Déduplication de lignes et recherche de valeurs Null à l’aide d’extraits de flux de données
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
En utilisant des extraits de code dans des flux de données de mappage, vous pouvez facilement effectuer des tâches courantes telles que la déduplication des données et le filtrage de valeurs Null. Cet article explique comment ajouter facilement ces fonctions à vos pipelines à l’aide d’extraits de script de flux de données.
Créer un pipeline
Sélectionnez Nouveau pipeline.
Ajoutez une activité de flux de données.
Sélectionnez l’onglet Paramètres de la source, ajoutez une transformation source, puis connectez-la à l’un de vos jeux de données.
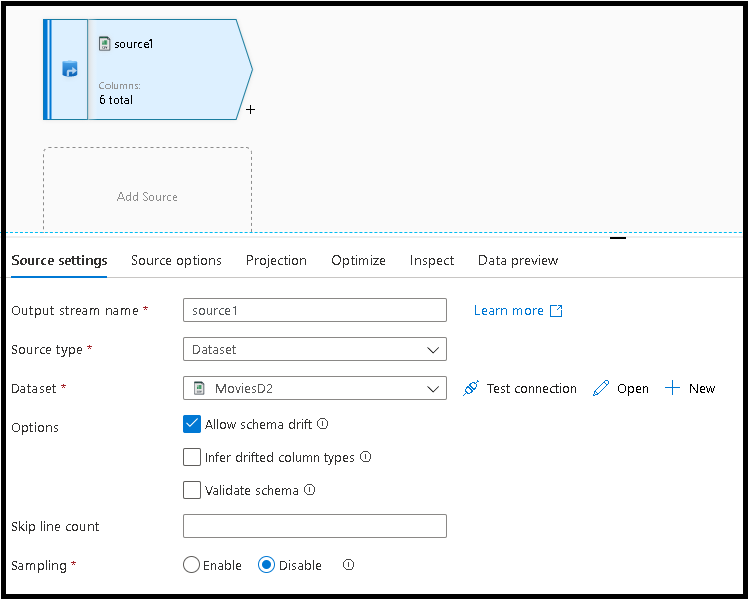
Les extraits de code de vérification de la déduplication et de la valeur Null utilisent des modèles génériques qui tirent parti de la dérive du schéma de flux de données. Les extraits de code fonctionnent avec n’importe quel schéma de votre jeu de données, ou avec des jeux de données qui n’ont pas de schéma prédéfini.
Dans la section « Ligne distincte utilisant toutes les colonnes » de Script de flux de données (DFS), copiez l’extrait de code pour DistinctRows.
-
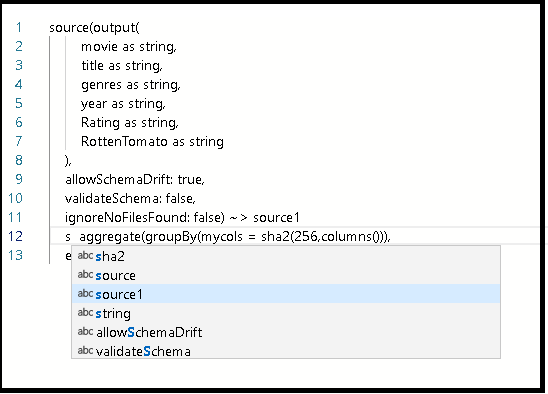
Dans votre script, après la définition de
source1, appuyez sur Entrée, puis collez l’extrait de code.Effectuez l'une des opérations suivantes :
Connectez cet extrait de code collé à la transformation source que vous avez créée précédemment dans le graphique en saisissant source1 devant le code collé.
Vous pouvez également connecter la nouvelle transformation dans le concepteur en sélectionnant le flux entrant à partir du nouveau nœud de transformation dans le graphique.
À présent, votre flux de données supprime les doublons de lignes de votre source à l’aide de la transformation d’agrégation, qui regroupe toutes les lignes à l’aide d’un hachage général pour toutes les valeurs de colonne.
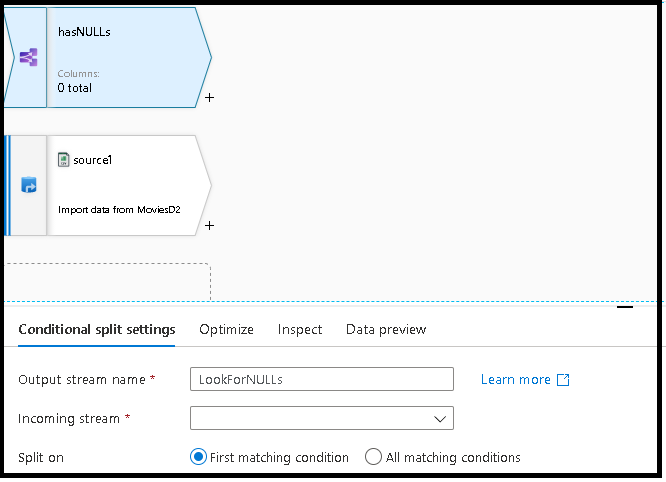
Ajoutez un extrait de code pour fractionner vos données en un flux qui contient des lignes avec des valeurs Null et un autre flux sans valeurs Null. Pour ce faire :
-
b. Dans le concepteur de flux de données, sélectionnez à nouveau Script, puis collez ce nouveau code de transformation en bas. Cette action connecte le script à votre transformation précédente en plaçant le nom de ladite transformation devant l’extrait de code collé.
Votre graphique de flux de données doit maintenant ressembler à ceci :
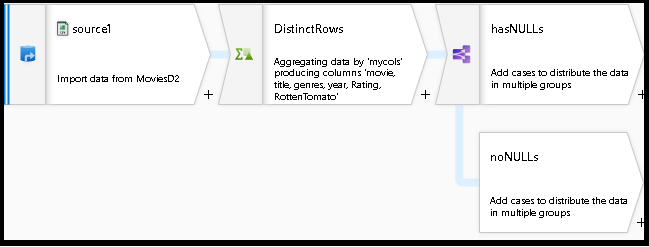
Vous avez maintenant créé un flux de données fonctionnel avec des déduplications génériques et des contrôles de valeur Null en récupérant les extraits de code existants de la bibliothèque de scripts de flux de données et en les ajoutant à votre conception existante.
Contenu connexe
- Créez le reste de votre logique de flux de données à l’aide de transformations de flux de données de mappage.