Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Les flux de données sont disponibles dans les pipelines Azure Data Factory et les pipelines Azure Synapse Analytics. Cet article s’applique aux flux de données de mappage. Si vous débutez avec les transformations, reportez-vous à l’article d’introduction Transformer des données à l’aide de flux de données de mappage.
Utilisez une transformation de sélection pour renommer, supprimer ou réorganiser les colonnes. Cette transformation ne modifie pas les données de ligne, mais choisit les colonnes qui sont propagées en aval.
Dans une transformation de sélection, les utilisateurs peuvent spécifier des mappages fixes, utiliser des modèles pour effectuer un mappage basé sur des règles ou activer le mappage automatique. Les mappages fixes et basés sur des règles peuvent être utilisés dans la même transformation de sélection. Si une colonne ne correspond pas à l’un des mappages définis, elle est supprimée.
Mappage fixe
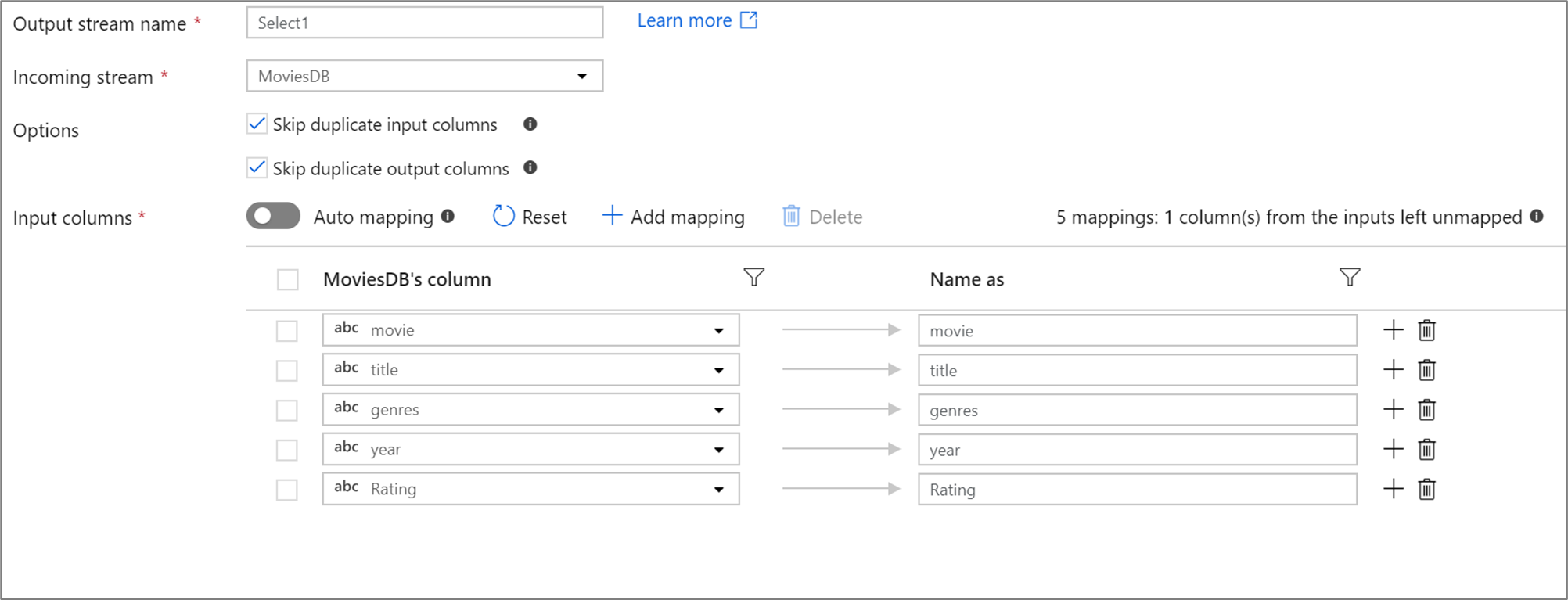
S’il y a moins de 50 colonnes définies dans votre projection, toutes les colonnes définies ont un mappage fixe par défaut. Un mappage fixe prend une colonne entrante définie et la mappe à un nom exact.
Note
Vous ne pouvez pas mapper ou renommer une colonne dérivée à l’aide d’un mappage fixe
Mappage de colonnes hiérarchiques
Les mappages fixes peuvent être utilisés pour mapper une sous-colonne d’une colonne hiérarchique à une colonne de niveau supérieur. Si vous avez une hiérarchie définie, utilisez la liste déroulante de la colonne pour sélectionner une sous-colonne. La transformation de sélection va créer une nouvelle colonne avec la valeur et le type de données de la sous-colonne.
Mappage basé sur des règles
Si vous voulez mapper plusieurs colonnes à la fois ou passer des colonnes dérivées en aval, utilisez un mappage basé sur des règles pour définir vos mappages à l’aide de modèles de colonne. Correspondance basée sur les valeurs name, type, stream et position de colonnes. Vous pouvez réaliser n’importe quelle combinaison de mappage fixe et basé sur des règles. Par défaut, toutes les projections contenant plus de 50 colonnes ont comme valeur par défaut un mappage basé sur des règles qui correspond à chaque colonne et génère le nom entré.
Pour ajouter un mappage basé sur les règles, cliquez sur Ajouter un mappage et sélectionnez Mappage basé sur les règles.

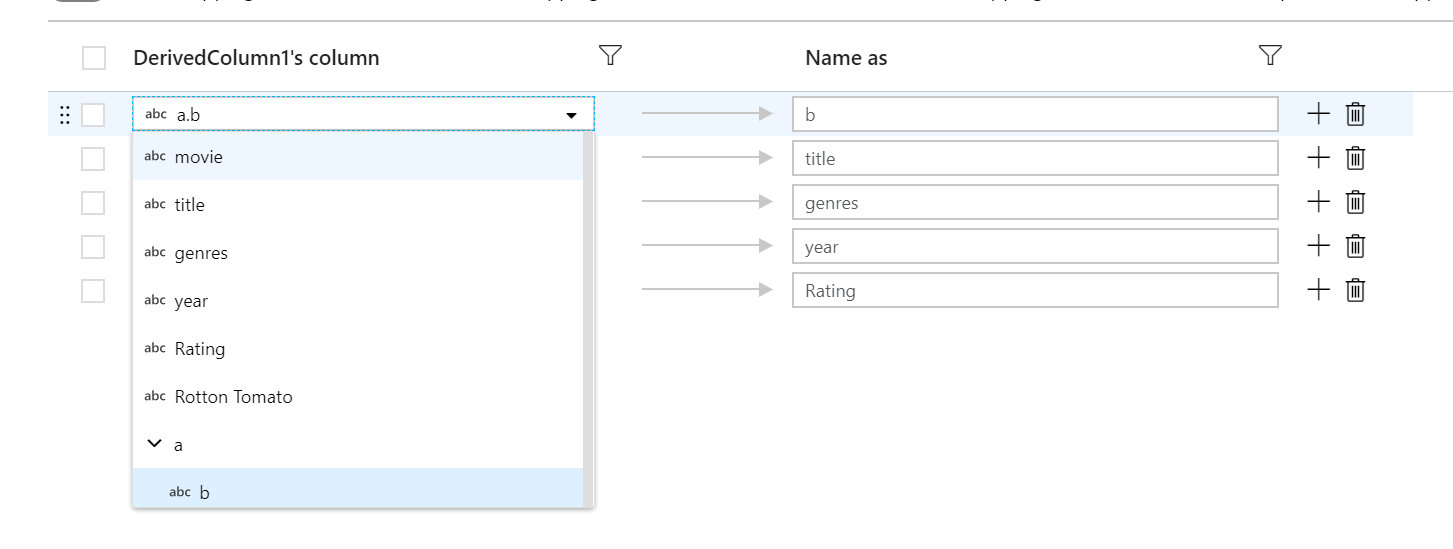
Chaque mappage basé sur des règles nécessite deux entrées : la condition à rechercher et le nom de chaque colonne mappée. Les deux valeurs sont entrées par l’intermédiaire du générateur d’expressions. Dans la zone d’expression de gauche, entrez votre condition de correspondance booléenne. Dans la zone d’expression de droite, indiquez ce à quoi la colonne correspondante sera mappée.

Utilisez la syntaxe $$ pour référencer le nom d’entrée d’une colonne correspondante. Prenons l’image ci-dessus comme exemple et imaginons qu’un utilisateur souhaite faire correspondre toutes les colonnes de chaîne dont les noms ont moins de six caractères. Si une colonne entrante a été nommée test, l’expression $$ + '_short' renomme la colonne en test_short. Si c’est le seul mappage qui existe, toutes les colonnes qui ne répondent pas à la condition sont supprimées des données générées.
Les modèles correspondent à la fois aux colonnes dérivées et définies. Pour voir les colonnes définies qui sont mappées par une règle, cliquez sur l’icône de lunettes à côté de la règle. Vérifiez votre sortie à l’aide de l’aperçu des données.
Mappage Regex
Si vous cliquez sur l’icône du chevron pointant vers le bas, vous pouvez spécifier une condition de mappage regex. Une condition de mappage regex correspond à tous les noms de colonne qui correspondent à la condition regex spécifiée. Elle peut être utilisée en association avec les mappages standard basés sur des règles.

L’exemple ci-dessus correspond au modèle regex (r) ou à tout nom de colonne qui contient un r minuscule. À l’instar du mappage standard basé sur des règles, toutes les colonnes correspondantes sont modifiées par la condition à droite à l’aide de la syntaxe $$.
Si vous avez plusieurs correspondances regex dans votre nom de colonne, vous pouvez référencer des correspondances spécifiques à l’aide de $n, où « n » référence le numéro de la correspondance. Par exemple, « $2 » référence à la deuxième correspondance dans un nom de colonne.
Hiérarchies basées sur des règles
Si votre projection définie a une hiérarchie, vous pouvez utiliser le mappage basé sur des règles pour mapper les sous-colonnes de hiérarchies. Spécifiez une condition de correspondance et la colonne complexe dont vous souhaitez mapper les sous-colonnes. Chaque sous-colonne correspondante est générée à l’aide de la règle « Nommer » spécifiée à droite.
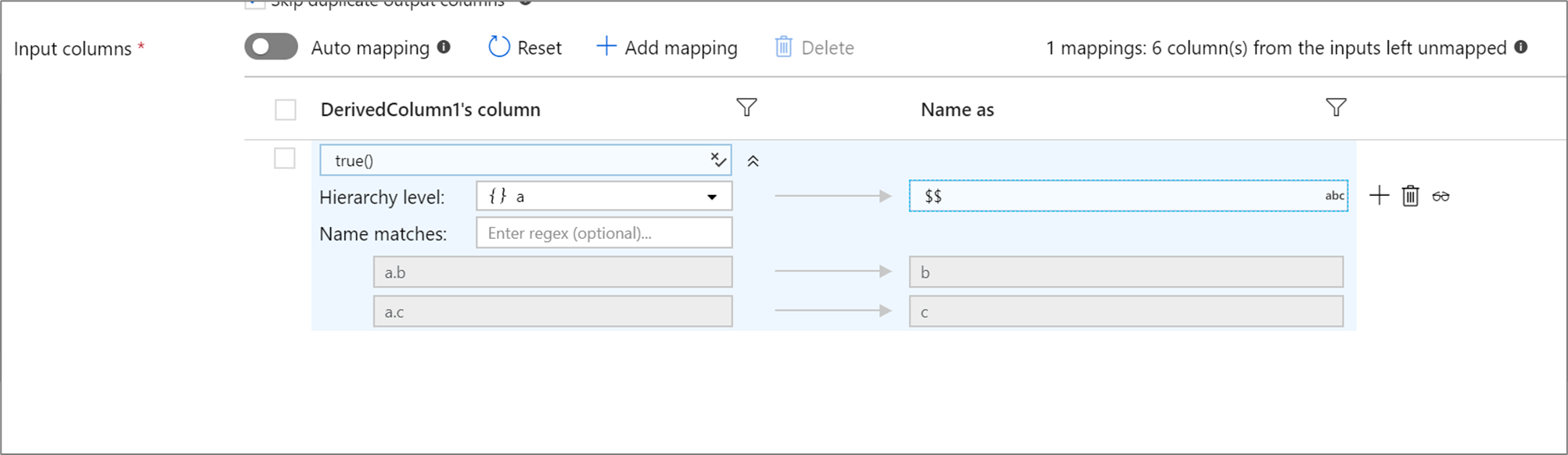
L’exemple ci-dessus correspond à toutes les sous-colonnes de la colonne complexe a.
a contient deux sous-colonnes b et c. Le schéma de sortie inclut deux colonnes b et c, car la condition « Nommer » est $$.
Paramétrage
Vous pouvez paramétrer des noms de colonne à l’aide d’un mappage basé sur des règles. Utilisez le mot clé name pour faire correspondre les noms de colonne entrants à un paramètre. Par exemple, si vous avez un paramètre de flux de données mycolumn, vous pouvez créer une règle qui correspond à tous les noms de colonne égaux à mycolumn. Vous pouvez renommer la colonne correspondante en chaîne codée en dur, par exemple, « clé métier » et la référencer explicitement. Dans cet exemple, la condition de correspondance est name == $mycolumn et la condition de nom est « clé métier ».
Mappage automatique
Quand vous ajoutez une transformation de sélection, vous pouvez activer le mappage automatique en basculant le curseur de mappage automatique. Avec le mappage automatique, la transformation de sélection mappe toutes les colonnes entrantes, à l’exception des doublons, au même nom que leur entrée. Il s’agit notamment des colonnes dérivées, ce qui signifie que les données de sortie peuvent contenir des colonnes non définies dans votre schéma. Pour plus d’informations sur les colonnes dérivées, consultez Dérive de schéma.
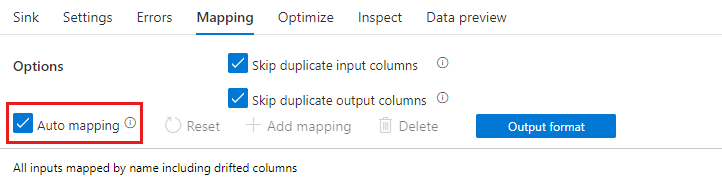
Si le mappage automatique est activé, la transformation de sélection respecte les paramètres indiquant d’ignorer les doublons et fournit un nouvel alias pour les colonnes existantes. L’utilisation d’alias est utile quand vous effectuez plusieurs jointures ou recherches sur le même flux et dans les scénarios d’auto-jointure.
Colonnes dupliquées
Par défaut, la transformation de sélection supprime les colonnes en double dans la projection d’entrée et de sortie. Les colonnes d'entrée dupliquées proviennent souvent des transformations de jointure et de recherche, où les noms de colonnes sont dupliqués de chaque côté de la jointure. Les colonnes de sortie en double peuvent se produire si vous mappez deux colonnes d’entrée différentes au même nom. Indiquez si vous souhaitez supprimer ou conserver les colonnes en double en utilisant la case à cocher.
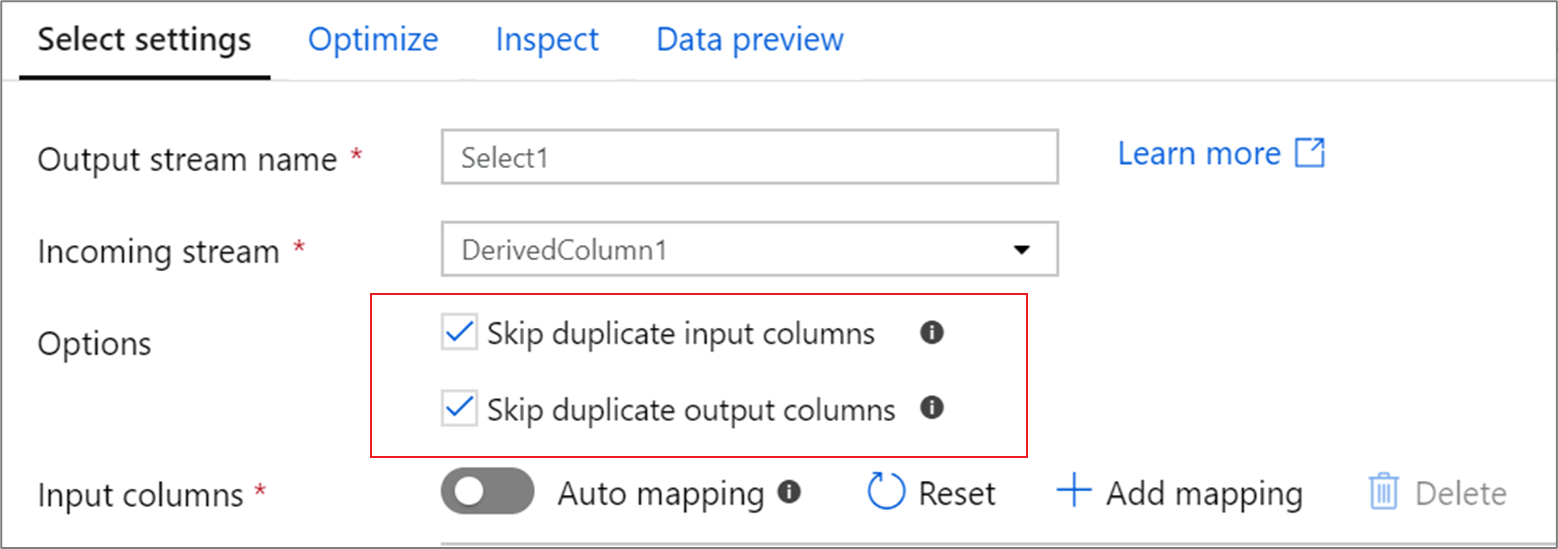
Classement des colonnes
L’ordre des mappages détermine l’ordre des colonnes de sortie. Si une colonne d’entrée est mappée plusieurs fois, seul le premier mappage est respecté. Pour toute suppression de colonne en double, la première correspondance est conservée.
Script de flux de données
Syntaxe
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Exemple
Voici un exemple de mappage de sélection et son script de flux de données :
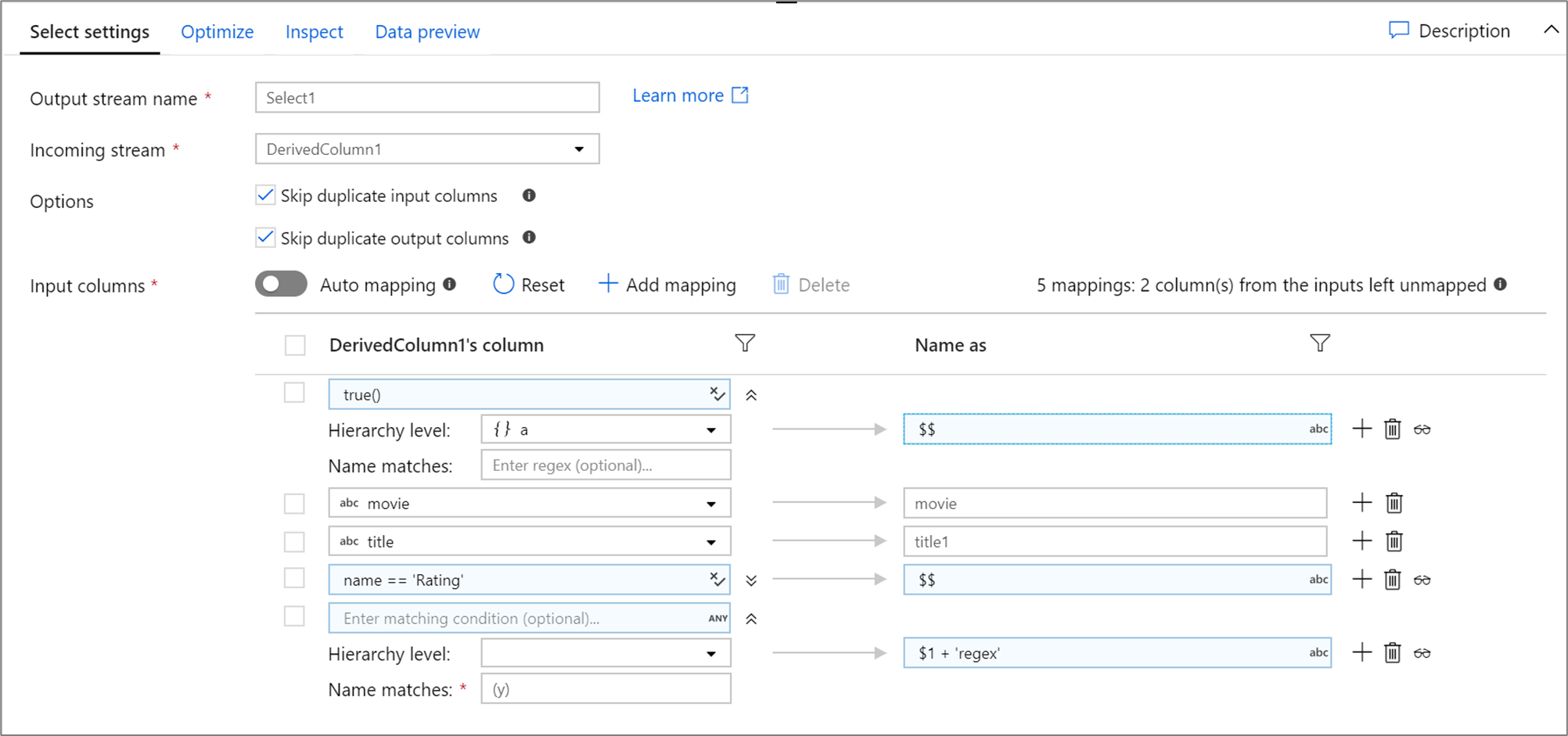
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Contenu connexe
- Après l’utilisation de Select pour renommer, réorganiser et attribuer des alias aux colonnes, utilisez la transformation Sink pour placer vos données dans un entrepôt de données.