteur accorde un accès en lecture seule aux ressources de la couche de gestion, mais ne dispose pas d’un accès en lecture aux données.
Les rôles, tels que Propriétaire, Collaborateur, Lecteur et Contributeur de compte de stockage, permettent à un principal de sécurité de gérer un compte de stockage. Ils ne fournissent pas d’accès aux données dans ce cas. Seuls les rôles explicitement définis pour l’accès aux données permettent à un principal de sécurité d’accéder aux données. Ces rôles, à l’exception de Lecteur, peuvent obtenir l’accès aux clés de stockage pour accéder aux données.
Rôles de gestion intégrés
Les rôles de gestion intégrés sont les suivants.
- Propriétaire : Gérez tout, notamment l’accès aux ressources. Ce rôle fournit un accès essentiel.
- Contributeur : Gérez tout, sauf l’accès aux ressources. Ce rôle fournit un accès essentiel.
- Contributeur de compte de stockage : Gérez en totalité les comptes de stockage. Ce rôle fournit un accès essentiel.
- Lecteur : Lisez et listez les ressources. Ce rôle ne fournit pas d’accès essentiel.
Rôles de données intégrés
Les rôles de données intégrés sont les suivants.
- Propriétaire des données Blob du stockage : Accès complet aux conteneurs d’objets blob du stockage Azure et aux données, notamment la définition de la propriété et la gestion du contrôle d’accès POSIX.
- Contributeur aux données Blob du stockage : Lire, écrire et supprimer des conteneurs et objets blob du stockage Azure.
- Lecteur des données blob du stockage : Lire et répertorier des conteneurs et objets blob du stockage Azure.
Le propriétaire des données Blob du stockage est un super utilisateur qui bénéficie d’un accès complet à toutes les opérations de mutation. Ces opérations incluent la définition du propriétaire d’un répertoire ou d’un fichier et d’ACL pour les répertoires et les fichiers pour lesquels ils ne sont pas propriétaires. L’accès de super utilisateur constitue la seule manière autorisée de modifier le propriétaire d’une ressource.
Remarque
La propagation et l’application des affectations Azure RBAC peuvent prendre jusqu’à cinq minutes.
Évaluation de l’accès
Au cours de l’autorisation basée sur les entités de sécurité, les autorisations sont évaluées dans l’ordre suivant. Pour plus d’informations, consultez le diagramme suivant.
- Azure RBAC est évalué en premier et est prioritaire sur les affectations d’ACL.
- Si l’opération est entièrement autorisée en fonction de RBAC, les ACL ne sont pas évaluées du tout.
- Si l’opération n’est pas entièrement autorisée, les ACL sont évaluées.
Pour plus d’informations, consultez Évaluation des autorisations.
Remarque
Ce modèle d’autorisation ne s’applique qu’à Azure Data Lake Storage. Il ne s’applique pas au stockage à usage général ou Blob sans espace de noms hiérarchique activé.
Cette description exclut les méthodes d’authentification par clé partagée et SAS. Il exclut également les scénarios dans lesquels le principal de sécurité a reçu le rôle intégré de Propriétaire des données Blob du stockage, qui procure un accès super utilisateur.
Définissez allowSharedKeyAccess sur false afin que l’accès soit audité par l’identité.

Pour plus d’informations sur les autorisations basées sur une liste de contrôle d’accès (ACL) requises pour une opération donnée, consultez Listes de contrôle d’accès dans Azure Data Lake Storage Gen2.
Remarque
- Les listes de contrôle d’accès ne s’appliquent qu’aux principaux de sécurité dans le même locataire, notamment les utilisateurs invités.
- Tout utilisateur disposant d’autorisations d’attachement à un cluster peut créer des points de montage Azure Databricks. Configurez le point de montage à l’aide des informations d’identification du principal de service ou de l’option de transmission directe (passthrough) de Microsoft Entra. Au moment de la création, les autorisations ne sont pas évaluées. Les autorisations sont évaluées lorsqu’une opération utilise le point de montage. Tout utilisateur qui peut se connecter à un cluster peut tenter d’utiliser le point de montage.
- Lors de la création d’une définition de table dans Azure Databricks ou Azure Synapse Analytics, l’utilisateur doit disposer d’un accès en lecture aux données sous-jacentes.
Configurer l’accès à Azure Data Lake Storage
Implémentez le contrôle d’accès dans Azure Data Lake Storage à l’aide d’Azure RBAC, d’ACL ou d’une combinaison des deux.
Configurer l’accès à l’aide d’Azure RBAC uniquement
Si le contrôle d’accès au niveau du conteneur est suffisant, les affectations Azure RBAC offrent une approche de gestion simple pour la sécurisation des données. Il est recommandé d’utiliser les listes de contrôle d’accès pour un grand nombre de ressources de données restreintes ou lorsque le contrôle d’accès granulaire est requis.
Configurer l’accès à l’aide des ACL uniquement
Voici les recommandations de configuration des listes de contrôle d’accès pour l’analytique à l’échelle du cloud.
Nous vous recommandons d’affecter des entrées de contrôle d’accès à un groupe de sécurité plutôt qu’à un utilisateur individuel ou à un principal de service. Pour plus d’informations, consultez Utilisation de groupes de sécurité et d’utilisateurs individuels.
Lorsque vous ajoutez ou supprimez des utilisateurs du groupe, vous n’êtes pas obligé d’effectuer des mises à jour sur Data Lake Storage. L’utilisation de groupes réduit également le risque de dépasser les 32 entrées de contrôle d’accès par ACL de fichier ou de dossier. Après les quatre entrées par défaut, il n’en reste que 28 pour les affectations d’autorisations.
Même en utilisant des groupes, vous pouvez avoir de nombreuses entrées de contrôle d’accès à des niveaux supérieurs de l’arborescence de répertoires. Cette situation peut se produire lorsque des autorisations granulaires sont requises pour les différents groupes.

Configurer l’accès à l’aide d’Azure RBAC et des listes de contrôle d’accès
L’autorisation Lecteur/Contributeur aux données Blob du stockage permet d’accéder aux données et non au compte de stockage. Vous pouvez accorder l’accès au niveau du compte de stockage ou du conteneur. Si le Contributeur aux données Blob du stockage est affecté, les ACL ne peuvent pas être utilisées pour gérer l’accès. Lorsque le Lecteur des données Blob du stockage est affecté, des autorisations d’accès en écriture élevées peuvent être accordées à l’aide d’ACL. Pour plus d’informations, consultez Évaluation de l’accès.
Cette approche favorise les scénarios où la plupart des utilisateurs ont besoin d’un accès en lecture, mais que seuls quelques utilisateurs ont besoin d’un accès en écriture. Les zones de lac de données peuvent être des comptes de stockage différents et les ressources de données peuvent être des conteneurs différents. Les zones de lac de données peuvent être représentées par des conteneurs et les ressources de données, par des dossiers.
Approches du groupe imbriqué de listes de contrôle d’accès
Il existe deux approches des groupes d’ACL imbriqués.
Option 1 : Groupe d’exécution parent
Avant de créer des fichiers et des dossiers, commencez par un groupe parent. Affectez à ce groupe des autorisations d’exécution sur les ACL par défaut et d’accès au niveau du conteneur. Ajoutez ensuite les groupes qui nécessitent l’accès aux données au groupe parent.
Avertissement
Nous vous recommandons d’éviter ce modèle où vous avez des suppressions récursives et d’utiliser plutôt l’Option 2 : Autre entrée de liste de contrôle d’accès.
Cette technique est appelée imbrication de groupes. Le groupe de membres hérite des autorisations du groupe parent, qui fournit des autorisations d’exécution globale à tous les groupes de membres. Le groupe de membres n’a pas besoin d’autorisations d’exécution, car ces autorisations sont héritées. Un plus grand nombre d’imbrications peut offrir une flexibilité et une agilité plus importantes. Ajoutez des groupes de sécurité qui représentent des équipes ou des travaux automatisés aux groupes de lecteurs et de rédacteurs d’accès aux données.
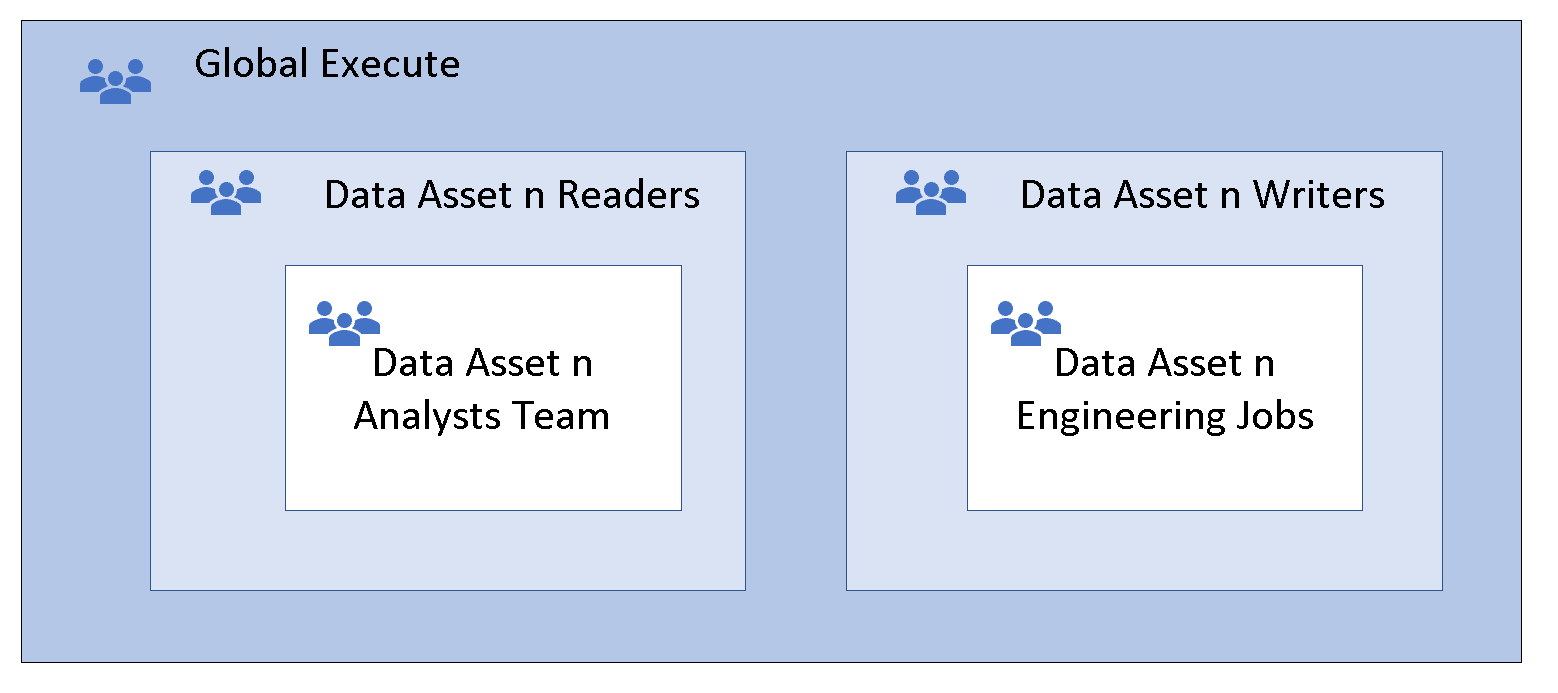
Option 2 : Autre entrée de la liste de contrôle d’accès
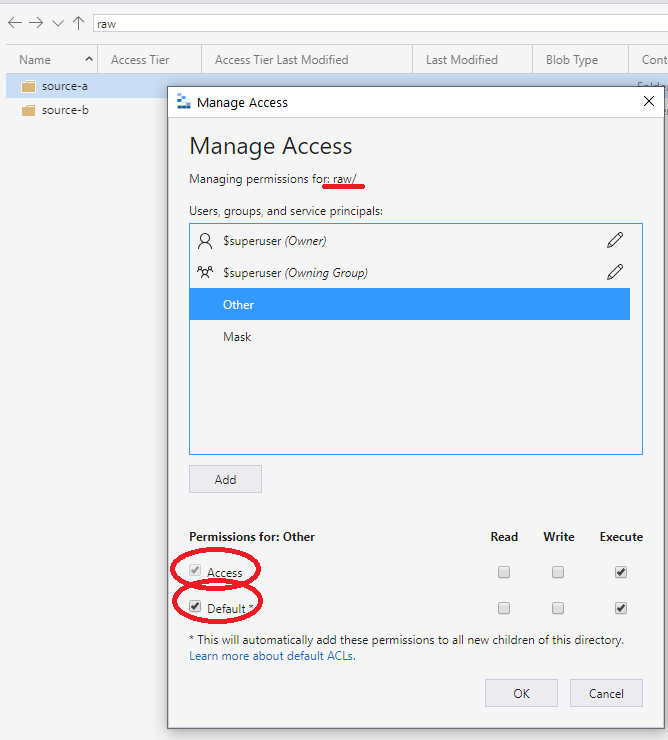
L’approche recommandée consiste à utiliser l’autre entrée de l’ACL définie au niveau du conteneur ou de la racine. Spécifiez les valeurs par défaut et les ACL d’accès comme indiqué dans l’écran suivant. Cette approche garantit que chaque partie du chemin d’accès de la racine au niveau le plus bas dispose d’autorisations d’exécution.
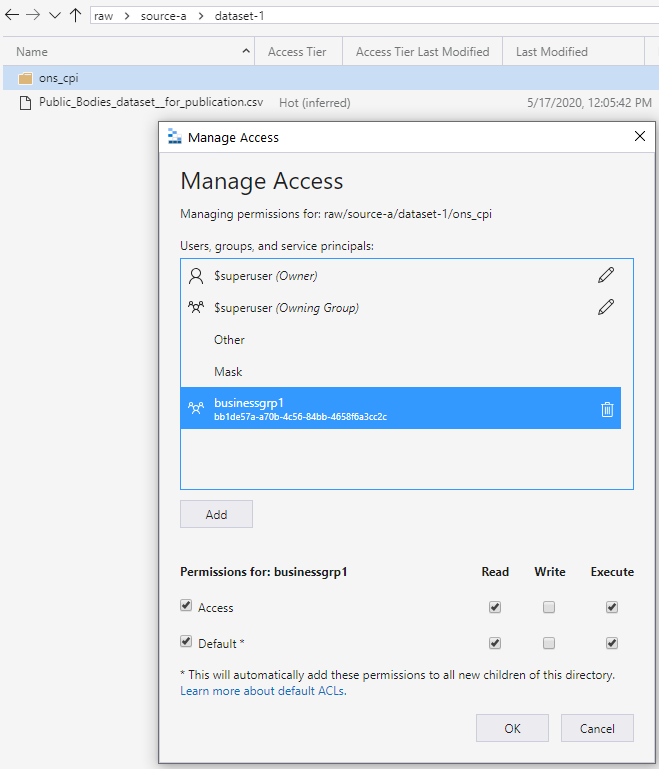
Cette autorisation d’exécution se propage aux dossiers enfants ajoutés. L’autorisation se propage en profondeur jusqu’au niveau où le groupe d’accès prévu a besoin d’autorisations de lecture et d’exécution. Le niveau se trouve dans la partie la plus basse de la chaîne, comme illustré dans l’écran suivant. Cette approche accorde l’accès de groupe pour lire les données. L’approche fonctionne de la même façon pour l’accès en écriture.
Sécurité des zones de lac de données recommandée
Ces utilisations suivantes sont les modèles de sécurité recommandés pour chacune des zones de lac de données :
- La zone brute ne doit autoriser l’accès qu’aux données à l’aide de noms de principal de sécurité (SPN).
- La zone enrichie ne doit autoriser l’accès qu’aux données à l’aide de noms de principal de sécurité (SPN).
- La zone organisée doit autoriser l’accès avec des noms de principal de sécurité (SPN) et des noms d’utilisateur principal (UPN).
Exemple de scénario pour l’utilisation des groupes de sécurité Microsoft Entra
Il existe plusieurs façons de configurer des groupes. Par exemple, imaginez que vous disposez d’un répertoire nommé /LogData qui contient les données du journal générées par votre serveur. Azure Data Factory ingère les données dans ce dossier. Les utilisateurs spécifiques de l’équipe d’ingénierie des services chargent les journaux et gèrent les autres utilisateurs de ce dossier. Les clusters d’espace de travail de la science des données et d’analyse Azure Databricks peuvent analyser les journaux à partir de ce dossier.
Pour autoriser ces activités, créez un groupe LogsWriter et un groupe LogsReader. Attribuez les autorisations suivantes :
- Ajoutez le groupe
LogsWriterà l’ACL du répertoire/LogDataavec les autorisationsrwx. - Ajoutez le groupe
LogsReaderà l’ACL du répertoire/LogDataavec les autorisationsr-x. - Ajoutez l’objet de principal de service ou Managed Service Identity (MSI) pour Data Factory au groupe
LogsWriters. - Ajoutez les utilisateurs de l’équipe d’ingénierie des services au groupe
LogsWriter. - Azure Databricks est configuré pour le passage de Microsoft Entra vers le magasin Azure Data Lake.
Si un utilisateur de l’équipe d’ingénierie des services est transféré vers une autre équipe, supprimez simplement cet utilisateur du groupe LogsWriter.
Si vous n’avez pas ajouté cet utilisateur à un groupe, mais que vous avez ajouté une entrée ACL dédiée pour cet utilisateur, vous devez supprimer cette entrée ACL du répertoire /LogData. Vous devez également supprimer l’entrée de tous les sous-répertoires et fichiers de l’ensemble de la hiérarchie de répertoires du répertoire /LogData.
Contrôle d’accès aux données Azure Synapse Analytics
Pour déployer un espace de travail Azure Synapse, un compte Azure Data Lake Storage Gen2 est nécessaire. Azure Synapse Analytics utilise le compte de stockage principal pour plusieurs scénarios d’intégration et stocke les données dans un conteneur. Le conteneur contient des tables et des journaux des applications Apache Spark dans un dossier appelé /synapse/{workspaceName} . L’espace de travail utilise également un conteneur pour gérer les bibliothèques que vous choisissez d’installer.
Lors du déploiement de l’espace de travail via le portail Azure, fournissez un compte de stockage existant ou créez-en un. Le compte de stockage fourni est le compte de stockage principal de l’espace de travail. Le processus de déploiement accorde l’accès pour l’identité de l’espace de travail au compte Data Lake Storage Gen2 spécifié à l’aide du rôle Contributeur aux données Blob du Stockage.
Si vous déployez l’espace de travail en dehors du portail Azure, ajoutez manuellement l’identité de l’espace de travail Azure Synapse Analytics au rôle Contributeur aux données Blob du stockage. Nous vous recommandons d’attribuer le rôle Contributeur aux données Blob du stockage au niveau du conteneur pour suivre le principe du privilège minimum.
Lors de l’exécution de pipelines, de flux de travail et de blocs-notes par le biais de travaux, le contexte d’autorisation d’identité d’espace de travail est utilisé. Si l’un des travaux est lu ou écrit dans le stockage principal de l’espace de travail, l’identité de l’espace de travail utilise les autorisations de lecture/écriture accordées via le Contributeur aux données Blob du stockage.
Lorsque les utilisateurs se connectent à l’espace de travail pour exécuter des scripts ou pour le développement, les autorisations de contexte de l’utilisateur sont utilisées pour autoriser l’accès en lecture/écriture sur le stockage principal.
Contrôle d’accès aux données affiné à l’aide d’Azure Synapse Analytics à l’aide de listes de contrôle d’accès
Lors de la configuration du contrôle d’accès au lac de données, certaines organisations ont besoin d’un accès de niveau granulaire. Elles peuvent posséder des données sensibles qui ne peuvent pas être vues par certains groupes de l’organisation. Azure RBAC n’autorise les accès en lecture ou en écriture qu’au niveau du compte de stockage et du conteneur. Avec les listes de contrôle d’accès, vous pouvez configurer un contrôle d’accès affiné au niveau des dossiers et des fichiers pour autoriser la lecture/l’écriture sur un sous-ensemble de données pour des groupes spécifiques.
Considérations relatives à l’utilisation des tables Spark
Lorsque vous utilisez des tables Apache Spark dans le pool Spark, un dossier entrepôt est créé. Ce dossier se trouve à la racine du conteneur dans le stockage principal de l’espace de travail :
synapse/workspaces/{workspaceName}/warehouse
Si vous envisagez de créer des tables Apache Spark dans le pool Azure Synapse Spark, accordez l’autorisation d’accès en écriture sur le dossier de l'entrepôt pour le groupe exécutant la commande qui crée la table Spark. Si la commande s’exécute via un travail déclenché dans un pipeline, accordez une autorisation d’accès en écriture à l’espace de travail MSI.
L'exemple suivant crée une table Spark :
df.write.saveAsTable("table01")
Pour plus d’informations, consultez Guide pratique pour configurer le contrôle d’accès pour votre espace de travail Synapse.
Résumé de l’accès Azure Data Lake
Aucune approche unique de la gestion de l’accès au lac de données n’est adaptée à tous. L’un des principaux avantages d’un lac de données est de fournir un accès sans heurt aux données. En pratique, des organisations différentes veulent des niveaux différents de gouvernance et de contrôle sur leurs données. Certaines organisations disposent d’une équipe centralisée pour gérer l’accès et approvisionner les groupes avec des contrôles internes rigoureux. D’autres organisations sont plus agiles et disposent d’un contrôle décentralisé. Choisissez l’approche qui correspond à votre niveau de gouvernance. Votre choix ne doit pas entraîner de retards ni de frictions excessifs pour bénéficier d’un accès aux données.