Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Si vous débutez avec Azure Data Factory, consultez Introduction dans Azure Data Factory.
Dans ce tutoriel, vous allez découvrir les meilleures pratiques qui peuvent être appliquées lors de l'écriture de fichiers dans ADLS Gen2 ou Azure Blob Storage à l'aide de flux de données. Vous aurez besoin d'un compte Azure Blob Storage ou d'un compte Azure Data Lake Store Gen2 pour lire un fichier Parquet, puis stocker les résultats dans des dossiers.
Prérequis
- abonnement Azure. Si vous n'avez pas d'abonnement Azure, créez un compte Azure gratuit avant de commencer.
- Compte de stockage Azure. Vous utilisez le stockage ADLS comme magasins de données source et récepteur. Si vous n'avez pas de compte de stockage, consultez Créer un compte de stockage Azure pour connaître les étapes à suivre pour en créer un.
Les étapes de ce tutoriel supposent que vous avez
Créer une fabrique de données
Au cours de cette étape, vous allez créer une fabrique de données et ouvrir l’interface utilisateur de Data Factory afin de créer un pipeline dans la fabrique de données.
Ouvrez Microsoft Edge ou Google Chrome. Actuellement, l’interface utilisateur de Data Factory est prise en charge uniquement dans les navigateurs web Microsoft Edge et Google Chrome.
Dans le menu de gauche, sélectionnez Créer une ressource>Intégration>Fabrique de données
Dans la page Nouvelle fabrique de données , sous Nom, entrez ADFTutorialDataFactory
Sélectionnez l'abonnement Azure dans lequel vous souhaitez créer la fabrique de données.
Pour Groupe de ressources, effectuez l'une des actions suivantes :
a) Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
b. Sélectionnez Créer, puis entrez le nom d’un groupe de ressources. Pour en savoir plus sur les groupes de ressources, consultez Utilisez les groupes de ressources pour gérer vos ressources Azure.
Sous Version, sélectionnez V2.
Sous Emplacement, sélectionnez un emplacement pour la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste déroulante. Les magasins de données (par exemple, Azure Storage et SQL Database) et les calculs (par exemple, Azure HDInsight) utilisés par la fabrique de données peuvent se trouver dans d’autres régions.
Sélectionnez Créer.
Une fois la création terminée, vous voyez apparaître l’avis dans le centre de notifications. Sélectionnez Accéder à la ressource pour accéder à la page Fabrique de données.
Sélectionnez Author &Monitor pour lancer l’interface utilisateur de Data Factory dans un onglet distinct.
Créer un pipeline avec une activité de flux de données
Au cours de cette étape, vous allez créer un pipeline qui contient une activité de flux de données.
Dans la page d’accueil de Azure Data Factory, sélectionnez Orchestrate.
Dans l’onglet Général du pipeline, entrez DeltaLake pour le nom du pipeline.
Dans la barre supérieure de la fabrique, faites glisser le curseur Débogage du flux de données. Le mode de débogage permet un test interactif de la logique de transformation sur un cluster Spark activé. Les clusters Data Flow prennent 5 à 7 minutes pour se réchauffer, et il est conseillé aux utilisateurs d’activer le débogage en premier s'ils prévoient de faire du développement Data Flow. Pour plus d’informations, consultez Mode de débogage.
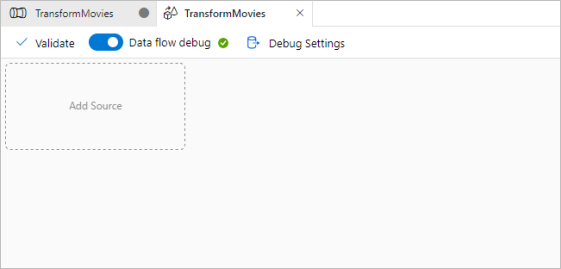
Dans le volet Activités, développez la section Déplacer et transformer. Faites glisser et déposez l’activité Flux de données à partir du volet vers le canevas du pipeline.
Générer une logique de transformation dans le canevas de flux de données
Vous prendrez n'importe quelle donnée source (dans ce tutoriel, nous utiliserons un fichier Parquet) et utiliserez une transformation du récepteur pour déposer les données au format Parquet en utilisant les mécanismes les plus efficaces pour le processus ETL du lac de données.

Objectifs du tutoriel
- Choisissez l’un de vos jeux de données sources dans un nouveau flux de données 1. Utiliser des flux de données pour partitionner efficacement votre jeu de données récepteur
- Déposer vos données partitionnées dans les dossiers du lac ADLS Gen2
Démarrer à partir d’un canevas de flux de données vide
Commençons par configurer l'environnement de flux de données correspondant à chacun des mécanismes décrits ci-dessous pour les données déposées dans ADLS Gen2.
- Cliquez sur la transformation de la source.
- Cliquez sur le nouveau bouton en regard du jeu de données dans le panneau inférieur.
- Choisissez un jeu de données ou créez-en un nouveau. Pour cette démonstration, nous allons utiliser un jeu de données Parquet nommé Données utilisateur.
- Ajoutez une transformation de colonne dérivée. Nous l'utiliserons pour définir dynamiquement les noms de dossier de votre choix.
- Ajoutez une transformation du récepteur.
Sortie de dossiers hiérarchiques
Il est très courant d'utiliser des valeurs uniques disponibles dans les données pour créer des hiérarchies de dossiers et partitionner les données au sein du lac. Il s'agit d'un moyen optimal d'organiser et de traiter les données au sein du lac et dans Spark (le moteur de calcul qui est derrière les flux de données). Cela dit, ce type d'organisation de votre production aura un léger coût en termes de performances. Attendez-vous à une légère diminution des performances globales du pipeline si vous utilisez ce mécanisme dans le récepteur.
- Revenez au concepteur de flux de données et modifiez le flux de données créé ci-dessus. Cliquez sur la transformation du récepteur.
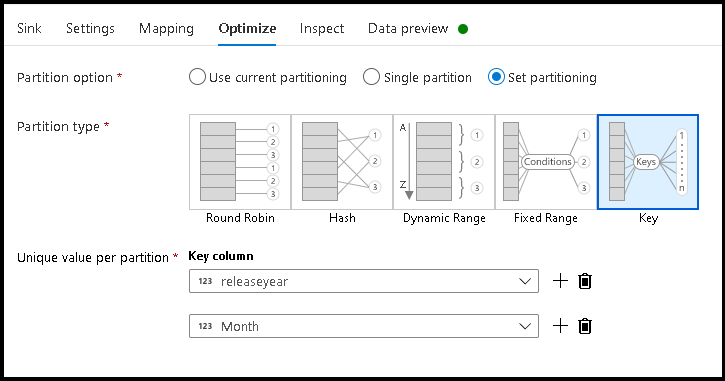
- Cliquez sur Optimiser > Définir le partitionnement > Clé.
- Sélectionnez la ou les colonnes que vous souhaitez utiliser pour définir votre structure hiérarchique de dossiers.
- Notez que l'exemple ci-dessous utilise l'année et le mois comme colonnes pour la dénomination des dossiers. Les résultats seront des dossiers au format
releaseyear=1990/month=8. - Lorsque vous accédez aux partitions de données au sein d'une source de flux de données, vous pointez uniquement vers le dossier de niveau supérieur situé au dessus de
releaseyearet utilisez un modèle de caractère générique pour chaque dossier suivant, par exemple :**/**/*.parquet - Pour manipuler les valeurs des données, ou même si vous devez générer des valeurs synthétiques pour les noms de dossier, utilisez la transformation de colonne dérivée afin de créer les valeurs que vous souhaitez utiliser dans vos noms de dossier.
Nommer le dossier d'après les valeurs des données
Name folder as column data est une technique de récepteur légèrement plus performante pour les données de lac utilisant ADLS Gen2, mais elle n'offre pas le même avantage que le partitionnement clé/valeur. Alors que le style de partitionnement des clés de la structure hiérarchique vous permettra de traiter plus facilement les tranches de données, cette technique est une structure de dossiers aplatis qui permet d'écrire les données plus rapidement.
- Revenez au concepteur de flux de données et modifiez le flux de données créé ci-dessus. Cliquez sur la transformation du récepteur.
- Cliquez sur Optimiser > Définir le partitionnement > Utiliser le partitionnement actuel.
- Cliquez sur Paramètres > Nommer le dossier d'après les données de la colonne.
- Sélectionnez la colonne que vous souhaitez utiliser pour générer les noms de dossier.
- Pour manipuler les valeurs des données, ou même si vous devez générer des valeurs synthétiques pour les noms de dossier, utilisez la transformation de colonne dérivée afin de créer les valeurs que vous souhaitez utiliser dans vos noms de dossier.
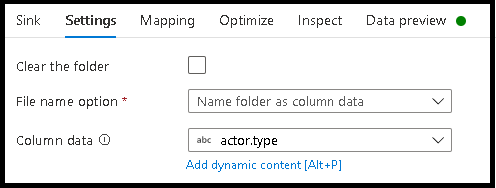
Nommer le fichier d'après les valeurs des données
Les techniques répertoriées dans les tutoriels ci-dessus sont de bons cas d'usage pour créer des catégories de dossiers dans votre lac de données. Le schéma de dénomination de fichier par défaut utilisé par ces techniques consiste à utiliser l'ID de travail de l'exécuteur Spark. Parfois, vous pouvez souhaiter définir le nom du fichier de sortie dans un récepteur de texte de flux de données. Cette technique est uniquement suggérée pour les petits fichiers. Le processus de fusion des fichiers de partition en un seul fichier de sortie est un processus de longue haleine.
- Revenez au concepteur de flux de données et modifiez le flux de données créé ci-dessus. Cliquez sur la transformation du récepteur.
- Cliquez sur Optimiser > Définir le partitionnement > Partition unique. Cette exigence de partition unique crée un goulot d'étranglement dans le processus d'exécution lors de la fusion des fichiers. Cette option est uniquement recommandée pour les petits fichiers.
- Cliquez sur Paramètres > Nommer le fichier d'après les données de la colonne.
- Sélectionnez la colonne que vous souhaitez utiliser pour générer les noms de fichier.
- Pour manipuler les valeurs des données, ou même si vous devez générer des valeurs synthétiques pour les noms de fichier, utilisez la transformation de colonne dérivée afin de créer les valeurs que vous souhaitez utiliser dans vos noms de fichier.
Contenu connexe
En savoir plus sur les récepteurs de flux de données.