Intégration et livraison continues dans Azure Data Factory
S’APPLIQUE À :  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
L’intégration continue consiste à tester automatiquement et, dès que possible, chaque modification apportée à votre code base. La livraison continue fait suite au test effectué pendant l’intégration continue, et envoie (push) les modifications à un système de préproduction ou de production.
Dans Azure Data Factory, l’intégration et la livraison continues (CI/CD) impliquent de déplacer des pipelines Data Factory d’un environnement (développement, test, production) vers un autre. Azure Data Factory utilise des modèles Azure Resource Manager pour stocker la configuration de vos diverses entités ADF (pipelines, jeux de données, flux de données, etc.). Deux méthodes sont recommandées pour promouvoir une fabrique de données dans un autre environnement :
- Déploiement automatisé grâce à l’intégration de Data Factory avec Azure Pipelines.
- Chargement manuel d’un modèle Resource Manager en tirant parti de l’intégration de l’expérience utilisateur de Data Factory avec Azure Resource Manager.
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Cycle de vie d’intégration et de livraison continues
Notes
Pour plus d’informations, consultez Améliorations en matière de déploiement continu.
Vous trouverez ci-dessous une vue d’ensemble du cycle de vie d’intégration et de livraison continues dans une fabrique de données Azure configurée avec Azure Repos Git. Pour plus d’informations sur la configuration d’un dépôt Git, consultez Contrôle de code source dans Azure Data Factory.
Une fabrique de données de développement est créée et configurée avec Azure Repos Git. Tous les développeurs doivent avoir l’autorisation de créer des ressources Data Factory telles que des pipelines et des jeux de données.
Un développeur crée une branche de fonctionnalité pour apporter une modification. Il débogue les exécutions de son pipeline avec ses modifications les plus récentes. Pour plus d’informations sur le débogage d’une exécution de pipeline, consultez Développement et débogage itératifs avec Azure Data Factory.
Une fois satisfait de ses modifications, le développeur crée une demande de tirage (pull) de sa branche de fonctionnalité vers la branche primaire ou la branche de collaboration pour que ces modifications soient examinées par des pairs.
Une fois la demande de tirage (pull) approuvée et les modifications fusionnées dans la branche primaire, les modifications sont publiées dans la fabrique de développement.
Lorsque l’équipe est prête à déployer les modifications dans une fabrique de test ou de test d’acceptation utilisateur (UAT), elle accède à la mise en production sur Azure Pipelines et déploie la version souhaitée de la fabrique de développement vers l’UAT. Ce déploiement a lieu dans le cadre d’une tâche Azure Pipelines et utilise des paramètres de modèle Resource Manager pour appliquer la configuration appropriée.
Une fois les modifications vérifiées dans la fabrique de test, opérez le déploiement vers la fabrique de production en utilisant la tâche suivante de la mise en production de pipelines.
Notes
Seule la fabrique de développement est associée à un dépôt Git. Les fabriques de test et de production ne doivent pas avoir de dépôt Git associé et ne doivent être mises à jour que via un pipeline Azure DevOps ou un modèle de gestion des ressources.
L’image ci-dessous met en évidence les différentes étapes de ce cycle de vie.
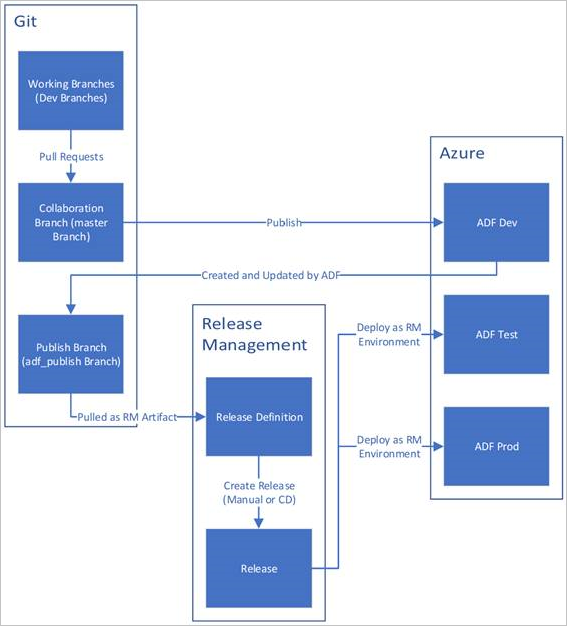
Meilleures pratiques pour CI/CD
Si vous utilisez une intégration Git avec votre fabrique de données, et disposez d’un pipeline CI/CD qui déplace vos modifications du développement aux tests, puis en production, nous vous recommandons les bonnes pratiques suivantes :
Intégration Git. Configurez uniquement votre fabrique de données de développement avec l’intégration Git. Les modifications au niveau des tests et de la production sont déployées via CI/CD et ne nécessitent pas d’intégration Git.
Script de pré-déploiement et de post-déploiement. Avant l’étape de déploiement Resource Manager dans CI/CD, vous devez effectuer certaines tâches, telles que l’arrêt et le redémarrage des déclencheurs, et le nettoyage. Nous vous recommandons d’utiliser des scripts PowerShell avant et après la tâche de déploiement. Pour plus d’informations, consultez Mettre à jour des déclencheurs actifs. L’équipe Data Factory a fourni un script à utiliser, qui se trouve en bas de cette page.
Notes
Utilisez le PrePostDeploymentScript.Ver2.ps1 si vous souhaitez désactiver/activer uniquement les déclencheurs qui ont été modifiés au lieu d’activer/désactiver tous les déclencheurs pendant CI/CD.
Avertissement
Veillez à utiliser PowerShell Core dans la tâche ADO pour exécuter le script
Avertissement
Si vous n’utilisez pas les dernières versions des modules PowerShell et Data Factory, vous risquez de rencontrer des erreurs de désérialisation lors de l’exécution des commandes.
Runtimes d’intégration et partage. Les runtimes d’intégration ne changent pas souvent et sont similaires dans toutes les phases de CI/CD. Ainsi, Data Factory s’attend à ce que vous ayez le même nom, le même type et le même sous-type de runtime d’intégration dans toutes les phases de CI/CD. Si vous voulez partager les runtimes d’intégration dans toutes les phases, envisagez d’utiliser une fabrique ternaire qui contiendra uniquement les runtimes d’intégration partagés. Vous pouvez utiliser cette fabrique partagée dans tous vos environnements en tant que type de runtime d’intégration lié.
Notes
Le partage du runtime d’intégration est disponible uniquement pour les runtimes d’intégration auto-hébergés. Les runtimes d’intégration Azure SSIS ne prennent pas en charge le partage.
Déploiement du point de terminaison privé managé. Si un point de terminaison privé existe déjà dans une fabrique et que vous essayez de déployer un modèle ARM qui contient un point de terminaison privé portant le même nom mais dont les propriétés sont modifiées, le déploiement échoue. En d’autres termes, vous pouvez déployer avec succès un point de terminaison privé, à condition qu’il ait les mêmes propriétés que celui qui existe déjà dans la fabrique. Si une propriété est différente d’un environnement à un autre, vous pouvez la remplacer en paramétrant cette propriété et en fournissant la valeur correspondante pendant le déploiement.
Key Vault. Lorsque vous utilisez des services liés dont les informations de connexion sont stockées dans Azure Key Vault, il est recommandé de conserver des coffres de clés distincts pour les différents environnements. Vous pouvez également configurer des niveaux d’autorisation distincts pour chaque coffre de clés. Par exemple, vous ne souhaitez peut-être pas que les membres de votre équipe disposent d’autorisations sur les secrets de production. Si vous suivez cette approche, nous vous recommandons de conserver les mêmes noms de secrets dans toutes les phases. Si vous conservez les mêmes noms secrets, vous n’avez pas besoin de paramétrer chaque chaîne de connexion dans les environnements d’intégration et de livraison continues, car la seule chose qui change est le nom du coffre de clés, qui est un paramètre distinct.
Nommage des ressources. En raison de contraintes liées au modèle ARM, des problèmes de déploiement peuvent survenir si le nom de vos ressources contient des espaces. L’équipe Azure Data Factory recommande d’utiliser des caractères « _ » ou « - » au lieu d’espaces dans les noms de ressources. Par exemple, le nom « Pipeline_1 » est préférable à « Pipeline 1 ».
Modification du dépôt. ADF gère automatiquement le contenu du référentiel GIT. La modification ou l’ajout manuel de fichiers ou de dossiers non liés dans n’importe où dans le dossier de données du référentiel Git ADF peut entraîner des erreurs de chargement des ressources. Par exemple, la présence de fichiers .bak peut provoquer une erreur CI/CD ADF. Ils doivent donc être supprimés pour que ADF soit chargé.
Indicateurs de contrôle d’exposition et de fonctionnalité. Quand vous travaillez en équipe, il peut arriver que vous souhaitiez fusionner des modifications sans les exécuter dans des environnements élevés tels que PROD et QA. Pour gérer un tel scénario, l’équipe ADF recommande le concept DevOps utilisant les indicateurs de fonctionnalité. Dans ADF, vous pouvez combiner les paramètres globaux et l’activité IfCondition pour masquer des ensembles de logique en fonction de ces indicateurs d’environnement.
Pour savoir comment configurer un indicateur de fonctionnalité, consultez le tutoriel vidéo ci-dessous :
Fonctionnalités non prises en charge
Par conception, Data Factory n’autorise pas le cherry-picking des validations ni la publication sélective des ressources. Les publications incluent toutes les modifications apportées dans la fabrique de données.
- Les entités Data Factory dépendent les unes des autres. Par exemple, les déclencheurs dépendent des pipelines et les pipelines dépendent des jeux de données et d’autres pipelines. La publication sélective d’un sous-ensemble de ressources peut engendrer des comportements inattendus et des erreurs.
- Dans les rares cas où vous avez besoin d’une publication sélective, envisagez d’utiliser un correctif logiciel. Pour plus d’informations, consultez Environnement de production de correctif logiciel.
L’équipe Azure Data Factory ne recommande pas d’attribuer des contrôles Azure RBAC à des entités individuelles (pipelines, jeux de données, etc.) dans une fabrique de données. Par exemple, si un développeur a accès à un pipeline ou à un jeu de données, il doit être en mesure d’accéder à tous les pipelines ou jeux de données de la fabrique de données. Si vous estimez que vous devez implémenter de nombreux rôles Azure dans une fabrique de données, envisagez de déployer une deuxième fabrique de données.
Vous ne pouvez pas publier à partir de branches privées.
Vous ne pouvez actuellement pas héberger de projets sur Bitbucket.
Vous ne pouvez pas exporter et importer actuellement des alertes et des matrices en tant que paramètres.
Depuis le 1er novembre 2021, les modèles ARM partiels de votre branche de publication ne sont plus pris en charge. Si votre projet utilise cette fonctionnalité, veuillez passer à un mécanisme pris en charge pour les déploiements à l’aide de fichiers :
ARMTemplateForFactory.jsonoulinkedTemplates.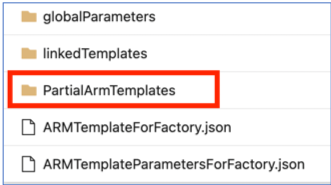
Contenu connexe
- Améliorations du déploiement continu
- Automatiser l’intégration continue à l’aide des versions d’Azure Pipelines
- Promouvoir manuellement un modèle Resource Manager pour chaque environnement
- Utiliser des paramètres personnalisés avec un modèle Resource Manager
- Modèles Resource Manager liés
- Utilisation d’un environnement de production de correctif logiciel
- Exemple de script de pré-déploiement et de post-déploiement