Utiliser un conteneur Azure AI Vision avec Kubernetes et Helm
L’une des options permettant de gérer vos conteneurs Azure AI Vision en local consiste à utiliser Kubernetes et Helm. En utilisant Kubernetes et Helm pour définir une image de conteneur Azure AI Vision, nous créons un package Kubernetes. Ce package sera déployé sur un cluster Kubernetes local. Enfin, nous allons découvrir comment tester les services déployés. Pour plus d’informations sur l’exécution de conteneurs Docker sans orchestration Kubernetes, consultez Installer et exécuter des conteneurs Azure AI Vision.
Prérequis
L’utilisation locale des conteneurs Azure AI Vision est soumise aux prérequis suivants :
| Obligatoire | Objectif |
|---|---|
| Compte Azure. | Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer. |
| Kubernetes CLI | L’interface Kubernetes CLI est requise pour gérer les informations d’identification partagées à partir du registre de conteneurs. Kubernetes est également nécessaire avant Helm, qui est le gestionnaire de package de Kubernetes. |
| Helm CLI | Installez l’interface de ligne de commande Helm, utilisée pour installer un graphique Helm (définition de package de conteneur). |
| Ressource Vision par ordinateur | Pour pouvoir utiliser le conteneur, vous devez disposer des éléments suivants : Une ressource Vision par ordinateur, la clé d’API associée et l’URI de point de terminaison. Les deux valeurs, disponibles dans les pages Vue d’ensemble et Clés de la ressource, sont nécessaires au démarrage du conteneur. {API_KEY} : L’une des deux clés de ressource disponibles à la page Clés {ENDPOINT_URI} : Le point de terminaison tel qu'il est fourni à la pageVue d’ensemble |
Collecter les paramètres obligatoires
Trois paramètres principaux sont obligatoires pour tous les conteneurs Azure AI. Les termes du contrat de licence logiciel Microsoft doivent être présents avec la valeur Accepter. Un URI de point de terminaison et une clé API sont également nécessaires.
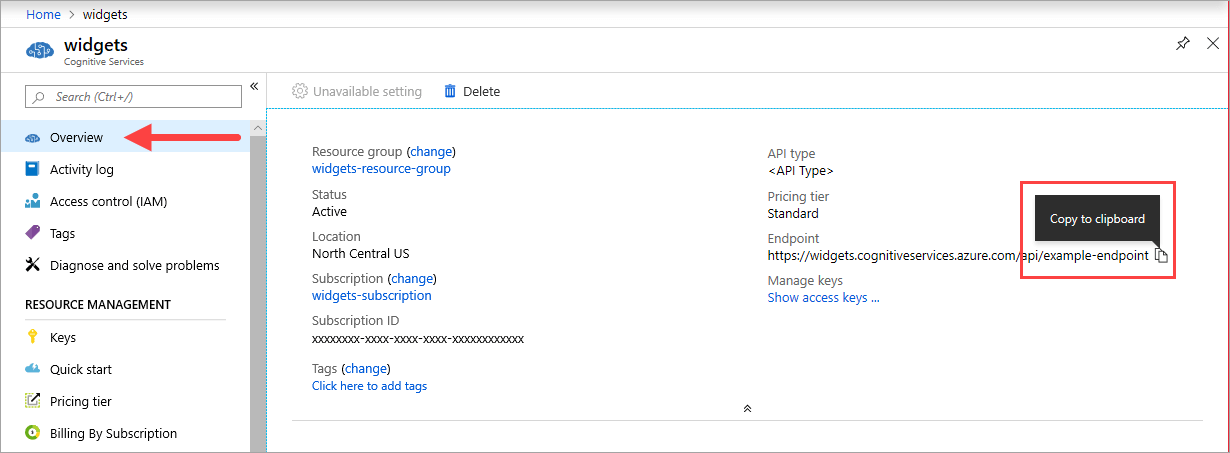
URI de point de terminaison
La valeur {ENDPOINT_URI} est disponible sur la page Vue d’ensemble du portail Azure de la ressource Azure AI services correspondante. Accédez à la page Vue d’ensemble, passez le curseur sur le point de terminaison et une icône Copier dans le Presse-papiers s’affiche. Copiez et utilisez le point de terminaison si nécessaire.
Touches
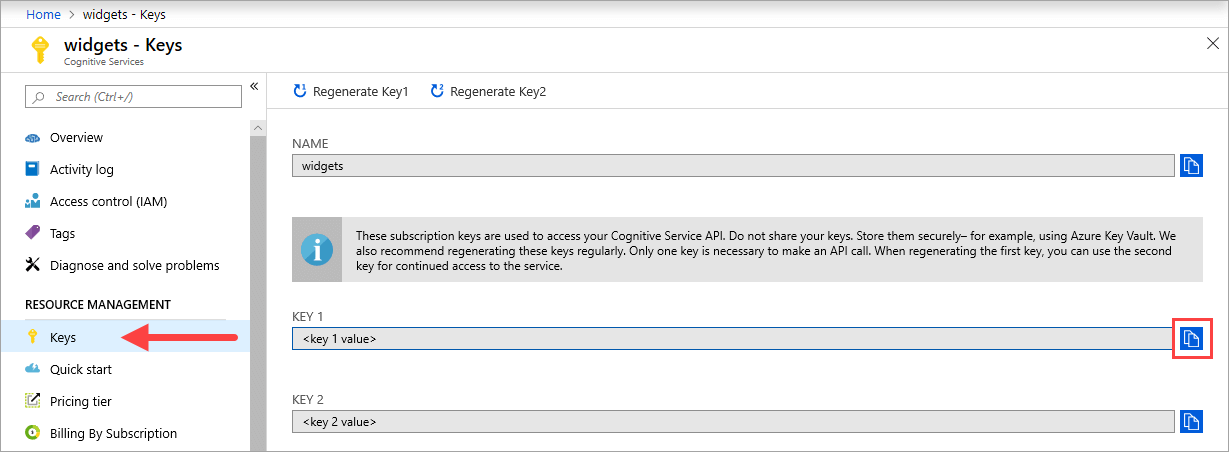
La valeur {API_KEY}, utilisée pour démarrer le conteneur, est disponible sur la page Clés de la ressource Azure AI services correspondante sur le portail Azure. Accédez à la page Clés, puis sélectionnez l’icône Copier dans le Presse-papiers.
Important
Ces clés d’abonnement sont utilisées pour accéder à votre API Azure AI services. Ne partagez pas vos clés. Stockez-les en toute sécurité. Par exemple, utilisez Azure Key Vault. Nous vous recommandons également de regénérer ces clés régulièrement. Une seule clé est nécessaire pour effectuer un appel d’API. Lors de la régénération de la première clé, vous pouvez utiliser la deuxième clé pour un accès continu au service.
L’ordinateur hôte
L’hôte est un ordinateur x64 qui exécute le conteneur Docker. Il peut s’agir d’un ordinateur local ou d’un service d’hébergement Docker dans Azure, comme :
- Azure Kubernetes Service.
- Azure Container Instances.
- Un cluster Kubernetes déployé sur Azure Stack. Pour plus d’informations, consultez Déployer Kubernetes sur Azure Stack.
Exigences et suggestions relatives au conteneur
Notes
Les exigences et les suggestions sont basées sur des tests d’évaluation effectués avec une seule requête par seconde, à partir d’une image de 523 Mo d’une lettre d’entreprise analysée qui contient 29 lignes et 803 caractères au total. La configuration recommandée a entraîné une réponse environ 2 fois plus rapide par rapport à la configuration minimale.
Le tableau suivant décrit l'allocation de ressources minimale et recommandée pour chaque conteneur OCR Read.
| Conteneur | Minimum | Recommandé |
|---|---|---|
| Read 3.2 2022-04-30 | 4 cœurs, 8 Go de mémoire | 8 cœurs, 16 Go de mémoire |
| Read 3.2 2021-04-12 | 4 cœurs, 16 Go de mémoire | 8 cœurs, 24 Go de mémoire |
- Chaque cœur doit être cadencé à au moins 2,6 gigahertz (GHz).
Le nombre de cœurs et la quantité de mémoire correspondent aux paramètres --cpus et --memory qui sont utilisés dans le cadre de la commande docker run.
Se connecter au cluster Kubernetes
L’ordinateur hôte doit avoir un cluster Kubernetes disponible. Consultez ce didacticiel sur le déploiement d’un cluster Kubernetes pour des informations conceptuelles sur la façon de déployer un cluster Kubernetes sur un ordinateur hôte. Pour plus d’informations sur les déploiements, consultez la documentation Kubernetes.
Configurer les valeurs du graphique Helm pour le déploiement
Commencez par créer un dossier nommé lecture. Collez ensuite le contenu YAML suivant dans un nouveau fichier nommé chart.yaml :
apiVersion: v2
name: read
version: 1.0.0
description: A Helm chart to deploy the Read OCR container to a Kubernetes cluster
dependencies:
- name: rabbitmq
condition: read.image.args.rabbitmq.enabled
version: ^6.12.0
repository: https://kubernetes-charts.storage.googleapis.com/
- name: redis
condition: read.image.args.redis.enabled
version: ^6.0.0
repository: https://kubernetes-charts.storage.googleapis.com/
Pour configurer les valeurs par défaut du graphique Helm, copiez et collez le YAML suivant dans un fichier nommé values.yaml. Remplacez les commentaires # {ENDPOINT_URI} et # {API_KEY} par vos propres valeurs. Configurez resultExpirationPeriod, Redis et RabbitMQ si nécessaire.
# These settings are deployment specific and users can provide customizations
read:
enabled: true
image:
name: cognitive-services-read
registry: mcr.microsoft.com/
repository: azure-cognitive-services/vision/read
tag: 3.2-preview.1
args:
eula: accept
billing: # {ENDPOINT_URI}
apikey: # {API_KEY}
# Result expiration period setting. Specify when the system should clean up recognition results.
# For example, resultExpirationPeriod=1, the system will clear the recognition result 1hr after the process.
# resultExpirationPeriod=0, the system will clear the recognition result after result retrieval.
resultExpirationPeriod: 1
# Redis storage, if configured, will be used by read OCR container to store result records.
# A cache is required if multiple read OCR containers are placed behind load balancer.
redis:
enabled: false # {true/false}
password: password
# RabbitMQ is used for dispatching tasks. This can be useful when multiple read OCR containers are
# placed behind load balancer.
rabbitmq:
enabled: false # {true/false}
rabbitmq:
username: user
password: password
Important
Si les valeurs
billingetapikeyne sont pas fournies, les services expirent après 15 minutes. De même, la vérification échoue car les services ne sont pas disponibles.Si vous déployez plusieurs conteneurs Read OCR derrière un équilibreur de charge, par exemple sous Docker Compose ou Kubernetes, vous devez avoir un cache externe. Étant donné que le conteneur de traitement et le conteneur de requêtes GET peuvent être différents, un cache externe est utilisé pour stocker les résultats et les partager entre les conteneurs. Pour plus d’informations sur les paramètres de cache, consultez l’article Configurer les conteneurs Docker Azure AI Vision.
Créez un dossier de modèles sous le répertoire read. Copiez et collez la configuration YAML suivante dans un fichier nommé deployment.yaml. Le fichier deployment.yaml servira de modèle Helm.
Les modèles génèrent des fichiers manifeste, qui sont des descriptions de ressources au format YAML que Kubernetes peut comprendre. - Guide du modèle de graphique Helm
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: {{.Values.read.image.name}}
image: {{.Values.read.image.registry}}{{.Values.read.image.repository}}
ports:
- containerPort: 5000
env:
- name: EULA
value: {{.Values.read.image.args.eula}}
- name: billing
value: {{.Values.read.image.args.billing}}
- name: apikey
value: {{.Values.read.image.args.apikey}}
args:
- ReadEngineConfig:ResultExpirationPeriod={{ .Values.read.image.args.resultExpirationPeriod }}
{{- if .Values.read.image.args.rabbitmq.enabled }}
- Queue:RabbitMQ:HostName={{ include "rabbitmq.hostname" . }}
- Queue:RabbitMQ:Username={{ .Values.read.image.args.rabbitmq.rabbitmq.username }}
- Queue:RabbitMQ:Password={{ .Values.read.image.args.rabbitmq.rabbitmq.password }}
{{- end }}
{{- if .Values.read.image.args.redis.enabled }}
- Cache:Redis:Configuration={{ include "redis.connStr" . }}
{{- end }}
imagePullSecrets:
- name: {{.Values.read.image.pullSecret}}
---
apiVersion: v1
kind: Service
metadata:
name: read-service
spec:
type: LoadBalancer
ports:
- port: 5000
selector:
app: read-app
Dans le même dossier de modèles, copiez et collez les fonctions d’assistance suivantes dans helpers.tpl. helpers.tpl définit des fonctions utiles pour générer le modèle Helm.
{{- define "rabbitmq.hostname" -}}
{{- printf "%s-rabbitmq" .Release.Name -}}
{{- end -}}
{{- define "redis.connStr" -}}
{{- $hostMain := printf "%s-redis-master:6379" .Release.Name }}
{{- $hostReplica := printf "%s-redis-replica:6379" .Release.Name -}}
{{- $passWord := printf "password=%s" .Values.read.image.args.redis.password -}}
{{- $connTail := "ssl=False,abortConnect=False" -}}
{{- printf "%s,%s,%s,%s" $hostMain $hostReplica $passWord $connTail -}}
{{- end -}}
Le modèle spécifie un service d’équilibrage de charge et le déploiement de votre conteneur/image pour Lire.
Le package Kubernetes (graphique Helm)
Le graphique Helm contient la configuration de la ou des images docker à extraire du registre de conteneurs mcr.microsoft.com.
Un graphique Helm est une collection de fichiers qui décrivent un ensemble de ressources Kubernetes. Un graphique unique peut être utilisé pour déployer quelque chose de simple comme un pod mis en cache, ou quelque chose de complexe, comme une pile d’application web complète avec des serveurs HTTP, des bases de données, des caches et ainsi de suite.
Les graphiques Helm fournis tirent les images Docker du service Azure AI Vision et le service correspondant du registre de conteneurs mcr.microsoft.com.
Installer le graphique Helm sur le cluster Kubernetes
Pour installer le graphique Helm, vous devez exécuter la commande helm install. Veillez à exécuter la commande d’installation à partir du répertoire situé au-dessus du dossier read.
helm install read ./read
Voici un exemple de sortie que vous pouvez vous attendre à voir pour une exécution d’installation réussie :
NAME: read
LAST DEPLOYED: Thu Sep 04 13:24:06 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
read-57cb76bcf7-45sdh 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 0s
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
read 0/1 1 0 0s
Le déploiement de Kubernetes peut prendre plusieurs minutes. Pour vérifier que les pods et les services sont correctement déployés et disponibles, exécutez la commande suivante :
kubectl get all
Vous devriez obtenir un graphique similaire à la sortie suivante :
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-57cb76bcf7-45sdh 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
service/read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 1/1 1 1 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-57cb76bcf7 1 1 1 17s
Déployer plusieurs conteneurs v3 sur le cluster Kubernetes
Depuis la version v3 du conteneur, vous pouvez utiliser les conteneurs en parallèle au niveau d’une tâche et d’une page.
Par défaut, chaque conteneur v3 a un répartiteur et un Worker de reconnaissance. Le répartiteur est chargé de fractionner une tâche de plusieurs pages en plusieurs sous-tâches d’une seule page. Le Worker de reconnaissance est optimisé pour la reconnaissance d’un document d’une seule page. Pour atteindre le parallélisme au niveau de la page, déployez plusieurs conteneurs v3 derrière un équilibreur de charge et laissez les conteneurs partager un stockage et une file d’attente universels.
Notes
Actuellement, seuls les stockages et les files d’attente Azure sont pris en charge.
Le conteneur recevant la demande peut fractionner la tâche en sous-tâches d’une seule page et ajouter celles-ci à la file d’attente universelle. Tout Worker de reconnaissance d’un conteneur moins occupé peut consommer des sous-tâches de page unique de la file d’attente, effectuer la reconnaissance et charger le résultat dans le stockage. Le débit peut être amélioré jusqu’à n fois, en fonction du nombre de conteneurs déployés.
Le conteneur v3 expose l’API de probe liveness dans le chemin /ContainerLiveness. Utilisez l’exemple de déploiement suivant afin de configurer une probe liveness pour Kubernetes.
Copiez et collez la configuration YAML suivante dans un fichier nommé deployment.yaml. Remplacez les commentaires # {ENDPOINT_URI} et # {API_KEY} par vos propres valeurs. Remplacez le commentaire # {AZURE_STORAGE_CONNECTION_STRING} par votre chaîne de connexion Stockage Azure. Configurez replicas sur le nombre de votre choix, qui est défini sur 3 dans l’exemple suivant.
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
replicas: # {NUMBER_OF_READ_CONTAINERS}
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: cognitive-services-read
image: mcr.microsoft.com/azure-cognitive-services/vision/read
ports:
- containerPort: 5000
env:
- name: EULA
value: accept
- name: billing
value: # {ENDPOINT_URI}
- name: apikey
value: # {API_KEY}
- name: Storage__ObjectStore__AzureBlob__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
- name: Queue__Azure__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
livenessProbe:
httpGet:
path: /ContainerLiveness
port: 5000
initialDelaySeconds: 60
periodSeconds: 60
timeoutSeconds: 20
---
apiVersion: v1
kind: Service
metadata:
name: azure-cognitive-service-read
spec:
type: LoadBalancer
ports:
- port: 5000
targetPort: 5000
selector:
app: read-app
Exécutez la commande suivante.
kubectl apply -f deployment.yaml
Voici un exemple de sortie que vous pourriez voir suite à l’exécution d’un déploiement réussi :
deployment.apps/read created
service/azure-cognitive-service-read created
Le déploiement de Kubernetes peut prendre plusieurs minutes. Pour vérifier que tant les pods que les services sont correctement déployés et disponibles, exécutez la commande suivante :
kubectl get all
Vous devriez voir une sortie de console similaire à celle-ci :
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-6cbbb6678-58s9t 1/1 Running 0 3s
pod/read-6cbbb6678-kz7v4 1/1 Running 0 3s
pod/read-6cbbb6678-s2pct 1/1 Running 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/azure-cognitive-service-read LoadBalancer 10.0.134.0 <none> 5000:30846/TCP 17h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 78d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 3/3 3 3 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-6cbbb6678 3 3 3 3s
Valider l’exécution d’un conteneur
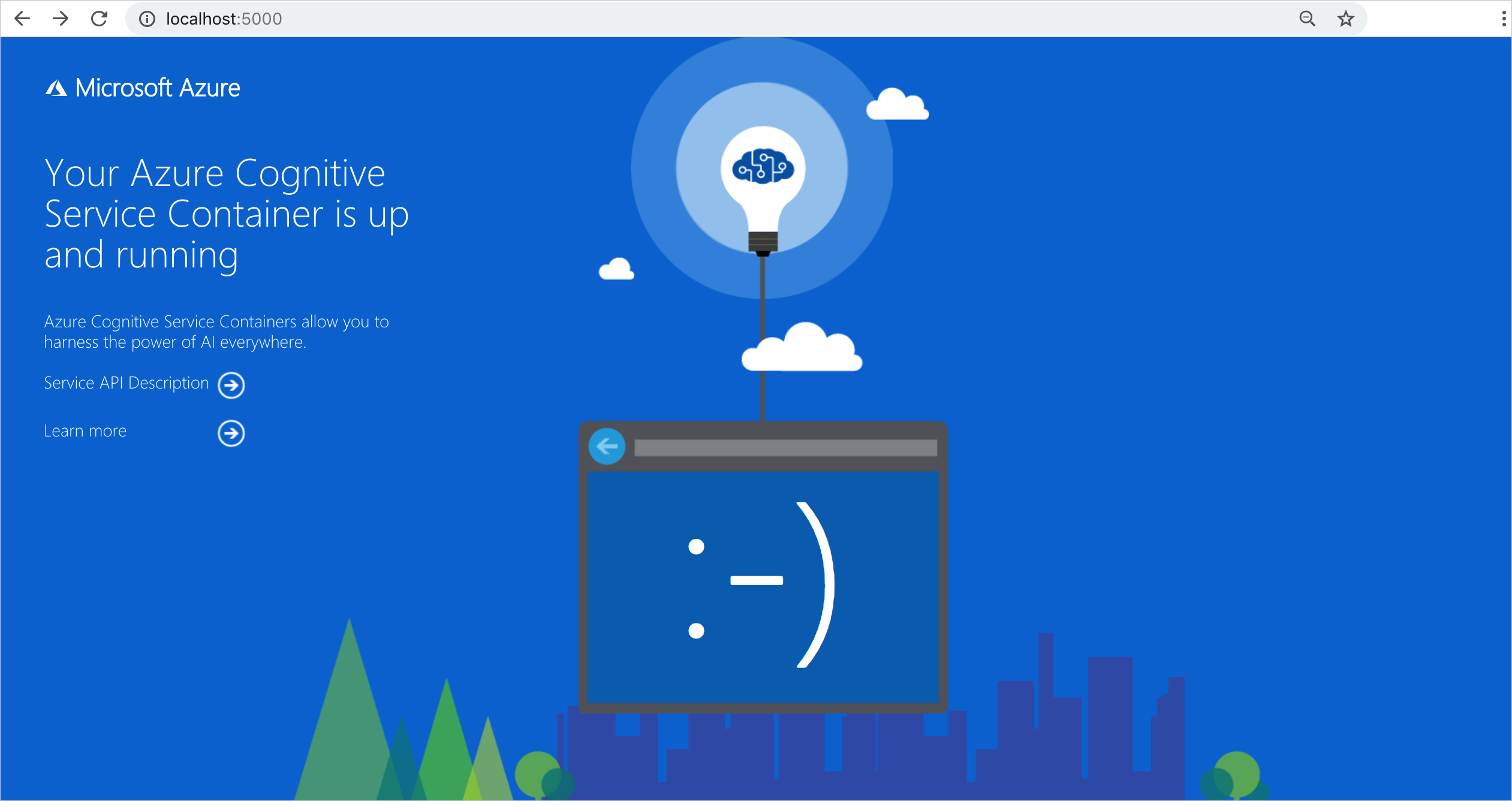
Il existe plusieurs façons de confirmer que le conteneur s’exécute. Recherchez l’adresse IP externe et le port exposé du conteneur en question, puis ouvrez le navigateur web de votre choix. Utilisez les différentes URL de requête suivantes pour vérifier que le conteneur est en cours d’exécution. Les exemples d’URL de requête listés ici sont http://localhost:5000, mais votre conteneur spécifique peut varier. Veillez à vous fier à l’adresse IP externe de votre conteneur et au port exposé.
| URL de la demande | Objectif |
|---|---|
http://localhost:5000/ |
Le conteneur fournit une page d’accueil. |
http://localhost:5000/ready |
Demandée avec la fonction d’extraction, cette URL permet de vérifier que le conteneur est prêt à accepter une requête sur le modèle. Cette requête peut être utilisée pour les probes liveness et readiness de Kubernetes. |
http://localhost:5000/status |
Également demandée avec la fonction d’extraction, cette URL permet de vérifier si la clé API servant à démarrer le conteneur est valide sans provoquer de requête de point de terminaison. Cette requête peut être utilisée pour les probes liveness et readiness de Kubernetes. |
http://localhost:5000/swagger |
Le conteneur fournit un ensemble complet de documentation pour les points de terminaison et une fonctionnalité Essayer. Avec cette fonctionnalité, vous pouvez entrer vos paramètres dans un formulaire HTML basé sur le web, et constituer la requête sans avoir à écrire du code. Une fois la requête retournée, un exemple de commande CURL est fourni pour illustrer les en-têtes HTTP, et le format du corps qui est nécessaire. |
Étapes suivantes
Pour plus d’informations sur l’installation d’applications avec Helm dans Azure Kubernetes Service (AKS), consultez ceci.