Vue d’ensemble de la continuité d'activité et de la reprise d'activité
Dans Azure Data Explorer, la continuité d'activité et la reprise d'activité permettent à votre entreprise de continuer de fonctionner en cas de perturbation. Cet article traite de la disponibilité (intra-région) et de la récupération d’urgence. Il détaille les fonctionnalités natives et les considérations architecturales pour un déploiement robuste d’Azure Data Explorer. Il détaille la récupération des erreurs humaines, la haute disponibilité, de même que plusieurs configurations de récupération d’urgence. Ces configurations dépendent des exigences en matière de résilience, telles que l’objectif de point de récupération (RPO) et l’objectif de délai de récupération (RTO), l’effort nécessaire et le coût.
Atténuer les événements perturbateurs
- Erreur humaine
- Haute disponibilité d’Azure Data Explorer
- Panne d’une zone de disponibilité Azure
- Panne d’un centre de données Azure
- Panne d’une région Azure
Erreur humaine
Les erreurs humaines sont inévitables. Les utilisateurs peuvent accidentellement supprimer un cluster, une base de données ou une table.
Suppression accidentelle d’un cluster ou d’une base de données
La suppression accidentelle d’un cluster ou d’une base de données est irréversible. En tant que propriétaire de ressource Azure Data Explorer, vous pouvez prévenir la perte de données en activant la fonctionnalité de suppression de verrouillage, disponible au niveau des ressources Azure.
Suppression accidentelle de table
Les utilisateurs dotés d’autorisations d’administration de table, voire davantage, sont autorisés à supprimer des tables. Si l’un de ces utilisateurs supprime accidentellement une table, vous pouvez la récupérer à l’aide de la commande .undo drop table. Pour que cette commande aboutisse, vous devez d’abord activer la propriété de récupération dans la stratégie de rétention.
Suppression accidentelle de table externe
Les tables externes sont des entités de schéma de requête Kusto qui font référence aux données stockées en dehors de la base de données Kusto. La suppression d’une table externe supprime uniquement les métadonnées de la table. Vous pouvez la récupérer en exécutant à nouveau la commande de création de table. Utilisez la fonctionnalité de suppression réversible pour prévenir les suppressions accidentelles ou le remplacement d’un fichier/objet blob pour un intervalle de temps défini par l’utilisateur.
Haute disponibilité d’Azure Data Explorer
La haute disponibilité fait référence à la tolérance de panne d’Azure Data Explorer, de ses composants et des dépendances sous-jacentes au sein d’une région Azure. La tolérance de panne évite les points de défaillance uniques (SPOF) dans l’implémentation. Dans Azure Data Explorer, la haute disponibilité comprend la couche de persistance, la couche de calcul et une configuration « leader-suiveur ».
Couche de persistance
Azure Data Explorer utilise le stockage Azure comme couche de persistance durable. Le stockage Azure fournit automatiquement la tolérance de panne, avec le paramètre par défaut offrant un stockage localement redondant (LRS) au sein d’un centre de données. Trois réplicas sont conservés. Si un réplica est perdu en cours d’utilisation, un autre est déployé sans interruption. Une résilience plus poussée est possible avec le stockage redondant interzone (ZRS, zone redundant storage)qui place les réplicas intelligemment dans les zones de disponibilité régionales Azure pour une tolérance de panne maximale, moyennant un coût supplémentaire. Le stockage avec ZRS est automatiquement configuré lorsque le cluster Azure Data Explorer est déployé dans des Zones de disponibilité.
Couche de calcul
Azure Data Explorer est une plateforme de calcul distribuée et peut présenter deux nœuds, voire davantage en fonction de l’échelle et du type de rôle de nœud. Au moment de l’approvisionnement, sélectionnez les zones de disponibilité dans lesquelles répartir le déploiement de nœuds, dans plusieurs zones pour une résilience intra-région maximale. L’échec d’une zone de disponibilité ne provoque pas de panne complète, mais une dégradation des performances jusqu’à la restauration de la zone.
Configuration de cluster « leader-suiveur »
Azure Data Explorer fournit une fonctionnalité de suivi facultative pour permettre à un cluster leader d’être suivi par d’autres clusters suiveurs à des fins d’accès en lecture seule aux données et métadonnées du leader. Les modifications apportées au leader, comme create, appendet drop, sont automatiquement synchronisées avec le suiveur. Si les leaders peuvent s’étendre sur les régions Azure, les clusters suiveurs doivent être hébergés dans les mêmes régions que le leader. Si le cluster leader est en panne ou si des bases de données ou tables ont été accidentellement supprimées, les clusters suiveurs en perdront l’accès jusqu’à ce que celui-ci soit rétabli dans le leader.
Panne d’une zone de disponibilité Azure
Les zones de disponibilité Azure sont des emplacements physiques uniques au sein de la même région Azure. Elles peuvent protéger un cluster de calcul et des données Azure Data Explorer contre la défaillance partielle d’une région. La défaillance d’une zone est un scénario de disponibilité car elle est intra-région.
Épinglez un cluster Azure Data Explorer à la même zone que les autres ressources Azure connectées. Pour plus d’informations sur l’activation des zones de disponibilité, consultez Créer un cluster.
Notes
Le déploiement vers des zones de disponibilité est possible lors de la création d’un cluster ou peut être migré ultérieurement.
Panne d’un centre de données Azure
Les zones de disponibilité Azure ont un coût et certains clients optent pour un déploiement sans redondance zonale. Avec un déploiement Azure Data Explorer de ce type, une panne du centre de données Azure entraîne une panne de cluster. La gestion d’une panne de centre de données Azure est donc identique à celle d’une panne de région Azure.
Panne d’une région Azure
Azure Data Explorer ne fournit pas de protection automatique contre une panne de région Azure entière. Pour réduire l’impact d’une panne sur l’entreprise, multipliez les clusters Azure Data Explorer dans des régions jumelées Azure. En fonction de l’objectif de délai de récupération (RTO), de l’objectif de point de récupération (RPO), ainsi que des considérations en matière d’effort et de coût, il existe plusieurs configurations de récupération d’urgence. Les optimisations des coûts et des performances sont possibles avec les recommandations Azure Advisor et la configuration de mise à l’échelle automatique.
Configuration de la récupération d'urgence
Cette section détaille les différentes configurations de la récupération d’urgence selon les exigences de résilience (RPO et RTO), de l’effort nécessaire et du coût.
L’objectif de délai de récupération (RTO) fait référence au délai nécessaire pour procéder à une récupération après une interruption. Par exemple, un RTO de 2 heures signifie que l’application doit être en cours d’exécution dans les deux heures qui suivent une interruption. L’objectif de point de récupération (RPO) fait référence à l’intervalle de temps qui peut s’écouler pendant une interruption avant que la quantité de données perdues au cours de cette période dépasse le seuil autorisé. Par exemple, si le RPO est de 24 heures et qu’une application contient des données remontant à 15 ans, elles sont toujours dans les paramètres du RPO convenu.
Les processus d’ingestion, de traitement et d’intégration nécessitent une conception diligente au moment de la planification de la récupération d’urgence. L’ingestion fait référence aux données intégrées à Azure Data Explorer à partir de différentes sources, le traitement fait référence à des transformations et activités similaires, l’intégration fait référence aux vues matérialisées, aux exportations vers le lac de données, et ainsi de suite.
Voici quelques configurations de récupération d’urgence courantes. Chacune est décrite en détail ci-dessous.
- Configuration Active-Active-Active (Always On)
- Configuration active-active
- Configuration de secours active
- Configuration de cluster de récupération de données à la demande
Configuration Active-Active-Active
Cette configuration est également appelée « Always On ». Pour les déploiements d’applications critiques sans tolérance de panne, vous devez utiliser plusieurs clusters Azure Data Explorer dans des régions jumelées Azure. Configurez l’ingestion, le traitement et l’intégration en parallèle pour tous les clusters. La référence SKU du cluster doit être la même dans toutes les régions. Azure s’assure que les mises à jour sont déployées et échelonnées dans les régions jumelées Azure. Une panne de région Azure ne provoque pas de panne d’application. Vous pouvez cependant noter une dégradation de la latence ou des performances.
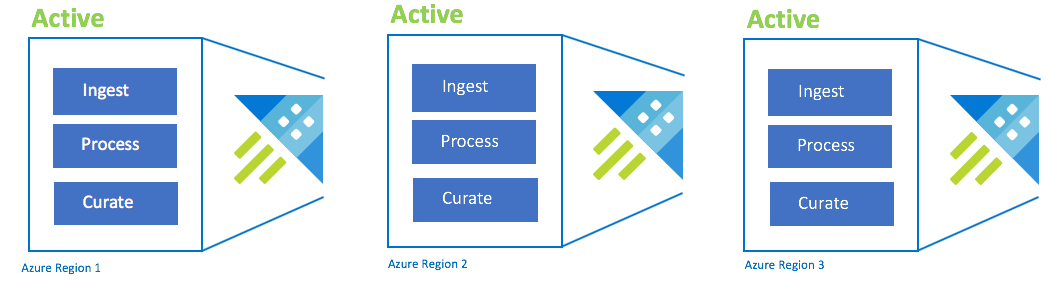
| Configuration | RPO | RTO | Effort | Coût |
|---|---|---|---|---|
| Active-Active-Active-n | 0 heure | 0 heure | Moins grand | Le plus élevé |
Configuration active/active
Cette configuration est identique à la Configuration Active-Active-Active, mais implique seulement deux régions jumelées Azure. Configurez l’ingestion, le traitement et l’intégration en double. Les utilisateurs sont acheminés vers la région la plus proche. La référence SKU du cluster doit être la même dans toutes les régions.
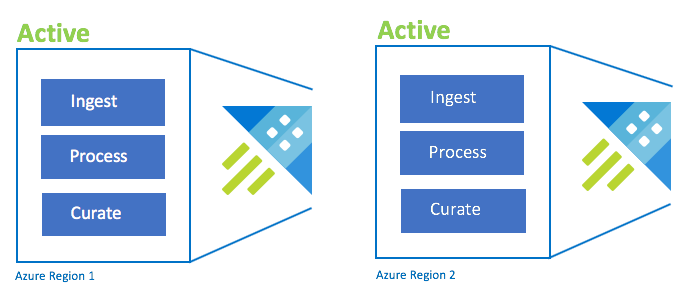
| Configuration | RPO | RTO | Effort | Coût |
|---|---|---|---|---|
| Active-Active | 0 heure | 0 heure | Moins grand | Élevé |
Configuration de secours active
La configuration de secours active est similaire à la configuration active-active en matière d’ingestion, de traitement et d’intégration en double. Bien que le cluster de secours soit en ligne pour l’ingestion, le processus et la curation, il n’est pas disponible pour l’interrogation. Le cluster de secours n’a pas besoin d’être dans la même référence SKU que le cluster principal. Il peut s’agir d’une référence SKU et d’une échelle plus petites, ce qui peut la rendre moins performante. Dans un scénario de sinistre, les utilisateurs sont redirigés vers le cluster de secours, qui peut éventuellement être mis à l’échelle pour augmenter les performances.
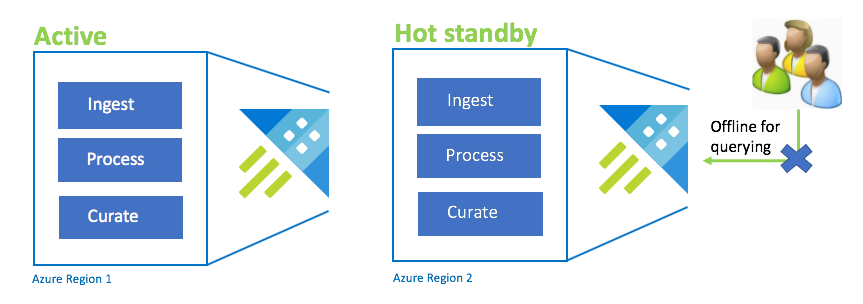
| Configuration | RPO | RTO | Effort | Coût |
|---|---|---|---|---|
| Configuration de secours active | 0 heure | Faible | Moyenne | Moyenne |
Configuration de la récupération des données à la demande
Cette solution offre le moins de résilience (RPO et RTO les plus élevés), son coût est moindre et l’effort nécessaire plus élevé. Dans cette configuration, il n’existe aucun cluster de récupération de données. Configurez l’exportation continue de données organisées (sauf si des données brutes et intermédiaires sont également requises) sur un compte de stockage configuré pour le stockage géoredondant (GRS). Un cluster de récupération de données est lancé s’il existe un scénario de récupération d’urgence. Dès lors, les DDL, la configuration, les stratégies et les processus sont appliqués. Les données sont ingérées à partir du stockage à l’aide de la propriété d’ingestion kustoCreationTime de manière à remplacer le délai d’ingestion par défaut par le délai du système.
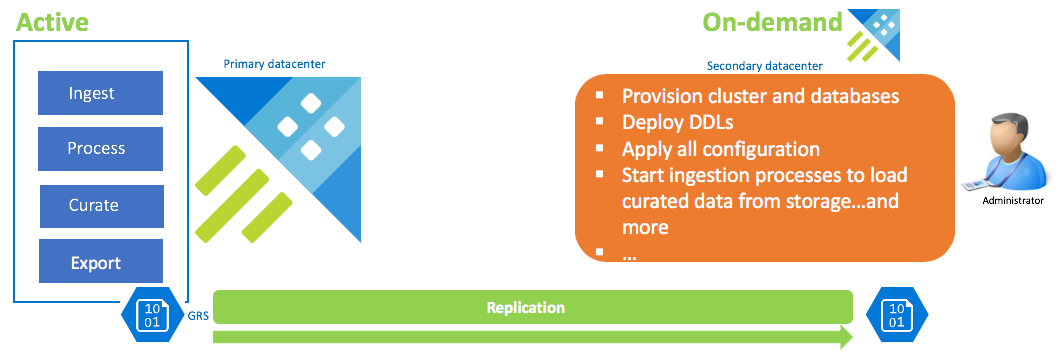
| Configuration | RPO | RTO | Effort | Coût |
|---|---|---|---|---|
| Cluster de récupération de données à la demande | Le plus élevé | Le plus élevé | Le plus élevé | Minimale |
Résumé des options de configuration de récupération d'urgence
| Configuration | Résilience | RPO | RTO | Effort | Coût |
|---|---|---|---|---|---|
| Active-Active-Active-n | Le plus élevé | 0 heure | 0 heure | Moins grand | Le plus élevé |
| Active-Active | Élevé | 0 heure | 0 heure | Moins grand | Élevé |
| Configuration de secours active | Moyenne | 0 heure | Faible | Moyenne | Moyenne |
| Cluster de récupération de données à la demande | Minimale | Le plus élevé | Le plus élevé | Le plus élevé | Minimale |
Meilleures pratiques
Quelle que soit la configuration de récupération d’urgence choisie, suivez les meilleures pratiques suivantes :
- Tous les objets de base de données, stratégies et configurations doivent être conservés dans le contrôle de code source de manière à pouvoir être utilisés dans le cluster à l’aide de votre outil d’automatisation de lancement. Pour plus d’informations, consultez Prise en charge d’Azure DevOps pour Azure Data Explorer.
- Concevez, développez et implémentez des routines de validation pour vous assurer que tous les clusters sont synchronisés en termes de données. Azure Data Explorer prend en charge les jointures entre clusters . Un simple nombre de lignes dans les tables peut faciliter la validation.
- Les procédures de mise en œuvre doivent impliquer des contrôles et des équilibrages de gouvernance afin de garantir la mise en miroir des clusters.
- Soignez pleinement informé des exigences liées à la création d’un cluster de bout en bout.
- Créez une liste de contrôle des unités de déploiement. Votre liste est propre vos besoins, mais doit inclure : scripts de déploiement, connexions d’ingestion, outils BI et autres configurations importantes.
Étape suivante
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour