Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : ![]() NoSQL
NoSQL
Pour migrer une base de données relationnelle vers Azure Cosmos DB for NoSQL, il peut être nécessaire d’apporter des modifications au modèle de données pour l’optimisation.
L’une des transformations courantes consiste à dénormaliser les données en incorporant des sous-éléments associés dans un document JSON. Ici, nous examinons quelques options pour cela à l’aide d’Azure Data Factory ou d’Azure Databricks. Pour plus d’informations sur la modélisation des données pour Azure Cosmos DB, consultez Modélisation des données dans Azure Cosmos DB.
Exemple de scénario
Supposons que nous ayons les deux tables suivantes dans notre base de données SQL, Orders et OrderDetails.
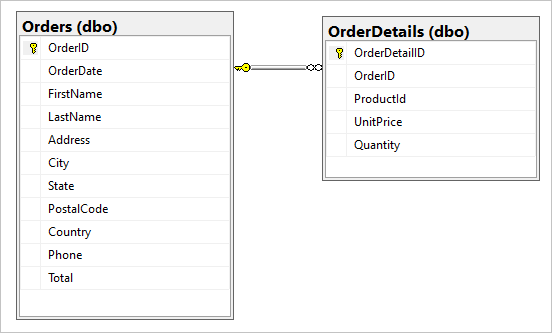
Nous voulons combiner cette relation un-à-plusieurs dans un document JSON pendant la migration. Pour créer un document unique, créez une requête T-SQL à l’aide de FOR JSON :
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
Les résultats de cette requête incluent les données de la table Orders :

Dans l’idéal, vous souhaitez utiliser une activité unique de copie Azure Data Factory (ADF) pour interroger les données SQL en tant que source et écrire la sortie directement sur le récepteur Azure Cosmos DB en tant qu’objets JSON appropriés. Actuellement, il n’est pas possible d’effectuer la transformation JSON nécessaire dans une seule activité de copie. Si nous essayons de copier les résultats de la requête ci-dessus dans un conteneur d’Azure Cosmos DB for NoSQL, nous voyons le champ OrderDetails en tant que propriété de chaîne de notre document, au lieu du tableau JSON attendu.
Nous pouvons contourner cette limitation actuelle de l’une des manières suivantes :
-
Utilisez Azure Data Factory avec deux activités de copie :
- Obtenez des données au format JSON à partir de SQL et copiez-les vers un fichier texte dans un emplacement de stockage d’objets blob intermédiaire
- Chargez des données à partir du fichier texte JSON dans un conteneur d’Azure Cosmos DB.
- Utilisez Azure Databricks pour lire à partir de SQL et écrire dans Azure Cosmos DB : nous présentons deux options ici.
Examinons ces approches plus en détail :
Azure Data Factory.
Bien que nous ne puissions pas incorporer OrderDetails en tant que tableau JSON dans le document Azure Cosmos DB de destination, nous pouvons contourner le problème en utilisant deux activités de copie distinctes.
Activité de copie n° 1 : SqlJsonToBlobText
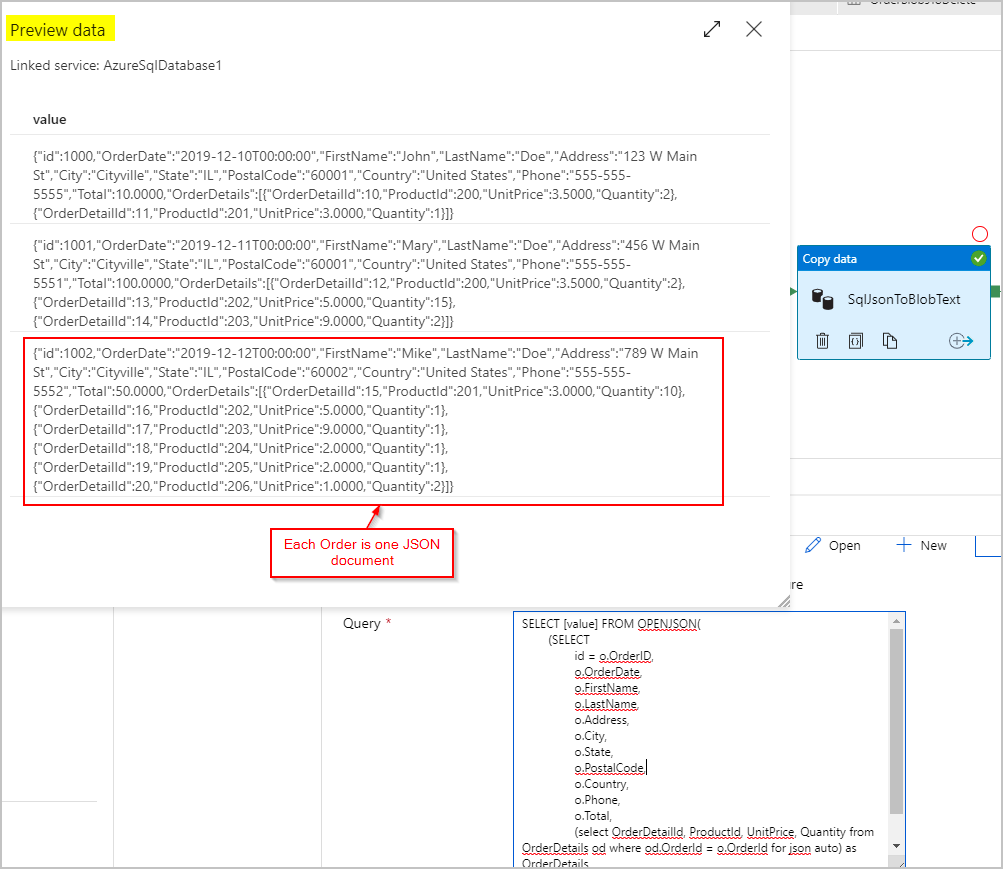
Pour les données sources, nous utilisons une requête SQL pour obtenir le jeu de résultats sous la forme d’une colonne unique avec un objet JSON (représentant la commande) par ligne à l’aide des fonctionnalités SQL Server OPENJSON et FOR JSON PATH :
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
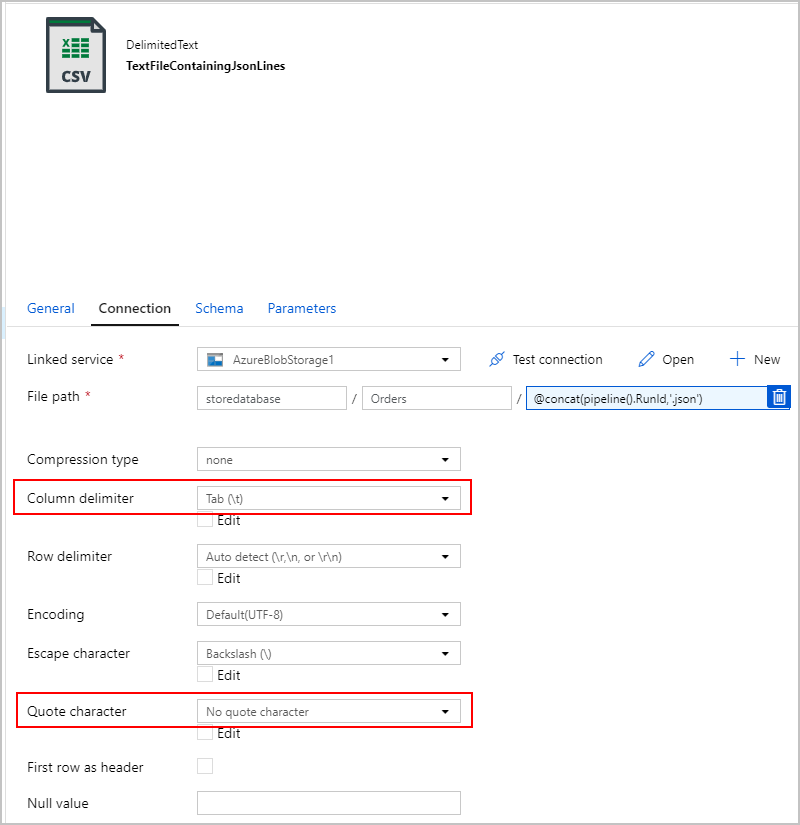
Pour le récepteur de l'activité de copie SqlJsonToBlobText, nous choisissons « Texte délimité » et nous le dirigeons vers un dossier spécifique dans Azure Blob Storage. Ce récepteur inclut un nom de fichier unique généré dynamiquement (par exemple, @concat(pipeline().RunId,'.json').
Étant donné que notre fichier texte n’est pas vraiment « délimité » et que nous ne voulons pas qu’il soit analysé dans des colonnes distinctes à l’aide de virgules. Nous voulons également conserver les guillemets doubles ("), définir le « Délimiteur de colonne » par une tabulation ("\t") ou un autre caractère n'apparaissant pas dans les données, puis définir le « Caractère de citation » par « Aucun caractère de citation ».
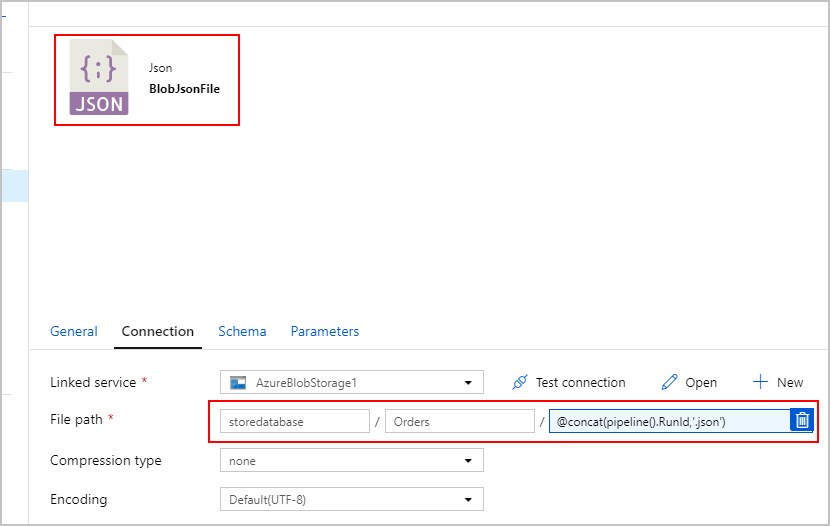
Activité de copie n° 2 : BlobJsonToCosmos
Ensuite, nous modifions notre pipeline ADF en ajoutant la deuxième activité de copie qui recherche le fichier texte créé par la première activité dans Stockage Blob Azure. Il le traite en tant que source « JSON » à insérer dans le récepteur Azure Cosmos DB sous la forme d’un document par ligne JSON trouvée dans le fichier texte.
En option, nous ajoutons également une activité « Supprimer » au pipeline pour qu’il supprime tous les fichiers précédents restants dans le dossier /Orders/ avant chaque exécution. Notre pipeline ADF ressemble maintenant à ce qui suit :
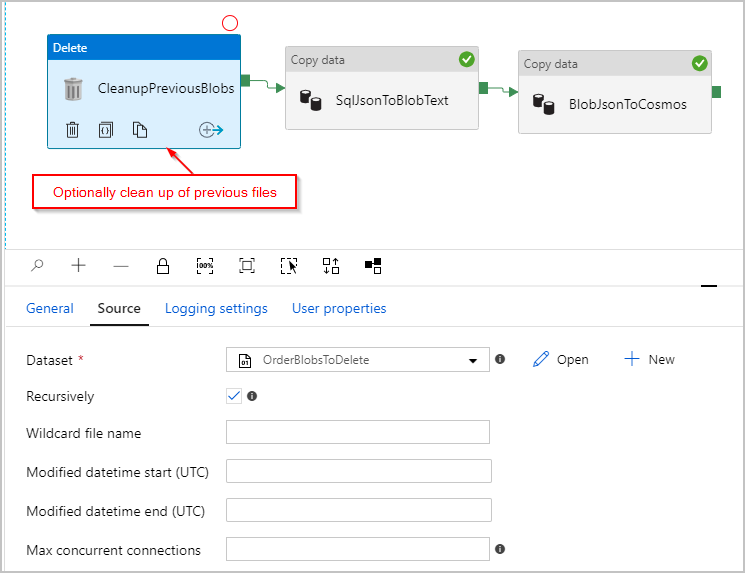
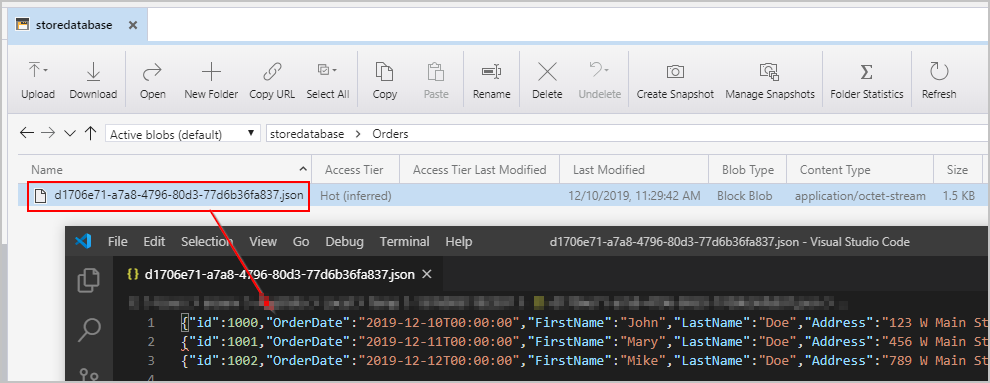
Une fois que nous avons déclenché le pipeline ci-dessus, nous voyons un fichier créé dans l’emplacement Stockage Blob Azure intermédiaire contenant un objet JSON par ligne :
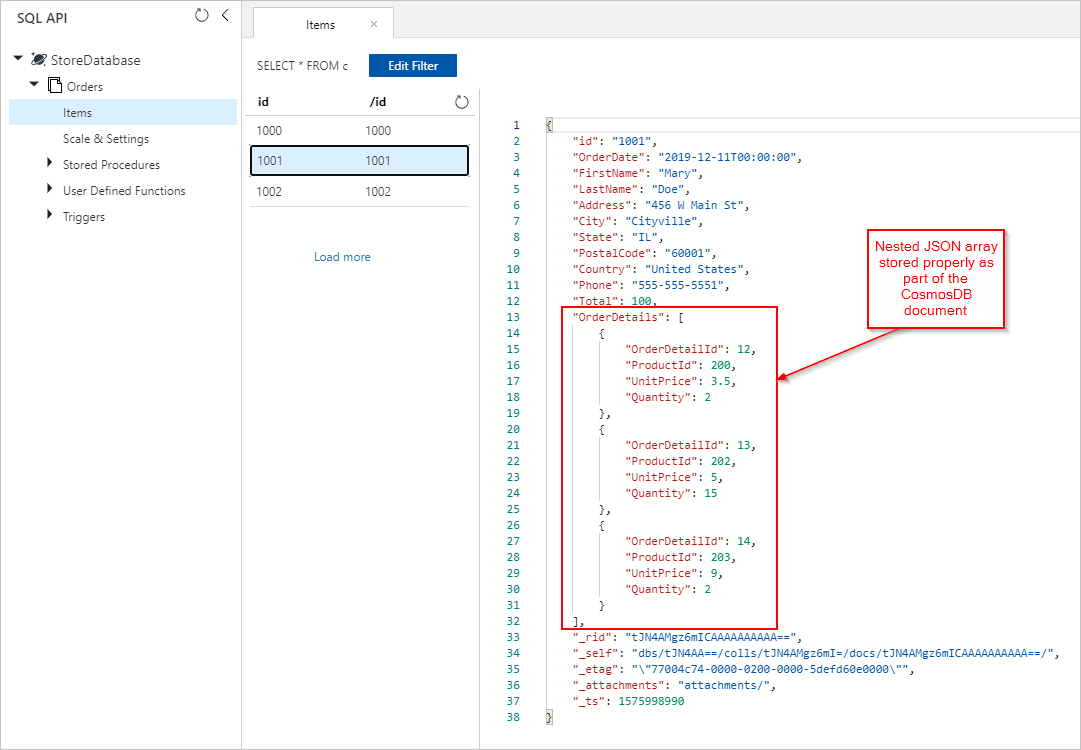
Nous voyons également les documents Orders avec des OrderDetails correctement incorporés et insérés dans notre collection Azure Cosmos DB :
Azure Databricks
Vous pouvez également utiliser Spark dans Azure Databricks pour copier les données de notre source de SQL Database vers la destination Azure Cosmos DB sans créer les fichiers text/JSON intermédiaires dans Stockage Blob Azure.
Notes
Pour des raisons de clarté et de simplicité, les extraits de code incluent des mots de passe de base de données factices explicitement inlined, mais vous devez idéalement utiliser des secrets Azure Databricks.
Tout d’abord, nous créons et attachons les bibliothèques des connecteur SQL et connecteur Azure Cosmos DB requises à notre cluster Azure Databricks. Redémarrez le cluster pour vous assurer que les bibliothèques sont chargées.

Nous présentons ensuite deux exemples pour Scala et Python.
Langage de programmation Scala
Ici, nous obtenons les résultats de la requête SQL avec la sortie « FOR JSON » dans un DataFrame :
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
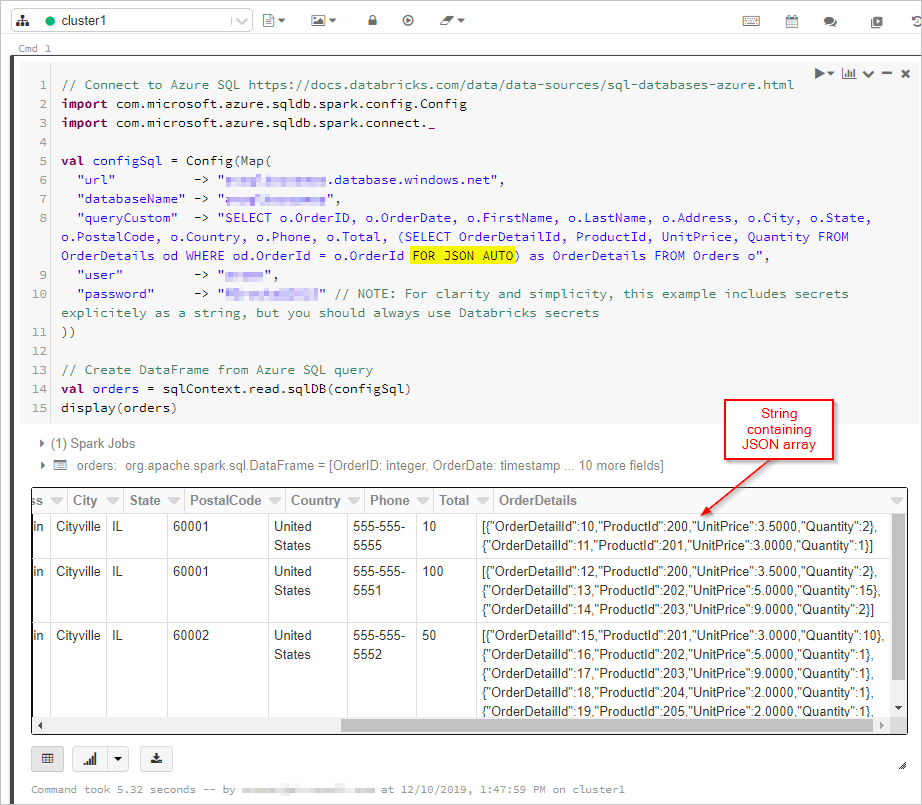
Ensuite, nous nous connectons à notre base de données et collection Azure Cosmos DB :
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
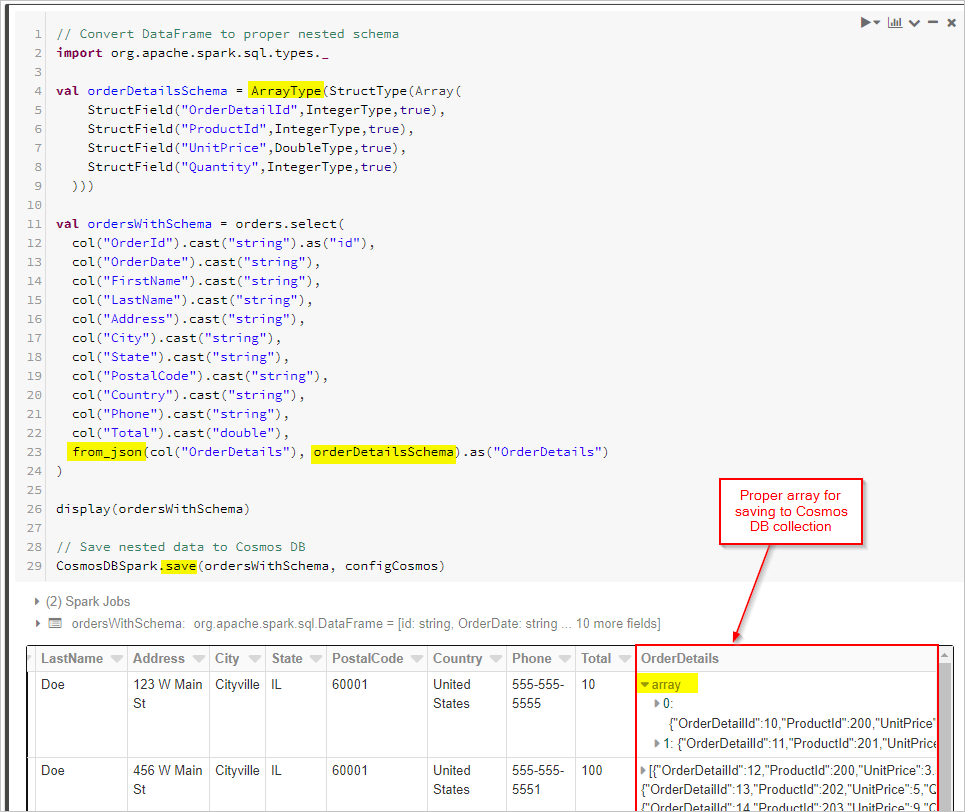
Enfin, nous définissons notre schéma et utilisons from_json pour appliquer le DataFrame avant de l’enregistrer dans la collection Cosmos DB.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
En guise d’approche alternative, vous devrez peut-être exécuter des transformations JSON dans Spark si la base de données source ne prend pas en charge FOR JSON ou une opération similaire. Vous pouvez également utiliser des opérations parallèles pour un jeu de données volumineux. Ici, nous présentons un exemple PySpark. Commencez par configurer les connexions à la base de données source et cible dans la première cellule :
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Ensuite, nous interrogeons la base de données source (dans ce cas, SQL Server) pour les enregistrements des commandes et des détails de commande, en plaçant les résultats dans des DataFrames Spark. Nous créons une liste contenant tous les ID de commande et un pool de threads pour les opérations parallèles :
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Créez ensuite une fonction pour l’écriture de commandes dans la collection d’API pour NoSQL cible. Cette fonction filtre tous les détails de la commande pour l’ID de commande donné, les convertit en tableau JSON et insère le tableau dans un document JSON. Le document JSON est ensuite écrit dans le conteneur d’API cible pour NoSQL pour cet ordre :
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Enfin, nous appelons la fonction writeOrder Python à l’aide d’une fonction de mappage sur le pool de threads, à exécuter en parallèle, en transmettant la liste des ID de commande que nous avons créée précédemment :
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
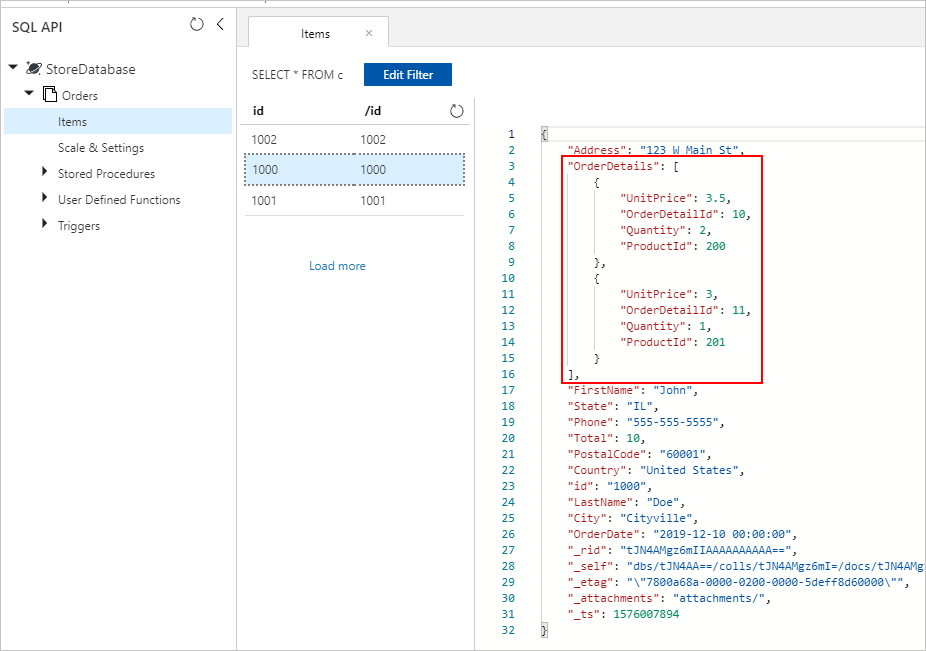
Dans l’une ou l’autre approche, nous devrions correctement enregistrer à la fin les OrderDetails incorporés dans chaque document Order de la collection Azure Cosmos DB :
Étapes suivantes
- En savoir plus sur la modélisation des données dans Azure Cosmos DB
- Lire le Guide pratique pour modéliser et partitionner des données sur Azure Cosmos DB