Migrer des données de manière dynamique d’Apache Cassandra vers Azure Cosmos DB for Apache Cassandra en utilisant un proxy à double écriture et Azure Spark
L'API for Cassandra d'Azure Cosmos DB est devenue un excellent choix pour les charges de travail d'entreprise exécutées sur Apache Cassandra, notamment pour les raisons suivantes :
Aucune surcharge liée à la gestion et à la surveillance : l'API élimine les surcharges liées à la gestion et à la surveillance d'une multitude de paramètres dans les fichiers du système d'exploitation, les fichiers JVM et les fichiers yaml, ainsi qu'à leurs interactions.
Réduction significative des coûts : vous pouvez réaliser des économies grâce à Azure Cosmos DB, notamment sur les machines virtuelles, la bande passante et les licences applicables. En outre, vous n'avez pas à gérer les coûts liés aux centres de données, aux serveurs, au stockage SSD, à la mise en réseau et à la consommation électrique.
Possibilité d'utiliser le code et les outils existants : Azure Cosmos DB fournit une compatibilité au niveau du protocole filaire avec les SDK et outils Cassandra existants. Cette compatibilité garantit la possibilité d’utiliser votre codebase avec Azure Cosmos DB for Apache Cassandra sans changements majeurs.
Azure Cosmos B ne prend pas en charge le protocole de bavardage Apache Cassandra natif pour la réplication. Par conséquent, lorsqu’un temps d’arrêt nul est une exigence pour la migration, une autre approche est nécessaire. Ce tutoriel explique comment migrer des données de manière dynamique vers Azure Cosmos DB for Apache Cassandra à partir d’un cluster Apache Cassandra natif en utilisant un proxy à double écriture et Apache Spark.
L’approche est illustrée dans l’image suivante. Le proxy à double écriture est utilisé pour capturer les modifications en direct pendant que les données historiques sont copiées en bloc à l’aide d’Apache Spark. Le proxy peut accepter des connexions depuis votre code d’application avec peu ou pas de modifications de configuration. Il routera toutes les requêtes vers votre base de données source, et routera de manière asynchrone les écritures vers l’API for Cassandra pendant la copie en bloc.

Prérequis
Approvisionner un compte Azure Cosmos DB for Apache Cassandra.
Passez en revue les principes fondamentaux de la connexion à Azure Cosmos DB for Apache Cassandra.
Passez en revue les fonctionnalités prises en charge dans Azure Cosmos DB for Apache Cassandra pour garantir la compatibilité.
Vérifiez que vous disposez d’une connectivité réseau entre votre cluster source et le point de terminaison de l’API for Cassandra cible.
Vérifiez que vous avez déjà migré l’espace de clés/le schéma de table de votre base de données Cassandra source vers votre compte d’API for Cassandra cible.
Important
Si vous devez conserver Apache Cassandra
writetimelors de la migration, les indicateurs suivants doivent être définies lors de la création des tables :with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=truePar exemple :
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
Approvisionner un cluster Spark
Nous vous recommandons Azure Databricks. Utilisez un runtime qui prend en charge Spark 3.0 ou supérieur.
Important
Vous devez vérifier que votre compte Azure Databricks dispose d’une connectivité réseau à votre cluster Apache Cassandra source. Cela peut nécessiter une injection de VNet. Pour plus d’informations, consultez cet article.
Ajouter des dépendances Spark
Vous devez ajouter la bibliothèque du connecteur Apache Spark Cassandra à votre cluster pour vous connecter aux points de terminaison Cassandra natifs et Azure Cosmos DB. Dans votre cluster, sélectionnez Bibliothèques>Installer nouveau>Maven, puis ajoutez com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 dans les coordonnées Maven.
Important
Si vous devez conserver le writetime Apache Cassandra de chaque ligne pendant la migration, nous vous recommandons d’utiliser cet exemple. Dans cet exemple, le fichier .jar des dépendances contient également le connecteur Spark. Vous devez donc l’installer plutôt que l’assembly du connecteur ci-dessus. Cet exemple est également utile si vous voulez valider une comparaison de lignes entre la source et la cible une fois le chargement des données historiques terminé. Pour plus d’informations, consultez les sections « Effectuer le chargement des données d’historique » et « Vérifier la source et la cible » ci-dessous.
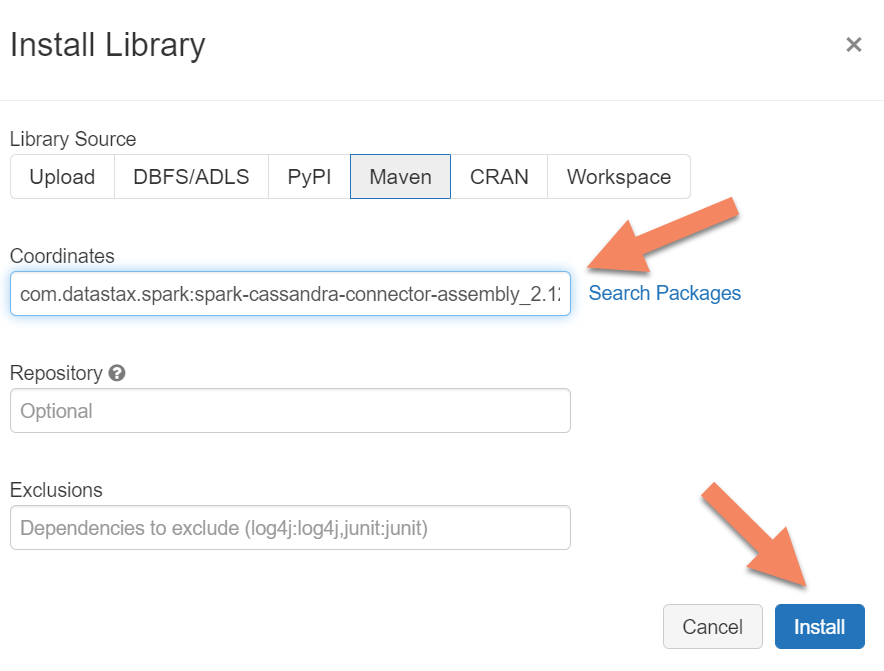
Sélectionnez Installer, puis redémarrez le cluster une fois l’installation terminée.
Notes
Veillez à redémarrer le cluster Azure Databricks après l’installation de la bibliothèque du connecteur Cassandra.
Installer le proxy de double écriture
Pour des performances optimales lors des doubles écritures, nous vous recommandons d’installer le proxy sur tous les nœuds dans votre cluster Cassandra source.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Démarrer le proxy de double écriture
Nous vous recommandons d’installer le proxy sur tous les nœuds dans votre cluster Cassandra source. Au minimum, exécutez la commande suivante pour démarrer le proxy sur chaque nœud. Remplacez <target-server> par l’adresse IP ou de serveur de l’un des nœuds dans le cluster cible. Remplacez <path to JKS file> par le chemin vers un fichier .jks local, et remplacez <keystore password> par le mot de passe correspondant.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Démarrer le proxy de cette façon suppose que les conditions suivantes sont réunies :
- Les points de terminaison source et cible ont le même nom d’utilisateur et le même mot de passe.
- Les points de terminaison source et cible implémentent SSL (Secure Sockets Layer).
Si vos points de terminaison source et cible ne peuvent pas répondre à ces critères, consultez les informations ci-dessous pour d’autres options de configuration.
Configuration du chiffrement SSL
Pour SSL, vous pouvez implémenter un magasin de clés existant (par exemple celui qu’utilise votre cluster source) ou créer un certificat auto-signé en utilisant keytool :
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
Vous pouvez aussi désactiver SSL pour les points de terminaison source ou cible s’ils n’implémentent pas SSL. Utilisez les indicateurs --disable-source-tls ou --disable-target-tls :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Notes
Vérifiez que votre application cliente utilise le même magasin de clés et le même mot de passe que ceux utilisés pour le proxy de double écriture lors de la création de connexions SSL à la base de données via le proxy.
Configurer les informations d’identification et le port
Par défaut, les informations d’identification sources sont passées depuis votre application cliente. Le proxy va utiliser les informations d’identification pour établir des connexions avec les clusters source et cible. Comme mentionné plus haut, ce processus suppose que les informations d’identification de la source et de la cible sont identiques. Il sera nécessaire de spécifier un nom d’utilisateur et un mot de passe différents pour le point de terminaison d’API for Cassandra cible séparément lors du démarrage du proxy :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Si les ports source et cible ne sont pas spécifiés, le port par défaut est 9042. Dans ce cas, l’API for Cassandra s’exécute sur le port 10350. Vous devez donc utiliser --source-port ou --target-port pour spécifier les numéros de ports :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Déployer le proxy à distance
Dans certaines circonstances, vous ne voulez pas installer le proxy sur les nœuds de cluster proprement dits et vous préférez l’installer sur une machine distincte. Dans ce scénario, vous devez spécifier l’adresse IP de <source-server> :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Avertissement
Le fait d’installer et d’exécuter le proxy à distance sur un ordinateur séparé (plutôt que de l’exécuter sur tous les proxys de votre cluster Apache Cassandra source) a une incidence sur les performances pendant la migration en temps réel. Même si cela fonctionne, le pilote client ne pourra pas ouvrir les connexions à tous les nœuds du cluster et s’appuiera sur le nœud coordinateur (sur lequel est installé le proxy) pour établir des connexions.
Autoriser les modifications sans aucun code d’application
Par défaut, le proxy écoute sur le port 29042. Le code d’application doit être modifié de façon à pointer vers ce port. Cependant, vous pouvez changer le port sur lequel le proxy est à l’écoute. Vous pouvez faire ceci si vous voulez ne pas modifier le code au niveau de l’application :
- Faire en sorte que le serveur Cassandra source s’exécute sur un port différent.
- Faire en sorte que le proxy s’exécute sur le port Cassandra standard 9042.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Notes
L’installation du proxy sur des nœuds de cluster ne nécessite pas de redémarrage des nœuds. Cependant, si vous avez de nombreux clients d’application et que vous préférez que le proxy s’exécute sur le port Cassandra standard 9042 afin d’éviter des modifications du code au niveau de l’application, vous devez changer le port par défaut d’Apache Cassandra. Vous devez ensuite redémarrer les nœuds de votre cluster et configurer le port source pour qu’il corresponde au nouveau port que vous avez défini pour votre cluster Cassandra source.
Dans l’exemple suivant, nous modifions le cluster Cassandra source pour qu’il s’exécute sur le port 3074 et nous démarrons le cluster sur le port 9042 :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Forcer les protocoles
Le proxy dispose de fonctionnalités pour forcer les protocoles, ce qui peut être nécessaires si le point de terminaison source est plus avancé que la cible ou s’il n’est pas pris en charge. Dans ce cas, vous pouvez spécifier --protocol-version et --cql-version pour forcer le protocole à se conformer à la cible :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Une fois que le proxy à double écriture est en cours d’exécution, vous devez changer le port sur votre client d’application et redémarrer. (Ou bien changer le port Cassandra et redémarrer le cluster si vous avez choisi cette approche.) Le proxy va alors démarrer le transfert des écritures vers le point de terminaison cible. Des informations sur la surveillance et les métriques dans l’outil proxy sont disponibles.
Effectuer le chargement des données d’historique
Pour charger les données, créez un notebook Scala dans votre compte Azure Databricks. Remplacez vos configurations Cassandra source et cible par les informations d’identification correspondantes, et remplacez les espaces de clés et les tables sources et cibles. Ajoutez des variables à l’exemple ci-dessous pour chaque table en fonction des besoins, puis lancez l’exécution. Une fois que votre application a commencé à envoyer des demandes au proxy de double écriture, vous êtes prêt à migrer les données d’historique.
Important
Avant de migrer les données, augmentez le débit du conteneur jusqu'à la quantité requise pour que votre application migre rapidement. La mise à l’échelle du débit avant le début de la migration vous aidera à migrer vos données plus rapidement. Pour mieux vous protéger contre la limitation de débit pendant le chargement historique des données, vous pouvez activer les nouvelles tentatives côté serveur dans l’API for Cassandra. Pour plus d’informations et des instructions sur l’activation des nouvelles tentatives côté serveur, consultez cet article.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Notes
Dans l’exemple Scala précédent, notez que timestamp est défini sur l’heure actuelle avant de lire toutes les données de la table source. Ensuite writetime est défini sur cet horodatage antidaté. Ceci garantit que les enregistrements écrits depuis le chargement des données d’historique sur le point de terminaison cible ne peuvent pas remplacer les mises à jour qui arrivent avec un horodatage ultérieur en provenance du proxy de double écriture pendant la lecture des données d’historique.
Important
Si pour une raison quelconque, vous devez conserver les horodatages exacts, il vous faut adopter une approche de la migration des données d’historique qui conserve les horodatages, comme dans cet exemple. Dans l’exemple, le fichier .jar de dépendances contient également le connecteur Spark. Vous n’avez donc pas besoin d’installer l’assembly du connecteur Spark mentionné dans les prérequis précédents. L’installation des deux assemblys dans votre cluster Spark entraînera des conflits.
Vérifier la source et la cible
Une fois le chargement des données d’historique terminé, vos bases de données doivent être synchronisées et prêtes pour le basculement. Cependant, nous vous recommandons de vérifier que la source et la cible correspondent bien avant d’effectuer le basculement final.
Notes
Si vous avez utilisé l’exemple cassandra migrator mentionné ci-dessus pour conserver writetime, vous pouvez valider la migrationen comparant les lignes de la source et de la cible en fonction de certaines tolérances.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour