Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article présente des méthodes couramment employées pour résoudre les problèmes liés aux flux de données de mappage dans Azure Data Factory.
Instructions générales pour la résolution des problèmes
- Vérifiez l’état de vos connexions de jeu de données. Dans chaque transformation de la source et du récepteur, accédez au service lié pour chaque jeu de données que vous utilisez et testez les connexions.
- Vérifiez l’état de vos connexions aux fichiers et aux tables dans le concepteur de flux de données. En mode de débogage, sélectionnez Aperçu des données dans vos transformations sources pour vérifier que vous pouvez accéder à vos données.
- Si tout semble correct dans l’aperçu des données, accédez au concepteur de pipeline et mettez votre flux de données dans une activité de pipeline. Déboguez le pipeline pour un test de bout en bout.
Erreurs de serveur internes
Des scénarios spécifiques qui peuvent provoquer des erreurs internes de serveurs sont présentés ci-dessous.
Scénario 1 : Ne pas choisir la taille/le type de calcul approprié et d’autres facteurs
La réussite de l’exécution des flux de données dépend de nombreux facteurs, parmi lesquels la taille/le type de calcul, le nombre de sources/récepteurs à traiter, la spécification de partition, les transformations impliquées, la taille des jeux de données, l’asymétrie des données, etc.
Pour plus d’informations, consultez Performances du runtime d’intégration.
Scénario 2 : Utilisation de sessions de débogage avec des activités parallèles
Lorsque vous déclenchez d’une exécution en utilisant une session de débogage de flux de données avec des constructions telles que ForEach dans le pipeline, plusieurs exécutions parallèles peuvent être soumises au même cluster. Cette situation peut entraîner des problèmes de défaillance du cluster au moment de l’exécution en raison de problèmes de ressources, tels qu’une mémoire insuffisante.
Pour soumettre une exécution avec la configuration de runtime d’intégration appropriée définie dans l’activité de pipeline et après la publication des modifications, sélectionnez Déclencher maintenant ou Déboguer, puis >
Scénario 3 : Problèmes temporaires
Des problèmes temporaires avec des microservices impliqués dans l’exécution peuvent entraîner l’échec de l’exécution.
La configuration de nouvelles tentatives dans l’activité de pipeline peut résoudre les problèmes dus à des problèmes temporaires. Pour plus d’informations, consultez Stratégies d’activité.
Messages et codes d’erreur courants
Cette section répertorie les codes d’erreur courants et les messages signalés par les flux de données de mappage dans Azure Data Factory, ainsi que les causes et les recommandations associées.
Code d’erreur : DF-AdobeIntegration-InvalidMapToFilter
- Message : la ressource personnalisée ne peut avoir qu’une clé/ID mappée au filtre.
- Cause : Les configurations fournies ne sont pas valides.
- Recommandation : Dans vos paramètres AdobeIntegration, assurez-vous que la ressource personnalisée ne peut avoir qu'une seule clé ou un seul ID mappé au filtre.
Code d’erreur : DF-AdobeIntegration-InvalidPartitionConfiguration
- Message : seule une partition unique est prise en charge. Le schéma de partition peut être RoundRobin ou Hash.
- Cause : Les configurations de partition fournies ne sont pas valides.
- Recommandation : Dans les paramètres d'AdobeIntegration, vérifiez que seule la partition unique est définie, et que les schémas de partition peuvent être RoundRobin ou Hash.
Code d’erreur : DF-AdobeIntegration-InvalidPartitionType
- Message : le type de la partition doit être roundRobin.
- Cause : Les types de partition fournis ne sont pas valides.
- Recommandation : mettez à jour les paramètres d'AdobeIntegration pour définir votre type de partition sur RoundRobin.
Code d’erreur : DF-AdobeIntegration-InvalidPrivacyRegulation
- Message: seul le règlement sur la confidentialité actuellement pris en charge est « RGPD ».
- Cause : Les configurations fournies en matière de confidentialité ne sont pas valides.
- Recommandation : mettez à jour les paramètres d'AdobeIntegration. Seul le « RGPD » est pris en charge.
Code d’erreur : DF-AdobeIntegration-KeyColumnMissed
- Message : la clé doit être spécifiée pour les opérations qui ne peuvent pas être insérées.
- Cause : Des colonnes clés sont manquantes.
- Recommandation : Mettez à jour les paramètres d'AdobeIntegration afin de vous assurer que les colonnes clés sont spécifiées pour les opérations non insérables.
Code d’erreur : DF-AzureDataExplorer-InvalidOperation
- Message : L’opération d’objet blob n’est pas prise en charge sur les anciens comptes de stockage. La création d’un compte de stockage peut résoudre le problème.
- Cause : l'opération n'est pas prise en charge.
- Recommandation : la modification de la configuration de la méthode de mise à jour comme la suppression, la mise à jour et l’upsert n’est pas prise en charge dans Azure Data Explorer.
Code d’erreur : DF-AzureDataExplorer-ReadTimeout
- Message : L’opération a expiré lors de la lecture de données.
- Cause : l’opération expire lors de la lecture de données.
- Recommandation : augmentez la valeur dans l’option Timeout dans les paramètres de transformation source.
Code d’erreur : DF-AzureDataExplorer-WriteTimeout
- Message : L’opération a expiré lors de l’écriture de données.
- Cause : l’opération expire lors de l’écriture de données.
- Recommandation : augmentez la valeur dans l’option Timeout dans les paramètres de transformation du récepteur.
Code d’erreur : DF-BLOB-FunctionNotSupport
- Message : ce point de terminaison ne prend pas en charge BlobStorageEvents, SoftDelete ou AutomaticSnapshot. Désactivez ces fonctionnalités de compte si vous souhaitez utiliser ce point de terminaison.
- Cause : les événements de Stockage Blob Azure, la suppression réversible ou la capture instantanée automatique ne sont pas pris en charge dans les flux de données si le service lié Stockage Blob Azure est créé avec l’authentification du principal de service ou de l’identité managée.
- Recommandation : désactivez les événements de Stockage Blob Azure, la suppression réversible ou la fonctionnalité de capture instantanée automatique sur le compte Azure Blob, ou utilisez l’authentification par clé pour créer le service lié.
Code d’erreur : DF-Blob-InvalidAccountConfiguration
- Message : Une clé de compte ou un jeton SAS doit être spécifié.
- Cause : Les informations d'identification fournies dans le service lié Azure Blob ne sont pas valides.
- Recommandation : Utilisez une clé de compte ou un jeton SAS pour le service lié Azure Blob.
Code d’erreur : DF-Blob-InvalidAuthConfiguration
- Message : vous pouvez spécifier une seule des deux méthodes d’authentification (Clé, SAS).
- Cause : La méthode d'authentification fournie dans le service lié n'est pas valide.
- Recommandation : Utilisez l'authentification par clé ou SAS pour le service lié Azure Blob.
Code d'erreur : DF-Blob-InvalidCloudType
- Message : le type de Cloud n’est pas valide.
- Cause : Le type de cloud fourni n'est pas valide.
- Recommandation : vérifiez le type de cloud dans le service lié Azure Blob associé.
Code d'erreur : DF-Cosmos-DeleteDataFailed
- Message : Échec de la suppression des données d’Azure Cosmos DB après 3 tentatives.
- Cause : Le débit sur la collection Azure Cosmos DB est faible, et entraîne une limitation ou mène à des données de ligne qui n'existent pas dans Azure Cosmos DB.
-
Recommandation : pour résoudre ce problème, effectuez les actions suivantes :
- En cas d'erreur 404, vérifiez que les données de la ligne associée existent dans la collection Azure Cosmos DB.
- En cas d'erreur de limitation, augmentez le débit de la collection Azure Cosmos DB ou définissez-le sur Mise à l'échelle automatique.
- E cas d’erreur d’expiration de la requête, définissez « Taille du lot » dans le récepteur Azure Cosmos DB sur une valeur plus petite, par exemple 1000.
Code d'erreur : DF-Cosmos-FailToResetThroughput
- Message : l'opération de mise à l'échelle du débit d’Azure Cosmos DB ne peut être effectuée car une autre opération de mise à l'échelle est en cours. Réessayez ultérieurement.
- Cause : L’opération de mise à l’échelle du débit d’Azure Cosmos DB ne peut pas être effectuée, car une autre opération de mise à l’échelle est en cours.
- Recommandation : Connectez-vous au compte Azure Cosmos DB et modifiez manuellement le débit du conteneur pour mise à l’échelle automatique ou ajoutez une activité personnalisée après le mappage des flux de données pour réinitialiser le débit.
Code d’erreur : DF-Cosmos-IdPropertyMissed
- Message : la propriété « ID » doit être mappée pour les opérations de suppression et de mise à jour.
-
Cause : La propriété
idest manquante pour les opérations de mise à jour et de suppression. -
Recommandation : assurez-vous que les données d'entrée comportent une colonne
iddans les paramètres de transformation du récepteur Azure Cosmos DB. Si ce n’est pas le cas, utilisez une transformation de colonne sélectionnée ou dérivée pour générer cette colonne avant la transformation du récepteur.
Code d’erreur : DF-Cosmos-InvalidAccountConfiguration
- Message : Les éléments AccountName ou accountEndpoint doivent être spécifiés.
- Cause : Les informations de compte fournies ne sont pas valides.
- Recommandation : Dans le service lié Azure Cosmos DB, spécifiez le nom ou le point de terminaison du compte.
Code d’erreur : DF-Cosmos-InvalidAccountKey
- Message : Le jeton d’autorisation d’entrée ne peut pas traiter la requête. Assurez-vous que la charge utile attendue est conçue conformément au protocole et vérifiez la clé utilisée.
- Cause : L’autorisation de lecture/d’écriture de données Azure Cosmos DB est insuffisante.
- Recommandation : utilisez la clé de lecture/écriture pour accéder à Azure Cosmos DB.
Code d’erreur : DF-Cosmos-InvalidConnectionMode
- Message : Mode de connexion non valide.
- Cause : Le mode de connexion fourni n'est pas valide.
- Recommandation : Vérifiez que le mode pris en charge est Gateway et DirectHttps dans les paramètres Azure Cosmos DB.
Code d’erreur : DF-Cosmos-InvalidPartitionKey
- Message : le chemin de la clé de partition ne peut pas être vide pour les opérations de mise à jour et de suppression.
- Cause : Le chemin de la clé de partition est vide pour les opérations de mise à jour et de suppression.
- Recommandation : Utilisez la clé de partition fournie dans les paramètres du récepteur Azure Cosmos DB.
- Message : La clé de partition n'est pas mappée dans le récepteur pour les opérations de suppression et de mise à jour.
- Cause : La clé de partition fournie n'est pas valide.
- Recommandation : Dans les paramètres du récepteur Azure Cosmos DB, utilisez la même clé de partition que celle de votre conteneur.
Code d’erreur : DF-Cosmos-InvalidPartitionKeyContent
- Message : la clé de partition doit commencer par /.
- Cause : La clé de partition fournie n'est pas valide.
-
Recommandation : Veillez à ce que la clé de partition commence par
/dans les paramètres du récepteur Azure Cosmos DB (par exemple,/movieId).
Code d’erreur : DF-Cosmos-PartitionKeyMissed
- Message : le chemin d’accès de la clé de partition doit être indiqué pour les opérations de mise à jour et de suppression.
- Cause : Le chemin de la clé de partition est manquant dans le récepteur Azure Cosmos DB.
- Recommandation : fournissez la clé de partition dans les paramètres du récepteur Azure Cosmos DB.
Code d’erreur : DF-Cosmos-ResourceNotFound
- Message : Ressource introuvable.
- Cause : une configuration non valide est fournie (par exemple, la clé de partition avec des caractères non valides) ou la ressource n’existe pas.
- Recommandation : Pour résoudre ce problème, reportez-vous à la page Diagnostic et résolution des problèmes liés à des ressources Azure Cosmos DB introuvables.
Code d’erreur : DF-Cosmos-ShortTypeNotSupport
- Message : Le type de données courtes n’est pas pris en charge dans Azure Cosmos DB.
- Cause : le type de données courtes n’est pas pris en charge dans l’instance Azure Cosmos DB.
- Recommandation : Ajoutez une transformation de colonne dérivée pour convertir les colonnes associées de « short » en « integer » avant de les utiliser dans la transformation du récepteur Azure Cosmos DB.
Code d’erreur : DF-CSVWriter-InvalidQuoteSetting
- Message : Échec du travail lors de l’écriture de données avec l’erreur : Le caractère de guillemet et le caractère d’échappement ne peuvent pas être vides si la valeur de colonne contient le délimiteur de colonnes
- Cause : Les guillemets et les caractères d’échappement sont vides lorsque la valeur de colonne contient le délimiteur de colonne.
- Recommandation : Définissez votre caractère de guillemet ou d’échappement.
Code d’erreur : DF-Delimited-ColumnDelimiterMissed
- Message : Délimiteur de colonne requis pour l'analyse.
- Cause : Le délimiteur de colonne est manquant.
- Recommandation : dans vos paramètres CSV, vérifiez que vous disposez du délimiteur de colonne requis pour l'analyse.
Code d’erreur : DF-Delimited-InvalidConfiguration
- Message : vous devez spécifier l’une des lignes vides ou un en-tête personnalisé.
- Cause : La configuration délimitée fournie n'est pas valide.
- Recommandation : mettez à jour les paramètres CSV pour spécifier une des lignes vides ou l'en-tête personnalisé.
Code d’erreur : DF-DELTA-InvalidConfiguration
- Message : le timestamp et la version ne peuvent pas être définis en même temps.
- Message : Le timestamp et la version ne peuvent pas être définis en même temps.
- Recommandation : Définissez le timestamp ou la version dans les paramètres delta.
Code d’erreur : DF-Delta-InvalidProtocolVersion
- Message : version du protocole de table Delta non prise en charge, reportez-vous à https://docs.delta.io/latest/versioning.html#-table-version pour obtenir des informations de contrôle de version.
- Cause : les flux de données ne prennent pas en charge cette version du protocole de table Delta.
- Recommandation : utilisez une version inférieure du protocole de table Delta.
Code d’erreur : DF-DELTA-InvalidTableOperationSettings
- Message : les options Recréer et Tronquer ne peuvent pas être indiquées en même temps.
- Cause : Les options Recréer et Tronquer ne peuvent pas être spécifiées simultanément.
- Recommandation : Mettez à jour les paramètres delta pour bénéficier d'une opération Recréer ou Tronquer.
Code d’erreur : DF-DELTA-KeyColumnMissed
- Message : les colonnes clés doivent être spécifiées pour les opérations qui ne peuvent pas être insérées.
- Cause : les colonnes clés sont manquantes pour les opérations non insérables.
- Recommandation : pour obtenir des opérations non insérables, spécifiez une ou plusieurs colonnes clés sur le récepteur delta.
Code d’erreur : DF-Dynamics-InvalidNullAlternateKeyColumn
- Message : Aucune valeur de colonne de la clé de remplacement ne peut être NULL.
- Cause : La valeur de votre colonne de clé alternative ne peut pas être NULL.
- Recommandation : vérifiez que la valeur de votre colonne de votre clé alternative n’est pas NULL.
Code d’erreur : DF-Dynamics-TooMuchAlternateKey
- Cause : un champ de recherche avec plusieurs références de clé de remplacement n’est pas valide.
- Recommandation : Vérifiez votre mappage de schéma et vérifiez que chaque champ de recherche a une seule clé alternative.
Code d’erreur : DF-Excel-DifferentSchemaNotSupport
- Message : la lecture des fichiers Excel avec un schéma différent n’est pas prise en charge pour le moment.
- Cause : La lecture de fichiers Excel à l'aide d'autres schémas n'est pas prise en charge pour le moment.
-
Recommandation : appliquez une des options suivantes pour résoudre ce problème :
- Utilisez l'activité de flux de données ForEach + pour lire les feuilles de calcul Excel une par une.
- Mettez à jour manuellement le schéma de chaque feuille de calcul pour avoir les mêmes colonnes avant de lire les données.
Code d’erreur : DF-Excel-InvalidDataType
- Message : Type de données non pris en charge.
- Cause : Le type de données n'est pas pris en charge.
- Recommandation : remplacez le type de données par « string » pour les colonnes de données d'entrée associées.
Code d’erreur : DF-Excel-InvalidFile
- Message : un fichier Excel non valide est fourni alors que seuls les fichiers .xlsx et .xls sont pris en charge.
- Cause : Les fichiers Excel fournis ne sont pas valides.
-
Recommandation : Utilisez le caractère générique pour filtrer et récupérer les fichiers Excel
.xlset.xlsxavant de lire les données.
Code d’erreur : DF-Excel-InvalidRange
- Message : Une plage non valide est fournie.
- Cause : La plage fournie n'est pas valide.
- Recommandation : vérifiez la valeur du paramètre et indiquez la plage valide à l’aide de la référence suivante : format Excel dans les propriétés d’Azure Data Factory-Dataset.
Code d’erreur : DF-Excel-InvalidWorksheetConfiguration
- Message : Le nom et l’index d’une feuille Excel ne peuvent pas exister en même temps.
- Cause : Le nom et l'index de la feuille Excel sont fournis en même temps.
- Recommandation : pour lire les données Excel, vérifiez la valeur du paramètre et spécifiez le nom ou l'index de la feuille.
Code d’erreur : DF-Excel-WorksheetConfigMissed
- Message : Le nom ou l’index de la feuille de calcul Excel est requis.
- Cause : La configuration fournie pour la feuille de calcul Excel n'est pas valide.
- Recommandation : pour lire les données Excel, vérifiez la valeur du paramètre et spécifiez le nom ou l'index de la feuille.
Code d’erreur : DF-Excel-WorksheetNotExist
- Message : La feuille de calcul Excel n’existe pas.
- Cause : Le nom ou l'index fourni pour la feuille de calcul n'est pas valide.
- Recommandation : pour la feuille afin de lire les données Excel, vérifiez la valeur du paramètre et spécifiez un nom ou un index valide.
Code d'erreur : DF-Executor-AcquireStorageMemoryFailed
- Message : Le transfert de la mémoire de déroulement vers la mémoire de stockage a échoué. Le cluster a manqué de mémoire pendant l'exécution. Veuillez réessayer en utilisant un runtime d'intégration avec plus de cœurs et/ou un type de calcul à mémoire optimisée.
- Cause : Le cluster n'a pas assez de mémoire.
- Recommandation : utilisez un runtime d'intégration avec plus de cœurs et/ou le type de calcul à mémoire optimisée.
Code d’erreur : DF-Executor-BlockCountExceedsLimitError
- Message : Le nombre de blocs non validés ne peut pas dépasser la limite maximale de 100 000 blocs. Vérifiez la configuration de l’objet blob.
- Cause : Le nombre maximal de blocs non validés dans un objet blob est de 100 000.
- Recommandation : Pour plus d’informations sur ce problème, contactez l’équipe produit Microsoft.
Code d’erreur : DF-Executor-BroadcastFailure
Message : L’exécution du flux de données a échoué pendant l’échange de diffusion. Les causes potentielles incluent des connexions à des sources mal configurées ou une erreur de délai d’expiration de la jointure de diffusion. Pour vous assurer que les sources sont correctement configurées, testez la connexion ou exécutez un aperçu des données sources dans une session de débogage de flux de données. Pour éviter le délai d’expiration de la jointure de diffusion, vous pouvez choisir l’option de diffusion « Désactivé » dans les transformations de jointure/d’existence/de recherche. Si vous envisagez d’utiliser l’option de diffusion pour améliorer les performances, assurez-vous que les flux de diffusion peuvent produire des données dans un délai de 60 secondes pour les exécutions de débogage et un délai de 300 secondes pour les exécutions de travaux. Si le problème persiste, contactez le support.
Cause :
- L’erreur de connexion/configuration source peut entraîner une défaillance de diffusion dans les transformations de jointure/d’existence/de recherche.
- Le délai d’expiration par défaut de la diffusion est de 60 secondes dans les exécutions de débogage et de 300 secondes dans les exécutions de travaux. Dans la jointure de diffusion, le flux choisi pour la diffusion semble être trop volumineux pour produire des données respectant cette limite. Si une jointure de diffusion n’est pas utilisée, la diffusion par défaut effectuée par un flux de données peut atteindre la même limite.
Recommandation :
- Affichez l’aperçu des données au niveau des sources pour vérifier que les sources sont bien configurées.
- Désactivez l’option de diffusion ou évitez de diffuser des flux de données volumineux dont le traitement peut prendre plus de 60 secondes. Choisissez plutôt un flux plus petit à diffuser.
- Les fichiers sources et les tables SQL/Data Warehouse volumineux sont généralement de mauvais candidats.
- En l’absence d’une diffusion de la jonction, utilisez un cluster plus grand si l’erreur se produit.
- Si le problème persiste, contactez le support client.
Code d’erreur : DF-Executor-BroadcastTimeout
Message: erreur de délai d’expiration de la jointure de diffusion. Vérifiez que la diffusion en streaming produit des données en moins de 60 s dans les exécutions de débogage et en moins de 300 s dans les exécutions de travaux.
Cause : Le délai d’expiration par défaut de la diffusion est de 60 secondes pour les exécutions de débogage et de 300 secondes pour les exécutions de travaux. Le flux choisi pour la diffusion est trop volumineux pour produire des données respectant cette limite.
Recommandation : Sous l’onglet Optimiser, vérifiez les transformations de jointure, d’existence et de recherche de votre flux de données. L’option par défaut pour la diffusion est Auto. Si l’option Auto est définie ou que vous indiquez manuellement la diffusion du côté gauche ou droit sous Fixe, vous pouvez soit définir une configuration de runtime d’intégration Azure plus importante, soit désactiver la diffusion. Pour obtenir des performances optimales dans les flux de données, nous vous recommandons d’autoriser Spark à diffuser à l’aide de l’option Auto et d’utiliser un runtime d’intégration Azure à mémoire optimisée.
Si vous exécutez le flux de données dans une exécution de test de débogage à partir d’une exécution de pipeline de débogage, vous pouvez rencontrer cette situation plus fréquemment. L’occurrence la plus fréquente de l’erreur est due au fait qu’Azure Data Factory limite le délai d’attente de diffusion à 60 secondes pour maintenir une expérience de débogage plus rapide. Vous pouvez étendre ce délai d’expiration au délai de 300 secondes d’une exécution déclenchée. Pour ce faire, vous pouvez utiliser l’option Déboguer>Utiliser le runtime d’activité afin d’utiliser le runtime d’intégration Azure défini dans votre activité de pipeline Exécuter un flux de données.
Message: erreur de délai d’expiration de la jointure de diffusion. Pour éviter ce problème, vous pouvez choisir l’option de diffusion « Désactivé » dans la transformation de recherche/existence/jonction. Si vous envisagez de diffuser l’option de jonction pour améliorer les performances, assurez-vous que le flux de diffusion peut produire des données dans un délai de 60 secondes dans des exécutions de débogage et un délai de 300 secondes dans les exécutions de travaux.
Cause : Le délai d’expiration par défaut de la diffusion est de 60 secondes dans les exécutions de débogage et de 300 secondes dans les exécutions de travaux. Dans la jointure de diffusion, le flux choisi pour la diffusion est trop volumineux pour produire des données respectant cette limite. Si une jointure de diffusion n’est pas utilisée, la diffusion par défaut effectuée par un flux de données peut atteindre la même limite.
Recommandation : Désactivez l’option de diffusion ou évitez de diffuser des flux de données volumineux pour lesquels le traitement peut prendre plus de 60 secondes. Choisissez un flux plus petit à diffuser. Les fichiers sources et les tables Azure SQL Data Warehouse volumineux ne sont généralement pas de bons choix. En l’absence d’une jointure de diffusion, utilisez un cluster plus grand si cette erreur se produit.
Code d’erreur : DF-Executor-ColumnNotFound
- Message : Le nom de colonne utilisé dans l’expression n’est pas disponible ou n’est pas valide.
- Cause : Un nom de colonne non valide ou non disponible est utilisé dans une expression.
- Recommandation : Vérifiez les noms de colonne utilisés dans les expressions.
Code d’erreur : DF-Executor-Conversion
- Message : Échec de conversion en date ou heure en raison d’un caractère non valide
- Cause : Les données ne sont pas au format attendu.
- Recommandation : Utilisez le type de données correct.
Code d’erreur : DF-Executor-DriverError
- Message : INT96 est un type de timestamp hérité qui n’est pas pris en charge par le flux de données ADF. Envisagez de mettre à niveau le type de colonne vers les types les plus récents.
- Cause : Erreur de pilote.
- Recommandation : INT96 est un type d’horodatage hérité que le flux de données Azure Data Factory ne prend en charge. Envisagez de mettre à niveau le type de colonne vers le type le plus récent.
Code d'erreur : DF-Executor-FieldNotExist
- Message : Champ inexistant dans la structure.
- Cause : Des noms de champs non valides ou non disponibles sont utilisés dans les expressions.
- Recommandation : Vérifiez les noms de champs utilisés dans les expressions.
Code d’erreur : DF-Executor-illegalArgument
- Message : vérifiez que la clé d’accès de votre service lié est correcte
- Cause : Le nom du compte ou la clé d’accès est incorrect.
- Recommandation : Vérifiez que le nom du compte ou la clé d'accès spécifiés dans votre service lié sont corrects.
Code d’erreur : DF-Executor-IncorrectLinkedServiceConfiguration
-
Message : les causes possibles sont
- Le service lié est configuré de manière incorrecte en tant que type « Stockage Blob Azure », et non « Azure DataLake Storage Gen2 » et l’espace de noms hiérarchique est activé. Créez un service lié de type « Azure DataLake Storage Gen2 » pour le compte de stockage en question.
- Certains scénarios avec toutes les combinaisons de « Effacer le dossier », « Option de nom de fichier » non par défaut, le partitionnement « Clé » peut échouer avec un service lié d’objets BLOB sur un compte de stockage activé pour l’espace de noms hiérarchique. Vous pouvez désactiver ces paramètres de flux de données (si activé) et réessayer si vous ne souhaitez pas créer un service lié Gen2.
- Cause : l’opération de suppression sur le compte Azure Data Lake Storage Gen2 a échoué, car son service lié est correctement configuré comme Stockage Blob Azure.
- Recommandation : créez un service lié Azure Data Lake Storage Gen2 pour le compte de stockage. Si cela n’est pas possible, certains scénarios connus comme Effacer le dossier, l’option Nom de fichier non par défaut, le partitionnement de Clés dans toutes les combinaisons peut échouer avec un service lié Stockage Blob Azure sur un compte de stockage avec espace de noms hiérarchique activé. Vous pouvez désactiver ces paramètres de flux de données si vous les avez activés et réessayez.
Code d’erreur : DF-Executor-InternalServerError
- Message : échec de l’exécution du flux de données avec une erreur de serveur interne, réessayez ultérieurement. Si le problème persiste, contactez le support technique Microsoft pour obtenir de l’aide.
- Cause : l’exécution du flux de données a échoué en raison de l’erreur système.
- Recommandation : pour résoudre ce problème, reportez-vous aux erreurs internes du serveur.
Code d’erreur : DF-Executor-InvalidColumn
- Message : Le nom de colonne doit être spécifié dans la requête, définissez un alias si vous utilisez une fonction SQL.
- Cause : Aucun nom de colonne n’est spécifié.
- Recommandation : Définissez un alias si vous utilisez une fonction SQL telle que min() ou max().
Code d'erreur : DF-Executor-InvalidInputColumns
- Message : La colonne de la configuration source est introuvable dans le schéma des données sources.
- Cause : Des colonnes non valides sont fournies sur la source.
- Recommandation : Vérifiez les colonnes dans la configuration source et assurez-vous qu’il s’agit du sous-ensemble des schémas des données sources.
Code d'erreur : DF-Executor-InvalidOutputColumns
- Message : Le résultat ne contient aucune colonne de sortie. Veuillez vous assurer qu'au moins une colonne est mappée.
- Cause : Aucune colonne n'est mappée.
- Recommandation : vérifiez le schéma du récepteur pour vous assurer qu'au moins une colonne est mappée.
Code d'erreur : DF-Executor-InvalidPartitionFileNames
- Message : les noms de fichiers ne peuvent pas comporter de valeurs vides lorsque l'option de nom de fichier est définie selon la partition.
- Cause : Des noms de fichiers de partition non valides sont fournis.
- Recommandation : vérifiez que les paramètres de votre récepteur sont définis sur les valeurs de noms de fichiers appropriées.
Code d'erreur : DF-Executor-InvalidPath
- Message : le chemin d’accès ne correspond à aucun fichier. Assurez-vous que le fichier/dossier existe et qu'il n'est pas masqué.
- Cause : Un chemin d’accès à un fichier/dossier non valide est fourni. Celui-ci est introuvable ou inaccessible.
- Recommandation : vérifiez le chemin d'accès au fichier/dossier, et assurez-vous qu'il existe et qu'il est accessible dans votre stockage.
Code d’erreur : DF-Executor-InvalidStageConfiguration
- Message : le stockage avec l’authentification d’identité managée affectée par l’utilisateur en préproduction n’est pas pris en charge.
- Cause : une exception est survenue en raison d’une configuration intermédiaire non valide.
- Recommandation : l’authentification d’identité managée affectée par l’utilisateur n’est pas prise en charge en préproduction. Utilisez une authentification différente pour créer un service lié Azure Data Lake Storage Gen2 ou Stockage Blob Azure, puis utilisez-la comme préproduction dans les flux de données de mappage.
Code d’erreur : DF-Executor-InvalidType
- Message : Vérifiez que le type de paramètre correspond au type de valeur transmis. Le passage de paramètres flottants à partir de pipelines n’est pas pris en charge actuellement.
- Cause : Les types de données sont incompatibles entre le type déclaré et la valeur réelle du paramètre.
- Recommandation : Vérifiez que les valeurs de paramètre passées dans le flux de données correspondent au type déclaré.
Code d’erreur : DF-Executor-OutOfDiskSpaceError
- Message : Erreur interne du serveur
- Cause : Le cluster manque d’espace disque.
- Recommandation : Relancez le pipeline. Si cela ne résout pas le problème, contactez le support technique.
Code d’erreur : DF-Executor-OutOfMemoryError
- Message : Le cluster a rencontré un problème de mémoire insuffisante pendant l’exécution, réessayez en utilisant un runtime d’intégration avec un nombre de cœurs plus élevé et/ou un type de calcul à mémoire optimisée.
- Cause : Le cluster manque de mémoire.
- Recommandation : Les clusters de débogage sont destinés au développement. Utilisez l’échantillonnage des données ainsi que le type et la taille de calcul appropriés pour exécuter la charge utile. Pour obtenir des conseils sur les performances, consultez le guide des performances de flux de données de mappage.
Code d'erreur : DF-Executor-OutOfMemorySparkBroadcastError
- Message : Le jeu de données diffusé explicitement à l'aide de l’option gauche/droite doit être suffisamment petit pour tenir dans la mémoire du nœud. Pour contourner ce problème, vous pouvez choisir l'option de diffusion « Désactivé » dans la transformation de recherche/existence/jonction, ou utiliser un runtime d'intégration avec plus de mémoire.
- Cause : La taille de la table diffusée dépasse de loin la limite de mémoire du nœud.
- Recommandation: l’option de diffusion gauche/droite ne doit être utilisée que pour des tailles de jeu de données plus petites, qui peuvent s’adapter à la mémoire du nœud. Veillez à configurer la taille du nœud de manière appropriée ou à désactiver l’option de diffusion.
Code d’erreur : DF-Executor-OutOfMemorySparkError
- Message : les données peuvent être trop volumineuses pour s’adapter à la mémoire.
- Cause : la taille des données dépasse de loin la limite de mémoire du nœud.
- Recommandation : augmentez le nombre de cœurs et basculez vers le type de calcul optimisé en mémoire.
Code d’erreur : DF-Executor-ExpressionParseError
- Message : Impossible d’analyser l’expression.
- Cause : Une expression a généré des erreurs d’analyse en raison d’une mise en forme incorrecte.
- Recommandation : Vérifiez la mise en forme dans l’expression.
Code d’erreur : DF-Executor-PartitionDirectoryError
- Message : Le chemin source spécifié comporte plusieurs répertoires partitionnés (par exemple, <Chemin source>/<Répertoire racine de partition 1>/a=10/b=20, <Chemin source>/<Répertoire racine de partition 2>/c=10/d=30), un répertoire partitionné avec un autre fichier ou un répertoire non partitionné (par exemple, <Chemin source>/<Répertoire racine de partition 1>/a=10/b=20, <Chemin source>/Répertoire 2/fichier1). Supprimez le répertoire racine de la partition du chemin source et lisez-le par le biais d’une transformation source distincte.
- Cause : Le chemin source comporte plusieurs répertoires partitionnés ou un répertoire partitionné avec un autre fichier ou un répertoire non partitionné.
- Recommandation : Supprimez le répertoire racine partitionné du chemin source et lisez-le par le biais d’une transformation source distincte.
Code d’erreur : DF-Executor-RemoteRPCClientDisassociated
- Message : Travail abandonné en raison d’un échec d’étape. Client RPC dissocié. Cette erreur est probablement provoquée par des conteneurs dépassant des seuils ou des problèmes réseau.
- Cause : L’exécution de l’activité de flux de données a échoué en raison du problème réseau temporaire ou parce que la mémoire d’un nœud du cluster Spark est insuffisante.
-
Recommandation : Utilisez les options suivantes pour résoudre ce problème :
Option 1 : utilisez un cluster puissant (la mémoire des nœuds lecteur et exécuteur est suffisante pour gérer les Big Data) afin d’exécuter des pipelines de flux de données avec le paramètre « Type de calcul » sur « Mémoire optimisée ». Les paramètres sont affichés dans l’image suivante.
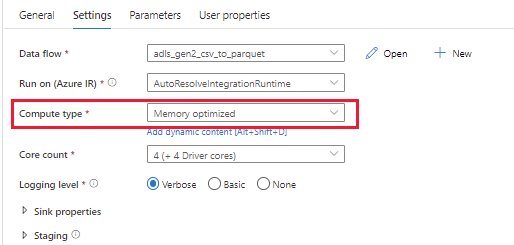
Option 2 : utilisez une plus grande taille de cluster (par exemple, 48 cœurs) pour exécuter vos pipelines de flux de données. Vous pouvez en savoir plus sur la taille du cluster dans ce document : Taille du cluster.
Option 3 : répartissez vos données d’entrée. Pour la tâche en cours d’exécution sur le cluster Spark de flux de données, une partition est une tâche et s’exécute sur un nœud. Si les données d’une partition sont trop volumineuses, la tâche associée en cours d’exécution sur le nœud doit consommer plus de mémoire que le nœud lui-même, ce qui entraîne une défaillance. Par conséquent, vous pouvez utiliser la répartition pour éviter une asymétrie des données, vous assurer que la taille des données dans chaque partition est moyenne et que la consommation de mémoire n’est pas trop importante.
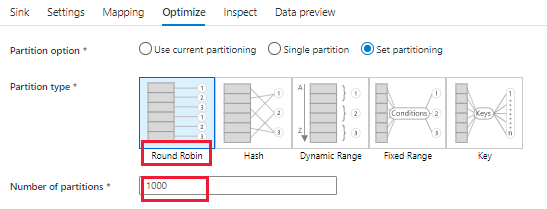
Notes
Vous devez évaluer la taille des données ou le nombre de partitions de données d’entrée, puis définir un numéro de partition raisonnable sous « Optimiser ». Par exemple, le cluster que vous utilisez dans l’exécution du pipeline de flux de données comporte 8 cœurs et la mémoire de chaque cœur est de 20 Go, mais les données d’entrée sont de 1000 Go avec 10 partitions. Si vous exécutez le flux de données directement, il rencontrera le problème OOM, car 1000 Go/10 > 20 Go. Il est donc préférable de définir le nombre de répartitions sur 100 (1000 Go/100 < 20 Go).
Option 4 : Réglez et optimisez les paramètres de la source/du récepteur/de la transformation. Par exemple, essayez de copier tous les fichiers dans un conteneur et n’utilisez pas le modèle de caractère générique. Pour plus d’informations, reportez-vous au Guide des performances et réglages des flux de données de mappage.
Code d’erreur : DF-Executor-SourceInvalidPayload
- Message : L’exécution de l’aperçu des données, du débogage et du flux de données de pipeline a échoué car le conteneur n’existe pas.
- Cause : Un jeu de données comprend un conteneur qui n’existe pas dans le stockage.
- Recommandation : Vérifiez que le conteneur référencé dans votre jeu de données existe et est accessible.
Code d’erreur : DF-Executor-StoreIsNotDefined
- Message: la configuration du magasin n’est pas définie. Cette erreur peut être provoquée par une attribution incorrecte de paramètre dans le pipeline.
- Cause : La configuration fournie pour le magasin n'est pas valide.
- Recommandation : Vérifiez l’attribution de la valeur du paramètre dans le pipeline. Une expression de paramètre peut contenir des caractères non valides.
Code d’erreur : DF-Executor-StringValueNotInQuotes
- Message : les opérandes de colonne ne sont pas autorisés dans les expressions littérales.
- Cause : la valeur d’un paramètre de chaîne ou d’une valeur de chaîne attendue n’est pas placée entre guillemets uniques.
- Recommandation : près des numéros de ligne mentionnés dans le script de flux de données, vérifiez que la valeur d’un paramètre de chaîne ou d’une valeur de chaîne attendue est placée entre guillemets uniques.
Code d’erreur : DF-Executor-SystemImplicitCartesian
- Message : le produit cartésien implicite pour la jointure INNER n’est pas pris en charge. Utilisez CROSS JOIN à la place. Les colonnes utilisées dans la jointure doivent créer une clé unique pour les lignes.
- Cause : Les produits cartésiens implicites pour les jointures INNER entre les plans logiques ne sont pas pris en charge. Si vous utilisez des colonnes dans la jointure, créez une clé unique.
- Recommandation : Pour les jointures non basées sur l’égalité, utilisez CROSS JOIN.
Code d’erreur : DF-Executor-SystemInvalidJson
- Message : Erreur d’analyse JSON, encodage ou multiligne non pris en charge.
- Cause : Problèmes possibles avec le fichier JSON (encodage non pris en charge, octets endommagés ou utilisation de la source JSON comme document unique sur de nombreuses lignes imbriquées).
- Recommandation : Vérifiez que l’encodage du fichier JSON est pris en charge. Sur la transformation source qui utilise un jeu de données JSON, développez Paramètres JSON et activez Un seul document.
Code d’erreur : DF-Executor-UnauthorizedStorageAccess
Cause : Vous n’êtes pas autorisé à accéder au compte de stockage en raison de rôles manquants pour l’authentification de l’identité managée/du principal de service ou des paramètres de pare-feu réseau.
Recommandation : Lors de l’utilisation de l’authentification de l’identité managée/du principal de service,
- Pour la source: dans l’Explorateur Stockage, accordez à l’identité managée/au principal de service au moins l’autorisation Exécution à l’ensemble des dossiers en amont et au système de fichiers, et l’autorisation Lecture pour les fichiers à copier. Dans le contrôle d’accès (IAM), vous pouvez également accorder à l’identité managée/au principal de service au moins un rôle Lecteur de données Blob du stockage.
- Pour le récepteur: dans l’Explorateur Stockage, accordez à l’identité managée/au principal de service au moins l’autorisation Exécution à l’ensemble des dossiers en amont et au système de fichiers, et l’autorisation Écriture pour le dossier du récepteur. Dans le contrôle d’accès (IAM), vous pouvez également accorder à l’identité managée/au principal de service au moins un rôle Contributeur aux données Blob du stockage.
Vérifiez également que les paramètres de pare-feu réseau dans le compte de stockage sont correctement configurés, car l’activation des règles de pare-feu pour votre compte de stockage bloque les demandes entrantes pour les données par défaut, sauf si les demandes proviennent d’un service fonctionnant au sein d’un réseau virtuel Azure ou d’adresses IP publiques autorisées.
Code d’erreur : DF-Executor-UnreachableStorageAccount
- Message : Le système ne peut pas résoudre l’adresse IP de l’hôte. Vérifiez que votre nom d’hôte est correct ou si votre serveur DNS est en mesure de résoudre correctement l’hôte en adresse IP
- Cause : Impossible d’atteindre le compte de stockage donné.
- Recommandation : Vérifiez le nom du compte de stockage et assurez-vous que le compte de stockage existe.
Code d’erreur : DF-Executor-UserError
- Message: Échec du travail en raison de la raison : GetjobStatus, Échec du travail - com.microsoft.dataflow.issues : DF-MICROSOFT365-CONSENTPENDING
- Cause: l’approbation de l’accès privilégié est nécessaire pour copier des données. Il s’agit d’un problème de configuration utilisateur.
- Recommandation: Demandez à l’administrateur du locataire d’approuver votre demande d’accès aux données dans Office365 dans le module de gestion des accès privilégiés (PAM).
Code d’erreur : DF-Executor-DSLParseError
- Message : le script de flux de données ne peut pas être analysé.
- Cause : le script de flux de données comporte des erreurs d’analyse.
- Recommandation : recherchez les erreurs (par exemple, symboles manquants, symboles indésirables) à proximité des numéros de ligne mentionnés dans le script de flux de données.
Code d’erreur : DF-Executor-IncorrectQuery
- Message : syntaxe incorrecte. Erreur SQL Server rencontrée lors de la lecture à partir de la table donnée ou lors de l’exécution de la requête donnée.
- Cause : la requête envoyée était incorrecte du point de vue syntaxique.
- Recommandation : vérifiez l’exactitude syntaxique de la requête donnée. Veillez à avoir une chaîne de requête non entre guillemets lorsqu’elle est référencée en tant que paramètre de pipeline.
Code d’erreur : DF-Executor-ParameterParseError
- Message : le flux de paramètres comporte des erreurs d’analyse. Il est possible que le fait de ne pas respecter le type de données des paramètres soit l’une des causes.
- Cause : erreurs d’analyse dans un ou plusieurs paramètres donnés.
- Recommandation : vérifiez les paramètres ayant des erreurs, vérifiez l’utilisation des fonctions appropriées et respectez les types de données donnés.
Code d’erreur : DF-File-InvalidSparkFolder
- Message : échec de lecture du pied de page du fichier.
- Cause : le dossier _spark_metadata est créé par le travail de streaming structuré.
- Recommandation : Supprimez le dossier _spark_metadata s’il existe.
Code d’erreur : DF-GEN2-InvalidAccountConfiguration
- Message : vous devez spécifier l’une des clés de compte, jeton SAS, client/SpnId/SpnCredential/SpnCredentialType, userAuth ou MiServiceUri/miServiceToken.
- Cause: des informations d’identification non valides sont fournies dans le service lié Azure Data Lake Storage (ADLS) Gen2.
- Recommandation : Mettez à jour le service lié ADLS Gen2 afin de bénéficier de la configuration appropriée pour les informations d'identification.
Code d’erreur : DF-GEN2-InvalidAuthConfiguration
- Message : seule une des trois méthodes d’authentification (Clé, ServicePrincipal et MI) peut être utilisée.
- Cause : La méthode d'authentification fournie dans le service lié ADLS Gen2 n'est pas valide.
- Recommandation : Mettez à jour le service lié ADLS Gen2 pour bénéficier d'une des trois méthodes d'authentification disponibles (par clé, ServicePrincipal et MI).
Code d'erreur : DF-GEN2-InvalidCloudType
- Message : le type de Cloud n’est pas valide.
- Cause : Le type de cloud fourni n'est pas valide.
- Recommandation : Vérifiez le type de cloud dans le service lié ADLS Gen2 associé.
Code d’erreur : DF-GEN2-InvalidServicePrincipalCredentialType
- Message : Type d'informations d'identification du principal de service non valide.
- Cause : Le type d'informations d'identification du principal de service n'est pas valide.
- Recommandation : mettez à jour le service lié ADLS Gen2 afin de définir le type d'informations d'identification approprié pour le principal de service.
Code d’erreur : DF-GEN2-InvalidStorageAccountConfiguration
- Message : L’opération d’objet blob n’est pas prise en charge sur les anciens comptes de stockage. La création d’un compte de stockage peut résoudre le problème.
- Cause : le compte de stockage est trop ancien.
- Recommandation : créez un nouveau compte de stockage.
Code d’erreur : DF-GitHub-WriteNotSupported
- Message : Le magasin GitHub n’autorise pas les écritures.
- Cause : Le magasin GitHub est en lecture seule.
- Recommandation : La définition de l'entité magasin se trouve à un autre emplacement.
Code d’erreur : DF-Hive-InvalidBlobStagingConfiguration
- Message : les propriétés de mise en lots du stockage d’objets BLOB doivent être spécifiées.
- Cause : La configuration de la mise en lots fournie dans Hive n'est pas valide.
- Recommandation : vérifiez que la clé de compte, le nom du compte et le conteneur sont correctement définis dans le service lié Blob associé qui est utilisé pour la mise en lots.
Code d’erreur : DF-Hive-InvalidDataType
- Message : colonne non prise en charge.
- Cause : les colonnes fournies ne sont pas prises en charge.
- Recommandation : Mettez à jour la colonne de données d'entrée pour qu'elle corresponde au type de données pris en charge par Hive.
Code d’erreur : DF-Hive-InvalidGen2StagingConfiguration
Message : la mise en lots du stockage ADLS Gen2 ne prend en charge que les informations d’identification de la clé principale du service.
Cause : La configuration de la mise en lots fournie dans Hive n'est pas valide.
Recommandation : mettez à jour le service lié ADLS Gen2 associé qui est utilisé pour la mise en lots. Actuellement, seules les informations d'identification de la clé du principal de service sont prises en charge.
Message : les propriétés de mise en lots du stockage d’objets ADLS Gen2 doivent être spécifiées. L’une des clés ou tenant/spnId/spn Credential/spnCredentialType ou miServiceUri/miServiceToken est requise.
Cause : La configuration de la mise en lots fournie dans Hive n'est pas valide.
Recommandation : Mettez à jour le service lié ADLS Gen2 associé avec les informations d'identification appropriées utilisées pour la mise en lots dans Hive.
Code d’erreur : DF-Hive-InvalidStorageType
- Message : le type de stockage peut être un objet BLOB ou un Gen2.
- Cause : Seul le type de stockage Azure Blob ou ADLS Gen2 est pris en charge.
- Recommandation : Choisissez le type de stockage qui convient à partir d'Azure Blob ou d'ADLS Gen2.
Code d’erreur : DF-JSON-WrongDocumentForm
- Message : des enregistrements mal formés sont détectés dans l’inférence de schéma. Mode d’analyse : FAILFAST. Cela peut être dû à une sélection incorrecte dans le formulaire de document pour analyser les fichiers JSON. Veuillez essayer un autre « Formulaire de document » (document/document unique par ligne/tableau de documents) sur la source JSON.
- Cause : un formulaire de document incorrect est sélectionné pour analyser les fichiers JSON.
- Recommandation : essayez un autre formulaire de document (Document unique/Document par ligne/Tableau de documents) dans les paramètres JSON. La plupart des cas d’analyse d’erreurs sont causés par une configuration incorrecte.
Code d’erreur : DF-MICROSOFT365-CONSENTPENDING
- Message : un consentement administrateur est en attente.
- Cause : un consentement administrateur est manquant.
- Recommandation : fournissez le consentement, puis réexécutez le pipeline. Pour fournir un consentement, reportez-vous aux requêtes PAM.
Code d’erreur : DF-MSSQL-ErrorRowsFound
- Cause : Des lignes d’erreur/non valides ont été trouvées lors de l’écriture dans le récepteur Azure SQL Database.
- Recommandation : recherchez les lignes d'erreur à l'emplacement de stockage des données rejetées (s’il est configuré).
Code d'erreur : DF-SQLDW-ExportErrorRowFailed
- Message : Une exception s'est produite lors de l'écriture des lignes d'erreur dans le stockage.
- Cause : Une exception s'est produite lors de l'écriture des lignes d'erreur dans le stockage.
- Recommandation : Vérifiez la configuration du service lié des données rejetées.
Code d’erreur : DF-MSSQL-InvalidAuthConfiguration
- Message : seule une des trois méthodes d’authentification (Clé, ServicePrincipal et MI) peut être utilisée.
- Cause : La méthode d'authentification fournie dans le service lié MSSQL n'est pas valide.
- Recommandation : Vous ne pouvez spécifier qu'une des trois méthodes d'authentification disponibles (par clé, ServicePrincipal ou MI) dans le service lié MSSQL associé.
Code d’erreur : DF-MSSQL-InvalidCloudType
- Message : le type de Cloud n’est pas valide.
- Cause : Le type de cloud fourni n'est pas valide.
- Recommandation : Vérifiez votre type de Cloud dans le service lié MSSQL associé.
Code d’erreur : DF-MSSQL-InvalidCredential
- Message: l’un des uuser/pwd ou tenant/SpnId/SpnKey ou MiServiceUri/miServiceToken doit être spécifié.
- Cause : Les informations d'identification fournies dans le service lié MSSQL ne sont pas valides.
- Recommandation : mettez à jour le service lié MSSQL associé avec les informations d'identification appropriées. Une des autorisations user/pwd, tenant/spnId/spnKey ou miServiceUri/miServiceToken doit aussi être spécifiée.
Code d’erreur : DF-MSSQL-InvalidDataType
- Message : champ non pris en charge.
- Cause : des champs non pris en charge sont fournis.
- Recommandation : modifiez la colonne de données d’entrée pour qu’elle corresponde au type de données pris en charge par MSSQL.
Code d'erreur : DF-MSSQL-InvalidFirewallSetting
- Message : La connexion TCP/IP à l'hôte a échoué. Assurez-vous qu’une instance de SQL Server est en cours d’exécution sur l’hôte et accepte les connexions TCP/IP au port. Vérifiez que les connexions TCP au port ne sont pas bloquées par un pare-feu.
- Cause : Le paramètre de pare-feu de la base de données SQL bloque l'accès au flux de données.
- Recommandation : vérifiez le paramètre de pare-feu de votre base de données SQL, et autorisez les services et ressources Azure à accéder à ce serveur.
Code d’erreur : DF-MSSQL-InvalidCertificate
- Message : Erreur de configuration du serveur SQL. Installez un certificat approuvé sur votre serveur ou remplacez le paramètre de chaîne de connexion « encrypt » par false et le paramètre de chaîne de connexion « trustServerCertificate » par true.
- Cause : Erreur de configuration du serveur SQL.
-
Recommandations : Installez un certificat approuvé sur votre serveur SQL ou remplacez le paramètre de chaîne de connexion
encryptpar false et le paramètre de chaîne de connexiontrustServerCertificatepar true.
Code d’erreur : DF-PGSQL-InvalidCredential
- Message : L’utilisateur et le mot de passe doivent être spécifiés.
- Cause : L'utilisateur/mot de passe est manquant.
- Recommandation : Assurez-vous que vous disposez des paramètres d'identification qui conviennent dans le service lié PostgreSQL associé.
Code d’erreur : DF-SAPODATA-InvalidRunMode
- Message : échec de l’exécution du flux de données avec un mode d’exécution non valide.
- Les causes possibles sont les suivantes :
- Seul le mode
fullLoadlecture peut être spécifié lorsqueenableCdca la valeur false. - Seul les modes d’exécution
incrementalLoadoufullAndIncrementalLoadpeut être spécifié lorsqueenableCdca la valeur true. - Seul
fullLoad,incrementalLoadoufullAndIncrementalLoadpeuvent être spécifiés.
- Seul le mode
- Recommandation : reconfigurez l’activité et réexécutez-la. Si le problème persiste, contactez le support technique Microsoft pour obtenir de l’aide.
Code d’erreur : DF-SAPODATA-StageLinkedServiceMissed
- Message : échec de l’exécution du flux de données lorsque le service lié intermédiaire n’existe pas dans DSL. Reconfigurez l’activité et réexécutez-la. Si le problème persiste, contactez le Support Microsoft pour obtenir une assistance supplémentaire.
- Cause : le service lié intermédiaire n’existe pas dans DSL.
- Recommandation : reconfigurez l’activité et réexécutez-la. Si le problème persiste, contactez le support technique Microsoft pour obtenir de l’aide.
Code d’erreur : DF-SAPOODATA-StageContainerMissed
- Message : le conteneur ou le système de fichiers est requis pour le stockage intermédiaire.
- Cause : aucun conteneur ou système de fichiers n’est spécifié pour le stockage intermédiaire.
- Recommandation : spécifiez le conteneur ou le système de fichiers pour le stockage intermédiaire.
Code d’erreur : DF-SAPODATA-StageFolderPathMissed
- Message : le chemin d’accès au dossier est requis pour le stockage intermédiaire.
- Cause : aucun chemin d’accès au dossier n’est spécifié pour le stockage intermédiaire.
- Recommandation : spécifiez le chemin d'accès au dossier de stockage intermédiaire.
Code d’erreur : DF-SAPODATA-ODataServiceOrEntityMissed
- Message : SAP servicePath et entityName sont tous deux requis dans l’opération import-schema, preview-data et read data.
- Cause : Le chemin du service et le nom de l’entité ne peuvent pas être nuls lors de l’importation du schéma, de l’aperçu des données ou de la lecture de données.
- Recommandation : spécifiez le chemin du service et le nom de l’entité lors de l’importation du schéma, de l’aperçu des données ou de la lecture de données.
Code d’erreur : DF-SAPODATA-TimeoutInvalid
- Message : le délai d’expiration n’est pas valide, il ne doit pas dépasser 7 jours.
- Cause : le délai d’expiration ne peut pas dépasser 7 jours.
- Recommandation : spécifiez le délai d’expiration valide.
Code d’erreur : DF-SAPODATA-ODataServiceMissed
- Message : SAP servicePath est requis lors de l’exploration du nom de l’entité.
- Cause : le chemin d’accès du service ne peut pas être nul lors de la navigation dans le nom de l’entité.
- Recommandation : spécifiez le chemin d’accès du service.
Code d’erreur : DF-SAPODATA-SystemError
- Message : erreur système : échec de l’obtention de deltaToken à partir de SAP. Contactez le support technique de Microsoft pour obtenir de l'aide.
- Cause : échec de l’obtention du jeton delta auprès de SAP.
- Recommandation : contactez le support technique de Microsoft pour obtenir de l'aide.
Code d’erreur : DF-SAPODATA-StageAuthInvalid
- Message : secret client fourni non valide
- Cause : les informations d’identification du principal de service du stockage intermédiaire ne sont pas correctes.
- Recommandation : testez la connexion dans votre service lié de stockage intermédiaire et vérifiez que les paramètres d’authentification dans votre stockage intermédiaire sont corrects.
Code d’erreur : DF-SAPODATA-NotReached
Causes et recommandations : échec de la création de la connexion OData à l’URL de la requête. Différentes causes peuvent être à l’origine de ce problème. Consultez la liste ci-dessous pour connaître les causes possibles et les recommandations associées.
Analyse de la cause Recommandation Votre serveur SAP est arrêté. Vérifiez que votre serveur SAP est démarré. Problème avec le proxy du runtime d’intégration auto-hébergé. Vérifiez le proxy du runtime d’intégration auto-hébergé. Entrée de paramètres incorrecte (par exemple, nom de serveur SAP ou mot de passe non valide) Vérifiez vos paramètres d’entrée : nom du serveur SAP, mot de passe.
Code d’erreur : DF-SAPODATA-NoneODPService
- Message : Le service odata actuel ne prend pas en charge l’extraction de données ODP. Activez ODP pour le service
- Cause : le service OData actuel ne prend pas en charge l’extraction de données ODP.
- Recommandation : activez ODP pour le service.
Code d’erreur : DF-SAPODP-AuthInvalid
- Message : nom ou mot de passe SapOdp incorrect
- Cause : nom ou mot de passe d’entrée incorrect
- Recommandation : vérifiez que votre nom ou mot de passe d’entrée est correct
Code d’erreur : DF-SAPODP-ContextInvalid
- Cause : la valeur de contexte n’existe pas dans SAP OPD.
- Recommandation : vérifiez la valeur de contexte et vérifiez qu’elle est valide.
Code d’erreur : DF-SAPODP-ContextMissed
Message : le contexte est requis
Causes et recommandations : Différentes causes peuvent être à l’origine de cette erreur. Consultez la liste ci-dessous pour obtenir une analyse des causes possibles et des recommandations associées.
Analyse de la cause Recommandation Votre valeur de contexte ne peut pas être vide lors de la lecture des données. Spécifiez le contexte. Votre valeur de contexte ne peut pas être vide lors de la recherche de noms d’objets. Spécifiez le contexte.
Code d’erreur : DF-SAPODP-DataflowSystemError
- Recommandation : Reconfigurez l’activité et réexécutez-la. Si le problème persiste, vous pouvez contacter le support technique Microsoft pour obtenir de l’aide.
Code d’erreur : DF-SAPODP-DataParsingFailed
- Cause : La plupart du temps, vous avez des paramètres de colonne masqués dans votre table SAP. Lorsque vous utilisez le flux de données de mappage SAP pour lire des données à partir du serveur SAP, il retourne tous les schémas (colonnes, y compris les colonnes masquées), mais les données retournées ne contiennent pas de valeurs associées. Ainsi, un mauvais alignement des données s’est produit et a entraîné un problème de valeur d’analyse ou un problème de valeurs de données incorrectes.
-
Recommandation : Il existe deux recommandations pour ce problème :
- Supprimez les paramètres masqués des colonnes associées via l’interface utilisateur SAP.
- Si vous souhaitez conserver les paramètres SAP existants inchangés, utilisez la fonctionnalité de masquage (ajoutez manuellement la propriété DSL
enableProjection:truedans le script) dans le flux de données de mappage SAP pour filtrer les colonnes masquées et continuer à lire les données.
Code d’erreur : DF-SAPODP-ObjectInvalid
- Cause : le nom de l’objet est introuvable ou n’est pas libéré.
- Recommandation : vérifiez le nom de l’objet et vérifiez qu’il est valide et déjà publié.
Code d’erreur : DF-SAPODP-ObjectNameMissed
- Message : 'objectName' (nom de l’objet SAP) est requis
- Cause : les noms d’objets doivent être définis lors de la lecture de données à partir de SAP ODP.
- Recommandation : spécifiez le nom de l’objet SAP ODP.
Code d’erreur : DF-SAPODP-SAPSystemError
-
Cause : il s’agit d’une erreur système SAP :
user id locked. - Recommandation : contactez l’administrateur SAP pour obtenir de l’aide.
Code d’erreur : DF-SAPODP-SessionTerminate
- Message : session interne terminée avec une erreur d’exécution RAISE_EXCEPTION (voir ST22)
- Cause : problèmes temporaires pour les objets SLT.
- Recommandation : réexécuter l’activité de flux de données.
Code d’erreur : DF-SAPODP-SHIROFFLINE
- Cause : le runtime d’intégration auto-hébergé est hors connexion.
- Recommandation : vérifiez l’état de votre runtime d’intégration auto-hébergé et vérifiez qu’il est en ligne.
Code d’erreur : DF-SAPODP-SLT-LIMITATION
- Message : la préversion n’est pas prise en charge dans le système SLT
- Cause : votre contexte ou objet se trouve dans le système SLT qui ne prend pas en charge la préversion. Il s’agit d’une limitation du système SLT SAP ODP.
- Recommandation : exécutez directement l’activité de flux de données.
Code d’erreur : DF-SAPODP-StageAuthInvalid
- Message : secret client fourni non valide
- Cause : les informations d’identification du certificat du principal de service du stockage intermédiaire ne sont pas correctes.
- Recommandation : vérifiez si la connexion de test réussit dans votre service lié de stockage intermédiaire et vérifiez que le paramètre d’authentification de votre stockage intermédiaire est correct.
- Message : échec de l’authentification de la demande sur le stockage
- Cause : la clé de votre stockage intermédiaire n’est pas correcte.
- Recommandation : vérifiez si la connexion de test réussit dans votre service lié de stockage intermédiaire et vérifiez que la clé de votre Stockage Blob Azure intermédiaire est correcte.
Code d’erreur : DF-SAPODP-StageBlobPropertyInvalid
- Message : échec de la lecture à partir du stockage intermédiaire : propriétés d’authentification du stockage intermédiaire d’objets BLOB non valides.
- Cause : les propriétés du stockage intermédiaire d’objets BLOB ne sont pas valides.
- Recommandation : Vérifiez le paramètre d’authentification dans votre service lié intermédiaire.
Code d’erreur : DF-SAPODP-StageContainerInvalid
- Message : impossible de créer un conteneur d’objets BLOB Azure
- Cause: le conteneur d’entrée n’existe pas dans votre stockage intermédiaire.
- Recommandation : entrez un nom de conteneur valide pour le stockage intermédiaire. Sélectionnez à nouveau un autre nom de conteneur ou créez un conteneur manuellement avec votre nom d’entrée.
Code d’erreur : DF-SAPODP-StageContainerMissed
- Message : le conteneur ou le système de fichiers est requis pour le stockage intermédiaire.
- Cause : votre conteneur ou le système de fichiers n’est pas spécifié pour le stockage intermédiaire.
- Recommandation : spécifiez le conteneur ou le système de fichiers pour le stockage intermédiaire.
Code d’erreur : DF-SAPODP-StageFolderPathMissed
- Message : le chemin d’accès au dossier est requis pour le stockage intermédiaire
- Cause : le chemin d’accès de votre dossier de stockage intermédiaire n’est pas spécifié.
- Recommandation : spécifiez le dossier de stockage intermédiaire.
Code d’erreur : DF-SAPODP-StageGen2PropertyInvalid
- Message : échec de la lecture à partir du stockage intermédiaire : propriétés d’authentification du stockage intermédiaire Gen2 non valides.
- Cause : les propriétés d’authentification de votre stockage intermédiaire Azure Data Lake Storage Gen2 ne sont pas valides.
- Recommandation : Vérifiez le paramètre d’authentification dans votre service lié intermédiaire.
Code d’erreur : DF-SAPODP-StageStorageServicePrincipalCertNotSupport
- Message : échec de la lecture à partir du stockage intermédiaire : l’authentification du stockage intermédiaire d’objets BLOB ne prend pas en charge la certification du principal du service.
- Cause : les informations d’identification du certificat du principal de service ne sont pas prises en charge pour le stockage intermédiaire.
- Recommandation : modifiez votre authentification pour ne pas utiliser les informations d’identification du certificat du principal de service.
Code d’erreur : DF-SAPODP-StageStorageTypeInvalid
- Message : votre type de stockage intermédiaire SapOdp n’est pas valide
- Cause : seuls Stockage Blob Azure et Azure Data Lake Storage Gen2 sont pris en charge pour la préproduction SAP ODP.
- Recommandation : sélectionnez Stockage Blob Azure ou Azure Data Lake Storage Gen2 comme stockage intermédiaire.
Code d’erreur : DF-SAPODP-SubscriberNameMissed
- Message : « subscriberName » est requis alors que l’option « Activer la capture de données modifiées » est sélectionnée
-
Cause : la propriété
subscriberNamedu service lié SAP est requis alors que l’option « Activer la capture de données modifiées » est sélectionnée. -
Recommandation : spécifiez le
subscriberNamedans le service lié SAP ODP.
Code d’erreur : DF-SAPODP-SystemError
- Cause : cette erreur est une erreur système de flux de données ou une erreur système de serveur SAP.
- Recommandation : consultez le message d’erreur. S’il contient la pile d’erreurs associée au serveur SAP, contactez l’administrateur SAP pour obtenir de l’aide. Sinon, contactez le support technique de Microsoft pour obtenir de l'aide.
Code d’erreur : DF-SAPODP-NotReached
Message : Impossible d’accéder au partenaire '.*'
Causes et recommandations : Il s’agit d’un problème de connectivité. Différentes causes peuvent être à l’origine de ce problème. Consultez la liste ci-dessous pour obtenir une analyse des causes possibles et des recommandations associées.
Analyse de la cause Recommandation Votre serveur SAP est arrêté. Vérifiez que votre serveur SAP est démarré. Votre adresse IP ou port du runtime d’intégration auto-hébergé n’est pas dans la règle de sécurité réseau SAP. Vérifiez que votre adresse IP ou port du runtime d’intégration auto-hébergé se trouve dans la règle de sécurité réseau SAP. Problème avec le proxy du runtime d’intégration auto-hébergé. Vérifiez le proxy du runtime d’intégration auto-hébergé. Entrée de paramètres incorrecte (par exemple, nom de serveur SAP ou adresse IP non valide). Vérifiez vos paramètres entrés : nom du serveur SAP, adresse IP.
Code d’erreur : DF-SAPODP-DependencyNotFound
- Message : Impossible de charger le fichier ou l’assembly 'sapnco, Version=*
- Cause : Vous ne téléchargez pas et n’installez pas le connecteur SAP .NET sur l’ordinateur du runtime d’intégration auto-hébergé.
- Recommandation : suivez la procédure Configurer un runtime d’intégration auto-hébergé pour configurer le runtime d’intégration auto-hébergé propre connecteur SAP de la capture des changements de données (CDC).
Code d’erreur : DF-SAPODP-NoAuthForFunctionModule
- Message : Autorisation REF manquante pour le module de fonction RODPS_REPL_CONTEXT_GET_LIST
- Cause : Absence d’autorisation pour exécuter le module de fonction associé.
- Recommandation : Suivez ces notes SAP pour ajouter le profil d’autorisation requis à votre compte SAP.
Code d’erreur : DF-SAPODP-OOM
- Message : Plus de mémoire disponible pour ajouter des lignes à une table interne
- Cause : Le connecteur SAP Table est soumis à une limitation pour l’extraction de tables volumineuses. Le connecteur SAP Table sous-jacent repose sur une RFC qui lit toutes les données de la table dans la mémoire du système SAP. Par conséquent, un problème de mémoire insuffisante (OOM) se produit lors de l’extraction de tables volumineuses.
- Recommandation : Utilisez le connecteur SAP CDC pour faire un chargement complet des données directement à partir de votre système source, puis déplacez le delta vers le serveur de réplication SAP Landscape Transformation (SLT) une fois que l’init sans delta est publié.
Code d’erreur : DF-SAPODP-SourceNotSupportDelta
- Message : La source .* ne prend pas en charge les deltas
- Cause : le contexte ODP/nom ODP que vous avez spécifié ne prend pas en charge le delta.
- Recommandation : Activez le mode delta pour votre source SAP, ou sélectionnez Complet sur chaque exécution en mode d’exécution dans le flux de données. Pour plus d’informations, consultez cette documentation.
Code d’erreur : DF-SAPODP-SAPI-LIMITATION
- Message : Numéro d’erreur 518, Source .* introuvable, non publiée ou non autorisée
- Cause: vérifiez si votre contexte est l’API SAP Service (SAPI). Le cas échéant, dans le contexte SAPI, vous pouvez extraire uniquement les extracteurs pertinents pour les tables SAP.
- Recommandations : Consultez cette documentation.
Code d’erreur : DF-SAPODP-KeyColumnsNotSpecified
- Message : une ou plusieurs colonnes clés doivent être spécifiées pour les opérations qui ne peuvent pas être insérées (mises à jour/suppressions)
- Cause : Cette erreur se produit lorsque vous ignorez la sélection des colonnes clés dans la table du récepteur.
- Recommandations : Autoriser les options de suppression, d’upsert et de mise à jour nécessite la spécification d’une colonne clé. Spécifiez une ou plusieurs colonnes pour la correspondance de lignes dans le récepteur.
Code d’erreur : DF-SAPODP-InsufficientResource
- Message : Un court vidage s’est produit dans une opération de base de données
- Cause : Le système SAP a manqué de ressources, ce qui a entraîné un court vidage sur le serveur SAP.
- Recommandations : Contactez votre administrateur SAP pour résoudre le problème dans l’instance SAP, puis réessayez.
Code d’erreur : DF-SAPODP-ExecuteFuncModuleWithPointerFailed
- Message : Échec de l’exécution du module de fonction .* avec le pointeur .*
- Cause : Problème avec le système SAP.
- Recommandations : Accédez à l’instance SAP et vérifiez ST22 (court vidage, similaire à un vidage de fenêtres), et passez en revue le code où l’erreur s’est produite. Dans la plupart des cas, SAP fournit des conseils sur différentes possibilités de résolution des problèmes.
Code d’erreur : DF-Snowflake-IncompatibleDataType
- Message : Le type expression ne correspond pas au type de données « colonne » : VARIANT attendu, mais a obtenu VARCHAR
- Cause : le type de colonne de données d’entrée qui est une chaîne est différent du type de colonne associée dans la transformation du récepteur Snowflake qui est VARIANT.
- Recommandation : Pour le type VARIANT de Snowflake, elle ne peut accepter que la valeur du flux de données qui est de type struct, carte ou tableau. Si la valeur de vos colonnes de données d’entrée est JSON ou XML ou une autre chaîne, utilisez une transformation d’analyse avant la transformation du récepteur Snowflake pour masquer la valeur en type struct, map ou array.
Code d’erreur : DF-Snowflake-InvalidDataType
- Message : le type Spark n’est pas pris en charge dans le flocon.
- Cause : Le type de données fourni dans Snowflake n'est pas valide.
- Recommandation : utilisez la transformation de dérivation avant d'appliquer le récepteur Snowflake pour mettre à jour la colonne associée des données d'entrée dans le type String.
Code d’erreur : DF-Snowflake-InvalidStageConfiguration
Message : seul le type de stockage BLOB peut être utilisé en tant qu’étape de lecture/écriture en flocon.
Cause : La configuration de la mise en lots fournie dans Snowflake n'est pas valide.
Recommandation : Mettez à jour les paramètres de mise en lots de Snowflake pour veiller à ce que seul le service lié Azure Blob soit utilisé.
Message : Les propriétés de l’index Snowflake doivent être spécifiées avec l’authentification Azure Blob + SAS.
Cause : La configuration de la mise en lots fournie dans Snowflake n'est pas valide.
Recommandation : Veillez à ce que seule l'authentification Azure Blob + SAS soit spécifiée dans les paramètres de mise en lots de Snowflake.
Code d'erreur : DF-SQLDW-ErrorRowsFound
- Cause : Des lignes d'erreur/non valides ont été trouvées lors de l'écriture dans le récepteur Azure Synapse Analytics.
- Recommandation : recherchez les lignes d'erreur à l'emplacement de stockage des données rejetées, si un tel emplacement est configuré.
Code d'erreur : DF-SQLDW-ExportErrorRowFailed
- Message : Une exception s'est produite lors de l'écriture des lignes d'erreur dans le stockage.
- Cause : Une exception s'est produite lors de l'écriture des lignes d'erreur dans le stockage.
- Recommandation : Vérifiez la configuration du service lié des données rejetées.
Code d’erreur : DF-SQLDW-IncorrectLinkedServiceConfiguration
-
Message : le service lié est configuré de manière incorrecte comme type « Azure Synapse Analytics » au lieu de « Base de données Azure SQL ». Veuillez créer un service lié de type « Base de données Azure SQL »
Remarque : veuillez vérifier que la base de données donnée est de type « Pool SQL dédié (anciennement SQL Data Warehouse) » pour le type de service lié « Azure Synapse Analytics ». - Cause : le service lié est configuré de manière incorrecte comme type Azure Synapse Analytics au lieu de Azure SQL Database.
- Recommandation : créez un service lié de type Azure SQL Database et vérifiez que la base de données donnée est de type Pool SQL dédié (anciennement SQL DW) pour le type de service lié Azure Synapse Analytics.
Code d’erreur : DF-SQLDW-InternalErrorUsingMSI
- Message : une erreur interne s’est produite lors de l’authentification par rapport à Identité du service géré dans l’instance Azure Synapse Analytics. Redémarrez l’instance Azure Synapse Analytics ou contactez le support Azure Synapse Analytics prise en dédié au pool SQL si ce problème persiste.
- Cause : une erreur interne s’est produite dans Azure Synapse Analytics.
- Recommandation : redémarrez l’instance Azure Synapse Analytics ou contactez le support Azure Synapse Analytics prise en dédié au pool SQL si ce problème persiste.
Code d’erreur : DF-SQLDW-InvalidBlobStagingConfiguration
- Message : les propriétés de mise en lots du stockage d’objets BLOB doivent être spécifiées.
- Cause : Les paramètres de mise en lots du stockage d'objets blob fournis ne sont pas valides.
- Recommandation : vérifiez que les propriétés du service lié Blob utilisé pour la mise en lots sont correctes.
Code d’erreur : DF-SQLDW-InvalidConfiguration
- Message : les propriétés de mise en lots du stockage d’objets ADLS Gen2 doivent être spécifiées. L’une des clés ou tenant/spnId/spnCredential/spnCredentialType ou miServiceUri/miServiceToken est requise.
- Cause : Les propriétés de mise en lots ADLS Gen2 fournies ne sont pas valides.
- Recommandation : mettez à jour les paramètres de mise en lots du stockage ADLS Gen2 pour bénéficier d'une des trois méthodes d'authentification disponibles (par clé, tenant/spnId/spnCredential/spnCredentialType ou miServiceUri/miServiceToken).
Code d’erreur : DF-SQLDW-InvalidGen2StagingConfiguration
- Message : la mise en lots du stockage ADLS Gen2 ne prend en charge que les informations d’identification de la clé principale du service.
- Cause : Les informations d'identification fournies pour la mise en lots du stockage ADLS Gen2 ne sont pas valides.
- Recommandation : Utilisez les informations d'identification de la clé de principal de service du service lié Gen2 utilisé pour la mise en lots.
Code d’erreur : DF-SQLDW-InvalidStorageType
- Message : le type de stockage peut être un objet BLOB ou un Gen2.
- Cause : Le type de stockage fourni pour la mise en lots n'est pas valide.
- Recommandation : Vérifiez que le type de stockage du service lié utilisé pour la mise en lots est bien Blob ou Gen2.
Code d’erreur : DF-SQLDW-StagingStorageNotSupport
- Message : Le stockage de préproduction avec un DNS de partition activé n’est pas pris en charge si vous activez le mode de préproduction. Décochez Activer le mode de préproduction dans le récepteur avec Synapse Analytics.
- Cause : le stockage de préproduction avec un DNS de partition activé n’est pas pris en charge si vous activez le mode de préproduction.
- Recommandations : Décochez Activer le mode de préproduction dans le récepteur avec Azure Synapse Analytics.
Code d’erreur : DF-SQLDW-DataTruncation
- Message : Votre table cible contient une colonne de type (n)varchar ou (n)varbinary qui a une limitation de longueur de colonne plus petite que les données réelles. Modifiez la définition de la colonne dans votre table cible ou changez les données sources.
- Cause : Votre table cible contient une colonne avec un type varchar ou varbinary qui a une limitation de longueur de colonne plus petite que les données réelles.
- Recommandations : Modifiez la définition de la colonne dans votre table cible ou changez les données sources.
Code d’erreur : DF-Synapse-DBNotExist
- Cause: la base de données n’existe pas.
- Recommandation : Vérifiez si la base de données existe.
Code d’erreur : DF-Synapse-InvalidDatabaseType
- Message : Le type de base de données n’est pas pris en charge.
- Cause: le type de base de données n’est pas pris en charge.
- Recommandation : Vérifiez le type de base de données et remplacez-le par le type approprié.
Code d’erreur : DF-Synapse-InvalidFormat
- Message : Le format n'est pas pris en charge.
- Cause: le format n’est pas pris en charge.
- Recommandation : Vérifiez le format et remplacez-le par le format approprié.
Code d’erreur : DF-Synapse-InvalidOperation
- Cause : l'opération n'est pas prise en charge.
- Recommandation : La modification de la configuration de la méthode de mise à jour comme la suppression, la mise à jour et l’upsert n’est pas prise en charge dans la base de données de l’espace de travail.
Code d’erreur : DF-Synapse-InvalidTableDBName
- Message : Le nom de table/base de données n’est pas un nom valide pour les tables/bases de données. Les noms valides ne contiennent que des caractères alphabétiques, des nombres et _.
- Cause : le nom de table/base de données n'est pas valide.
-
Recommandation : Donnez un nom valide à la table/base de données. Les noms valides ne contiennent que des caractères alphabétiques, des nombres et
_.
Code d’erreur : DF-Synapse-StoredProcedureNotSupported
- Message : L’utilisation de « Procédure stockée » en tant que source n’est pas prise en charge pour le pool serverless (à la demande).
- Cause : Le pool serverless présente des limitations.
- Recommandation : Réessayez en utilisant « requête » en tant que source ou en enregistrant la procédure stockée en tant que vue, puis utilisez « table » en tant que source pour lire directement à partir de la vue.
Code d’erreur : DF-XML-InvalidDataField
- Message : le champ pour les enregistrements endommagés doit être de type chaîne et pouvant accepter la valeur Null.
-
Cause : Le type de données fourni pour la colonne
\"_corrupt_record\"dans la source XML n'est pas valide. -
Recommandation : assurez-vous que la colonne
\"_corrupt_record\"de la source XML est définie sur le type de données String et qu'elle peut accepter les valeurs Null.
Code d'erreur : DF-Xml-InvalidElement
- Message : L'élément XML comporte des sous-éléments ou des attributs qui ne peuvent pas être convertis.
- Cause : L'élément XML comporte des sous-éléments ou des attributs qui ne peuvent pas être convertis.
- Recommandation : Mettez à jour le fichier XML pour que l'élément XML bénéficie des sous-éléments ou des attributs appropriés.
Code d’erreur : DF-XML-InvalidReferenceResource
- Message : La ressource de référence du fichier de données XML ne peut pas être résolue.
- Cause : La ressource de référence du fichier de données XML ne peut pas être résolue.
- Recommandation : vérifiez la ressource de référence dans le fichier de données XML.
Code d’erreur : DF-Xml-InvalidSchema
- Message : La validation du schéma a échoué.
- Cause : Le schéma fourni dans la source XML n'est pas valide.
- Recommandation : Vérifiez les paramètres du schéma au niveau de la source XML pour vous assurer qu’il s’agit du schéma de sous-ensemble des données source.
Code d’erreur : DF-XML-InvalidValidationMode
- Message : le mode de validation XML fourni n’est pas valide.
- Cause : Le mode de validation XML fourni n'est pas valide.
- Recommandation : vérifiez la valeur du paramètre et indiquez le mode de validation approprié.
Code d’erreur : DF-XML-MalformedFile
- Message : Fichier XML malformé avec chemin en mode FAILFAST.
- Cause : Existence d'un fichier XML malformé avec chemin en mode FAILFAST.
- Recommandation : mettez à jour le contenu du fichier XML au format approprié.
Code d’erreur : DF-XML-UnsupportedExternalReferenceResource
- Message : la ressource de référence externe dans le fichier de données XML n’est pas prise en charge.
- Cause : la ressource de référence externe du fichier de données XML n'est pas prise en charge.
- Recommandation : mettez à jour le contenu du fichier XML lorsque la ressource de référence externe n’est pas prise en charge.
Code d’erreur : Échec de GetCommand OutputAsync
- Message : Lors du débogage du flux de données et de l’aperçu des données : Échec de GetCommand OutputAsync avec...
- Cause : Cette erreur est une erreur de service back-end.
- Recommandation : Retentez l’opération et redémarrez votre session de débogage. Si la nouvelle tentative et le redémarrage ne résolvent pas le problème, contactez le support technique.
Code d’erreur : InvalidTemplate
- Message : L’expression de pipeline ne peut pas être évaluée.
- Cause : L’expression de pipeline passée dans l’activité de flux de données n’est pas traitée correctement en raison d’une erreur de syntaxe.
- Recommandation : Vérifiez le nom de l’activité de flux de données. Vérifiez les expressions dans l’analyse des activités. Par exemple, le nom de l’activité de flux de données ne peut pas contenir d’espace ou de trait d’union.
Code d’erreur : 127
- Message : le travail Spark du flux de données s’est terminé, mais l’état d’exécution est nul ou toujours InProgress.
- Cause : des problèmes temporaires avec des microservices impliqués dans l’exécution peuvent entraîner un échec de l’exécution.
- Recommandation : reportez-vous aux problèmes temporaires du scénario 3.
Code d’erreur : 2011
- Message : L’activité était exécutée sur Azure Integration Runtime et n’a pas pu déchiffrer les informations d’identification du magasin de données ou du calcul connecté via un runtime d’intégration auto-hébergé. Vérifiez la configuration des services liés associés à cette activité et veillez à utiliser le type de runtime d’intégration approprié.
- Cause : Le flux de données ne prend pas en charge les services liés sur les runtimes d’intégration auto-hébergés.
- Recommandation : Configurez le flux de données pour qu’il s’exécute sur un runtime d’intégration de réseau virtuel géré.
Code d’erreur : 4502
- Message : Des exécutions de MappingDataflow simultanées importantes entraînent des échecs en raison de la limitation sous le runtime d’intégration.
- Cause : Un grand nombre d’exécutions d’activités de flux de données se produisent simultanément sur le runtime d’intégration. Pour plus d’informations, consultez Limites d’Azure Data Factory.
- Recommandation : Si vous souhaitez exécuter davantage d’activités de flux de données en parallèle, répartissez-les sur plusieurs runtimes d’intégration.
Code d’erreur : 4503
- Message : Il existe des exécutions de MappingDataflow simultanées conséquentes qui provoquent des échecs en raison d’une limitation sous l’abonnement « %subscriptionId;’, ActivityId: ’%activityId; ».
- Cause : Le seuil de limitation a été atteint.
- Recommandation : Réessayez la requête après une période d’attente.
Code d’erreur : 4506
- Message : Échec d’approvisionnement de cluster pour « %activityId; », car l’ordinateur de requête dépasse le nombre maximal de 200 requêtes simultanées. Runtime d’intégration « %IRName; »
- Cause : Erreur temporaire.
- Recommandation : Réessayez la requête après une période d’attente.
Code d’erreur : 4507
- Message : Type de calcul et/ou valeur de nombre de cœurs non pris en charge.
- Cause : Type de calcul et/ou valeur de nombre de cœurs fournies non pris en charge.
- Recommendation : Utilisez l’une des valeurs de type de calcul et/ou de nombre de cœurs prises en charge indiquées dans ce document.
Error code : 4508
- Message: Cluster Spark introuvable.
- Recommendation : Redémarrez la session de débogage.
Error code : 4509
- Message : Échec inattendu lors de l’allocation de ressources de calcul. Réessayez. Si le problème persiste, veuillez contacter le Support Azure.
- Cause : Erreur temporaire.
- Recommandation : Réessayez la requête après une période d’attente.
Code d’erreur : 4510
- Message : Défaillance inattendue pendant l’exécution.
- Cause : Étant donné que les clusters de débogage fonctionnent différemment des clusters de travail, les exécutions de débogage excessives peuvent affecter le cluster dans le temps, ce qui peut provoquer des problèmes de mémoire et des redémarrages soudains.
- Recommandation : Redémarrez le cluster de débogage. Si vous exécutez plusieurs flux de données pendant la session de débogage, utilisez plutôt des exécutions d’activités, car l’exécution du niveau d’activité crée une session distincte sans imposer un cluster de débogage principal.
Error code : 4511
- Message : java.sql.SQLTransactionRollbackException. Blocage rencontré lors d’une tentative de verrouillage ; essayez de redémarrer la transaction. Si le problème persiste, veuillez contacter le Support Azure.
- Cause : Erreur temporaire.
- Recommandation : Réessayez la requête après une période d’attente.
Code d’erreur : SystemErrorSynapseSparkJobFailed (En cours)
- Message : Échec du travail pendant le temps d’exécution avec un état=[mort]. Les informations d’identification n’ont pas été fournies pour l’URI WASB.
- Cause : le flux de données n’est pas pris en charge dans les espaces de travail Synapse à l’aide de Spark version 3.4 lorsque DEP (Protection contre l’exfiltration des données) est activé en sélectionnant « Autoriser le trafic de données sortant uniquement aux cibles approuvées » pendant la configuration réseau de l’espace de travail.
- Recommandation : désactivez les paramètres ci-dessus lors de la création de l’espace de travail. Pour plus d’informations, consultez ce document
Conseils pour la résolution de problèmes divers
Problème : Une exception inattendue s’est produite et l’exécution a échoué.
- Message : Lors de l’exécution de l’activité de flux de données : Exception inattendue et échec de l’exécution.
- Cause : Cette erreur est une erreur de service back-end. Retentez l’opération et redémarrez votre session de débogage.
- Recommandation : Si la nouvelle tentative et le redémarrage ne résolvent pas le problème, contactez le support technique.
Problème : Aucune donnée de sortie lors de la jointure pendant l’aperçu des données de débogage.
- Message : Il existe un nombre élevé de valeurs Null ou manquantes qui peuvent être dues à l’échantillonnage d’un trop petit nombre de lignes. Essayez de mettre à jour la limite de lignes de débogage et d’actualiser les données.
- Cause : La condition de jointure ne correspond à aucune ligne ou a généré un nombre élevé de valeurs Null au cours de l’aperçu des données.
- Recommandation : Dans Paramètres de débogage, augmentez le nombre de lignes dans la limite de lignes sources. Veillez à sélectionner un runtime d’intégration Azure disposant d’un cluster de flux de données suffisamment grand pour gérer davantage de données.
Problème : Erreur de validation à la source avec des fichiers CSV multilignes.
-
Message : Vous pourriez voir l’un des messages d’erreur suivants :
- La dernière colonne est null ou manquante.
- Échec de la validation de schéma à la source.
- L’importation de schéma ne s’affiche pas correctement dans l’interface utilisateur et la dernière colonne contient un caractère de nouvelle ligne dans le nom.
- Cause : Dans le flux de données de mappage, les fichiers sources CSV multilignes ne fonctionnent pas quand \r\n est utilisé comme séparateur de lignes. Parfois, des lignes supplémentaires au niveau des retours chariot peuvent provoquer des erreurs.
- Recommandation : Générez le fichier à la source avec \n comme séparateur de lignes plutôt que \r\n. Vous pouvez aussi utiliser l’activité de copie pour convertir le fichier CSV afin d’utiliser \n comme séparateur de lignes.
-
Message : Vous pourriez voir l’un des messages d’erreur suivants :
Amélioration du format CSV/CDM dans le Data Flow
Si vous utilisez le format Texte délimité ou CDM pour le flux de données de mappage dans Azure Data Factory v2, vous pourrez être confronté à des changements de comportement de vos pipelines existants en raison de l’amélioration du format Texte délimité/CDM dans le flux de données à partir du 1er mai 2021.
Vous pouvez rencontrer les problèmes suivants avant l’amélioration, mais après l’amélioration, les problèmes seront corrigés. Lisez le contenu suivant pour déterminer si cette amélioration vous concerne.
Scénario 1 : Vous rencontrez un problème de délimiteur de ligne inattendu
Vous êtes concerné dans les conditions suivantes :
- Vous utilisez le format Texte délimité avec le paramètre Multiline défini sur True ou CDM comme source.
- La première ligne contient plus de 128 caractères.
- Le délimiteur de ligne dans les fichiers de données n’est pas
\n.
Avant l’amélioration, le délimiteur de ligne par défaut \n peut être utilisé de manière inattendue pour analyser les fichiers texte délimité, car, lorsque le paramètre Multiline est défini sur True, il invalide le paramètre de délimiteur de ligne et le délimiteur de ligne est automatiquement détecté en fonction des 128 premiers caractères. Si vous ne parvenez pas à détecter le délimiteur de ligne réel, le système revient à \n.
Après l’amélioration, un des trois délimiteurs de ligne, \r, \n ou \r\n, devrait avoir fonctionné.
L’exemple suivant montre un changement de comportement du pipeline après l’amélioration :
Exemple :
Pour la colonne suivante :
C1, C2, {long first row}, C128\r\n
V1, V2, {values………………….}, V128\r\n
Avant l’amélioration, \r est conservé dans la valeur de la colonne. Le résultat de la colonne analysée est le suivant :
C1 C2 {long first row} C128\r
V1 V2 {values………………….} V128\r
Après l’amélioration, le résultat de la colonne analysée doit être :
C1 C2 {long first row} C128
V1 V2 {values………………….} V128
Scénario 2 : Vous rencontrez un problème de lecture incorrecte des valeurs de colonne contenant « \r\n »
Vous êtes concerné dans les conditions suivantes :
- Vous utilisez le format Texte délimité avec le paramètre Multiline défini sur True ou CDM comme source.
- Le délimiteur de ligne est
\r\n.
Avant l’amélioration, lors de la lecture de la valeur de colonne, le \r\n de celle-ci peut être incorrectement remplacé par \n.
Après l’amélioration, \r\n dans la valeur de colonne ne sera pas remplacé par \n.
L’exemple suivant montre un changement de comportement du pipeline après l’amélioration :
Exemple :
Pour la colonne suivante :
"A\r\n", B, C\r\n
Avant l’amélioration, le résultat de la colonne analysée est le suivant :
A\n B C
Après l’amélioration, le résultat de la colonne analysée doit être :
A\r\n B C
Scénario 3 : Vous rencontrez un problème d’écriture incorrecte des valeurs de colonne contenant « \r\n »
Vous êtes concerné dans les conditions suivantes :
- Vous utilisez le format Texte délimité comme récepteur.
- La valeur de colonne contient
\n. - L’option Séparateur de lignes est définie sur
\r\n.
Avant l’amélioration, lors de l’écriture de la valeur de colonne, le \n de celle-ci peut être incorrectement remplacé par \r\n.
Après l’amélioration, \n dans la valeur de colonne ne sera pas remplacé par \r\n.
L’exemple suivant montre un changement de comportement du pipeline après l’amélioration :
Exemple :
Pour la colonne suivante :
A\n B C
Avant l’amélioration, le récepteur CSV est :
"A\r\n", B, C\r\n
Après l’amélioration, le récepteur CSV doit être :
"A\n", B, C\r\n
Scénario 4 : Vous rencontrez un problème de lecture incorrecte d’une chaîne vide comme NULL
Vous êtes concerné dans les conditions suivantes :
- Vous utilisez le format Texte délimité comme source.
- La valeur NULL est définie comme une valeur non vide.
- La valeur de colonne est une chaîne vide et est sans guillemets.
Avant l’amélioration, la valeur de colonne de la chaîne vide sans guillemets est lue comme NULL.
Après l’amélioration, la chaîne vide ne sera pas interprétée comme une valeur NULL.
L’exemple suivant montre un changement de comportement du pipeline après l’amélioration :
Exemple :
Pour la colonne suivante :
A, ,B,
Avant l’amélioration, le résultat de la colonne analysée est le suivant :
A null B null
Après l’amélioration, le résultat de la colonne analysée doit être :
A "" (empty string) B "" (empty string)
Contenu connexe
Pour obtenir une aide supplémentaire sur la résolution des problèmes, consultez les ressources suivantes :