Transformer des données dans le cloud à l’aide d’une activité Spark dans Azure Data Factory
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce didacticiel, vous utilisez le portail Azure pour créer un pipeline Azure Data Factory. Ce pipeline transforme les données à l’aide de l’activité Spark et un service lié HDInsight de la demande.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Créer une fabrique de données.
- Créer un pipeline qui utilise une activité Spark.
- Déclencher une exécution du pipeline.
- Surveiller l’exécution du pipeline.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour commencer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
- Compte Azure Storage. Vous créez un script Python et un fichier d’entrée, puis vous les chargez vers le stockage Azure. La sortie du programme Spark est stockée dans ce compte de stockage. Le cluster Spark sur demande utilise le même compte de stockage comme stockage principal.
Notes
HdInsight prend en charge uniquement les comptes de stockage universels avec un niveau standard. Assurez-vous que le compte n’est pas un compte de stockage premium ou un objet blob uniquement.
- Azure PowerShell. Suivez les instructions de la page Installation et configuration d’Azure PowerShell.
Charger le script Python dans votre compte de stockage d’objets Blob
Créez un fichier Python nommé WordCount_Spark.py avec le contenu suivant :
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Remplacez <storageAccountName> par le nom de votre compte de stockage Azure. Puis enregistrez le fichier.
Dans le stockage Blob Azure, créez un conteneur nommé adftutorial s’il n’existe pas.
Créez un dossier nommé spark.
Créez un sous-dossier nommé script sous le dossier spark.
Téléchargez le fichier WordCount_Spark.py dans le sous-dossier script.
Télécharger le fichier d’entrée
- Créez un fichier nommé minecraftstory.txt avec du texte. Le programme Spark compte le nombre de mots dans ce texte.
- Créez un sous-dossier nommé inputfiles sous le dossier spark.
- Chargez le fichier minecraftstory.txt dans le sous-dossier inputfiles.
Créer une fabrique de données
Suivez les étapes de l’article Démarrage rapide : Créer une fabrique de données à l’aide du portail Azure pour créer une fabrique de données si vous n’en avez pas déjà une.
Créez des services liés
Vous créez deux services liés dans cette section :
- Un service lié au stockage Azure relie un compte de stockage Azure à la fabrique de données. Ce stockage est utilisé par le cluster HDInsight à la demande. Il contient également le script Spark à exécuter.
- Un service lié HDInsight à la demande. Azure Data Factory crée un cluster HDInsight et exécute le programme Spark automatiquement. Il supprime ensuite le cluster HDInsight une fois que le cluster inactif pendant une période préconfigurée.
Créer un service lié Stockage Azure
Dans la page d’accueil, basculez vers l’onglet Gérer dans le volet gauche.
Cliquez sur Connexions au bas de la fenêtre, puis cliquez sur + Nouveau.
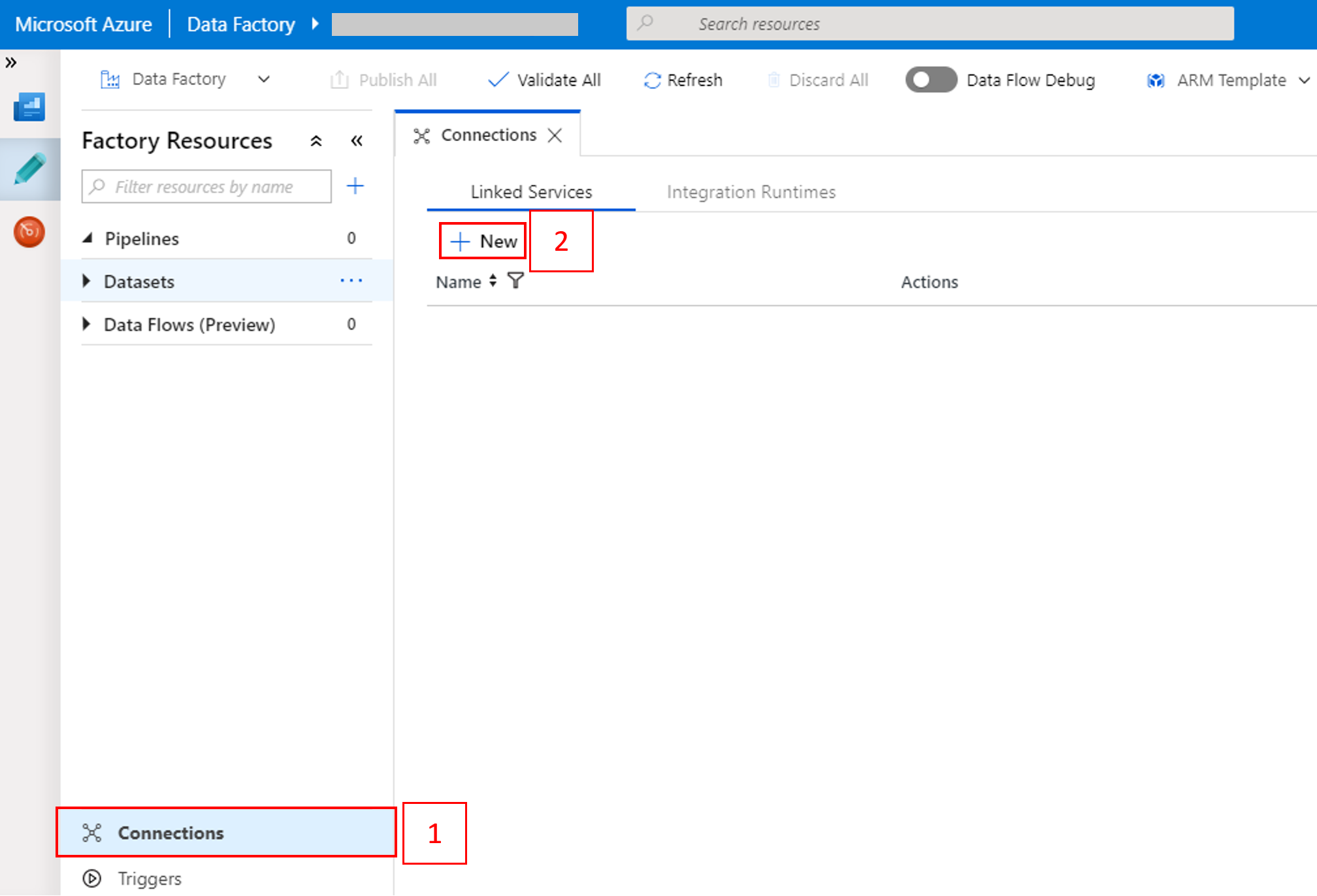
Dans la fenêtre Nouveau service lié, sélectionnez Magasin de données>Stockage Blob Azure, puis cliquez sur Continuer.

Pour Nom du compte de stockage, sélectionnez le nom dans la liste, puis cliquez sur Enregistrer.
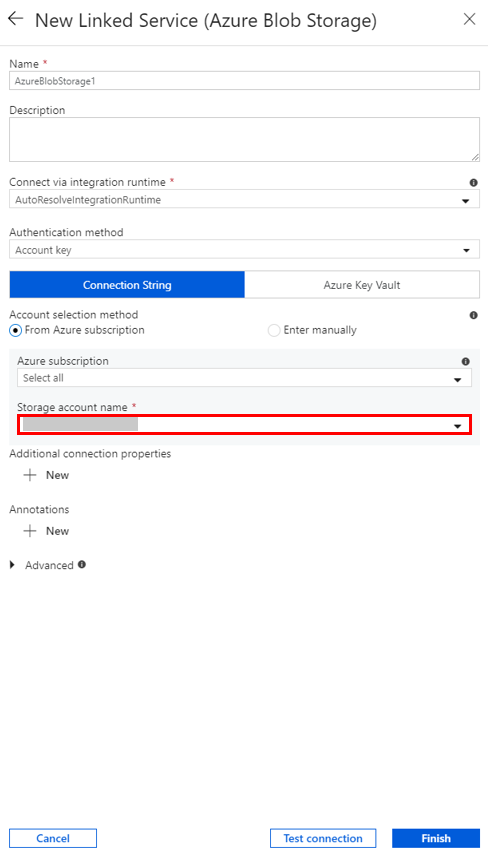
Créer un service lié HDInsight à la demande
Cliquez de nouveau sur le bouton + Nouveau pour créer un nouveau service lié.
Dans la fenêtre Nouveau service lié, sélectionnez Calcul>Azure HDInsight, puis cliquez sur Continuer.

Dans la fenêtre Nouveau service lié, procédez comme suit :
a. Entrez AzureHDInsightLinkedService pour le Nom.
b. Vérifiez que HDInsight à la demande est le Type sélectionné.
c. Sélectionnez AzureBlobStorage1 pour Service lié Stockage Azure. Vous avez déjà créé ce service lié. Si vous avez utilisé un nom différent, spécifiez le nom correct.
d. Sélectionnez spark pour Type de Cluster.
e. Entrez l’ID du principal de service ayant l’autorisation de créer un cluster HDInsight pour ID du principal de service.
Ce principal de service doit être membre du rôle Contributeur de l’abonnement ou du groupe de ressources dans lequel le cluster est créé. Pour plus d’informations, consultez Créer une application et un principal de service Microsoft Entra. L’ID de principal de service est équivalent à l’ID d’application et une clé de principal de service est équivalente à la valeur d’un secret client.
f. Pour Clé du principal de service, saisissez la clé.
g. Pour Groupe de ressources, sélectionnez le même groupe de ressources que celui utilisé lors de la création de la fabrique de données. Le cluster Spark est créé dans ce groupe de ressources.
h. Développer le type de système d’exploitation.
i. Entrez un nom pour le nom d’utilisateur du cluster.
j. Entrez le mot de passe du cluster correspondant à l’utilisateur.
k. Sélectionnez Terminer.
Notes
Azure HDInsight présente une limite relative au nombre total de cœurs que vous pouvez utiliser dans chaque région Azure prise en charge. Pour le service lié HDInsight à la demande, le cluster HDInsight est créé au même emplacement de stockage Azure que celui utilisé comme stockage principal. Vérifiez que vous disposez des quotas de cœurs suffisants pour pouvoir créer le cluster avec succès. Pour plus d’informations, reportez-vous à l’article Configurer des clusters dans HDInsight avec Hadoop, Spark, Kafka et bien plus encore.
Créer un pipeline
Cliquez sur le bouton + (plus), puis sélectionnez Pipeline dans le menu.
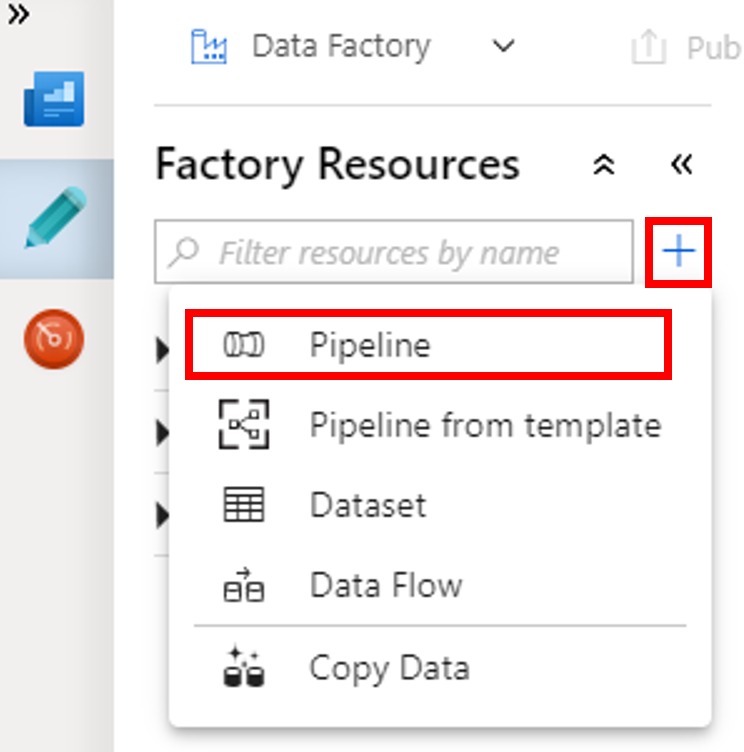
Dans la boîte à outils Activités, étendez le HDInsight. Faites glisser l’activité Spark depuis la boîte à outils Activités vers la surface du concepteur de pipeline.
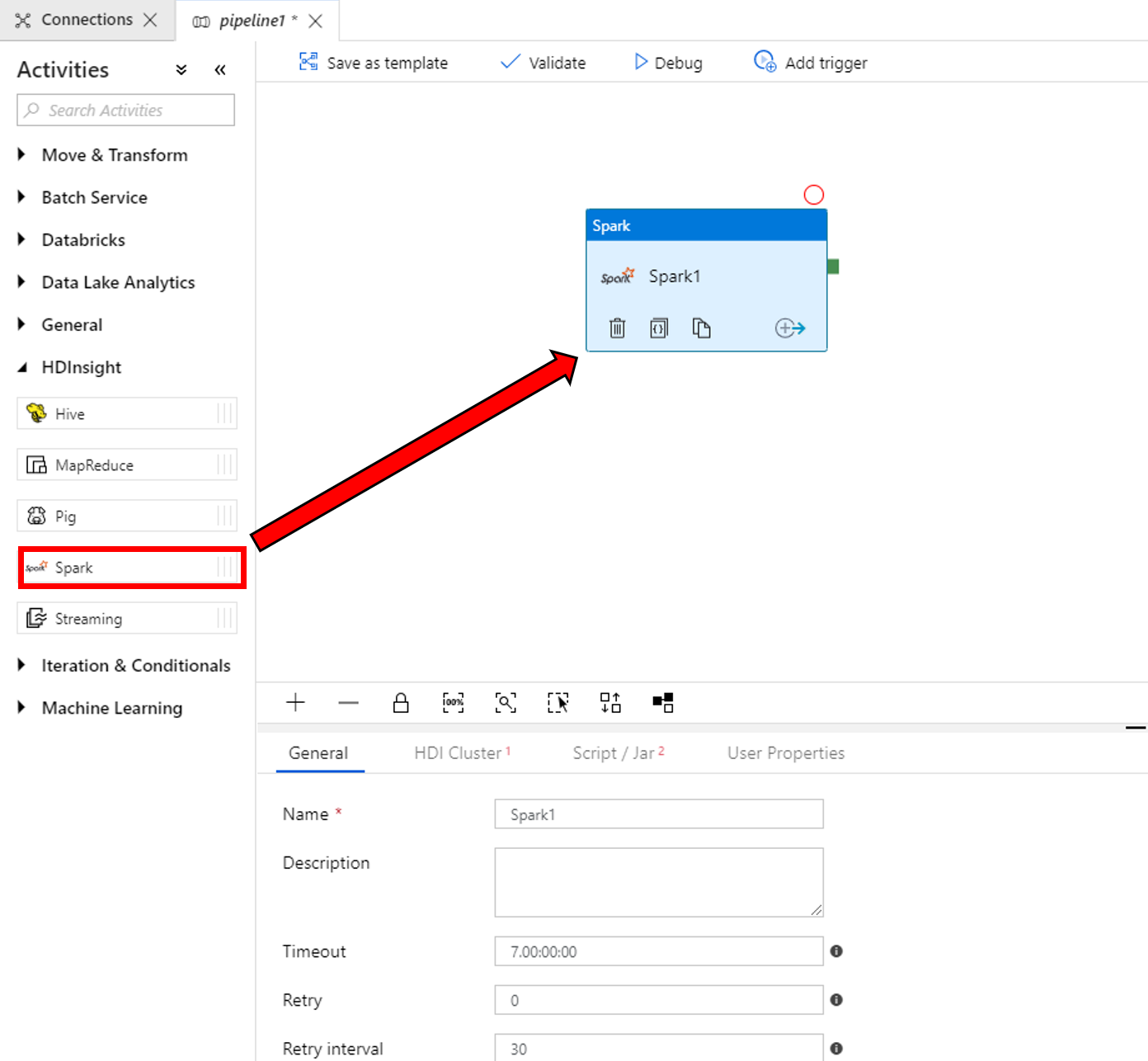
Dans les propriétés de la fenêtre d’activité Spark en bas, procédez comme suit :
a. Basculez vers l’onglet Cluster HDI.
b. Sélectionnez AzureHDInsightLinkedService créé lors de la procédure précédente.
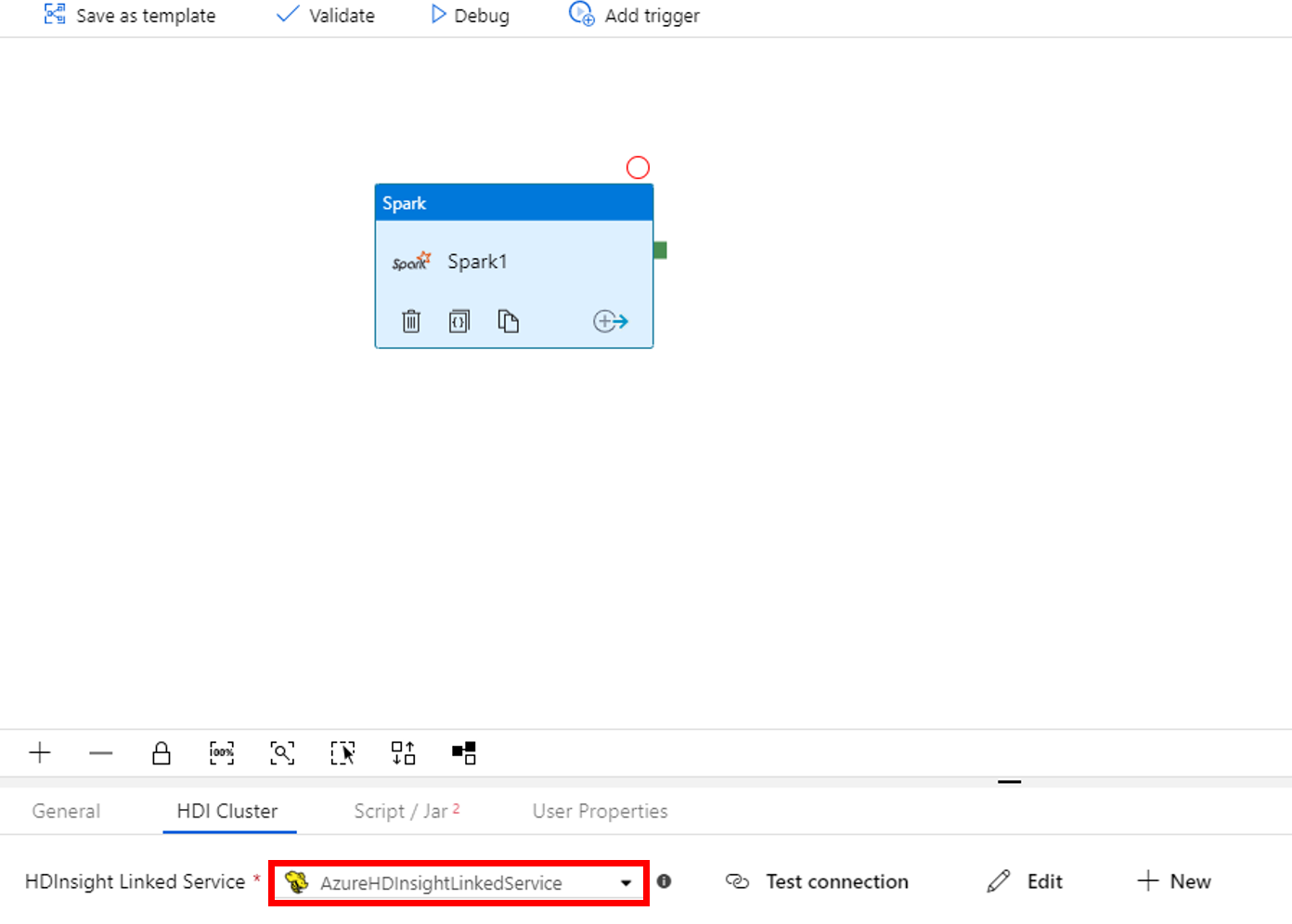
Basculez vers l’onglet Script/Jar, et procédez comme suit :
a. Sélectionnez AzureBlobStorage1 pour Service lié au travail.
b. Cliquez sur Parcourir le stockage.

c. Accédez au dossier adftutorial/spark/script, sélectionnez WordCount_Spark.py, puis cliquez sur Terminer.
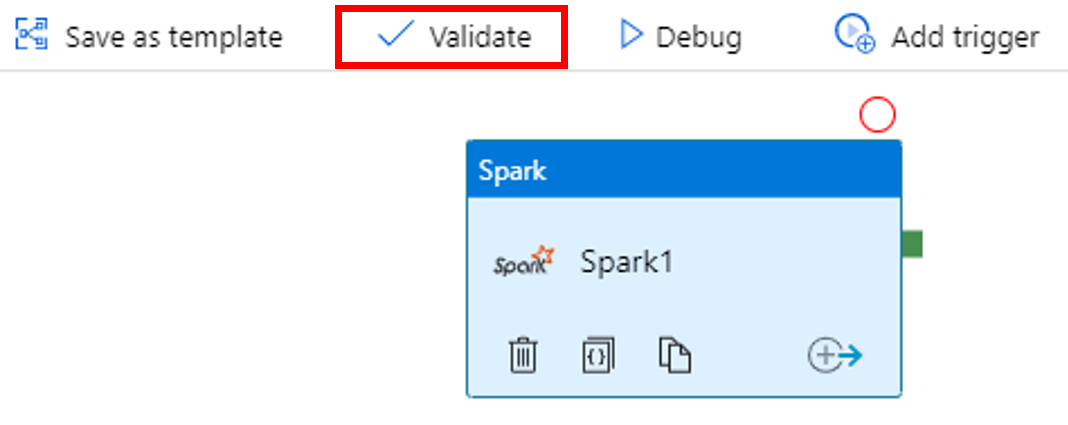
Pour valider le pipeline, cliquez sur le bouton Valider dans la barre d’outils. Cliquez sur le bouton >> flèche droite (>>) pour fermer la fenêtre de validation.
Sélectionnez Publier tout. L’interface utilisateur de Data Factory publie des entités (services liés et pipelines) sur le service Azure Data Factory.
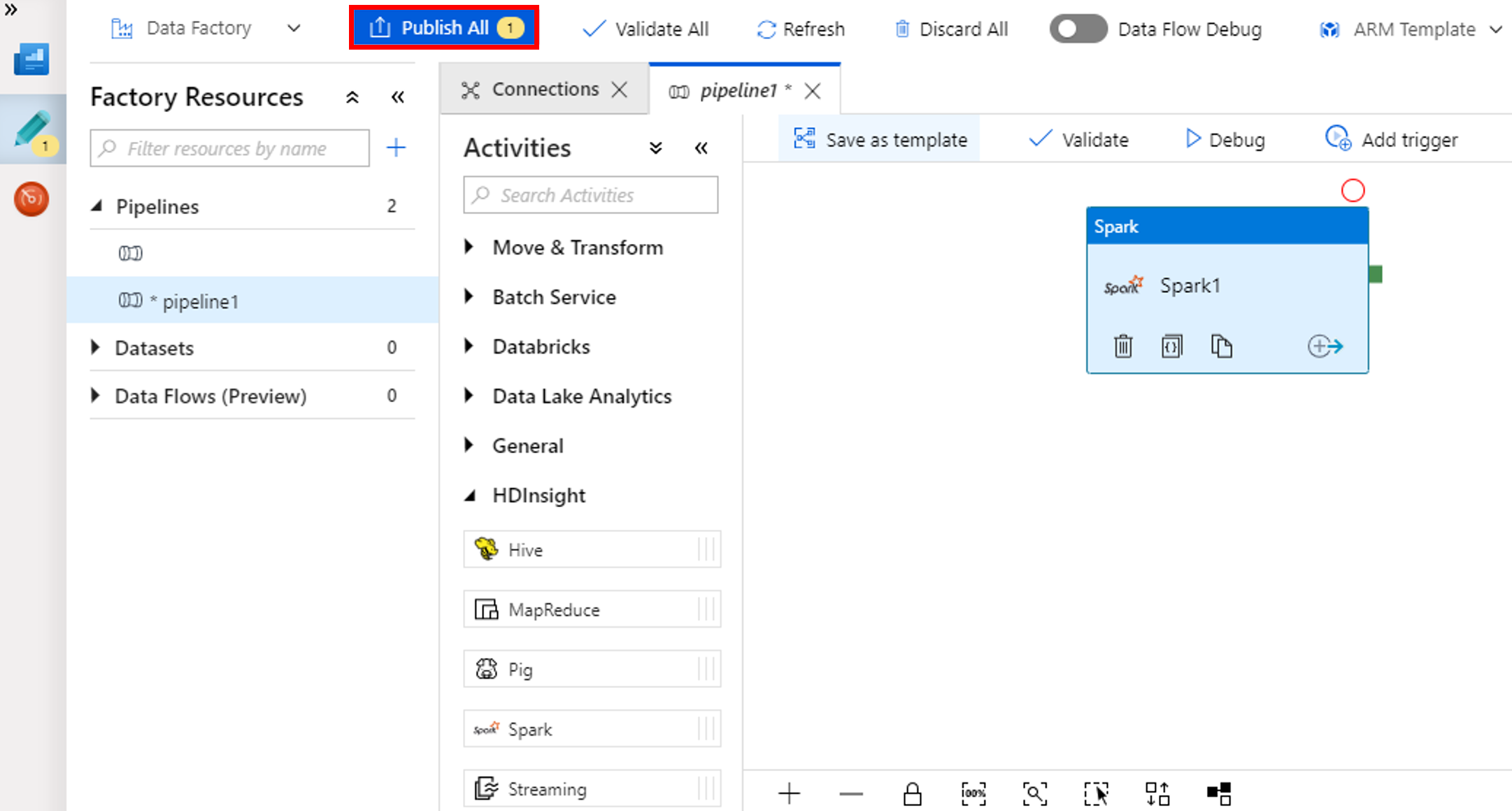
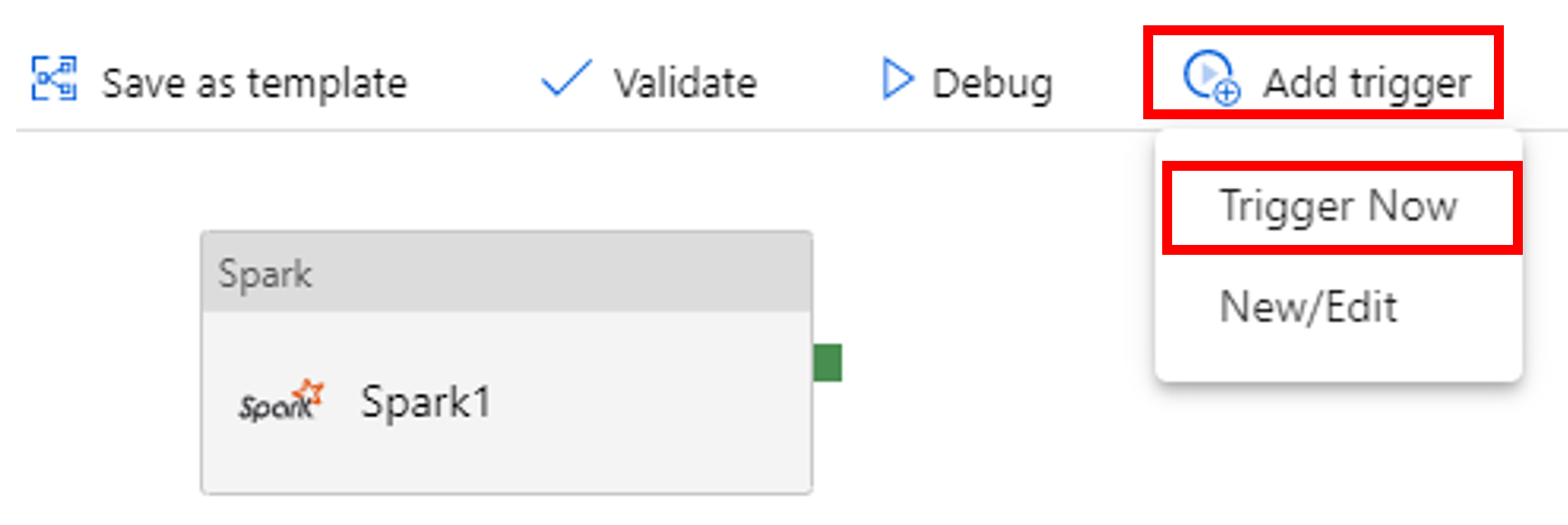
Déclencher une exécution du pipeline
Sélectionnez Ajouter déclencheur dans la barre d’outils, puis Déclencher maintenant.
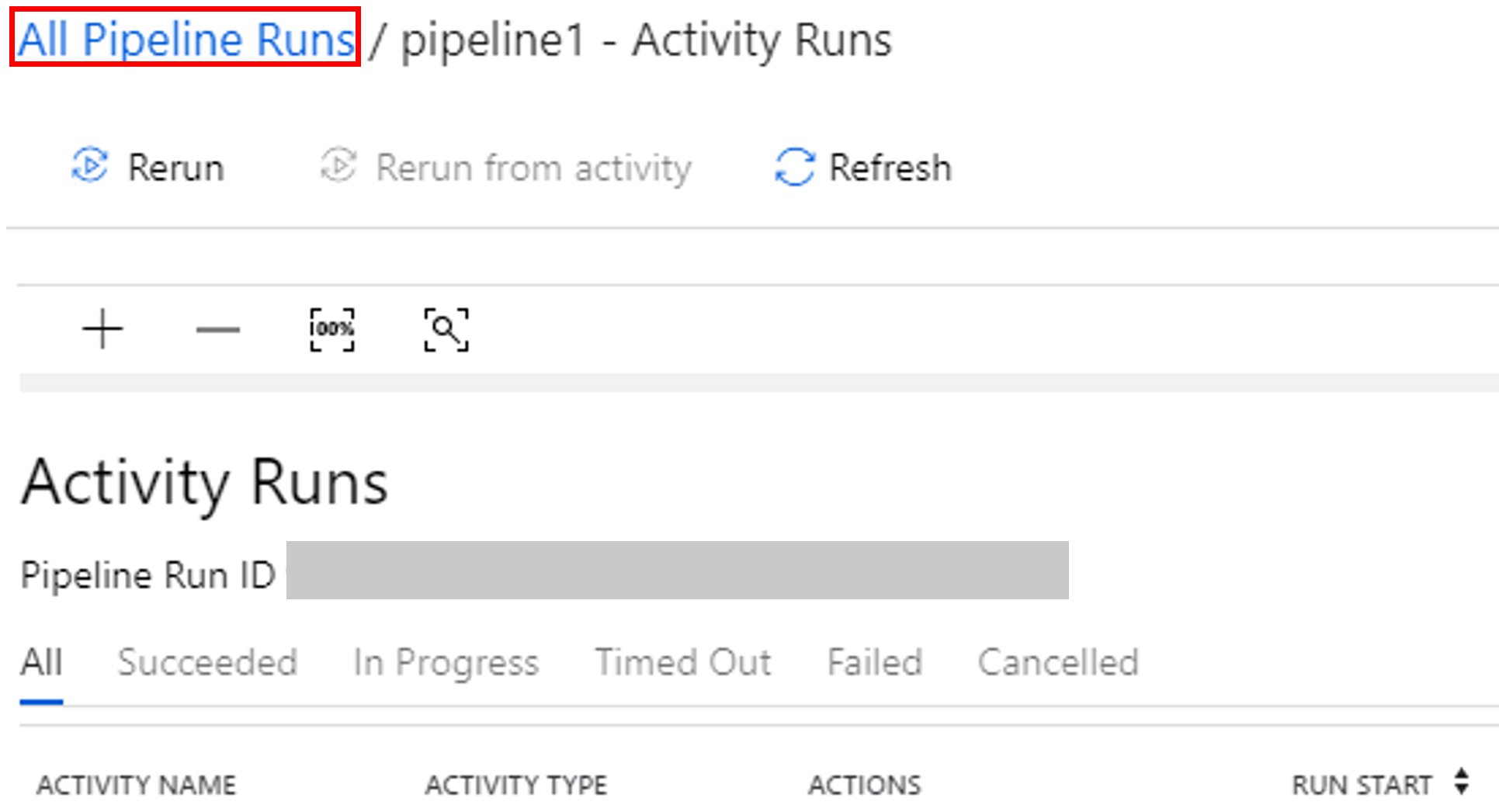
Surveiller l’exécution du pipeline.
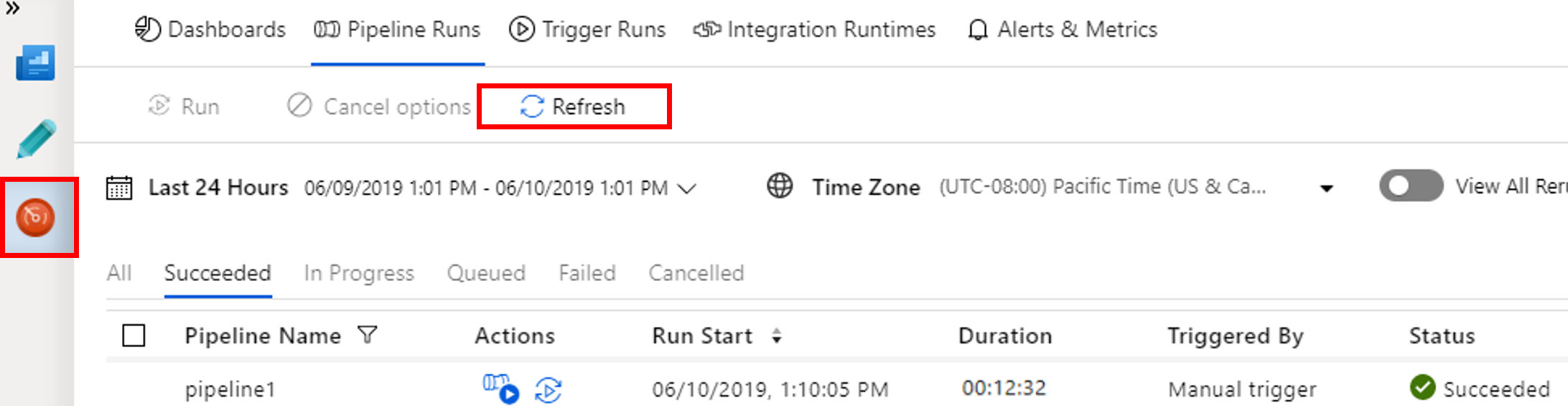
Basculez vers l’onglet Surveiller. Vérifiez qu’un pipeline est exécuté. La création d’un cluster Spark prend 20 minutes environ.
Cliquez régulièrement sur Actualiser pour vérifier l’état de l’exécution des pipelines.
Pour voir les exécutions d’activités associées à l’exécution du pipeline, cliquez sur le lien Afficher les exécutions d’activités dans la colonne Actions.
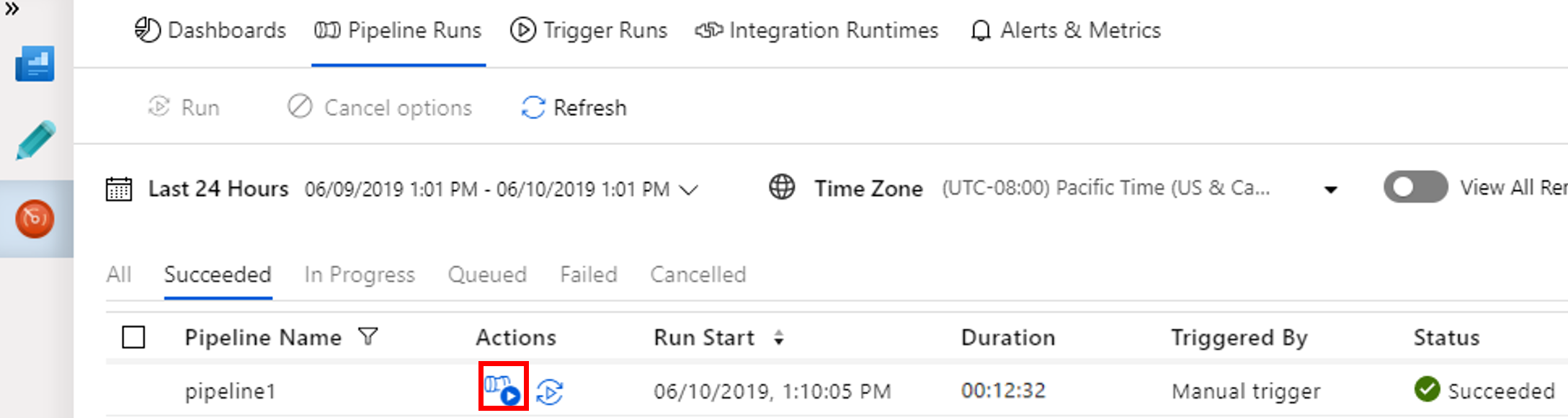
Vous pouvez basculer vers la vue des exécutions de pipelines en cliquant sur le lien Toutes les exécutions de pipeline en haut.
Vérifier la sortie
Vérifiez que le fichier de sortie est créé dans le dossier spark/otuputfiles/wordcount du conteneur adftutorial.
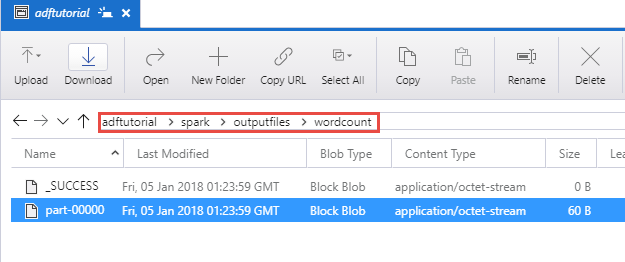
Le fichier doit contenir chaque mot du fichier texte entrée et le nombre d’apparitions du mot dans le fichier. Par exemple :
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Contenu connexe
Le pipeline dans cet exemple transforme les données à l’aide de l’activité Spark et un service lié HDInsight de la demande. Vous avez appris à :
- Créer une fabrique de données.
- Créer un pipeline qui utilise une activité Spark.
- Déclencher une exécution du pipeline.
- Surveiller l’exécution du pipeline.
Passez au tutoriel suivant pour découvrir comment transformer des données en exécutant un script Hive sur un cluster Azure HDInsight qui se trouve dans un réseau virtuel :