Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Important
Azure Cosmos DB pour PostgreSQL n’est plus pris en charge pour les nouveaux projets. N’utilisez pas ce service pour les nouveaux projets. Utilisez plutôt l’un des deux services suivants :
Utilisez Azure Cosmos DB pour NoSQL pour une solution de base de données distribuée conçue pour des scénarios à grande échelle avec un contrat de niveau de service de disponibilité (SLA) de 99,999%, une mise à l’échelle automatique instantanée et un basculement automatique entre plusieurs régions.
Utilisez la fonctionnalité Elastic Clusters d'Azure Database pour PostgreSQL pour un PostgreSQL partagé utilisant l'extension open source Citus.
Le choix de la colonne de distribution de chaque table est l’une des décisions les plus importantes que vous allez prendre en matière de modélisation. Azure Cosmos DB for PostgreSQL stocke des lignes dans des partitions en fonction de la valeur de la colonne de distribution des lignes.
Le choix correct permet de regrouper les données sur les mêmes nœuds physiques, ce qui a pour effet d’accélérer les requêtes et d’ajouter la prise en charge toutes les fonctionnalités SQL. En cas de mauvais choix, le système est ralenti.
Conseils généraux
Voici quatre critères qui vous aideront à choisir la colonne de distribution idéale pour vos tables distribuées.
Choisissez une colonne qui est un élément central dans la charge de travail de l’application.
Vous pouvez considérer cette colonne comme le « cœur », l’« élément central » ou la « dimension naturelle » pour le partitionnement des données.
Exemples :
-
device_iddans une charge de travail IoT -
security_idpour une application financière qui gère des titres -
user_iddans l’analytique utilisateur -
tenant_idpour une application SaaS multilocataire
-
Choisissez une colonne avec une cardinalité correcte et une distribution statistique uniforme.
La colonne doit contenir beaucoup de valeurs et distribuer les valeurs de manière rigoureuse et uniforme entre toutes les partitions.
Exemples :
- Cardinalité supérieure à 1 000
- Ne choisissez pas une colonne qui a la même valeur sur un grand pourcentage de lignes (asymétrie des données)
- Dans une charge de travail SaaS, l’existence d’un locataire bien plus grand que le reste peut entraîner une asymétrie des données. Dans ce cas, vous pouvez utiliser l’isolation du locataire pour créer une partition dédiée à la gestion du locataire.
Choisissez une colonne qui utilise vos requêtes existantes.
Pour une charge de travail transactionnelle ou opérationnelle (dans laquelle la plupart des requêtes ne prennent que quelques millisecondes), choisissez une colonne qui apparaît sous la forme d’un filtre dans les clauses
WHEREpour au moins 80 % des requêtes. Par exemple, la colonnedevice_iddansSELECT * FROM events WHERE device_id=1.Pour une charge de travail analytique (où la plupart des requêtes prennent entre une et deux secondes), choisissez une colonne qui permet la parallélisation des requêtes entre les nœuds worker. Par exemple, une colonne qui apparaît souvent dans les clauses GROUP BY, ou qui est interrogée sur plusieurs valeurs à la fois.
Choisissez une colonne qui est présente dans la majorité des grandes tables.
Les tables de plus de 50 Go doivent être distribuées. Le choix de la même colonne de distribution pour toutes ces tables vous permet de colocaliser les données de cette colonne sur les nœuds worker. La colocalisation permet d’exécuter efficacement des jointures (JOIN) et des cumuls (Rollup), ainsi que d’appliquer des clés étrangères.
Les autres tables (plus petites) peuvent être des tables locales ou de référence. Si la plus petite table doit être jointe (JOIN) à des tables distribuées, définissez-la en tant que table de référence.
Exemples de cas d’usage
Nous avons vu les critères généraux selon lesquels choisir la colonne de distribution. Voyons maintenant comment ils s’appliquent à des cas d’usage courants.
Applications multi-locataires
L’architecture mutualisée utilise une forme de modélisation de base de données hiérarchique pour distribuer les requêtes sur les nœuds dans le cluster. Le haut de la hiérarchie de données est appelé l’ID de locataire et doit être stocké dans une colonne sur chaque table.
Azure Cosmos DB for PostgreSQL inspecte les requêtes pour repérer l’ID de locataire impliqué et recherche la partition de table correspondante. Il achemine la requête à un nœud Worker unique qui contient la partition. L’exécution d’une requête avec toutes les données pertinentes placées sur le même nœud est appelée « colocation ».
Le diagramme suivant illustre la colocation dans le modèle de données mutualisé. Il contient deux tables (comptes et campagnes), chacune répartie par account_id. Les zones grisées représentent des partitions. Les partitions vertes sont stockées ensemble sur un nœud Worker, et les partitions bleues sur un autre. Notez comment une requête de jointure entre des comptes et des campagnes dispose de toutes les données nécessaires regroupées sur un seul nœud quand les deux tables sont limitées à la même valeur account_id.
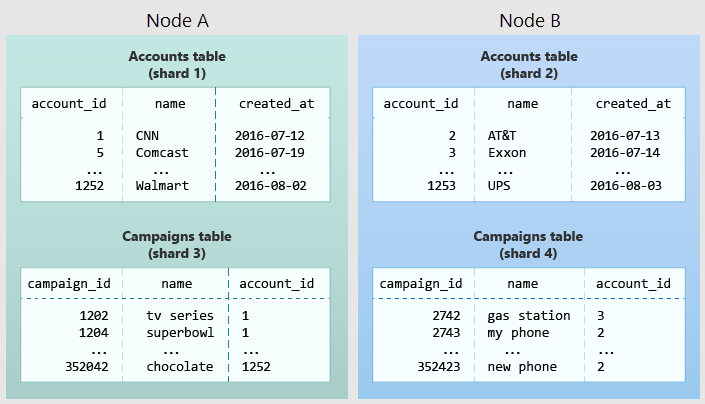
Pour appliquer cette conception dans votre propre schéma, identifiez ce qui constitue un locataire dans votre application. Les instances courantes incluent une société, un compte, une organisation ou un client. Le nom de colonne ressemble à company_id ou customer_id. Examinez chacune de vos requêtes et demandez-vous si elle fonctionnerait si elle contenait plus de clauses WHERE supplémentaires pour restreindre toutes les tables impliquées aux lignes avec le même ID de locataire ? Les requêtes dans le modèle mutualisé sont étendues à un locataire. Par exemple, des requêtes sur les ventes ou l’inventaire sont étendues dans un magasin donné.
Meilleures pratiques
- Distribuez les tables en fonction d’une colonne tenant_id commune. Par exemple, dans une application SaaS où les locataires sont des entreprises, la valeur tenant_id est susceptible d’être la valeur company_id.
- Convertissez les tables de petite taille partagées entre locataires en tables de référence. Lorsque plusieurs locataires partagent une petite table d’informations, distribuez-la comme une table de référence.
- Filtrez toutes les requêtes d’application par tenant_id. Chaque requête doit demander des informations pour un seul locataire à la fois.
Lisez le didacticiel mutualisé pour obtenir un exemple de création de ce type d’application.
Applications en temps réel
L’architecture mutualisée présente une structure hiérarchique et utilise la colocation de données pour acheminer les requêtes par locataire. En revanche, les architectures en temps réel dépendent des propriétés de distribution spécifiques de leurs données à obtenir un traitement hautement parallèle.
Nous utilisons « ID d’entité » pour désigner les colonnes de distribution dans le modèle en temps réel. Les entités standard sont des utilisateurs, des hôtes ou des appareils.
Les requêtes en temps réel nécessitent en général des agrégats numériques regroupés par date ou par catégorie. Azure Cosmos DB for PostgreSQL envoie ces requêtes à chaque partition pour obtenir des résultats partiels et assemble la réponse finale sur le nœud coordinateur. Les requêtes s’exécutent plus rapidement lorsqu’un maximum de nœuds contribuent, et lorsque aucun nœud unique ne doit faire une quantité disproportionnée du travail.
Meilleures pratiques
- Choisissez une colonne présentant une cardinalité élevée comme colonne de distribution. À titre de comparaison, un champ d’état sur une table de commandes avec les valeurs « nouvelle », « payée » et « livrée » est un choix médiocre de colonne de distribution. Il part du principe que seules ces quelques valeurs existent, ce qui limite le nombre de partitions pouvant stocker les données et le nombre de nœuds pouvant les traiter. Parmi les colonnes présentant une cardinalité élevée, il est également judicieux de choisir les celles qui sont fréquemment utilisées dans les clauses group-by ou en tant que clés de jointure.
- Choisissez une colonne avec une distribution uniforme. Si vous distribuez une table sur une colonne déviée vers certaines valeurs courantes, les données de la table ont tendance à s’accumuler dans certaines partitions. Les nœuds contenant ces partitions finissent par effectuer plus de travail que les autres nœuds.
- Distribuez les tables de faits et de dimension sur leurs colonnes communes. Votre table de faits ne peut avoir qu’une seule clé de distribution. Les tables qui créent une jointure sur une autre clé ne se trouvent pas au même emplacement que la table de faits. Choisissez une dimension pour effectuer la colocation selon la taille des lignes de jointure et la fréquence de jointure.
- Modifiez des tables de dimension en tables de référence. Si une table de dimension ne peut pas être au même emplacement que la table de faits, vous pouvez améliorer les performances des requêtes en distribuant des copies de la table de dimension à tous les nœuds sous la forme d’une table de référence.
Lisez le didacticiel de tableau de bord mutualisé pour obtenir un exemple de création de ce type d’application.
Données de série chronologique
Dans une charge de travail de série chronologique, les applications interrogent les informations récentes lors de l’archivage d’anciennes informations.
L’erreur la plus fréquente lors de la modélisation des informations de série chronologique dans Azure Cosmos DB for PostgreSQL consiste à utiliser l’horodatage comme colonne de distribution. Une distribution de hachage basée sur le temps distribue le temps de façon apparemment aléatoire dans différentes partitions plutôt que de conserver des plages de temps groupées dans des partitions. Les requêtes qui impliquent du temps font généralement référence à des plages de temps, par exemple, pour obtenir les données les plus récentes. Ce type de distribution de hachage entraîne une surcharge du réseau.
Meilleures pratiques
- Ne choisissez pas un horodatage comme colonne de distribution. Choisissez une colonne de distribution différente. Dans une application mutualisée, utilisez l’ID de locataire ou, dans une application en temps réel, l’ID d’entité.
- Utilisez le partitionnement de table PostgreSQL pour les données temporelles à la place. Utilisez le partitionnement de table pour diviser une table volumineuse de données chronologiques en plusieurs tables héritées contenant chacune différentes plages de temps. La distribution d’une table partitionnée Postgres crée des partitions pour les tables héritées.
Étapes suivantes
- Découvrez comment la colocation entre les requêtes distribuées permettent d’exécuter rapidement les requêtes.
- Découvrez la colonne de distribution d’une table distribuée et d’autres requêtes de diagnostic utiles.