Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Il existe plus de choix que jamais sur le type de base de données à utiliser avec votre charge de travail de données. L’un des principaux facteurs de sélection d’une base de données est les performances de la base de données ou du service, mais les performances d’évaluation peuvent être fastidieuses et sujettes aux erreurs. Le framework d’analyse de référence pour Les bases de données Azure simplifie le processus de mesure des performances avec des outils d’évaluation open source populaires avec des recettes à faible friction qui implémentent les meilleures pratiques courantes. Dans Azure Cosmos DB pour NoSQL, l’infrastructure implémente les meilleures pratiques pour le Kit de développement logiciel (SDK) Java et utilise l’outil YCSB open source. Dans ce guide, vous utilisez cette infrastructure d’évaluation pour implémenter une charge de travail de lecture pour vous familiariser avec l’infrastructure.
Prerequisites
- Un compte Azure avec un abonnement actif. Créez un compte gratuitement.
- Compte Azure Cosmos DB for NoSQL.
Créez une API pour un compte NoSQL.
- Veillez à noter l’URI de point de terminaison et la clé primaire du compte.
- Compte Stockage Azure.
Créer un compte de stockage Azure
- Veillez à noter la chaîne de connexion du compte de stockage. Vies Chaîne de connexion Stockage Azure.
- Deuxième groupe de ressources vide. Créez un groupe de ressources.
- Interface en ligne de commande Azure (CLI).
Créer des ressources de compte Azure Cosmos DB
Tout d’abord, vous créez une base de données et un conteneur dans l’API existante pour le compte NoSQL.
Accédez à votre compte API existante pour NoSQL dans le portail Azure.
Dans le menu de la ressource, sélectionnez Explorateur de données.
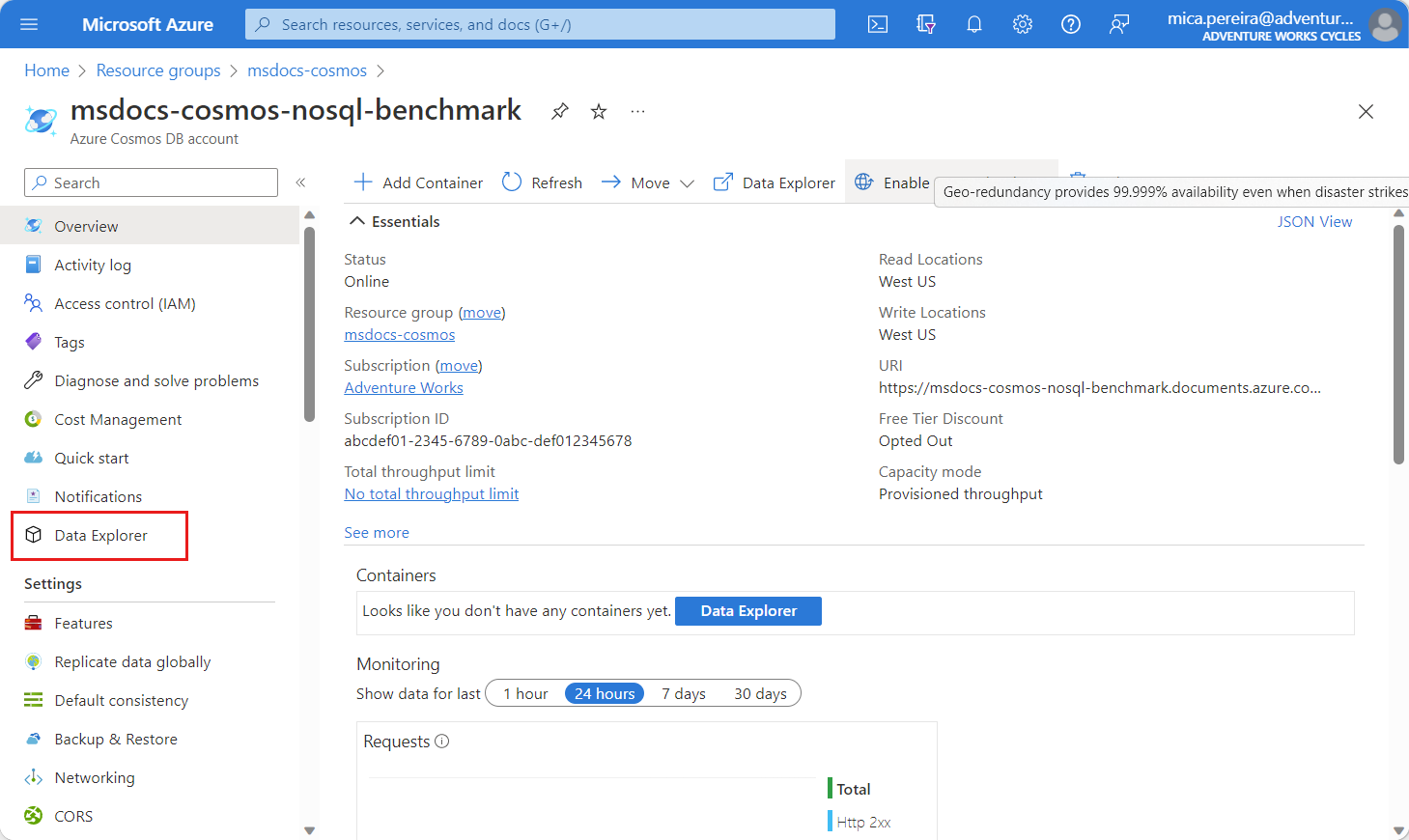
Dans la page Explorateur de données , sélectionnez l’option Nouveau conteneur dans la barre de commandes.
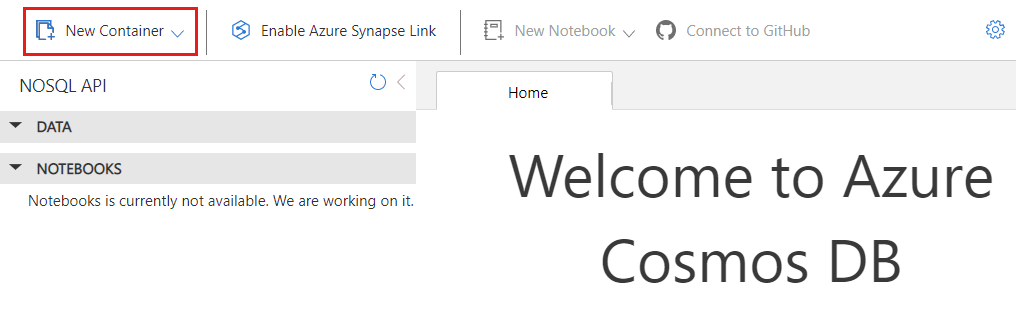
Dans la boîte de dialogue Nouveau conteneur , créez un conteneur avec les paramètres suivants :
Réglage Valeur ID de base de données ycsbType de débit de base de données Manuel Quantité de débit de base de données 400ID de conteneur usertableClé de partition /id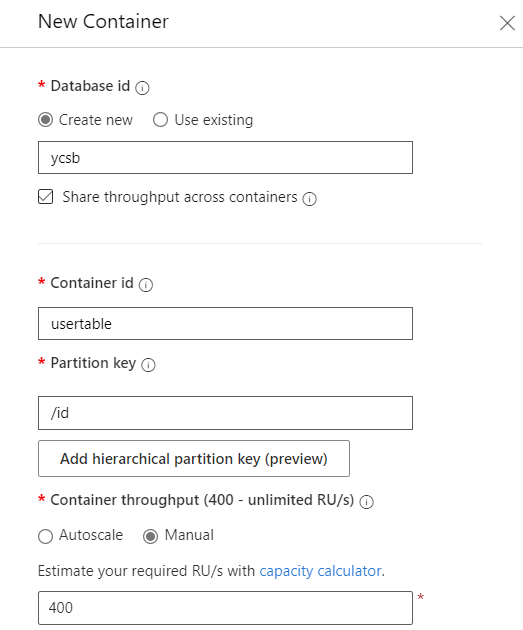

Déployer une infrastructure de référence sur Azure
À présent, vous utilisez un modèle Azure Resource Manager pour déployer l’infrastructure de référence sur Azure avec la recette de lecture par défaut.
Déployez l’infrastructure de référence à l’aide d’un modèle Azure Resource Manager disponible dans ce lien.
Dans la page Déploiement personnalisé, les paramètres suivants
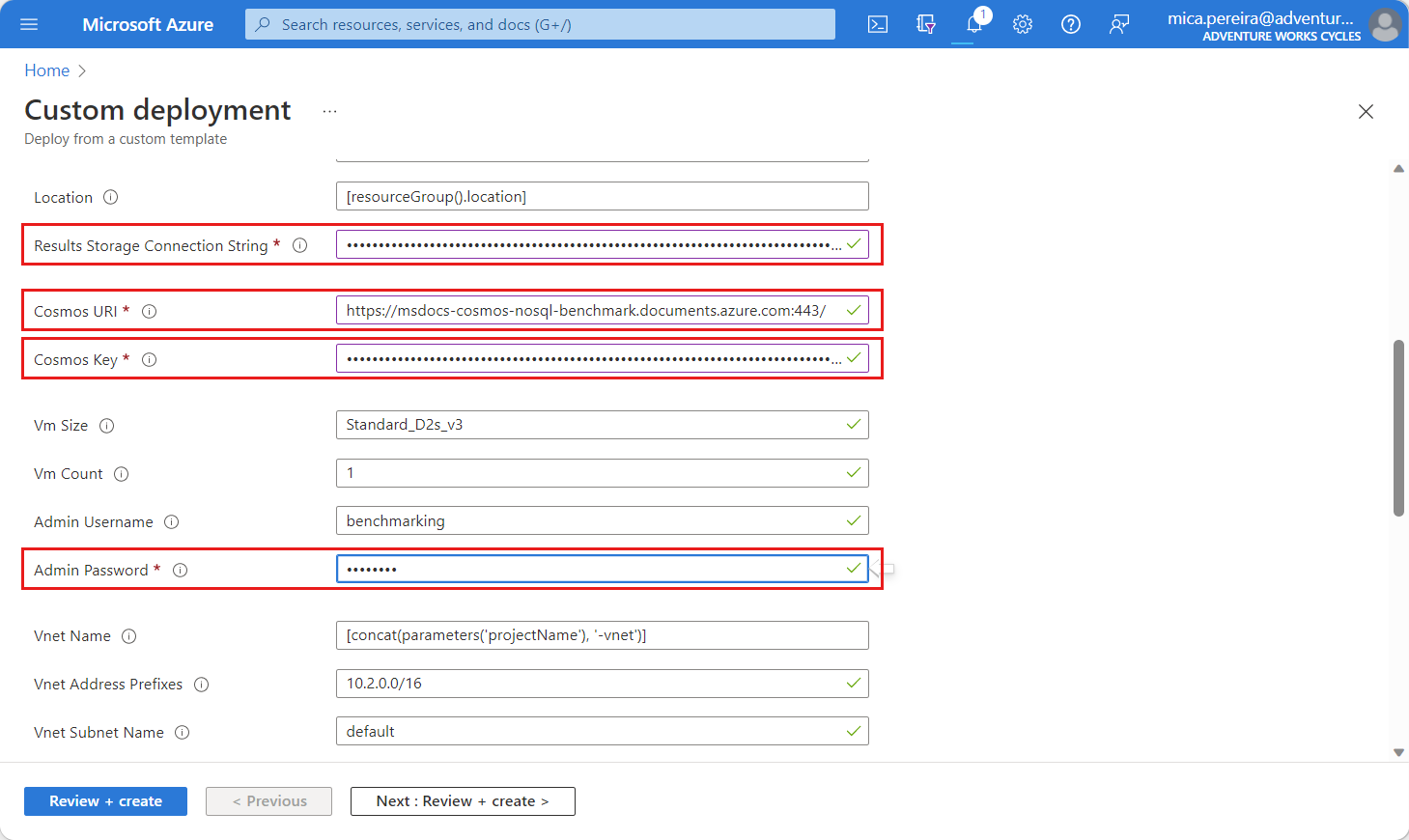
Sélectionnez Vérifier + créer , puis Créer pour déployer le modèle.
Attendez que le déploiement se termine.
Conseil / Astuce
Le déploiement peut prendre 5 à 10 minutes.

Afficher les résultats du benchmark
À présent, vous pouvez utiliser le compte de stockage Azure existant pour vérifier l’état du travail de test et afficher les résultats agrégés. L’état est stocké à l’aide d’une table de stockage et les résultats sont agrégés dans un objet blob de stockage au format CSV.
Accédez à votre compte de stockage Azure existant dans le portail Azure.
Accédez à une table de stockage nommée ycsbbenchmarkingmetadata et recherchez l’entité avec une clé de partition de
ycsb_sql.
Observez le
JobStatuschamp de l’entité de table. Initialement, l’état de la tâche estStartedet inclut un horodatage dans la propriétéJobStartTime, mais pas dans la propriétéJobFinishTime.Attendez que le travail soit en l’état
Finishedet qu’il inclut un horodatage dans la propriétéJobFinishTime.Conseil / Astuce
La fin du travail peut prendre environ 20 à 30 minutes.
Accédez au conteneur de stockage dans le même compte avec le préfixe ycsbbenchmarking-*. Observez les blobs de sortie et de diagnostic de l'outil.

Ouvrez l’objet blob aggregation.csv et observez le contenu. Vous devez maintenant disposer d’un jeu de données CSV avec des résultats agrégés de tous les clients de référence.

Operation,Count,Throughput,Min(microsecond),Max(microsecond),Avg(microsecond),P9S(microsecond),P99(microsecond) READ,180000,299,706,448255,1079,1159,2867
Recettes
L’infrastructure de référence pour Les bases de données Azure inclut des recettes permettant d’encapsuler les définitions de charge de travail passées à l’outil de référence sous-jacent pour une expérience « 1 clic ». Les définitions de charge de travail ont été conçues en fonction des meilleures pratiques publiées par l’équipe Azure Cosmos DB et de l’équipe de l’outil d’évaluation. Les recettes ont été testées et validées pour obtenir des résultats cohérents.
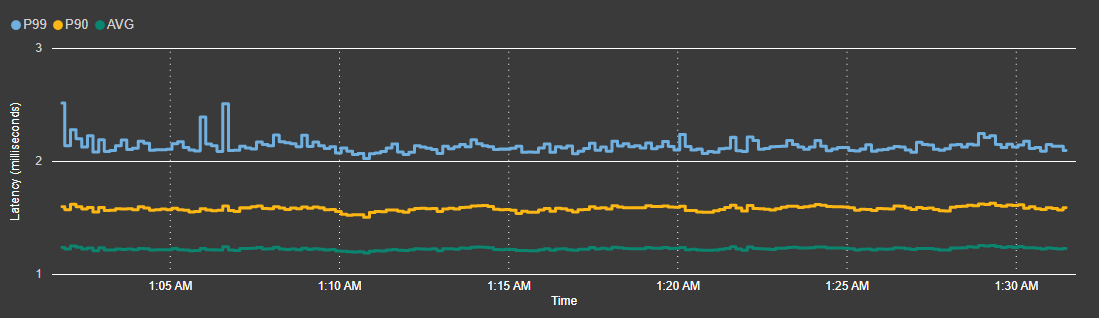
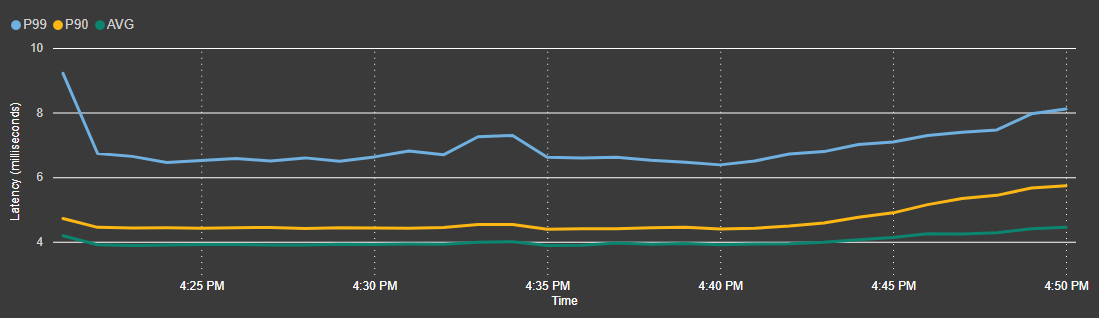
Vous pouvez vous attendre à voir les latences suivantes pour toutes les recettes de lecture et d’écriture dans le dépôt GitHub.
Latence de lecture
Latence d’écriture


Problèmes courants
Cette section inclut les erreurs courantes qui peuvent se produire lors de l’exécution de l’outil d’évaluation. Les journaux d’erreur de l’outil sont généralement disponibles dans un conteneur dans le compte de stockage Azure.

Si les journaux d’activité ne sont pas disponibles dans le compte de stockage, ce problème est généralement dû à une chaîne de connexion de stockage incorrecte ou manquante. Dans ce cas, cette erreur est répertoriée dans le fichier agent.out dans le dossier /home/benchmark de la machine virtuelle cliente.
Error while accessing storage account, exiting from this machine in agent.out on the VMCette erreur est répertoriée dans le fichier agent.out à la fois dans la machine virtuelle cliente et le compte de stockage si l’URI du point de terminaison Azure Cosmos DB est incorrect ou inaccessible.
Caused by: java.net.UnknownHostException: rtcosmosdbsss.documents.azure.com: Name or service not knownCette erreur est répertoriée dans le fichier agent.out à la fois dans la machine virtuelle cliente et le compte de stockage si la clé Azure Cosmos DB est incorrecte.
The input authorization token can't serve the request. The wrong key is being used….
Étapes suivantes
- En savoir plus sur l’outil d’évaluation avec le guide de prise en main.