Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explore les méthodes de résolution des problèmes liés aux connecteurs et à la mise en forme pour les flux de données de mappage dans Azure Data Factory (ADF).
Stockage Blob Azure
Le type de compte de stockage (v1 universel) ne prend pas en charge l’authentification par principal de service et par identité managée
Symptômes
Dans les flux de données, si vous utilisez Stockage Blob Azure (v1 usage général) avec l’authentification par principal de service ou par identité managée, vous pouvez rencontrer le message d’erreur suivant :
com.microsoft.dataflow.broker.InvalidOperationException: ServicePrincipal and MI auth are not supported if blob storage kind is Storage (general purpose v1)
La cause
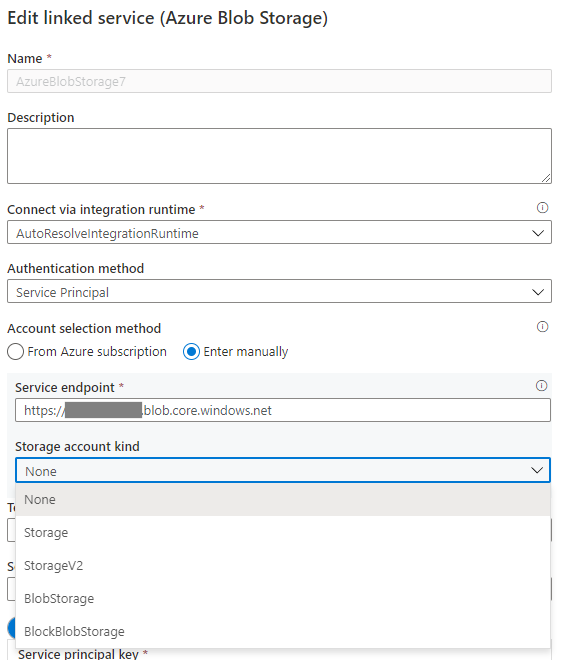
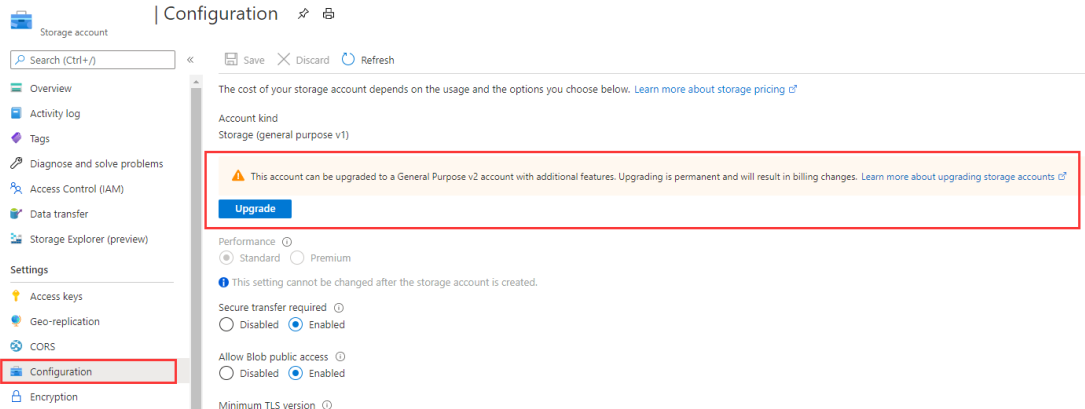
Lorsque vous utilisez le service lié Blob Azure dans un flux de données, l’authentification par identité managée ou par principal de service n’est pas prise en charge lorsque le type de compte est vide ou Stockage. Cette situation est illustrée dans les images 1 et 2 ci-dessous.
Image 1 : Type de compte dans le service lié Stockage Blob Azure

Image 2 : Page du compte de stockage

Recommandation
Pour résoudre ce problème, suivez les recommandations suivantes :
Si le type de compte de stockage est Aucun dans le service lié Blob Azure, spécifiez le type de compte approprié et reportez-vous à l’image 3 ci-dessous pour le faire. En outre, reportez-vous à l’image 2 pour obtenir le type de compte de stockage, puis vérifiez et confirmez que le type de compte n’est pas Stockage (v1 usage général).
Image 3 : Spécifier le type de compte de stockage dans le service lié Stockage Blob Azure
Si le type de compte est « Stockage (v1 universel) », mettez à niveau votre compte de stockage vers v2 universel ou choisissez une authentification différente.
Image 4 : Mettre à niveau le compte de stockage vers v2 universel

Format Azure Cosmos DB et JSON
Prendre en charge les schémas personnalisés dans la source
Symptômes
Lorsque vous souhaitez utiliser le flux de données ADF pour déplacer ou transférer des données à partir d’Azure Cosmos DB/JSON vers d’autres magasins de données, certaines colonnes des données sources peuvent être ignorées.
La cause
Pour les connecteurs sans schéma (le numéro de colonne, le nom de colonne et le type de données de colonne de chaque ligne peuvent être différents lors de la comparaison avec d’autres), par défaut, ADF utilise un échantillon de lignes (par exemple les données des 100 ou 1 000 premières lignes) pour déduire le schéma, et le résultat déduit est utilisé comme schéma pour lire les données. Par conséquent, si vos magasins de données ont des colonnes supplémentaires qui n’apparaissent pas dans les échantillons de lignes, les données de ces colonnes supplémentaires ne sont pas lues, déplacées ou transférées dans les magasins de données du récepteur.
Recommandation
Pour remplacer le comportement par défaut et importer d’autres champs, ADF fournit des options pour vous permettre de personnaliser le schéma source. Vous pouvez spécifier des colonnes supplémentaires/ignorées qui peuvent être manquantes dans le résultat déduit du schéma dans la projection source du flux de données afin de lire les données, et vous pouvez appliquer l’une des options suivantes pour définir le schéma personnalisé. En règle générale, l’option 1 est préférable.
Option 1 : comparé aux données sources d’origine qui peuvent être un fichier, une table ou un conteneur volumineux contenant des millions de lignes avec des schémas complexes, vous pouvez créer une table/conteneur temporaire avec quelques lignes qui contiennent toutes les colonnes que vous souhaitez lire, puis passer à l’opération suivante :
Utilisez les paramètres de débogage de la source de flux de données pour effectuer une projection d’importation avec des exemples de fichiers/tables afin d’obtenir le schéma complet. Vous pouvez suivre les étapes décrites dans l’image suivante :
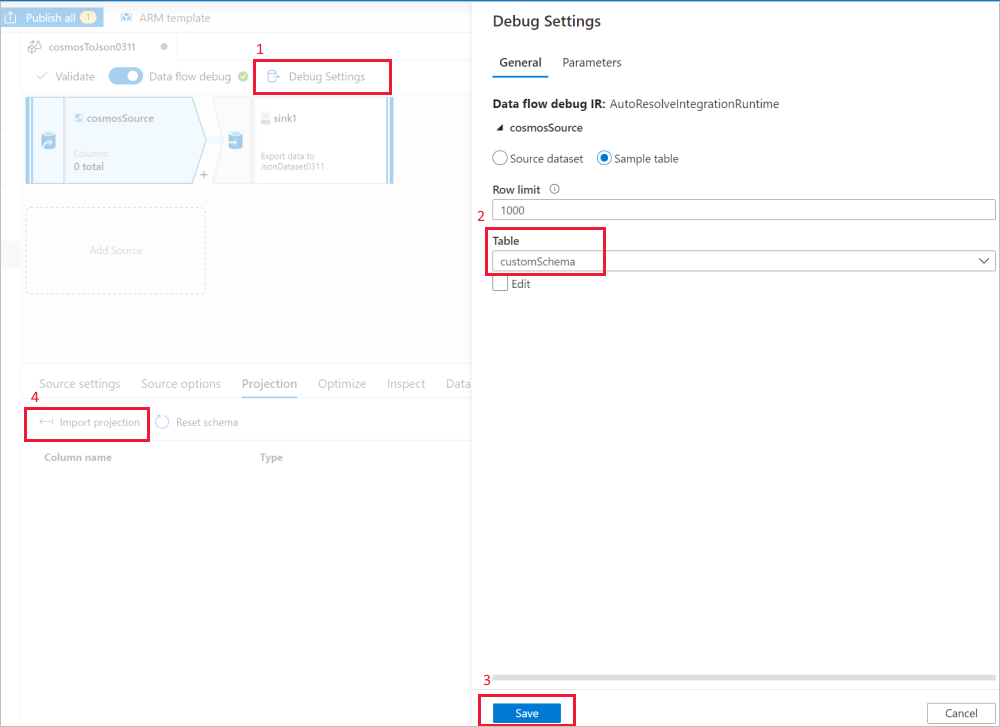
- Sélectionnez Paramètres de débogage dans le canevas du flux de données.
- Dans le volet contextuel, sélectionnez Exemple de table sous l’onglet cosmosSource, puis entrez le nom de votre table dans le bloc Table.
- Sélectionnez Save (Enregistrer) pour enregistrer vos paramètres.
- Sélectionnez Importer la projection.
Remodifiez les paramètres de débogage de façon à utiliser le jeu de données source pour le déplacement/la transformation des données restantes. Vous pouvez passer à la procédure indiquée dans l’image suivante :
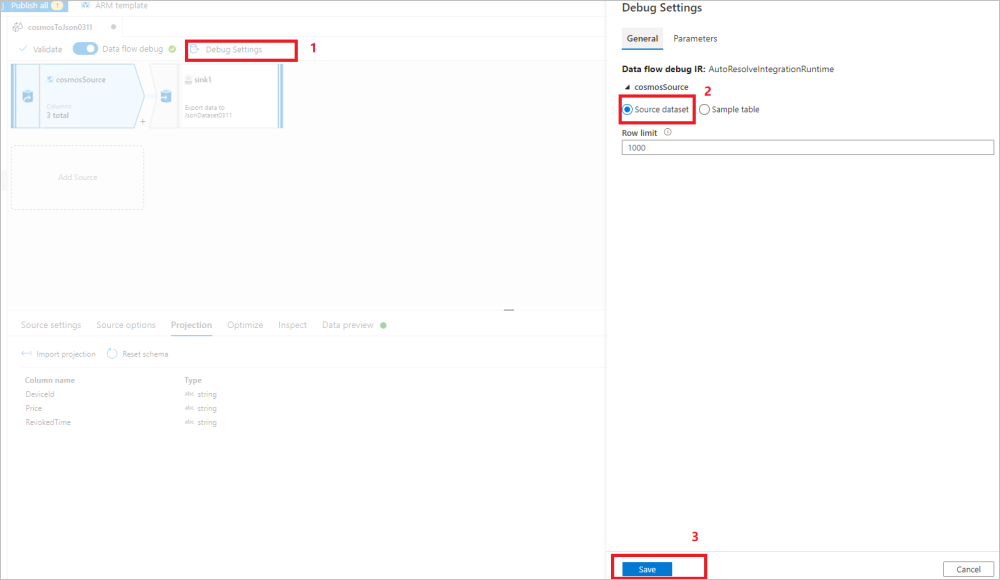
- Sélectionnez Paramètres de débogage dans le canevas du flux de données.
- Dans le volet contextuel, sélectionnez Jeu de données source sous l’onglet cosmosSource.
- Sélectionnez Save (Enregistrer) pour enregistrer vos paramètres.
Par la suite, le runtime de flux de données ADF honorera et utilisera le schéma personnalisé pour lire les données à partir du magasin de données d’origine.
Option 2 : si vous connaissez le schéma et le langage DSL des données sources, vous pouvez mettre à jour manuellement le script source du flux de données afin d’ajouter des colonnes supplémentaires/ignorées pour lire les données. Un exemple est présenté dans l’image suivante :
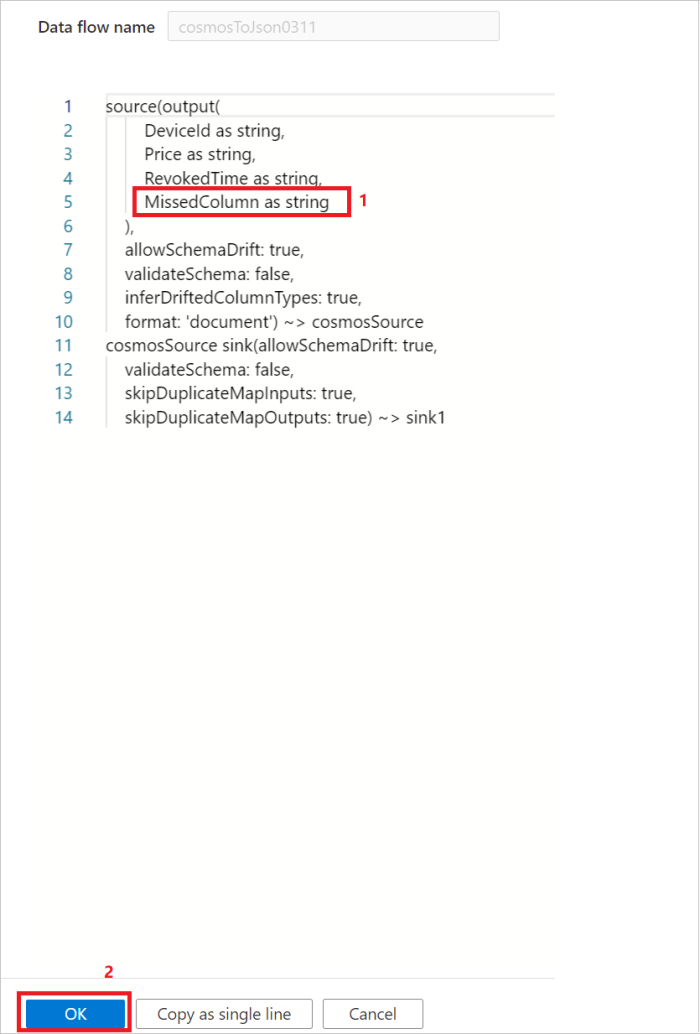
Prise en charge du type carte dans la source
Symptômes
Dans les flux de données ADF, le type de données de mappage ne peut pas être pris en charge directement dans la source Azure Cosmos DB ou JSON. Vous ne pouvez donc pas obtenir ce type de données sous « Importer la projection ».
La cause
Pour Azure Cosmos DB et JSON, il s’agit d’une connectivité sans schéma et le connecteur Spark associé utilise des exemples de données pour déduire le schéma, puis ce schéma est utilisé comme schéma de la source Azure Cosmos DB/JSON. Lors de la déduction du schéma, le connecteur Spark d’Azure Cosmos DB/JSON peut seulement déduire les données d’objet comme un struct plutôt qu’un type de données de mappage, et c’est pourquoi le type de mappage ne peut pas être directement pris en charge.
Recommandation
Pour résoudre ce problème, reportez-vous aux exemples et aux étapes ci-dessous pour mettre à jour manuellement le script (DSL) de la source Azure Cosmos DB/JSON afin d’obtenir le support du type de données « carte ».
Exemples :

Étape 1 : Ouvrez le script de l’activité de flux de données.
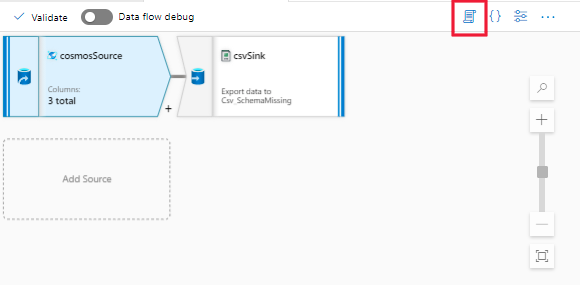
Étape 2 : Mettez à jour le script DSL pour obtenir la prise en charge du type carte en vous référant aux exemples ci-dessus.
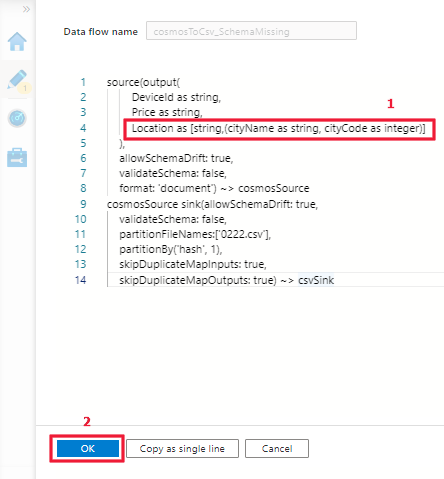
Le type carte prend en charge :
| Catégorie | Le type carte est-il pris en charge ? | Commentaires |
|---|---|---|
| Excel, CSV | Non | Les deux sont des sources de données tabulaires avec le type primitif. Il n’est donc pas nécessaire de prendre en charge le type de mappage. |
| Orc, Avro | Oui | Aucun. |
| JSON | Oui | Le type de mappage ne peut pas être directement pris en charge. Suivez la partie de cette section relative aux recommandations pour mettre à jour le script (DSL) sous la projection source. |
| Base de données Azure Cosmos DB | Oui | Le type de mappage ne peut pas être directement pris en charge. Suivez la partie de cette section relative aux recommandations pour mettre à jour le script (DSL) sous la projection source. |
| Parquet | Oui | À l’heure actuelle, le type de données complexe n’est pas pris en charge sur le jeu de données Parquet. Vous devez donc utiliser l’option « Importer la projection » sous la source Parquet du flux de données pour obtenir le type de mappage. |
| XML | Non | Aucun. |
Consommer les fichiers JSON générés par les activités de copie
Symptômes
Si vous utilisez l’activité de copie pour générer des fichiers JSON, puis essayez de lire ces fichiers dans des flux de données, vous échouez avec le message d’erreur suivant : JSON parsing error, unsupported encoding or multiline.
La cause
Les limitations suivantes s’appliquent à JSON pour les copies et les flux de données respectivement :
Pour les fichiers JSON encodés en Unicode (UTF-8, UTF-16, UTF-32), les activités de copie génèrent toujours les fichiers JSON avec une marque d’ordre d’octet.
La source JSON du flux de données avec l’option « Document individuel » activée ne prend pas en charge l’encodage Unicode avec marque d’ordre d’octet.
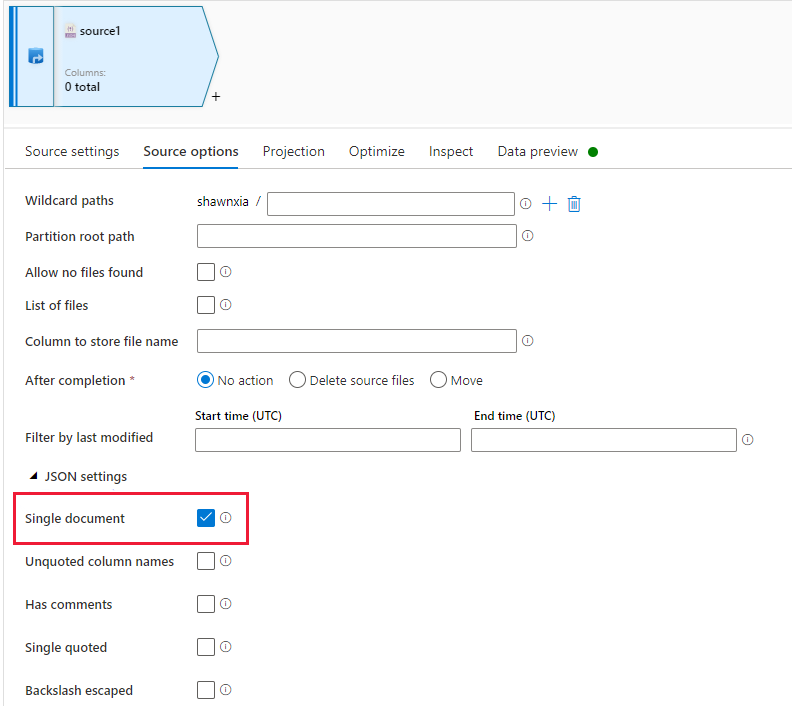
Vous pouvez donc rencontrer des problèmes si les critères suivants sont réunis :
Le jeu de données de récepteur utilisé par l’activité de copie est défini sur « Encodage Unicode » (UTF-8, UTF-16, UTF-16BE, UTF-32, UTF-32BE), ou la valeur par défaut est utilisée.
Le récepteur de copie est configuré pour utiliser le modèle de fichier « Tableau d’objets », comme illustré dans l’image suivante, que l’option « Document individuel » soit activée ou non dans la source JSON du flux de données.
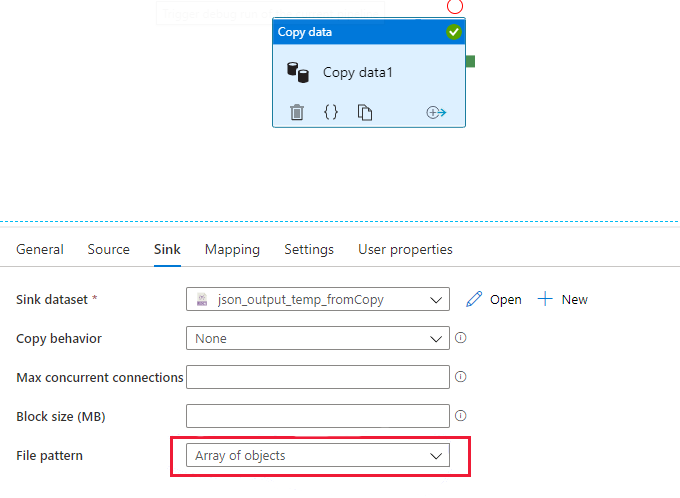
Recommandation
- Utilisez toujours le modèle de fichier par défaut ou le modèle « Jeu d’objets » explicite dans le récepteur de copie si les fichiers générés sont utilisés dans des flux de données.
- Désactivez l’option « Document individuel » dans la source JSON du flux de données.
Notes
L’utilisation de l’option « Jeux d’objets » est également la pratique recommandée du point de vue des performances. Étant donné que l’option JSON « Document individuel » dans le flux de données ne permet pas la lecture parallèle de fichiers individuels volumineux, cette recommandation n’a pas d’impact négatif.
La requête avec des paramètres ne fonctionne pas
Symptômes
Les flux de données de mappage dans Azure Data Factory prennent en charge l’utilisation de paramètres. Les valeurs des paramètres sont définies par le pipeline appelant via l’activité Exécuter un flux de données, et l’utilisation de paramètres constitue un bon moyen de rendre vos flux de données polyvalents, flexibles et réutilisables. Vous pouvez paramétrer les paramètres de flux de données et les expressions à l’aide de ces paramètres : Paramétrage de flux de données de mappage.
Après que vous ayez défini des paramètres et les ayez utilisés dans la requête de la source du flux de données, ils ne prennent pas effet.
La cause
Vous rencontrez cette erreur en raison d’une configuration incorrecte.
Recommandation
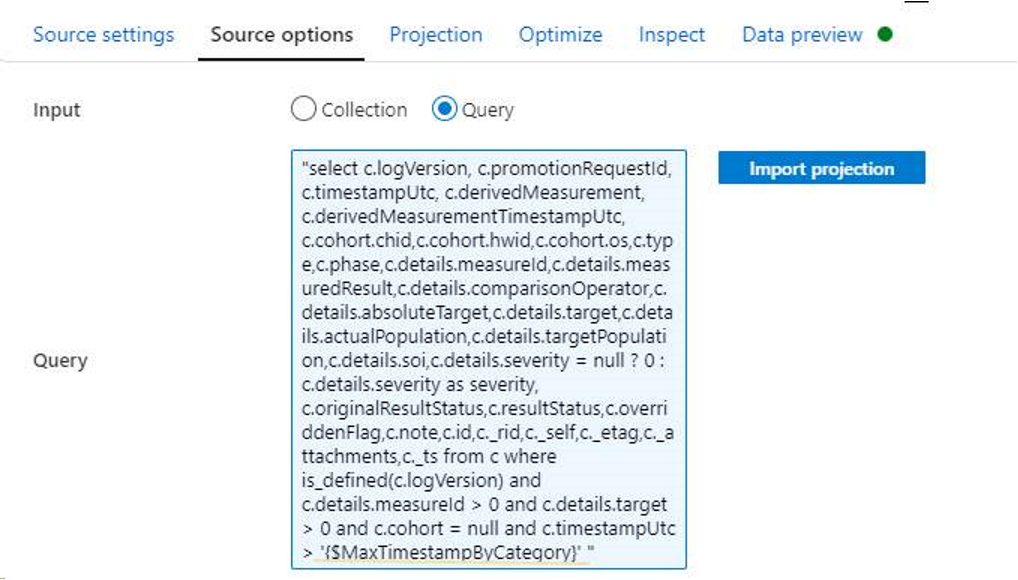
Utilisez les règles suivantes pour définir les paramètres de la requête. Pour obtenir des informations plus détaillées, consultez Générer des expressions dans un flux de données de mappage.
- Appliquez des guillemets doubles au début de l’instruction SQL.
- Utilisez des guillemets simples autour du paramètre.
- Utilisez des lettres minuscules pour toutes les instructions CLAUSE.
Par exemple :
Azure Data Lake Storage Gen1
Échec de la création de fichiers avec l’authentification par principal de service
Symptômes
Lorsque vous essayez de déplacer ou de transférer des données de différentes sources vers le récepteur ADLS Gen1, si la méthode d’authentification du service lié est l’authentification par principal de service, votre travail peut échouer avec le message d’erreur suivant :
org.apache.hadoop.security.AccessControlException: CREATE failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.). [2b5e5d92-xxxx-xxxx-xxxx-db4ce6fa0487] failed with error 0x83090aa2 (Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.)
La cause
L’autorisation RWX ou la propriété du jeu de données n’est pas définie correctement.
Recommandation
Si le dossier cible ne dispose pas des autorisations appropriées, reportez-vous à ce document pour attribuer l’autorisation appropriée dans Gen1 : Utiliser une authentification par principal de service.
Si le dossier cible possède l’autorisation appropriée et que vous utilisez la propriété du nom de fichier dans le flux de données pour cibler le dossier et le nom de fichier appropriés, mais que la propriété du chemin d’accès au fichier du jeu de données n’est pas définie sur le chemin d’accès au fichier cible (généralement, à ne pas définir), comme illustré dans les images suivantes, vous rencontrez cet échec parce que le système principal tente de créer des fichiers en fonction du chemin d’accès au fichier du jeu de données et que celui-ci ne dispose pas de l’autorisation appropriée.
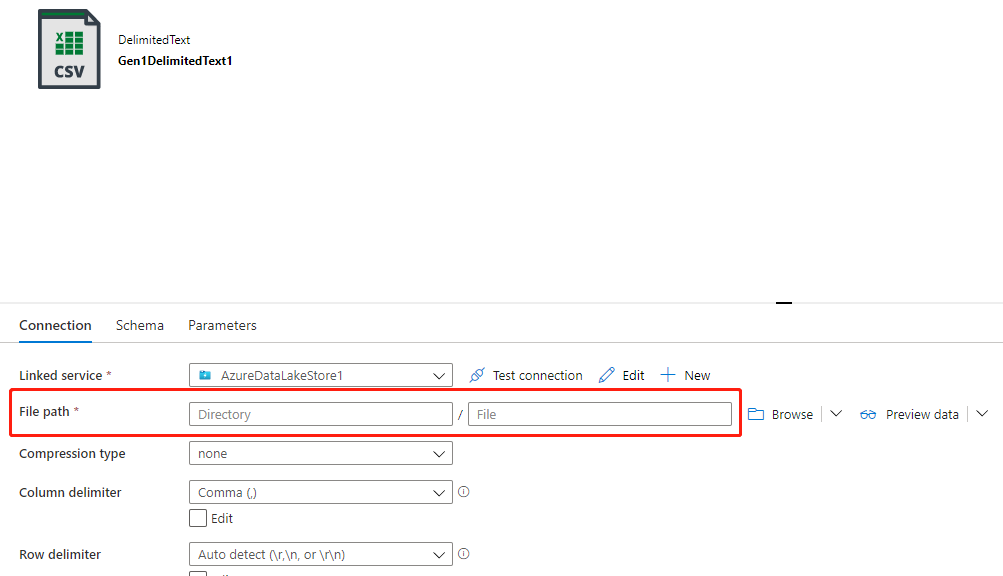
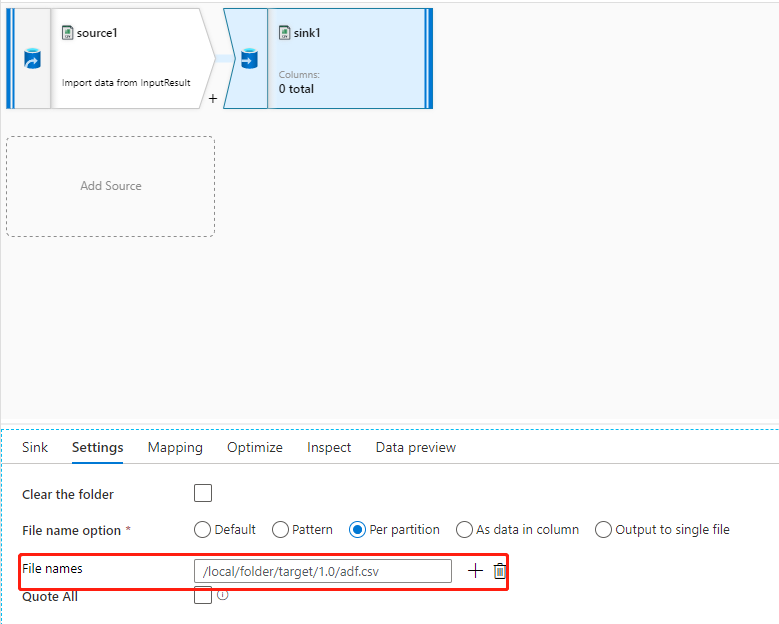
Il existe deux méthodes pour résoudre ce problème :
- Attribuez l’autorisation WX au chemin d’accès au fichier du jeu de données.
- Définissez le chemin d’accès au fichier du jeu de données en tant que dossier avec l’autorisation WX, puis définissez le chemin d’accès au dossier REST et le nom de fichier dans les flux de données.
Azure Data Lake Storage Gen2
Échec avec une erreur : « Erreur lors de la lecture du fichier XXX. Il est possible que les fichiers sous-jacents aient été mis à jour. »
Symptômes
Lorsque vous utilisez ADLS Gen2 comme récepteur dans le flux de données (pour afficher un aperçu des données, déboguer/déclencher l’exécution, etc.) et que le paramètre de partition de l’onglet Optimiser à l’étape Récepteur n’est pas défini par défaut, le travail peut échouer avec le message d’erreur suivant :
Job failed due to reason: Error while reading file abfss:REDACTED_LOCAL_PART@prod.dfs.core.windows.net/import/data/e3342084-930c-4f08-9975-558a3116a1a9/part-00000-tid-7848242374008877624-aaaabbbb-0000-cccc-1111-dddd2222eeee-1-1-c000.csv. It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.
La cause
- Vous n’avez pas attribué une autorisation appropriée à votre authentification par identité managée ou par principal de service.
- Vous avez peut-être un travail personnalisé pour traiter les fichiers dont vous ne voulez pas, ce qui aura une incidence sur la sortie intermédiaire du flux de données.
Recommandation
- Vérifiez si votre service lié dispose de l’autorisation R/W/E pour Gen2. Si vous utilisez l’authentification par identité managée ou par principal de service, accordez au moins le rôle Contributeur aux données Blob du stockage dans le contrôle d’accès (IAM).
- Vérifiez si vous avez des travaux spécifiques qui suppriment/déplacent des fichiers vers un autre emplacement dont le nom ne correspond pas à votre règle. Étant donné que les flux de données consignent d’abord les fichiers de partition dans le dossier cible, puis effectuent les opérations de fusion et de renommage, le nom du fichier intermédiaire peut ne pas correspondre à votre règle.
Azure Database pour PostgreSQL
Erreur : Échec avec l’exception : handshake_failure
Symptômes
Vous utilisez Azure PostgreSQL comme source ou récepteur dans le flux de données, par exemple l’aperçu des données et le débogage/déclenchement de l’exécution, et vous pouvez constater que la travail échoue avec le message d’erreur suivant :
PSQLException: SSL error: Received fatal alert: handshake_failure
Caused by: SSLHandshakeException: Received fatal alert: handshake_failure.
La cause
Si vous utilisez le serveur flexible ou Hyperscale (Citus) pour votre serveur Azure PostgreSQL, puisque le système est créé via Spark sur le cluster Azure Databricks, il y a une limitation où Azure Databricks bloque notre système pour se connecter au serveur flexible ou Hyperscale (Citus). Vous pouvez consulter les deux liens suivants à titre de référence.
Handshake fails trying to connect from Azure Databricks to Azure PostgreSQL with SSL (L’établissement d’une liaison échoue lors de la tentative de connexion d’Azure Databricks à Azure PostgreSQL avec SSL)
MCW-Real-time-data-with-Azure-Database-for-PostgreSQL-Hyperscale
Reportez-vous au contenu de l’image suivante dans cet article :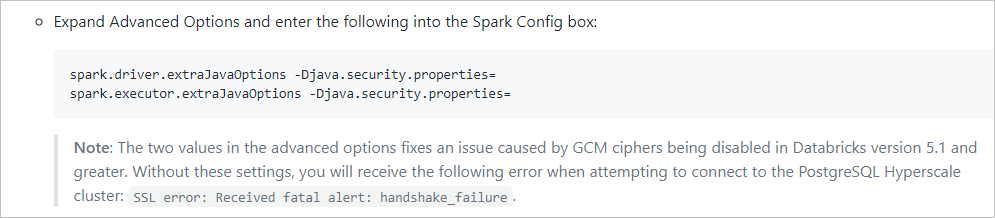
Recommandation
Vous pouvez essayer d’utiliser des activités de copie pour débloquer ce problème.
Azure SQL Database
Impossible de se connecter à la base de données SQL
Symptômes
Votre base de données Azure SQL peut fonctionner correctement dans la copie de données, l’affichage d’un aperçu des données et le test de connexion du jeu de données dans le service lié, mais elle échoue lorsque la même base de données Azure SQL est utilisée comme source ou récepteur dans le flux de données avec une erreur telle que Cannot connect to SQL database: 'jdbc:sqlserver://powerbasenz.database.windows.net;..., Please check the linked service configuration is correct, and make sure the SQL database firewall allows the integration runtime to access.'.
La cause
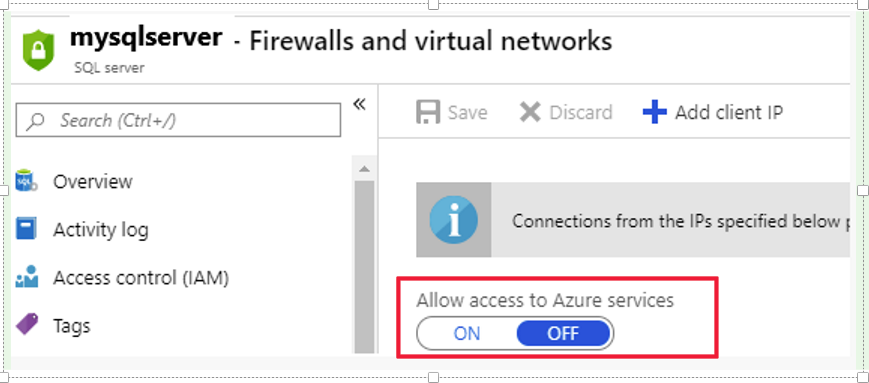
Les paramètres du pare-feu de votre serveur Azure SQL Database sont incorrects, de sorte qu’il ne peut pas se connecter par l’intermédiaire du runtime de flux de données. Actuellement, lorsque vous essayez d’utiliser le flux de données pour lire/écrire dans Azure SQL Database, Azure Databricks est utilisé pour créer le cluster Spark afin d’exécuter le travail, mais il ne prend pas en charge les plages d’adresses IP fixes. Pour plus d’informations, consultez Adresses IP Azure Integration Runtime.
Recommandation
Vérifiez les paramètres du pare-feu de votre instance Azure SQL Database et définissez-les sur « Autoriser l’accès aux services Azure » au lieu de définir une plage d’adresses IP fixes.
Erreur de syntaxe lors de l’utilisation de requêtes en entrée
Symptômes
Lorsque vous utilisez des requêtes en entrée dans la source du flux de données avec Azure SQL, vous échouez avec le message d’erreur suivant :
at Source 'source1': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax XXXXXXXX.
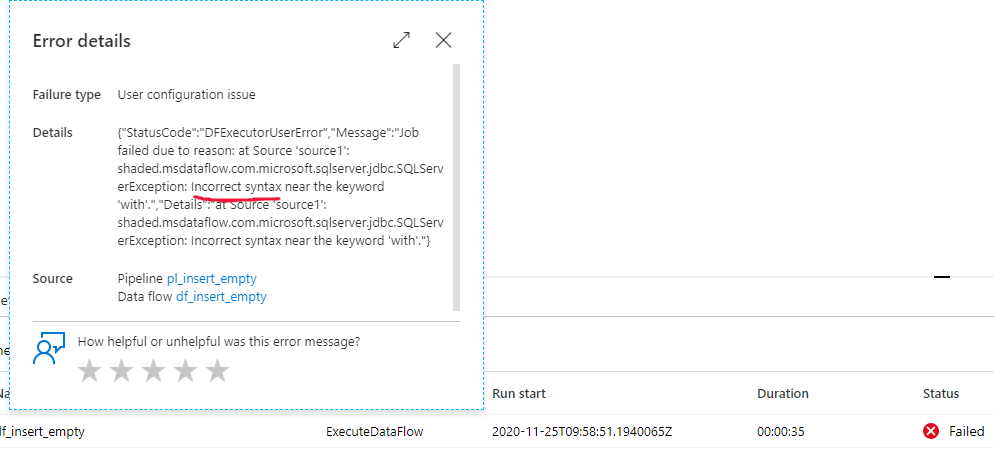
La cause
La requête utilisée dans la source du flux de données doit pouvoir s’exécuter en tant que sous-requête. La raison de cet échec est que la syntaxe de la requête est incorrecte ou qu’elle ne peut pas s’exécuter en tant que sous-requête. Vous pouvez exécuter la requête suivante dans SQL Server Management Studio pour la vérifier :
SELECT top(0) * from ($yourQuery) as T_TEMP
Recommandation
Fournissez une requête correcte et testez-la d’abord dans SQL Server Management Studio.
Échec avec une erreur : « SQLServerException : 111212 ; L’opération ne peut pas être effectuée dans une transaction. »
Symptômes
Lorsque vous utilisez Azure SQL Database comme récepteur dans le flux de données pour afficher un aperçu des données, déboguer/déclencher l’exécution, etc., vous pouvez constater que votre travail échoue avec le message d’erreur suivant :
{"StatusCode":"DFExecutorUserError","Message":"Job failed due to reason: at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction.","Details":"at Sink 'sink': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: 111212;Operation cannot be performed within a transaction."}
La cause
L’erreur « 111212;Operation cannot be performed within a transaction. » se produit uniquement dans le pool SQL dédié de Synapse. Mais vous commettez l’erreur d’utiliser Azure SQL Database comme connecteur à la place.
Recommandation
Vérifiez si votre instance SQL Database est un pool SQL dédié de Synapse. Si c’est le cas, utilisez Azure Synapse Analytics comme connecteur, tel qu’illustré dans l’image suivante.
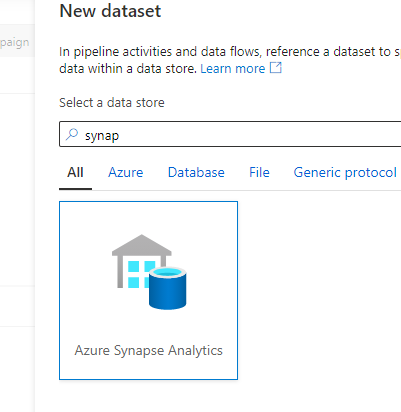
Les données de type décimal deviennent Null
Symptômes
Vous souhaitez insérer des données dans une table de la base de données SQL. Si les données contiennent le type décimal et doivent être insérées dans une colonne avec le type décimal dans la base de données SQL, la valeur des données peut être modifiée en nulle.
Si vous effectuez l’aperçu, dans les étapes précédentes, cela affiche la valeur comme dans l’image suivante :

À l’étape du récepteur, la valeur devient nulle, ce qui est indiqué dans l’image suivante.

La cause
Le type décimal a des propriétés d’échelle et de précision. Si votre type de données ne correspond pas à celui de la table de récepteur, le système vérifie que le décimal cible est plus grand que celui d’origine et que la valeur d’origine ne dépasse pas le décimal cible. Par conséquent, la valeur est castée en nulle.
Recommandation
Vérifiez et comparez le type décimal entre les données et la table dans la base de données SQL et modifiez l’échelle et la précision pour qu’elles soient identiques.
Vous pouvez utiliser toDecimal (IDecimal, échelle, précision) pour déterminer si les données d’origine peuvent être castées à l’échelle et à la précision cibles. Si la fonction renvoie une valeur nulle, cela signifie que les données ne peuvent pas être castées et approfondies lors de l’insertion.
Azure Synapse Analytics
Problèmes liés au pool serverless (SQL à la demande)
Symptômes
Vous utilisez Azure Synapse Analytics, et le service lié est en fait un pool serverless Synapse. Son ancien nom est Pool SQL à la demande, et vous pouvez le distinguer en recherchant le nom du serveur qui contient ondemand, par exemple, space-ondemand.sql.azuresynapse.net. Vous pouvez être confronté à plusieurs défaillances uniques telles que celles-ci :
- Lorsque vous souhaitez utiliser un pool serverless Synapse en tant que récepteur, vous êtes confronté à l’erreur suivante :
Sink results in 0 output columns. Please ensure at least one column is mapped - Lorsque vous sélectionnez « Activer la mise en lots » dans la source, vous êtes confronté à l’erreur suivante :
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near 'IDENTITY'.. - Lorsque vous souhaitez extraire des données d’une table externe, vous êtes confronté à l’erreur suivante :
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External table 'dbo' is not accessible because location does not exist or it is used by another process.. - Lorsque vous souhaitez extraire des données d’Azure Cosmos DB par le biais d’un pool serverless à partir d’une requête ou d’un affichage, vous êtes confronté à l’erreur suivante :
Job failed due to reason: Connection reset. - Lorsque vous souhaitez extraire des données à partir d’un affichage, vous pouvez être confronté à différentes erreurs.
La cause
Les causes des symptômes sont indiquées respectivement ici :
- Le pool serverless ne peut pas être utilisé comme récepteur. Il ne prend pas en charge l’écriture de données dans la base de données.
- Le pool serverless ne prend pas en charge le chargement de données mises en lots, donc l’option « Activer la mise en lots » n’est pas prise en charge.
- La méthode d’authentification que vous utilisez ne dispose pas d’une autorisation correcte pour la source de données externe à laquelle la table externe fait référence.
- Il existe une limitation connue dans le pool serverless Synapse qui vous empêche d’extraire des données Azure Cosmos DB des flux de données.
- L’affichage est une table virtuelle basée sur une instruction SQL. La cause racine se trouve dans l’instruction de l’affichage.
Recommandation
Vous pouvez appliquer les étapes suivantes pour résoudre vos problèmes en conséquence.
Il est préférable de ne pas utiliser le pool serverless comme récepteur.
N’utilisez pas « Activer la mise en lots » dans la source pour le pool serverless.
Seul le principal de service ou seule l’identité managée qui dispose de l’autorisation sur les données de la table externe peut l’interroger. Accordez l’autorisation « Contributeur aux données Blob du stockage » à la source de données externe pour la méthode d’authentification que vous utilisez dans ADF.
Notes
L’authentification par mot de passe utilisateur ne peut pas interroger les tables externes. Pour plus d’informations, consultez Modèle de sécurité.
Vous pouvez utiliser l’activité de copie pour extraire des données Azure Cosmos DB du pool serverless.
Vous pouvez fournir l’instruction SQL qui crée l’affichage à l’équipe du support technique responsable de l’ingénierie, qui pourra vous aider à analyser si l’instruction rencontre un problème d’authentification ou autre.
Le chargement de données de petite taille dans Data Warehouse sans mise en lots est lent
Symptômes
Lorsque vous chargez des données de petite taille dans Data Warehouse sans mise en lots, cela prend beaucoup de temps. Par exemple, la taille des données est de 2 Mo, mais le chargement prend plus d’une heure.
La cause
Ce problème est dû au nombre de lignes plutôt qu’à la taille. Le nombre de lignes est de quelques milliers, et chaque insertion doit être empaquetée dans une requête indépendante, accéder au nœud de contrôle, démarrer une nouvelle transaction, obtenir des verrous et accéder au nœud de distribution à plusieurs reprises. Le chargement en masse obtient le verrou une seule fois, et chaque nœud de distribution effectue l’insertion en effectuant un traitement par lot dans la mémoire de manière efficace.
Si 2 Mo sont insérés sous forme de quelques enregistrements, l’opération sera rapide. Par exemple, ce serait rapide si chaque enregistrement est de 500 ko * 4 lignes.
Recommandation
Vous devez activer la mise en lots pour améliorer les performances.
Lire une chaîne vide ("") comme NULL avec l’activation de la mise en lots
Symptômes
Quand vous utilisez Synapse comme source dans le flux de données, par exemple l’aperçu des données et le débogage/déclenchement de l’exécution, et que vous activez la mise en lots pour utiliser PolyBase, si la valeur de votre colonne contient une chaîne vide (""), elle est modifiée en nulle.
La cause
Le back end du flux de données utilise Parquet comme format PolyBase, et il existe une limitation connue dans le pool Synapse SQL Gen2, qui modifie automatiquement la valeur de chaîne vide par nulle.
Recommandation
Vous pouvez essayer de résoudre ce problème à l’aide des méthodes suivantes :
- Si la taille des données n’est pas énorme, vous pouvez désactiver l’option Activer la mise en lots dans la source, mais le niveau de performance est affecté.
- Si vous devez activer la mise en lots, vous pouvez utiliser la fonction iifNull() pour remplacer manuellement la colonne spécifique Null par une valeur de chaîne vide.
Erreur d’identité du service géré
Symptômes
Lorsque vous utilisez Synapse comme source ou récepteur dans le flux de données pour afficher un aperçu des données, déboguer ou déclencher l’exécution, etc., que vous activez la mise en lots pour utiliser PolyBase et que le service lié du magasin de mise en lots (Blob, Gen2, etc.) est créé pour utiliser l’authentification par identité managée, votre travail peut échouer avec l’erreur suivante illustrée dans l’image :
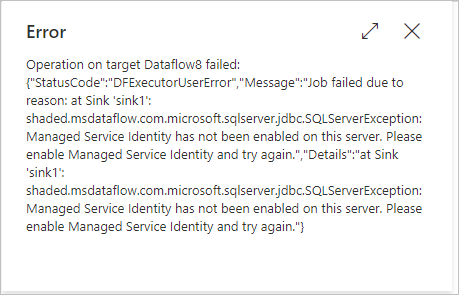
Message d’erreur
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: Managed Service Identity has not been enabled on this server. Please enable Managed Service Identity and try again.
La cause
- Si le pool SQL est créé à partir de l’espace de travail Synapse, l’authentification par identité managée sur le magasin de mise en lots avec PolyBase n’est pas prise en charge pour l’ancien pool SQL.
- Si le pool SQL est l’ancienne version de Data Warehouse (DWH), l’identité managée du serveur SQL n’est pas attribuée au magasin de mise en lots.
Recommandation
Confirmez que le pool SQL a été créé à partir de l’espace de travail Azure Synapse.
- Si le pool SQL a été créé à partir de l’espace de travail Azure Synapse, aucune étape supplémentaire n’est nécessaire. Vous n’avez plus besoin de réenregistrer l’identité managée de l’espace de travail. L’identité managée affectée par le système (SA-MI) de l’espace de travail est membre du rôle Administrateur Synapse, et dispose donc de privilèges élevés sur les pools SQL dédiés de l’espace de travail.
- Si le pool SQL est un pool SQL dédié (anciennement SQL DW) antérieur à Azure Synapse, activez uniquement l’identité managée pour votre serveur SQL et attribuez l’autorisation du magasin intermédiaire à l’identité managée votre serveur SQL. Vous pouvez vous reporter aux étapes décrites dans cet article à titre d’exemple : Utiliser des points de terminaison de service de réseau virtuel et des règles pour serveurs dans Azure SQL Database.
Échec avec une erreur : « SQLServerException : Impossible de valider l’emplacement externe, car le serveur distant a renvoyé une erreur : (403) »
Symptômes
Lorsque vous utilisez SQL DW comme récepteur pour déclencher et exécuter des activités de flux de données, l’activité peut échouer avec une erreur telle que : "SQLServerException: Not able to validate external location because the remote server returned an error: (403)"
La cause
- Lorsque vous utilisez l’identité managée dans la méthode d’authentification du compte ADLS Gen2 comme mise en lots, vous risquez de ne pas définir correctement la configuration de l’authentification.
- Avec le runtime d’intégration de réseau virtuel, vous devez utiliser l’identité managée dans la méthode d’authentification du compte ADLS Gen2 comme mise en lots. Si votre stockage Azure de mise en lots est configuré avec un point de terminaison de service de réseau virtuel, vous devez utiliser l’authentification par identité managée et activer « Autoriser le service Microsoft approuvé » sur le compte de stockage.
- Vérifiez si le nom de votre dossier contient une espace ou d’autres caractères spéciaux, par exemple :
Space " < > # % |. Actuellement, les noms de dossiers qui contiennent certains caractères spéciaux ne sont pas pris en charge dans la commande de copie de Data Warehouse.
Recommandation
Pour la cause 1, vous pouvez vous référer au document Utiliser des points de terminaison de service de réseau virtuel et des règles pour serveurs dans Azure SQL Database, Étapes pour résoudre ce problème.
Pour la cause 2, contournez le problème à l’aide de l’une des options suivantes :
Option 1 : si vous utilisez le runtime d’intégration de réseau virtuel, vous devez utiliser l’identité managée dans la méthode d’authentification du compte ADLS Gen2 comme mise en lots.
Option 2 : si votre stockage Azure de mise en lots est configuré avec un point de terminaison de service de réseau virtuel, vous devez utiliser l’authentification par identité managée et activer « Autoriser le service Microsoft approuvé » sur le compte de stockage. Pour plus d’informations, vous pouvez vous référer à ce document : Copie intermédiaire à l’aide de PolyBase.
Pour la cause 3, contournez le problème à l’aide de l’une des options suivantes :
Option 1 : Renommez le dossier et évitez d’utiliser des caractères spéciaux dans le nom du dossier.
Option 2 : Supprimez la propriété
allowCopyCommand:truedans le script de flux de données, par exemple :
Échec avec une erreur : « shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException : L’utilisateur n’est pas autorisé à effectuer cette action. »
Symptômes
Lorsque vous utilisez Azure Synapse Analytics comme source/récepteur et que vous utilisez la mise en lots PolyBase dans les flux de données, vous rencontrez l’erreur suivante :
shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action.
La cause
PolyBase requiert certaines autorisations dans votre serveur Synapse SQL pour fonctionner.
Recommandation
Accordez ces autorisations dans votre serveur Synapse SQL lorsque vous utilisez PolyBase :
ALTER ANY SCHEMA
MODIFIER TOUTE SOURCE DE DONNÉES EXTERNE
MODIFIER N’IMPORTE QUEL FORMAT DE FICHIER EXTERNE
BASE DE DONNÉES CONTROL
Format Common Data Model
Fichiers model.json contenant des caractères spéciaux
Symptômes
Vous pouvez rencontrer un problème dans lequel le nom final du fichier model.json contient des caractères spéciaux.
Message d’erreur
at Source 'source1': java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: PPDFTable1.csv@snapshot=2020-10-21T18:00:36.9469086Z.
Recommandation
Remplacez les caractères spéciaux dans le nom du fichier, ce qui fonctionne dans Synapse, mais pas dans ADF.
Aucune sortie de données dans l’aperçu des données ou après l’exécution des pipelines
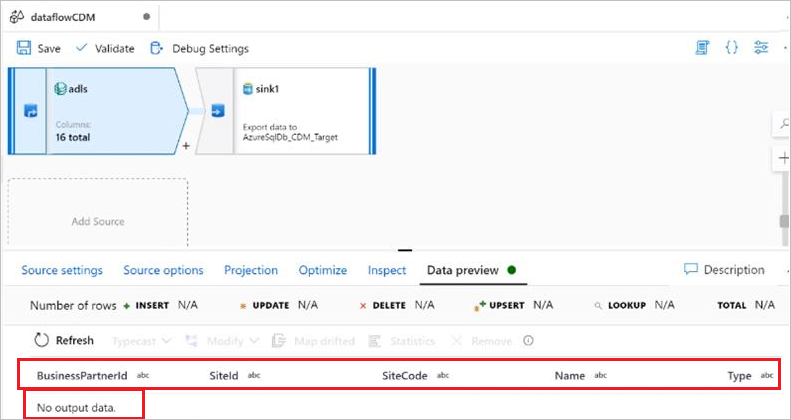
Symptômes
Lorsque vous utilisez le manifest.json pour CDM, aucune donnée n’est affichée dans l’aperçu des données ou après l’exécution d’un pipeline. Seuls les en-têtes sont affichés. Vous pouvez voir ce problème dans l’image ci-dessous.
La cause
Le document manifeste décrit le dossier CDM, par exemple, les entités que vous avez dans le dossier, les références de ces entités et les données qui correspondent à cette instance. Il manque à votre document manifeste l’information dataPartitions qui indique à ADF où lire les données et, dans la mesure où elle est vide, aucune donnée n’est renvoyée.
Recommandation
Mettez à jour votre document manifeste afin d’y inclure l’information dataPartitions. Vous pouvez vous référer à cet exemple de document manifeste pour mettre à jour votre document : Métadonnées Common Data Model : introduction au manifeste ; section Exemple de document manifeste.
Les attributs des tableaux JSON sont considérés comme des colonnes distinctes
Symptômes
Vous pouvez rencontrer un problème où un attribut (type chaîne) de l’entité CDM a un tableau JSON comme données. Lorsque ces données sont rencontrées, ADF les identifie de manière incorrecte comme des colonnes distinctes. Comme vous pouvez le voir dans les images suivantes, un seul attribut présenté dans la source (msfp_otherproperties) est considéré comme une colonne distincte dans l’aperçu du connecteur CDM.
Dans les données sources du CSV (reportez-vous à la deuxième colonne) :

Dans l’aperçu des données sources CDM :
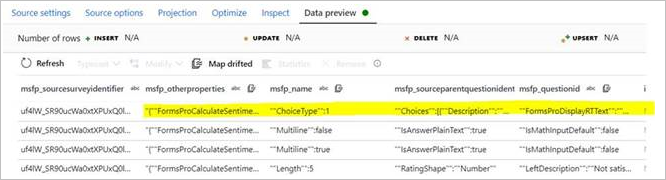
Vous pouvez également essayer de mapper les colonnes dérivées et utiliser l’expression de flux de données pour transformer cet attribut en tableau. Toutefois, étant donné que cet attribut est lu comme une colonne distincte lors de la lecture, la transformation en tableau ne fonctionne pas.
La cause
Ce problème est probablement dû à des virgules dans la valeur de votre objet JSON pour cette colonne. Comme votre fichier de données est censé être un fichier CSV, la virgule indique qu’il s’agit de la fin de la valeur d’une colonne.
Recommandation
Pour résoudre ce problème, vous devez placer votre colonne JSON entre guillemets doubles et éviter les guillemets internes avec une barre oblique inverse (\). Ainsi, le contenu de la valeur de cette colonne peut être lu comme une colonne unique.
Notes
Le CDM n’indique pas que le type de données de la valeur de colonne est JSON, mais il signale qu’il s’agit d’une chaîne et qu’elle est analysée comme telle.
Impossible d’extraire des données dans l’aperçu du flux de données
Symptômes
Vous utilisez CDM avec un model.json généré par Power BI. Lorsque vous prévisualisez les données CDM à l’aide de l’aperçu du flux de données, vous rencontrez l’erreur suivante : No output data..
La cause
Le code suivant existe dans les partitions du fichier model.json généré par le flux de données Power BI.
"partitions": [
{
"name": "Part001",
"refreshTime": "2020-10-02T13:26:10.7624605+00:00",
"location": "https://datalakegen2.dfs.core.windows.net/powerbi/salesEntities/salesPerfByYear.csv @snapshot=2020-10-02T13:26:10.6681248Z"
}
Pour ce fichier model.json, le problème est que le schéma d’affectation de noms du fichier de partition de données comporte des caractères spéciaux et que les chemins d’accès des fichiers sous-jacents avec « @ » n’existent pas actuellement.
Recommandation
Supprimez la partie @snapshot=2020-10-02T13:26:10.6681248Z du nom de fichier de la partition de données et du fichier model.json, puis réessayez.
Le chemin d’accès du corpus est null ou vide
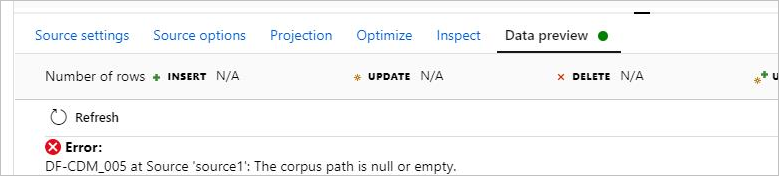
Symptômes
Lorsque vous utilisez CDM dans le flux de données avec le format de modèle, vous ne pouvez pas afficher un aperçu des données, et vous rencontrez l’erreur suivante : DF-CDM_005 The corpus path is null or empty. L’erreur est illustrée dans l’image suivante :
La cause
Le chemin d’accès de votre partition de données dans le model.json pointe vers un emplacement de stockage blob et non vers votre lac de données. L’emplacement doit avoir l’URL de base .dfs.core.windows.net pour ADLS Gen2.
Recommandation
Pour résoudre ce problème, vous pouvez vous référer à cet article : ADF ajoute la prise en charge des jeux de données inlined et de Common Data Model aux flux de données. L’illustration suivante montre la façon de corriger l’erreur de chemin d’accès du corpus dans cet article.
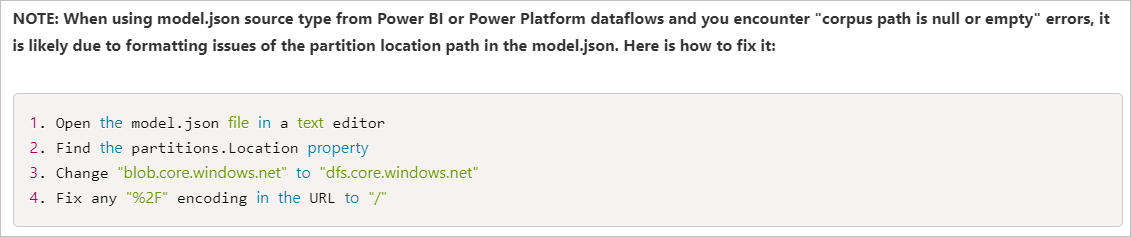
Impossible de lire les fichiers de données CSV
Symptômes
Vous utilisez le jeu de données inlined comme modèle de données commun avec le manifeste comme source, et vous fournissez le fichier manifeste d’entrée, le chemin d’accès racine et le nom et le chemin d’accès de l’entité. Dans le manifeste, vous disposez des partitions de données avec l’emplacement du fichier CSV. Pendant ce temps, le schéma d’entité et le schéma CSV sont identiques et toutes les validations ont réussi. Toutefois, dans l’aperçu des données, seul le schéma est chargé, et non les données, et ces dernières sont invisibles, comme le montre l’image suivante :
La cause
Votre dossier CDM n’est pas séparé en modèles logiques et physiques, et seuls les modèles physiques existent dans le dossier CDM. Les deux articles suivants décrivent la différence : Définitions logiques et Résolution d’une définition d’entité logique.
Recommandation
Pour le flux de données utilisant CDM comme source, essayez d’utiliser un modèle logique comme référence d’entité, et utilisez le manifeste qui décrit l’emplacement des entités physiques résolues et les emplacements des partitions de données. Vous pouvez voir quelques exemples de définitions d’entités logiques dans le référentiel public CDM de GitHub : CDM-schemaDocuments
Un bon point de départ pour la création de votre corpus consiste à copier les fichiers dans le dossier de documents de schéma (juste ce niveau dans le référentiel GitHub) et à placer ces fichiers dans un dossier. Ensuite, vous pouvez utiliser l’une des entités logiques prédéfinies dans le référentiel (comme point de départ ou de référence) pour créer votre modèle logique.
Une fois le corpus configuré, il est recommandé d’utiliser CDM comme récepteur dans les flux de données, afin qu’un dossier CDM bien formé puisse être correctement créé. Vous pouvez utiliser votre jeu de données CSV comme source, puis l’intégrer au modèle CDM que vous avez créé.
Format CSV et Excel
Le CSV ne prend pas en charge le caractère de guillemet défini sur « pas de guillemets »
Symptômes
Plusieurs problèmes ne sont pas pris en charge dans le CSV lorsque le caractère de guillemet est défini sur « pas de guillemets » :
- Lorsque le caractère de guillemet est défini sur « pas de guillemets », le délimiteur de colonne à plusieurs caractères ne peut pas commencer et se terminer par les mêmes lettres.
- Lorsque le caractère de guillemet est défini sur « pas de guillemets », le délimiteur de colonne à plusieurs caractères ne peut pas contenir le caractère d’échappement :
\. - Lorsque le caractère de guillemet est défini sur « pas de guillemets », la valeur de la colonne ne peut pas contenir de délimiteur de ligne.
- Le caractère de guillemet et le caractère d’échappement ne peuvent pas tous les deux être vides (pas de guillemets ni séquence d’échappement) si la valeur de la colonne contient un délimiteur de colonne.
La cause
Les causes des symptômes sont indiquées ci-dessous avec leurs exemples respectifs :
Commence et se termine par les mêmes lettres.
column delimiter: $*^$*
column value: abc$*^ def
csv sink: abc$*^$*^$*def
will be read as "abc" and "^&*def"Le délimiteur à plusieurs caractères contient des caractères d’échappement.
column delimiter: \x
escape char:\
column value: "abc\\xdef"
Le caractère d’échappement échappe le délimiteur de colonne ou le caractère.La valeur de la colonne contient un délimiteur de ligne.
We need quote character to tell if row delimiter is inside column value or not.Le caractère de guillemet et le caractère d’échappement sont tous les deux vides et la valeur de la colonne contient des délimiteurs de colonne.
Column delimiter: \t
column value: 111\t222\t33\t3
It will be ambiguous if it contains 3 columns 111,222,33\t3 or 4 columns 111,222,33,3.
Recommandation
Le premier symptôme et le second symptôme ne peuvent pas être résolus actuellement. Pour les troisième et quatrième symptômes, vous pouvez appliquer les méthodes suivantes :
- Pour le symptôme 3, n’utilisez pas l’option« pas de guillemets » pour un fichier CSV multiligne.
- Pour le symptôme 4, définissez le caractère de guillemet ou le caractère d’échappement comme non vide, ou vous pouvez supprimer tous les délimiteurs de colonne dans vos données.
Erreur de lecture des fichiers avec des schémas différents
Symptômes
Lorsque vous utilisez des flux de données pour lire des fichiers tels que des fichiers CSV et Excel avec des schémas différents, le débogage de flux de données, le bac à sable ou l’exécution d’activité échouent.
Pour CSV, le mauvais alignement des données existe lorsque le schéma des fichiers est différent.
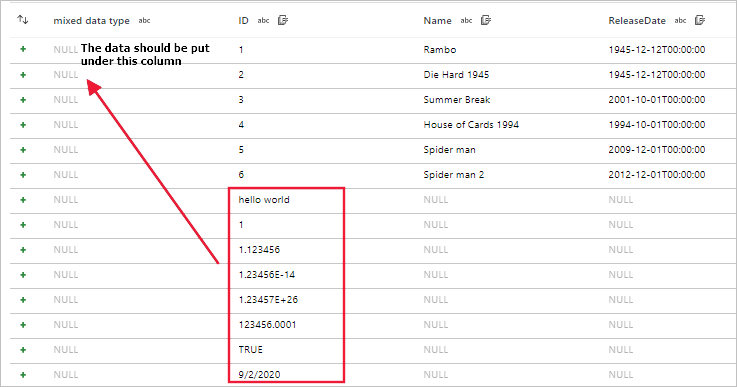
Pour Excel, une erreur se produit lorsque le schéma du fichier est différent.

La cause
La lecture de fichiers avec des schémas différents dans le flux de données n’est pas prise en charge.
Recommandation
Si vous souhaitez toujours transférer des fichiers tels que des fichiers CSV et Excel avec des schémas différents dans le flux de données, vous pouvez utiliser ces méthodes pour contourner le problème :
Pour CSV, vous devez fusionner manuellement le schéma des différents fichiers pour obtenir le schéma complet. Par exemple, file_1 contient des colonnes
c_1,c_2,c_3tandis que file_2 contient des colonnesc_3,c_4, ...c_10, donc le schéma fusionné et complet estc_1,c_2, ...c_10. Ensuite, faites en sorte que les autres fichiers aient également le même schéma complet, même s’ils ne contiennent pas de données. Par exemple, file_x contient uniquement des colonnesc_1,c_2,c_3,c_4. Ajoutez les colonnesc_5,c_6, ...c_10au fichier afin qu’elles soient cohérentes avec les autres fichiers.Pour Excel, vous pouvez résoudre ce problème en appliquant l’une des options suivantes :
-
Option 1 : Vous devez fusionner manuellement le schéma des différents fichiers pour obtenir le schéma complet. Par exemple, file_1 contient des colonnes
c_1,c_2,c_3tandis que file_2 contient des colonnesc_3,c_4, ...c_10, donc le schéma fusionné et complet estc_1,c_2, ...c_10. Ensuite, faites en sorte que les autres fichiers aient également le même schéma, même s’ils ne contiennent pas de données. Par exemple, file_x avec la feuille « SHEET_1 » contient uniquement des colonnesc_1,c_2,c_3,c_4. Ajoutez les colonnesc_5,c_6, ...c_10également dans la feuille, et cela pourra alors fonctionner. - Option 2 : Utilisez la plage (par exemple, A1:G100) + firstRowAsHeader=false, et il peut alors charger les données de tous les fichiers Excel, même si le nom et le nombre de colonnes sont différents.
-
Option 1 : Vous devez fusionner manuellement le schéma des différents fichiers pour obtenir le schéma complet. Par exemple, file_1 contient des colonnes
Flocon de neige
Impossible de se connecter au service lié Snowflake
Symptômes
Vous rencontrez l’erreur suivante lorsque vous créez le service lié Snowflake dans le réseau public et que vous utilisez le runtime d’intégration de résolution automatique.
ERROR [HY000] [Microsoft][Snowflake] (4) REST request for URL https://XXXXXXXX.east-us- 2.azure.snowflakecomputing.com.snowflakecomputing.com:443/session/v1/login-request?requestId=XXXXXXXXXXXXXXXXXXXXXXXXX&request_guid=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
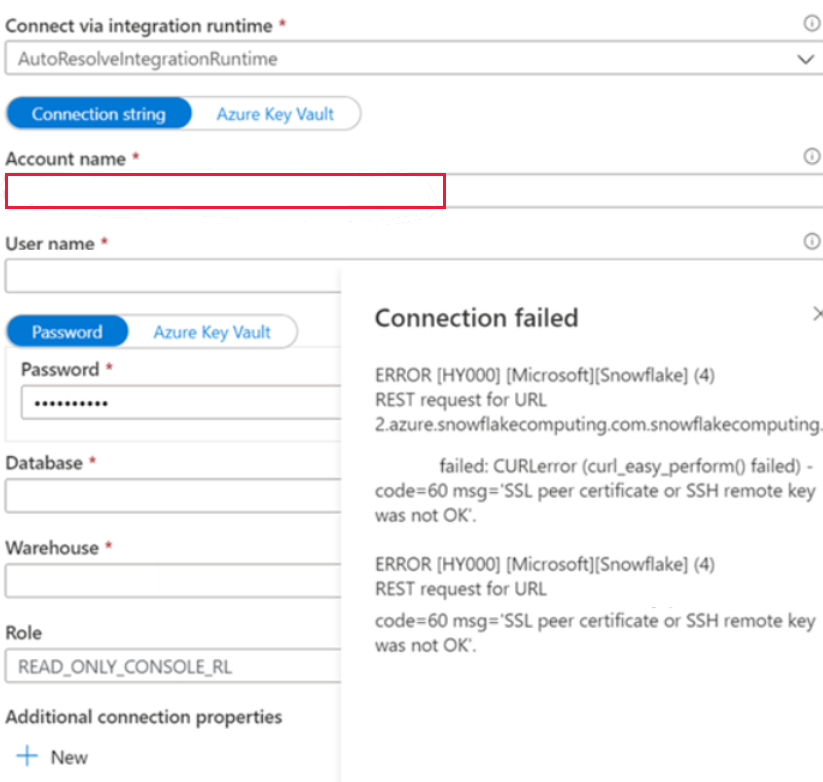
La cause
Vous n’avez pas appliqué le nom du compte dans le format indiqué dans le document du compte Snowflake (y compris les segments supplémentaires qui identifient la région et la plateforme cloud), par exemple XXXXXXXX.east-us-2.azure. Pour plus d’informations, vous pouvez vous référer à ce document : Propriétés du service lié.
Recommandation
Pour résoudre le problème, modifiez le format du nom de compte. Le rôle doit être l’un des rôles indiqués dans l’image suivante, mais le rôle par défaut est Public.
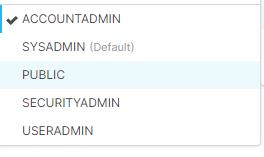
Erreur de contrôle d’accès SQL : « Privilèges insuffisants pour agir sur le schéma »
Symptômes
Lorsque vous essayez d’utiliser « Importer une projection », « Aperçu des données », etc. dans la source Snowflake des flux de données, vous rencontrez des erreurs telles que net.snowflake.client.jdbc.SnowflakeSQLException: SQL access control error: Insufficient privileges to operate on schema.
La cause
Vous rencontrez cette erreur en raison d’une configuration incorrecte. Lorsque vous utilisez le flux de données pour lire les données Snowflake, le runtime Azure Databricks (ADB) ne sélectionne pas directement la requête jusqu’à Snowflake. Au lieu de cela, une étape temporaire est créée et les données sont tirées (pull) des tables vers l’étape, puis compressées et tirées (pull) par ADB. Ce processus est illustré dans l’image ci-dessous.
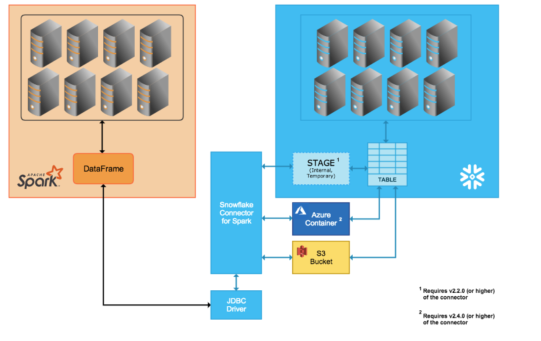
Par conséquent, l’utilisateur ou le rôle utilisé dans ADB doit disposer de l’autorisation nécessaire pour effectuer cette opération dans Snowflake. Mais en général, l’utilisateur/le rôle n’a pas l’autorisation puisque la base de données est créée sur le partage.
Recommandation
Pour résoudre ce problème, vous pouvez créer une base de données différente et créer des affichages en haut de la base de données partagée pour y accéder à partir d’ADB. Pour plus d’informations, référez-vous à Snowflake.
Échec avec une erreur : « SnowflakeSQLException : L’adresse IP x.x.x.x n’est pas autorisée à accéder à Snowflake. Contactez votre administrateur local de la sécurité. »
Symptômes
Lorsque vous utilisez Snowflake dans Azure Data Factory, vous pouvez utiliser test-connection dans le service lié Snowflake, preview-data/import-schema sur le jeu de données Snowflake et run copy/lookup/get-metadata ou d’autres activités avec celui-ci. Toutefois, lorsque vous utilisez Snowflake dans l’activité de flux de données, vous pouvez rencontrer des erreurs telles que SnowflakeSQLException: IP 13.66.58.164 is not allowed to access Snowflake. Contact your local security administrator.
La cause
Le flux de données Azure Data Factory ne prend pas en charge l’utilisation de plages d’adresses IP fixes. Pour plus d’informations, consultez Adresses IP du Runtime d’intégration Azure.
Recommandation
Pour résoudre ce problème, vous pouvez modifier les paramètres du pare-feu du compte Snowflake en procédant comme suit :
Vous pouvez obtenir la liste de plages d’adresses IP des étiquettes de service à partir du « lien de téléchargement de la plage d’adresses IP des étiquettes de service » : Détection de balises de service à l’aide de fichiers JSON téléchargeables.
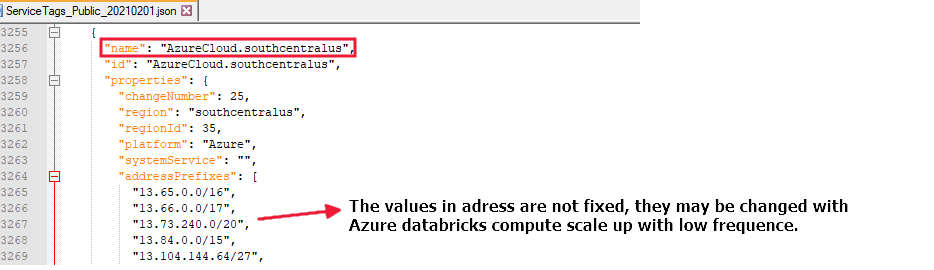
Si vous exécutez un flux de données dans la région « southcentralus », vous devez autoriser l’accès à partir de toutes les adresses portant le nom « AzureCloud.southcentraluss », par exemple :
Les requêtes dans la source ne fonctionnent pas
Symptômes
Lorsque vous tentez de lire des données à partir de Snowflake à l’aide d’une requête, vous pouvez rencontrer une erreur telle que :
SQL compilation error: error line 1 at position 7 invalid identifier 'xxx'SQL compilation error: Object 'xxx' does not exist or not authorized.
La cause
Vous rencontrez cette erreur en raison d’une configuration incorrecte.
Recommandation
Snowflake applique les règles suivantes pour stocker les identificateurs au moment de leur création ou définition et les résoudre dans les requêtes et autres instructions SQL :
Lorsqu’un identificateur (nom de table, nom de schéma, nom de colonne, etc.) est sans guillemets, il est stocké et résolu en majuscules par défaut et respecte la casse. Par exemple :

Comme elle respecte la casse, vous pouvez utiliser la requête suivante pour lire les données Snowflake, le résultat étant le même :
Select MovieID, title from Public.TestQuotedTable2Select movieId, title from Public.TESTQUOTEDTABLE2Select movieID, TITLE from PUBLIC.TESTQUOTEDTABLE2
Lorsqu’un identificateur (nom de table, nom de schéma, nom de colonne, etc.) est placé entre guillemets, il est stocké et résolu exactement comme il a été saisi, y compris la casse. Vous pouvez voir un exemple dans l’image suivante. Pour plus d’informations, consultez ce document : Identifier Requirements.

Étant donné que l’identificateur qui respecte la casse (nom de la table, nom du schéma, nom de la colonne, etc.) a un caractère minuscule, vous devez placer l’identificateur entre guillemets pendant la lecture des données à l’aide de la requête, par exemple :
- Sélectionnez "movieId" , "title" de Public. "testQuotedTable2" .
Si vous rencontrez une erreur avec la requête Snowflake, vérifiez si certains identificateurs (nom de la table, nom du schéma, nom de la colonne, etc.) respectent la casse à l’aide des étapes suivantes :
Connectez-vous au serveur Snowflake (
https://{accountName}.azure.snowflakecomputing.com/, remplacez {accountName} par le nom de votre compte) pour vérifier l’identificateur (nom de la table, nom du schéma, nom de la colonne, etc.).Créez des feuilles de calcul pour tester et valider la requête :
- Exécutez
Use database {databaseName}, remplacez {databaseName} par le nom de votre base de données. - Exécutez une requête avec une table, par exemple :
select "movieId", "title" from Public."testQuotedTable2".
- Exécutez
Une fois que la requête SQL de Snowflake est testée et validée, vous pouvez l’utiliser directement dans la source Snowflake de flux de données.
Le type expression ne correspond pas au type de données de colonne : VARIANT attendu, mais a obtenu VARCHAR
Symptômes
Lorsque vous essayez d’écrire des données dans la table Snowflake, vous pouvez rencontrer l’erreur suivante :
java.sql.BatchUpdateException: SQL compilation error: Expression type does not match column data type, expecting VARIANT but got VARCHAR
La cause
Le type colonne des données d’entrée est « chaîne », ce qui est différent du type VARIANT de la colonne correspondante dans le récepteur Snowflake.
Lorsque vous stockez des données avec des schémas complexes (tableau/mappage/struct) dans une nouvelle table Snowflake, le type de flux de données est automatiquement converti en son type physique VARIANT.

Les valeurs associées sont stockées sous forme de chaînes JSON, comme le montre l’image ci-dessous.

Recommandation
Pour le type VARIANT de Snowflake, elle ne peut accepter que la valeur du flux de données qui est de type struct, carte ou tableau. Si la valeur de votre colonne de données d’entrée est JSON, XML ou d’autres chaînes, utilisez l’une des options suivantes pour résoudre ce problème :
Option 1 : Utilisez la transformation d’analyse avant d’utiliser Snowflake comme récepteur pour convertir la valeur de la colonne de données d’entrée en type struct, carte ou tableau, par exemple :
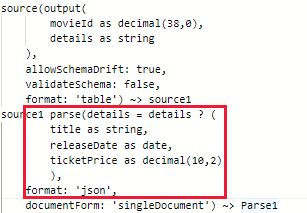
Notes
La valeur de la colonne Snowflake de type VARIANT est lue par défaut comme une chaîne dans Spark.
Option 2 : Connectez-vous à votre serveur Snowflake (
https://{accountName}.azure.snowflakecomputing.com/, remplacez {accountName} par le nom de votre compte) pour modifier le schéma de votre table cible Snowflake. Appliquez les étapes suivantes en exécutant la requête sous chaque étape.Créez une nouvelle colonne avec VARCHAR pour stocker les valeurs.
alter table tablename add newcolumnname varchar;Copiez la valeur de VARIANT dans la nouvelle colonne.
update tablename t1 set newcolumnname = t1."details"Supprimez la colonne VARIANT inutilisée.
alter table tablename drop column "details";Renommez la nouvelle colonne avec l’ancien nom.
alter table tablename rename column newcolumnname to "details";
Contenu connexe
Pour obtenir une aide supplémentaire sur la résolution des problèmes, consultez les ressources suivantes :