Démarrage rapide : reconnaître les intentions avec la compréhension du langage courant
Documentation de référencePackage (NuGet)Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser les services Speech et de langage pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le service Speech pour reconnaître la parole et un modèle de Compréhension du langage courant (CLU) pour identifier les intentions.
Important
La compréhension du langage courant (CLU) est disponible pour C# et C++ avec le kit de développement logiciel (SDK) Speech version 1.25 ou ultérieure.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure.
- Obtenez la clé et le point de terminaison de la ressource Language. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés. Si vous souhaitez en savoir plus sur les ressources Azure AI services, veuillez consulter la rubrique Obtenir les clés de votre ressource.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés. Pour plus d’informations sur les ressources Azure AI services, consultez Obtenir les clés de votre ressource.
Configurer l’environnement
Le kit de développement logiciel (SDK) Speech est disponible en tant que package NuGet et implémente .NET Standard 2.0. Ce guide vous invite à installer le SDK Speech plus tard. Consultez d’abord le guide d’installation du SDK pour connaître les éventuelles autres exigences.
Définir des variables d’environnement
Cet exemple nécessite des variables d’environnement nommées LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY et SPEECH_REGION.
Votre application doit être authentifiée pour accéder aux ressources Azure AI services. Pour la production, utilisez une méthode de stockage et d’accès sécurisée pour vos informations d’identification. Par exemple, après avoir obtenu une clé pour votre ressource Speech, écrivez-la dans une nouvelle variable d’environnement sur l’ordinateur local qui exécute l’application.
Conseil
N’incluez pas la clé directement dans votre code et ne la publiez jamais publiquement. Pour découvrir d’autres options d’authentification telles qu’Azure Key Vault, veuillez consulter l’article sur la sécurité d’Azure AI services.
Pour définir les variables d’environnement, ouvrez une fenêtre de console et suivez les instructions relatives à votre système d’exploitation et à votre environnement de développement.
- Pour définir la variable d’environnement
LANGUAGE_KEY, remplacezyour-language-keypar l’une des clés de votre ressource. - Pour définir la variable d’environnement
LANGUAGE_ENDPOINT, remplacezyour-language-endpointpar l’une des régions de votre ressource. - Pour définir la variable d’environnement
SPEECH_KEY, remplacezyour-speech-keypar l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacezyour-speech-regionpar l’une des régions de votre ressource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Notes
Si vous avez uniquement besoin d’accéder à la variable d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d’environnement, vous devrez peut-être redémarrer tous les programmes en cours d’exécution qui devront la lire, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Créer un projet de compréhension du langage courant
Une fois que vous avez créé une ressource Language, créez un projet de compréhension du langage courant dans Language Studio. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Accédez à Language Studio et connectez-vous avec votre compte Azure.
Créer un projet de compréhension du langage courant
Pour ce guide de démarrage rapide, vous pouvez télécharger cet exemple de projet de domotique et l’importer. Ce projet peut prédire les commandes prévues à partir de l’entrée utilisateur, comme allumer et éteindre les lumières.
Sous Comprendre les questions et le langage courant, dans Language Studio, sélectionnez Compréhension du langage courant.
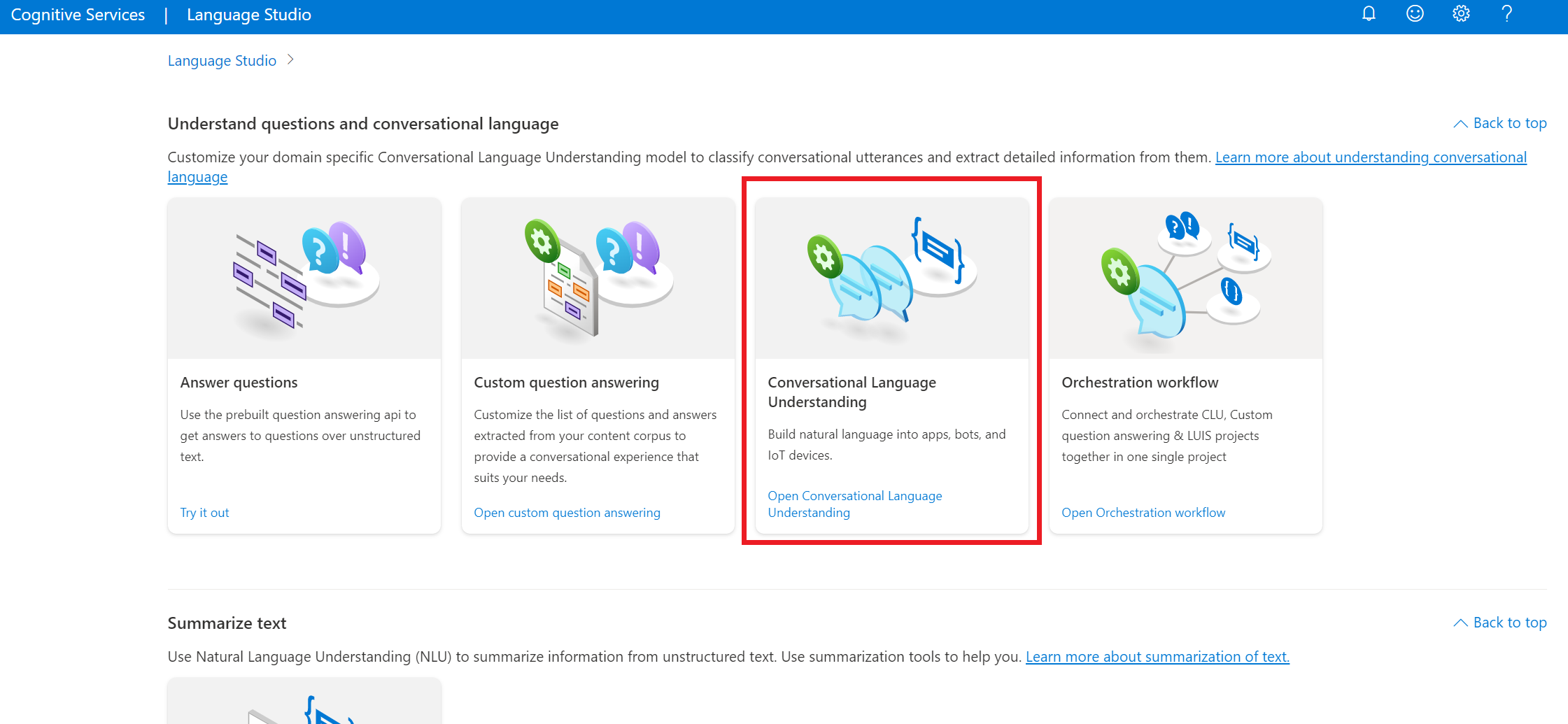
Cela vous amène à la page Projets de compréhension du langage courant. En regard du bouton Création d’un projet, sélectionnez Importer.
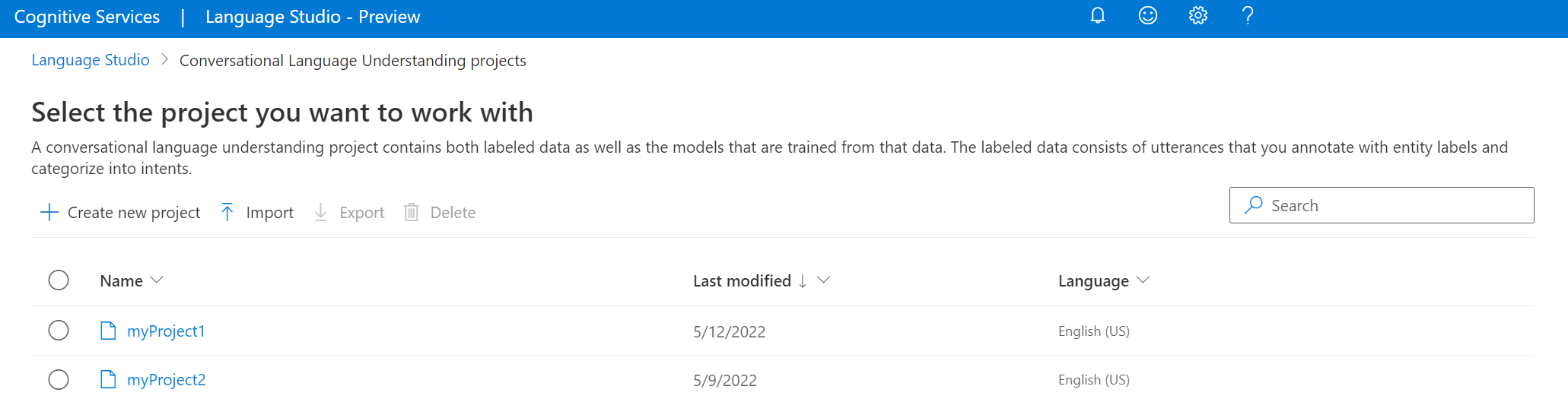
Dans la fenêtre qui s’affiche, chargez le fichier JSON que vous souhaitez importer. Assurez-vous que votre fichier suit le format JSON pris en charge.


Une fois le chargement terminé, vous accédez à la page Définition du schéma. Pour ce guide de démarrage rapide, le schéma est déjà généré et les énoncés sont déjà étiquetés avec des intentions et des entités.
Entraîner votre modèle
En règle générale, après avoir créé un projet, vous devez générer un schéma et étiqueter des énoncés. Pour ce guide de démarrage rapide, nous avons déjà importé un projet prêt avec un schéma généré et des énoncés étiquetés.
Pour entraîner un modèle, vous devez démarrer un travail d’entraînement. La sortie d’un travail d’entraînement réussi est votre modèle formé.
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Effectuer l’apprentissage du modèle.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Entraîner un nouveau modèle, puis entrez le nom d’un nouveau modèle dans la zone de texte. Sinon, pour remplacer un modèle existant par un modèle entraîné sur les nouvelles données, sélectionnez Remplacer un modèle existant, puis sélectionnez un modèle existant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.
Sélectionnez le mode d’entraînement. Vous pouvez choisir l’Entraînement standard pour un entraînement plus rapide, mais il n’est disponible que pour l’anglais. Vous pouvez aussi opter pour l’Entraînement avancé, qui est pris en charge pour d’autres langues et les projets multilingues, mais les temps d’entraînement sont plus longs. Apprenez-en davantage sur les modes d’apprentissage.
Sélectionnez une méthode de fractionnement des données. Vous pouvez choisir l’option Fractionnement automatique du jeu de test à partir des données d’entraînement. Dans ce cas, le système fractionne vos énoncés en jeux d’apprentissage et de test, selon les pourcentages spécifiés. Vous pouvez aussi Utiliser un fractionnement manuel des données d’entraînement et de test. Cette option est activée uniquement si vous avez ajouté des énoncés à votre jeu de test pendant l’étiquetage de vos énoncés.
Sélectionner le bouton Train (Entraîner).
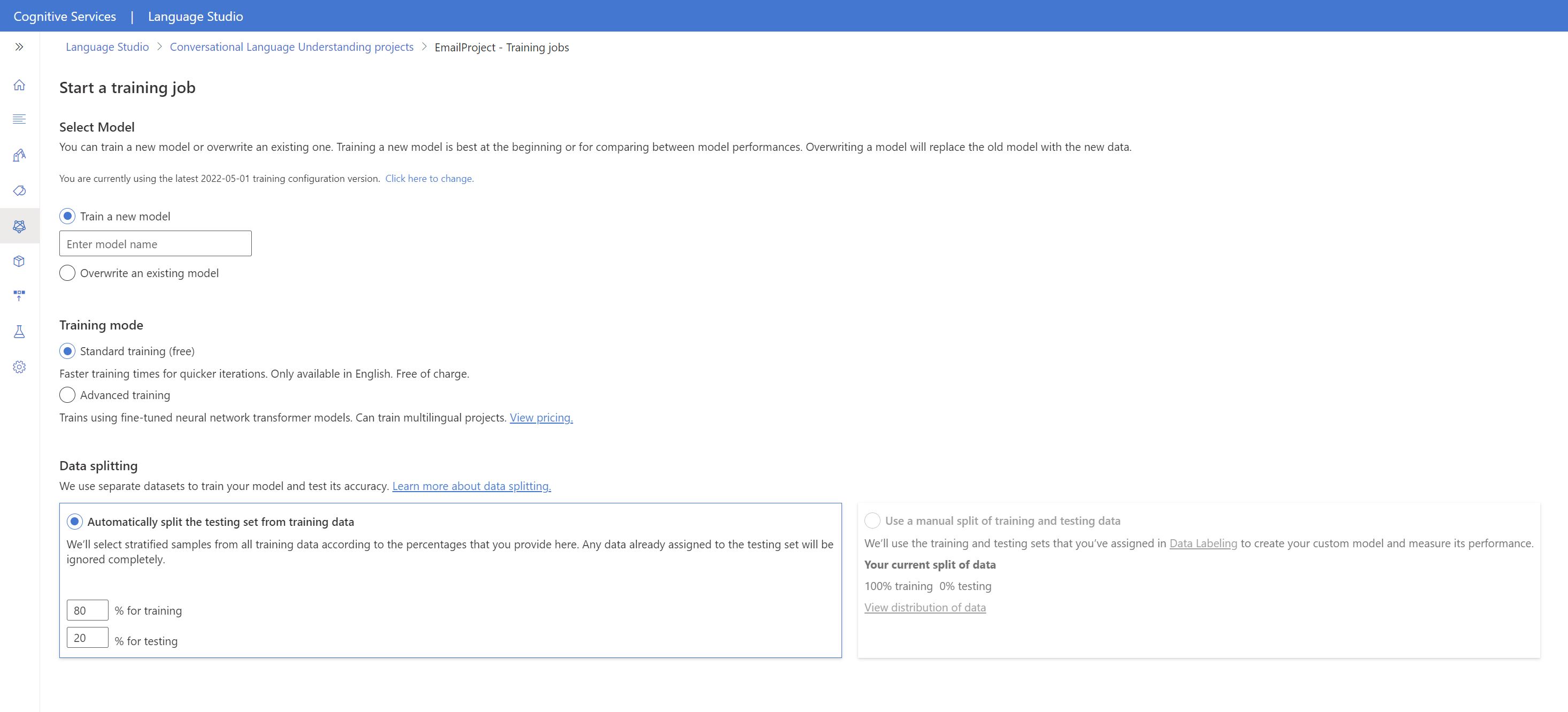
Sélectionnez l’ID du travail d’entraînement dans la liste. Un volet latéral s’affichera, dans lequel vous pourrez consulter la progression de l’entraînement, l’état du travail et d’autres détails concernant ce travail.
Notes
- Seuls les emplois de formation achevés avec succès génèrent des modèles.
- L’entraînement peut prendre entre quelques minutes et quelques heures, selon le nombre d’énoncés.
- Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas lancer d’autres travaux d’entraînement dans le même projet tant que le travail en cours d’exécution n’est pas terminé.
- Le machine learning utilisé pour entraîner les modèles est régulièrement mis à jour. Pour effectuer l’apprentissage sur une version de configuration précédente, sélectionnez Cliquez ici pour modifier à partir de la page Démarrer un travail d’apprentissage, puis choisissez une version précédente.

Déployer votre modèle
En général, après avoir formé un modèle, vous examinez les détails de son évaluation. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et le rendre disponible pour pouvoir l’essayer dans Language Studio. Vous pouvez également appeler l’API de prévision.
Pour déployer votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Déploiement d’un modèle.
Sélectionnez Ajouter un déploiement pour démarrer l’Assistant Ajouter un déploiement.
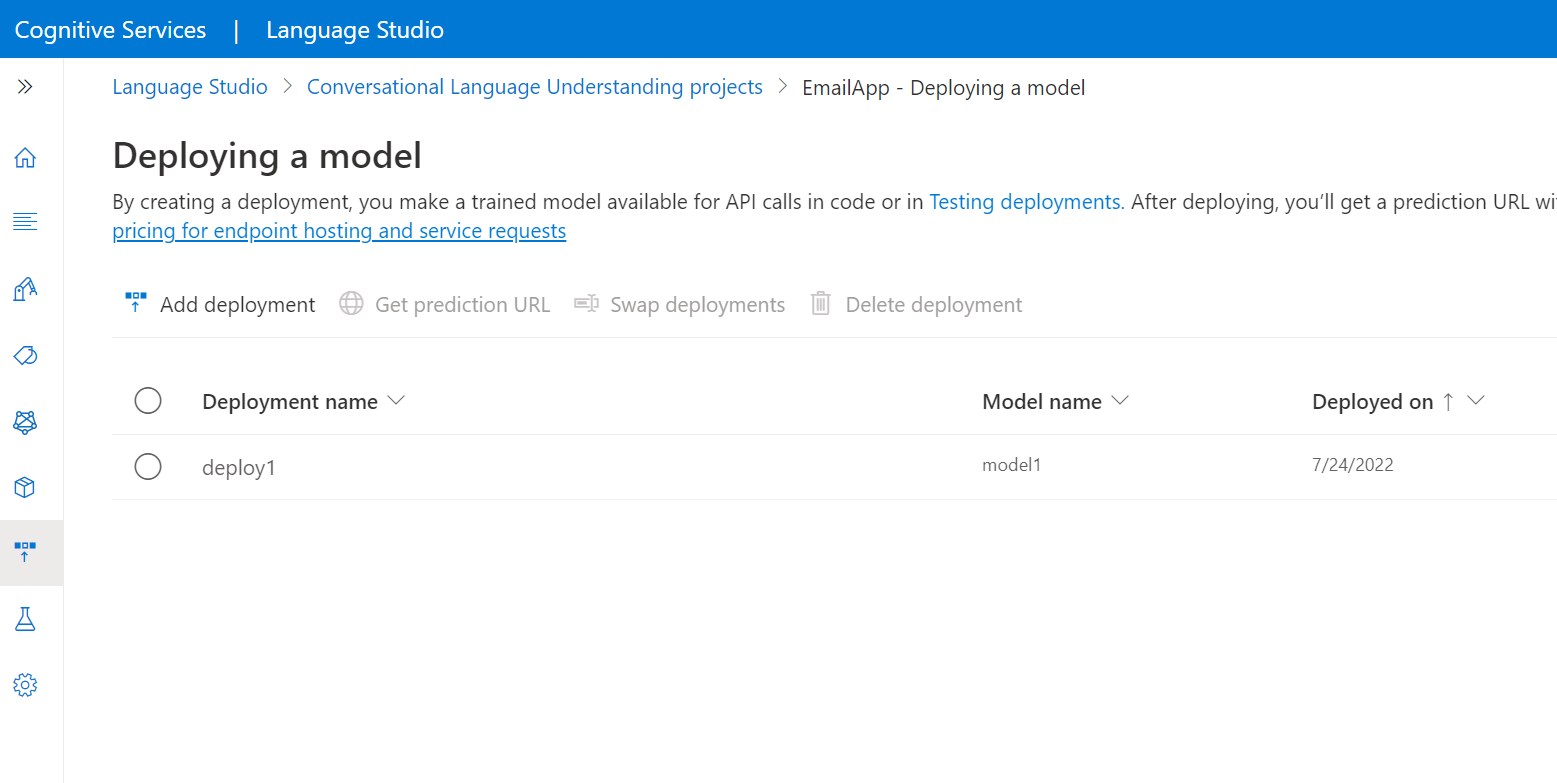
Sélectionnez Créer un nom de déploiement pour créer un nouveau déploiement et attribuer un modèle entraîné dans la liste déroulante ci-dessous. Sinon, vous pouvez sélectionner Remplacer un nom de déploiement existant pour remplacer efficacement le modèle utilisé par un déploiement existant.
Notes
Le remplacement d’un déploiement existant ne nécessite pas de modifier votre appel de l’API de prédiction. Toutefois, les résultats obtenus sont basés sur le modèle qui vient d’être attribué.

Sélectionnez un modèle entraîné dans la liste déroulante Modèle.
Sélectionnez Déployer pour démarrer le travail de déploiement.
Une fois le déploiement réussi, une date d’expiration s’affiche à côté de celui-ci. L’expiration du déploiement est le moment où votre modèle déployé n’est pas disponible pour la prédiction, ce qui se produit généralement douze mois après l’expiration d’une configuration d’entraînement.


Vous allez utiliser le nom du projet et le nom du déploiement dans la section suivante.
Reconnaître les intentions à partir d’un microphone
Procédez comme suit pour créer une nouvelle application console et installer le kit de développement logiciel (SDK) Speech.
Ouvrez une invite de commandes à l’emplacement où vous souhaitez placer le nouveau projet, puis créez une application console avec l’interface de ligne de commande .NET. Le fichier
Program.csdoit être créé dans le répertoire du projet.dotnet new consoleInstallez le kit de développement logiciel (SDK) Speech dans votre nouveau projet avec l’interface CLI .NET.
dotnet add package Microsoft.CognitiveServices.SpeechRemplacez le contenu de
Program.cspar le code suivant.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Dans
Program.cs, définissez les variablescluProjectNameetcluDeploymentNamesur les noms de votre projet et de votre déploiement. Pour plus d’informations sur la création d’un projet de compréhension du langage courant (CLU) et son déploiement, consultez Créer un projet de compréhension du langage courant.Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple,es-ESpour l’espagnol (Espagne). La langue par défaut esten-USsi vous ne spécifiez pas de langue. Pour plus d’informations sur l’identification de l’une des langues qui peuvent être parlées, consultez Identification de la langue.
Exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone :
dotnet run
Important
Vérifiez que vous avez défini les variables d’environnement LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY et SPEECH_REGION comme décrit ci-dessus. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.
Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites devrait être généré sous forme de texte :
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Notes
La prise en charge de la réponse JSON pour CLU via la propriété LanguageUnderstandingServiceResponse_JsonResult a été ajoutée dans le SDK Speech version 1.26.
Les intentions sont retournées dans l’ordre de probabilité de la plus probable à la moins probable. Voici une version mise en forme de la sortie JSON où topIntent est HomeAutomation.TurnOn avec un score de confiance de 0,97712576 (97,71 %). La deuxième intention la plus probable peut être HomeAutomation.TurnOff avec un score de confiance de 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Remarques
Maintenant que vous avez terminé le guide de démarrage rapide, voici quelques considérations supplémentaires :
- Cet exemple utilise l’opération
RecognizeOnceAsyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale. - Pour reconnaître la parole à partir d’un fichier audio, utilisez
FromWavFileInputau lieu deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer les ressources Language et Speech que vous avez créées.
Documentation de référencePackage (NuGet)Exemples supplémentaires sur GitHub
Dans ce guide de démarrage rapide, vous allez utiliser les services Speech et de langage pour reconnaître des intentions dans des données audio capturées à partir d’un microphone. Plus précisément, vous allez utiliser le service Speech pour reconnaître la parole et un modèle de Compréhension du langage courant (CLU) pour identifier les intentions.
Important
La compréhension du langage courant (CLU) est disponible pour C# et C++ avec le kit de développement logiciel (SDK) Speech version 1.25 ou ultérieure.
Prérequis
- Abonnement Azure - En créer un gratuitement
- Créez une ressource de langue dans le portail Azure.
- Obtenez la clé et le point de terminaison de la ressource Language. Une fois votre ressource de langue déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés. Si vous souhaitez en savoir plus sur les ressources Azure AI services, veuillez consulter la rubrique Obtenir les clés de votre ressource.
- Créer une ressource Speech dans le portail Azure.
- Obtenez la clé de ressource et la région Speech. Une fois votre ressource vocale déployée, sélectionnez Accéder à la ressource pour afficher et gérer les clés. Pour plus d’informations sur les ressources Azure AI services, consultez Obtenir les clés de votre ressource.
Configurer l’environnement
Le kit de développement logiciel (SDK) Speech est disponible en tant que package NuGet et implémente .NET Standard 2.0. Ce guide vous invite à installer le SDK Speech plus tard. Consultez d’abord le guide d’installation du SDK pour connaître les éventuelles autres exigences.
Définir des variables d’environnement
Cet exemple nécessite des variables d’environnement nommées LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY et SPEECH_REGION.
Votre application doit être authentifiée pour accéder aux ressources Azure AI services. Pour la production, utilisez une méthode de stockage et d’accès sécurisée pour vos informations d’identification. Par exemple, après avoir obtenu une clé pour votre ressource Speech, écrivez-la dans une nouvelle variable d’environnement sur l’ordinateur local qui exécute l’application.
Conseil
N’incluez pas la clé directement dans votre code et ne la publiez jamais publiquement. Pour découvrir d’autres options d’authentification telles qu’Azure Key Vault, veuillez consulter l’article sur la sécurité d’Azure AI services.
Pour définir les variables d’environnement, ouvrez une fenêtre de console et suivez les instructions relatives à votre système d’exploitation et à votre environnement de développement.
- Pour définir la variable d’environnement
LANGUAGE_KEY, remplacezyour-language-keypar l’une des clés de votre ressource. - Pour définir la variable d’environnement
LANGUAGE_ENDPOINT, remplacezyour-language-endpointpar l’une des régions de votre ressource. - Pour définir la variable d’environnement
SPEECH_KEY, remplacezyour-speech-keypar l’une des clés de votre ressource. - Pour définir la variable d’environnement
SPEECH_REGION, remplacezyour-speech-regionpar l’une des régions de votre ressource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Notes
Si vous avez uniquement besoin d’accéder à la variable d’environnement dans la console en cours d’exécution, vous pouvez la définir avec set au lieu de setx.
Après avoir ajouté les variables d’environnement, vous devrez peut-être redémarrer tous les programmes en cours d’exécution qui devront la lire, y compris la fenêtre de console. Par exemple, si vous utilisez Visual Studio comme éditeur, redémarrez Visual Studio avant d’exécuter l’exemple.
Créer un projet de compréhension du langage courant
Une fois que vous avez créé une ressource Language, créez un projet de compréhension du langage courant dans Language Studio. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Accédez à Language Studio et connectez-vous avec votre compte Azure.
Créer un projet de compréhension du langage courant
Pour ce guide de démarrage rapide, vous pouvez télécharger cet exemple de projet de domotique et l’importer. Ce projet peut prédire les commandes prévues à partir de l’entrée utilisateur, comme allumer et éteindre les lumières.
Sous Comprendre les questions et le langage courant, dans Language Studio, sélectionnez Compréhension du langage courant.
Cela vous amène à la page Projets de compréhension du langage courant. En regard du bouton Création d’un projet, sélectionnez Importer.
Dans la fenêtre qui s’affiche, chargez le fichier JSON que vous souhaitez importer. Assurez-vous que votre fichier suit le format JSON pris en charge.
Une fois le chargement terminé, vous accédez à la page Définition du schéma. Pour ce guide de démarrage rapide, le schéma est déjà généré et les énoncés sont déjà étiquetés avec des intentions et des entités.
Entraîner votre modèle
En règle générale, après avoir créé un projet, vous devez générer un schéma et étiqueter des énoncés. Pour ce guide de démarrage rapide, nous avons déjà importé un projet prêt avec un schéma généré et des énoncés étiquetés.
Pour entraîner un modèle, vous devez démarrer un travail d’entraînement. La sortie d’un travail d’entraînement réussi est votre modèle formé.
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Effectuer l’apprentissage du modèle.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Entraîner un nouveau modèle, puis entrez le nom d’un nouveau modèle dans la zone de texte. Sinon, pour remplacer un modèle existant par un modèle entraîné sur les nouvelles données, sélectionnez Remplacer un modèle existant, puis sélectionnez un modèle existant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.
Sélectionnez le mode d’entraînement. Vous pouvez choisir l’Entraînement standard pour un entraînement plus rapide, mais il n’est disponible que pour l’anglais. Vous pouvez aussi opter pour l’Entraînement avancé, qui est pris en charge pour d’autres langues et les projets multilingues, mais les temps d’entraînement sont plus longs. Apprenez-en davantage sur les modes d’apprentissage.
Sélectionnez une méthode de fractionnement des données. Vous pouvez choisir l’option Fractionnement automatique du jeu de test à partir des données d’entraînement. Dans ce cas, le système fractionne vos énoncés en jeux d’apprentissage et de test, selon les pourcentages spécifiés. Vous pouvez aussi Utiliser un fractionnement manuel des données d’entraînement et de test. Cette option est activée uniquement si vous avez ajouté des énoncés à votre jeu de test pendant l’étiquetage de vos énoncés.
Sélectionner le bouton Train (Entraîner).
Sélectionnez l’ID du travail d’entraînement dans la liste. Un volet latéral s’affichera, dans lequel vous pourrez consulter la progression de l’entraînement, l’état du travail et d’autres détails concernant ce travail.
Notes
- Seuls les emplois de formation achevés avec succès génèrent des modèles.
- L’entraînement peut prendre entre quelques minutes et quelques heures, selon le nombre d’énoncés.
- Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas lancer d’autres travaux d’entraînement dans le même projet tant que le travail en cours d’exécution n’est pas terminé.
- Le machine learning utilisé pour entraîner les modèles est régulièrement mis à jour. Pour effectuer l’apprentissage sur une version de configuration précédente, sélectionnez Cliquez ici pour modifier à partir de la page Démarrer un travail d’apprentissage, puis choisissez une version précédente.
Déployer votre modèle
En général, après avoir formé un modèle, vous examinez les détails de son évaluation. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et le rendre disponible pour pouvoir l’essayer dans Language Studio. Vous pouvez également appeler l’API de prévision.
Pour déployer votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Déploiement d’un modèle.
Sélectionnez Ajouter un déploiement pour démarrer l’Assistant Ajouter un déploiement.
Sélectionnez Créer un nom de déploiement pour créer un nouveau déploiement et attribuer un modèle entraîné dans la liste déroulante ci-dessous. Sinon, vous pouvez sélectionner Remplacer un nom de déploiement existant pour remplacer efficacement le modèle utilisé par un déploiement existant.
Notes
Le remplacement d’un déploiement existant ne nécessite pas de modifier votre appel de l’API de prédiction. Toutefois, les résultats obtenus sont basés sur le modèle qui vient d’être attribué.
Sélectionnez un modèle entraîné dans la liste déroulante Modèle.
Sélectionnez Déployer pour démarrer le travail de déploiement.
Une fois le déploiement réussi, une date d’expiration s’affiche à côté de celui-ci. L’expiration du déploiement est le moment où votre modèle déployé n’est pas disponible pour la prédiction, ce qui se produit généralement douze mois après l’expiration d’une configuration d’entraînement.
Vous allez utiliser le nom du projet et le nom du déploiement dans la section suivante.
Reconnaître les intentions à partir d’un microphone
Procédez comme suit pour créer une nouvelle application console et installer le kit de développement logiciel (SDK) Speech.
Créez un projet console en C++ dans Visual Studio Community 2022, nommé
SpeechRecognition.Installez le kit de développement logiciel (SDK) Speech dans votre nouveau projet avec le gestionnaire de package NuGet.
Install-Package Microsoft.CognitiveServices.SpeechRemplacez le contenu de
SpeechRecognition.cpppar le code suivant :#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Dans
SpeechRecognition.cpp, définissez les variablescluProjectNameetcluDeploymentNamesur les noms de votre projet et de votre déploiement. Pour plus d’informations sur la création d’un projet de compréhension du langage courant (CLU) et son déploiement, consultez Créer un projet de compréhension du langage courant.Pour modifier la langue de la reconnaissance vocale, remplacez
en-USpar une autre langue prise en charge. Par exemple,es-ESpour l’espagnol (Espagne). La langue par défaut esten-USsi vous ne spécifiez pas de langue. Pour plus d’informations sur l’identification de l’une des langues qui peuvent être parlées, consultez Identification de la langue.
Générez et exécutez votre nouvelle application console pour démarrer la reconnaissance vocale à partir d’un microphone.
Important
Vérifiez que vous avez défini les variables d’environnement LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY et SPEECH_REGION comme décrit ci-dessus. Si vous ne définissez pas ces variables, l’exemple échoue avec un message d’erreur.
Parlez dans votre microphone lorsque vous y êtes invité. Ce que vous dites devrait être généré sous forme de texte :
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Notes
La prise en charge de la réponse JSON pour CLU via la propriété LanguageUnderstandingServiceResponse_JsonResult a été ajoutée dans le SDK Speech version 1.26.
Les intentions sont retournées dans l’ordre de probabilité de la plus probable à la moins probable. Voici une version mise en forme de la sortie JSON où topIntent est HomeAutomation.TurnOn avec un score de confiance de 0,97712576 (97,71 %). La deuxième intention la plus probable peut être HomeAutomation.TurnOff avec un score de confiance de 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Remarques
Maintenant que vous avez terminé le guide de démarrage rapide, voici quelques considérations supplémentaires :
- Cet exemple utilise l’opération
RecognizeOnceAsyncpour transcrire les énoncés de jusqu’à 30 secondes ou jusqu’à ce que le silence soit détecté. Pour plus d’informations sur la reconnaissance continue des données audio plus longues, y compris les conversations multilingues, consultez Comment effectuer la reconnaissance vocale. - Pour reconnaître la parole à partir d’un fichier audio, utilisez
FromWavFileInputau lieu deFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Pour les fichiers audio compressés tels que les fichiers MP4, installez GStreamer et utilisez
PullAudioInputStreamouPushAudioInputStream. Pour plus d’informations, consultez Utilisation de l’audio d’entrée compressée.
Nettoyer les ressources
Vous pouvez utiliser le portail Azure ou l’interface de ligne de commande (CLI) Azure pour supprimer les ressources Language et Speech que vous avez créées.
Documentation de référence | Exemples supplémentaires sur GitHub
Le Kit de développement logiciel (SDK) Speech pour Java ne prend pas en charge la reconnaissance des intentions avec la compréhension du langage courant (CLU). Veuillez sélectionner un autre langage de programmation, ou la référence Java et des exemples liés au début de cet article.