Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
La transformation d’agrégation définit des agrégations de colonnes dans vos flux de données. À l’aide du Générateur d’expressions, vous pouvez définir différents types d’agrégations telles que SUM, MIN, MAX et COUNT regroupées par colonnes calculées ou existantes.
Regrouper par
Sélectionnez une colonne existante ou créez une colonne calculée à utiliser en tant que groupe par la clause de votre agrégation. Pour utiliser une colonne existante, sélectionnez-la dans la liste déroulante. Pour créer une colonne calculée, placez le curseur sur la clause et cliquez sur Colonne calculée. Cela ouvre le générateur d’expressions de flux de données. Une fois que vous avez créé votre colonne calculée, entrez le nom de colonne de sortie dans le champ Name as (Nommer sous). Si vous souhaitez ajouter un groupe supplémentaire par clause, placez le curseur sur une clause existante, puis cliquez sur l’icône plus.
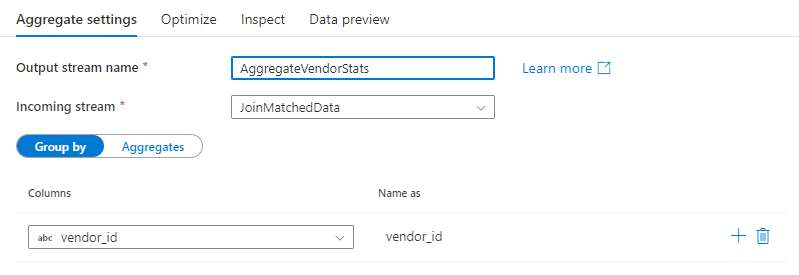
Un groupe par clause est facultatif dans une transformation d’agrégation.
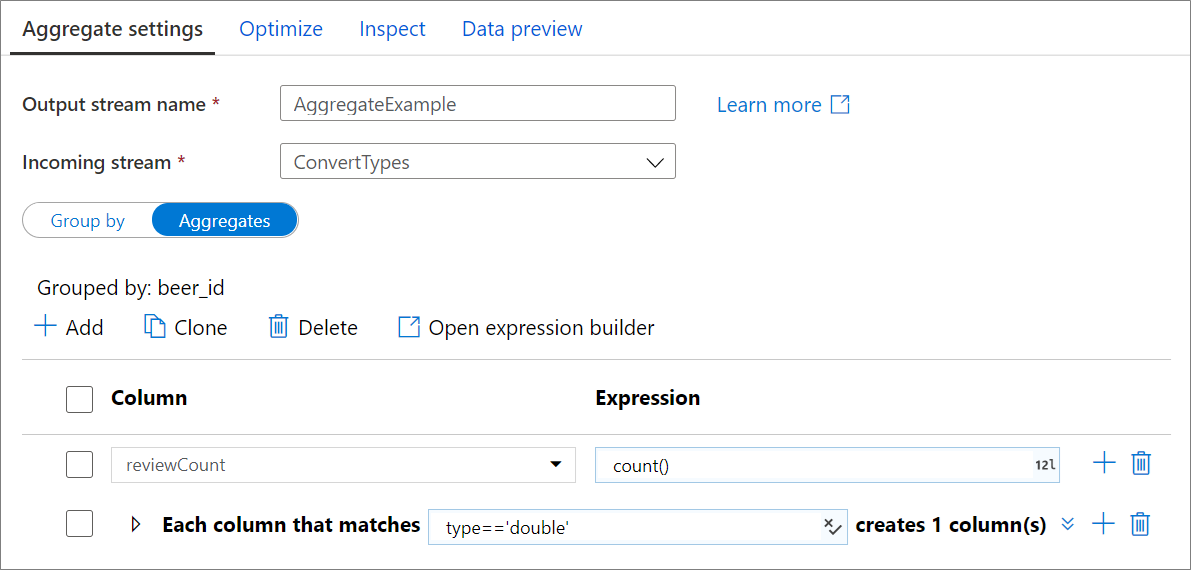
Colonnes d’agrégation
Accédez à l’onglet Agrégations pour créer des expressions d’agrégation. Vous pouvez soit remplacer une colonne existante par une agrégation, soit créer un nouveau champ avec un nouveau nom. L’expression d’agrégation est entrée dans la zone de droite en regard du sélecteur de nom de colonne. Pour modifier l’expression, cliquez sur la zone de texte pour ouvrir le Générateur d’expressions. Pour ajouter des colonnes d’agrégation, cliquez sur Ajouter au-dessus de la liste des colonnes ou de l’icône « plus » en regard d’une colonne d’agrégation existante. Choisissez Ajouter une colonne ou Ajouter un modèle de colonne. Chaque expression d’agrégation doit contenir au moins une fonction d’agrégation.
Notes
En mode Débogage, le Générateur d’expressions ne peut pas produire d’aperçus de données avec des fonctions d’agrégation. Pour afficher des aperçus de données pour les transformations d’agrégation, fermez le Générateur d’expressions et affichez les données via l’onglet Aperçu des données.
Modèles de colonne
Utilisez des modèles de colonne pour appliquer la même agrégation à un ensemble de colonnes. Cela est utile si vous souhaitez conserver de nombreuses colonnes du schéma d’entrée, car elles sont supprimées par défaut. Utilisez une méthode heuristique telle que first() pour conserver les colonnes d’entrée à l’aide de l’agrégation.
Reconnecter les lignes et les colonnes
Les transformations d’agrégation sont similaires aux requêtes SQL Aggregate Select. Les colonnes qui ne sont pas incluses dans la clause Regrouper par ou les fonctions d’agrégation ne sont pas transmises à la sortie de votre transformation d’agrégation. Si vous souhaitez inclure d’autres colonnes dans votre sortie agrégée, effectuez l’une des méthodes suivantes :
- Utilisez une fonction d’agrégation telle que
last()oufirst()pour inclure cette colonne supplémentaire. - Rattachez les colonnes à votre flux de sortie à l’aide du modèle de jointure réflexive.
Suppression de lignes en double
Une utilisation courante de la transformation d’agrégation consiste à supprimer ou à identifier les entrées en double dans les données sources. Ce processus est appelé déduplication. Sur la base d’un ensemble de clés Grouper par, utilisez l’euristique de votre choix pour déterminer la ligne dupliquée à conserver. Les euristiques courantes sont first(), last(), max() et min(). Utilisez les modèles de colonne pour appliquer la règle à chaque colonne, à l’exception des colonnes Grouper par.
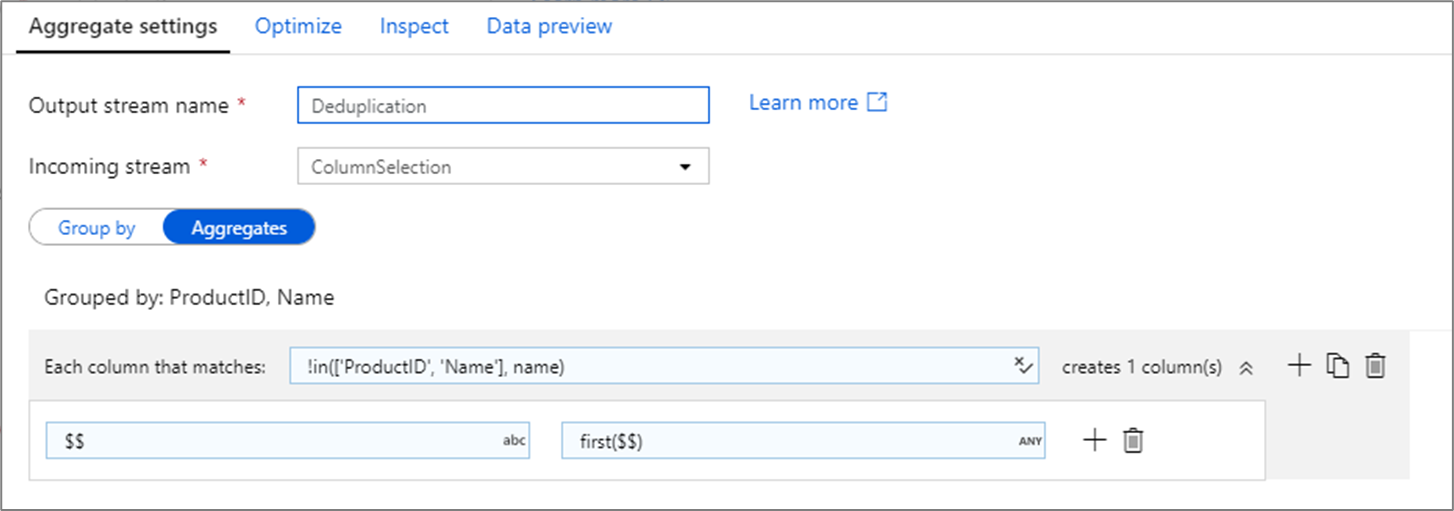
Dans l’exemple ci-dessus, les colonnes ProductID et Name sont utilisées pour le regroupement. Si deux lignes ont les mêmes valeurs pour ces deux colonnes, elles sont considérées comme des doublons. Dans cette transformation d’agrégation, les valeurs de la première ligne correspondante sont conservées et toutes les autres sont supprimées. À l’aide de la syntaxe du modèle de colonne, toutes les colonnes dont les noms ne sont pas ProductID et Name sont mappées à leur nom de colonne existant et reçoivent la valeur des premières lignes correspondantes. Le schéma de sortie est le même que le schéma d’entrée.
Pour les scénarios de validation des données, la fonction count() peut être utilisée pour compter le nombre de doublons.
Script de flux de données
Syntaxe
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Exemple
L’exemple ci-dessous prend un flux entrant MoviesYear et regroupe les lignes par colonne year. La transformation crée une colonne d’agrégation avgrating qui correspond à la moyenne de la colonne Rating. Cette transformation d’agrégation est nommée AvgComedyRatingsByYear.
Dans l’IU, cette transformation se présente comme dans l’image ci-dessous :
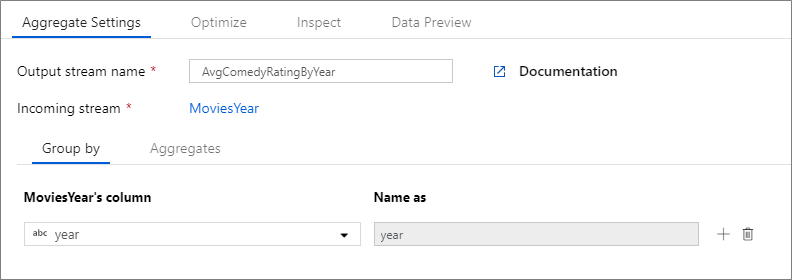
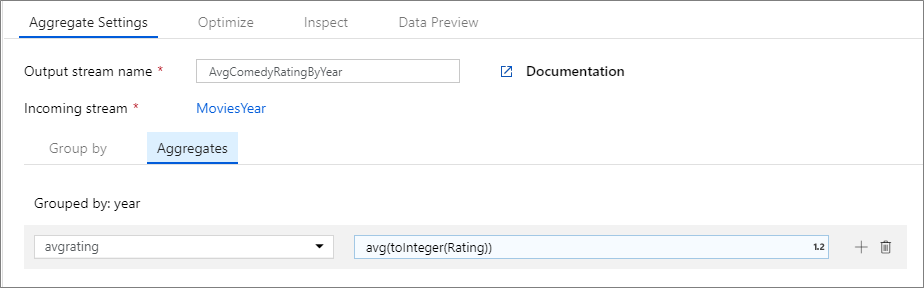
Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
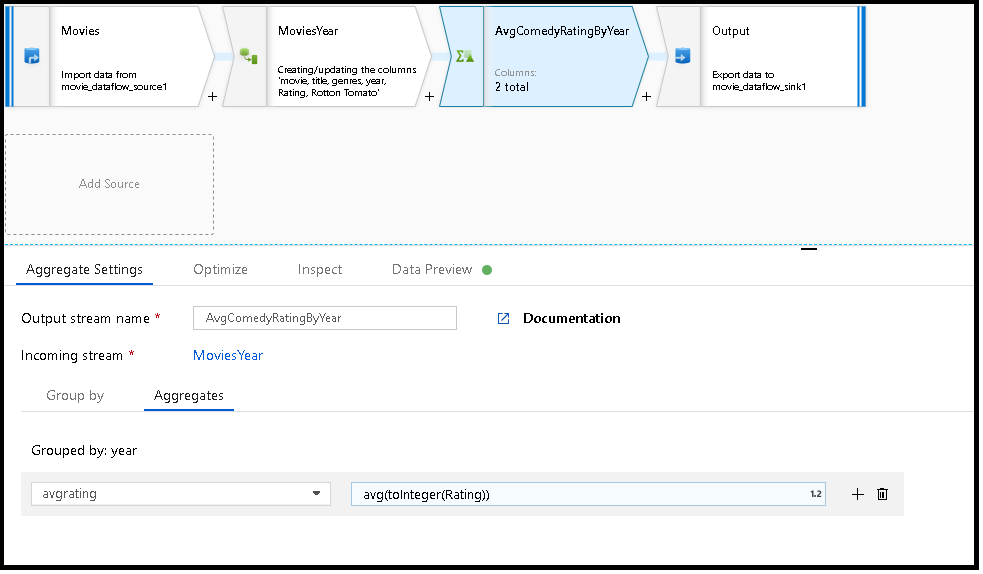
MoviesYear: Colonne dérivée définissant les colonnes Year et Title AvgComedyRatingByYear : Transformation d’agrégation pour l’évaluation moyenne de comédies regroupées par année avgrating : Nom de la colonne créée pour contenir la valeur agrégée
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Contenu connexe
- Définir l’agrégation en fonction d’une fenêtre à l’aide de la transformation Fenêtre